目錄
變量
變量類型
動態類型
注釋????????
輸出輸入
運算符
算術運算符
關系運算符
邏輯運算符
賦值運算符
條件語句
循環語句
函數
函數作用域
函數嵌套調用
函數默認參數
關鍵字參數
列表
切片
列表遍歷
新增元素
查找元素
刪除元素
列表拼接
元組
字典
增刪改查
遍歷
合法的key
文件操作
打開和關閉
讀寫操作
文件管理器
查找文件
第三方庫
二維碼
execl
程序猿鼓勵師
變量
? ? ? ? 與C++不同的是,python定義變量時不用自己寫變量類型,編譯器根據=后面的值推導后賦予變量類型,且語句結束不用加分號;
a = 0變量類型
? ? ? ? 整數:int,由于C++的int類型有范圍,值超過限定范圍會溢出,所有需要?long long 長整形來控制值;而python整數類型只有int:每次值變大都會開辟新空間儲存(自動擴容)
a = 10? ? ? ? 浮點數:float,C++中有單精度浮點數float 與雙精度浮點數double,在python中float就代表雙精度浮點數,并沒有double
a = 3.14? ? ? ? 字符串:str,使用單引號‘’或者雙引號“”都可以;在字符串中如果里面字符串有包含“”,外面就用‘’進行區分;如果兩種都用就用三引號‘’‘’‘’進行區分
a = ' My name is "zzj" '
b = ''' My 'name' is "zzj" '''? ? ? ? 可以使用 + 將字符串進行拼接,使用 len()函數計算字符串長度
c = a + b
print(len(c))? ? ? ? 布爾類型:bool,使用True或者False表示真假,首字母大寫
動態類型
? ? ? ? 一個變量被定義出來有了類型后,后序可以根據賦值數據把它變成其它類型

? ? ? ? 有了它就能很靈活的根據需要轉換變量類型進行使用;但這也帶來問題:讀者在閱讀代碼時就會很疑惑:到底這行的變量類型是什么呢?所以實際開發還是要慎用
注釋????????
? ? ? ? python的注釋有兩種:#開頭的注釋和開頭結尾使用三引號(單雙都可以)的注釋;注釋內容就不要精簡,也不要太長:把代碼的功能或者注意點說清楚即可;關于注釋語言一般都是中文,實際安裝公司規定來
#這是注釋"""
這是文檔字符串,也是注釋
"""輸出輸入
? ? ? ? 輸出使用函數print 打印如何類型的變量;但如果是混合:字符串與變量的打印,就不能進行拼接,需要使用在前加f進行former-string
a = 10
print(f"a={a}")? ? ? ? 輸入使用函數input 進行獲取用戶輸入的數據
a = input('輸入數據: ')
print(a)
print(type(a))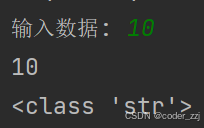
? ? ? ? 雖然輸入的是int 類型,但用變量進行獲取后類型變成str;如果對數據用要求用什么類型就要進行轉化
a = int(a)![]()
運算符
算術運算符
? ? ? ? 在python中有 + - * / % ** // 七種算術運算符,**算的是幾次方;// 除完后進行向下取整;運算順序:先** //,再 * /,最后+ -,需要改變順序就加括號()
print(3 // ( 2 * 10))![]()
? ? ? ? ?如果使用 / 運算結果類型是浮點數float,結果是整數也是一樣;使用 / 不能除0操作,否則會拋異常
print(2 / 2)
print(2 / 0)
print("result finish")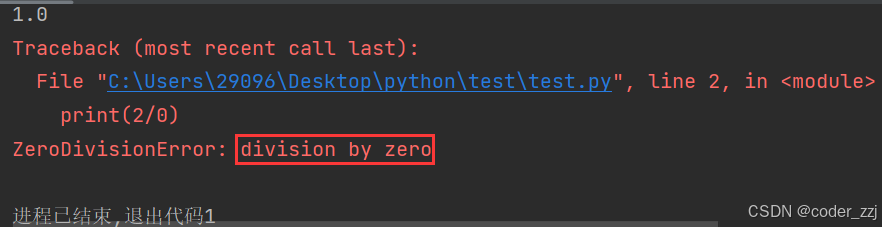
關系運算符
? ? ? ? 關系運算符有:<? =? >? <=? >=? != 五種關系運算符;用來進行值之間,變量之間的比較;為真返回True,假返回為False;如果是字符比較則是比較它們的字典序,越靠后字典序越小;如果是字符串str,就從第一個開始比較,第一個比較不出來就往后找...使用== 則是比較字符串之間是否相等;而在C語言中字符串比較需要用到strcmp函數來實現,它的==比較的是字符串的首元素地址是否相等,不符合預期
a = 5
b = 10
print(a < b)
print("abc" == "abc")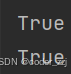
? ? ? ? 注意:如果是浮點數進行運算后進行比較,得出來的結果可能不符合預期
a = 0.1
b = 0.2
print(a + b == 0.3)![]()
? ? ? ? 原因是因為浮點數在儲存規則不同,導致計算結果有誤差
a = 0.1
b = 0.2
print(a + b)![]()
? ? ? ? 我們要這樣來使用,在合理的誤差我們忽略不計
a = 0.1
b = 0.2
c = 0.3
print(-0.000001 < (a + b - 0.3) < 0.000001)![]()
邏輯運算符
? ? ? ? 共有三種:and表示邏輯與操作(一假則假),or表示邏輯或操作(一真則真),not表示邏輯取反操作(真為假,假為真);如果使用and左邊表達式為假后面的表達式就不執行了,這稱為短路求值
a = 10
b = 5
print(a < b and a / 0)![]()
? ? ? ? 第一個表達式換成結果為真則就出現除0錯誤
print(a > b and a / 0)
賦值運算符
? ? ? ? 賦值運算符=,左邊為變量,右邊為常量,把常量的值賦給變量;而==是判斷左右表達式是否相等,在判斷時不要寫錯;除此之外,還有鏈式賦值:同一行進行多個變量的賦值
a = b = 10
print(f"a={a} b={b}")
? ? ? ? 還有逗號賦值,能夠用來解決兩個變量的交換
a = 10
b = 20
a, b = b, a
print(f"a={a} b={b}")?
? ? ? ? 除此之外,還有+= -= *= /= %=等復合賦值運算符,但不支持前置后置++(--);前置++可以運行但變量沒有變化
a = 10
a += 1
print(a)
++a
print(a)

????????后置++編譯就報錯
a = 10
a++
print(a)
條件語句
? ? ? ? if語句格式
if 表達式:語句? ? ? ? 案例?
#牛馬判斷器
val = input("輸入一個值:")
if(val == '1'):print("你是牛")
elif(val == '2'):print("你是馬")
else:print("你是牛馬")? ? ? ? 注意這里的val獲取到的是一個字符串str,不能使用1進行比較而是字符‘1’
? ? ? ? 判斷語句還可以繼續多層嵌套
val1 = input("輸入一個值:")
val2 = input("再次輸入一個值:")
if(val1 == '1'):if(val2 == '2'):print("馬")print("牛")
print("牛馬")
? ? ? ? 使用判斷語句判斷輸入的數是奇數還是偶數時,要進行類型轉化不然str類型無法進行計算
val = int(input("輸入一個值:"))
if(val % 2 == '0'):print("偶數")
else:print("奇數")? ? ? ? 在python這里負數模2是1或者0,而在C++中負數%2是-1或0;另外如果用戶輸入的是字符串在轉化時python直接報錯

? ? ? ? 如果在條件中沒有什么語句要執行的話,不能空著,要使用pass表面此處是空語句
val = 1
if val != 1:pass
elseprint("Yes")循環語句
? ? ? ? ? 循環語句之一while語法
while 表達式:語句? ? ? ? 案例?
#1到100之和
sums = 0
i = 1
while i <= 100:sums = sums + ii = i + 1
print(f"sum = {sums}")? ? ? ? 循環語句for語法
for 變量 in 可迭代對象語句? ? ? ? 案例
#1到100之和
sums = 0
for i in range(1,101):sums = sums + i
print(f"sum={sums}")? ? ? ? range是一個函數,傳入的兩個參數是一個[1,101?) 區間;它還要第三個參數表示變量i執行的步數,不傳默認是1
#打印10到1
for a in range(5,0,-1):print(a)
? ? ? ? 使用continue關鍵字表面此次循環跳過;break關鍵字則是跳出循環
函數
? ? ? ? 如果需要頻繁使用到相似的代碼的功能但需要根據需求改變值的話就可以使用函數根據需要進行調用
def 函數名(參數列表):語句? ? ? ? 案例
def cal_sum(begin, end):sums = 0for i in range(begin, end+1):sums += iprint(f"sums = {sums}")# 1到100之和
cal_sum(1, 100)
# 1到1000之和
cal_sum(1, 1000)
? ? ? ? 函數定義要調用函數之前,因為代碼是從上往下執行,在調用函數之后定義導致調用時找不到后編譯器報錯,所以要:先定義,再調用

? ? ? ? 有些代碼下面有黃線,但是程序正常運行;這可能是要你遵守它所要的規范,不如函數名CalSum這樣命名不符合它所要的規范,你要使用cal_sum來命名而不是以大寫字母分隔來命名(但這樣無傷大雅,只是盡量按照它的規范來,因為可以有的黃線可能影響代碼的正確性,要能夠識別的出就需要把那些因為錯誤命名規范導致的黃線給去掉(修改))
? ? ? ? 在python中函數列表有幾個就要傳入幾個,至于類型不規定:因為有動態類型(這也就在一些場景下不同收到類型的約束從而去學習復雜的語法比如C++的模板)
? ? ? ? 上面函數沒有返回值,在實際設計函數更推薦設置返回值:因為設置了返回值可以讓使用者與函數之間進行解耦合(一方改變另一方不受影響)
def sum_val(a, b):return a + bresult = sum_val(2, 6)
print(result)
result = sum_val(2.0, 3.0)
print(result)

? ? ? ? 除了返回一個值,在python中還可以一次返回多個值
def get_point():x = 10y = 20return x, yx, y = get_point()
print(x, y)

? ? ? ? 如果只需要返回多個值的中一個,用_把不需要的值進行站位
_, y = get_point()
函數作用域
定義x,y變量進行接收,與函數內容定義的x,y是否是一樣的呢?
? ? ? ? 不一樣,因為在函數有作用域的限制,外面的人實際上是不知道函數內容有什么變量,定義的變量名字相同時各自之間是不會受影響的
a = 10def fun():a = 20print(a)fun()
print(a)

? ? ? ? 如果里面想要讓外面的a進行修改,可以使用關鍵字global聲明后進行修改
a = 10def fun():global aa = 20print(a)fun()
print(a)

? ? ? ? 而像if,else,while,for雖然也與函數一樣形成代碼塊(里面語句需要縮進),但它們里面定義的變量再外部可以訪問,也就是說沒有作用域限制
if True:a = 10
print(a)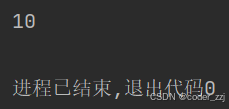
函數嵌套調用
? ? ? ? 函數的返回值可以作為下一個函數的參數進行調用,這樣就不用再創建變量保存返回值;但嵌套的多了影響可讀性,嵌套層數適量即可
? ? ? ? 打印兩者相加之和的結果
def sum_val(a, b):return a + bprint(sum_val(10, 20))
?
函數默認參數
? ? ? ? 與C++一樣:pyhton也支持函數參數給上默認參數:函數參數沒如果有傳入就使用默認的,有傳參數就使用傳參的;默認參數只能從右向左設置,不能從左邊或者中間設置
def sum_val(a, b, debug=False, debug1=True):if debug and debug1:print(f"a={a} b={b}")return a + bprint(sum_val(10, 20))

關鍵字參數
? ? ? ? 默認函數參數列表與調用函數傳參的順序相同;但也可以不順序傳,使用關鍵字參數指定傳
def test(x, y):print(f"x={x} y={y}")test(y=10, x=20)

列表
? ? ? ? 列表與元組其實是C/C++的數組,但它們有些差別;列表與元組具有相同的功能,唯一不同的是列表后面還要還可以加變量,而元組則在創建時就時固定下來的,如要更改就需要創建新的元組
? ? ? ? 表示列表的方法有兩種
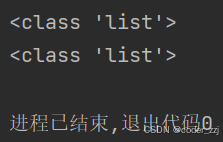
a = []
print(type(a))
b = list()
print(type(b))
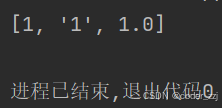
? ? ? ? 保存在列表中的變量,類型可以不同
a = [1, '1', 1.0]
print(a)
? ? ? ? 訪問列表的變量,下標從0開始;也可以通過下標修改變量
a = [1, '1', 1.0]
print(a[2])
a[2] = 2.0
print(a[2])

? ? ? ? 除了len()用來計算字符串長度,也可以用來計算列表長度
a = [1, '1', 1.0]
print(len(a))

? ? ? ? 所以列表的使用下標范圍 < len() ;因為python允許下標為負數,比如-1表示倒數第一個位置,-2表示倒數第二個位置....
print(a[-1])
print(a[3])
切片
? ? ? ? 列表可以通過切片操作獲取子列表
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
print(a[1:5])

? ? ? ? 取子列表的區間是左閉右開;切片操作只是取出列表中一部分,不涉及拷貝,因此列表長度較大時使用切片操作還是很高效
? ? ? ? 還可以省略下標進行切片
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
print(a[:5])
print(a[1:])
print(a[:])

? ? ? ? 使用切片的第三個參數指定步長(可以是負數),不傳默認為1
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 0]
print(a[1:5])
print(a[1:5:2])
print(a[::-1])

列表遍歷
? ? ? ? 對列表每個值進行遍歷,可以使用for循環或者while循環進行操作(以for循環為例)
a = [1, 2, 3]
for i in a:print(i)

? ? ? ? 這種遍歷時修改變量不影響內部變量,如果要進行修改列表的變量就要用遍歷下標的方式
a = [1, 2, 3]
for i in range(0, len(a)):a[i] += 10
print(a)

新增元素
? ? ? ? 可以使用append()函數或者insert()函數來新增變量
a = [1, 2, 3]
a.append(4)
a.insert(100, 5)
print(a)
? ? ? ? insert()需要傳插入的下標位置,如果超過列表長度就默認插入在最后一個位置
查找元素
? ? ? ? 使用 in 來判斷是否存在列表中
a = [1, 2, 3]
print(1 in a)
print(5 in a)

? ? ? ? 使用 inodex 返回值所在的下標
a = [1, 2, 3]
print(a.index(1))

????????如果不存在就拋異常
print(a.index(10))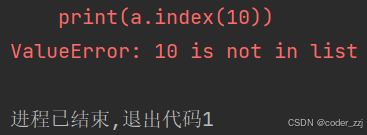
刪除元素
? ? ? ? 使用pop刪除默認刪除最后一個變量
a = [1, 2, 3]
a.pop()
print(a)

? ? ? ? 也可以指定下標刪除(不存在拋異常)
a = [1, 2, 3]
a.pop(1)
print(a)

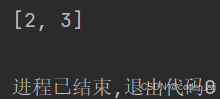
? ? ? ? 也可以使用remove()傳入指定的變量進行刪除(不存在拋異常)
a = [1, 2, 3]
a.remove(1)
print(a)
列表拼接
? ? ? ? 使用extend()函數進行列表之間的拼接
a = [1, 2, 3]
b = [5, 6, 7]
a.extend(b)
print(a)

? ? ? ? 也可以使用字符串拼接時的方法 + 進行拼接
a = [1, 2, 3]
b = [5, 6, 7]
a += b
print(a)
?
? ? ? ? 但這種原理是要先創建出一個大的臨時列表來保存 a 和 b的值,再把它拷貝給 a,最后臨時列表進行銷毀;而 extend()是直接把b列表拼接在a 的后面,這種效率更好
元組
? ? ? ? 元組與列表上定義不同:列表用的是【】而元組用的是()且元組定義后不可被修改;使用上如果涉及修改元組(如新增,修改,刪除遍歷)在元組這里行不通,其它的可讀操作如遍歷,切片,查找元素都與列表是一樣的
a = (1, 2, 3)
print(a)
print(a[0])
print(a[0:1])

? ? ? ? 函數可以返回多個變量底層就是根據元組進行返回
def get_point(x, y):return x, ya = (1, 2)
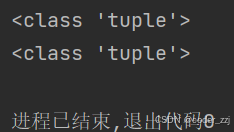
print(type(a))
print(type(get_point(5, 6)))
列表能做到元組不能做到的事,為什么還要有元組呢?
? ? ? ? 在實際協同開發時,程序猿A要開發一些功能(函數)給程序猿B使用,但程序猿B有個顧慮:如果在調用函數時把我的參數給修改導致結果是錯誤的,怎么辦?所以在這種場景下就可以傳元組,函數里面就不能進行修改啦
字典
? ? ? ? 字典中的儲存是鍵值對:第一個變量叫做key,第二個變量叫做val;使用時通過key找到val,key的變量類型有約束而val類型則無所謂
? ? ? ? 字典的定義有兩種
a = {}
b = dict()
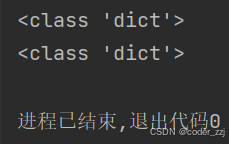
print(type(a))
print(type(b))
? ? ? ? 打印字典建議每一個鍵值對每隔一行寫一對進行對齊,可讀性高;可以是用 in(not in)判斷key值是否存在
a = {"id": 1,"name": "John",12306: "Jonh"
}
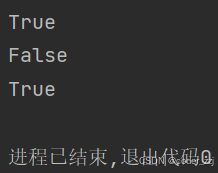
print("id" in a)
print(1 in a)
print("classed" not in a)
? ? ? ? 使用列表訪問變量一樣使用 [key] 找對應的val(如果key不存在就拋異常)
a = {"id": 1,"name": "John",12306: "Jonh"
}
print(a["name"])

print(a["classed"])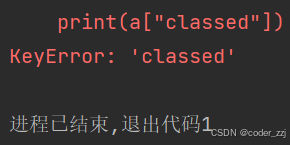
? ? ? ? 效率上使用 in(not in) 和 []查找key 和value在字典上效率都是很快,但在列表中[]查找變量快而 in反而效率不高:因為使用in 需要遍歷列表一遍
增刪改查
? ? ? ? 增加字段的鍵值對,修改key對應的val,查詢key對應的val都可以使用【】來完成
a = {"id": 1,"name": "John",12306: "Jonh"
}a["score"] = 90
print(a["score"])
print(a[12306])
a[12306] = "Mike"
print(a[12306])

? ? ? ? 刪除字典的鍵值對使用pop()函數來進行
a.pop("id")
print(a["id"])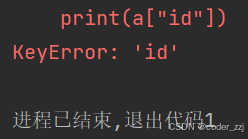
? ? ? ? 字典使用時效率達到常數級別的時間,不管數據是否變多還是變少,實踐用字典也是最多的
遍歷
? ? ? ? 可以使用for循環進行遍歷
a = {"id": 1,"name": "John",12306: "Jon"
}
for key in a:print(a[key])

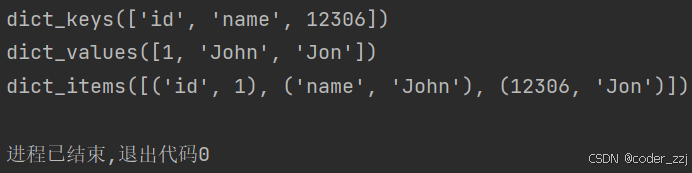
? ? ? ? 還可以使用函數 keys() values() items() 分別獲取字典的key,val,鍵值對
a = {"id": 1,"name": "John",12306: "Jon"
}
print(a.keys())
print(a.values())
print(a.items())
合法的key
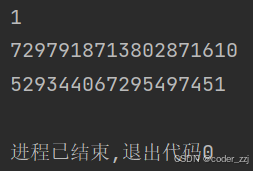
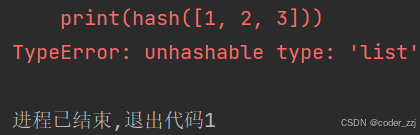
? ? ? ? 可以使用hash()函數來判斷key是否合法:hash()通過稱為可哈希,一般是不可變類型的變量如元組,整形,字符串;而hash()后報錯則稱為不可哈希,也就是不合法的key,一般是可變類型如列表,字典
print(hash(1))
print(hash("hello"))
print(hash((1, 2, 3)))
print(hash([1, 2, 3]))
文件操作
打開和關閉
? ? ? ? 打開文件時會返回一個文件對象,通過該文件對象來進行對文件進行操作;使用完成就要對文件對象進行關閉也就是釋放,因為打開一個文件時是需要效率系統資源的,使用完不關閉等到打開的文件足夠多之后程序就會崩潰(內存被文件對象占滿了)
f = open("C:/Users/29096/Desktop/test.txt", "w")
f.close()
? ? ? ? opne第第一個參數傳入文件路徑(文件儲存在系統的唯一性),第二個則是打開文件要進行什么操作:“r”:讀read操作;“w”:寫write操作;“a”:文件內存追加append操作?
? ? ? ? 持續打開后把文件對象保存在列表中看看最多創建多少個文件對象
a = []
count = 0
while True:f = open("C:/Users/29096/Desktop/test.txt", "w")a.append(f)count += 1print(f"文件對象個數:{count}")
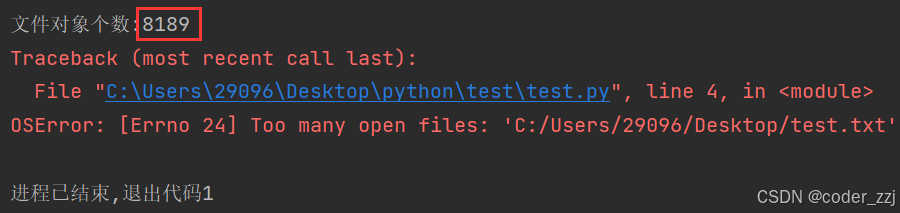
? ? ? ? 如果不保存在a列表中則可以無限創建文件對象:因為在python有垃圾回收機制:當他判斷創建的文件對象不是使用時垃圾時就會給你進行回收(釋放);但盡量還是要手動關閉,保不齊在判斷之前就已經發生文件申請過多程序崩潰了
讀寫操作
? ? ? ? 寫操作簡單
f = open("C:/Users/29096/Desktop/test.txt", "w")
f.write("hello world")
f.close()
? ? ? ? 程序正常退出
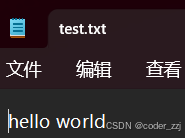
????????到指定路徑下看看是否有test.txt文件且內容是否符合預期
? ? ? ? 如果再次往該文件寫內容且不要清空原來的內容此時打開文件時用到是‘a’操作進行寫
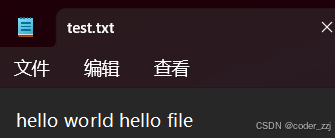
? ? ? ? 在文件中有以下內容
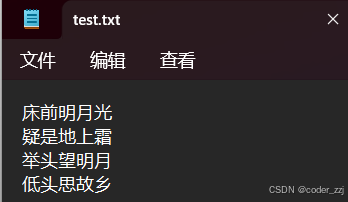
? ? ? ? 讀文件內容打印到控制臺有很多操作:按個數進行讀,但如果只是直接讀的話會報錯
f = open("C:/Users/29096/Desktop/test.txt", "r")
content = f.read(3)
print(content)

? ? ? ? 原因是讀操作嘗試以gbk編碼方式進行讀取,但文件使用的是UTF8(文件右下角)
![]()
所以在打開文件時要設置編碼方式
f = open("C:/Users/29096/Desktop/test.txt", "r", encoding="utf8")
content = f.read(2)
print(content)
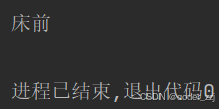
? ? ? ? 要想按行為單位進行讀取可以使用
f = open("C:/Users/29096/Desktop/test.txt", "r", encoding="utf8")
for content in f:print(content)

? ? ? ? 但是這里打印出來有空行:原因是文件每一行結尾有“\n”表示換行,而print后也要換行;所以對print進行設置讓它不要換行
for content in f:print(content, end="")
? ? ? ? 既然要讀取全部內容,可以使用 readlines() 來實現
f = open("C:/Users/29096/Desktop/test.txt", "r", encoding="utf8")
content = f.readlines()
print(content)

文件管理器
? ? ? ? 在進行文件操作時用戶可能會忘記或者跳過文件關閉的代碼,如在文件操作時由于判斷條件,return 導致沒能執行到關閉文件這行代碼函數就結束了,所以python提供了文件管理器來自動釋放打開文件時創建的文件資源
with open("C:/Users/29096/Desktop/test.txt", "w") as f:f.write("hello world")查找文件
? ? ? ? 給出的路徑與文件關鍵詞,在給出的路徑下查找是存在文件
import ospath = input("輸入文件路徑:")
name = input("輸入文件關鍵詞:")
# 路徑 當前路徑目錄名列表 當前路徑文件名列表
for dirpath,dirname,filename in os.walk(path):for file in filename:if name in file:print(f"dirpath:{dirpath} filename:{file}")
第三方庫
? ? ? ? python能夠流行大部分來源于它豐富的第三方庫,怎么使用?
? ? ? ? 各種第三方庫都能在 pypi.org網站上找到,一般使用 pip 工具以指令方式進行安裝(按照python默認自帶的)
二維碼
? ? ? ? 使用搜索引擎找到是第三方庫:qrcode;取 pypi.org網站上查使用文檔(比較權威),現在當前python環境安裝
pip install "qrcode[pil]"? ? ? ? 使用qrcode庫生成二維碼
import qrcoderesult = qrcode.make('python生成的二維碼')
result.save("1.png")
execl
? ? ? ? 按照xlrd庫,對execl格式的文件進行讀,寫使用 xlwd庫
pip install xlrd==1.2.0? ? ? ? 需求:統計班級100的學生平均分
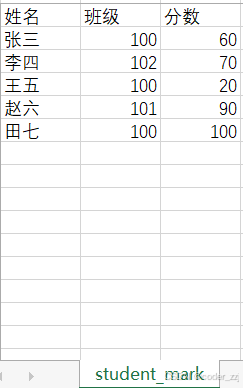
import xlrdxd = xlrd.open_workbook("C:/Users/29096/Desktop/1.xlsx")
#獲取execl中名為"student_mark"的表
table = xd.sheet_by_name("student_mark")
rows = table.nrows
score = 0
count = 0
for i in range(1, rows):grade = table.cell_value(i, 1)if grade == 100:score += table.cell_value(i, 2)count += 1
print(f"班級100 平均分:{score/count}")
程序猿鼓勵師
? ? ? ? 在按下若干次鍵盤后出現設置的隨機音頻進行播放效果
? ? ? ? 按照 pyuput 和 playsound 庫
pip install pynput==1.6.8
pip install playsound==1.2.2? ? ? ? 在當前路徑下準備好幾個mp3文件放在sound文件夾中?
import random
from threading import Thread
from pynput import keyboard
from playsound import playsoundsound_list = ["sound/1.mp3", "sound/2.mp3"]
count = 0def listen_release(key):global countcount += 1if count % 10 == 0:i = random.randint(0, len(sound_list) - 1)# 加線程才不會輸入鍵盤時卡頓t = Thread(target=playsound, args=(sound_list[i],))t.start()listen = keyboard.Listener(on_release=listen_release)
listen.start()
listen.join()
?以上便是全部內容,有問題歡迎在評論區指正,感謝觀看!















筆記)



顧客管理、供應商管理、用戶管理)