引言
在現代互聯網架構中,緩存是提升系統性能、降低數據庫壓力的核心手段之一。而 Redis 作為高性能的內存數據庫,憑借其豐富的數據結構、靈活的配置選項以及高效的網絡模型,已經成為緩存領域的首選工具。本文將從 Redis 的基本原理出發,深入探討其在緩存場景中的核心概念、設計模式、常見問題及解決方案,并結合高可用架構的設計思路,幫助讀者全面掌握 Redis 緩存的技術要點。
一、Redis 與緩存的基本原理
1.1 什么是 Redis?
Redis(Remote Dictionary Server)是一個開源的內存鍵值存儲系統,支持多種數據結構(如 String、Hash、List、Set、Sorted Set 等)。它通過內存操作實現極低的延遲(通常為微秒級),同時提供持久化機制和主從復制功能,確保數據的可靠性和高可用性。
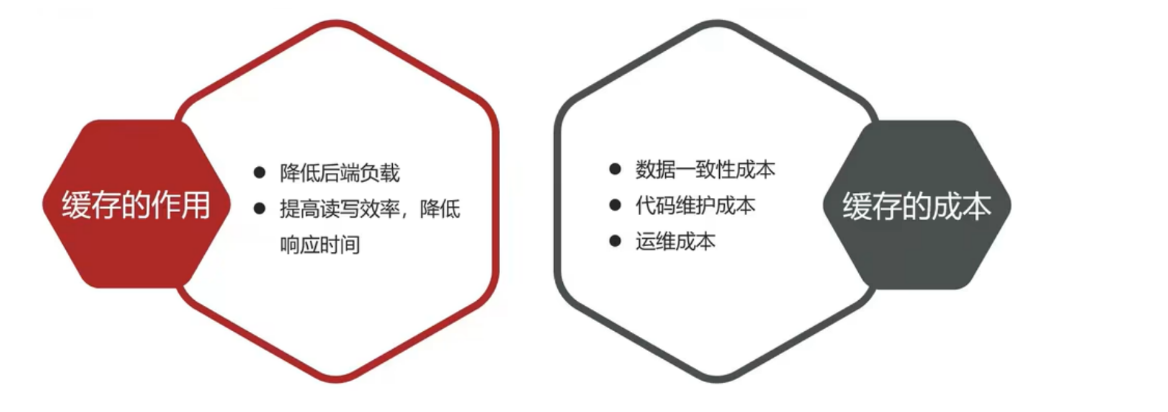
1.2 緩存的核心作用
緩存的本質是通過空間換時間,將高頻訪問的數據存儲在內存中,減少對底層數據庫的直接請求。其核心優勢包括:
- 降低數據庫負載:通過緩存熱點數據,減少數據庫的查詢壓力。
- 提高響應速度:內存讀取速度遠高于磁盤,顯著縮短請求響應時間。
- 應對突發流量:在秒殺、促銷等場景中,緩存可以有效吸收瞬時高并發請求。
1.3 緩存的缺點
但是緩存也會增加代碼復雜度和運營的成本:
二、如何使用緩存
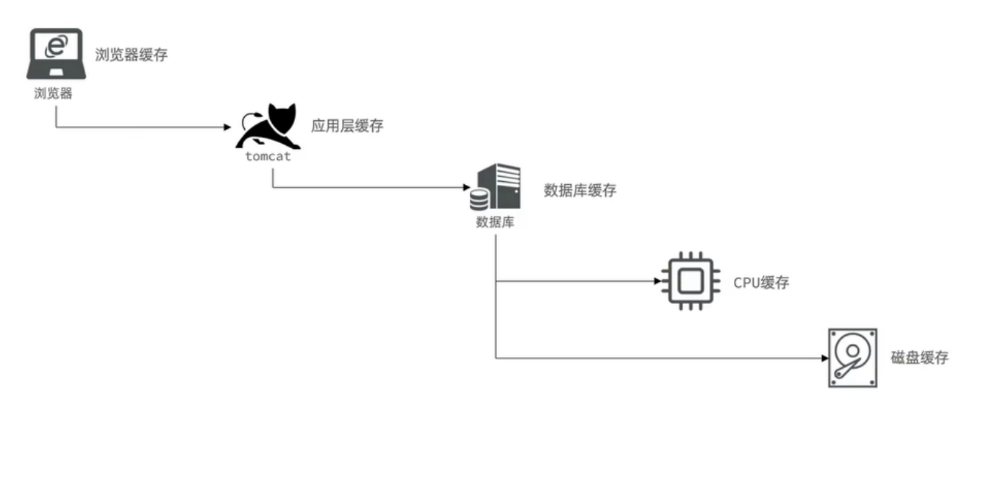
實際開發中,會構筑多級緩存來使系統運行速度進一步提升,例如:本地緩存與redis中的緩存并發使用
瀏覽器緩存:主要是存在于瀏覽器端的緩存
應用層緩存:可以分為tomcat本地緩存,比如之前提到的map,或者是使用redis作為緩存
數據庫緩存:在數據庫中有一片空間是 buffer pool,增改查數據都會先加載到mysql的緩存中
CPU緩存:當代計算機最大的問題是 cpu性能提升了,但內存讀寫速度沒有跟上,所以為了適應當下的情況,增加了cpu的L1,L2,L3級的緩存
三、緩存更新策略
3.1 介紹
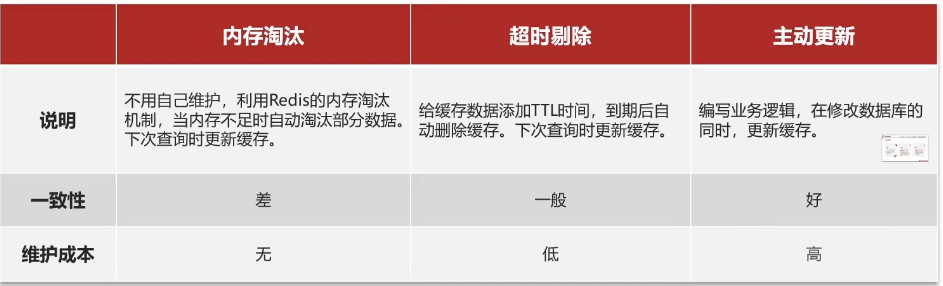
緩存更新是redis為了節約內存而設計出來的一個東西,主要是因為內存數據寶貴,當我們向redis插入太多數據,此時就可能會導致緩存中的數據過多,所以redis會對部分數據進行更新,或者把他叫為淘汰更合適。
內存淘汰:redis自動進行,當redis內存達到咱們設定的max-memery的時候,會自動觸發淘汰機制,淘汰掉一些不重要的數據(可以自己設置策略方式)
超時剔除:當我們給redis設置了過期時間ttl之后,redis會將超時的數據進行刪除,方便咱們繼續使用緩存
主動更新:我們可以手動調用方法把緩存刪掉,通常用于解決緩存和數據庫不一致問題
3.2 數據庫緩存不一致解決方案:
由于我們的緩存的數據源來自于數據庫,而數據庫的數據是會發生變化的,因此,如果當數據庫中數據發生變化,而緩存卻沒有同步,此時就會有一致性問題存在,其后果是:
用戶使用緩存中的過時數據,就會產生類似多線程數據安全問題,從而影響業務,產品口碑等
綜合考慮我們采用人工編碼方式來解決數據庫和緩存不一致的問題。
????????人工編碼方式:緩存調用者在更新完數據庫后再去更新緩存,也稱之為雙寫方案。
操作緩存和數據庫時有三個問題需要考慮:
刪除緩存還是更新緩存?
更新緩存:每次更新數據庫都更新緩存,無效寫操作較多
刪除緩存:更新數據庫時讓緩存失效,查詢時再更新緩存
如果采用第一個方案,那么假設我們每次操作數據庫后,都操作緩存,但是中間如果沒有人查詢,那么這個更新動作實際上只有最后一次生效,中間的更新動作意義并不大,我們可以把緩存刪除,等待再次查詢時,將緩存中的數據加載出來。
如何保證緩存與數據庫的操作的同時成功或失敗?
單體系統,將緩存與數據庫操作放在一個事務
分布式系統,利用TCC等分布式事務方案
先操作緩存還是先操作數據庫?
先刪除緩存,再操作數據庫
先操作數據庫,再刪除緩存
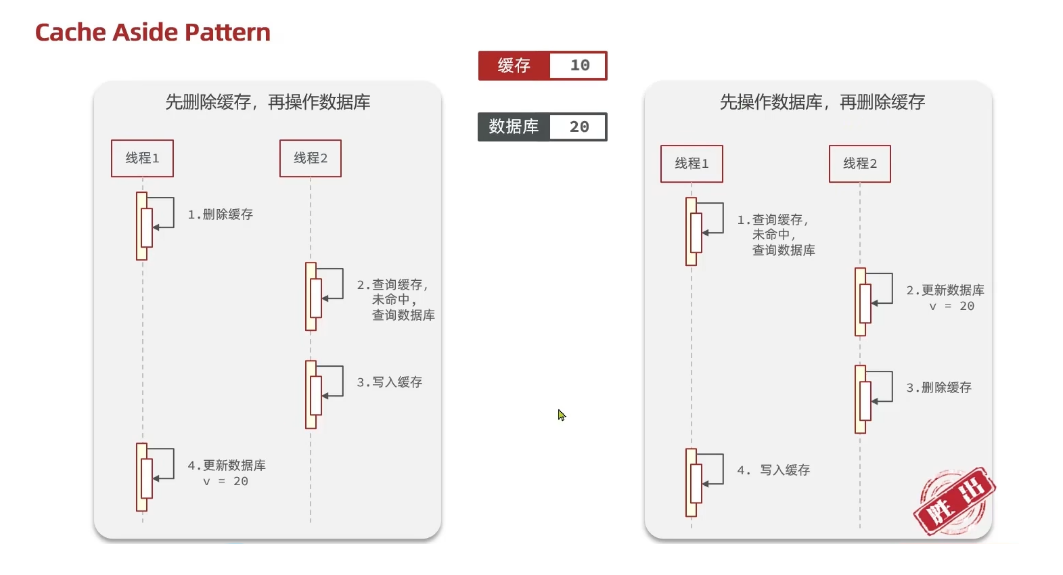
????????應該具體操作緩存還是操作數據庫,我們應當是先操作數據庫,再刪除緩存,原因在于,如果你選擇第一種方案,在兩個線程并發來訪問時,假設線程1先來,他先把緩存刪了,此時線程2過來,他查詢緩存數據并不存在,此時他寫入緩存,當他寫入緩存后,線程1再執行更新動作時,實際上寫入的就是舊的數據,新的數據被舊數據覆蓋了。
四、緩存穿透:無效請求的“黑洞”
4.1 問題定義
緩存穿透是指請求的數據既不存在于緩存中,也不存在于數據庫中,導致請求直接穿透到數據庫。這種現象會顯著增加數據庫的負載,甚至引發服務不可用。
4.2 常見場景
- 惡意攻擊:黑客通過偽造非法 ID(如隨機字符串)持續請求,消耗數據庫資源。
- 業務邏輯漏洞:未校驗用戶輸入的合法性,導致非法請求直接訪問數據庫。
- 冷啟動數據:新業務上線初期,緩存尚未填充,所有請求均需查詢數據庫。
4.3 解決方案
(1)布隆過濾器(Bloom Filter)
- 原理:使用位數組和哈希函數快速判斷數據是否存在。
- 優勢:
- 內存占用極小(如百萬級數據僅需幾 MB)。
- 攔截效率高(哈希計算時間復雜度為 O(1))。
- 局限性:
- 存在誤判率(需合理設置哈希函數數量和位數組大小)。
- 不支持刪除操作(需使用 Counting Bloom Filter)。
(2)緩存空值(Null Caching)
- 原理:對數據庫中不存在的數據返回空值,并設置短 TTL(如 5 分鐘)。
- 優勢:
- 實現簡單,無需額外數據結構。
- 有效攔截惡意請求。
- 缺點:
- 占用緩存空間(需評估空值占比)。
- 短時間內可能被高頻請求反復觸發。
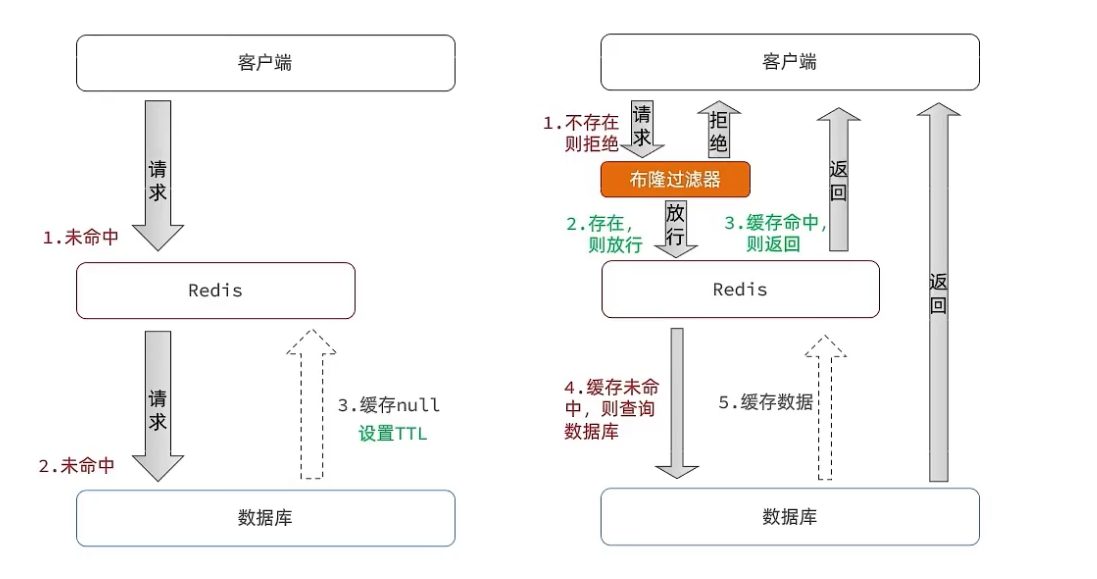
緩存空對象思路分析:當我們客戶端訪問不存在的數據時,先請求redis,但是此時redis中沒有數據,此時會訪問到數據庫,但是數據庫中也沒有數據,這個數據穿透了緩存,直擊數據庫,我們都知道數據庫能夠承載的并發不如redis這么高,如果大量的請求同時過來訪問這種不存在的數據,這些請求就都會訪問到數據庫,簡單的解決方案就是哪怕這個數據在數據庫中也不存在,我們也把這個數據存入到redis中去,這樣,下次用戶過來訪問這個不存在的數據,那么在redis中也能找到這個數據就不會進入到緩存了。
布隆過濾:布隆過濾器其實采用的是哈希思想來解決這個問題,通過一個龐大的二進制數組,走哈希思想去判斷當前這個要查詢的這個數據是否存在,如果布隆過濾器判斷存在,則放行,這個請求會去訪問redis,哪怕此時redis中的數據過期了,但是數據庫中一定存在這個數據,在數據庫中查詢出來這個數據后,再將其放入到redis中,
假設布隆過濾器判斷這個數據不存在,則直接返回
這種方式優點在于節約內存空間,存在誤判,誤判原因在于:布隆過濾器走的是哈希思想,只要哈希思想,就可能存在哈希沖突
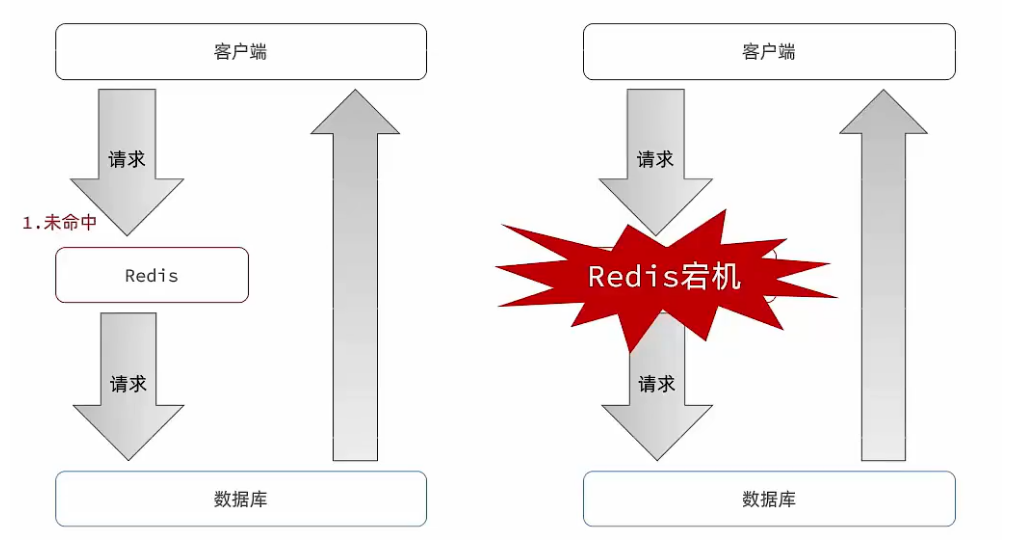
五、緩存雪崩
????????緩存雪崩是指在同一時段大量的緩存key同時失效或者Redis服務宕機,導致大量請求到達數據庫,帶來巨大壓力。
解決方案:
給不同的Key的TTL添加隨機值
利用Redis集群提高服務的可用性
給緩存業務添加降級限流策略
給業務添加多級緩存
????????
六、緩存擊穿
6.1解決方案
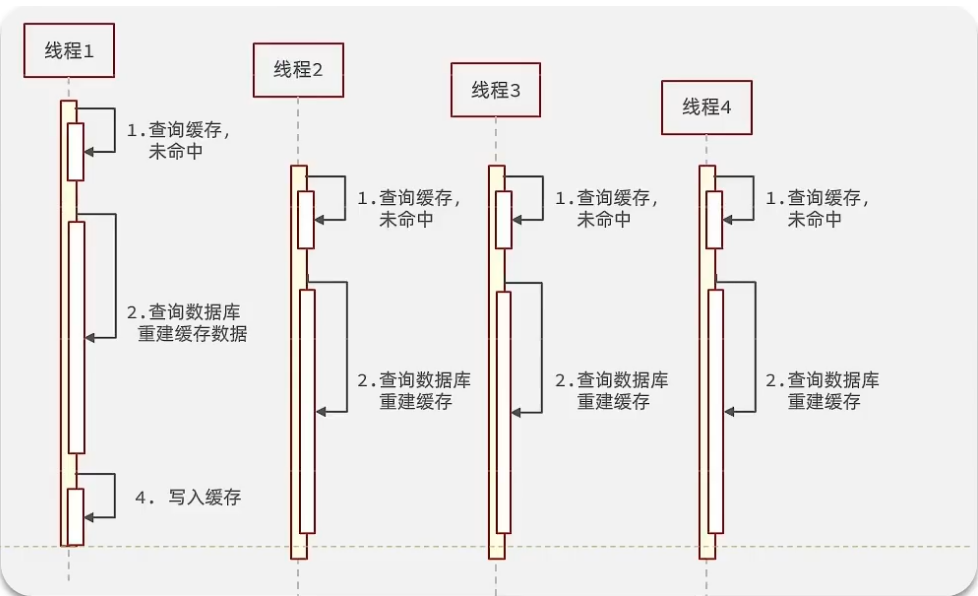
緩存擊穿問題也叫熱點Key問題,就是一個被高并發訪問并且緩存重建業務較復雜的key突然失效了,無數的請求訪問會在瞬間給數據庫帶來巨大的沖擊。
常見的解決方案有兩種:
互斥鎖
邏輯過期
邏輯分析:假設線程1在查詢緩存之后,本來應該去查詢數據庫,然后把這個數據重新加載到緩存的,此時只要線程1走完這個邏輯,其他線程就都能從緩存中加載這些數據了,但是假設在線程1沒有走完的時候,后續的線程2,線程3,線程4同時過來訪問當前這個方法, 那么這些線程都不能從緩存中查詢到數據,那么他們就會同一時刻來訪問查詢緩存,都沒查到,接著同一時間去訪問數據庫,同時的去執行數據庫代碼,對數據庫訪問壓力過大
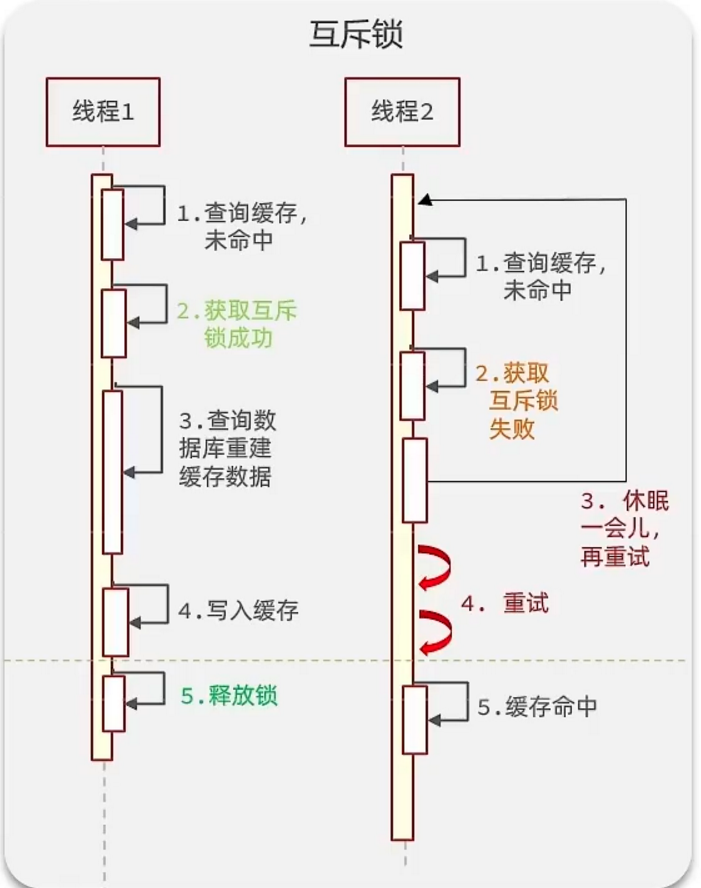
解決方案一、使用鎖來解決:
因為鎖能實現互斥性。假設線程過來,只能一個人一個人的來訪問數據庫,從而避免對于數據庫訪問壓力過大,但這也會影響查詢的性能,因為此時會讓查詢的性能從并行變成了串行,我們可以采用tryLock方法 + double check來解決這樣的問題。
假設現在線程1過來訪問,他查詢緩存沒有命中,但是此時他獲得到了鎖的資源,那么線程1就會一個人去執行邏輯,假設現在線程2過來,線程2在執行過程中,并沒有獲得到鎖,那么線程2就可以進行到休眠,直到線程1把鎖釋放后,線程2獲得到鎖,然后再來執行邏輯,此時就能夠從緩存中拿到數據了。
解決方案二、邏輯過期方案
方案分析:我們之所以會出現這個緩存擊穿問題,主要原因是在于我們對key設置了過期時間,假設我們不設置過期時間,其實就不會有緩存擊穿的問題,但是不設置過期時間,這樣數據不就一直占用我們內存了嗎,我們可以采用邏輯過期方案。
我們把過期時間設置在 redis的value中,注意:這個過期時間并不會直接作用于redis,而是我們后續通過邏輯去處理。假設線程1去查詢緩存,然后從value中判斷出來當前的數據已經過期了,此時線程1去獲得互斥鎖,那么其他線程會進行阻塞,獲得了鎖的線程他會開啟一個 線程去進行 以前的重構數據的邏輯,直到新開的線程完成這個邏輯后,才釋放鎖, 而線程1直接進行返回,假設現在線程3過來訪問,由于線程線程2持有著鎖,所以線程3無法獲得鎖,線程3也直接返回數據,只有等到新開的線程2把重建數據構建完后,其他線程才能走返回正確的數據。
這種方案巧妙在于,異步的構建緩存,缺點在于在構建完緩存之前,返回的都是臟數據。
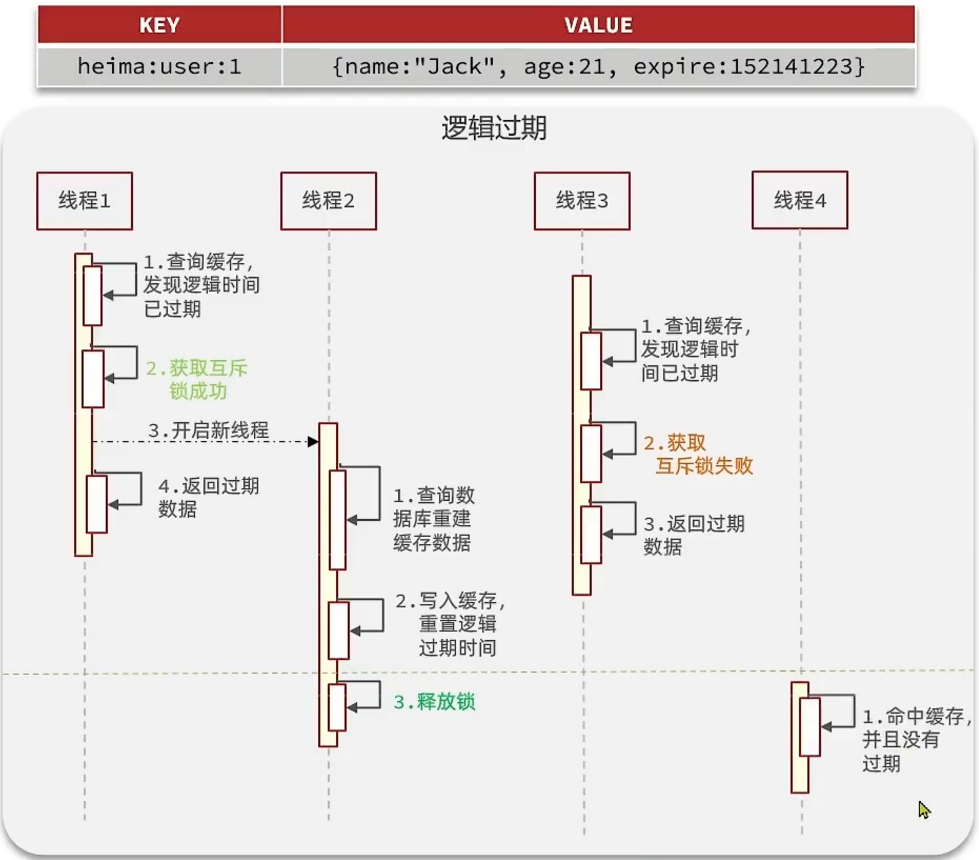
6.2 進行對比
互斥鎖方案:由于保證了互斥性,所以數據一致,且實現簡單,因為僅僅只需要加一把鎖而已,也沒其他的事情需要操心,所以沒有額外的內存消耗,缺點在于有鎖就有死鎖問題的發生,且只能串行執行性能肯定受到影響
邏輯過期方案: 線程讀取過程中不需要等待,性能好,有一個額外的線程持有鎖去進行重構數據,但是在重構數據完成前,其他的線程只能返回之前的數據,且實現起來麻煩







 推薦使用 constexpr和模板 (Templates) 作為宏 (#define) 的替代品??)





)



)


