本文較長,建議點贊收藏,以免遺失。更多AI大模型應用開發學習視頻及資料,盡在聚客AI學院。如果你想系統學習AI大模型應用開發,挑戰AI高薪崗位,可在文章底部聯系。
在現代大語言模型(LLM)應用架構中,Model-Client-Protocol (MCP) 設計模式因其清晰的職責分離(服務器暴露工具、數據和提示,客戶端使用 LLM 調用)而廣受歡迎。然而,一個關鍵問題隨之浮現:當服務器自身邏輯也需要利用 LLM 的智能(如文本理解、生成、摘要、決策)來完成其功能時,傳統的 MCP 模式就顯得力不從心了。?服務器通常需要自行集成昂貴的 LLM API 或在本地運行計算密集型模型,這帶來了成本、擴展性和靈活性的巨大挑戰。今天我們就來探討使用FastMCP框架進行采樣的概念、實現和應用。
一、MCP 采樣:概念與核心動機
LLM 采樣(Sampling)?正是為解決這一矛盾而設計的創新機制。它顛覆了傳統的單向 MCP 交互,創造了一個“雙向”或“反轉”的架構:
- 傳統模式:?客戶端 LLM 調用服務器提供的工具/函數。
- 采樣模式:服務器在處理客戶端請求的過程中,可以主動向客戶端發出請求,委托客戶端的 LLM 模型執行文本生成任務(即“采樣”),并將結果返回給服務器。
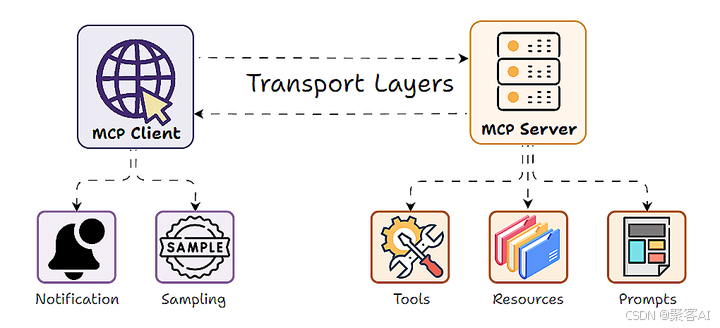
簡單來說,MCP 采樣允許服務器說:“嘿,客戶端,請用你的 LLM 幫我完成這個任務(比如總結這段文本、分析這個數據點、生成一條回復),然后把結果告訴我。”
ps:如果你對MCP相關技術不是很熟悉,我這邊還整理了一個詳細的技術文檔,粉絲朋友自行領取《MCP 技術詳解》
二、為什么需要采樣?關鍵優勢解析
采樣機制為 MCP 架構帶來了革命性的優勢:
強大的可擴展性:
- 痛點:?服務器端集中處理所有 LLM 推理任務會成為性能瓶頸,尤其在高并發場景下(如數百用戶同時觸發文本生成)。
- 采樣方案:?服務器將計算密集型的 LLM 工作負載卸載(Offload)到各個客戶端。
- 效果:?服務器自身資源(CPU、內存)得以釋放,專注于核心業務邏輯和協調,從而能夠輕松處理海量并發請求。每個客戶端負責處理自己的 LLM 計算需求,實現了分布式 AI 計算。
顯著的成本效率:
- 痛點:?服務器端集中調用商業 LLM API 會產生巨額費用,或在本地部署高性能模型需要昂貴的基礎設施投入和維護。
- 采樣方案:?與 LLM 推理相關的所有成本(API 調用費、本地計算資源消耗)均由客戶端承擔。
- 效果:?服務器運營方無需為用戶的 AI 計算付費或維護龐大的 GPU 集群,極大降低了運營成本。成本被自然地分攤給最終用戶。
LLM 選擇的終極靈活性:
- 痛點:?服務器強制規定使用的 LLM 模型,無法滿足不同用戶對模型性能、成本、隱私或本地部署的差異化需求。
- 采樣方案:客戶端完全自主決定使用哪個 LLM 模型來處理服務器的采樣請求(例如:OpenAI GPT-4o、Anthropic Claude、本地運行的 LLaMA、Mistral 等)。服務器可以建議偏好模型,但決定權在客戶端。
- 效果:?用戶可以根據自身情況選擇最優模型,服務器代碼無需為適配不同模型而修改,實現了真正的解耦和靈活性。
有效避免性能瓶頸:
- 痛點:?集中式 LLM 處理容易在服務器端形成隊列,導致請求延遲增加。
- 采樣方案:?LLM 任務由用戶各自的本地環境并行處理。
- 效果:?消除了服務器端的單一 LLM 處理瓶頸,顯著降低延遲,提升整體系統響應速度和用戶體驗。
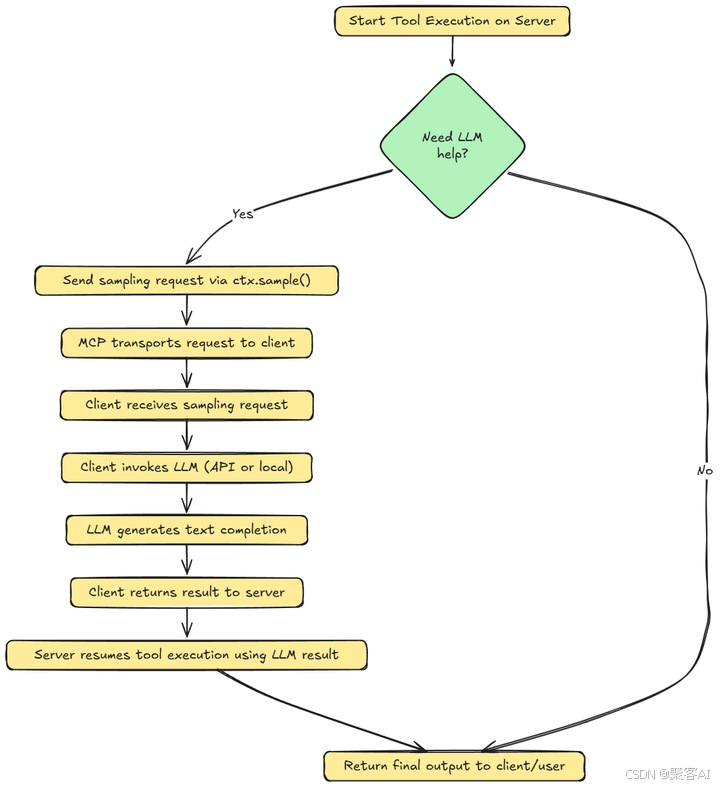
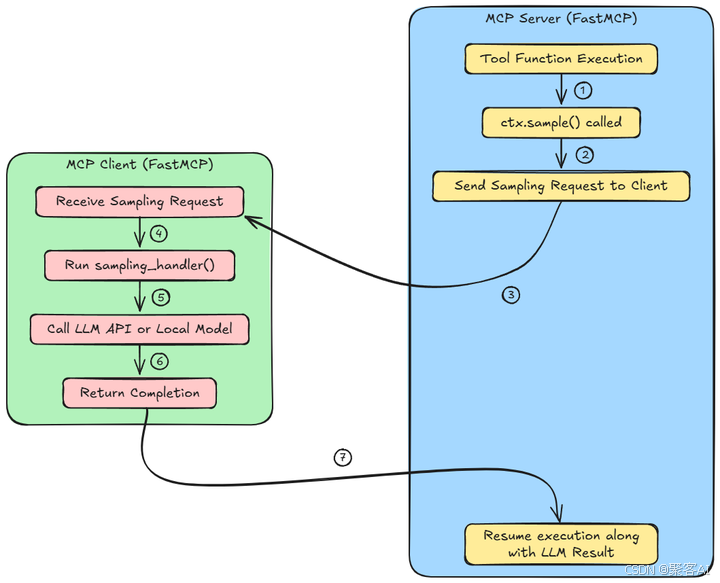
三、MCP 采樣架構深度解析
理解采樣如何融入 MCP 的客戶端-服務器模型至關重要:
MCP 服務器(藍色)
- 一個函數/工具正在服務器上的代理工作流程中運行。
- 在這個函數內部,
ctx.sample()?被調用來調用一個大語言模型以生成響應或做出決策。 - 此調用不會在本地執行采樣。相反,它將請求打包并發送到MCP客戶端。
MCP客戶端(綠色)
- 客戶端監聽來自服務器的采樣請求,并接收此請求。
- 用戶定義的
sampling_handler()被觸發。此函數定義了如何處理請求。例如,格式化提示,處理重試等。 - 客戶端使用外部LLM API(如OpenAI)或本地模型(如LLaMA或Mistral)來完成請求。
- 客戶端將生成的文本作為對服務器的響應發送回來。
完成之后,我們返回MCP服務器(藍色),并繼續執行LLM的結果。服務器從客戶端接收結果,并使用LLM生成的輸出恢復工具函數的執行。
關鍵技術點:
- 異步非阻塞:?整個采樣過程是異步的。當服務器工具函數調用?
ctx.sample()?時,該協程會暫停(Yield)?并等待客戶端響應,期間服務器可以處理其他請求,避免阻塞。 - 協議保障:?MCP 協議負責采樣請求和響應的可靠傳輸。FastMCP 等框架抽象了底層傳輸細節(stdio, SSE, WebSocket 等)。
- 安全邊界:?采樣請求嚴格限定為請求文本生成。服務器無法強制客戶端執行任意代碼;客戶端也僅在其安全環境下運行自己的 LLM 處理預設的提示詞。這符合最小權限原則。
- 上下文對象 (
ctx):?在 FastMCP 中,服務器工具函數通過?Context?對象(通常命名為?ctx)訪問采樣功能(ctx.sample())。這個對象是強大的樞紐,還提供日志記錄、發送進度更新等功能。框架通過依賴注入自動將?ctx?提供給聲明了該參數的函數。
FastMCP 實現示例
# 服務器端 (FastMCP Server - Blue)
from fastmcp import tool, Context@tool
async def analyze_data(ctx: Context, input_data: dict) -> dict:"""一個需要LLM協助分析數據的工具函數。"""# ... 一些預處理邏輯 ...# 關鍵采樣調用:請求客戶端LLM分析數據# 提示詞由服務器定義,但執行在客戶端analysis_prompt = f"基于以下數據生成關鍵洞察報告:\n{input_data}\n報告要求:..."llm_analysis = await ctx.sample(prompt=analysis_prompt,model="gpt-4-turbo", # 可選:服務器建議的模型偏好temperature=0.7,max_tokens=500) # 此處異步等待客戶端返回# ... 使用 llm_analysis 結果進行后續處理 ...final_result = process_analysis(llm_analysis, input_data)return final_result# 客戶端 (FastMCP Client - Green)
from fastmcp import FastMCPClientdef my_sampling_handler(request: SamplingRequest) -> SamplingResponse:"""用戶定義的采樣處理器。request 包含 prompt, model(建議), temperature 等參數。"""# 1. (可選) 根據 request.model 或客戶端配置決定最終使用的模型chosen_model = select_model(request.model) # 客戶端有最終選擇權# 2. (可選) 對提示進行最終處理或添加指令final_prompt = f"你是一個數據分析專家。{request.prompt}"# 3. 調用實際LLM (示例: 使用OpenAI API, 也可以是本地模型)import openairesponse = openai.chat.completions.create(model=chosen_model,messages=[{"role": "user", "content": final_prompt}],temperature=request.temperature,max_tokens=request.max_tokens)# 4. 提取生成的文本llm_output = response.choices[0].message.content.strip()# 5. 構建并返回采樣響應return SamplingResponse(content=llm_output)# 創建客戶端并注冊采樣處理器
client = FastMCPClient(server_url="...")
client.register_sampling_handler(my_sampling_handler)
client.connect() # 開始連接服務器并監聽請求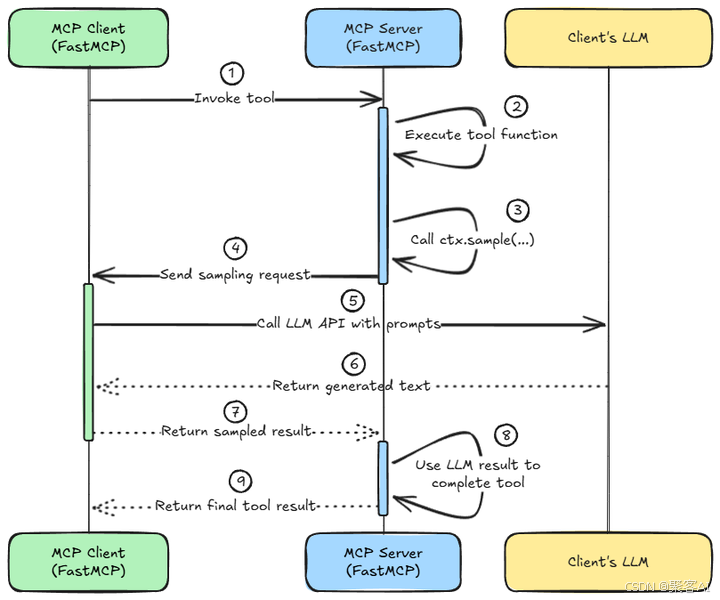
四、應用場景:釋放服務器端 AI 潛能
MCP 采樣的應用場景極其廣泛,尤其適用于需要服務器端引入智能但希望保持輕量和成本效益的場景:
- 智能文檔處理服務器:?服務器接收文件,委托客戶端 LLM 進行摘要、翻譯、關鍵信息提取、問答,然后整合結果提供高級服務。
- 個性化內容生成服務:?服務器管理內容和規則,將具體的、高度個性化的文本生成(如郵件草稿、營銷文案、故事延續)委托給用戶選擇的 LLM。
- 數據分析與洞察平臺:?服務器處理原始數據,將需要自然語言理解和推理的數據解釋、報告生成任務卸載到客戶端 LLM。
- AI 驅動的決策支持系統:?服務器提供決策框架和上下文,將基于復雜信息的建議生成或風險評估委托給客戶端 LLM。
- 交互式代理(Agents)工作流:?在復雜的多步驟 Agent 工作流中,服務器協調的 Agent 可以將特定的 LLM 思考、規劃或生成子任務分發給客戶端執行。
結語:總結來說,MCP中的采樣允許分布式AI計算。MCP服務器可以在不嵌入模型或調用外部API的情況下,整合強大的LLM功能。這是一座在通常確定性的服務器邏輯和動態文本生成之間的橋梁,通過標準化的協議調用來實現。好了,本次分享就到這里,如果對你有所幫助,記得告訴身邊有需要的人,我們下期見。


)






)

)







