在人工智能飛速發展的今天,機器學習作為其核心技術,正深刻改變著我們的生活與工作。從 AlphaGo 戰勝圍棋世界冠軍,到日常的智能推薦、人臉識別,機器學習的應用無處不在。本文將從基礎概念出發,帶你系統了解機器學習的核心邏輯、關鍵術語、學習類型及模型評估方法,為入門機器學習打下基礎。
一、什么是機器學習?
本質:
機器學習的本質是讓計算機從數據中自主學習規律,并利用這些規律解決實際問題。
1.處理某個特定的任務,以大量的經驗為基礎。
2.對任務完成的好壞給予一定的評判標準。
3.通過分析經驗數據,使任務完成的更好。
簡單來說,傳統編程是 “人類寫規則,機器執行”,而機器學習是 “機器從數據中找規則,自主優化”。
二、機器學習核心術語:讀懂數據的 “語言”
1. 數據相關術語
數據集:數據記錄的集合稱為一個"數據集"
樣本:數據集中每條記錄是關于一個事件或對象的描述,稱為"樣本"
特征(屬性):反映事件或對象在某方面的表現或性質的事項
屬性空間:所有特征構成的多維空間,每個樣本對應空間中的一個點(如 “色澤 + 根蒂 + 敲聲” 構成三維空間,每個西瓜對應一個三維坐標)。
2. 學習過程術語
訓練集:用于模型學習的數據,包含 “特征 + 標簽”(如標注了 “好瓜 / 壞瓜” 的西瓜數據)。
測試集:用于驗證模型性能的數據,通常不包含標簽,由模型預測后與真實結果對比(如未標注的西瓜數據,測試模型能否正確判斷好壞)。
模型:通過訓練得到的 “規律總結器”,能根據新樣本的特征輸出預測結果(如 “色澤青綠 + 根蒂蜷縮→好瓜” 的規則集合)。
三、機器學習的兩大核心類型:監督與無監督
1. 監督學習:有 “老師” 指導的學習
監督學習的訓練數據包含特征 + 標簽(即 “正確答案”),模型通過學習特征與標簽的對應關系,實現對新數據的預測。
分類:標簽是離散值(如 “好瓜 / 壞瓜”“垃圾郵件 / 正常郵件”),目標是將新樣本歸入已知類別。
回歸:標簽是連續值(如房價、溫度),目標是預測新樣本的具體數值(如 “88 平米房屋→價格 88 萬元”)。
2. 無監督學習:無 “答案” 的自主探索
無監督學習的訓練數據只有特征,沒有標簽,模型需自主發現數據中的隱藏結構。無需人工標注標簽,讓機器從無標簽數據中自主探索規律
聚類任務:將相似樣本自動歸為一類(如無需標注,自動將用戶按消費習慣分為 “高消費群”“低頻消費群”)。
3.集成學習:通過構建并結合多個學習器來完成學習任務。
集成學習通過組合多個基礎模型的預測結果,利用 “群體智慧” 提升性能,核心是整合優勢、彌補單一模型局限。
關鍵前提
基礎模型需具有多樣性(預測誤差不高度相關)
單個模型需具備一定準確性(不能太差)
四、模型評估:如何判斷模型好壞?
1. 基礎評估指標
錯誤率與精度:錯誤率是分類錯誤的樣本數占樣本總數的比例,精度 =‘ 1 - 錯誤率’。
殘差:回歸任務中,預測值與真實值的差異(如預測房價 100 萬,實際 95 萬,殘差 5?
查準率(P)與查全率(R):
查準率:預測為 “正類” 的樣本中,實際為正類的比例(如預測 10 個好瓜,其中 8 個真的好,查準率 80%)。
查全率:所有實際正類中,被正確預測的比例(如實際 10 個好瓜,模型預測對 8 個,查全率 80%)。兩者通常存在權衡:追求 “選的都是好瓜”(高查準率)可能漏掉部分好瓜(低查全率),反之亦然。


2. 數據劃分方法
為確保評估客觀,需合理劃分訓練集與測試集:
留出法:直接將數據集D劃分為兩個互斥的部分,其中一部分作為訓練集S,另一部分用作測試集T 。
交叉驗證法:先將數據集D劃分為k個大小相似的互斥子集,每次采用k?1個子集的并集作為訓練集,剩下的那個子集作為測試集。
3. 常見問題:欠擬合與過擬合
欠擬合:模型未學好數據規律(如僅用 “色澤” 判斷西瓜好壞,忽略根蒂、敲聲等關鍵特征),表現為訓練誤差和測試誤差都高。
欠擬合的處理方式: 1. 添加新特征,當特征不足或者現有特征與樣本標簽的相關性不強時,模型容易出現欠擬合。 2. 增加模型復雜度:簡單模型的學習能力較差,通過增加模型的復雜度可以使模型擁有更強的擬合能力。 3. 減小正則化系數:正則化是用來防止過擬合的,但當模型出現欠擬合現象時,則需要有針對性地減小正則化系數。
過擬合:模型 “死記硬背” 訓練數據,甚至學到噪聲(如認為 “有鋸齒的才是樹葉”,誤判光滑樹葉為非樹葉),表現為訓練誤差低但測試誤差高。
過擬合的處理方式: 1. 增加訓練數據:更多的樣本能夠讓模型學習到更多更有效的特征,減小噪聲的影響。 2. 降維:即丟棄一些不能幫助我們正確預測的特征。 3. 正則化(regularization)的技術,保留所有的特征,但是減少參數的大小(magnitude),它可以改善或者減少過擬合問題。 4. 集成學習方法:集成學習是把多個模型集成在一起,來降低單一模型的過擬合風險。
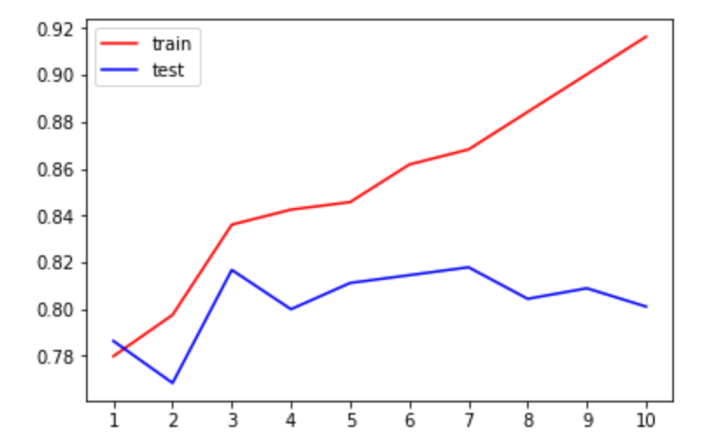
上為過擬合,test低。若欠擬合,train和test都低。正常時都高或走向一致。
五、機器學習的核心原則
1.奧卡姆剃刀原理:
“如無必要,勿增實體”, 在所有可能選擇的模型中,我們應該選擇能夠很好的解釋已知數據,并且十分簡單的模型。 ? 如果簡單的模型已經夠用,我們不應該一味的追求更小的訓練誤差,而把模型變得越來越復雜。
2.沒有免費的午餐(NFL):
不存在 “萬能算法”,算法優劣取決于具體問題。對于基于迭代的最優化算法,不存在某種算法對所有問題(有限的搜索空間內)都有效。
六、總結:機器學習的本質是 “數據驅動的智能”
機器學習不是神秘的 “黑科技”,而是一套 “從數據中找規律、用規律解決問題” 的系統化方法。從監督學習的 “有答案學習” 到無監督學習的 “自主探索”,從模型訓練到評估優化,每個環節都圍繞 “讓機器更好地理解數據” 展開。掌握核心概念(特征、標簽、訓練 / 測試集)、理解兩大學習類型(監督 / 無監督)、識別常見問題(欠擬合 / 過擬合)是關鍵。




)

)








)
--圖論)


在Linux里面怎么查看進程)