
筆記整理:蘭雅榕,浙江大學碩士生,研究方向為知識圖譜、大語言模型
論文鏈接:https://ojs.aaai.org/index.php/AAAI/article/view/33662
發表會議:AAAI 2025
1. 動機
提高開源大型語言模型(LLM)的數學推理能力是一項有價值但持續的挑戰,目前有的利用涉及思維鏈(CoT) 原理的注釋或生成的問題-解決方案數據對對模型進行微調的方法雖然有一定作用,但是對于復雜的數學問題提升不大,且其完全忽略了結合問題思考相應定理的顯性思維過程,增加了涉及無關定理和幻覺的危險,該限制阻礙了推理過程的透明度和可解釋性,使錯誤診斷和糾正更加困難。
對于人類而言,能否根據給定的問題選擇合適的定理是影響最終解決方案質量的關鍵因素,但這在?LLM 推理領域的先前研究中卻被忽視了。本文提出了一種新穎的方法,以增強 LLM 將數學定理應用于具體問題的能力,我們稱之為定理原理 (TR)。
2. 貢獻
(1)本文提出了一種方法,用于明確學習如何將定理應用于具體問題,并收集包含 TR 原則的數據集。
(2)本文設計了策略,從問題-定理對中自動演化出面向定理的指令,從而有助于從多個層次的視角學習 TR。
(3)在本文提到的的數據集上進行微調的模型實現了持續的改進,展現了該方法在提升 LLM 數學推理能力方面的潛力。
3. 方法
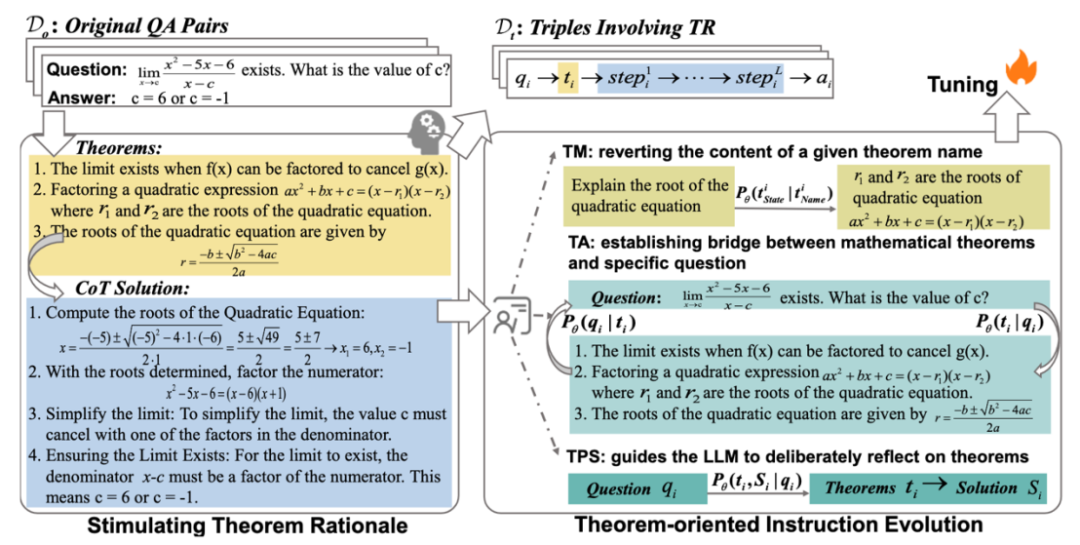
所謂定理基本原理就是涉及為特定問題選擇和利用定理原則的聯合分布定義,一個關鍵點在于將特定定理集和特定問題結合的過程,極具挑戰但是通常都被忽視。論文中引入了一個特定的提示來刺激?LLM 從每個原始 (qi, ai) 對中自動擴展涉及 TR 的 (qi, ti, Si) 三元組,并伴隨著啟發式算法進行進一步篩選,以確保數據質量。
原始數據收集:
收集問題-答案對:為LLM提供一些相關信息以生成更準確的三元組,使用BM25從以前的觀測中檢索最相關的三元組。首先在不同數據集中收集問題-答案對,更關注高水平問題,這些問題對于建立問題和定理之間的聯系更有幫助。
生成定理數據:論文中編譯了一個專門的提示和少量的上下文示例,以指導?GPT-4o1 從其參數知識中反思對應于 qi 的定理 ti,并在編寫解決方案之前明確列出 ti。通過提示中的刺激,生成的響應明確涉及推導出答案 ai 所需的數學定理 ti 和 ti 約束內的逐步解決方案,模仿了人類數學問題解決的過程。因此,我們將 Do 擴展到由并聯 (qi, ti, Si) 三元組組成的 Dt。
人工注釋和過濾:手動過濾三類不合理樣本(包含不一致最終答案的樣本,包含明顯定理不一致或者錯誤的樣本和包含過長、無意義且重復的解決方案的樣本)。此外實施重復數據刪除和基于長度的啟發式后處理策略。計算?Dt 中所有 (qi, ti, Si) 三元組的解 Si 的長度分布,去除長度異常的解(基于信念:如果模型有足夠的信心來掌握問題,則解決方案將在有限的推理步驟內完成。)
以定理為中心的指令優化:
參考人類教師在數學教學化中采用的方法,發展以定理為中心的分層指令;a) 建立概念理解,(b) 將數學概念與其應用聯系起來,(c) 培養解決問題的能力。設計與這三種能力對應的指導策略,以從Dt進化指令:
Theorem Memorization(TM)策略:涉及從定理名字到定理內容的映射,從Dt中提取1800個定理完成。
Theorem Alignment (TA):雙向TA指令策略:正向出發:提示列出指定問題所需的定理;反向出發:自動編寫示例來演示指定定理的應用。
Theorem-based Problem Solving (TPS):模型需要將明確地將思考相應的定理作為解決問題的第一步,而不是像?CoT 中的實踐那樣將它們耦合到解決方案中。
以?TM、TA 和 TPS 為指導原則,利用 GPT 生成多樣化的指令描述,從而從 Dt 中提取總共 30k 的指令數據用于后續訓練。
指令微調:
收集了48k個指令和響應數據對,使用因果語言建模來全參數微調llama3-8b。
4. 實驗
實驗設定:
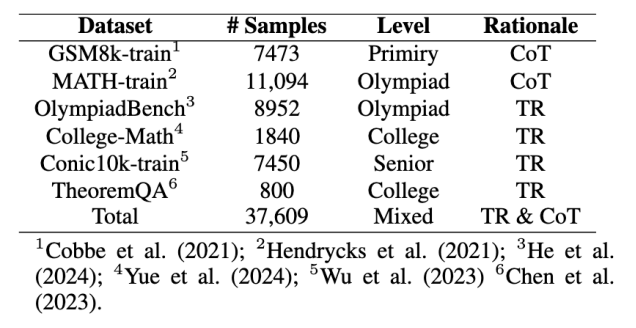
數據集:ID(Conic10K、MATH、GSM8k);OOD(MMLU-pro-Math、JEEBench-Math、SciBench、SAT-Math)包含開放式問題和多項選擇題
baseline:具有相同參數尺度的高級開源模型,包括?LLaMA2、Calactica、AQuA-SFT、WizardMath和 MAmmoTHCoT。以及具有代表性的閉源大模型例如 GPT-4、GPT-3.5 和 Claude-2。
評估指標:準確性
實驗結果:
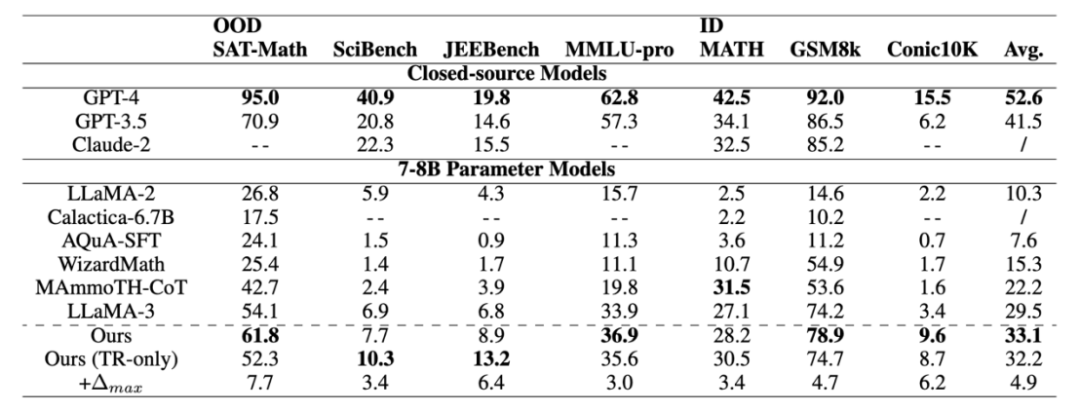
在包含不同數學級別的各種評估數據集中表現出準確性的一致提高,與?IND 數據集相比,模型在 OOD 數據集上獲得了更高的性能,這表明從 TR 中學習賦予了模型強大的數學推理能力。
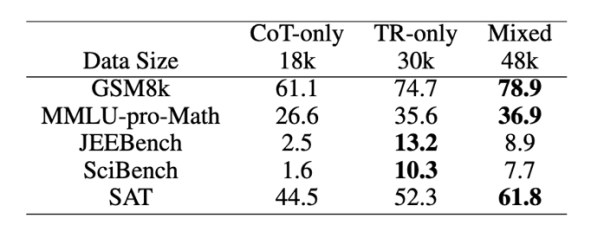
對于知識密集型數學任務,顯式學習和利用定理對提高推理能力起著至關重要的作用。
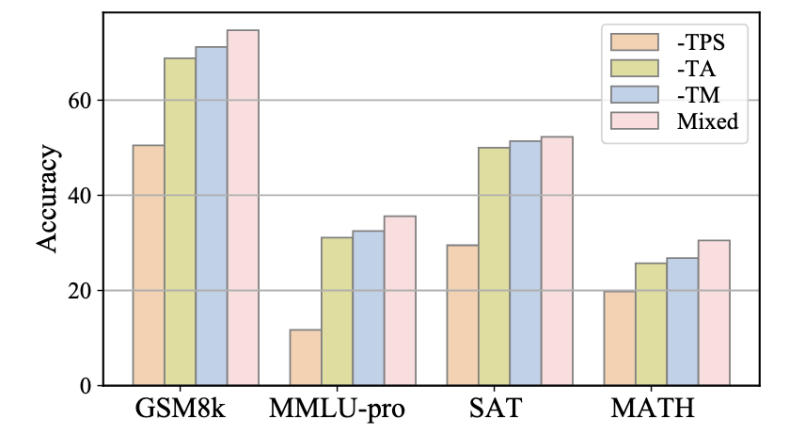
實驗還評估了三種指令有效性:對各種提出的面向定理的教學進化策略進行了進一步的消融研究,分別消除了專注于?TM、TA 和 TPS 策略的指令,并使用得到的子集 D-TM、D-TA 和 D-TPS 來微調模型。與使用合并數據集相比,刪除這些子集中的任何一個都會導致準確性降低,這凸顯了論文提出的指令進化方法而不是直接使用原始問答三元組訓練的必要性。比較去除不同子集帶來的性能下降,觀察到省略 TPS 導致的性能下降最大,其次是 TA 和刪除 TM 帶來的影響最小。這一發現驗證了假設:僅僅將數學定理作為普通文本記憶是遠遠不夠解決數學問題的,關鍵過程是學習如何將定理應用于特定問題。TA 暗示了將相應的定理與問題對齊的基本原理,而 TPS 在解決方案中進一步引入了定理的約束,因此為解決問題做出了更大的貢獻。
5. 總結
本文旨在學習將數學定理應用于具體問題,以提升大型語言模型(LLM)的數學推理能力。該工作精心構建了一個包含并行問題-定理-解三元組的高質量數據集,該數據集涉及TR原則。此外,他們提出了一種以定理為導向的策略來增強三元組中的指令,旨在使LLM能夠從不同角度運用定理。在廣泛使用的評估基準上進行的大量實驗表明,使用此數據集調整的模型獲得了強大的數學能力。此外,我們證實了明確引入與定理相關的思想對于提升閉源LLM性能的有效性。該工作為未來的數學推理和糾錯工作提供了新的視角。
OpenKG
OpenKG(中文開放知識圖譜)旨在推動以中文為核心的知識圖譜數據的開放、互聯及眾包,并促進知識圖譜算法、工具及平臺的開源開放。


點擊閱讀原文,進入 OpenKG 網站。

)





:nvidia與cuda介紹)
)

)








