
文章目錄
- 1. 背景介紹
- 2. 架構設計
- 3. 方案實現
- 3.1 CDC
- 3.1.1 自定義插件
- 3.1.2 配置 MSK Connect
- 3.2 實時攝入
- 3.2.1 Glue 實現方案
- 3.2.1.1 在 Glue 中創建 Kafka connection
- 3.2.1.2 Glue Streaming 任務
- 3.2.2 EMS Serverless 實現方案
- 3.3 使用 Athena 查詢 Iceberg 表
- 3.3.1 查詢
- 3.3.2 Iceberg 表優化
- 3.3.3 Athena 中優化 Iceberg 表的方法
- 3.3.4 通過 Glue Data Catalog 優化 Iceberg 表
- 4. 總結
1. 背景介紹
新福利:新用戶可獲得高達 200 美元的服務抵扣金。
亞馬遜云科技新用戶可以免費使用亞馬遜云科技免費套餐(Amazon Free Tier)。注冊即可獲得 100 美元的服務抵扣金,在探索關鍵亞馬遜云科技服務時可以再額外獲得最多 100 美元的服務抵扣金。使用免費計劃試用亞馬遜云科技服務,最長可達 6 個月,無需支付任何費用,除非您選擇付費計劃。付費計劃允許您擴展運營并獲得超過 150 項亞馬遜云科技服務的訪問權限。

隨著業務的不斷的發展,對海量數據分析場景也變的更加多樣化,當前流行的大數據技術場景往往需要處理 PB 級的大規模數據,并且對分析場景的數據實時性要求更高。
用戶通常會面臨以下問題:1. 在處理大規模數據時需要頻繁的擴縮資源,帶來繁重的運維工作;2. 對于數據庫到數據湖的同步,需要對數據庫事務性的數據變更進行處理才能夠使得數據庫與數據湖之間數據保持一致性。
因此,本文提出基于 Serverless 服務來構建數據湖,該方案主要利用 MSK Connect,MSK Serverless,Glue,Athena 來構建無服務的數據湖方案,來幫助用戶降低海量數據實時分析場景中的架構復雜度以及運維難度。
2. 架構設計
本方案包含以下幾個步驟:
- 在 MSK Connect 中創建 MySQL 到 MSK 的連接器,以便將數據流入 Kafka 集群中。
- 配置 Glue Streaming Job,通過消費 MSK 中的 CDC 數據,將數據實時寫入 Iceberg 表中。
- 在 Athena 中對存入 Iceberg 表的數據進行查詢和分析,并且對 Iceberg 表進行優化。
方案架構
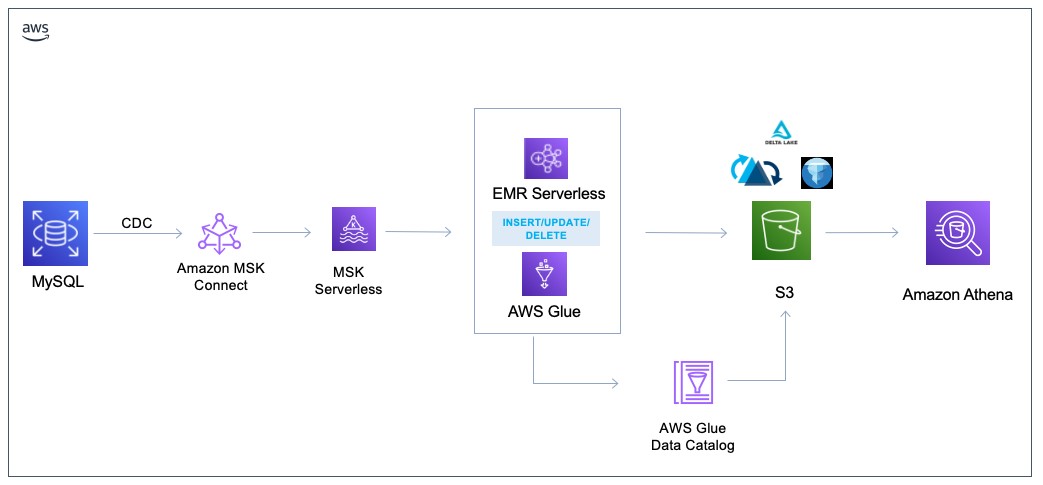
MSK Connect:MSK Connect 是 Amazon MSK 的一項功能,它使開發人員可以輕松地將數據流入和流出他們的 Apache Kafka 集群。MSK Connect 使用 Kafka Connect 2.7.1 版本,這是一個用于將 Apache Kafka 集群與數據庫、搜索引擎和文件系統等外部系統連接起來的開源框架。
使用 MSK Connect,可以部署專為 Kafka Connect 構建的完全托管的連接器,這些連接器將數據移入常用數據存儲(如 Amazon S3 和亞馬遜 OpenSearch 服務)或從中提取數據。可以部署第三方開發的連接器,例如 Debezium,用于將數據庫中的更改日志流式傳輸到 Apache Kafka 集群,或者部署現有連接器,無需更改代碼。Connector 會自動擴展以適應負載的變化,只需為使用的資源付費。
MSK Serverless:MSK Serverless 是 Amazon MSK 的一種集群類型,它使您無需管理和擴展集群容量即可運行 Apache Kafka。它可以在管理主題中的分區的同時自動預置和擴展容量,因此您可以流式傳輸數據,而無需考慮調整群集大小或擴展群集。
MSK Serverless 提供基于吞吐量的定價模式,因此您只需按實際用量付費。如果您的應用程序需要自動向上和向下擴展的按需流式傳輸容量,請考慮使用無服務器集群。
Glue:AWS Glue 是一項無服務器數據集成服務,可讓使用分析功能的用戶輕松發現、準備、移動和集成來自多個來源的數據。您可以將其用于分析、機器學習和應用程序開發。它還包括用于編寫、運行任務和實施業務工作流程的額外生產力和數據操作工具。
Athena:Amazon Athena 是一種交互式查詢服務,能夠輕松使用標準 SQL 直接分析 Amazon Simple Storage Service (Amazon S3) 中的數據。Athena 也支持 ACID 事務性數據的查詢,可以使用標準的 SQL 對 Iceberg 表數據進行增、刪、改、查的操作。
Apache Iceberg:Apache Iceberg 是 Amazon S3 中適用于大型數據集的開放表格式,可提供快速的大型表查詢性能、原子提交、并發寫入和 SQL 兼容表演進等功能。
Glue 3.0/4.0 原生支持開源數據庫框架 Iceberg。Iceberg 是為大數據平臺設計的,開發者可以使用它來存儲和查詢 PB 級數據集。除了 Glue,Amazon Athena 也已經與 Iceberg 深度集成,借助 Glue Data Catalog 對元數據的管理,可以快速使用 Athena 對 Iceberg 的表進行查詢分析,并且也可以通過 Athena 對 Iceberg 表進行寫操作。
3. 方案實現
3.1 CDC
我們使用 MSK Connect 來收集 MySQL binlog 產生的 CDC 數據。在 MSK Connect 中,只需要簡單的幾步操作,即可完成 CDC 數據的采集任務的配置。
3.1.1 自定義插件
使用 MSK Connect 前,我們需要為 MSK Connect 添加一個 Debezium MySQL Source Connector 插件(使用 1.9.7 版本),插件下載。下載后,在 MSK Connect 控制臺的自定義插件菜單中,創建一個自定義插件,并且下載的插件上傳到此處。
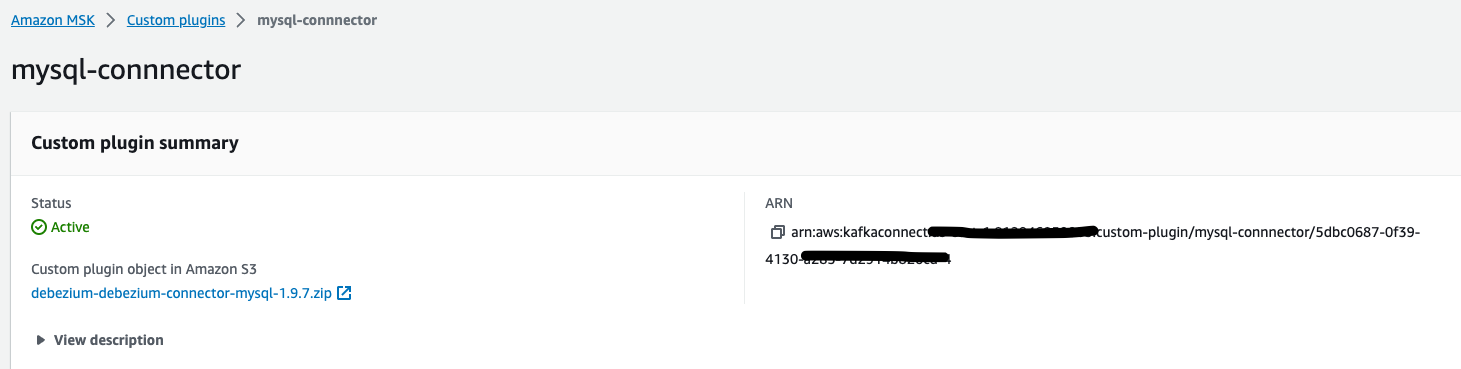
3.1.2 配置 MSK Connect
在 MSK Connect 控制臺,點擊創建 Connector,選擇已經創建好的 mysql 自定義插件。在 Connector configuration 中,如下為例子:
connector.class=io.debezium.connector.mysql.MySqlConnector
database.server.id=<custom id>
tasks.max=1
database.history.kafka.topic=dbhistory.<custom name>
database.history.kafka.bootstrap.servers=<mskserverless-endpoint>
database.server.name=<custom name>
database.port=3306
include.schema.changes=true
output.data.format=JSON
key.converter.schemas.enable=false
tombstones.on.delete=false
database.hostname=<RDS MYSQL ENDPOINT>
database.user=<RDS MYSQL USERNAME>
database.password=<RDS MYSQL PASSWORD>
value.converter.schemas.enable=false
insert.mode=upsert
database.include.list=<RDS MYSQL DB NAME>
decimal.handling.mode=string
time.precision.mode=adaptive_time_microseconds
database.connectionTimeZone=UT
topic.creation.enable=true
topic.creation.default.replication.factor=3
topic.creation.default.partitions=3
#MSK Serverless IAM 認證配置
database.history.consumer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
database.history.producer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
database.history.consumer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
database.history.consumer.security.protocol=SASL_SSL#按照正則表達式,將匹配前綴為tb_的表寫到同一個topic中
transforms=Reroute
transforms.Reroute.type=io.debezium.transforms.ByLogicalTableRouter
transforms.Reroute.topic.regex=(.*)tb_(.*)
transforms.Reroute.topic.replacement=$1<topicname>
這里,我們需要注意以下幾個配置參數:
- max:MySQL 連接器只使用一個 Task,因此不使用這個值,默認即可。
- creation.enable:由于 MSK Serverless 集群不能通過預置的方式設置集群參數,而 MSK Serverless 集群默認是不會自動創建 topic 的,因此在配置 MSK Connect 向 MSK Serverless 集群攝入數據的時候,需要指定自動創建 topic。
- on.delete:控制是否應在刪除事件后生成一個 delete 事件。當設置為 “true “時,刪除操作由一個刪除事件和一個后續的 tombstone 事件表示。當設置為 false 時,只發送一個刪除事件。發出墓碑事件(默認行為)允許 Kafka 在源記錄被刪除后完全刪除所有與給定鍵有關的事件。 因此,如果設置為 true 時,會收到一個空記錄的事件,由于,我們將數據寫入 Kafka 之后,需要消費數據根據 I/U/D 處理,因此建議將這個值設置為 false。
- transforms:如果我們需要將 MySQL 中的多個表寫入到一個 Topic 中,需要設置此參數,該參數通過使用正則表達式來將符合條件的表數據寫入到同一個 Topic 中。
需要注意的是 MSK Serverless 目前只支持 IAM 認證,在配置 MSK Connect 時需要指定 IAM 認證配置參數。
database.history.consumer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
database.history.producer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
database.history.consumer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
database.history.consumer.security.protocol=SASL_SSL
記錄 offset
當 MSK Connect 創建時,會自動創建 3 個 Topic (config.storage.topic,offset.storage.topic,status.storage.topic)用于記錄當前 Connect 相關的配置、狀態、offset 等。
當把這個 Connect 刪除后,重建時,需要從上一個 Connect 的最后的 offset 恢復,需要指定 offset.storage.topic 參數,這個參數需要配置在 Work Configuration 中。
另外,這個 topic 需要預先創建,并且設置 cleanup.policy=compact。命令如下:
kafka-topics.sh --bootstrap-server $MYBROKERS_SERVERLESSIAM --create \
--topic msk_connect_offsets_mysql-cdc-conect --partitions 3 \
--replication-factor 3 --command-config $KAFKA_HOME/config/client.properties \
--config cleanup.policy=compacts
有序性
MSK Connect 通過配置 message.key.columns 作為消息體的 key, kafka 的消息體的 key 默認是所采集的表的主鍵,如果表沒有主鍵,則消息體的 key 為空。
如果將多表攝入到一個 Topic 時,msk connect 會根據用戶表名+主鍵字段的方式來記錄 Key,并且按照 Key 分布到同一個 partition 中。
如果表沒有主鍵,也可以單獨根據表來設置該字段,作為數據的有序性。設置方式:
"message.key.columns": "topic-name:ID"
3.2 實時攝入
可以分別使用 Glue 或者 EMR Serverless 來實現數據的實時攝入。Glue 和 EMR Serverless 都支持 Spark,因此核心的業務實現都可以復用。下面分別來介紹這兩種數據實時攝入的方法。
3.2.1 Glue 實現方案
3.2.1.1 在 Glue 中創建 Kafka connection
打開【Amazon Glue Studio】,在左側菜單中點擊 Connectors,打開 Connectors 頁面,單擊【Create connection】
- Connection Type 選擇 Kafka
- Connection access 選擇 MSK,可以在下拉框中選擇已經創建好的 MSK 集群。(如果需要關聯自建的 Kafka 集群,可以選擇 Customer managed Apache Kafka),如果 MSK 設置了身份認證方式,需要在 Authentication 中選擇對應的身份認證類型
- 其他參數默認,點擊【Create Connector】
3.2.1.2 Glue Streaming 任務
獲取 Glue Streaming 代碼,參考代碼地址,在 Glue Studio 中創建一個 Spark script 任務,并且上傳下載的代碼。此代碼實現了通過 Glue 消費 MSK 中 CDC 日志數據,解析 I/U/D,將數據實時寫入 Iceberg 格式的表中。(也可以使用下面提交任務的腳本,自動下載樣例代碼并且在 Glue 中創建 Job)
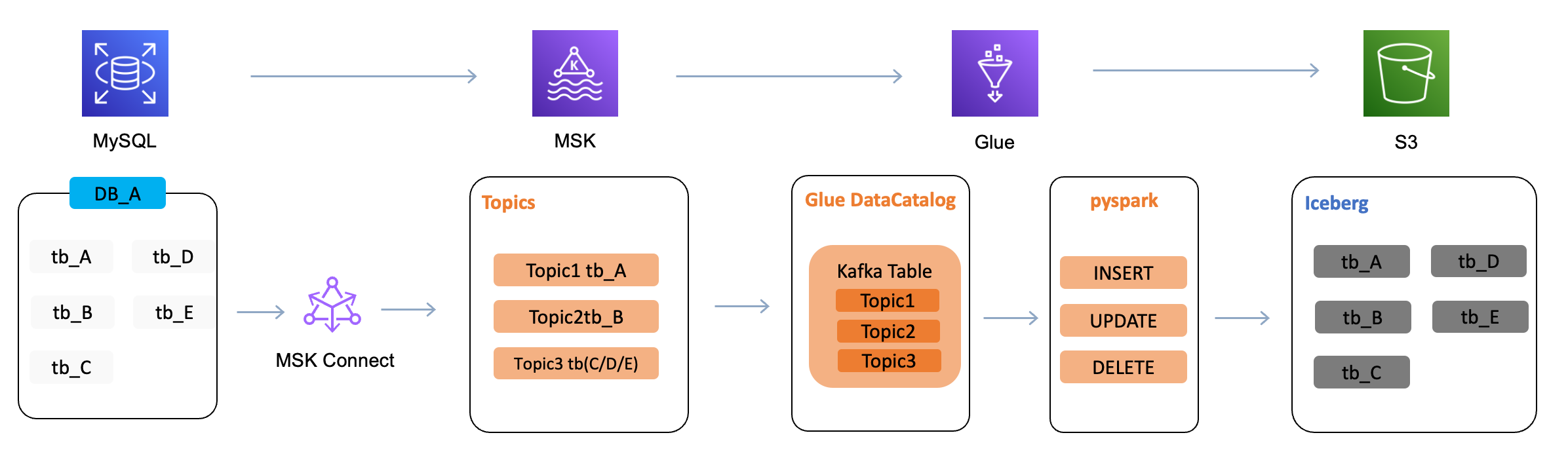
多表的實現
在 CDC 進行數據采集時,在 3.2.1 章節中已經介紹了通過 MSK Connect 的配置可以實現將多表數據寫入到一個 Topic 中,在 Glue 中,我們可以通過在 topicName 參數中設置多個 Topic,來實現多表的消費。而針對多表數據的處理,通過讀取 CDC log 中的 source 的內容來識別多表。
Iceberg Automatic Schema Evolution
對于實時數倉的場景,源表到數據湖時的 automatic schema evolution 是非常重要的。當源端的數據庫表結構發生變化,在目標端的數據湖中也需要做到實時的變更。目前 Spark 在 3.2 以上版本(Glue 4.0 支持 Spark 3.3)已經支持針對 Iceberg 表的 Schema 變更自適應處理方法。
參考如下方法:
- 創建 Iceberg 表時,在表屬性中設置 spark.accept-any-schema=true Spark 默認在生成計劃的時候會檢查寫入的 DataFrame 和表的 schema 是否匹配,不匹配就拋出異常。所以需要增加一個 TableCapability(TableCapability.ACCEPT_ANY_SCHEMA),這樣 Spark 就不會做這個檢查,交由具體的 DataFrame 來檢查
- 通過 DataFrame 的 writeTo 方法向 Iceberg 表寫數據時,設置參數 writeTo(tableName).option(“merge-schema”, “true”).append()
這樣,當數據寫入 Iceberg 表時,Spark 會通過 DataFrame 對目標表進行表結構的變更處理。
表參數配置
在數據實時入湖時我們還需要注意以下幾點:
- 對數據中 Update/Delete 的場景,在數據入湖時,需要根據表的主鍵字段來更新數據或者刪除數據。
- 時間字段的處理。
- 從消息隊列消費數據時,可能出現的亂序情況。
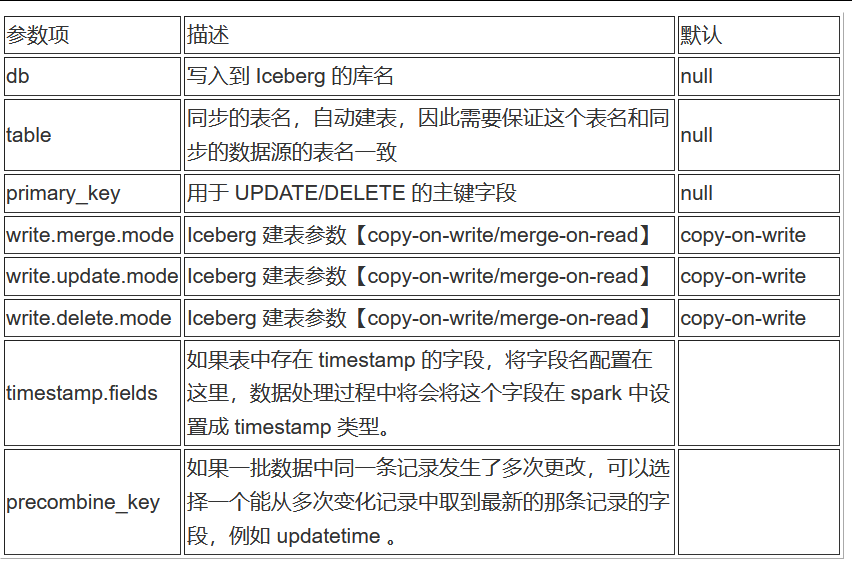
因此,增加了一個針對表屬性的配置文件,需要在這個配置文件來設置參數。配置文件采用 Json 的格式,示例如下:
[{"db":"<sink_database_name>","table":"sink_table_name","primary_key":"<primary_key>","format-version": 2,"write.merge.mode": "<merge-on-read or copy-on-write>","write.update.mode": "merge-on-read or copy-on-write","write.delete.mode": "merge-on-read or copy-on-write","timestamp.fields": ["<timestamp-col1>","timestamp-col2"],"precombine_key": "<precombine-key>"}]
參數說明:
提交任務
為了方便測試,可以通過以下腳本,來啟動一個 Glue Job。
首先,需要將代碼依賴的 python 腳本打包成 whl。
git clone https://github.com/norrishuang/cdc-data-lake-pyspark.gitcd cdc-data-lake-pyspark
pip3 install wheel
python3 setup.py bdist_wheel# 上傳到S3
aws s3 cp ./dist/transaction_log_venv-0.6-py3-none-any.whl s3://<s3-bucket>/pyspark/aws s3 cp ./aws-emr-serverless/iceberg/kafka-iceberg-streaming-glue.py s3://<s3-bucket>/pyspark/
創建一個 Glue Job(注意替換參數,例如 kafka-server,s3-bucket 為當前環境的服務地址)
MAIN_PYTHON_CODE_FILE=s3://<s3-bucket>/kafka-iceberg-streaming-glue.py
ADDITIONAL_PYTHON_MODULES=s3://<s3-bucket>/transaction_log_venv-0.6-py3-none-any.whl
KAFKA_SERVER='<kafka-server>'
TABLECONFFILE='s3://<s3-bucket>/config/<table-conf>.json'
AWS_REGION="us-east-1"
ICEBERG_WAREHOUSE=s3://<s3-bucket>/data/iceberg-folder/
TEMP_DIR=s3://<s3-bucket>/temporary/aws glue create-job \--name msk-to-iceberg \--role my-glue-role \--command '{ "Name": "gluestreaming", "PythonVersion": "3", "ScriptLocation": "'$MAIN_PYTHON_CODE_FILE'" }' \--region us-east-1 \--connections '{"Connections":["test"]}' \--output json \--default-arguments '{ "--job-language": "python","--additional-python-modules":"'$ADDITIONAL_PYTHON_MODULES'", "--aws_region": "'$AWS_REGION'", "--TempDir": "'$TEMP_DIR'","--conf": "spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions", "--config_s3_path": "'$TABLECONFFILE'", "--datalake-formats": "iceberg","--icebergdb": "<iceberg-database-name>","--glueconnect": "<glue-connect>","--tableconffile": "'$TABLECONFFILE'","--region": "'$AWS_REGION'","--warehouse": "'$ICEBERG_WAREHOUSE'","--starting_offsets_of_kafka_topic": "earliest","--user-jars-first": "true","--topics": "<topic-name>"}' \--glue-version 4.0 \--number-of-workers 3 \--worker-type G.1X
創建成功后,我們可以在 Glue ETL Jobs 中看到它,在控制臺中啟動這個作業。
3.2.2 EMS Serverless 實現方案
出于成本或者技術棧的選擇,我們也可以選擇使用 EMR Serverless 來替代 Glue ETL。因為都是使用 Spark 代碼實現,因此任務的配置參數已經表參數配置都與 Glue Job 保持一致。只是在 EMR Serverless 中有依賴的 python 庫需要通過打包依賴項的方式導入。下面是打包和提交腳本的方法:
- 1.獲取代碼
git clone https://github.com/norrishuang/cdc-data-lake-pyspark.gitcd cdc-data-lake-pyspark
- 2.打包公共類
pip3 install wheelpython3 setup.py bdist_wheel
- 3.打包 python 環境并且上傳到 S3
export S3_PATH=<s3-path>
# python lib
python3 -m venv --copies transaction_log_venvsource transaction_log_venv/bin/activate
pip3 install --upgrade pip
pip3 install boto3pip3 install ./dist/transaction_log_venv-0.6-py3-none-any.whl --force-reinstallpip3 install venv-pack
venv-pack -f -o transaction_log_venv.tar.gz# upload s3
aws s3 cp transaction_log_setup.tar.gz $S3_PATH
aws s3 cp aws-emr-serverless/iceberg/kafka-iceberg-streaming-emrserverless.py $S3_PATH
4.提交 EMR Serverless 作業
在提交 EMR Serverless 前,需要確認已經在 EMR Studio 中創建了 EMR Serverless Application,并且獲取到了 Application ID,需要作為下面提交腳本的輸入參數。
SPARK_APPLICATION_ID=<applicationid>JOB_ROLE_ARN=arn:aws:iam::<ACCOUNT_ID>:role/<ROLE>S3_BUCKET=<s3-buclet-name>STARTING_OFFSETS_OF_KAFKA_TOPIC='earliest'TOPICS='\"<topic-name>\"'TABLECONFFILE='s3://'$S3_BUCKET'/pyspark/config/tables.json'REGION='us-east-1'DATABASE_NAME='emr_icebergdb'WAREHOUSE='s3://'$S3_BUCKET'/data/iceberg-folder/'KAFKA_BOOSTRAPSERVER='<msk-bootstrap-server>'CHECKPOINT_LOCATION='s3://'$S3_BUCKET'/checkpoint/'JOBNAME="<job-name>"PYTHON_ENV=$S3_PATH/transaction_log_setup.tar.gzaws emr-serverless start-job-run \--application-id $SPARK_APPLICATION_ID \--execution-role-arn $JOB_ROLE_ARN \--name $JOBNAME \--job-driver '{"sparkSubmit": {"entryPoint": "s3://'${S3_BUCKET}'/pyspark/kafka-iceberg-streaming-emrserverless.py","entryPointArguments":["--jobname","'${JOBNAME}'","--starting_offsets_of_kafka_topic","'${STARTING_OFFSETS_OF_KAFKA_TOPIC}'","--topics","'${TOPICS}'","--tablejsonfile","'${TABLECONFFILE}'","--region","'${REGION}'","--icebergdb","'${DATABASE_NAME}'","--warehouse","'${WAREHOUSE}'","--kafkaserver","'${KAFKA_BOOSTRAPSERVER}'","--checkpointpath","'${CHECKPOINT_LOCATION}'"],"sparkSubmitParameters": "--jars /usr/share/aws/iceberg/lib/iceberg-spark3-runtime.jar,s3://<s3-bucket>/pyspark/*.jar --conf spark.executor.instances=10 --conf spark.driver.cores=2 --conf spark.driver.memory=4G --conf spark.executor.memory=4G --conf spark.executor.cores=2 --conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory --conf spark.archives='$PYTHON_ENV'#environment --conf spark.emr-serverless.driverEnv.PYSPARK_DRIVER_PYTHON=./environment/bin/python --conf spark.emr-serverless.driverEnv.PYSPARK_PYTHON=./environment/bin/python --conf spark.executorEnv.PYSPARK_PYTHON=./environment/bin/python"}}' \--configuration-overrides '{"monitoringConfiguration": {"s3MonitoringConfiguration": {"logUri": "s3://'${S3_BUCKET}'/sparklogs/"}}}'
提交之后,就可以在 EMR Serverless 控制臺觀察作業的執行狀態了。
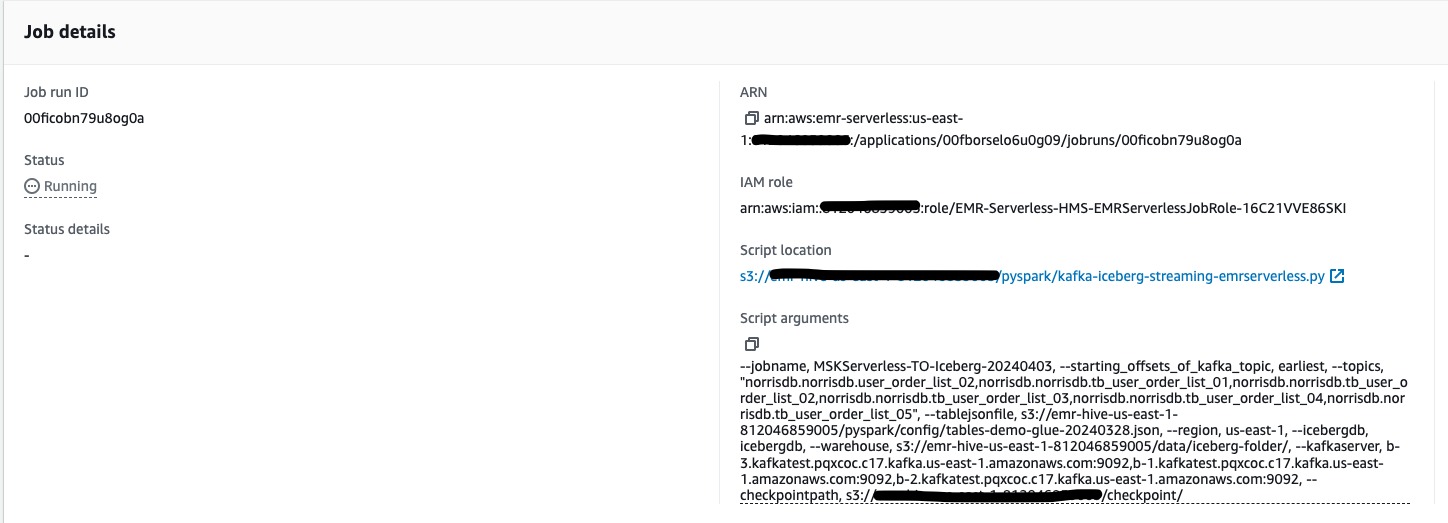
3.3 使用 Athena 查詢 Iceberg 表
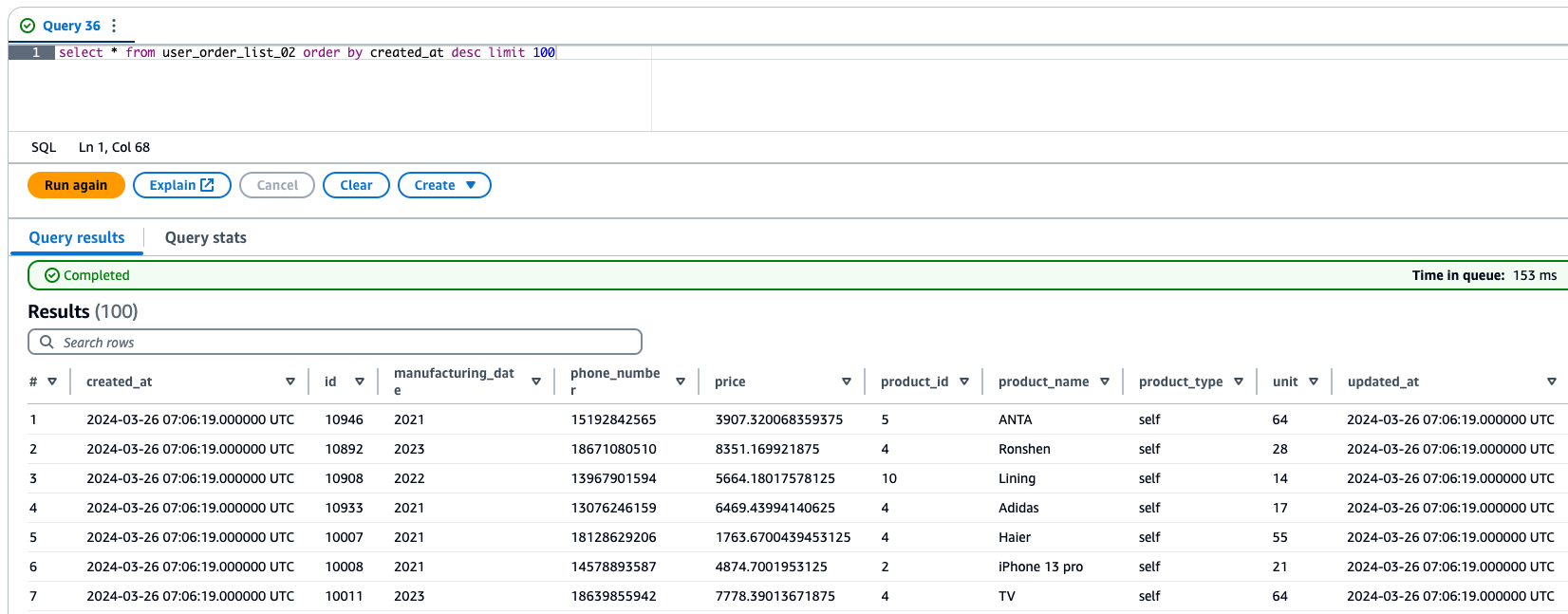
3.3.1 查詢
當同步任務運行起來之后,就可以在 Athena 中查詢相關的數據寫入情況。
3.3.2 Iceberg 表優化
對于實時攝入的場景,由于 Iceberg 元數據和版本管理的機制,會導致比較多的小文件,過多的小文件會導致查詢變慢,也會帶來更多的 S3 請求數量,導致成本的增加,因此需要定時對 Iceberg 表已經維護。通常可以在建表時設置以下參數來指定小文件合并的策略。
1. 優化參數
可以通過設置以下兩個參數來控制 Iceberg 元數據膨脹的問題
write.metadata.delete-after-commit.enabled=true
write.metadata.previous-versions-max=5
快照過期
history.expire.max-snapshot-age-ms = 259200000
2. 合并小文件參數
從 Iceberg 0.11 開始,支持了流式小文件合并。可以通過建表時初始化表屬性 TBLPROPERTIES ('write.distribution-mode'='hash'),動態合并小文件。這樣可以從源頭直接合并文件,一個 Task 會處理某個分區的數據,提交自己的 Datafile 文件。
也可以利用 Athena(以下章節 3.3.3) 或者 Glue (以下章節 3.3.4)來維護 Iceberg 的小文件。
3.3.3 Athena 中優化 Iceberg 表的方法
我們在 Iceberg 表屬性中添加快照過期、版本等參數,就可以通過 Athena,對 Iceberg 進行維護。
合并小文
可以通過以下命令對 Iceberg 的文件合并,執行后,它將按照設置的 write.target-file-size-bytes(默認 512M)參數來對文件進行合并。
OPTIMIZE <database>.<tablename> REWRITE DATA USING BIN_PACK[WHERE columns = <condition>]
在 Athena 提供的合并小文件方法中提供了一個過濾條件,可以選擇符合查詢條件的數據進行合并。所以如果需要優化的表分區數超出了 100,在 Athena 中就無法對整張表進行優化合并,這是由于 Athena 對于分區查詢的一個限制,這個時候可以在 WHERE 中添加分區條件,分批次的執行優化命令。
小文件合并完成后,會生成新的 snapshot,但是這個時候雖然小文件被合并成大文件了,但是歷史的文件仍然存放在 S3 中,沒有使用但是會占用存儲空間。我們需要根據實際的業務需求,對歷史變化數據的保留周期來設置合理的快照過期時間,并且設置版本相關參數。
可以在 Athena 中修改表的屬性 vacuum_max_metadata_files_to_keep=3(配置保留歷史數量的版本數,默認 100),可以按照實際場景來設置版本。例如設置為 3,元數據和數據都保留 3 份歷史數據和 1 份最新數據。
在 Athena 中設置快照過期以及保留元數據文件的數量
可以在 Athena 中修改表的屬性
vacuum_max_snapshot_age_seconds 默認 432000 秒 (5 天)
vacuum_max_metadata_files_to_keep 默認 100
ALTER TABLE <database>.<tablename> SET TBLPROPERTIES ('vacuum_max_snapshot_age_seconds'='86400''vacuum_max_metadata_files_to_keep'='3'
)
然后,可以執行下面的命令,刪除過期快照以及快照關聯的歷史數據文件。
3.3.4 通過 Glue Data Catalog 優化 Iceberg 表
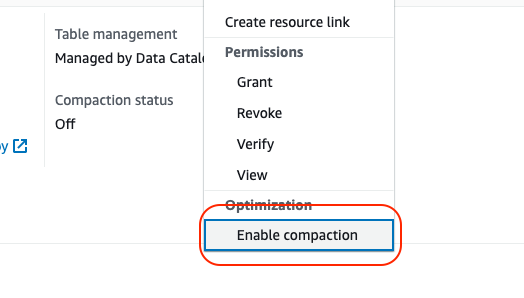
如果希望通過自動的方式對 Iceberg 表進行優化,那么可以使用 Glue Data Catalog 幫我們自動對 Iceberg 表進行壓縮。前提條件是,創建的 Iceberg 表需要使用 Glue Data Catalog。
- 在 Glue Data Catalog 中選擇一個 Iceberg 表。可以看到 Action 菜單中會多一個 Enable compation 的選項。
- 開啟之后,當向 Iceberg 表中寫入數據后,我們可以在 Glue Data Catalog 中觀察到執行文件壓縮的記錄。當然,這里會利用 Glue 的資源進行壓縮,所以我們可以看到會有 DPU 的消耗。

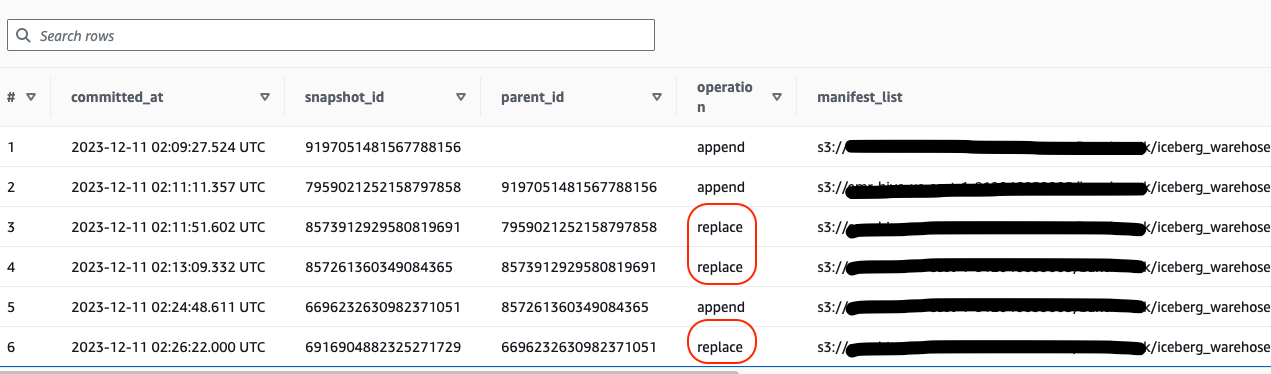
- 也可以通過 Iceberg 表的 snapshot 記錄查看,如下,每次寫入數據的 append 之后,都會有一次 replace 的操作,這就是由 Glue Data Catalog 的自動壓縮功能觸發的。
4. 總結
在當今數據分析領域,實時分析數據已經成為關鍵需求。實時數據湖能夠提供即時的數據可見性,支持實時決策和業務洞察,為企業帶來巨大價值。
在這個方案中我們使用 Amazon MSK Connect 實現數據變更數據(CDC)的實時采集并且攝入 MSK Serverless, 無需管理 Kafka 集群。利用 Amazon Glue 完成 CDC 數據的解析和處理,實現數據的增刪改操作,讓數據湖與數據庫之間保持了數據一致。采用 Amazon Athena 提供交互式的數據查詢。
基于 Iceberg 表格式構建實時數據湖,提供統一的數據訪問層。所有服務均采用 Serverless 服務,能夠大幅降低運維成本和復雜度,提高開發效率。
該方案適用于各種實時數據分析場景,如監控、業務分析、IoT 數據處理等;能夠快速構建可擴展的數據湖,滿足企業對于數據實時性和分析靈活性的需求;另外也通過 Serverless 架構實現了高可用性、彈性擴展和按需付費等優勢,大幅降低了運營成本。
以上就是本文的全部內容啦。最后提醒一下各位工友,如果后續不再使用相關服務,別忘了在控制臺關閉,避免超出免費額度產生費用~
)









)








)