在深度學習框架普及的今天,回歸基礎用NumPy從頭實現機器學習模型具有特殊意義。本文將完整演示如何用純NumPy實現二次函數回歸任務,揭示機器學習底層原理。整個過程不使用任何深度學習框架,每一行代碼都透明可見。
1. 環境配置與數據生成
import numpy as np
from matplotlib import pyplot as plt 設置隨機種子保證可復現性
np.random.seed(100) 生成訓練數據:100個點在[-1,1]區間均勻分布
x = np.linspace(-1, 1, 100).reshape(100, 1)基于y=3x2+2生成目標值,并添加高斯噪聲
y = 3 * np.power(x, 2) + 2 + 0.2 * np.random.rand(x.size).reshape(100, 1)
**數據可視化結果: **
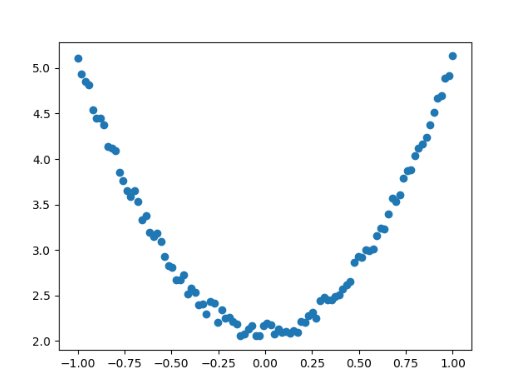
散點圖展示了添加噪聲后的數據分布,我們的目標是找到最佳擬合曲線y=wx2+by=wx^2+by=wx2+b
2. 模型初始化與核心參數
隨機初始化待學習參數
w = np.random.rand(1, 1) # 權重參數 (理論值應接近3)
b = np.random.rand(1, 1) # 偏置項 (理論值應接近2)lr = 0.001 # 學習率 (梯度下降步長)
epochs = 800 # 訓練輪數
初始參數可視化:
print(f"初始參數: w={w[0][0]:.4f}, b={b[0][0]:.4f}")
典型輸出: w=0.7123, b=0.1582 (每次運行結果不同)
3. 訓練過程與數學原理
3.1 前向傳播計算預測值
y_pred = np.power(x, 2) * w + b
3.2 損失函數定義
采用均方誤差(MSE)的變體:
loss = 0.5 * (y_pred - y) 2
total_loss = loss.sum() # 所有樣本損失之和
3.3 梯度計算解析
關鍵數學推導(鏈式法則):
權重w的梯度: ?Loss/?w = Σ(y_pred - y)*x2
grad_w = np.sum((y_pred - y) * np.power(x, 2))偏置b的梯度: ?Loss/?b = Σ(y_pred - y)
grad_b = np.sum((y_pred - y))
3.4 參數更新(梯度下降)
w -= lr * grad_w # w = w - η·(?Loss/?w)
b -= lr * grad_b # b = b - η·(?Loss/?b)
4. 完整訓練代碼
for epoch in range(epochs):# 前向傳播y_pred = np.power(x, 2) * w + b # 損失計算 loss = 0.5 * (y_pred - y) 2total_loss = loss.sum()# 梯度計算grad_w = np.sum((y_pred - y) * np.power(x, 2))grad_b = np.sum((y_pred - y))# 參數更新w -= lr * grad_w b -= lr * grad_b# 每100輪打印訓練進展 if epoch % 100 == 0:print(f"Epoch {epoch}: w={w[0][0]:.4f}, b={b[0][0]:.4f}, Loss={total_loss:.4f}")
訓練過程輸出:
Epoch 0: w=0.9461, b=0.3827, Loss=160.9256
Epoch 100: w=2.1433, b=1.8047, Loss=1.8925
Epoch 200: w=2.6555, b=2.0404, Loss=0.4583
Epoch 300: w=2.8543, b=2.1023, Loss=0.2985
...
Epoch 700: w=2.9887, b=2.0161, Loss=0.2502
5. 訓練結果可視化
生成預測曲線
x_test = np.linspace(-1, 1, 30).reshape(30, 1)
y_test = np.power(x_test, 2) * w + b 繪制結果對比圖
plt.figure(figsize=(10, 6))
plt.scatter(x, y, color='blue', alpha=0.5, label='真實數據')
plt.plot(x_test, y_test, 'r-', linewidth=3, label='模型預測')
plt.plot(x_test, 3*x_test2+2, 'g--', label='理論曲線')
plt.xlim(-1, 1)
plt.ylim(2, 6)
plt.legend()
plt.title('NumPy實現回歸結果')
plt.show()輸出最終參數
print(f"訓練結果: w={w[0][0]:.4f} (接近理論值3), b={b[0][0]:.4f} (接近理論值2)")
可視化結果:
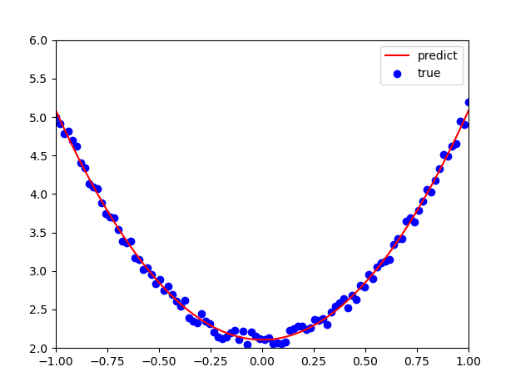
紅色實線為模型預測曲線,綠色虛線為理論曲線y=3x2+2y=3x^2+2y=3x2+2,藍色點為帶噪聲的訓練數據
6. 關鍵技術解析
1. 梯度下降的本質
通過參數空間中的"下坡運動"尋找最優解,學習率控制步長大小:
- 學習率過大 → 震蕩發散
- 學習率過小 → 收斂緩慢
- 本例0.001是多次試驗后的平衡值
2. 手動求導的意義
# 關鍵導數計算
grad_w = np.sum((y_pred - y) * np.power(x, 2))
理解此式需掌握:
- 鏈式法則:?Loss/?w = (?Loss/?y_pred)·(?y_pred/?w)
- 損失函數導數:?Loss/?y_pred = (y_pred - y)
- 模型輸出導數:?y_pred/?w = x2
3. 批量梯度下降特點
- 每次迭代使用全部樣本(不同于隨機梯度下降)
- 計算穩定但內存消耗大
- 適合中小規模數據集
7. 拓展思考
1. 學習率動態調整
# 添加學習率衰減
if epoch % 200 == 0:lr *= 0.8 # 每200輪衰減20%
2. 添加正則化項(L2正則化)
# 修改損失函數
lambda_reg = 0.01 # 正則化系數
loss = 0.5*(y_pred-y)2 + 0.5*lambda_reg*(w2)
3. 動量優化(Momentum)
# 添加動量項
beta = 0.9 # 動量系數
v_w = beta*v_w + (1-beta)*grad_w
w -= lr * v_w
8. 總結與啟示
NumPy實現的價值:
- 透明機制:每個運算步驟完全可見
- ?? 數學本質:揭示梯度下降和反向傳播核心原理
- 🔍 調試優勢:便于定位問題和理解優化過程
局限性:
- 📈 僅適合簡單模型
- ?? 復雜網絡需大量重復代碼
- 缺乏自動微分等高級功能
通過這個基礎實現,我們能更深刻地理解PyTorch/TensorFlow等框架封裝的高級功能背后的數學原理,為后續學習打下堅實基礎。

)
--圖論)


在Linux里面怎么查看進程)
---基于堆棧得到緩沖區溢出](http://pic.xiahunao.cn/[TryHackMe](知識學習)---基于堆棧得到緩沖區溢出)






)
 - 解析靜態網頁)


 ——225 用隊列實現棧(C語言))

