一、Kaggle社區概述
Kaggle 是全球最大的數據科學和機器學習社區,由Anthony Goldbloom于2010年創立,2017年被Google收購。平臺專注于數據科學競賽、開源數據集共享、協作編程以及技能學習,吸引了從初學者到專業數據科學家的廣泛用戶群體。
1、核心功能
競賽(Competitions)
Kaggle以舉辦數據科學競賽聞名,企業和組織通過發布數據集和問題,邀請社區成員提交解決方案。優勝者通常獲得獎金或職業機會,競賽涵蓋預測建模、自然語言處理、計算機視覺等領域。
數據集(Datasets)
平臺提供超過50,000個開源數據集,涵蓋醫療、金融、體育等多個領域。用戶可上傳、下載數據集,并通過版本控制和討論功能協作優化數據質量。
代碼筆記本(Notebooks)
集成Jupyter Notebook環境,支持Python和R語言。用戶可編寫、運行代碼,并分享給社區。優秀筆記本常被標記為“Expert”或“Grandmaster”,提升個人影響力。
學習資源(Courses)
提供免費的數據科學課程,涵蓋Python、機器學習、數據可視化等主題。課程以實踐為導向,適合不同水平的學習者。
社區與協作
用戶可通過論壇(Discussion)提問或分享見解,形成活躍的技術交流氛圍。Kaggle還設有“團隊”功能,允許成員組隊參與競賽。
2、用戶等級體系
Kaggle通過貢獻度劃分用戶等級,從Novice到Grandmaster。等級依據競賽排名、筆記本投票、數據集和討論質量等綜合評定,激勵用戶持續參與。
4、影響力與價值
Kaggle不僅是技能提升平臺,也是企業招聘的重要渠道。許多用戶通過競賽成績和項目展示獲得職業機會。此外,平臺推動了開源文化,助力解決現實世界的數據問題。
二、注冊 Kaggle 賬號
https://kagglecn.com
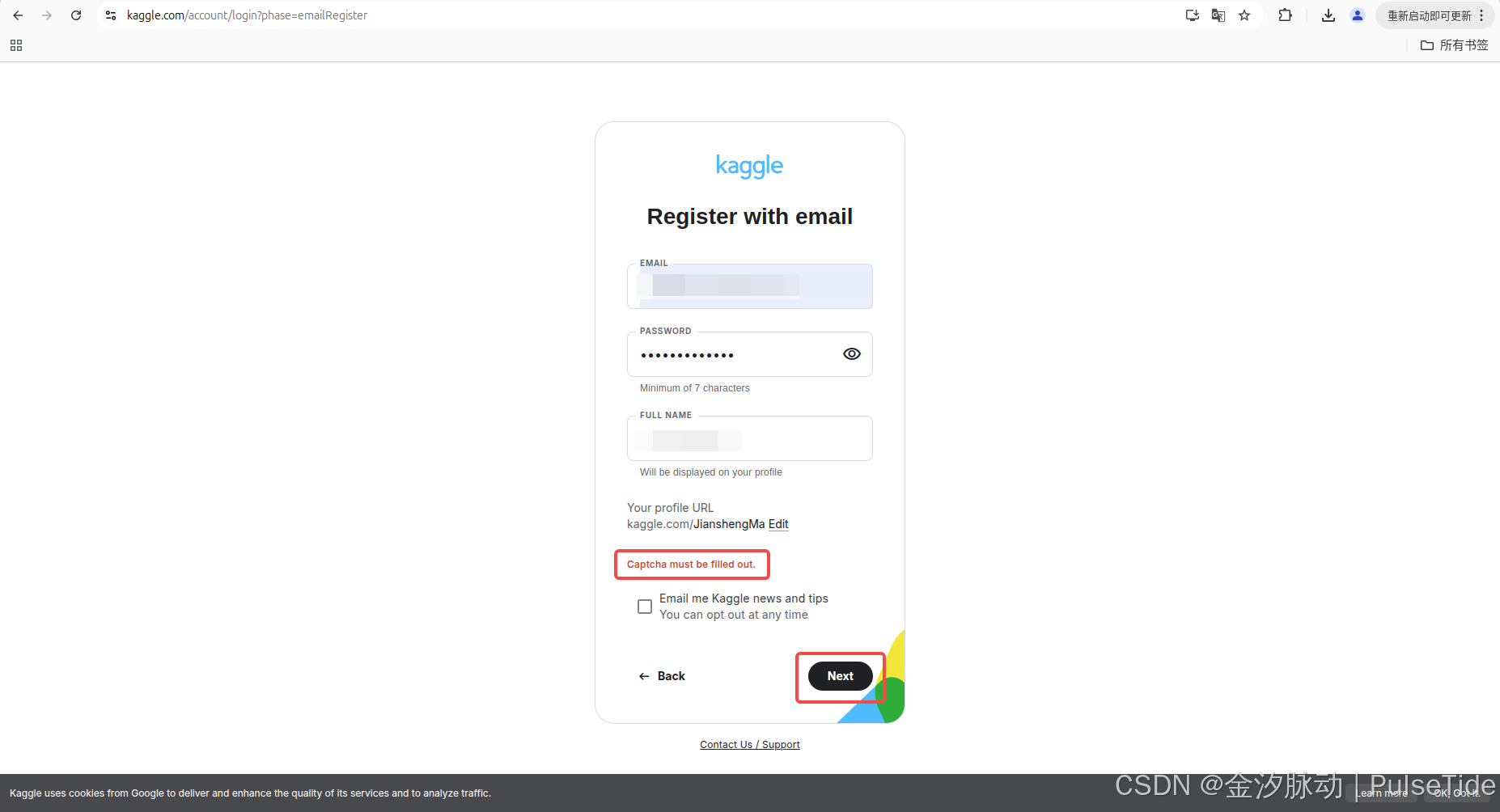
1、注冊驗證碼問題
Captcha must be filled out.
在注冊 Kaggle 時,通常會因為網絡問題導致提交表單時驗證碼報錯:
2、解決方案
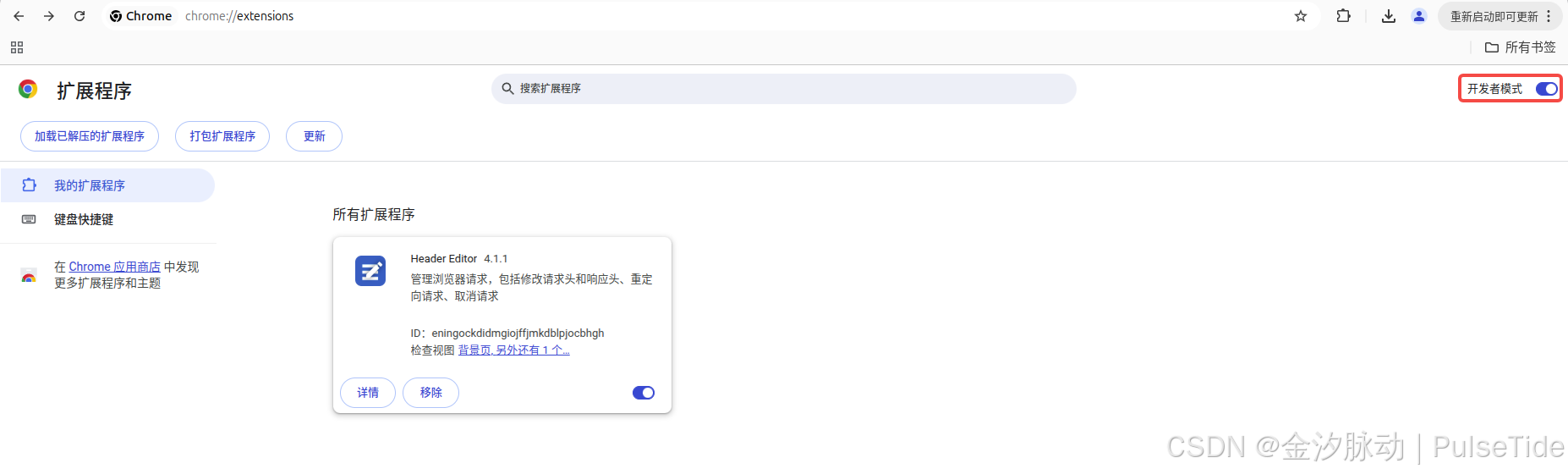
以谷歌瀏覽器為例,先下載插件 Header Editor 4.1.1.crx,然后打開拓展程序管理頁面chrome://extensions/,開啟開發者模式,直接把插件拖進來或者點擊左上角的加載已解壓的擴展程序:
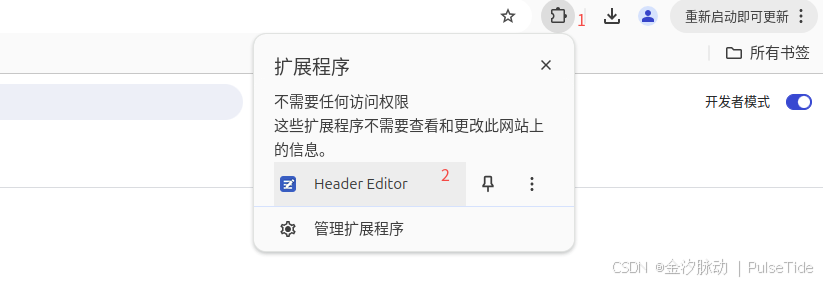
此時啟用拓展程序,進行配置:
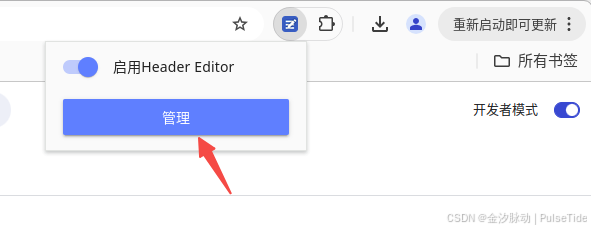
切到導出和導入頁簽,在下載規則的 URL 欄位輸入 https://azurezeng.com/static/HE-GoogleRedirect.json,點擊下載按鈕,等待導入結果刷新,最后點擊保存:
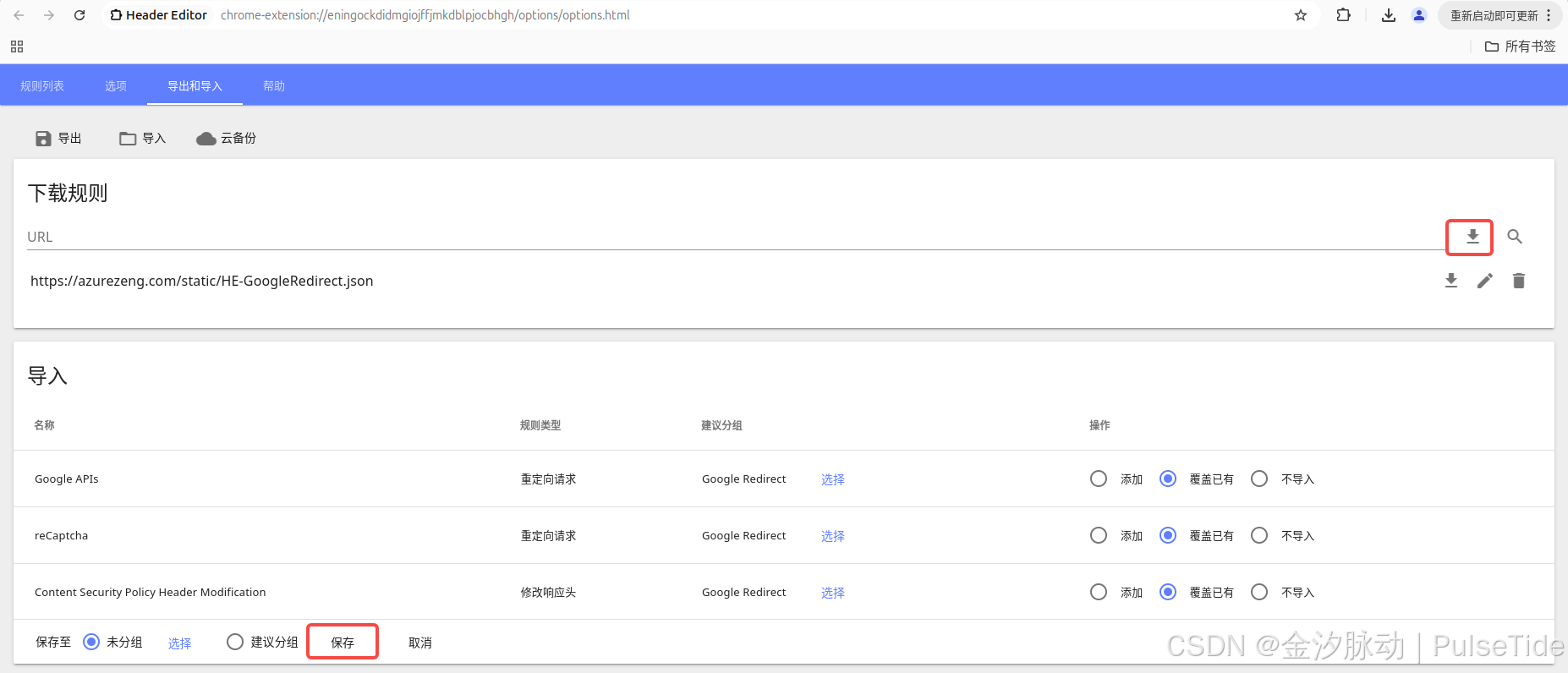
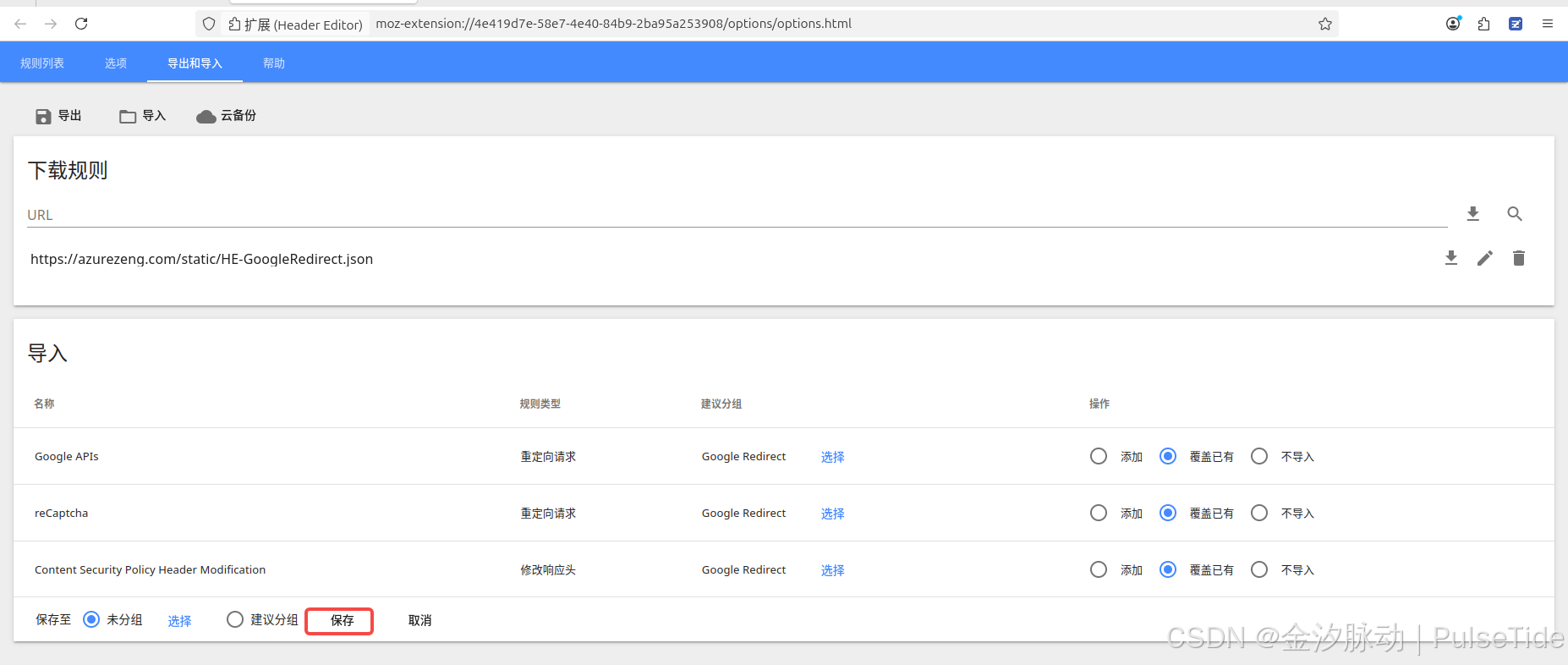
以火狐瀏覽器為例,同樣先下載插件header_editor-4.1.1.xpi,然后打開拓展管理頁面about:addons,直接把插件拖進去,同樣地啟用配置插件:

刷新 Kaggle 注冊頁面,可以看到驗證碼正常顯示了:
注冊成功!
三、競賽指南
Competitions->Getting Started,在競賽頁面開始部分,可以看到有一些較為容易上手的機器學習競賽項目,我們選擇其中的“泰坦尼克號生存者預測”作為開始。
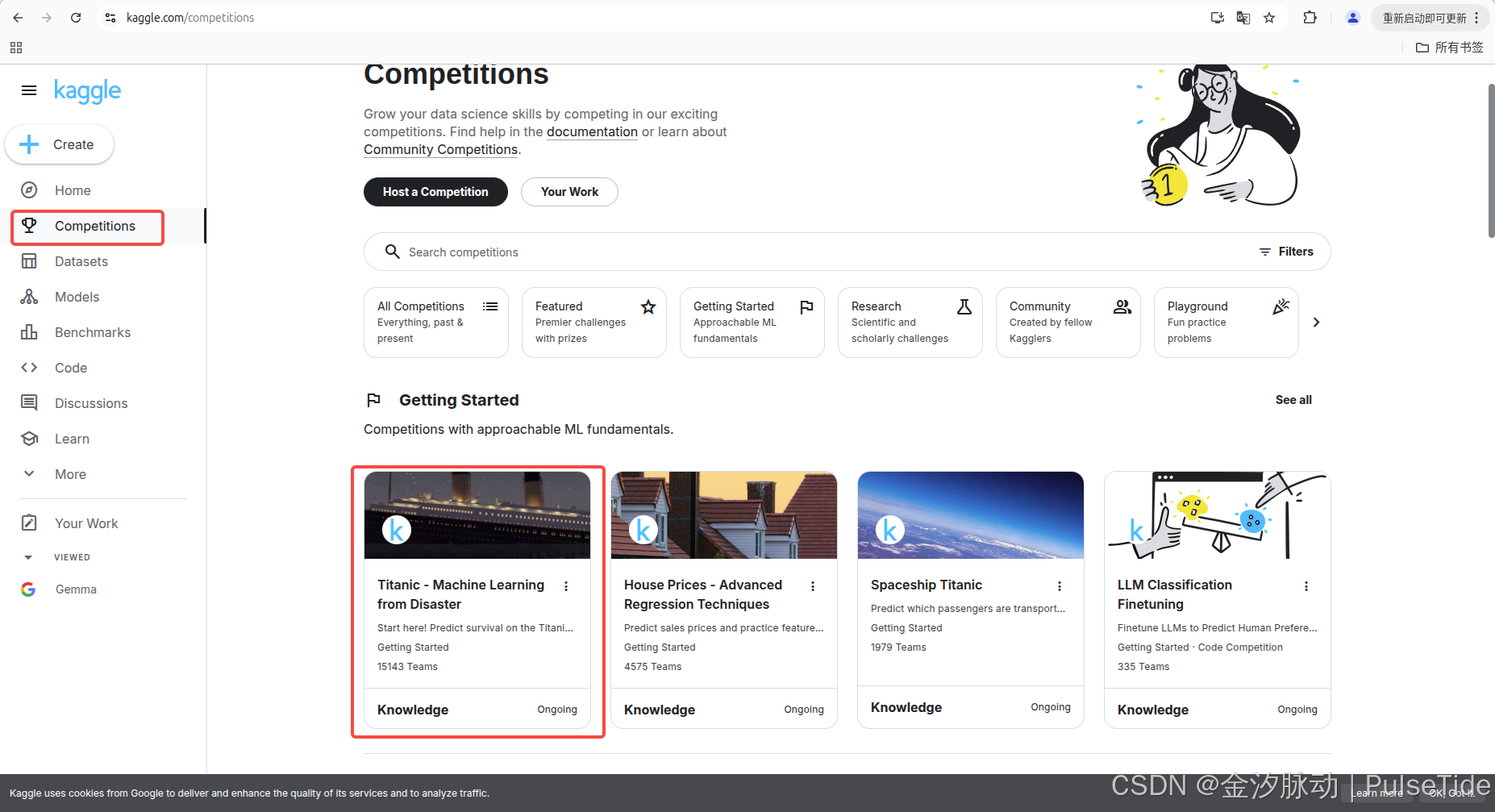
1、賽事任務
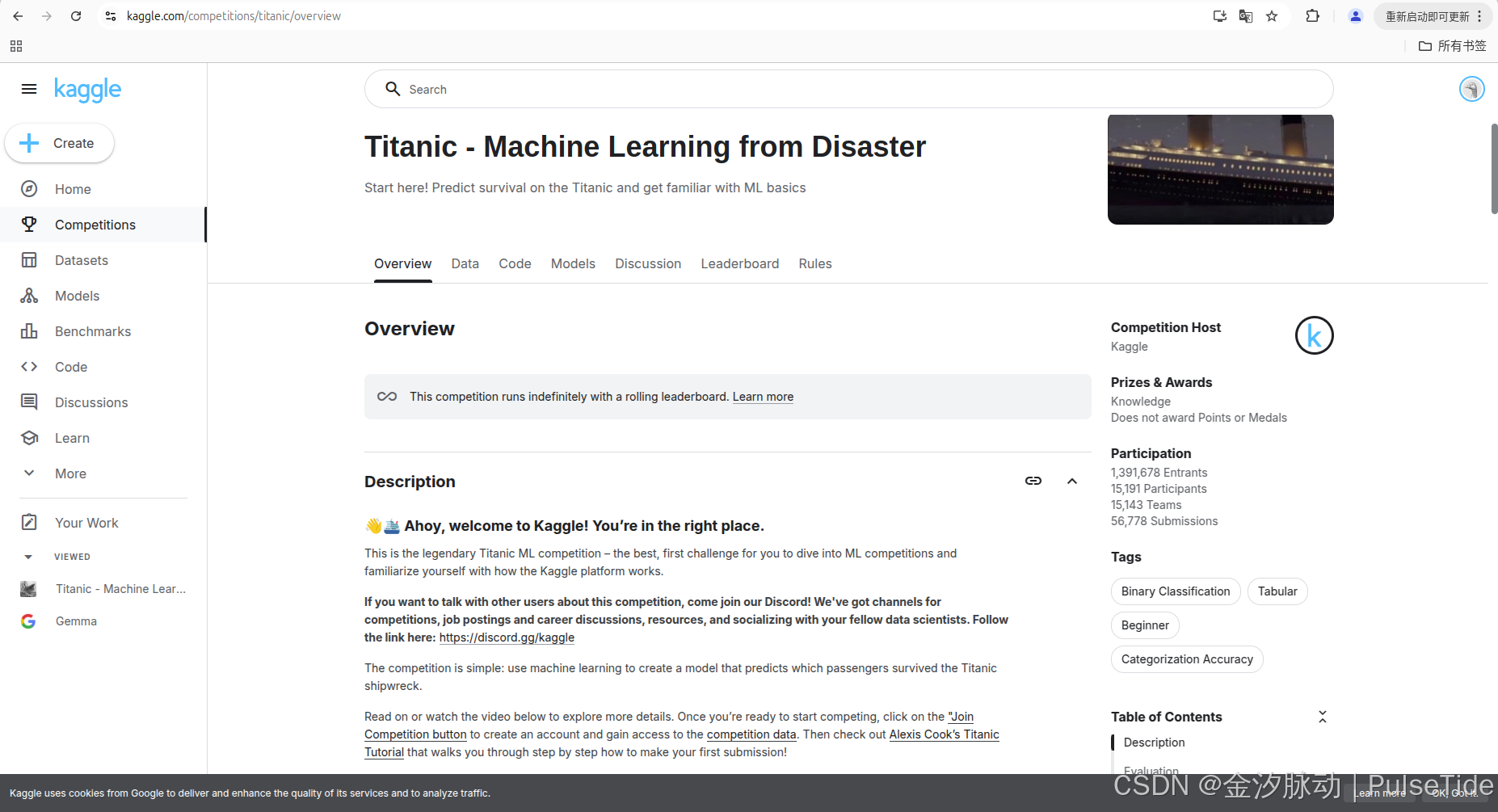
使用機器學習創建一個模型來預測哪些乘客在泰坦尼克號沉船災難中幸存下來。
2、數據集
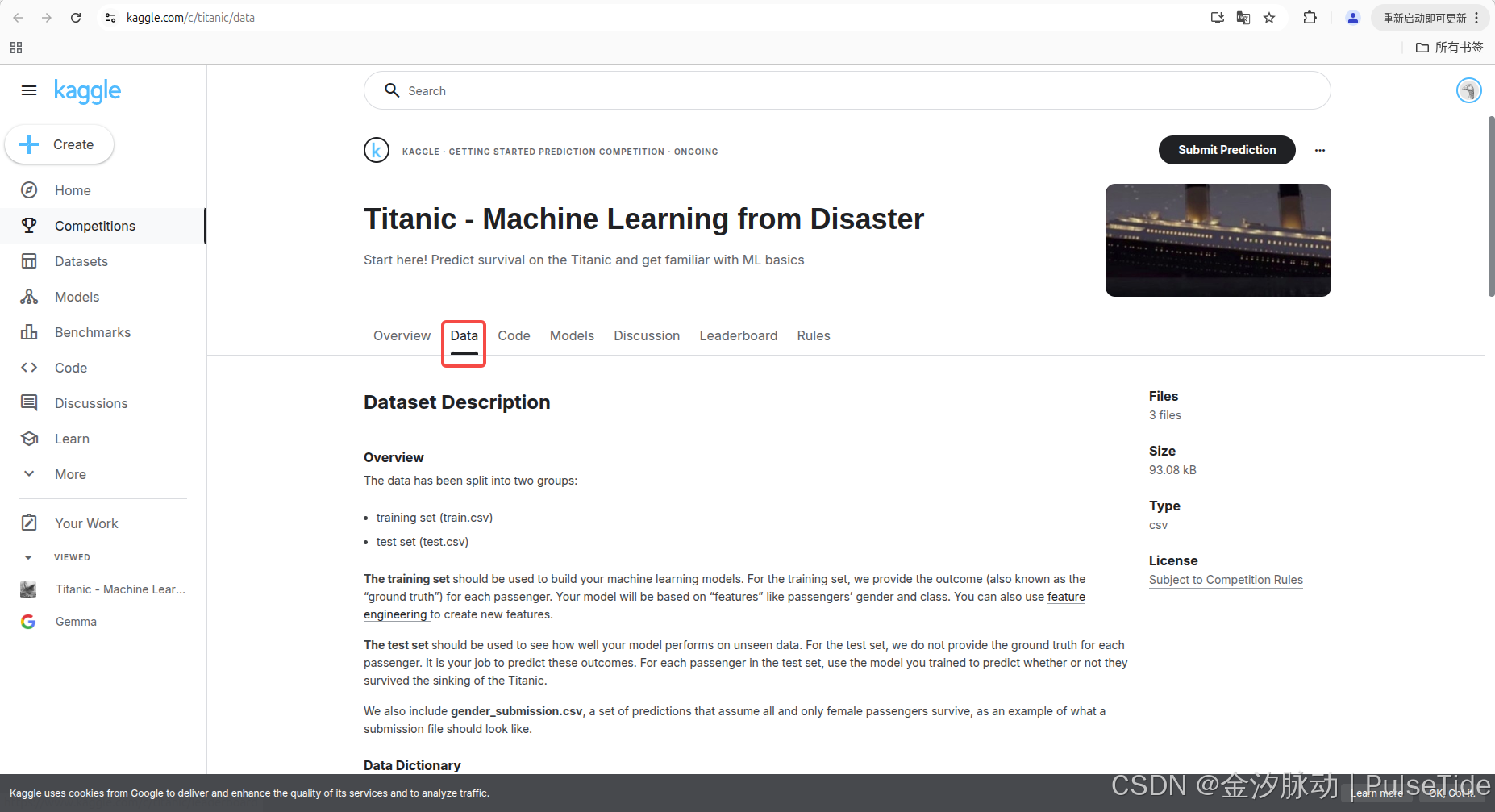
該賽事一共提供了三個數據集:
- 訓練集(train.csv)
- 核心用途:用于構建機器學習模型
- 關鍵特征:包含乘客性別、艙位等級等特征字段
- 特殊屬性:提供每個乘客的生存結果
- 擴展功能:支持通過特征工程創建新特征
- 測試集(test.csv)
- 核心用途:評估模型在未知數據上的表現
- 關鍵差異:不提供乘客生存的真實結果
- 用戶任務:需使用訓練好的模型預測乘客生存狀態
- 應用場景:模擬真實業務中的預測場景
- 示例文件(gender_submission.csv)
- 示范性質:展示標準提交文件的格式規范
- 設計目的: 演示預測結果的文件結構,說明二分類問題的提交格式 。
如果需要本地環境進行實驗的話,可以點擊 Download All 下載全部數據集:
3、代碼教程
Titanic Tutorial 介紹了代碼如何實現訓練模型并提交第一個預測結果:
可以點進鏈接直接查看 notebook:
當然也可以復制一份 notebook:
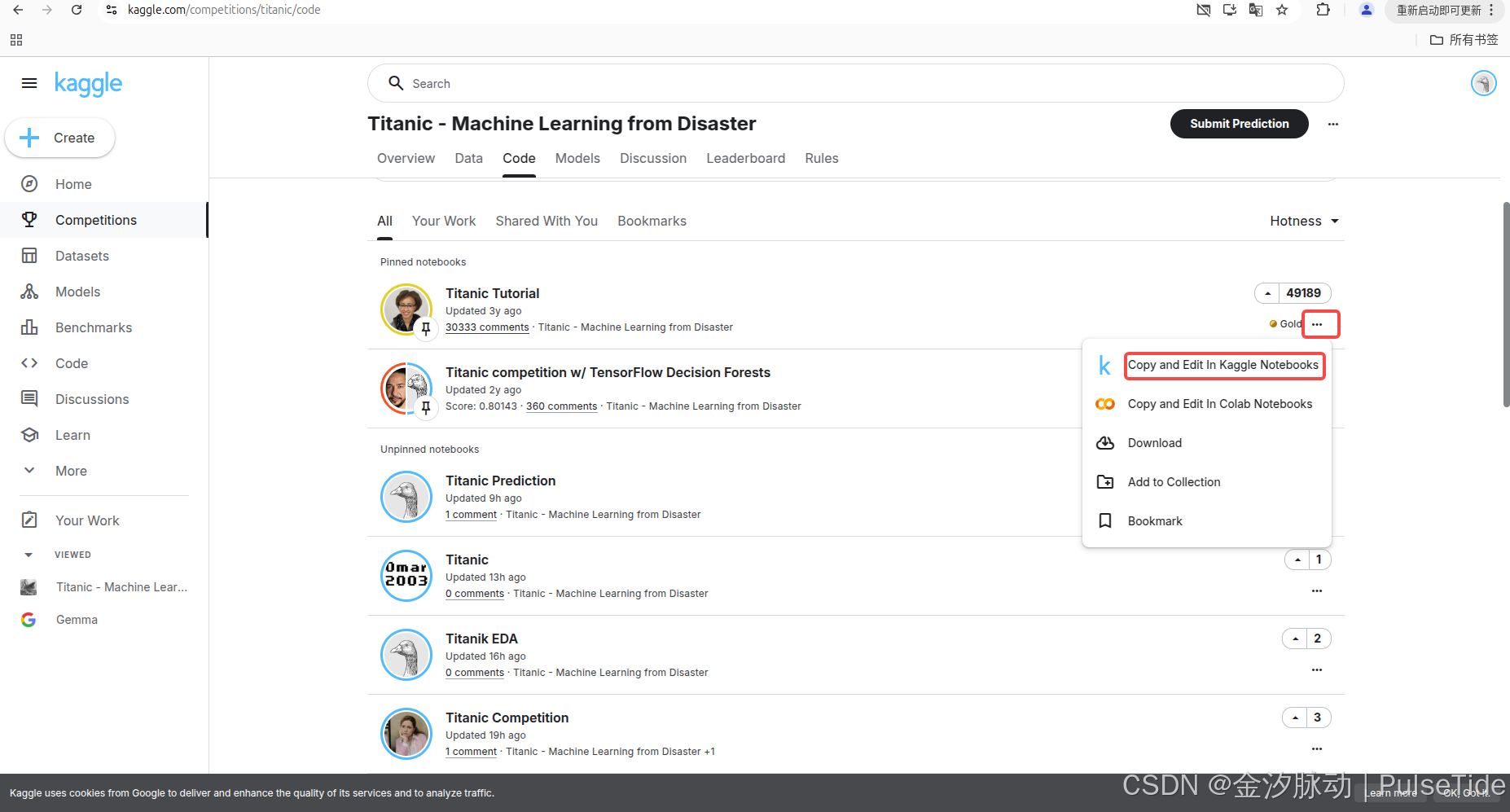
四、上手實戰
1、創建一個Notebook
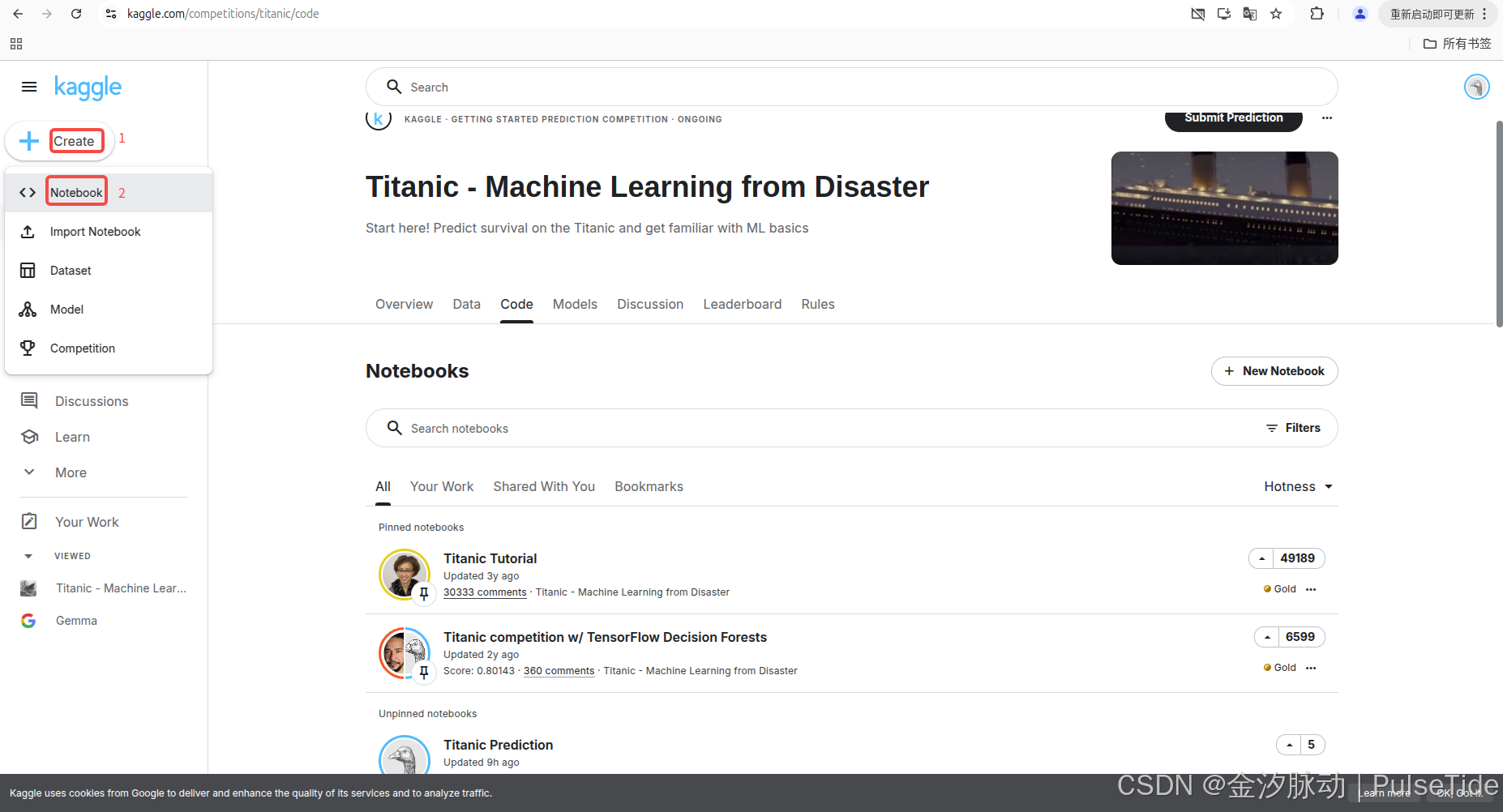
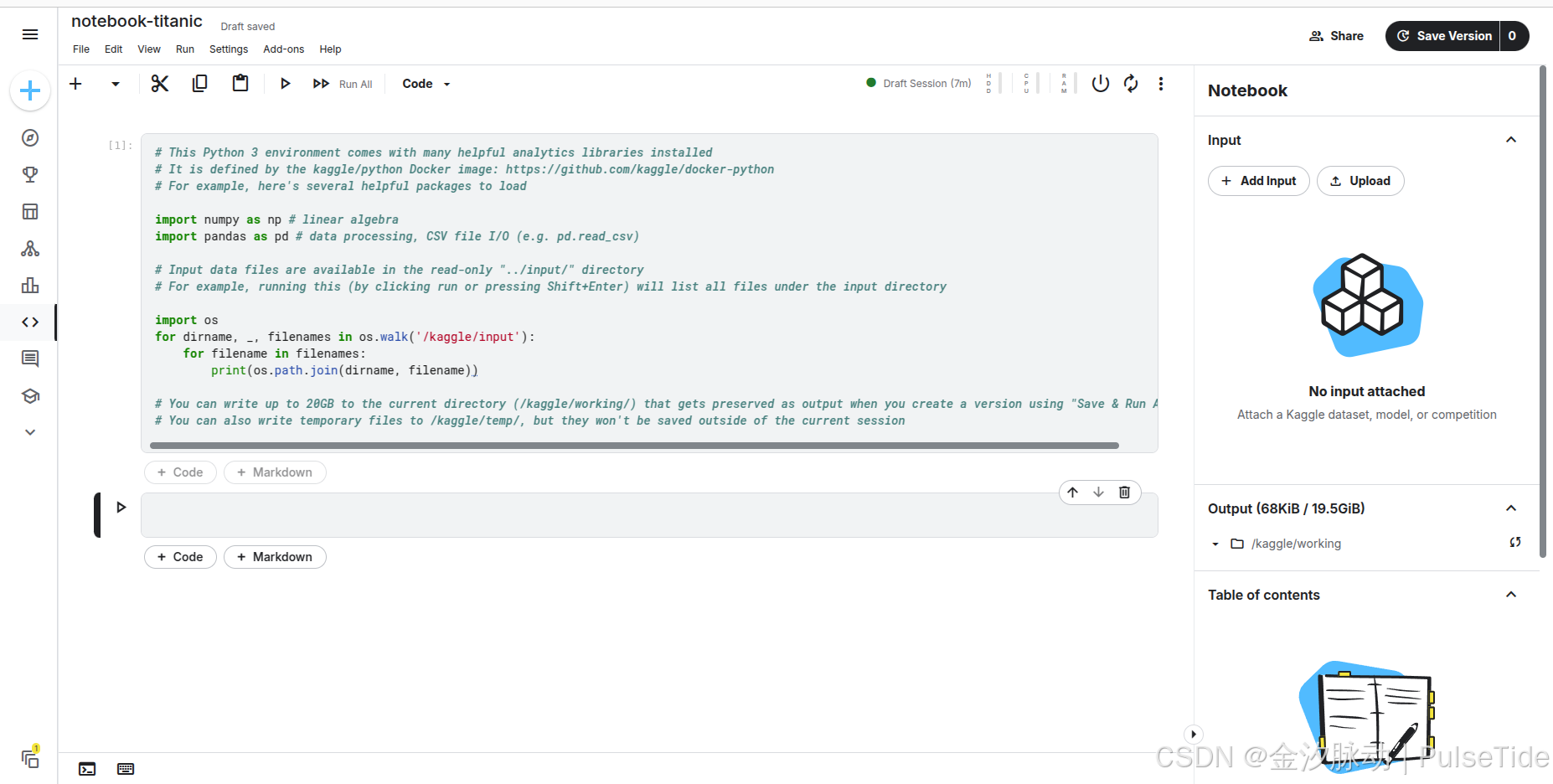
自動創建的 Notebook 會自動生成一段代碼,它引導我們如何讀取文件輸入。
2、導入數據集
我們可以在線導入競賽數據集:
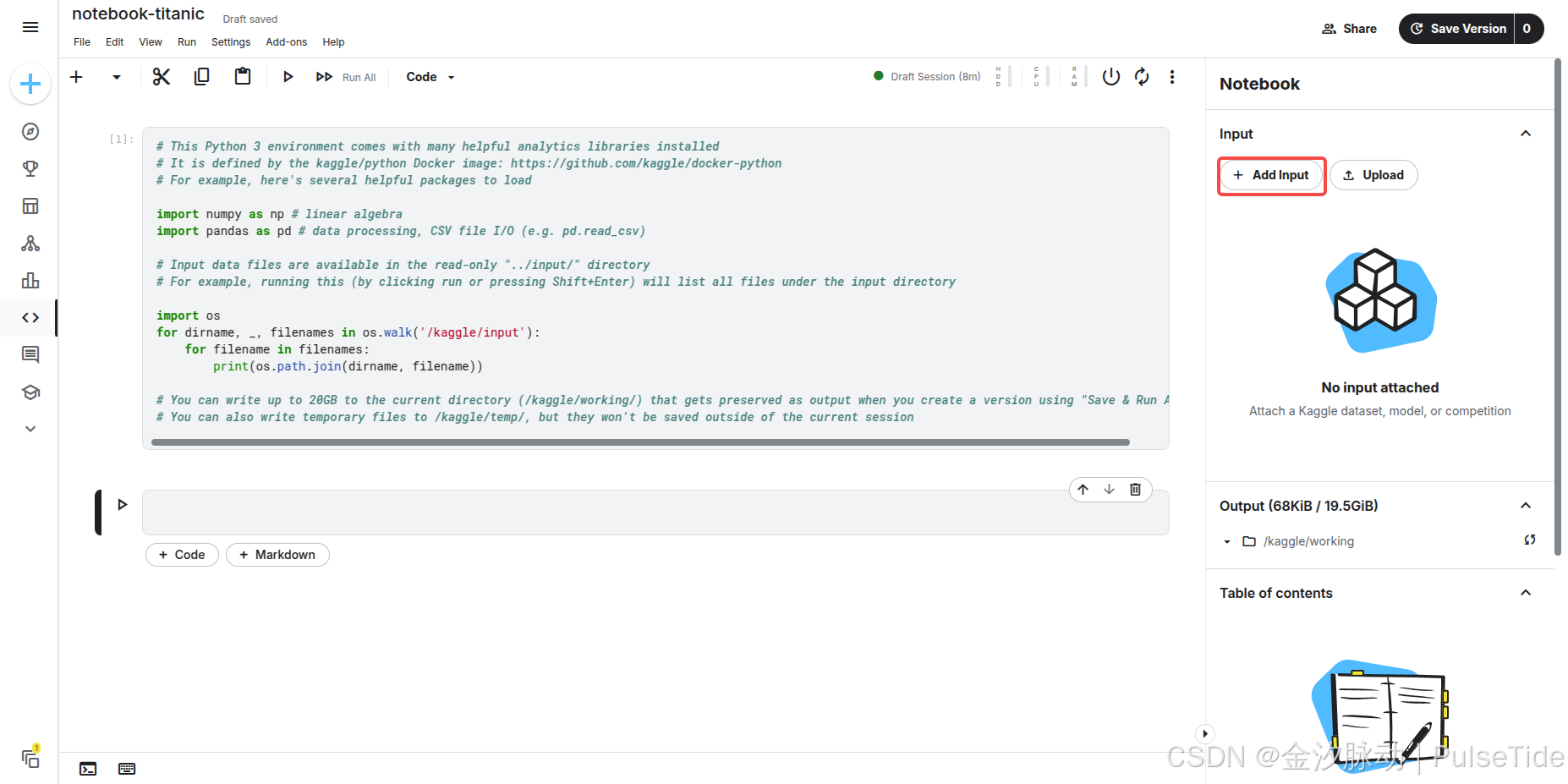
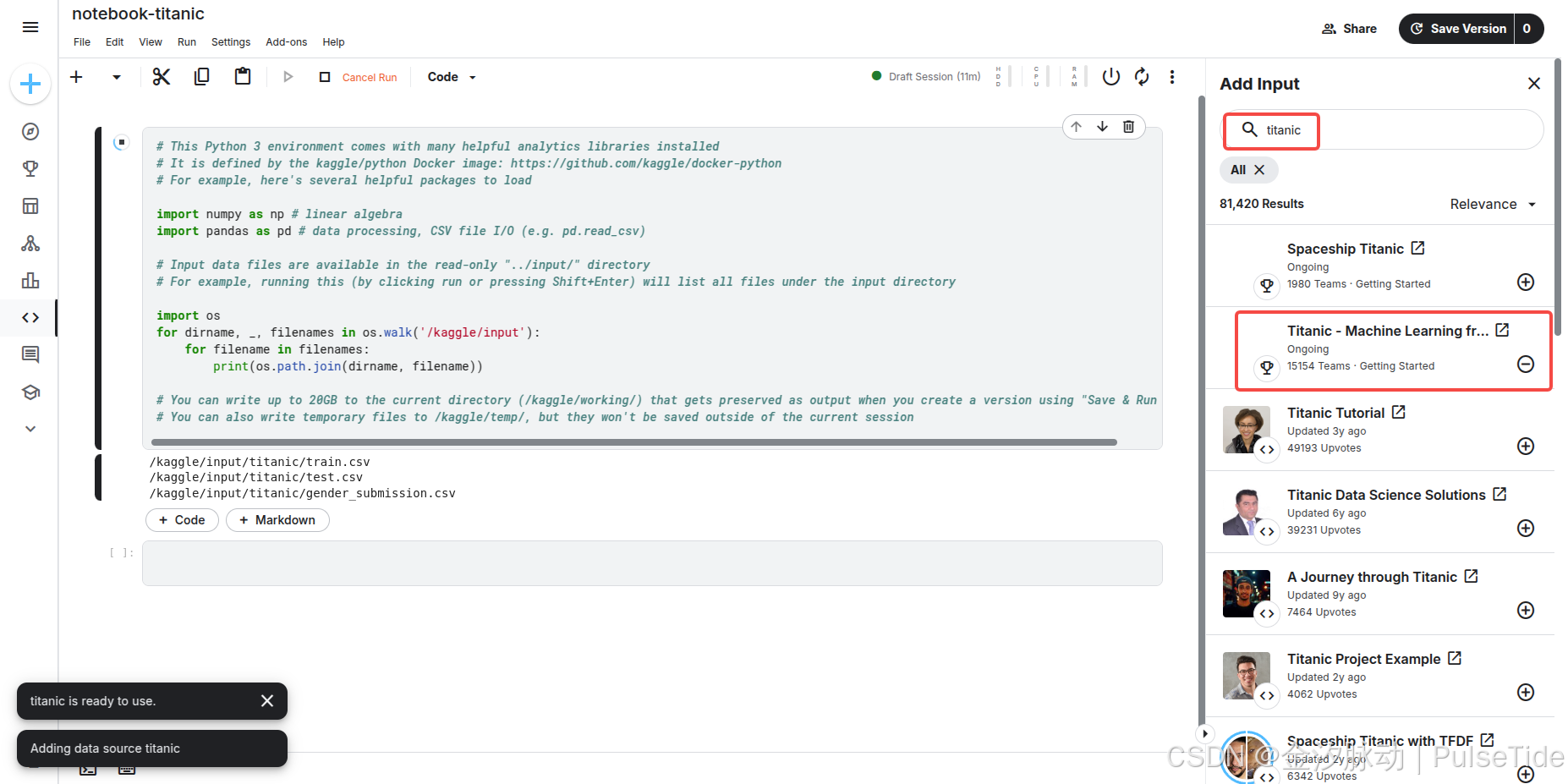
此時按下 [Shift] + [Enter] 執行代碼,則對應輸出三個文件路徑。
除了在線導入數據集,我們也可以上傳本地數據集:
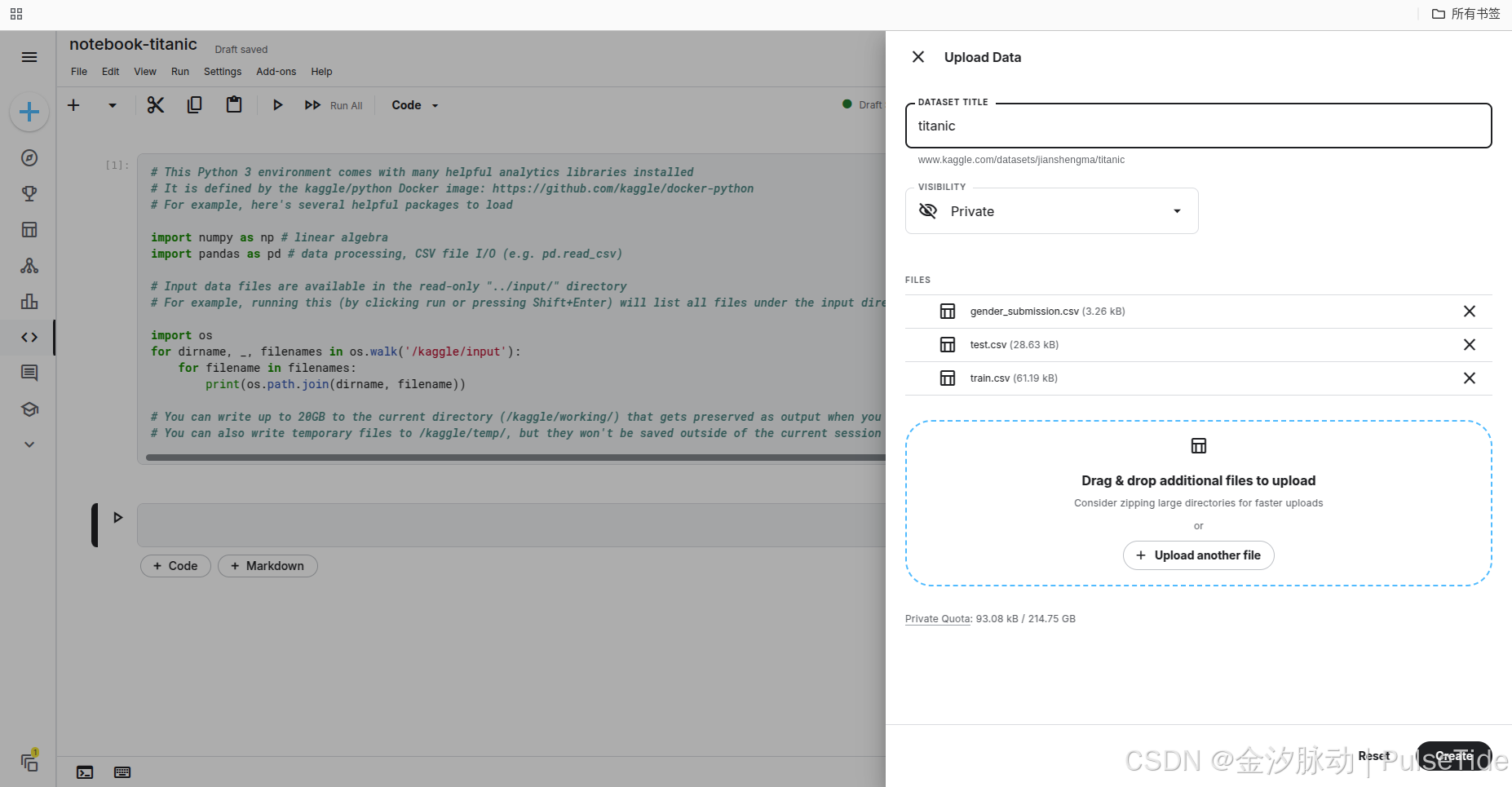
3、加載數據
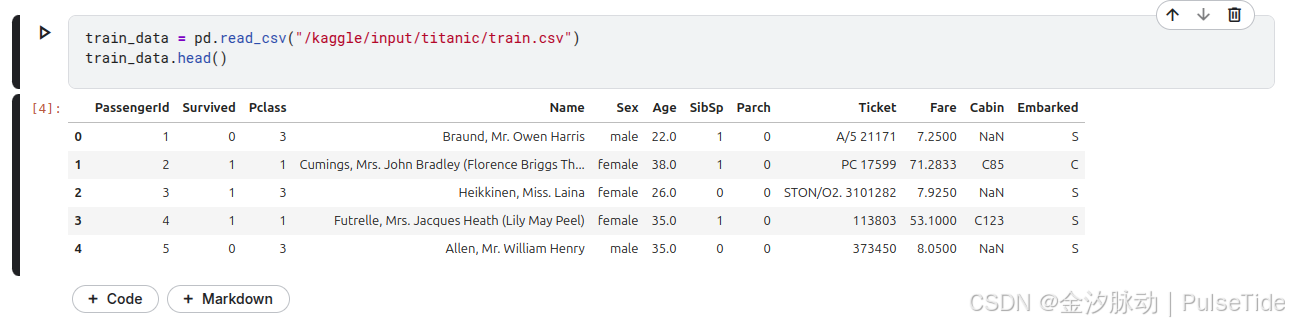
讀取訓練集數據,并查看前5行數據:
train_data = pd.read_csv("/kaggle/input/titanic/train.csv")
train_data.head()
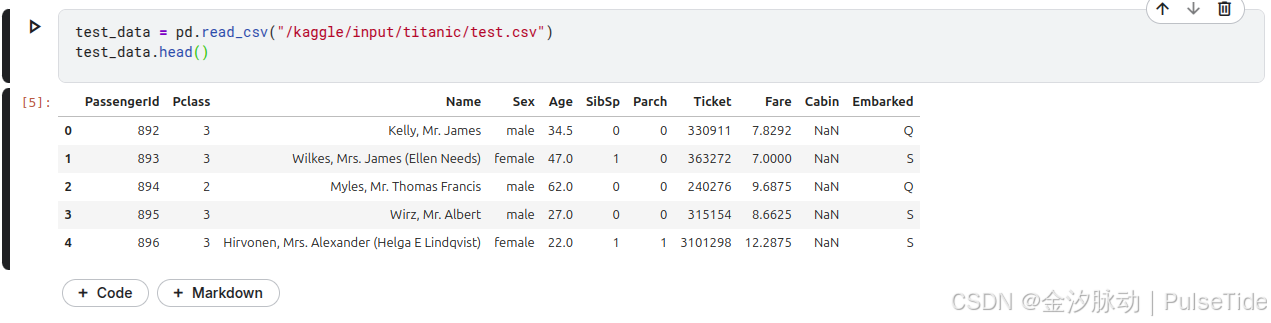
讀取測試集數據,并查看前5行數據:
test_data = pd.read_csv("/kaggle/input/titanic/test.csv")
test_data.head()
4、建立模型
Tutorial 中構建了一個名為隨機森林的模型,該模型由多棵"決策樹"組成,每棵樹將獨立分析每位乘客的數據,并對其是否幸存進行投票,最終,隨機森林模型將通過?民主決策?確定結果:得票最高的結果即為預測結果。
Tutorial 代碼通過分析數據中的四個字段(“Pclass”(艙位等級)、“Sex”(性別)、“SibSp”(同行兄弟姐妹/配偶數)和"Parch"(同行父母/子女數))來尋找規律,它將基于 train.csv 訓練集文件中的數據規律構建隨機森林模型中的決策樹,隨后對 test.csv 測試集中的乘客生成預測結果,同時,代碼會將預測結果保存至 submission.csv 文件中。
from sklearn.ensemble import RandomForestClassifiery = train_data["Survived"]features = ["Pclass", "Sex", "SibSp", "Parch"]
X = pd.get_dummies(train_data[features])
X_test = pd.get_dummies(test_data[features])model = RandomForestClassifier(n_estimators=100, max_depth=5, random_state=1)
model.fit(X, y)
predictions = model.predict(X_test)output = pd.DataFrame({'PassengerId': test_data.PassengerId, 'Survived': predictions})
output.to_csv('submission.csv', index=False)
print("Your submission was successfully saved!")
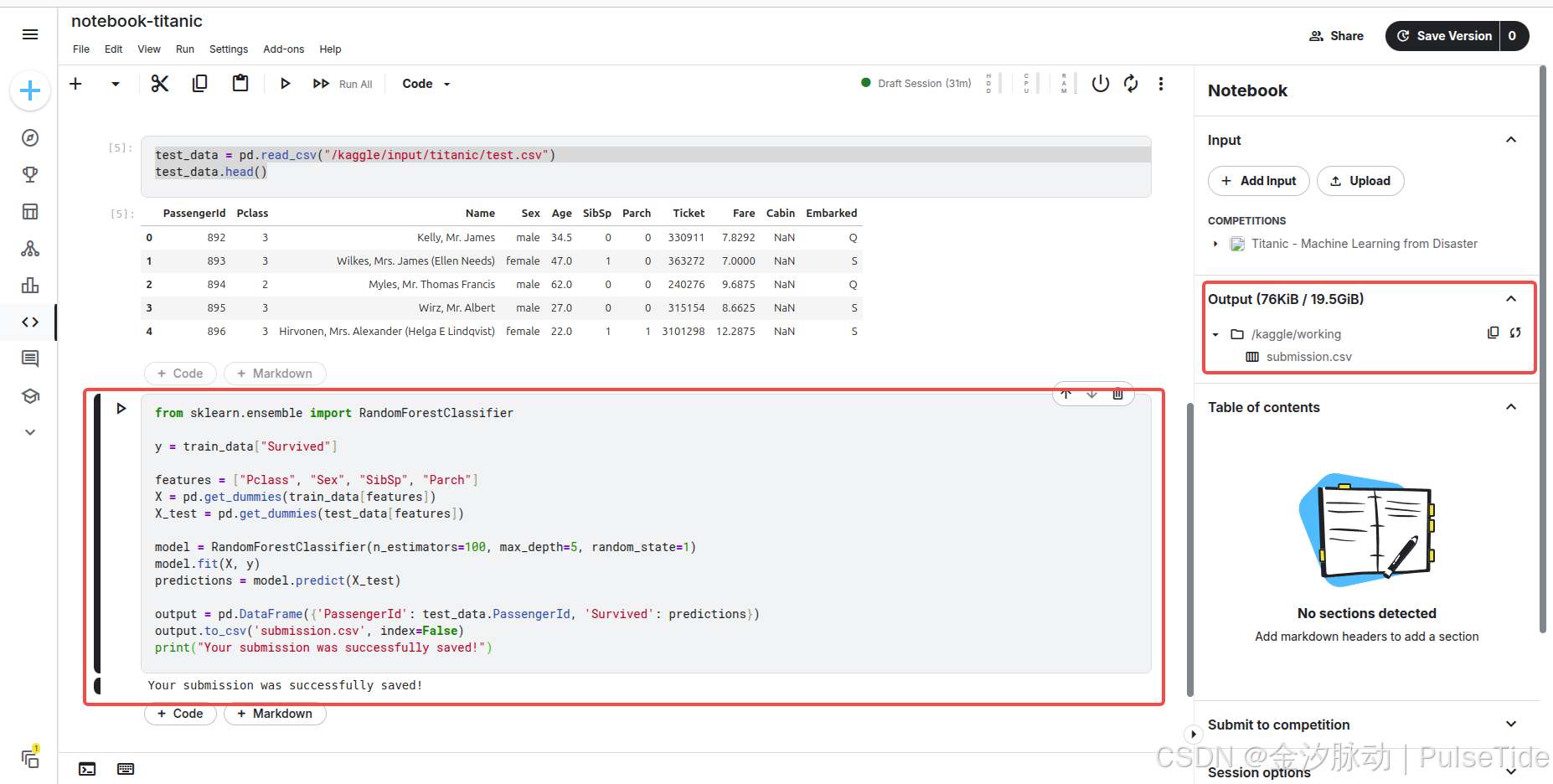
執行代碼,在 Output 路徑下生成了預測結果文件 submission.csv。
5、提交結果
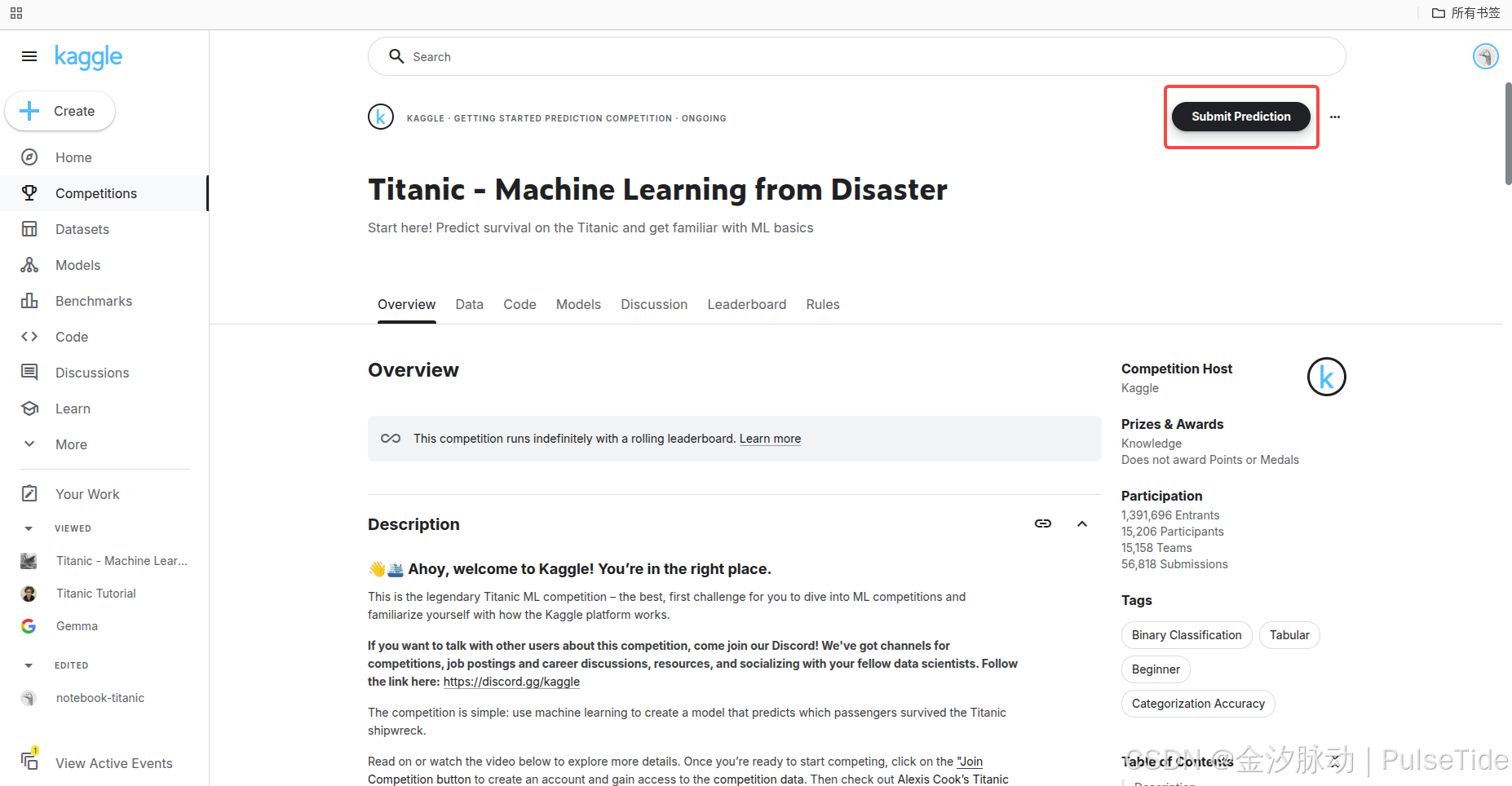
可以提交本地 csv 文件:
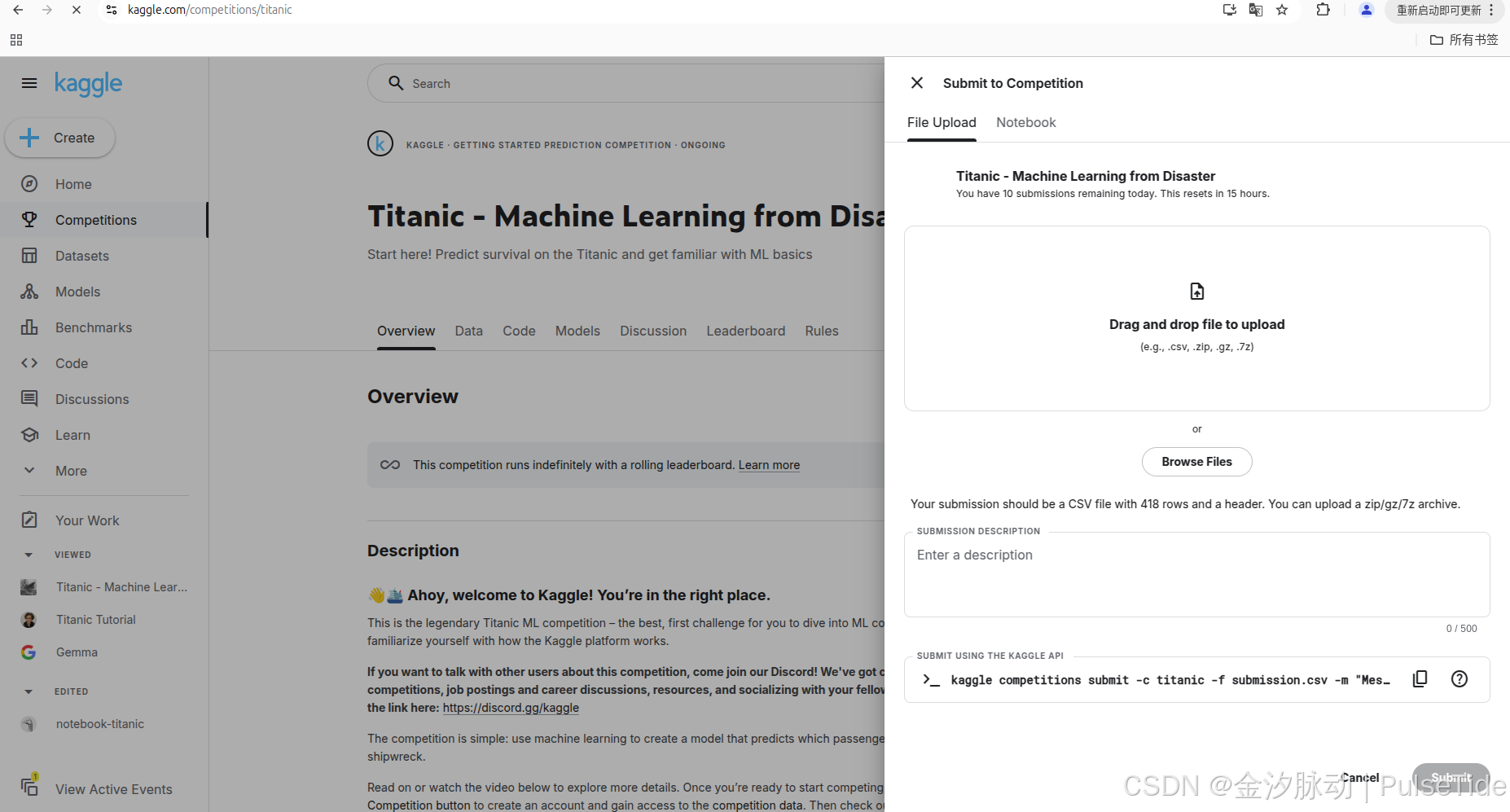
也可以在剛剛的 notebook 中直接提交 :
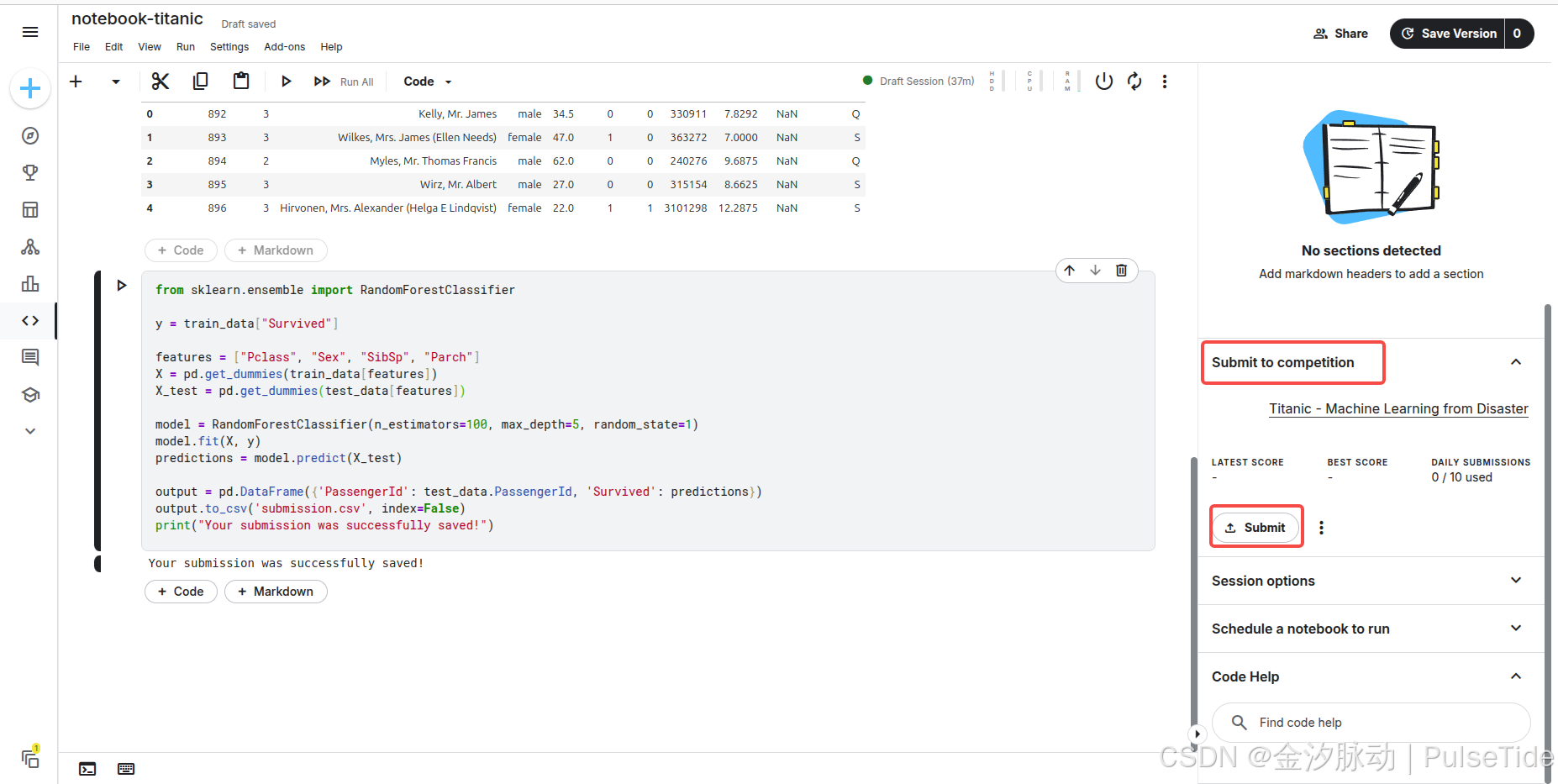
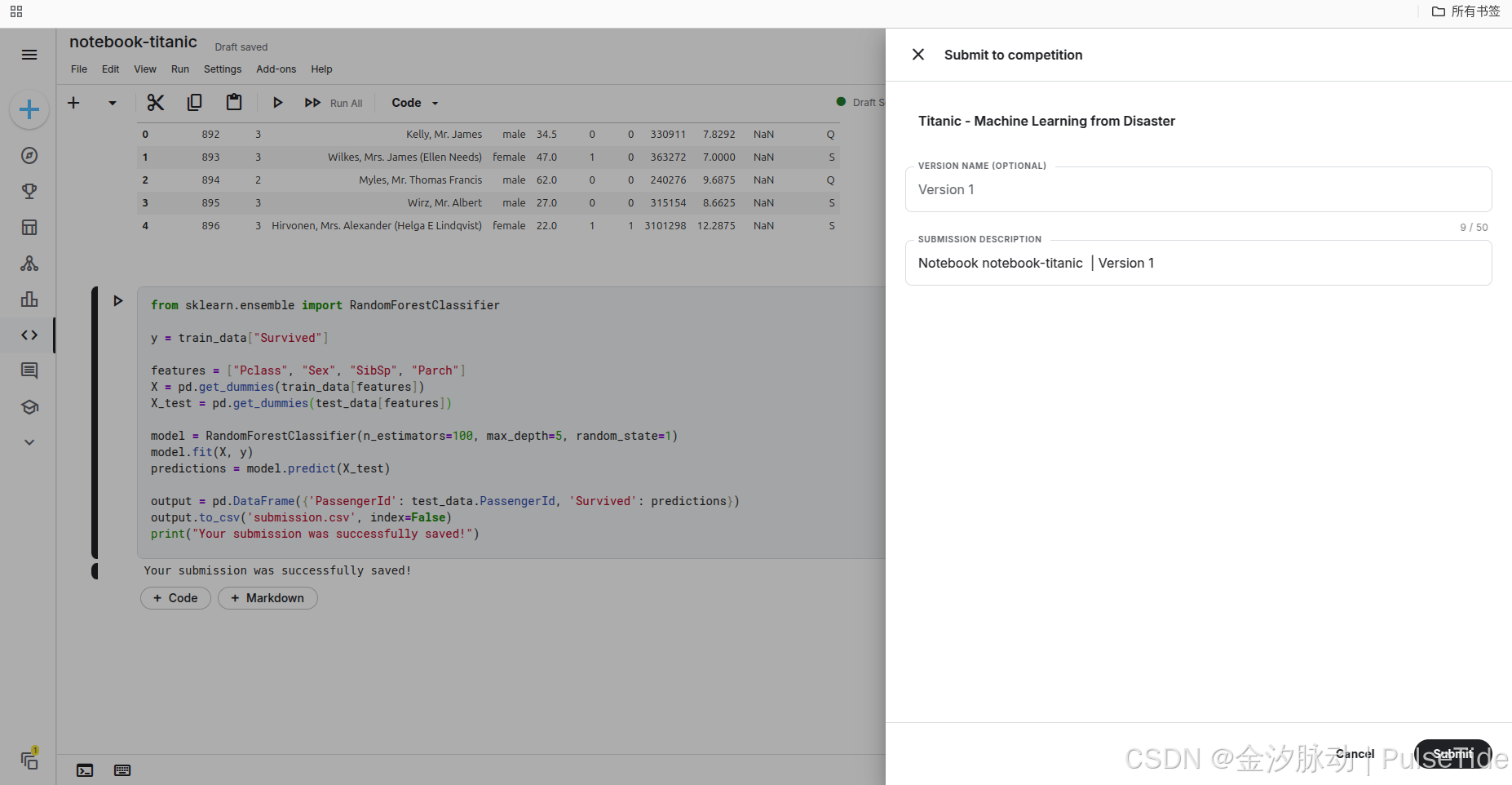
6、排行榜
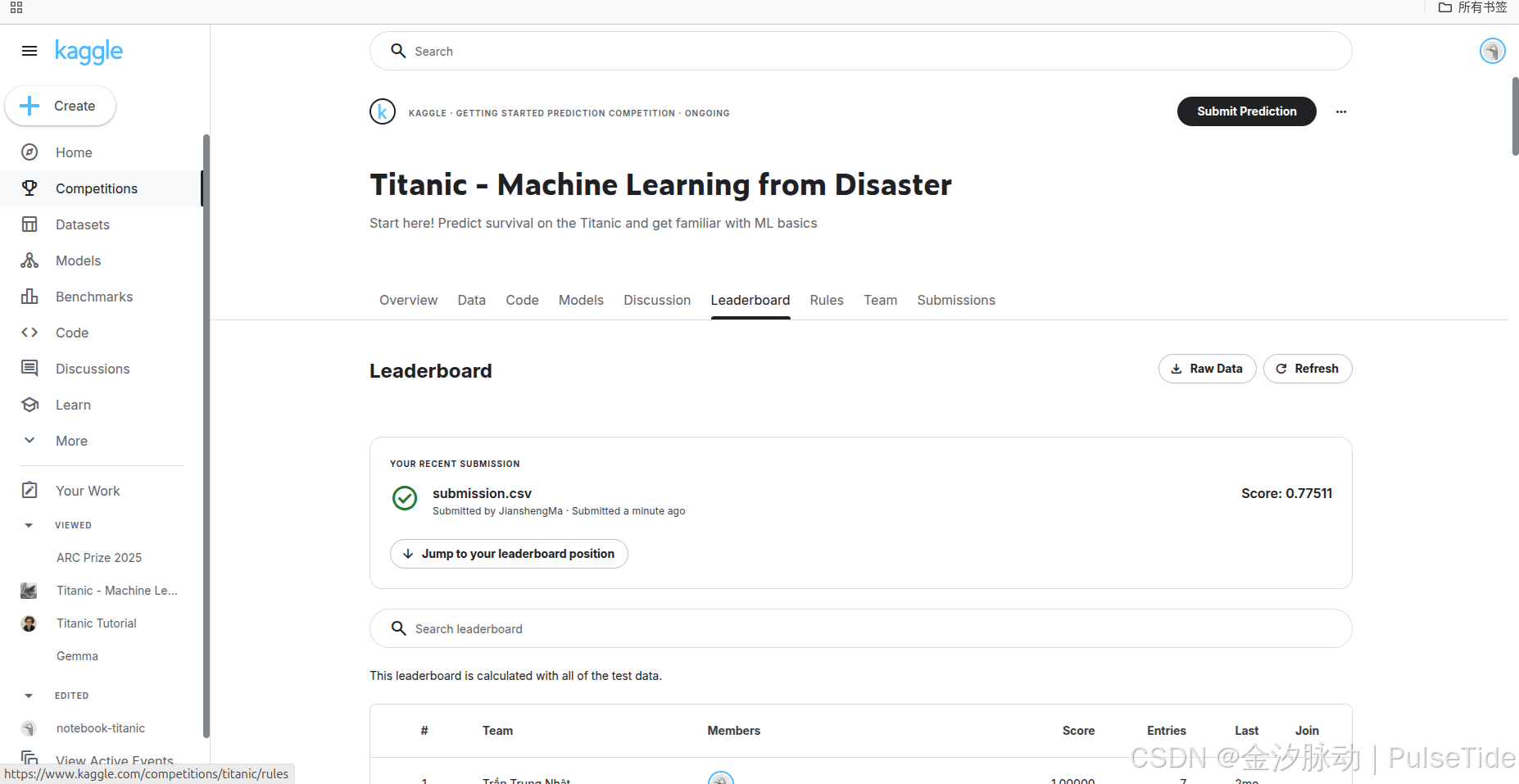
提交結果后,可以在 Leaderboard 頁面查看得分與排行:

7、上分打榜
接下來就是使用各種方法不斷打磨模型提升預測準確度,注意賽事每天都有提交限制,需要充分利用每一次機會。
8、隨機森林算法
核心概念
隨機森林是一種基于Bagging集成學習的分類算法,通過組合多棵獨立訓練的決策樹提升模型精度與魯棒性。其核心思想是:
- 雙重隨機性:
- 數據隨機抽樣(Bootstrap):每棵樹訓練時從原始數據集中有放回抽取樣本子集。
- 特征隨機選擇:每棵樹分裂節點時,僅從隨機子集(如√n個特征)中選取最優分裂特征。
- 集成預測:最終分類結果由所有決策樹投票決定(多數表決)。
工作原理
- 構建多棵決策樹:
- 通過自助采樣生成
n_estimators個樣本子集,每個子集訓練一棵決策樹。 - 決策樹完全生長(不剪枝),依賴隨機特征選擇降低過擬合風險。
- 通過自助采樣生成
- 分類過程:
- 輸入樣本通過每棵決策樹獨立預測類別。
- 森林輸出得票最高的類別作為最終結果。
主要優勢
- 抗過擬合:雙重隨機性降低模型方差,提升泛化能力。
- 處理復雜數據:
- 支持高維特征,無需手動特征選擇。
- 對缺失值、異常值不敏感。
- 輔助分析:可評估特征重要性(基于分裂時的信息增益)。
- 并行化訓練:各決策樹獨立構建,適合分布式計算。
局限性
- 計算開銷大:樹的數量(
n_estimators)增加會顯著延長訓練時間。 - 模型解釋性差:黑盒性質強,單棵樹可解釋但整體集成邏輯復雜。
- 空間占用高:需存儲多棵樹結構,內存消耗較大。
典型應用場景
- 醫療診斷:預測疾病風險(如癌癥早期篩查)。
- 金融風控:信用評分、欺詐交易檢測。
- 電商推薦:用戶行為分類與商品個性化推薦。
- 生物信息學:基因分類與蛋白質功能預測。
關鍵參數說明:
n_estimators:樹的數量(默認100,建議50-200)。max_depth:單棵樹最大深度(控制復雜度)。max_features:隨機選擇特征數(如"sqrt"表示√n)。oob_score=True:啟用袋外樣本評估模型精度。
總結
隨機森林分類器以其高準確性、魯棒性和易用性成為經典算法,尤其適用于復雜分類任務。盡管計算成本較高且可解釋性弱,其在工業界和學術界的廣泛應用驗證了其有效性。
五、GPU/TPG 額度
GPU的并行架構(數千核心)可加速神經網絡的海量矩陣運算,顯著縮短訓練周期(如ResNet、BERT等大型模型);針對已訓練模型(如Transformer),TPU的定制化張量計算單元可實現超高吞吐量響應,成本低于GPU。
Kaggle 提供的 GPU/TPG 額度如下:
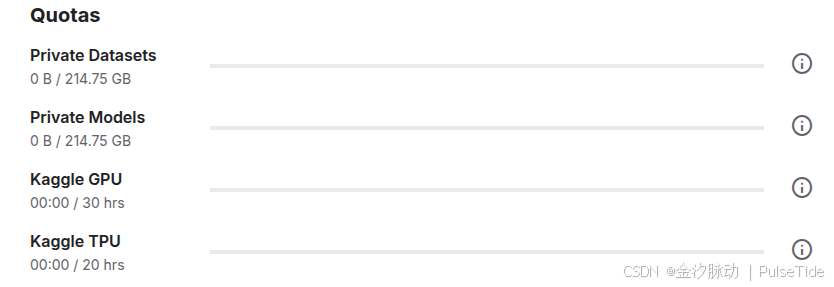
- GPU免費額度:每周30小時
- TPU免費額度:每周20小時
六、不止競賽
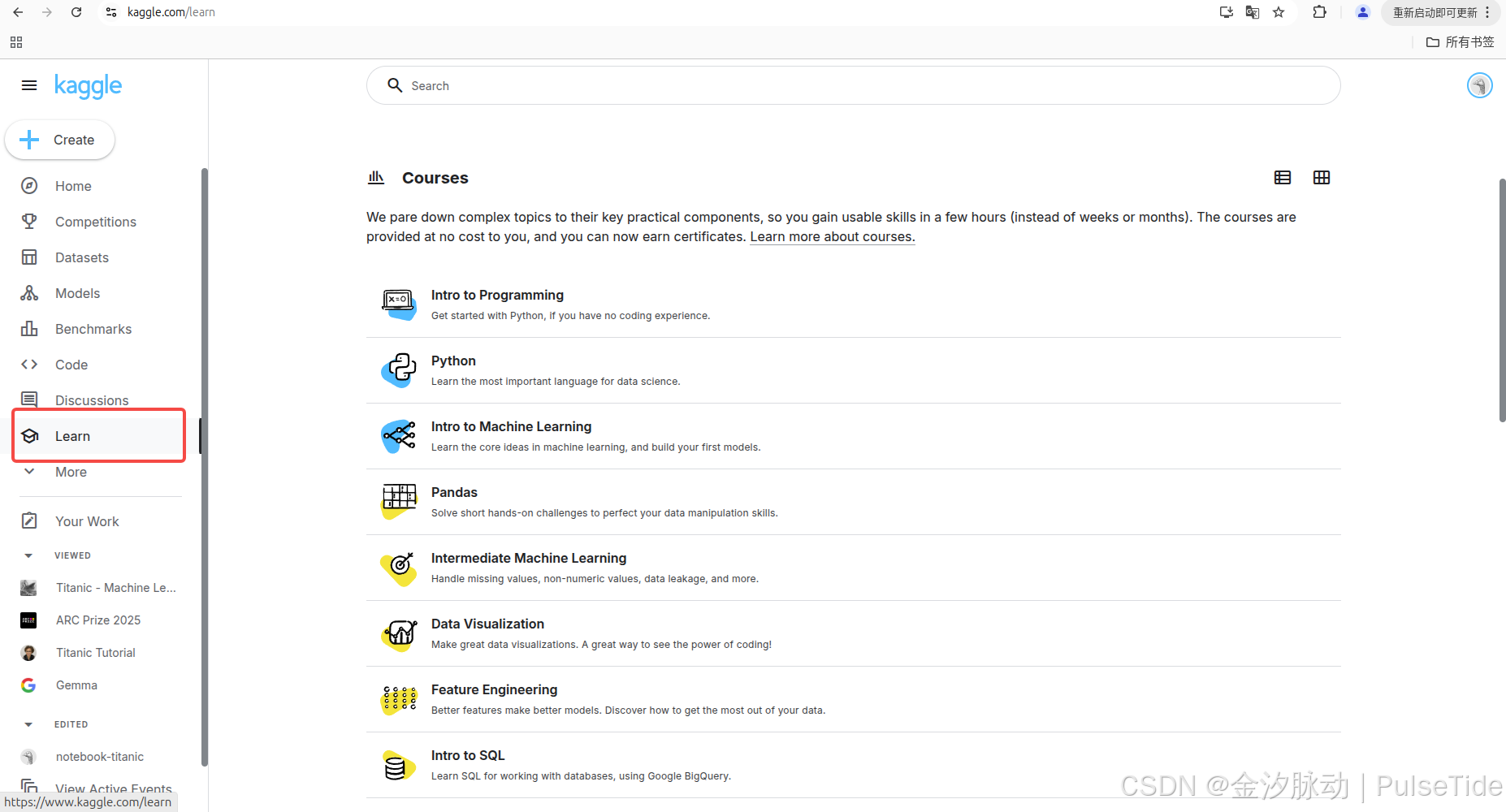
Kaggle 上還有很多競賽時需要用到的基礎知識課程,我們可以從這些課程中快速學會相關技能。









)









