本系列文章將圍繞東南亞頭部科技集團的真實遷移歷程展開,逐步拆解 BigQuery 遷移至 MaxCompute 過程中的關鍵挑戰與技術創新。本篇為第3篇,解析跨國數倉遷移背后的性能優化技術。
注:客戶背景為東南亞頭部科技集團,文中用 GoTerra 表示。
背景
作為東南亞數字經濟的核心參與者,GoTerra的數據架構需支撐億級用戶規模的交易、高并發風控及跨區域物流調度。其原有BigQuery數倉雖具備強大的分析能力,但在業務規模突破臨界點后,成本問題日益凸顯。遷移至MaxCompute的核心目標,是通過底層架構重塑與性能優化技術體系,實現“降本”與“增效”的雙重突破。在攻克 SQL 語法轉換、存儲格式等技術難題后,遷移進入深水區——性能優化成為項目推進的關鍵瓶頸,并且面臨三大核心挑戰:
- 業務腳本復雜性高:涉及 1萬+ 生產級 SQL 腳本,覆蓋支付、物流、風控等核心業務線,腳本模式豐富、性能目標及成本訴求各異,優化難度大。
- 增量功能疊加挑戰大:遷移過程中同步推出的600+新功能(如
append2。0、unnest等)導致優化復雜度指數級上升。 - 極限交付時間窗口:需在不足 4 個月的時間內,保障所有業務平滑遷移至 MaxCompute,同時全面滿足高標準 SLA,容錯空間極小。
性能優化方法論:從“盲人摸象”到“精準狙擊”
針對上述挑戰,團隊摒棄傳統“粗放式”優化策略,轉而建立“數據驅動、分層治理”的優化框架,其核心邏輯是通過智能分類,將有限資源投入關鍵瓶頸點。根據二八原則 ,80% 的問題/資源消耗來自 20% 的高頻或低效查詢,為了精準定位問題,我們通過一個自動化的分類工具快速識別:
- 高頻查詢:優化收益最大
- 低效查詢:存在潛在優化空間(如全表掃描、非預期CROSS JOIN)
- 關鍵業務查詢:需優先保障 SLA
同時在這個工具基礎上:
- 建立性能基線:分類后統計各類型查詢的耗時、資源消耗趨勢。
- 評估優化效果:對比優化前后的同類型查詢指標變化。
以下是性能優化初期查詢分類的一個示例圖,從圖中我們很輕易的可以看到,分區裁剪/復雜類型/append2/unnest等是主要問題,應該著重解決。
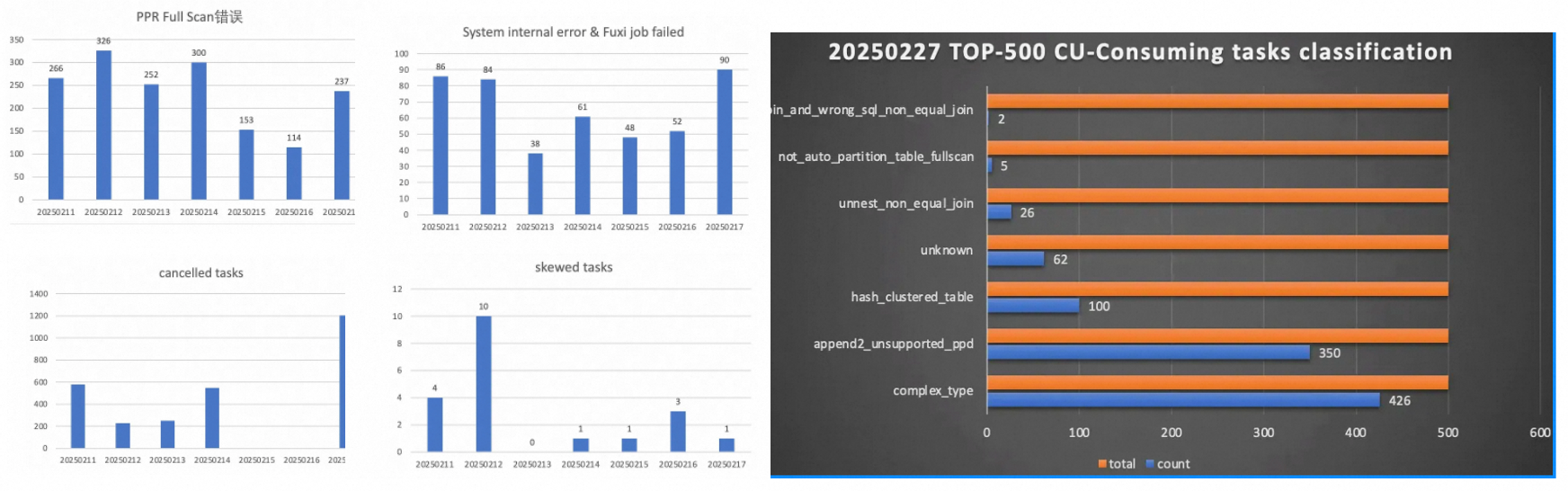
關鍵優化
Auto Partition優化
痛點
MC通過Auto Partition表來實現和BQ time-unit column partitioning類似的功能。相較于傳統靜態分區表,Auto Partition 表通過 trunc_time 函數動態生成分區列,如下圖所示:
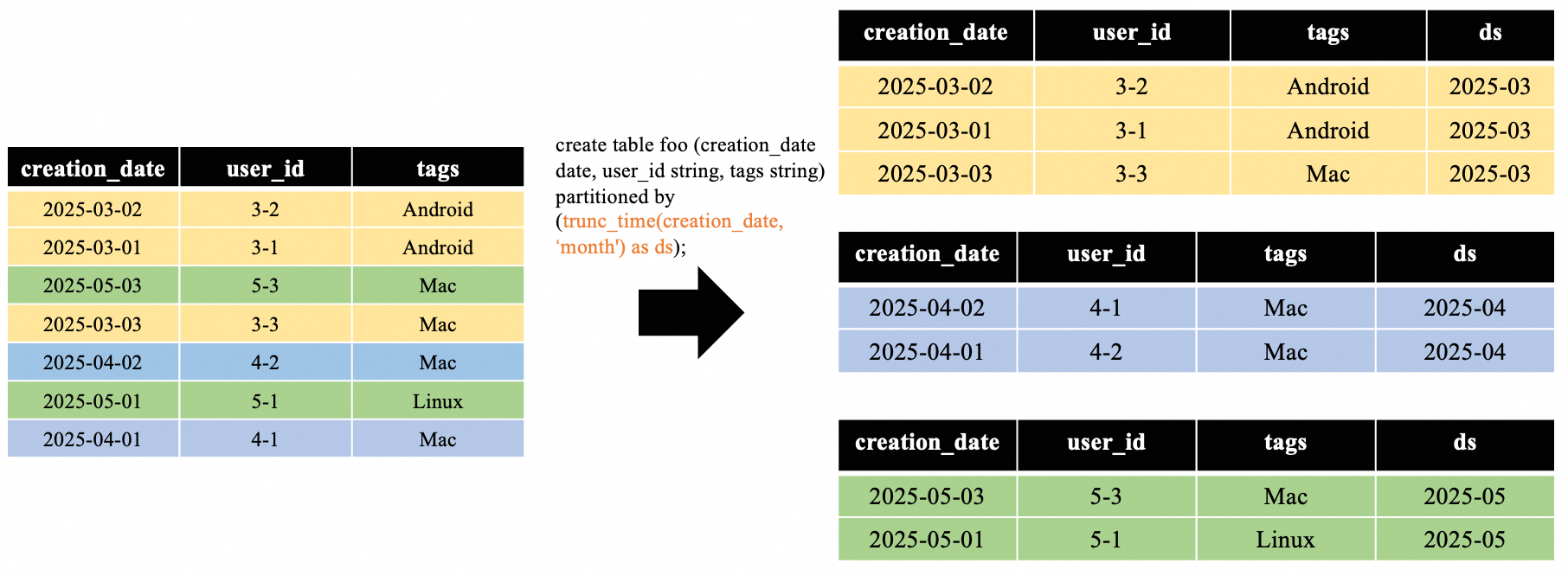
Auto Partition功能有效提升了分區管理的靈活性,但是分區列與查詢條件無法直接映射導致無法直接復用靜態分區表的分區裁剪流程,從而使得分區裁剪失效,引發兩大核心問題:
- 讀表性能劣化:查詢需全量掃描所有分區,時延高
- 資源浪費嚴重:冗余數據掃描使計算資源消耗高
方案
為了支持Auto Partition表的分區裁剪功能,我們設計了基于表達式推導的動態分區裁剪方案,在保證查詢語義正確性的前提下最大化減少數據掃描量。假設有下Auto Partition 表及其查詢:
create table auto_partition_table
(key string, value bigint, ts timestamp
)
partitioned by trunc_time(ts, 'day') as pt
;SELECT * FROM auto_partition_table
WHERE ts > timestamp'2024-09-25 01:12:15';從上可以看到基于ts列的過濾條件做分區裁剪的本質是進行表達式映射轉換,即將ts列相關的表達式轉換成pt列相關的表達式。需要注意的是轉換前后的表達式不要求完全等價,但是要求過濾結果存在“包含”的關系,具體又可以分為以下3種場景。
基礎裁剪場景
對于ts列的過濾條件中不包括函數的場景,可以直接做表達式的推導轉換,但是轉換前后的表達式過濾范圍不等價,因而原始表達式需要保留,推導過程如下所示:
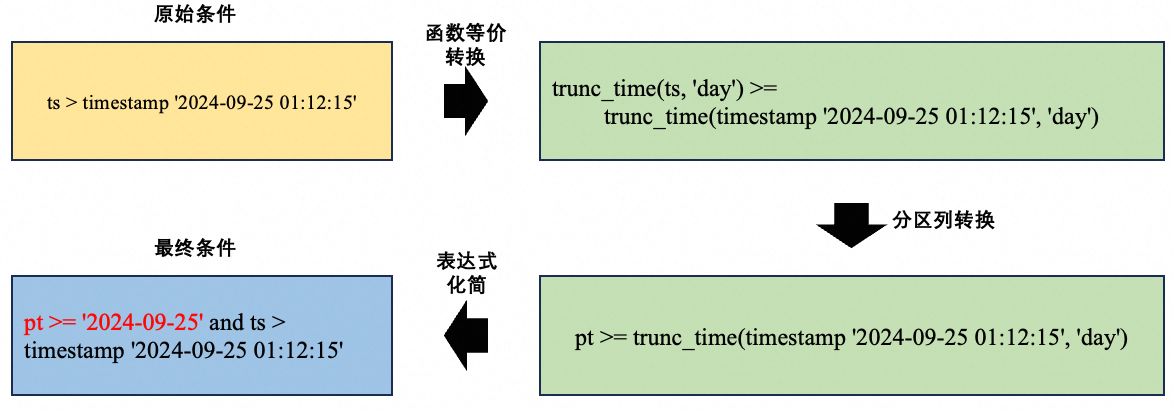
函數非等價轉換場景
對于查詢條件包含時區轉換、日期格式函數等操作時,對于ts列的過濾條件無法直接做表達式的映射轉換,因此我們引入了內置函數理解的能力,將表達式中的函數fold掉。假設有如下查詢:
select * from auto_partition_table
where TODATE(FROM_UTC_TIMESTAMP(ts, 'Asia/Jakarta')) = date '2024-09-14'在分區裁剪過程中,過濾條件會做如下推導:
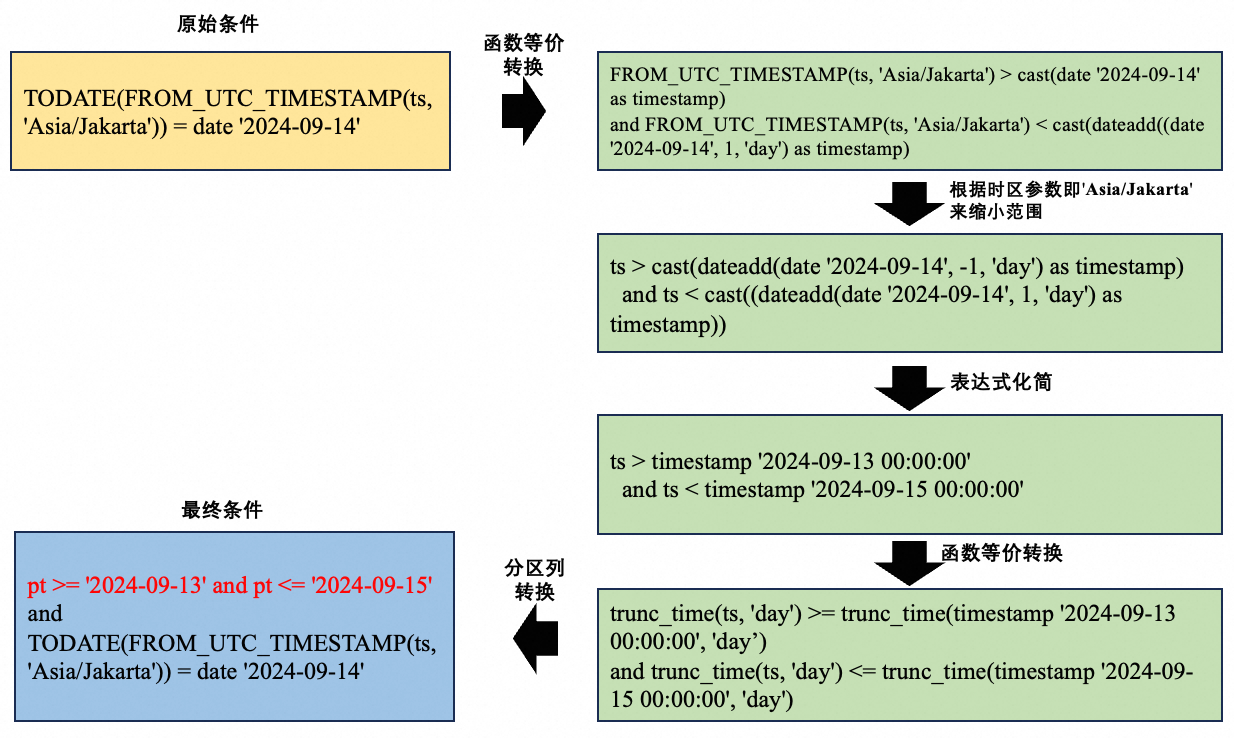
需要注意的是,原始過濾條件的結果是分區裁剪結果的子集,所以推導的過程只能應用在分區裁剪內部,原始的過濾條件會保留。
函數等價轉換場景
如果查詢條件中的函數與分區鍵定義函數語義完全等價,如datetrunc(ts, 'day')與trunc_time(ts, 'day'),那么對于ts列的過濾條件可以做等價轉換,這個過程也依托內置函數理解框架來實現。
select * from auto_partition_table
where datetrunc(ts, 'day') >= timestamp '2024-09-14 10:01:01';上述查詢中datetrunc(ts, 'day') 語義上和trunc_time(ts, 'day')相同,因而可以做如下推導轉換:
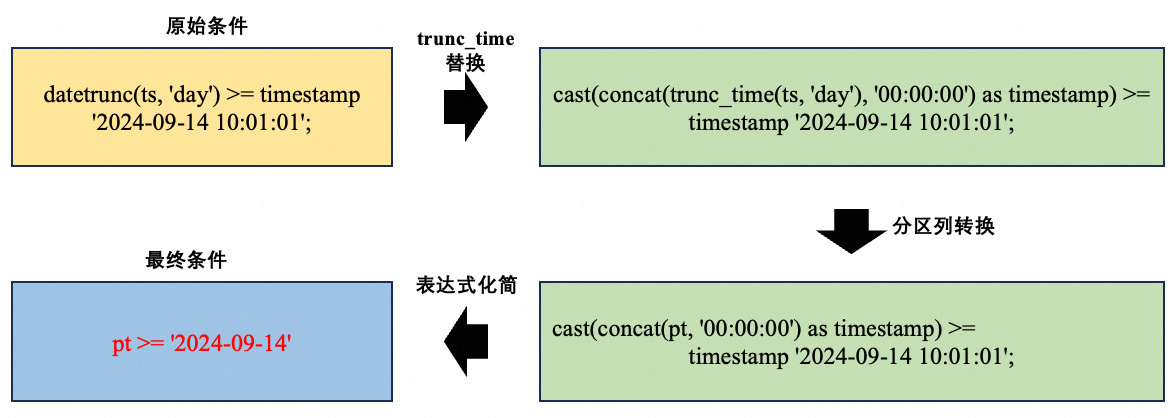
這個過程中的表達式轉換是等價的,因此,分區裁剪完成后,原始的過濾條件不需要再保留。
價值
通過基于表達式推導的動態分區裁剪方案,MaxCompute 在保持分區管理靈活性的同時,實現了與靜態分區表同級的 高性能、低成本的數據處理能力。
復雜類型之unnest優化
痛點
在 Google BigQuery 中,UNNEST 是處理 數組(ARRAY) 類型數據的核心操作,用于將嵌套的數組結構展開為多行平鋪數據,如下所示:
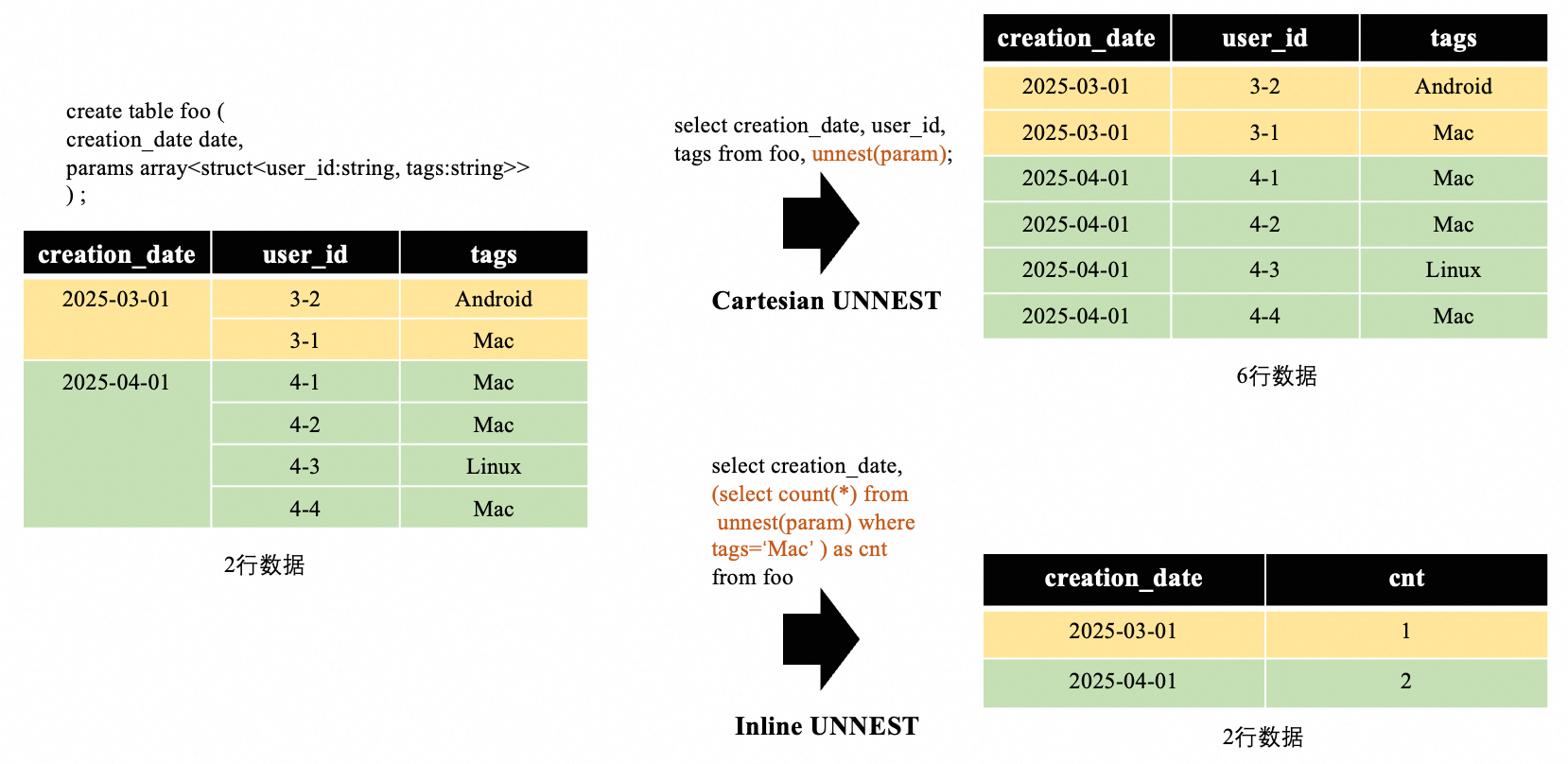
GoTerra的查詢大量使用UNNEST,這些查詢遷移至 MaxCompute 后,需通過 LATERAL VIEW + EXPLODE 或 CROSS JOIN 模擬此功能,導致以下性能問題:
- 執行計劃冗余:單次
UNNEST被拆解為 多次 TableScan 和 Join,資源消耗激增。 - 數據膨脹風險:笛卡爾積引發中間結果爆炸。
- 功能局限:無法高效處理 多層嵌套 ARRAY
以下是一個簡化的case:
create table foo (creation_date date, params array<struct<user_id:string, tags:string>>
) ;select creation_date,
(select count(*) fromunnest(param) where tags=‘Mac’ ) as m_cnt,
(select count(*) fromunnest(param) where tags=‘Linux’ ) as l_cnt
from foo;其執行計劃如下:
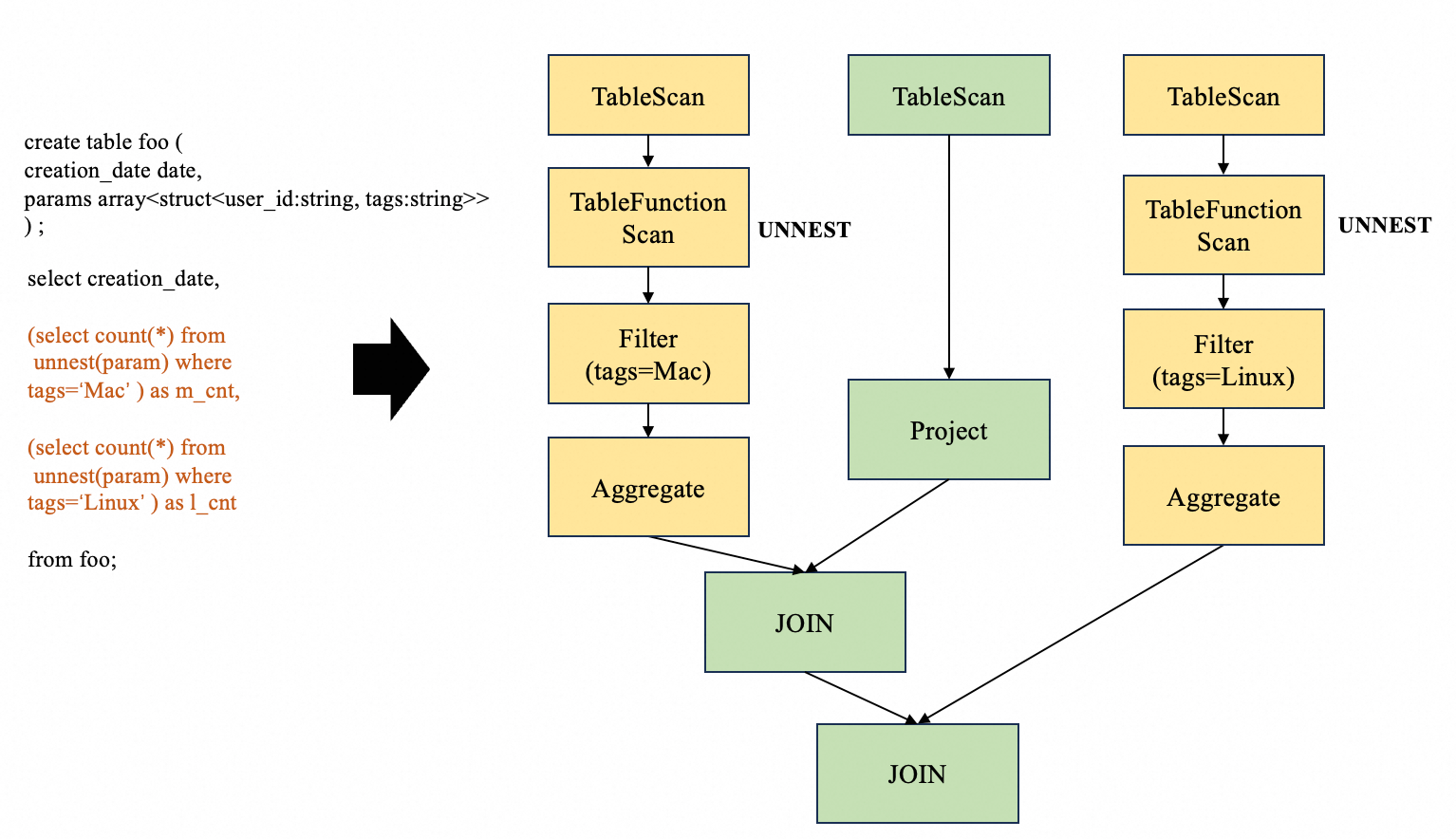
從上圖可以看到,執行計劃有以下問題:
- 對同一個table有3次Scan
- 對同一個column執行了2次同樣的explode操作
- 執行了多次join
方案
針對上述問題,我們重新設計了unnest的支持框架,采用了通用的框架,即支持執行sub plan的apply算子,以便具備通用的subquery執行能力和更強的擴展性。在新的框架下,unnest相關的查詢計劃如下所示:
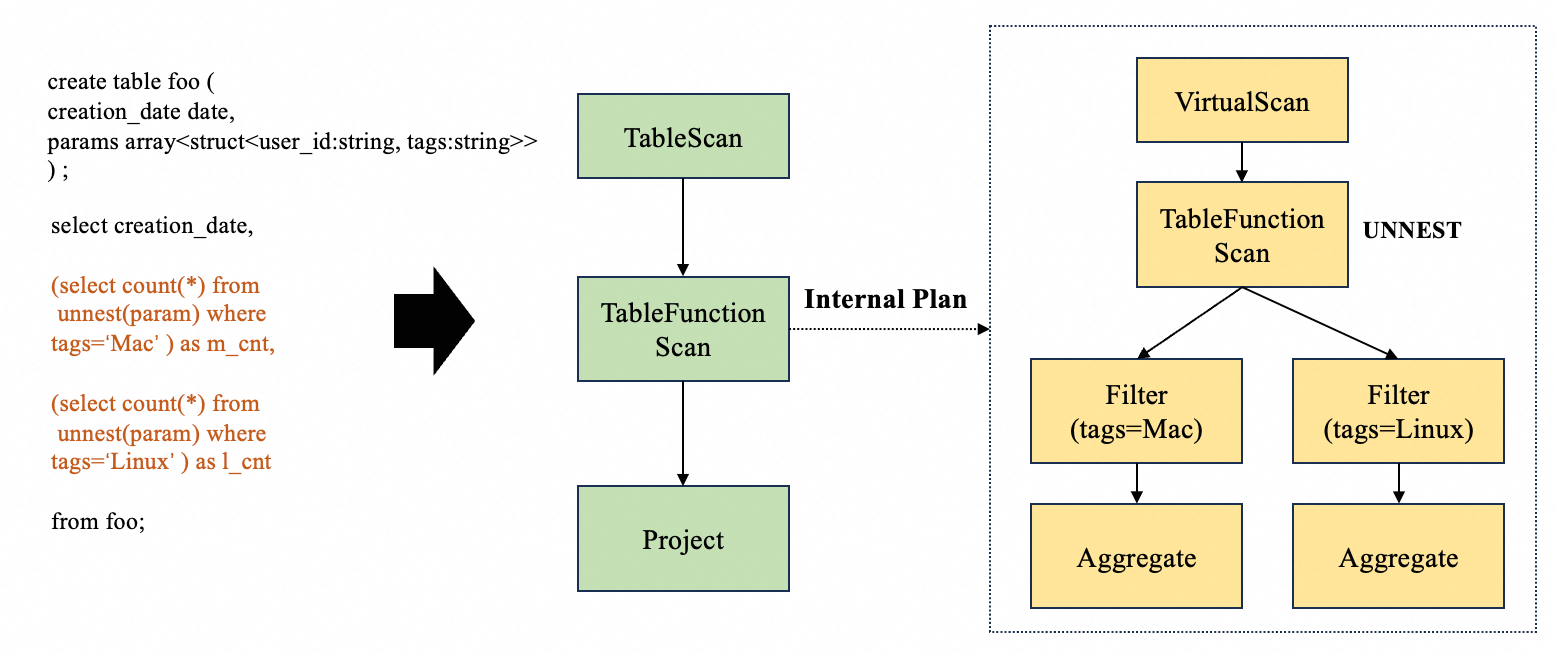
整個優化過程可以概述為下面幾個步驟:
- 引入了Internal plan的概念,Internal plan也是一顆算子樹,代表外層中對每一行數據的內部計算邏輯,編譯器會按照上述要求生成初始的plan。
- 優化器需要做進一步優化,關鍵的步驟包含:
- Internal plan不能影響外部plan的優化,包括下推、列裁剪等。
- 外部plan優化完成后,需要對Internal plan做優化。
- 優化過程中需要對相鄰TableFunctionScan做合并,之后對合并后的Internal plan做SubtreeMerge
- 執行器需要根據外層和內層執行計劃執行。
價值
通過對UNNEST執行框架的重構和升級,MaxCompute 的 Unnest 能力在性能、穩定性上方面都有突破:1)性能提升1-10倍;2)避免了大型嵌套UNNEST場景下導致的OOM錯誤,為復雜數據分析場景打下了堅實的基礎
超大型查詢優化
痛點
GoTerra的查詢中存在大量超大型查詢,這些超大型查詢出來的執行計劃體量遠大于一般大型查詢計劃, 其特征為算子多, 子查詢深度嵌套, 單行類型信息中 單列的 STRUCT 內部列達數千個。

超大型查詢計劃會使得優化器在處理計劃過程中出現大量內存使用, 遍歷圖緩慢等問題。針對超大型查詢計劃, 我們開發了以下技術解決。
方案
圖優化
每一個查詢計劃都是由關系算子組成的有向無環圖, 圖的遍歷方向為從輸出到輸入。
而優化器主要的工作是對圖中的算子模式進行匹配, 并且使用新的算子結構替換圖中舊的算子結構。
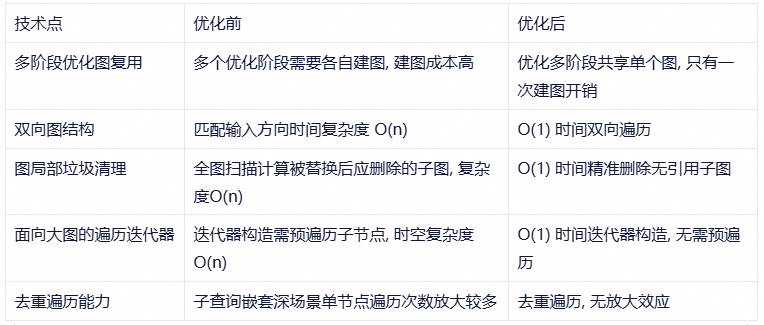
Digest 全局復用
Digest(完整摘要) 表達了關系算子的任意部分的完整信息, 是優化器識別關系算子的關鍵。 每次變換生成新的關系算子, 都需要構造關系算子整體 Digest, 包含類型信息 Digest/標量函數Digest 等。
我們支持了對這三類信息的緩存以及局部復用。 由于實際計劃中存在大量相似信息結構, 在實際優化過程中將相關對象哈希和相等比較計算復雜度, 以及所需內存空間降低了幾個數量級。
以類型信息為例

價值
通過超大規模查詢優化技術,MaxCompute 突破優化器瓶頸,實現 深度嵌套、復雜類型、百萬級算子 執行計劃的高效處理。在典型大型查詢中, 優化耗時從15分鐘+降至1分鐘, 峰值內存從 5GB+ 降低至 1GB。
Intelligent Tuning
痛點
在大數據計算場景下,因為統計信息的缺失、大量存在的UDF優化黑盒、作業復雜度高(如GoTerra的SQL經常有幾千行)等等因素,使得優化器很難做準確的基數估計,產生最優的執行計劃,以及難以事先給定一個理想的各stage資源分配計劃。
這就導致一方面系統miss了大量的優化機會,另一方面用戶對關心的作業往往需要進行手動調優,如調整各stage并發度、添加調優flag等,費時費力門檻高,并且當數據和作業發生變化時,還需要進行相應的調整。
Intelligent Tuning就是要解決這一系統和用戶的痛點,對于計算邏輯基本相似的recurring job,能夠充分利用歷史執行信息,來對未來執行起到指導作用,從而能夠做到系統自動優化,提升作業整體性能。
方案
我們的主要思路是收集作業實際運行的豐富的統計信息,經過實時的feedback或者離線的更加復雜的training和分析后,使得優化器能夠學習到作業的歷史執行狀態,更加聰明地“理解數據、理解作業”,一方面將歷史統計信息注入到CBO框架中產生全局最優的執行計劃,另一方面根據每個stage的計算量、運行速度等,智能地調整并發度,避免worker資源的浪費,以及自動對并發度偏低的stage進行加速。
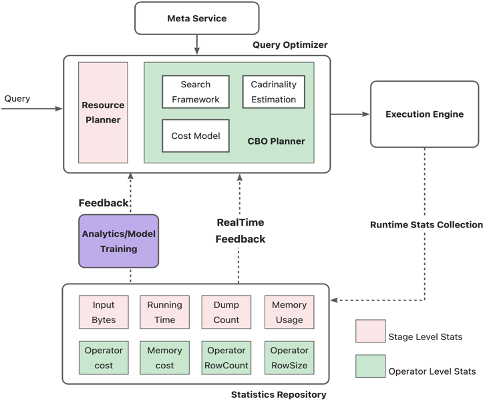
架構圖
下圖列舉了Intelligent Tuning整體的優化能力,包括執行計劃優化、資源分配優化、執行模式選擇優化、以及runtime算子執行優化。Intelligent Tuning具備框架性的優化擴展能力,一方面能夠自動利用CBO框架去讓一些優化規則生效,另一方面也能不斷拓展作業運行方方面面的優化。
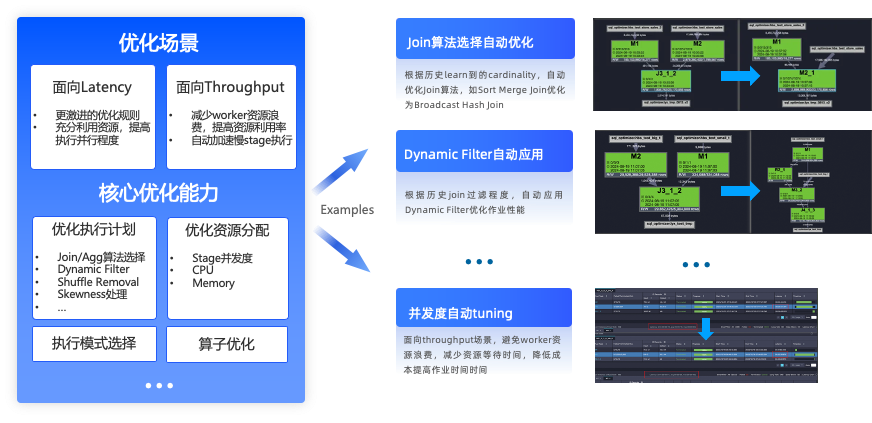
價值
Intelligent Tuning是性能優化的“第二增長曲線”,極大地避免了人工作業調優,同時使得系統自動優化能力大大增強。在GoTerra項目中,應用Intelligent Tuning的資源分配優化后,典型項目能夠節省87%資源,通過更加智能的執行模式選擇,避免online job回退offline job帶來的損耗,典型作業提速45%。Intelligent Tuning的優化能力還在擴展中,將不斷提升引擎的性能和易用性。
總結及未來展望
對MaxCompute而言,GoTerra的遷移不僅是亞太區頭部客戶的標桿實踐,更是一次超大規模負載下的性能極限驗證。在4個月的性能攻堅中,我們通過內核級重構和升級,實現了資源效率與計算性能的范式級突破:
1. 資源效率突破
- 金融ETL場景:CU消耗僅為 BigQuery 的 50%
- BI 分析場景:E2E 端到端查詢耗時相比初始減少 83%,完全滿足業務需求
2. 技術突破
- 新增包括Auto Partition/Unnest/Append2。0等600+功能,語法/性能方面無縫對接BigQuery
- 超大規模計劃優化:支持百萬級算子的執行計劃解析,典型查詢優化耗時從15分鐘+降至1分鐘
- 復雜類型深度優化:支持/完善復雜類型列裁剪/謂詞下推/零拷貝等優化,典型case性能提升20倍
回顧本次GoTerra遷移至MaxCompute的性能優化過程,我們通過分階段、分場景的持續優化,有效提升了BI、ETL等場景下的查詢性能,圓滿完成了遷移目標。面向未來,我們將結合 GoTerra 的業務需求和業界技術發展趨勢,繼續圍繞“更快、更省、更穩”的目標,重點聚焦以下幾個方向:
更快:持續深挖性能潛力,極致性能優化
- 增量更新:持續推進數據的增量更新機制,顯著降低計算資源消耗,加快數據可用速度,提升用戶操作體驗。
- 地理類型原生支持:加強對地理空間數據類型的原生支持,結合空間索引,大幅提升時空數據復雜查詢的執行效率,增強地理類業務的核心競爭力。
- 異構計算融合:探索異構計算(如GPU等)與MaxCompute的深度融合場景,進一步加快關鍵分析任務處理速度。
更省:精細化資源管理與成本優化
- 智能彈性伸縮:開發并完善基于實時負載的彈性資源調度機制,在業務波峰波谷場景下,實現資源的自動擴容和縮減,顯著提升資源利用率,降低用戶成本。
- 按需計費與成本監控:引入更為精細化的多維度資源計量體系和主動式成本告警,幫助用戶按需選型,合理分配預算,避免資源浪費。
更穩:面向未來的高可用性和可觀測性
- 容災與高可用:構建多區域、多活的數據冗余與容錯機制,提升系統面對硬件故障、大規模流量和異常情況時的業務連續性和可靠性。
- 完善可觀測性:加強全鏈路的性能監控、SQL診斷和自動健康檢查能力,實現故障早發現、早定位、快速自愈,保障核心業務穩定運行。
結語
GoTerra 跨國數倉遷移不僅為行業樹立了數據平臺升級與性能優化的技術標桿,也為 MaxCompute 實現世界一流性能奠定了堅實基礎。在整個項目過程中,團隊積累了針對大規模復雜場景的性能優化方法論、自動化工具鏈及通用實戰經驗,為后續跨地域、超大規模數據倉庫系統的遷移提供了成熟范本和可復用經驗。展望未來,MaxCompute 將持續深化性能驅動的技術創新。一方面,聚焦 AI 驅動的智能調優和自動化運維,不斷提升系統的自適應資源調度、性能監控和異常自愈能力,進一步提高開發和運維效率;另一方面,將積極推動數據湖與數倉融合、原生地理類型/非結構化類型和增量計算等新方向,不斷拓展性能優化的邊界。通過持續的技術演進,MaxCompute 將為大規模數據場景下的企業提供更強的性能保障和更高的運維效率,加速業務價值釋放,助力客戶應對未來更為復雜的大數據挑戰。



)

Cursor)




)




 ? | VerifyAccountUi(驗證碼組件))



