現有網絡模型的使用與調整
VGG — Torchvision 0.22 documentation
????????VGG 模型是由牛津大學牛津大學(Oxford University)的 Visual Geometry Group 于 2014 年提出的卷積神經網絡模型,在 ImageNet 圖像分類挑戰賽中表現優異,以其簡潔統一的網絡結構設計而聞名。
- 優點:結構簡潔統一,易于理解和實現;小卷積核設計提升了特征提取能力,泛化性能較好。
- 缺點:參數量巨大(主要來自全連接層),計算成本高,訓練和推理速度較慢,對硬件資源要求較高。
ImageNet — Torchvision 0.22 documentation
????????在 PyTorch 的torchvision庫中,ImageNet相關功能主要用于加載和預處理 ImageNet 數據集,方便用戶在該數據集上訓練或評估模型。
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader# train_data = torchvision.datasets.ImageNet('./data_image_net', split='train', download=True,
# transform=torchvision.transforms.ToTensor())
# 指定要加載的數據集子集。這里設置為'train',表示加載的是 ImageNet 的訓練集(包含約 120 萬張圖像)。
# 若要加載驗證集,可將該參數改為'val'(驗證集包含約 5 萬張圖像)。vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)print(vgg16_true)# 利用現有網絡修改結構
train_data = torchvision.datasets.CIFAR10('./dataset', train=True, download=True,transform=torchvision.transforms.ToTensor())vgg16_true.add_module('add_linear', nn.Linear(1000, 10))
print(vgg16_true)
# (add_linear): Linear(in_features=1000, out_features=10, bias=True)# 修改位置不同
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))# 直接修改某層
print(vgg16_false)
vgg16_false.classifier[6] = nn.Linear(4096, 10)
print(vgg16_false)vgg16_false:適合用于訓練全新的任務,vgg16_true:常用于遷移學習場景
- vgg16_false:pretrained=False表示不加載在大型數據集上(如 ImageNet)預訓練好的權重參數。此時,模型的權重參數會按照默認的隨機初始化方式進行初始化,比如卷積層和全連接層的權重會從一定范圍內的隨機值開始,偏置項通常初始化為 0 或一個較小的值。這種初始化方式下,模型需要從頭開始學習訓練數據中的特征表示。
- vgg16_true:pretrained=True表示加載在 ImageNet 數據集上預訓練好的權重參數。VGG16 在 ImageNet 上經過大量圖像的訓練,已經學習到了通用的圖像特征,比如邊緣、紋理、形狀等。加載這些預訓練權重后,模型在新的任務上可以利用已學習到的特征,減少訓練所需的樣本數量和訓練時間,在很多情況下能更快地收斂到較好的性能。
模型的保存與加載
模型保存
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoadervgg16 = torchvision.models.vgg16(pretrained=False)# 方式一保存 模型結構+模型參數
torch.save(vgg16, 'vgg16_method1.pth')# 方式二保存 模型參數 (推薦)
torch.save(vgg16.state_dict(), 'vgg16_method2.pth')# 陷阱
class Chenxi(nn.Module):def __init__(self, *args, **kwargs) -> None:super().__init__(*args, **kwargs)self.conv1 = nn.Conv2d(3, 64, kernel_size=3)def forward(self, x):x = self.conv1(x)return xchenxi = Chenxi()
torch.save(chenxi, 'chenxi_method1.pth')相應模型加載方法
import torch
import torchvision
from module_save import * # 注意from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader# 方式一, 加載模型
model = torch.load('vgg16_method1.pth')
# print(model)# 方式二, 加載模型
vgg16 = torchvision.models.vgg16(pretrained=False) # 新建網絡模型結構
vgg16.load_state_dict(torch.load('vgg16_method2.pth'))
# print(vgg16)
# model = torch.load('vgg16_method2.pth')
# print(model)# 陷阱1
# 方法一必須要有模型# class Chenxi(nn.Module):
# def __init__(self, *args, **kwargs) -> None:
# super().__init__(*args, **kwargs)
# self.conv1 = nn.Conv2d(3, 64, kernel_size=3)
# def forward(self, x):
# x = self.conv1(x)
# return x# chenxi = Chenxi() 不需要model = torch.load('chenxi_method1.pth')
print(model)完整的模型訓練套路
CIFAR10為例
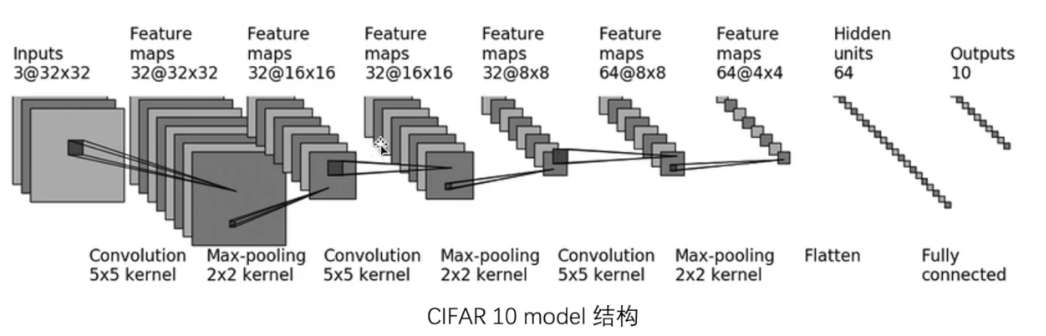
model文件
import torch
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear# 搭建神經網絡
class Chenxi(nn.Module):def __init__(self, *args, **kwargs) -> None:super().__init__(*args, **kwargs)self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10),)def forward(self, x):x = self.model1(x)return xif __name__ == '__main__':chenxi = Chenxi()input = torch.ones((64, 3, 32, 32))output = chenxi(input)print(output.shape)# torch.Size([64, 10])train文件
import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d, Sequential, Conv2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriterfrom model import *# 準備數據集
train_data = torchvision.datasets.CIFAR10('./dataset', train=True, download=True,transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10('./dataset', train=False, download=True,transform=torchvision.transforms.ToTensor())train_data_size = len(train_data)
test_data_size = len(test_data)print("訓練數據集的長度為:{}".format(train_data_size))
print("測試數據集的長度為:{}".format(test_data_size))
# 訓練數據集的長度為:50000
# 測試數據集的長度為:10000train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 創建網絡模型
chenxi = Chenxi()# 損失函數
loss_fn = nn.CrossEntropyLoss()# 優化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(chenxi.parameters(),lr=learning_rate)# 設置訓練網絡的參數
# 記錄訓練次數
total_train_step = 0
# 記錄測試次數
total_test_step = 0
# 訓練的輪數
epoch = 10# 添加Tensorboard
writer = SummaryWriter('./logs_train')for i in range(epoch):print('---------第{}輪訓練開始-----------'.format(i + 1))# 訓練開始chenxi.train()for data in train_dataloader:imgs, target = dataoutputs = chenxi(imgs)loss = loss_fn(outputs, target)# 優化器優化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:print("訓練次數:{}, loss:{}".format(total_train_step, loss.item()))writer.add_scalar('train_loss', loss.item(), total_train_step)# 測試步驟開始chenxi.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():# 禁用梯度計算for data in test_dataloader:imgs, targets = dataoutputs = chenxi(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整體測試集上的Loss:{}".format(total_test_loss))print("整體測試集上的正確率:{}".format(total_accuracy/test_data_size))writer.add_scalar('test_loss', loss.item(), total_test_step)writer.add_scalar('test_accuracy', loss.item(), total_test_step)total_test_step += 1torch.save(chenxi, "chenxi_{}.pth".format(i))# torch.save(chenxi.state_dict(), "chenxi_{}.pth".format(i))print("模型已保存")writer.close()train優化部分
import torch
outputs = torch.tensor([[0.1, 0.2],[0.05, 0.4]])
# print(outputs.argmax(0)) # 縱向
# print(outputs.argmax(1)) # 橫向preds = outputs.argmax(0)
targets = torch.tensor([0, 1])
print((preds == targets).sum())使用GPU進行訓練
方法一:使用.cuda()
????????對 網絡模型、數據及標注、損失函數, 進行 .cuda()操作
????????如果電腦不支持GPU,可以使用谷歌瀏覽器:
https://colab.research.google.com/drive/1HKuF0FtulVXkHaiWV8VzT-VXZmbq4kK4#scrollTo=861yC3qEpi3F
方法二:使用.to(device)
device = torch.device('cpu')
# device = torch.device('cuda')
x = x.to(device)
# 代替.cuda()import torch
import torchvision.datasets
from torch import nn
from torch.nn import MaxPool2d, Sequential, Conv2d, Flatten, Linear
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# from model import *# 準備數據集
train_data = torchvision.datasets.CIFAR10('./dataset', train=True, download=True,transform=torchvision.transforms.ToTensor())
test_data = torchvision.datasets.CIFAR10('./dataset', train=False, download=True,transform=torchvision.transforms.ToTensor())train_data_size = len(train_data)
test_data_size = len(test_data)print("訓練數據集的長度為:{}".format(train_data_size))
print("測試數據集的長度為:{}".format(test_data_size))
# 訓練數據集的長度為:50000
# 測試數據集的長度為:10000train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)# 創建網絡模型
class Chenxi(nn.Module):def __init__(self, *args, **kwargs) -> None:super().__init__(*args, **kwargs)self.model1 = Sequential(Conv2d(3, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 32, 5, padding=2),MaxPool2d(2),Conv2d(32, 64, 5, padding=2),MaxPool2d(2),Flatten(),Linear(1024, 64),Linear(64, 10),)def forward(self, x):x = self.model1(x)return xchenxi = Chenxi()
if torch.cuda.is_available():chenxi = chenxi.cuda()
# 損失函數
loss_fn = nn.CrossEntropyLoss()
if torch.cuda.is_available():loss_fn = loss_fn.cuda()# 優化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(chenxi.parameters(),lr=learning_rate)# 設置訓練網絡的參數
# 記錄訓練次數
total_train_step = 0
# 記錄測試次數
total_test_step = 0
# 訓練的輪數
epoch = 10# 添加Tensorboard
writer = SummaryWriter('./logs_train')for i in range(epoch):print('---------第{}輪訓練開始-----------'.format(i + 1))# 訓練開始chenxi.train()for data in train_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = chenxi(imgs)loss = loss_fn(outputs, targets)# 優化器優化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step = total_train_step + 1if total_train_step % 100 == 0:print("訓練次數:{}, loss:{}".format(total_train_step, loss.item()))writer.add_scalar('train_loss', loss.item(), total_train_step)# 測試步驟開始chenxi.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():# 禁用梯度計算for data in test_dataloader:imgs, targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = chenxi(imgs)loss = loss_fn(outputs, targets)total_test_loss = total_test_loss + loss.item()accuracy = (outputs.argmax(1) == targets).sum()total_accuracy = total_accuracy + accuracyprint("整體測試集上的Loss:{}".format(total_test_loss))print("整體測試集上的正確率:{}".format(total_accuracy/test_data_size))writer.add_scalar('test_loss', loss.item(), total_test_step)writer.add_scalar('test_accuracy', loss.item(), total_test_step)total_test_step += 1torch.save(chenxi, "chenxi_{}.pth".format(i))# torch.save(chenxi.state_dict(), "chenxi_{}.pth".format(i))print("模型已保存")writer.close()
完整的模型驗證套路


 詳細解釋,使用 PyTorch代碼示例說明)






)

Cursor)




)


