一、堆的概念
堆(Heap)是一種特殊的基于樹的數據結構,通常分為最大堆和最小堆兩種類型。它滿足堆屬性:對于最大堆,父節點的值總是大于或等于其子節點的值;而對于最小堆,父節點的值總是小于或等于其子節點的值。
數組實現:雖然堆是一個基于樹的結構,但它通常用數組來實現。對于位于數組索引i處的元素,其左孩子的索引是2*i + 1,右孩子的索引是2*i + 2,而其父節點的索引是(i-1)/2
將根節點最大的堆叫做最大堆或大根堆,根節點最小的堆叫做最小堆或小根堆。
堆的性質: 堆中某個節點(孩子節點)的值總是不大于或不小于其父節點的值;
堆總是一棵完全二叉樹
2.堆得存儲方式
二叉樹層序遍歷存儲在數組中
1)堆的創建(大根堆)
向下調整法 (同理可創建小根堆,孩子中最小的與根節點交換)
?完全二叉樹從最后一棵子樹慢慢調整為堆,最后一課子樹根節點與左右孩子最大值交換(根節點<左/右孩子).然后記得遞歸調整堆結構被破壞的子樹
package org.example;import java.util.Arrays;public class TestHeap {private int[] elem;private int usedsize;public TestHeap(int capacity){this.elem=new int[capacity];}//初始化堆public void initHeap(int []array){for (int i = 0; i < array.length ; i++) {elem[i]=array[i];usedsize++;//數組堆元素個數}}public void display(){System.out.println(Arrays.toString(elem));}//創建堆//一棵子樹有孩子一定先有左孩子 左孩子(usedsize-1-1)/2->父親節點public void createHeap(){//從最后一棵子樹根節點按個遍歷每棵樹根節點for(int parent=((usedsize-1-1)/2);parent>=0;parent--){shiftDown(parent,usedsize);}}public void shiftDown(int parent,int usedsize){int child=(2*parent)+1;//左孩子節點下標while(child<usedsize){//要確保有右孩子且不越界if(child+1<usedsize&&elem[child]<elem[child+1]){//右孩子比左孩子大 找到孩子節點的最大值child++;}//child是左右孩子節點最大值的下標if(elem[child]>elem[parent]){//交換節點swap(child,parent);//父節點向下移,繼續調整parent=child;child=2*parent+1;}else {//已經是大根堆不需要調整break;}}}public void swap(int i,int j){int tmp=elem[i];elem[i]=elem[j];elem[j]=tmp;}}Test測試類
package org.example;import java.util.Arrays;public class Test {public static void main(String[] args) {int []array={27,15,19,18,28,34,65,49,25,37};TestHeap testheap=new TestHeap(array.length);testheap.initHeap(array);testheap.createHeap();testheap.display();}
}?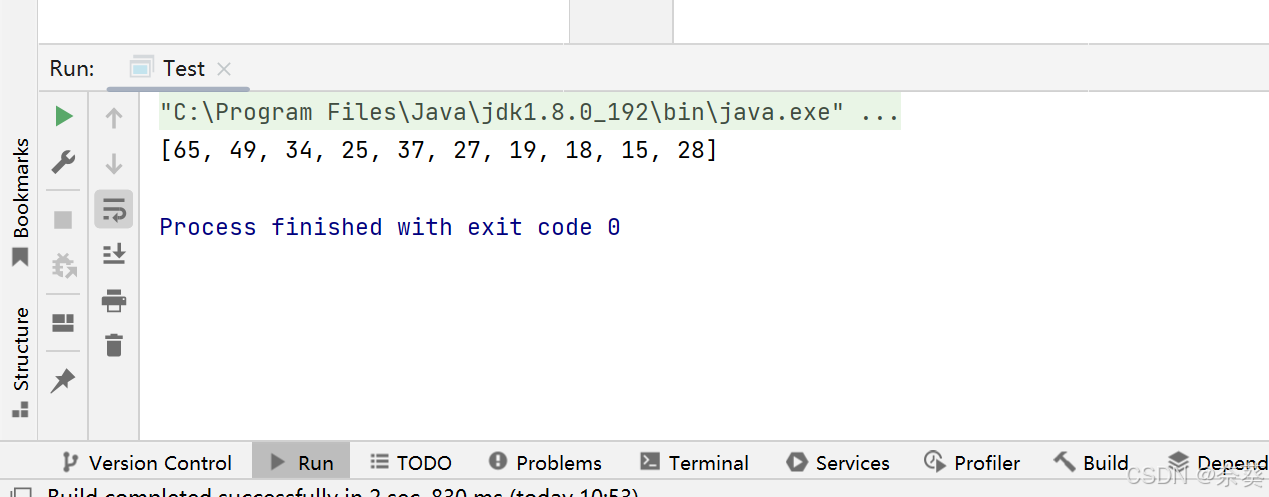
創建前
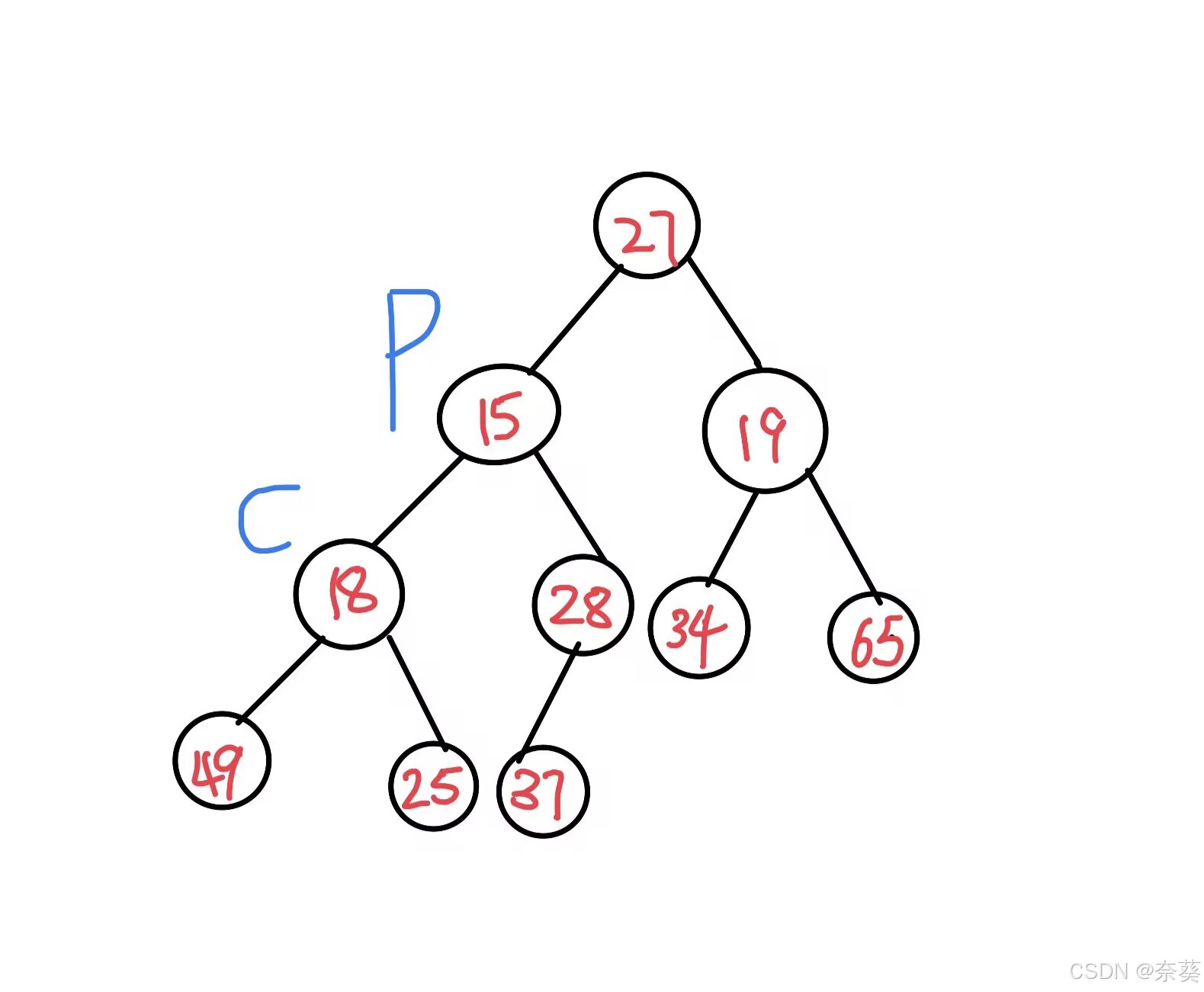
創建后(大根堆)
 ?2)堆的插入
?2)堆的插入
向上調整(先將新插入的節點放到堆的末尾,最后一個孩子之后,堆的結構性質被破壞,在慢慢往上移,向上調整為大/小根堆)
注意:空間放滿時需要擴容
public void offer(int val){if(isfull()){this.elem=Arrays.copyOf(elem,2*elem.length);//向上調整}//添加的元素是新的孩子this.elem[usedsize]=val;shiftUp(usedsize);usedsize++;}//向上調整函數 (也創建堆)//向下調整方法比向上調整方法少遍歷(最后)一層節點public void shiftUp(int child){int parent=(child-1)/2;while (child>0){if(elem[child]>elem[parent]){swap(child,parent);child=parent;parent=(child-1)/2;}else {break;}}}public boolean isfull(){return elem.length==usedsize;}
main方法
int []array={27,15,19,18,28,34,65,49,25,37};TestHeap testheap=new TestHeap(array.length);testheap.initHeap(array);testheap.createHeap();//testheap.display();testheap.offer(88);//插入元素打印testheap.display();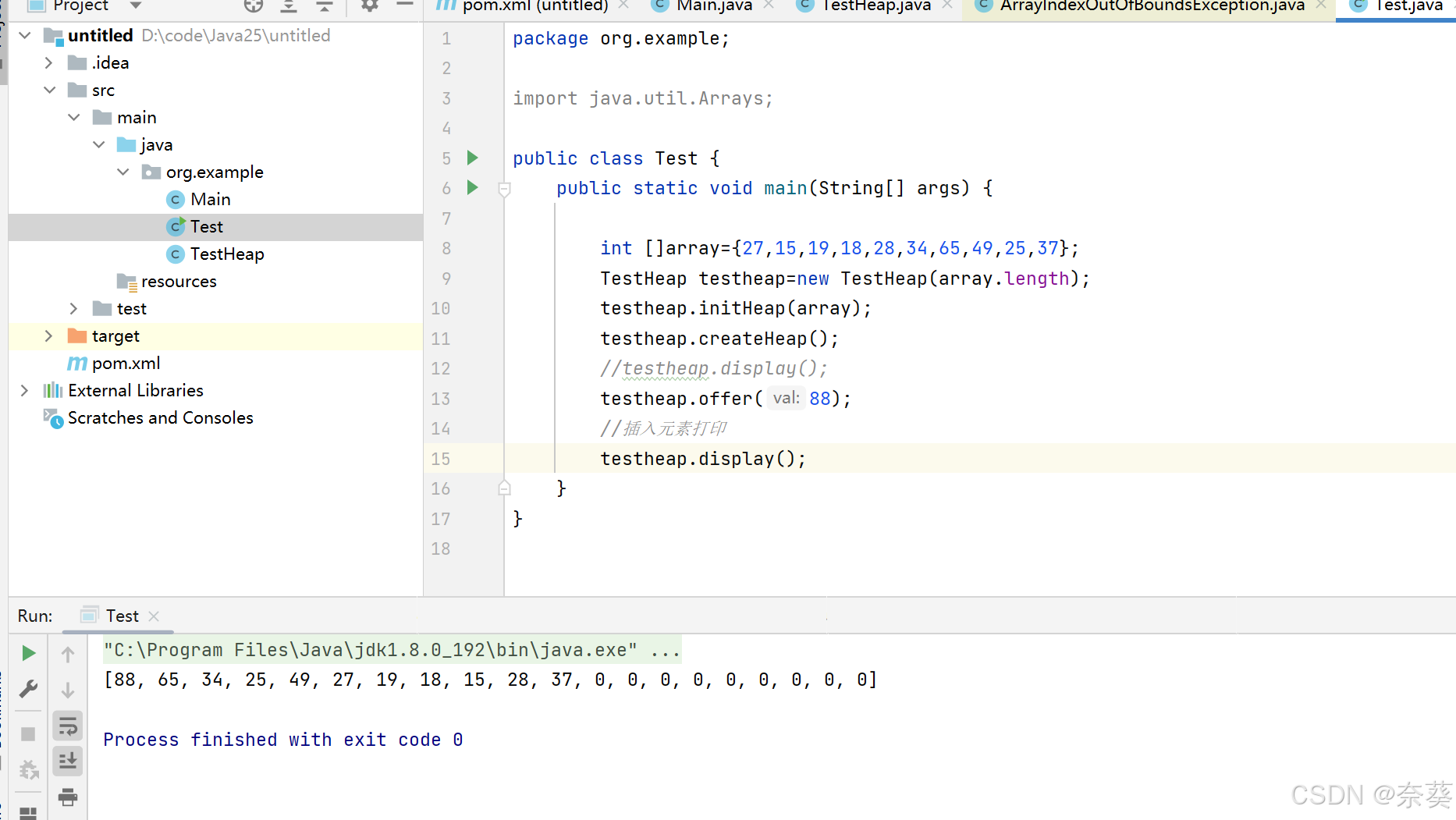
3)堆的刪除
刪除的一定是堆頂(根節點元素)
a.將堆頂元素與最后一個孩子元素交換
b.將堆中有效元素的個數減少一個
c.將堆頂元素向下調整,滿足堆特性為止
public int pool(){//一定是刪除堆頂元素int tmp= elem[0];//保留刪除的元素//交換元素swap(0,usedsize-1);usedsize--;shiftDown(0,usedsize);//返回被刪除的元素return tmp;}
int val=testheap.pool();System.out.println("被刪除的元素是"+val);//刪除后元素打印testheap.display();
public void display(){// System.out.println(Arrays.toString(elem));//顯示堆的有效部分System.out.println(Arrays.toString(Arrays.copyOf(elem, usedsize)));}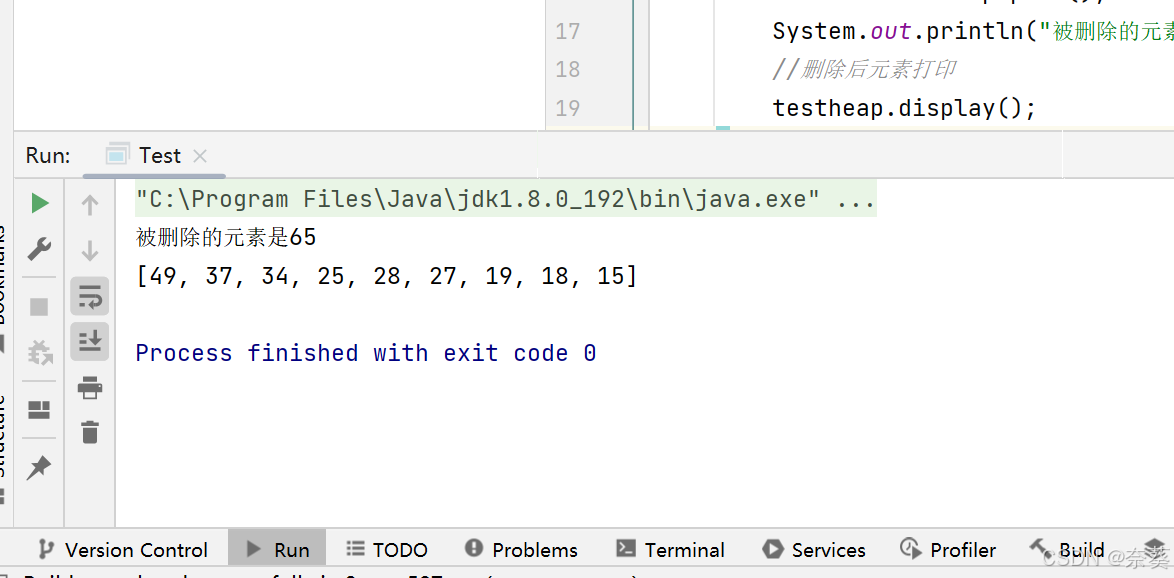
打印方法display()修改原因
你遇到的問題是:
> 刪除堆頂元素(65)后,65 **仍然出現在數組中**,只是被“擠”到了最后面,數組并沒有真正縮小,65 依然存在。
---
## ? 你的代碼是**邏輯正確的**,但你對 `display()` 方法的理解有誤。
---
## 🧠 堆的底層實現是一個數組,但它**不是動態收縮的數組**,而是通過 `usedsize` 來控制堆的有效元素數量。
你調用 `pool()` 方法后:
```java
usedsize--;
```
這意味著堆的有效長度減少了 1,但底層數組并沒有變小,**只是堆不再“關心”最后一個元素**。
---
## 🔍 舉個例子
你原來的堆是:
```
[65, 49, 34, 25, 37, 27, 19, 18, 15, 28]
```
調用 `pool()` 后,堆會執行:
```java
swap(0, usedsize - 1); // 交換 65 和 28
usedsize--; ? ? ? ? ? ?// usedsize 從 10 變成 9
shiftDown(0, usedsize); // 從新的堆頂 28 開始下濾
```
此時數組變成:
```
[49, 37, 34, 25, 28, 27, 19, 18, 15, 65]
```
但是 `usedsize = 9`,意味著堆只“看到”前 9 個元素:
```
[49, 37, 34, 25, 28, 27, 19, 18, 15]
```
而 `65` 被留在數組最后,**只是不再屬于堆的范圍**。
---
## ? 所以你看到的輸出:
```
[49, 37, 34, 25, 28, 27, 19, 18, 15, 65]
```
這是完全正常的,因為:
- `display()` 方法打印的是整個數組(包括不屬于堆的部分)
- 你沒有重新拷貝數組或清空無效數據
---
## ? 如何正確打印堆的有效部分?
修改 `display()` 方法為只打印有效部分:
```java
public void display() {
System.out.println(Arrays.toString(Arrays.copyOf(elem, usedsize)));
}
```
## ? 修改后輸出:
調用 `testheap.display();` 會輸出:
```
49 37 34 25 28 27 19 18 15
```
二、優先級隊列
隊列是一種先進先出(FIFO)的數據結構,但有些情況下,操作的數據可能帶有優先級,一般出隊 列時,可能需要優先級高的元素先出隊列,該中場景下,使用隊列顯然不合適,比如:在手機上玩游戲的時候,如 果有來電,那么系統應該優先處理打進來的電話;
數據結構應該提供兩個最基本的操作,一個是返回最高優先級對象,一個是添加新的對象。這種數 據結構就是優先級隊列(Priority Queue)。
JDK1.8中的PriorityQueue底層使用了堆這種數據結構,而堆實際就是在完全二叉樹的基礎上進行了一些調整。
Java集合框架中提供了PriorityQueue和PriorityBlockingQueue兩種類型的優先級隊列,PriorityQueue是線 程不安全的,PriorityBlockingQueue是線程安全的
1)優先級隊列使用
導包
import java.util.PriorityQueue;
2. PriorityQueue中放置的元素必須要能夠比較大小,不能插入無法比較大小的對象,否則會拋出 ClassCastException異常
3. 不能插入null對象,否則會拋出NullPointerException
4. 沒有容量限制,可以插入任意多個元素,其內部可以自動擴容
5. 插入和刪除元素的時間復雜度為
6. PriorityQueue底層使用了堆數據結構
7. PriorityQueue默認情況下是小堆---即每次獲取到的元素都是最小的元素
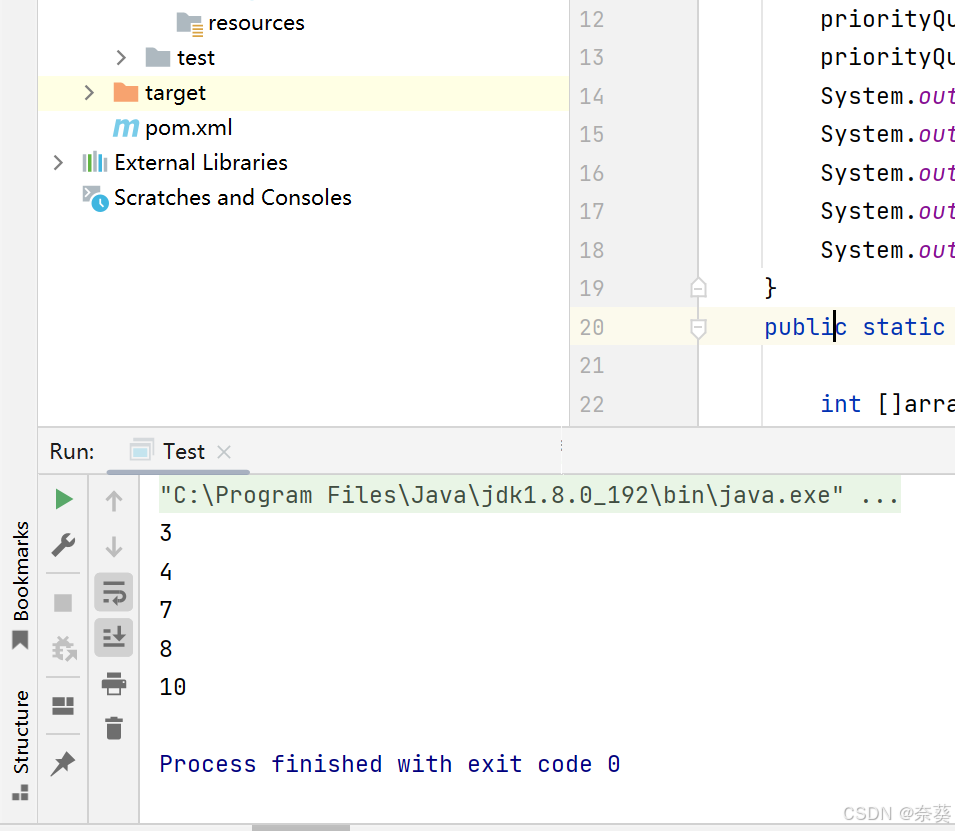
public class Test {public static void main(String[] args) {PriorityQueue<Integer> priorityQueue=new PriorityQueue<>();priorityQueue.offer(10);priorityQueue.offer(4);priorityQueue.offer(8);priorityQueue.offer(3);priorityQueue.offer(7);System.out.println(priorityQueue.poll());System.out.println(priorityQueue.poll());System.out.println(priorityQueue.poll());System.out.println(priorityQueue.poll());System.out.println(priorityQueue.poll());}打印結果證明是小根堆
?2)優先級隊列的創建方式(3種)
static void TestPriorityQueue(){
// 創建一個空的優先級隊列,底層默認容量是11
PriorityQueue<Integer> q1 = new PriorityQueue<>();
// 創建一個空的優先級隊列,底層的容量為initialCapacity
PriorityQueue<Integer> q2 = new PriorityQueue<>(100);
ArrayList<Integer> list = new ArrayList<>();
list.add(4);
list.add(3);
list.add(2);
list.add(1);
// 用ArrayList對象來構造一個優先級隊列的對象
// q3中已經包含了三個元素
PriorityQueue<Integer> q3 = new PriorityQueue<>(list);
System.out.println(q3.size());
System.out.println(q3.peek());
}3)優先級隊列的使用方法
函數名? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 功能介紹
boolean offer(E e)? ? 插入元素e,插入成功返回true,如果e對象為空,拋出NullPointerException異常,時間復雜度 log2N,注意:空間不夠時候會進行擴容
E peek() 獲取優先級最高的元素,如果優先級隊列為空,返回null
E poll() 移除優先級最高的元素并返回,如果優先級隊列為空,返回null
int size() 獲取有效元素的個數
void clear() 清空
boolean isEmpty() 檢測優先級隊列是否為空,空返回true

)

)









![[ComfyUI] -入門2- 小白零基礎搭建ComfyUI圖像生成環境教程](http://pic.xiahunao.cn/[ComfyUI] -入門2- 小白零基礎搭建ComfyUI圖像生成環境教程)




的跨越)
