開篇
在8月5號,微軟研究院發布了一篇博客文章,在該篇博客中推出了一款名為Project Ire的AI Agent。該Agent可以在無需人類協助的情況下,自主分析和分類二進制文件。它可以在無需了解二進制文件來源或用途的情況下,對文件進行完全的逆向工程,然后利用LLM來審查逆向后的輸出內容,并確定軟件是惡意的還是良性的。
我們知道,針對二進制的分析工作極具挑戰性,因為它不像腳本文件那樣能夠直接的看到代碼意圖。通常需要使用逆向工具,從匯編代碼或者反編譯后的偽代碼中去抽絲剝繭,總結出二進制文件的實際行為。
目前Project Ire還處于原型階段,據稱在使用 Windows 驅動程序的公共數據集上進行測試,能達到 0.98 的精確度和 0.83 的召回率,這在二進制分析領域已經可以算是很高的了。
遍歷已有
事實上,隨著MCP協議的出現,各類逆向MCP Server也如雨后春筍般層出不窮。
比如github上Ghidra逆向工具的MCP Server就有多個repo。
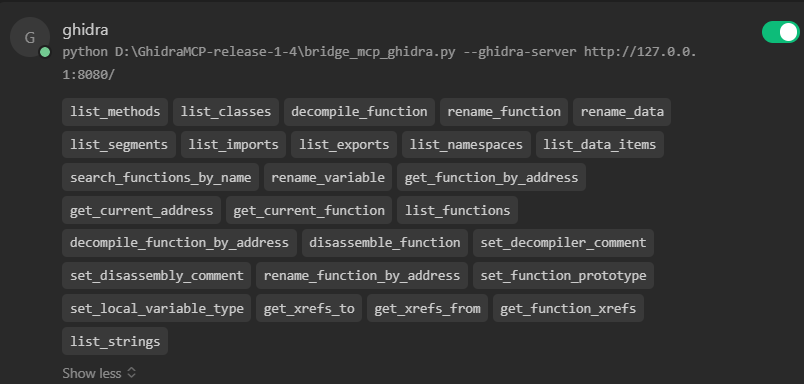
筆者嘗試了其中的一些,發現它們的功能基本大同小異。都是通過IDA Pro或者Ghidra的插件能力,在實現的插件中啟動http server對外暴漏了一些逆向的基本tools(工具),比如下面是Ghidra暴漏的一些tools,包括列舉出二進制文件的所有函數(list_functions)、反編譯指定函數(decompile_function)等等。
然后隨便分析了一個惡意的二進制文件:
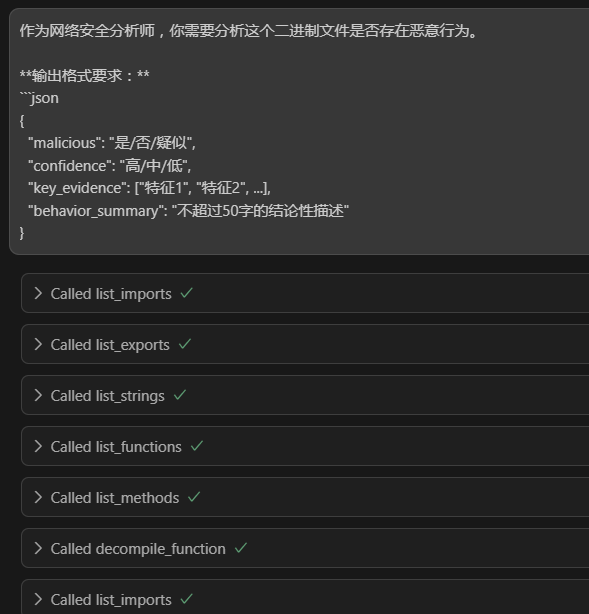
可見其調用了Ghidra MCP Sverver提供的工具來獲取該二進制文件的信息。然后綜合判斷后給出了下面的結論:
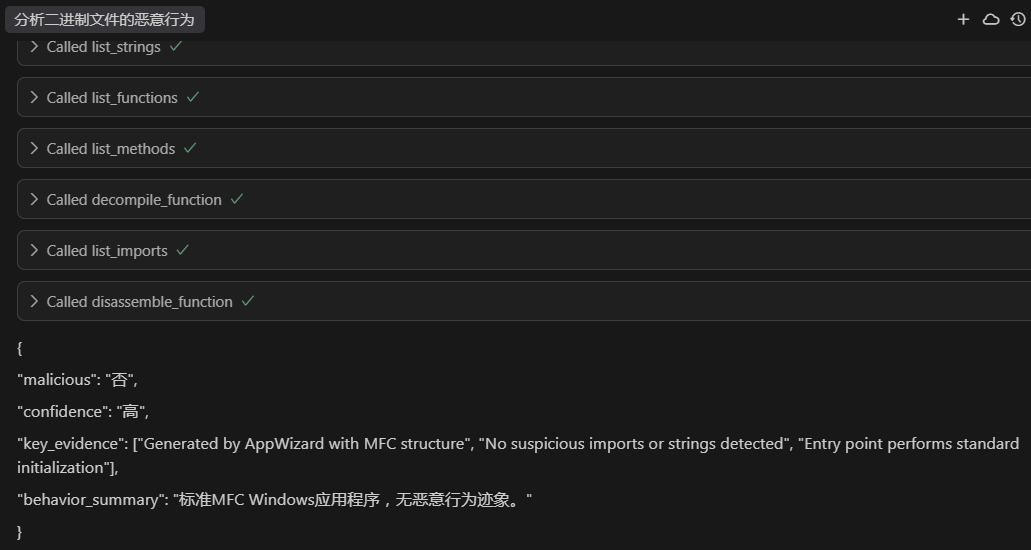
很可惜,大模型并沒有分析出其包含的惡意行為。
簡單的AI Agent可以提高人類分析二進制文件的效率,但不能把判斷權完全交給大模型。
筆者嘗試過讓大模型分析反匯編后的函數匯編代碼,大模型的表現非常敏感,經常會出現誤報的情況,一個正常函數也會被認為存在惡意行為。無論怎么調整提示詞也無法達到一個理想狀態。
所以,微軟推出的Project Ire并不是一個簡單的AI Agent,能達到98%的準確率肯定是有其獨特的技術創新和深度優化。
Project Ire
Project Ire 誕生于微軟研究院、Microsoft Defender和Microsoft Discovery & Quantum 的合作,匯集了安全專業知識、安全運營知識、全球惡意軟件威脅情報以及人工智能研究。
Microsoft Discovery是2025年微軟推出的面向企業的AI科研平臺。該平臺集成了多種專業的 AI 模型與工具,其主要特點是具備高度的可擴展性。
它建立在 GraphRAG (知識圖譜+RAG)和 Microsoft Discovery 的基礎之上,使用高級大語言模型以及一套逆向和二進制分析工具來推動調查和判斷。
逆向工具會識別文件類型、結構以及潛在的關注點。之后,系統會使用angr和Ghidra等二進制分析框架重建二進制文件的控制流圖。這些構建的成果構成了Project Ire 內存模型的Graph,用于指導后續分析工作。
通過迭代函數進行分析,LLM 通過 API 調用二進制分析工具來識別和總結關鍵函數。每個分析的結果都會被輸入到“證據鏈”中,這是一個詳細且可審計的線索,展示了Project Ire是如何得出結論的。這份可追溯的證據日志支持安全團隊進行二次審查,并有助于在出現錯誤分類的情況下改進系統。
為了驗證其分析結果,Project Ire 可以調用一個驗證工具,根據證據鏈對分析報告中的內容進行交叉核對。該工具借鑒了 Project Ire 團隊惡意軟件逆向工程師的專家知識。系統會根據這些證據及其內部模型,創建最終報告,并將樣本分類為惡意或良性。
總結
基于LLM的AI Agent是AI時代進行二進制文件分析的重要工具,Project Ire作為微軟在這一領域的杰出代表,是網絡安全和惡意軟件檢測領域的一大進步。
但也要看到這類AI工具的局限性,降低誤報率依舊是個大難題,仍然需要人類分析師參與其中。
不過以目前AI領域的發展速度,有理由相信,在不久的將來,AI工具在二進制文件分析上的表現將會取得質的飛躍。




的方法)
)



)
![week1-[分支嵌套]公因數](http://pic.xiahunao.cn/week1-[分支嵌套]公因數)



)




