大型語言模型(Large Language Models, LLMs)如GPT-OSS、GPT-4、LLaMA和Mixtral的快速發展顯著提升了人工智能的能力邊界,但同時也帶來了嚴峻的內存資源挑戰。以1200億參數的模型為例,在FP16精度下僅權重存儲就需要約240GB的內存空間,這遠超單個NVIDIA A100或H100 GPU的容量限制。
面對這一技術瓶頸,GPT-OSS通過創新的量化技術實現了突破性進展。該系統能夠在單個80GB GPU上運行1200億參數模型,同時保持競爭性的基準測試性能。其核心技術基于Mixture-of-Experts (MoE) 權重的訓練后量化,將權重精度降低至MXFP4格式,實現每參數僅需4.25位的存儲效率。
本文將從量化的數學理論基礎出發,深入分析硬件層面的技術影響,并探討實際部署策略的實現細節,全面闡述這一技術突破的實現機制。
大規模模型的內存約束分析
內存需求的數學建模
對于包含P個參數的神經網絡模型,其內存需求與數據精度呈線性關系。在FP32精度下,每個參數需要4字節存儲空間,因此總內存需求為:
Memory = P × 4 bytes
當采用FP16精度時,內存需求減半:
Memory = P × 2 bytes
針對1200億參數的模型,不同精度下的內存需求對比顯示:FP32精度需要480GB內存空間,在單GPU環境下無法實現;FP16精度雖然將需求降至240GB,但仍然超出現有單GPU的容量限制。
傳統解決方案的局限性
傳統的模型分片技術雖然可以將大型模型分布在多個GPU上,但這種方法引入了新的技術挑戰。高速互連帶寬(如NVLink或InfiniBand)成為系統性能的關鍵瓶頸,同時顯著增加了硬件成本、部署復雜性以及跨設備通信延遲。這些因素限制了大規模模型在資源受限環境中的實際應用。
量化技術的理論基礎
量化技術通過減少每個參數的表示位數來實現內存壓縮。其數學表達式可以形式化為:
Q(w) = clip(round(w/Δ), ?2^(b?1), 2^(b?1)?1) × Δ
其中,w表示原始權重值,b表示量化位數(FP4格式為4位),Δ表示量化比例因子。這一過程通過離散化連續的權重分布來實現壓縮,同時需要在精度損失和存儲效率之間找到最優平衡點。

量化技術帶來的優勢體現在三個關鍵方面:內存節省通過減少每個權重的存儲空間實現顯著的容量優化;計算加速利用低位矩陣乘法操作提升運算效率;帶寬減少降低了顯存與流式多處理器之間的數據傳輸負載。
低精度浮點格式的技術特征
FP4格式的結構與特性
FP4(4位浮點)格式采用符號-指數-尾數的布局結構:
| S | EE | M | | 1 | 2 | 1 |
在相關研究文獻中,FP4格式通常采用radix-4結構,包含1位符號位、3位指數位和0位尾數位。然而,根據Hugging Face的研究分析,采用2位指數和1位尾數的組合能夠在實際應用中獲得更優的性能表現。FP4格式相比FP32實現了8倍的存儲壓縮,但其較窄的動態范圍對高方差權重的表示構成了技術挑戰。
FP8格式的平衡設計
FP8(8位浮點)格式提供了兩種主要的布局方案:E4M3格式在數值范圍和精度之間實現良好平衡,適用于大多數深度學習場景;E5M2格式在極端數值范圍下表現更優,特別適合處理異常值分布。NVIDIA Hopper GPU架構對FP8格式提供了廣泛的硬件支持,使其成為壓縮效率和計算精度之間的理想折衷方案。
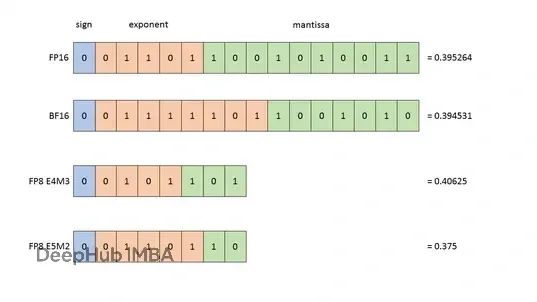
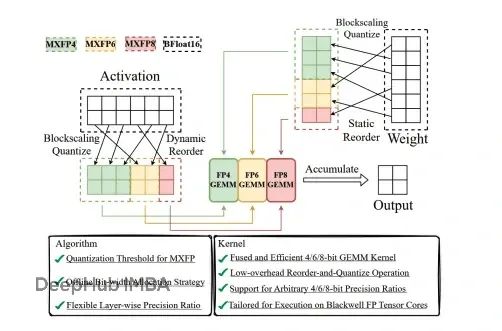
MXFP4的智能化設計
MXFP4(混合精度FP4)代表了量化技術的重要進步。該格式通過動態調整權重塊的縮放因子,實現了精度和壓縮率的優化平衡。雖然其位數略有增加(約4.25位),但通過更細粒度的敏感參數編碼,有效降低了量化誤差對模型性能的影響。
Mixture-of-Experts架構的量化優勢
Mixture-of-Experts架構通過專家網絡的稀疏激活實現計算效率的提升。在包含N個專家的系統中,路由器機制為每個輸入token僅激活k個專家(其中k遠小于N),從而在保持模型容量的同時顯著減少單次前向傳播的計算量。
MoE架構的一個重要特征是其參數分布的不均勻性:超過90%的模型參數集中在專家網絡的權重中。這種分布特性為量化技術的應用創造了理想條件。通過對MoE權重進行激進量化,可以實現巨大的內存節省,同時路由器和嵌入層可以保持高精度表示,確保模型的核心功能不受影響。
GPT-OSS的內存優化計算分析
基于GPT-OSS的具體配置參數:總參數數量為1200億,其中MoE參數占1080億(90%),非MoE參數為120億(10%),我們可以進行詳細的內存需求分析。
在未應用量化技術的FP16配置下,MoE權重需要216GB存儲空間(108B × 2B),非MoE參數需要24GB空間(12B × 2B),總計240GB,超出單GPU容量限制。
采用MXFP4量化技術后(4.25位等效于0.53125字節),MoE權重的存儲需求降至57.4GB(108B × 0.53125),而非MoE參數仍保持FP16精度的24GB。經過優化后的總內存需求為81.4GB,通過少量運行時優化即可適配80GB A100 GPU的容量限制。
硬件實現的技術挑戰與解決方案
當前GPU架構中的tensor core對FP4格式的原生支持仍然有限,這要求系統采用位切片操作或開發自定義CUDA內核來實現高效計算。雖然NVIDIA的Hopper架構為FP8格式提供了更好的硬件支持,但FP4格式的計算通常需要通過軟件模擬實現,這在一定程度上影響了計算效率。
內存帶寬是影響大規模模型推理性能的關鍵因素。傳統的1200億參數FP16模型推理需要約1.9TB/s的內存帶寬,而MXFP4量化技術將這一需求降低約3.8倍,至500GB/s左右,使其完全處于A100 GPU的帶寬承受范圍內。
精度與壓縮效率的量化分析
不同量化格式在內存壓縮和精度保持方面的性能表現存在顯著差異。FP16格式相對于FP32實現2倍內存減少,精度損失幾乎為零;FP8格式實現4倍壓縮,精度下降控制在0.1%至0.3%之間;傳統FP4格式雖然實現8倍壓縮,但精度損失可能達到1%至3%;而MXFP4格式在實現約7.5倍壓縮的同時,將精度損失控制在0.3%以內,展現了卓越的技術平衡。
總結
GPT-OSS通過MoE權重的MXFP4量化技術實現了大規模語言模型部署的重要突破。該技術方案使80GB GPU能夠托管1200億參數模型,在幾乎不損失精度的前提下顯著降低了內存帶寬需求,為資源受限的團隊和組織提供了新的部署可能性。
隨著人工智能模型規模向數萬億參數發展,類似的量化優化技術將成為實現AI技術民主化訪問的關鍵支撐。這些技術創新不僅解決了當前的資源約束問題,更為未來更大規模模型的實際應用奠定了重要的技術基礎。
參考文獻:
introduces new methods that allow training with FP4 while maintaining accuracy comparable to BF16/FP8 for up to 13B-parameter models.
Training LLMs with MXFP4” details training strategies using MXFP4 GEMMs with stochastic rounding and transforms for variance reduction — showing that MXFP4 can nearly match BF16 with speedups.
“LLM-FP4: 4-Bit Floating-Point Quantized Transformers” presents post-training quantization of LLMs to 4 bits, discussing challenges, exponent bit allocations, and activation quantization techniques.
MxMoE: Mixed-precision Quantization for MoE with Accuracy and Performance Co-Design”explores how MoE models lend themselves to ***\mixed-precision quantization strategies, optimizing for expert activation frequency and hardware dynamics.(https://arxiv.org/abs/2505.05799)
https://avoid.overfit.cn/post/462b6fb63ffa41b3828a7be09b041843

)

)





:nvidia與cuda介紹)
)

)






