本篇文章主要講解 C++ 的入門語法知識引用、inline 關鍵字與 nullptr 關鍵字。
目錄
1? 引用
1) 引用的概念與定義
(1) 引用的概念? ? ? ??
(2) 引用的定義
2) 引用的特性?
3) 引用的使用場景以及作用
(1) 引用傳參提高效率
(2) 改變引用對象同時改變被引用對象
(3) 引用做返回值
4) const 引用
5) 指針與引用的關系與區別
2? inline關鍵字
1) inline 關鍵字的用法
2) 內聯函數的特性
3) 內聯函數聲明與定義分離到兩個文件
(1) 報錯原因
(2) 解決方法
3? nullptr 關鍵字
1? 引用
1) 引用的概念與定義
? ? ? ? 在C語言中,我們寫一個交換函數我們需要使用指針類型作為形參,實現形參的改變影響實參:
#include<stdio.h>void swap(int* x, int* y)
{int tmp = *x;*x = *y;*y = tmp;
}而在C++中,我們可以這樣寫交換函數:
#include<iostream>using namepsace std;void swap(int& x, int& y)
{int tmp = x;x = y;y = tmp;
}且結合上一篇文章我們講解過的函數重載,可以定義出不同的交換函數:
#include<iostream>using namespace std;//交換整型
void swap(int& x, int& y)
{int tmp = x;x = y;y = tmp;
}//交換浮點數
void swap(double& x, double& y)
{double tmp = x;x = y;y = tmp;
}int main()
{int a = 10, b = 20;double c = 1.1, d = 2.2;cout << "交換前:";cout << a << ' ' << b << ' ' << c << ' ' << d << endl;swap(a, b);swap(c, d);cout << "交換后:"; cout << a << ' ' << b << ' ' << c << ' ' << d << endl;return 0;
}運行結果:
輸出:
交換前:10 20 1.1 2.2
交換后:20 10 2.2 1.1其中 int& 就稱之為引用,在這里引用起著類似于指針的作用,接下來我們就來講解引用。
(1) 引用的概念? ? ? ??
????????引用并不是像指針一樣重新定義一個變量,而是為已經存在的變量取一個別名,在語法層編譯器并不會為其開辟一塊空間(但底層依然使用指針),而是讓它和它引用的變量共用一塊空間。比如,西游記中孫悟空也叫做齊天大圣,雖然名字不同,但本質上都是指的同一個人;在C++中,被引用的變量就像孫悟空,引用就像齊天大圣,盡管名字不同,但本質上都是指向同一塊空間。
(2) 引用的定義
? ? ? ? 在上面的交換函數中,我們已經見過引用是如何定義了,以下是定義引用的通用語法:
類型& 引用別名 = 被引用對象;這里的類型可以是內置類型int, double等,也可以是后面STL(數據結構與算法庫)中的自定義類型 vector<int>,string等。
? ? ? ? 引用的語法符號為&,與給變量取地址是一個符號,在初學的時候容易搞混,只需要記住在變量(對象)前面的就是取地址,在類型后面就是引用即可。
#include<iostream>using namespace std;int main()
{int a = 10;//b是a的別名int& b = a;//取別名之后依舊可以取別名int& c = a;//也可給別名取別名int& d = b;//別名++,其他的別名與原名都++,因為都是一塊空間++d;cout << a << ' ' << b << ' ' << c << ' ' << d << endl;//原名++,其余的別名都++++a;cout << a << ' ' << b << ' ' << c << ' ' << d << endl;//取地址都是相同的cout << &a << endl;cout << &b << endl;cout << &c << endl;cout << &d << endl;return 0;
}?運行結果:
輸出:
11 11 11 11
12 12 12 12
0000002A5CEFF724
0000002A5CEFF724
0000002A5CEFF724
0000002A5CEFF7242) 引用的特性?
引用具有以下特性:
(1) 引用在定義時必須初始化
(2) 一個變量可以有多個引用
(3) 引用一旦引用一個實體,無法再引用其他實體
????????其實引用的第一點特性是依賴于第三點特性的,由于引用在引用后無法改變,所以如果在定義時不初始化,后續又無法改變,因而是無法知道引用哪個實體的。
#include<iostream>using namespace std;int main()
{//編譯報錯,引用定義時必須初始化//int& a;int a = 10;int& b = a;cout << "改變前:";cout << a << ' ' << b << endl;int c = 20;//這里并不是改變引用對象,而是將c的值賦給a和bb = c;cout << "改變后:";cout << a << ' ' << b << endl;cout << &a << endl;cout << &b << endl;cout << &c << endl;return 0;
}運行結果:
輸出:
改變前:10 10
改變后:20 20
0000002030CFF974
0000002030CFF974
0000002030CFF9B43) 引用的使用場景以及作用
? ? ? ? 引用的在實踐中主要用于引用傳參或者引用做返回值提高效率,以及改變引用對象的同時改變被引用對象(如上面的swap函數)。
(1) 引用傳參提高效率
? ? ? ? 在C語言中傳參分為兩種,一種是傳值傳參,一種是傳址傳參,傳值傳參會傳遞實參的拷貝,而傳址傳參只會傳遞實參的地址,所以傳址傳參是比傳值傳參效率更高的。引用傳參就類似于傳址傳參(因為引用傳參底層也是傳遞的地址),所以引用傳參也是比傳值傳參效率更高的,但是引用傳參比傳址傳參更加方便,因為傳參的時候不需要再取地址,直接傳遞變量(對象)就可以。以下是傳值傳參,傳址傳參與引用傳參的對比:
#include<string>using namespace std;//傳值傳參,x是a的拷貝
void Func1(int x)
{++x;
}//傳址傳參,x是a的地址
void Func2(int* x)
{++(*x);
}//引用傳參,x是a的別名
void Func3(int& x)
{++x;
}int main()
{int a = 10;//傳值傳參,不改變實參Func1(a);cout << a << endl;//傳址傳參,需要取地址Func2(&a);cout << a << endl;//引用傳參,不需要取地址,更加方便Func3(a);cout << a << endl;return 0;
}?運行結果:
輸出:
10
11
12(2) 改變引用對象同時改變被引用對象
? ? ? ? 在(1)引用提高傳參效率的示例代碼以及上面的 swap 函數中都多次使用了改變引用對象的同時改變被引用對象,所以這里就不再舉例。總之,如果采用引用傳參,在函數中,只要改變形參就可以改變實參。
(3) 引用做返回值
引用做返回值的場景相對復雜,所以我們結合以下的例子來進行講解。
#include<iostream>
#include<assert.h>using namespace std;typedef int STDataType;
typedef struct Stack
{STDataType* arr;int top;int capacity;
}ST;//初始化
//這里引用傳參,改變rs會同時改變main函數中的st
void STInit(ST& rs, int n = 4)
{rs.arr = (STDataType*)malloc(sizeof(STDataType) * n);if (rs.arr == NULL){perror("malloc fail!\n");exit(1);}rs.top = 0;rs.capacity = n;
}//入棧
void STPush(ST& rs, STDataType x)
{//滿了先擴容if (rs.top == rs.capacity){int newCapacity = rs.capacity == 0 ? 4 : rs.capacity * 2;STDataType* tmp = (STDataType*)realloc(rs.arr, sizeof(STDataType) * newCapacity);if (tmp == NULL){perror("realloc fail!\n");exit(1);}rs.arr = tmp;rs.capacity = newCapacity;}rs.arr[rs.top++] = x;
}//取棧頂元素 -- 版本1
int STTop1(ST& rs)
{assert(rs.top > 0);int top = rs.arr[rs.top - 1];return top;
}//取棧頂元素 -- 版本2
int& STTop2(ST& rs)
{assert(rs.top > 0);return rs.arr[rs.top - 1];
}int main()
{ST st;//這里也不需要傳地址了,因為是引用傳參STInit(st);STPush(st, 1);STPush(st, 2);STPush(st, 3);STPush(st, 4);cout << STTop1(st) << endl;cout << STTop2(st) << endl;STTop2(st) = 5;cout << STTop1(st) << endl;return 0;
}? ? ? ? 上述代碼實現了棧的一部分功能,包括初始化,入棧以及返回棧頂元。可以看到 STTop 實現了兩個版本,一個是 int 作為返回值的版本,一個是 int& 作為返回值的版本,接下來我們來講解這兩個版本的 STTop 的區別。
STTop1:
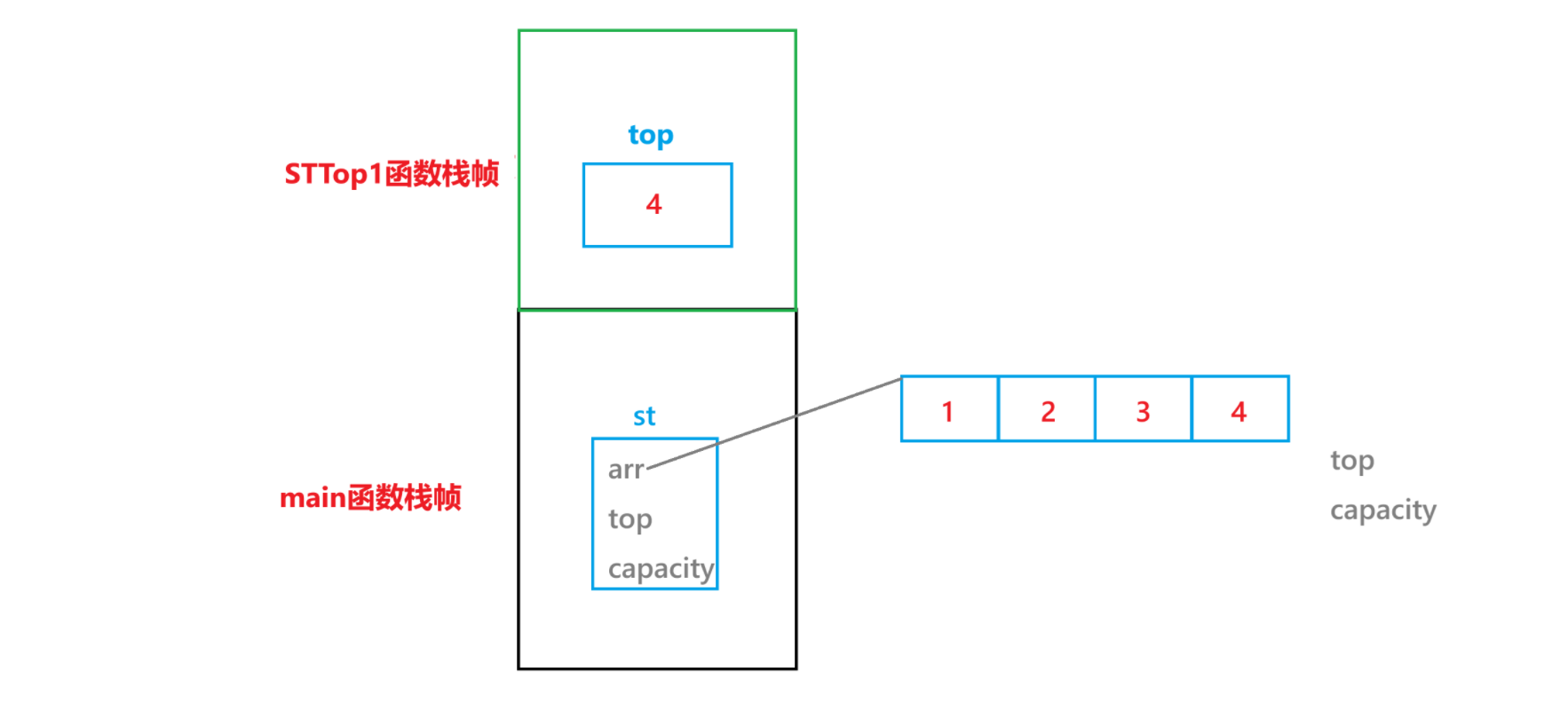
上圖中標識了 main 函數的函數棧幀中各變量以及 STTop 函數的函數棧幀中各變量在內存中的存儲情況。main函數中有一個 st 的結構體變量,結構體中有三個變量,分別是 arr,top,以及capacity,都存儲在 main 函數的棧幀里面,arr 指向了堆上的一塊空間,里面存儲了1,2,3,4 四個數據;在 STTop1的函數棧幀中存在一個 top 變量,該變量是 arr 數組中 st.top - 1 位置的拷貝,當STTop1 函數調用結束之后,函數棧幀被銷毀,top 也就隨之被銷毀了,所以返回的其實是 top 的拷貝。
? ? ? ? 經過上述分析,其實 STTop1 是不能用引用做為返回值的,因為如果用引用做返回值的話,返回的其實是 top 的那一塊空間的引用,但是 top 的存儲空間會隨著?STTop1 函數棧幀的銷毀而銷毀,所以返回 top 空間的引用其實是野引用,訪問的話會造成非法訪問的,所以不能引用返回。
STTop2:
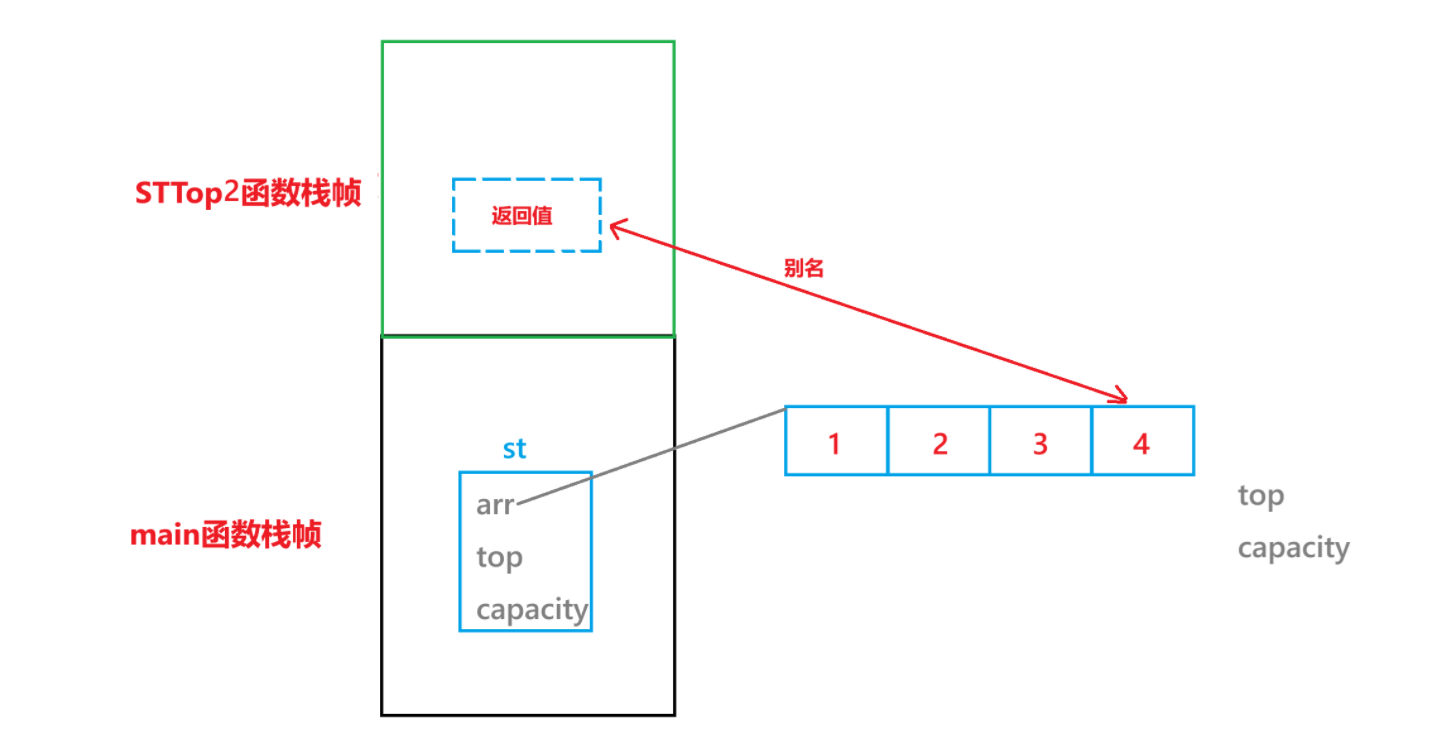
在 STTop2 函數棧幀中返回值是?rs.arr[rs.top - 1],而 rs 是 st 的別名,所以返回的其實是 st.arr[st.top - 1] 的引用,而 st.arr[st.top - 1] 的空間在 STTop2 函數的函數棧幀銷毀后,st.arr[st.top - 1] 的空間是沒有銷毀的,所以是可以返回引用的,而且由于返回的是其引用,所以改變其返回值,原空間中的值也會進而發生改變。
示例代碼的運行結果:
輸出:
4
4
5? ? ? ? 總結來說,就是如果當前函數棧幀銷毀后,返回值的空間沒有被銷毀,那就可以引用返回;如何當前函數棧幀銷毀后,返回值的空間被銷毀,那就不能引用返回,只能傳值返回。而且引用返回還有一個好處,就是改變返回值,原值也會發生改變。
4) const 引用
? ? ? ? 如果要引用一個對象,需要注意權限的放大與縮小問題,如果要引用一個 const 對象的話,如果使用普通引用,就涉及到了權限的放大問題,因為被引用的對象是 const 對象,是無法被改變的,具有常性,而如果使用普通引用,普通引用是可以改變被引用對象的值的,所以使用 const 引用引用普通對象就涉及到了權限放大問題(原對象不能改變,而引用對象可以改變),所以必須使用 const 引用。
#include<iostream>using namespace std;int main()
{const int a = 10;//這里不能使用普通引用,因為權限會放大//int& ra = a;//必須使用 const 引用const int& ra = a;//const引用不可改變//編譯報錯++ra;return 0;
}但是引用對象的權限是可以縮小的,所以一個普通對象是可以使用 const 引用的。
#include<iostream>using namespace std;int main()
{int a = 10;//可以使用 const 引用普通對象,權限的縮小const int& ra = a;//const 引用普通對象,同樣不可以改變//編譯報錯++ra;return 0;
}還有一種情況涉及到權限的放大與縮小的問題:
#include<iostream>using namespace std;int main()
{int a = 10;//算數表達式的結果會存放在臨時對象里面//臨時對象具有常性,普通引用會權限放大//編譯報錯int& ra = a * 3;int b = 20;//類型轉換的結果也會存放在臨時對象里面double& rd = a;//字面量也具有常性,所以也會權限放大int& ri = 10;return 0;
}當引用的對象具有常性時,如:臨時對象(類型轉換與運算表達式的值都會存放在臨時對象里面)、匿名對象(后面會講解)與字面量都具有常性,引用這些對象的時候需要使用 const 引用。?
5) 指針與引用的關系與區別
? ? ? ? 通過上述對引用的講解,可以發現其實引用與指針有許多功能是重疊,但是指針與引用在實踐中是相輔相成,但又互相不可替代的。
指針與引用的區別:
(1) 引用在定義時必須初始化;雖然指針在定義時不必初始化,但是建議初始化
(2) 引用在語法層不開空間;但是指針是一個變量,要開空間
(3) 引用在引用一個對象后,不可更改引用的對象;但是指針在定義之后,可以更改指向的對象
(4) 引用可以直接訪問對象,而指針需要解引用才能訪問對象
(5) sizeof 中含義不同,sizeof 引用是引用對象的大小,而 sizeof 指針始終是 4 或者 8 個字節
? ? ? ? 總結來說,雖然 C++ 引入了引用的新語法,但是引用是沒法完全代替指針的,有些指針所能達到的效果是引用所達不到的,比如在結構體訪問內部成員變量的時候,指針可以用 "->" 訪問但是引用只能用 "." 訪問,是不能同 "->" 訪問的;同時引用的存在,在某些情況下又可以大大簡化使用場景(如上面的swap函數),引用做返回值也是指針所達不到的。所以,指針與引用是相輔相成,互相不可替代的。
2? inline關鍵字
? ? ? ? 在C語言中,我們學習過宏的概念,宏類似于函數,但是在使用宏的部分會直接替換,而不是去調用函數,比如定義一個乘法宏:
#include<iostream>using namespace std;#define MUL(X, Y) X * Yint main()
{int c = MUL(2, 4);cout << c << endl;return 0;
}運行結果:
輸出:
8但是寫這樣一個宏是有問題的,比如運行下面這個代碼:
#include<iostream>using namespace std;#define MUL(X, Y) X * Yint main()
{int c = MUL(2 + 4, 4 + 8);cout << c << endl;return 0;
}運行結果:
輸出:
26很明顯,我們想要輸出的是72,但是輸出的卻是26,原因就是在預處理階段代碼被替換為了下面這段代碼:
int main()
{int c = 2 + 4 * 4 + 8;cout << c << endl;return 0;
}所以正確的乘法宏應該在參數和外面都加上括號:
#include<iostream>using namespace std;#define MUL(X, Y) ((X) * (Y))int main()
{int c = MUL(2 + 4, 4 + 8);cout << c << endl;return 0;
}運行結果:
輸出:
72? ? ? ? 那么為什么不寫成一個函數呢?是因為寫為宏效率更高,寫為宏在預處理階段就直接替換了,在編譯階段就會將其變為指令,變為匯編;而函數還需要經歷調用,開辟函數棧幀等一系列的過程,開銷跟宏比起來大了很多;但是宏只適合于實現一些較為簡單的功能,比如加法、減法、乘法等,而且特別容易寫錯,所以C++就綜合了函數與宏的優點,將其合并為了 inline 關鍵字 -- 內聯函數。
1) inline 關鍵字的用法
? ? ? ? inline 關鍵字的用法很簡單,只要在函數定義的前面加?inline 關鍵字就可以了。如定義一個加法的內聯函數:
#include<iostream>using namespace std;inline int Add(int x, int y)
{return x + y;
}int main()
{int x, y;cin >> x >> y;cout << Add(x, y) << endl;return 0;
}運行結果:
輸入:2 10
輸出:12那么內聯函數有沒有直接展開呢?我們可以切換到反匯編看一下。
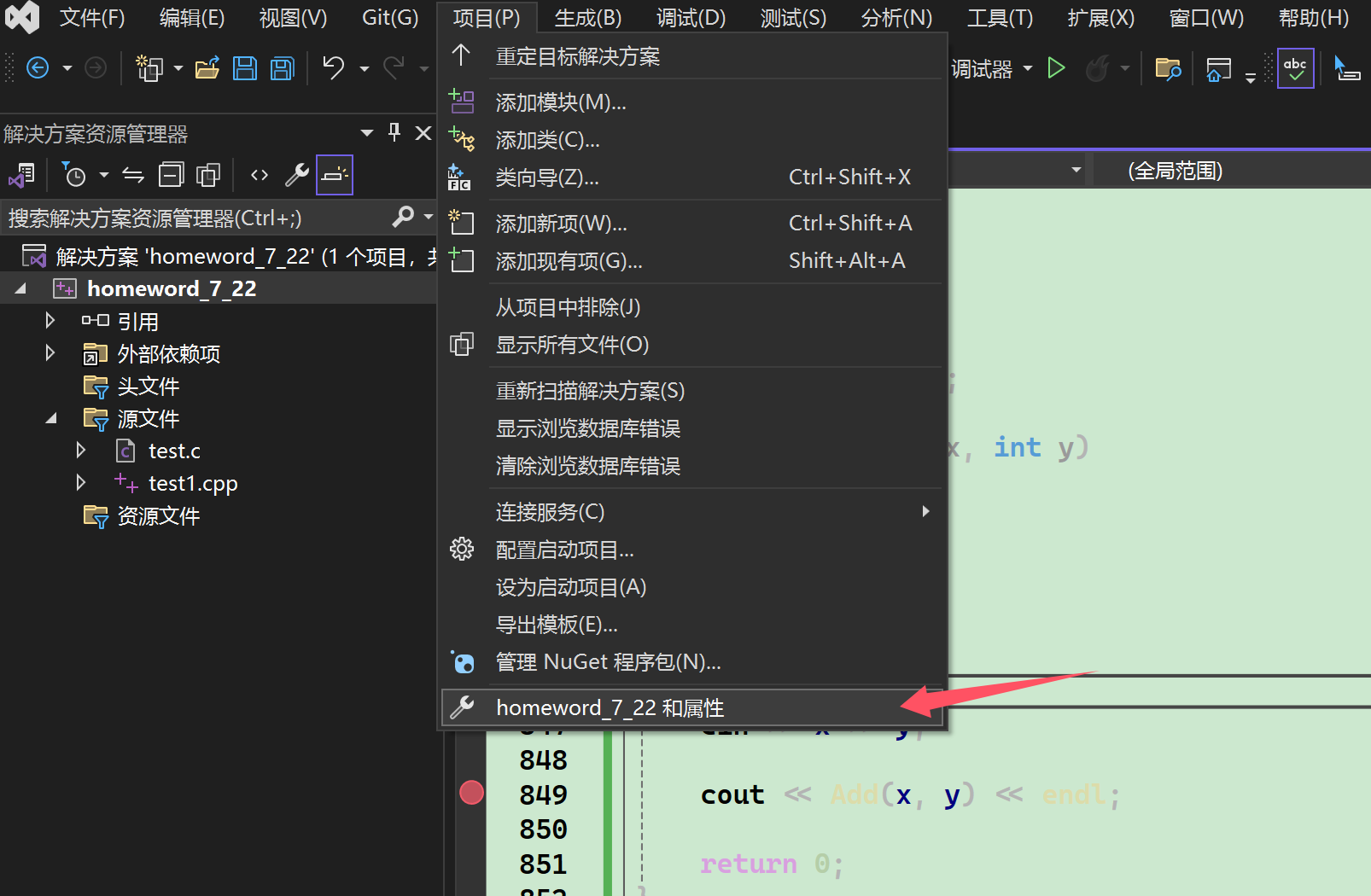
vs的 debug 下默認是不展開內聯函數的,需要設置一下才能看到內聯函數的展開:
第一步:先點擊 vs 界面窗口中的項目選項卡,選擇屬性選項
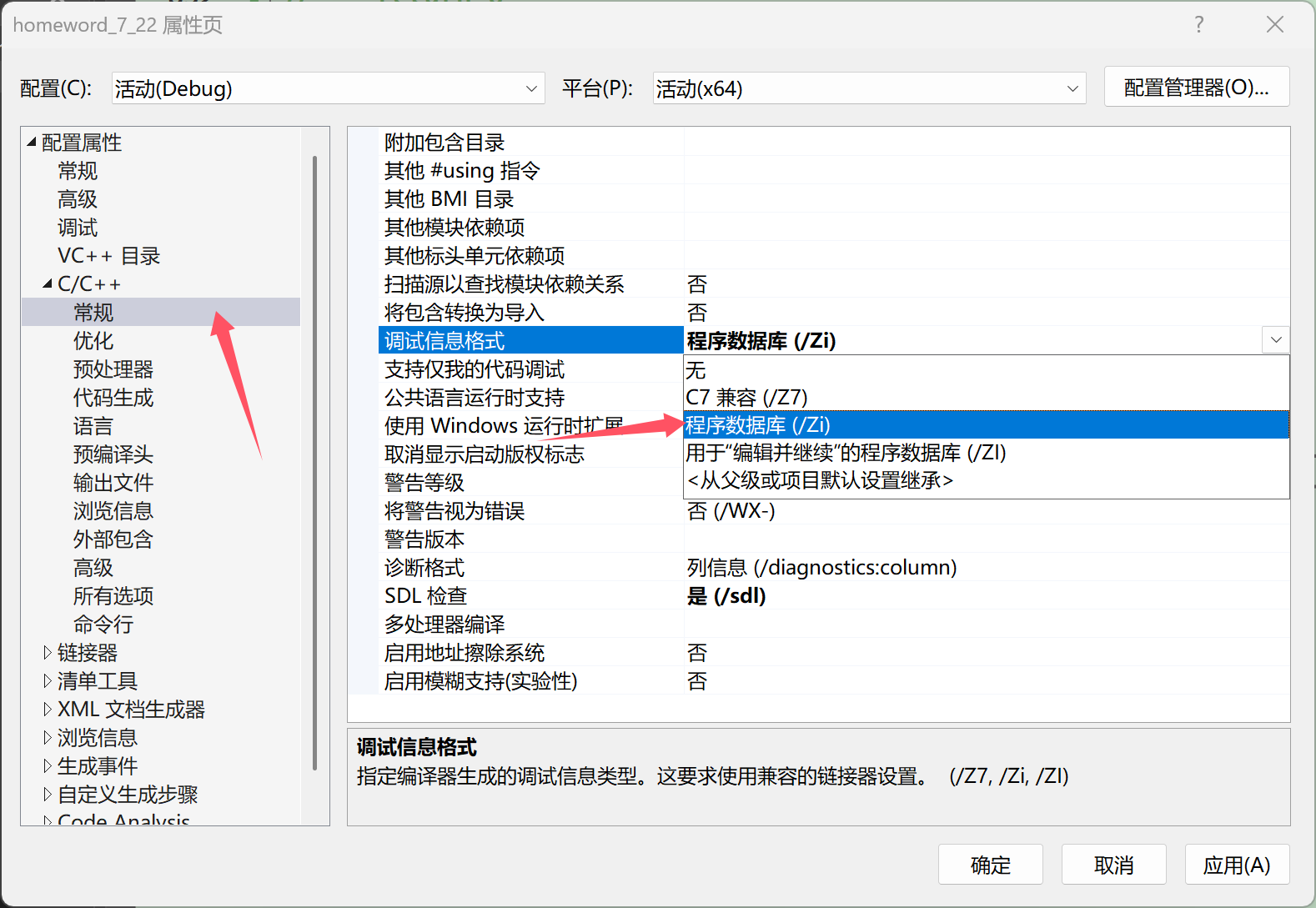
第二步:點擊常規選項,將調試信息格式改為程序數據庫
?第三步:再點擊優化選項,將內聯函數擴展改為只適用于 _inline(/Ob1)
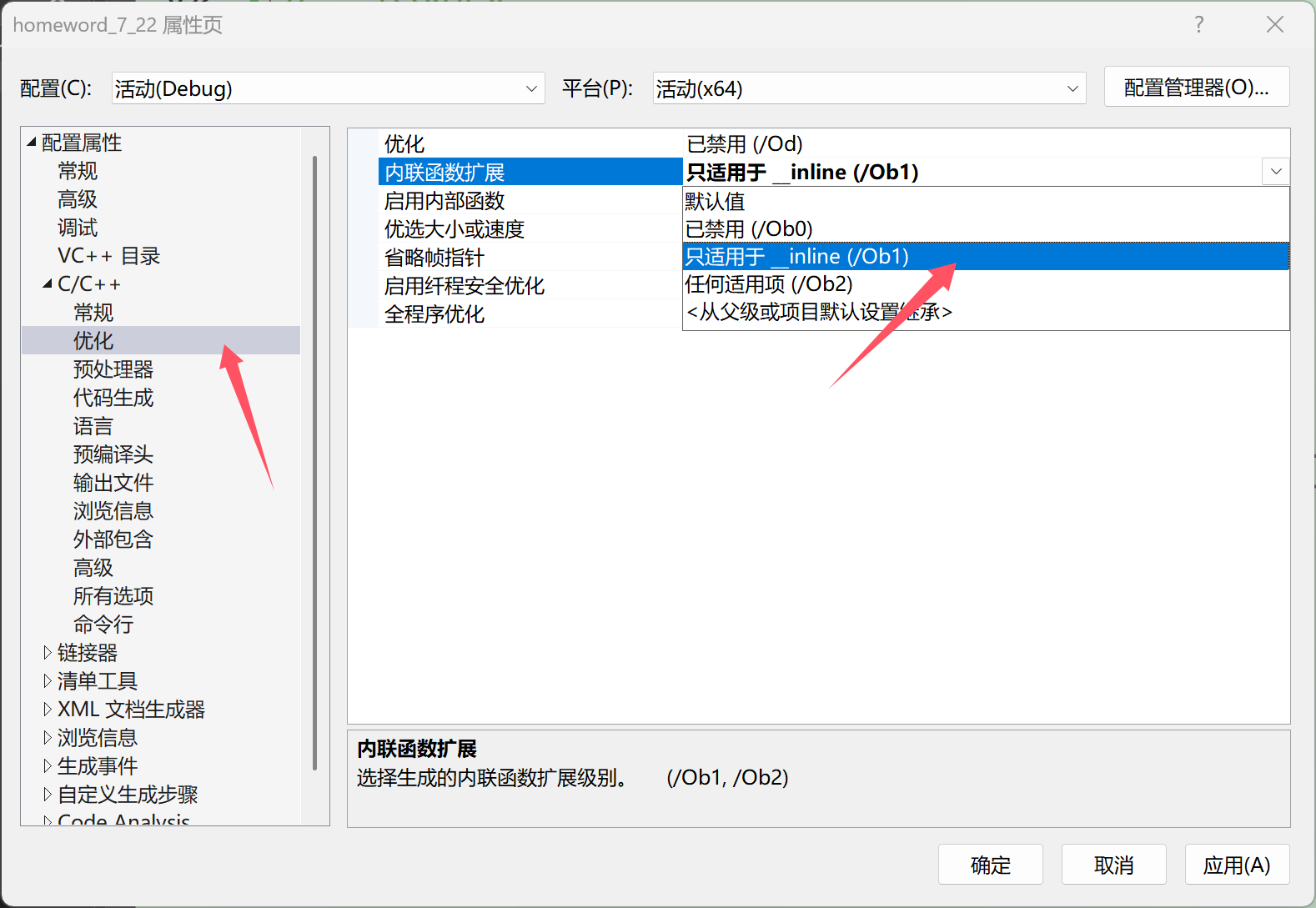
經過上述三個步驟,就可以在調試的反匯編界面看到內聯函數的展開過程了。?
沒有加 inline 關鍵字:
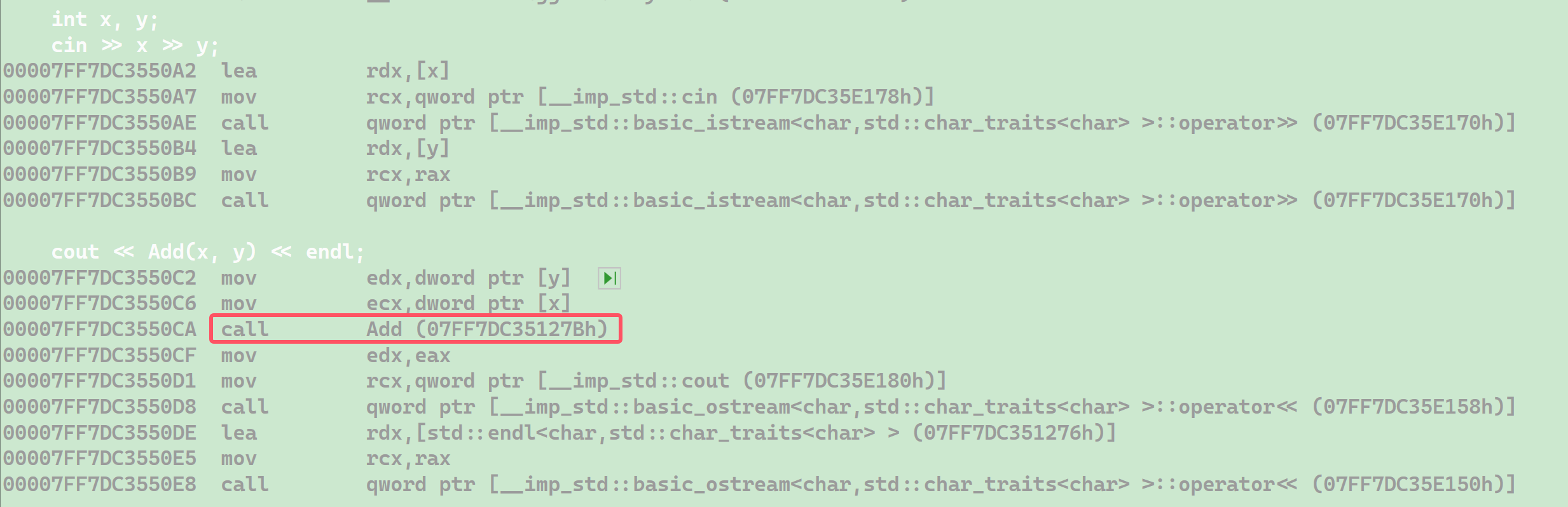
可以看到沒有加 inline 關鍵字是調用了 Add 函數的,調用 Add 函數需要經歷開辟函數棧幀,初始化等一系列過程,開銷較大。再看加了 inline 關鍵字:
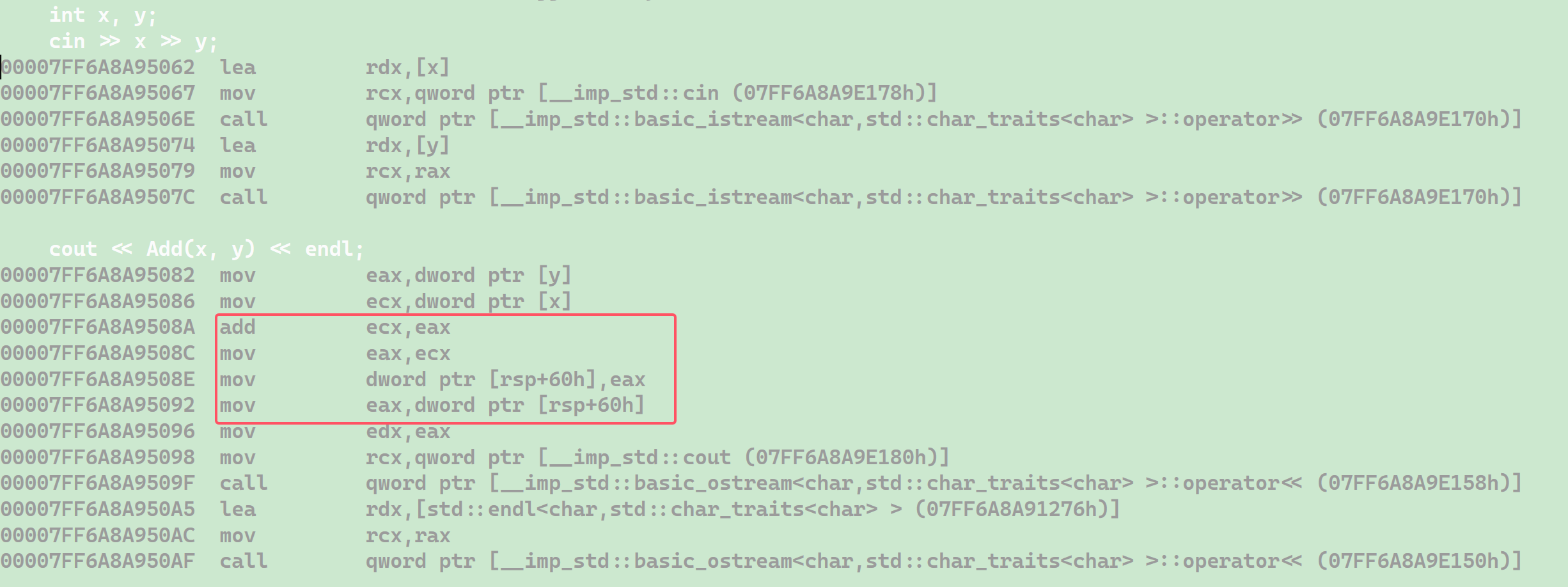
可以看到匯編代碼中沒有調用 Add 函數了,而是替換為了 add,mov 等一系列的指令,也就沒有開辟函數棧幀等一系列的過程了,開銷是比直接調用小的多的。
2) 內聯函數的特性
? ? ? ? 是不是所有的函數前面加上 inline 都會展開呢?并不是的,內聯函數展不展開是取決于編譯器的,當函數里的代碼相對多一些、遞歸函數或者調用頻繁的短小函數,編譯器是不會選擇展開函數的,因為如果每次調用都展開這個函數,是沒有直接開辟函數棧幀的開銷小的。比如一個函數其代碼為 5 行,然后調用開辟函數棧幀等代碼變為了 15 行。假設調用 100 次這個函數,如果展開代碼會變為 500 行,但是調用僅僅需要 115 行(因為需要 call,所以會多 100 行),可以看到調用是比直接展開代碼量少了 4/5 的,所以直接調用的開銷更小。
#include<iostream>using namespace std;void Func1()
{int x = 0;x = 1;x = 2;x = 3;x = 4;x = 5;x = 6;x = 7;x = 8;x = 9;x = 10;x = 11;
}inline int Fact(int n)
{if (n == 0) return 1;return n * Fact(n - 1);
}int main()
{//代碼量過多,不展開Func1();//遞歸函數不展開Fact(5);return 0;
}反匯編代碼:
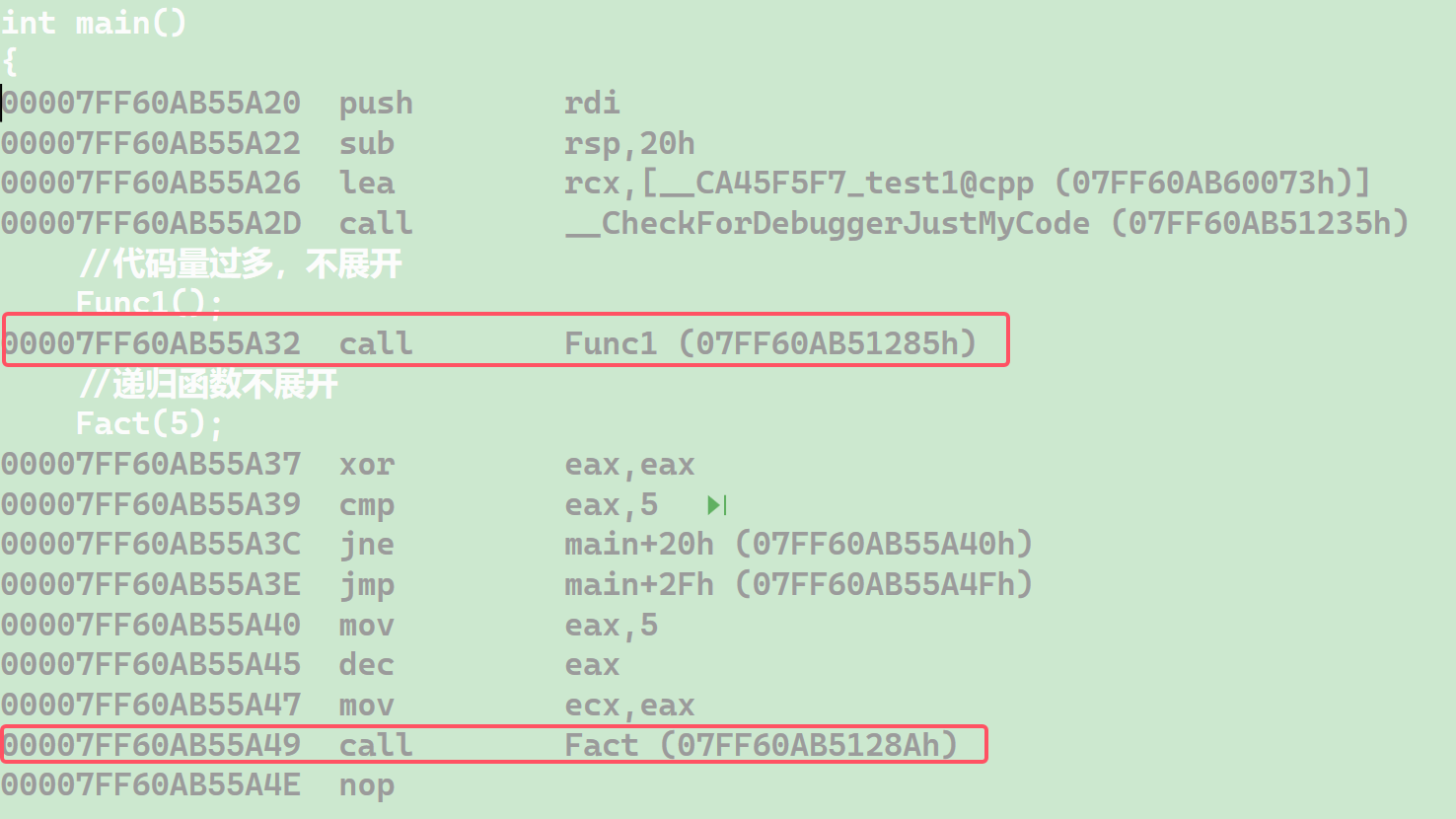
? ? ? ? inline 關鍵字結合了宏和函數的優點,當代碼量很小時,會直接展開函數,提高效率,而當代碼量很大或者遞歸函數時,編譯器會識別這種情況,選擇不展開函數。所以展不展開函數全部由編譯器所決定,程序員只管在前面加上 inline 關鍵字,展不展開全權交給編譯器就可以了(但還是建議能不加的地方就不加,不要一股腦在所有的函數前面都加上inline)。
3) 內聯函數聲明與定義分離到兩個文件
(1) 報錯原因
????????如果用 inline 關鍵字定義一個函數的話,是不能將函數聲明和定義分離到兩個文件的,分離會導致鏈接錯誤。以下是分離到兩個文件的示例:
//F.h
#include<iostream>using namespace std;inline void f(int x);//F.cpp
#include"F.h"void f(int x)
{cout << x << endl;
}//test.cpp
#include"F.h"int main()
{f(10);return 0;
}如果將 f 內聯函數的聲明與定義分離在 F.h 和 F.cpp 文件,是會發生鏈接錯誤的:
 ? ? ? ? ?原因就是因為在預處理階段會將包含的頭文件展開,在編譯階段會將調用了但是不在本文件中的函數生成一個無效地址放進符號表,在鏈接階段會將所有文件合并,用定義了該函數的其他文件中的有效地址來替換這個無效地址,進而可以達到調用其他文件的函數的效果。但是內聯函數與其他函數不同的是,在編譯階段會將該函數展開,也就沒有該函數的有效地址,無效地址無法替換,就會發生鏈接錯誤(如果無法理解的話,可以去回顧之前講解的編譯與鏈接文章)。
? ? ? ? ?原因就是因為在預處理階段會將包含的頭文件展開,在編譯階段會將調用了但是不在本文件中的函數生成一個無效地址放進符號表,在鏈接階段會將所有文件合并,用定義了該函數的其他文件中的有效地址來替換這個無效地址,進而可以達到調用其他文件的函數的效果。但是內聯函數與其他函數不同的是,在編譯階段會將該函數展開,也就沒有該函數的有效地址,無效地址無法替換,就會發生鏈接錯誤(如果無法理解的話,可以去回顧之前講解的編譯與鏈接文章)。
(2) 解決方法
? ? ? ? 只要將內聯函數的定義放在頭文件就可以解決了:
//F.h
#include<iostream>using namespace std;inline void f(int x)
{cout << x << endl;
}//test.cpp
#include "F.h"int main()
{f(10);return 0;
}? ? ? ? 能夠解決問題的原因就是在 main 函數中調用 f 函數,由于 f 函數是內聯函數,在編譯階段會直接替換,而內聯函數直接定義在了 F.h 頭文件中,這樣編譯器在編譯階段就能夠直接看到內聯函數的定義,從而在編譯階段編譯器就能夠正確的進行調用函數代碼的替換,所以就不會發生鏈接錯誤了。
3? nullptr 關鍵字
? ? ? ? C++ 11(2011年推出的C++標準)中引入了nullptr來替代原C語言中的NULL,原因就是之前C語言中的 NULL 在C++中使用會存在一些問題。以下是 NULL 的定義:
//如果沒有定義過NULL
#ifndef NULL//如果定義過__cplusplus,代表在C++文件中#ifdef __cplusplus//NULL被定義為0#define NULL 0#else//在C語言中被定義為空指針的0#define NULL ((void*)0)#endif
#endif?可以看到在C++ 中NULL被定義為了0,所以在下列代碼中會調用錯誤:
#include<iostream>using namespace std;void Func(int x)
{cout << "Func(int x)" << endl;
}void Func(int* x)
{cout << "Func(int* x)" << endl;
}int main()
{Func(NULL);return 0;
}
運行結果:
輸出:Func(int x)? ? ? ? 本來是想要使用 NULL 來調用void Func(int* x) 函數,但是由于 NULL 被定義為了0,所以調用了void Func(int x) 函數。C++為了解決這種問題,重新定義了一個關鍵字 nullptr,nullptr是一個字面量,可以隱式的轉換成其他的指針類型,但是不能轉換成整型。所以使用 nullptr 會調用正確:
#include<iostream>using namespace std;void Func(int x)
{cout << "Func(int x)" << endl;
}void Func(int* x)
{cout << "Func(int* x)" << endl;
}int main()
{Func(nullptr);return 0;
}運行結果:
輸出:Func(int* x)總之,以后在C++中空指針就不要使用 NULL 了,建議使用 nullptr。



















筆記)