
導讀

ChatGPT 用戶量指數級暴漲,OpenAI 的 Kafka 集群在一年內增長 20 倍至 30+ 個集群[1],其 Kafka 架構面臨日均千億級消息(峰值 QPS 800萬/秒) 的壓力。這揭示了一個關鍵事實:OpenAI 的成功不只依賴模型,更依托能支撐高并發迭代的數據基礎設施。?
基于 OpenAI 在 Confluent 技術演講中披露的內容,本文將從 Kafka 在 OpenAI 中的使用場景出發,揭示業務暴漲后的所面臨的痛點,并重點介紹 “Proxy代理層”架構(Prism + uForwarder)如何實現業務與基礎設施的深度解耦、跨集群容災無縫遷移等能力。
在此基礎上,我們將探討 Apache Pulsar 的架構潛力(存儲計算分離/消息流統一)和其在高可用、低延遲場景的優勢(內置重試/死信/高效GEO復制),為 AI 業務的消息流選型提供前瞻洞察。
OpenAI中Kafka的使用場景

基于OpenAI在Confluent技術演講中披露的架構實踐,Kafka在OpenAI的場景中有深入的應用,例如典型的數據飛輪場景[2]如下:
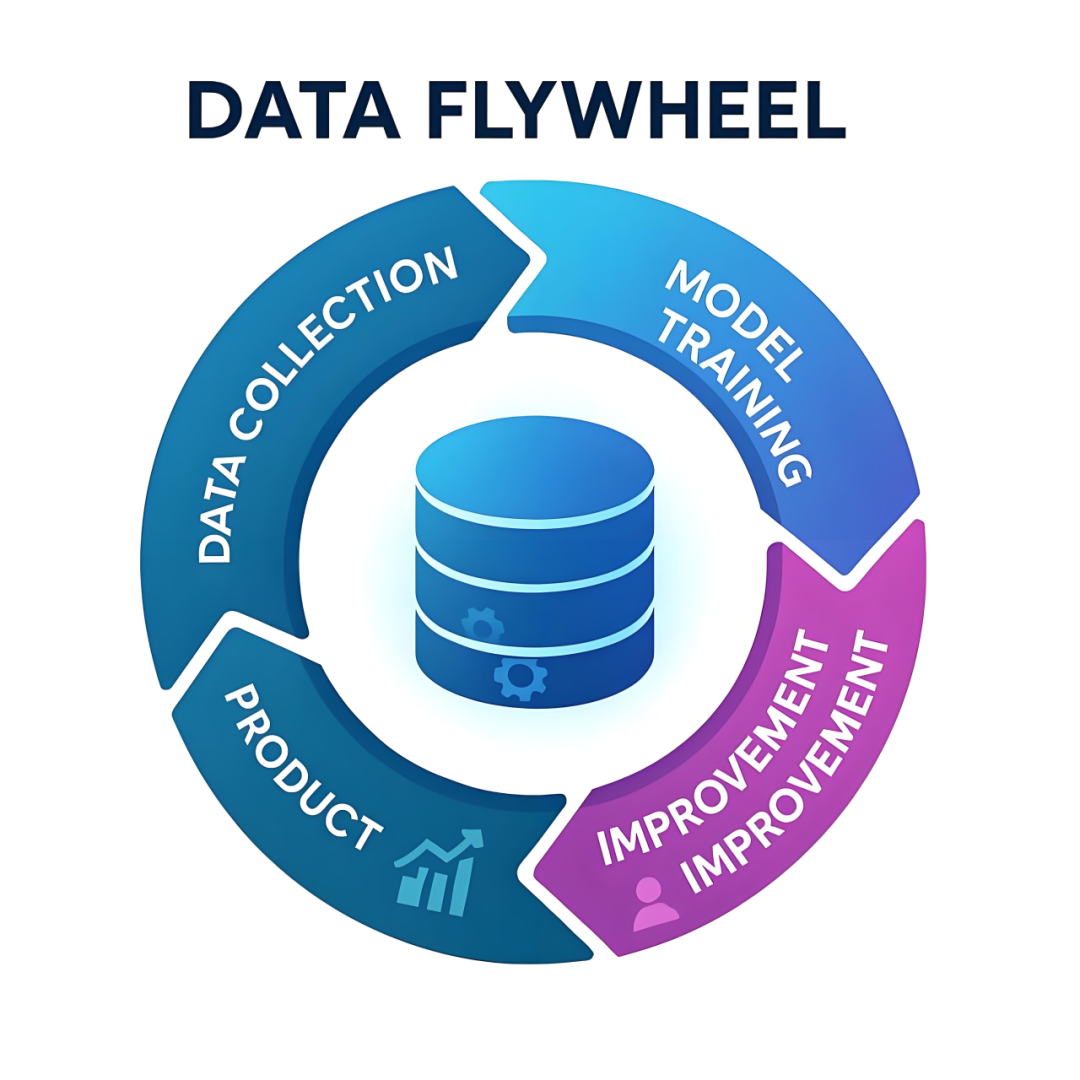
? OpenAI ?
數據收集(DATA COLLECTION):用戶與ChatGPT等產品的交互行為數據(每次對話/點擊)。
模型訓練(MODEL TRAINING):根據實時收集的行為數據,對模型進行增量學習和訓練。
模型優化(IMPROVEMENT):根據模型訓練的結果,結合當前模型進行參數調優和能力增強。
模型上線(PRODUCT):新模型實時生效于用戶終端,用戶行為數據實時回流至采集端。
該流程與成熟的實時推薦系統高度一致:通過實時收集用戶行為并反饋,持續修正推薦模型,形成正反饋循環。其中,消息中間件貫穿全流程,加速產品使用數據反饋至模型能產生實質影響。Kafka 在其中承擔三重關鍵角色:數據管道(Data Pipeline)、流處理協同層、反饋加速器。
此外,在 AI 開發場景中,快速實驗迭代是模型演進的核心驅動力[2],實現數據無縫管道化處理可建立關鍵基礎
統一數據源:打破數據孤島;將線上業務數據按需同步至實驗沙盒環境。
快速實驗:快速實現A/B Test,從數據的收集到最終的反饋一體化,加速模型優化 。通過端到端一體化流程實現A/B測試——從實時數據收集到模型效果反饋,加速模型優化。

最后是消息中間的核心場景,例如服務間異步解耦通信、削峰填谷等。
OpenAI中Kafka面臨的挑戰

當ChatGPT的用戶量如野火般蔓延,OpenAI中Kafka集群數量快速增長,隨之問題也逐漸暴露出來。

業務接入痛點

認知成本過高
開發者需正確掌握 Kafka 機制和 api 使用(如 Offset 提交策略、消費者重平衡)。
業務邏輯與基礎設施知識耦合,業務人員需要關心 Kafka 的部署架構,以及 Topic 歸屬哪個集群、該怎么連接。
分區限制所帶來的性能問題
OpenAI 大量使用 Python 語言進行業務系統開發,對于高并發消費場景,一味地增加 Topic 的分區并不能從根本上解決問題;進一步地,因為 Kafka 集群支持的分區數由于本身 IO 模型而受限,過多的分區(Kafka 磁盤順序寫退化為隨機寫)會導致集群性能下降和延遲增加,增加分區的動作反而會帶來 Kafka 集群不穩定的風險。

集群可用性痛點

單集群運維風險
分區/節點擴縮容操作,觸發分區不可用(如 ISR 收縮、Leader 選舉失敗),導致分鐘級業務中斷。
連鎖反應,局部故障可能演變為集群級雪崩(如Controller切換失敗)單Kafka集群在運維時有非常多的弊端,例如擴分區擴容場景,會導致分區級別不用的情況,導致業務終端,帶來集群不可用的風險。
多集群拆分困境
由于 Kafka 集群分區數規模的限制,不得不拆解更多的集群來滿足業務的發展,同時集群運維成本也倍數增加
將一個 Topic 從 A 集群遷移到 B 集群,又對業務系統存在侵入性,無法做到平滑遷移。
公有云環境風險疊加
OpenAI的大部份服務部署于公有云,其底層基礎設施異常(如區域級故障)會直接傳導至 Kafka 集群;為規避單點風險,必須采用多區域多集群部署架構。

高階特性缺失

Kafka 作為異步解耦通道,其原生 API?未提供業務級高階特性[4],需系統自行實現。
重試消息:消費場景中,如果業務邏輯處理失敗,需要進行退避式重試。這對于業務是必須的,但在 Kafka 的 API 里不支持。
死信消息:對于重試一直失敗的消息(大多數情況是異常消息)需要放入到死信 Topic 中,不能占有資源部釋放。
上述挑戰并非 OpenAI 獨有;所有經歷指數級業務擴張的企業,其 Kafka 架構必然面臨系統性瓶頸。下面讓我們看看 OpenAI 是如何解決這些問題的。
OpenAI的解決方案

從 OpenAI 的技術方案可見,其架構設計始終以業務需求為驅動原點,核心聚焦業務系統與 Kafka 基礎設施的解耦、全鏈路高可用保障,整體架構如下:
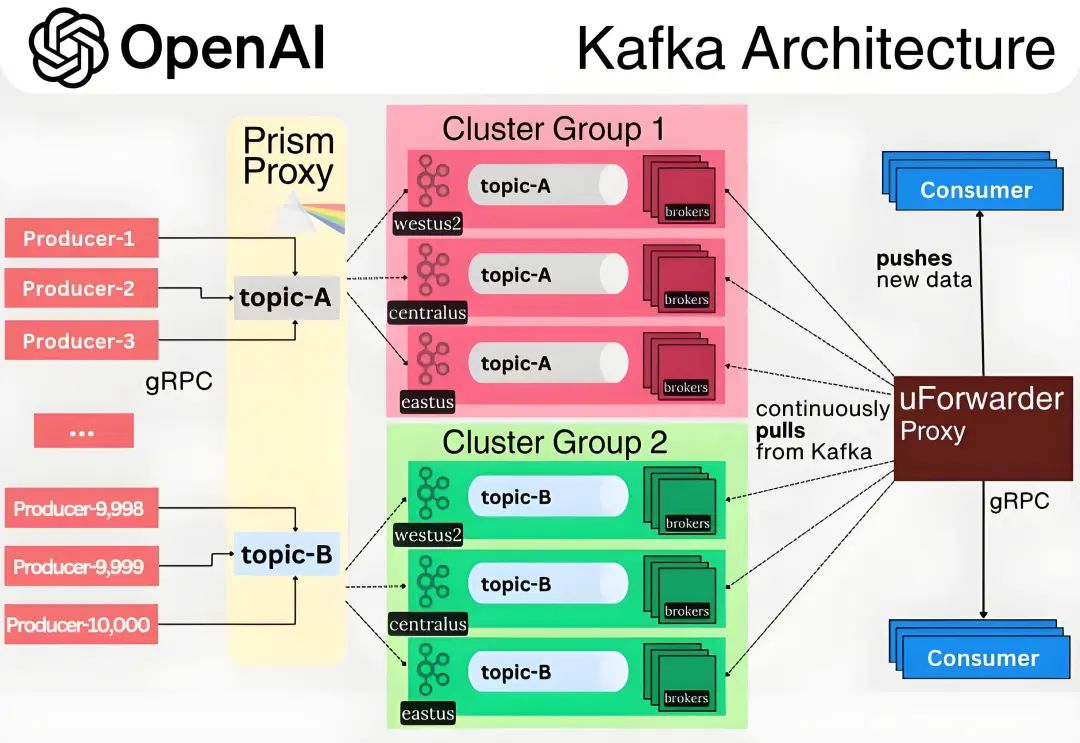

抽象分層

生產解耦[3]
通過 Prism Proxy 代理層,將原生 Kafka 協議轉換為標準化 gRPC 接口,屏蔽集群對接細節。
Prism Proxy 提供消息生產路由和負載均衡能力。
業務僅需指定邏輯主題(如 topic-A),無需感知物理集群部署(如 Cluster Group 1的位置與架構) 。
收斂生產者直連數量,規避海量連接導致的集群過載風險。
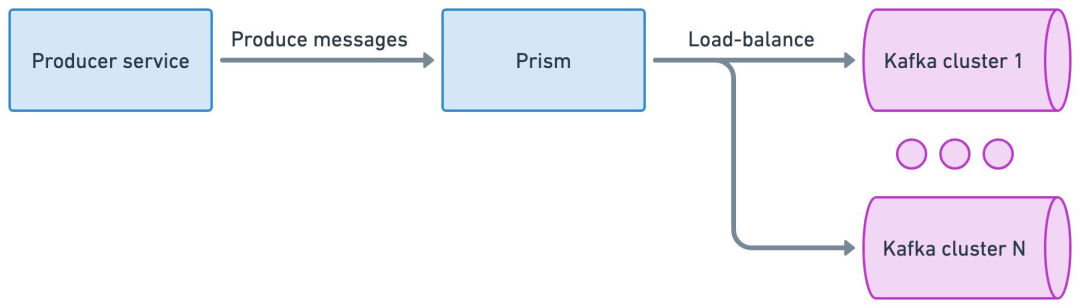
消費解耦[4]
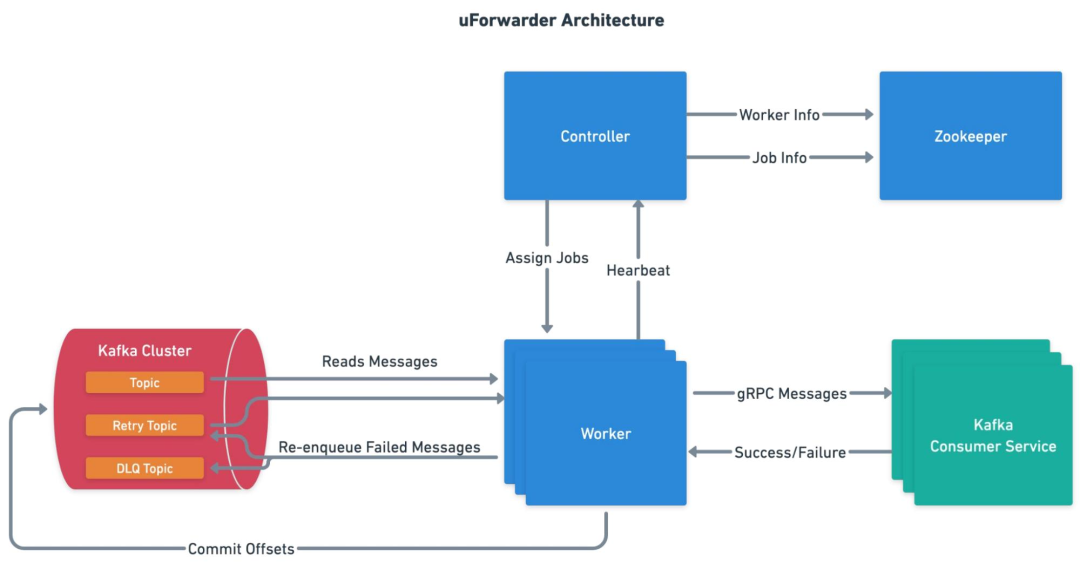
uForwarder 模塊實時從 Kafka 拉取新數據,并通過 gRPC 協議主動推送給業務消費服務。
uForwarder 模塊通過 Zookeeper 管理消費相關的元數據配置,Controller 將任務下發給 Worker,實現高效的分布式內部協作。
uForwarder 內部基于Retry Topic 和 DLQ Topic 實現了重試消息和死信消息的能力。
消費服務僅需關注業務邏輯處理,通過返回成功或失敗的應答,告知uForwarder是確認該消息還是重新推送。

可用性保障

物理隔離
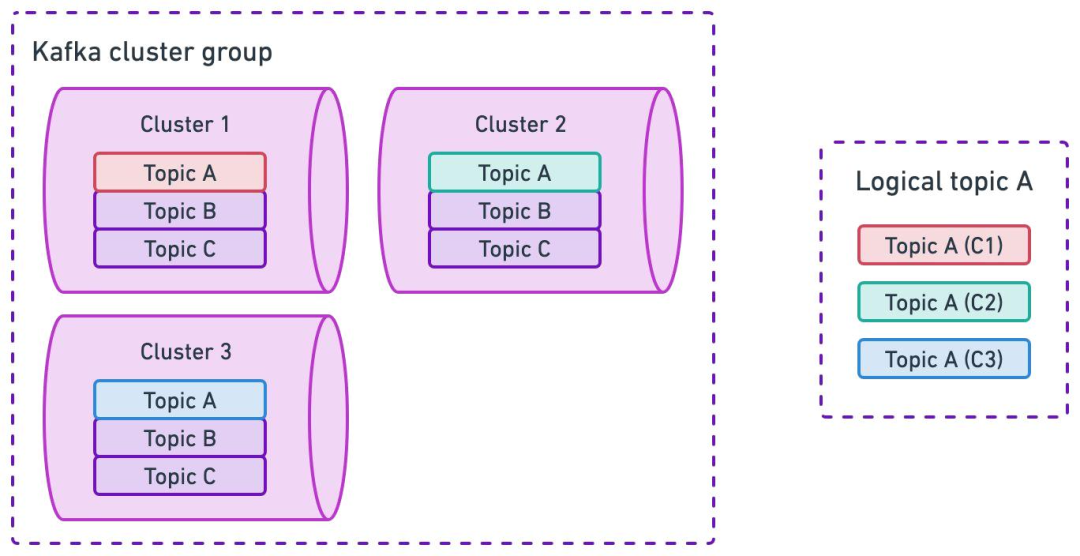
業務按集群組劃分,每個業務組映射到特定集群組,降低業務間影響。
集群組內,Topic 會在所有集群中創建,避免單集群故障問題。
應對云環境的區域故障,集群組內采用跨區域部署。
生產高可用
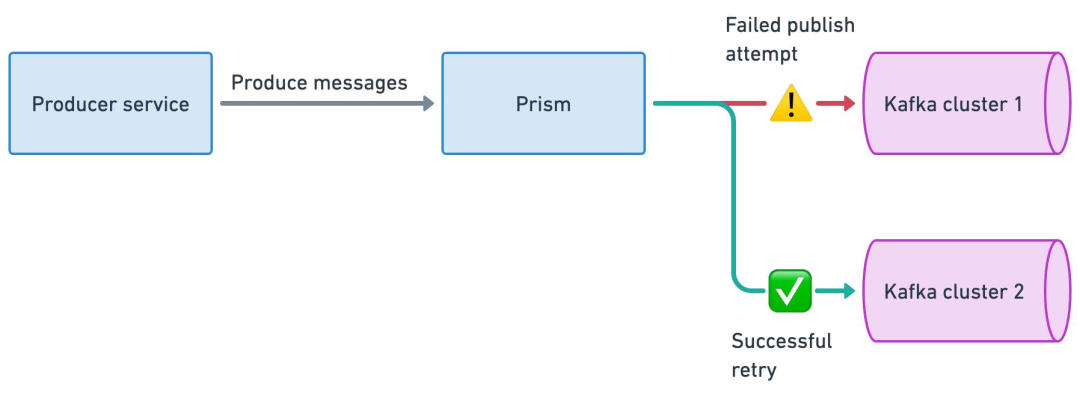
正常情況下,Prism Proxy 會基于負載均衡策略,將寫入請求均勻分散到整個集群組。
當 Prism 向集群組中的 Kafka1 發送一批消息失敗時,會自動選擇另一個正常運行的集群(如 Kafka2)進行寫入。
邏輯 TopicA 的消息會被均勻分散存儲在集群組的所有 Kakfa 集群 TopicA 中,基于這種方式,實現了生產端的高可用性。
消費高可用
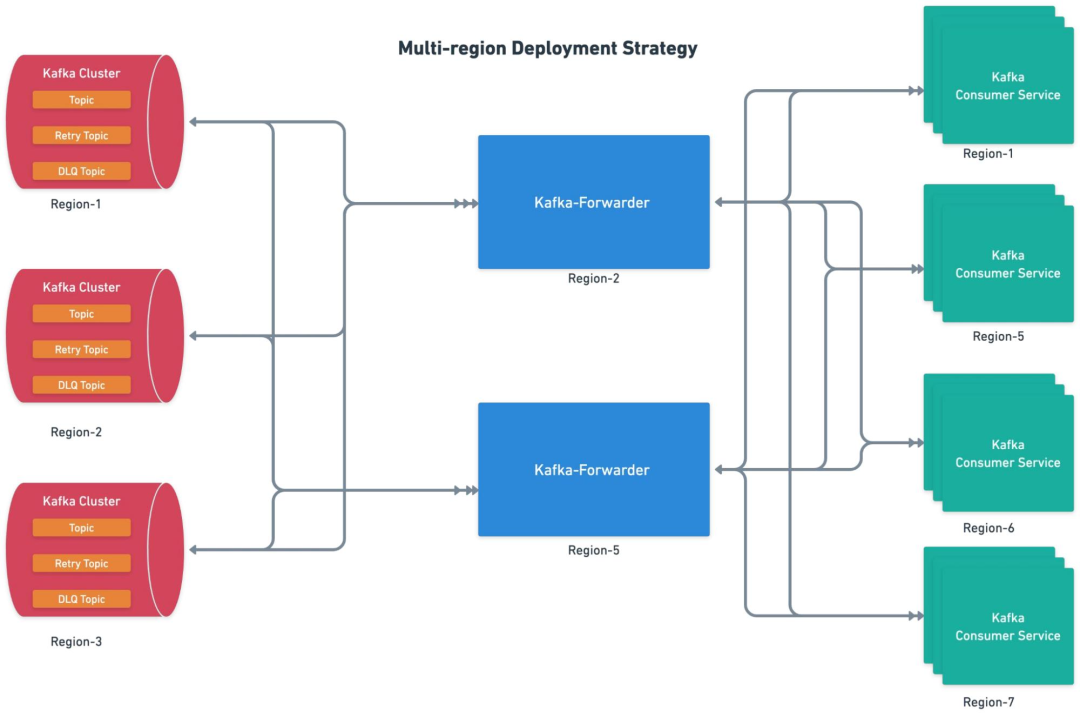
uForwarder 會與同集群組中的所有 Kafka 集群建立訂閱關系。
uForwarder 模塊負責定義邏輯 Topic 與后端 Consumer Server 端點的映射關系。
uForwarder 支持跨區域部署。
集群無縫遷移
歷史集群遷移方案較為簡單:
首先,Prism Proxy 通過調整路由配置,將生產請求從 legacy 集群摘除
待 uForwarder 消費完 legacy 集群中的殘留消息后,即可安全下線該集群,完成遷移過程。
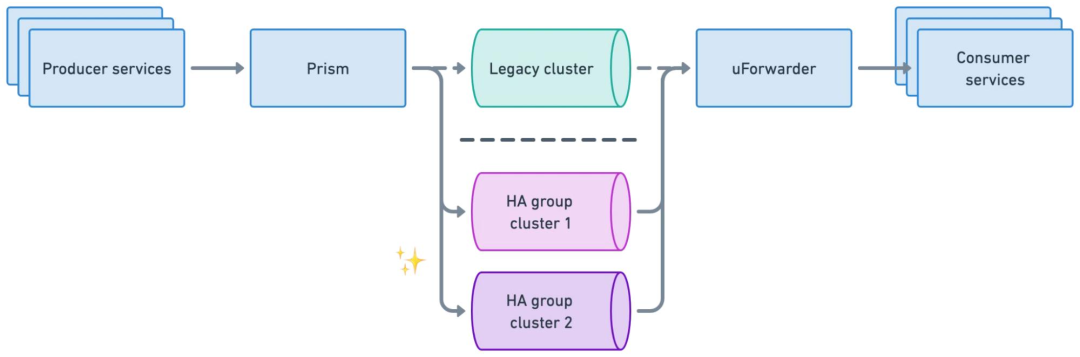
OpenAI 中 Kafka 這套架構方案比較常規,通過生產和消費的代理層來實現業務邏輯和消息中間件的解耦,同時在代理層實現流量的精細化調度。很多企業例如滴滴出行的 DDMQ[5]?也比較類似。
每個方案都有取舍,OpenAI 這個也不例外,主要體現在[3]:
消息的順序性無法得到保證。在 Kafka 常規模式下,可以通過 key-based 路由將相同 key 的消息發送到同一 Topic 分區,從而提供分區級別的局部順序性。然而,多集群寫入方案在提升高可用性的同時,犧牲了消息的順序性保障。OpenAI 將順序問題由業務層自行處理,例如通過 Flink 批量消費數據后,在內部進行排序來規避這個問題。
消息冪等或事務性寫入無法得到保證,原因同上。
OpenAI 更關注消息服務的可用性保障和業務系統的高效接入能力,當前這套技術方案能夠較好地滿足這些需求。
Kakfa 替換成 Pulsar 會更好

Apache Pulsar 作為下一代云原生分布式消息流平臺,從架構上要領先于 Kakfa,更適合 OpenAI 所關注的集群可用性、可靠性以及端到端的低延遲場景。
架構對比
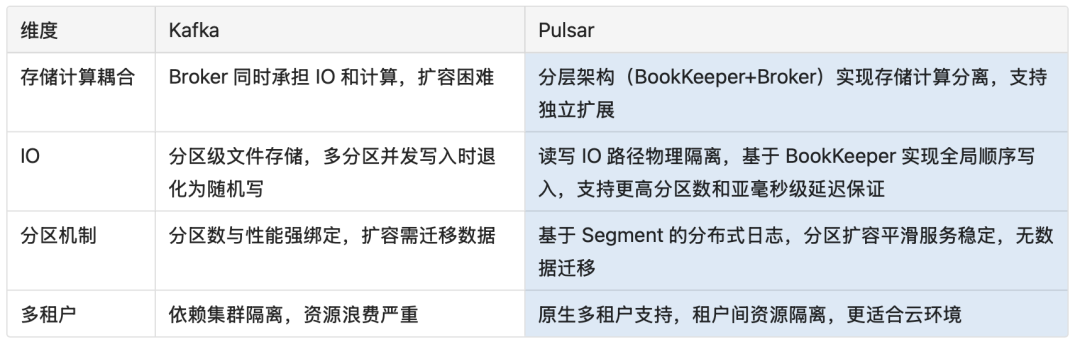
業務特性對比
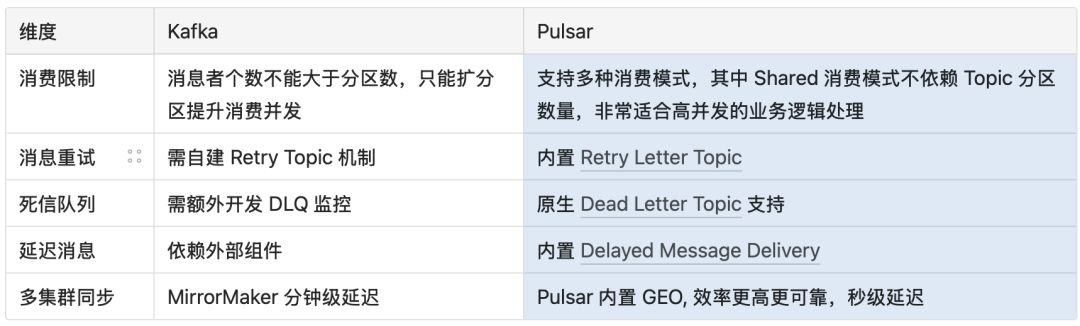
多集群同步機制至關重要。OpenAI 將業務數據分散存儲在一個集群組中,并跨多個云可用區部署。這種情況下,Flink 無法從一個統一的數據源完整獲取數據,同時還存在因重復讀取同一份數據而產生的額外網絡費用開銷。

運維成本對比
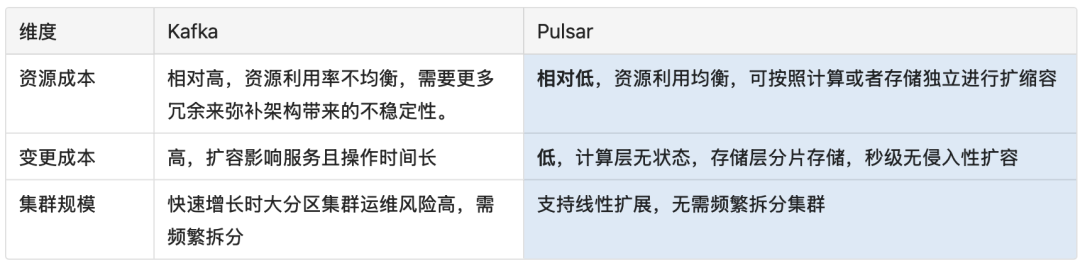
Apache Pulsar 能為 OpenAI 提供更簡潔的流式架構、更經濟的公有云消息中間件部署方案,同時具備更適合在線業務的功能特性,并能提供更可靠、更低延遲的消費服務。
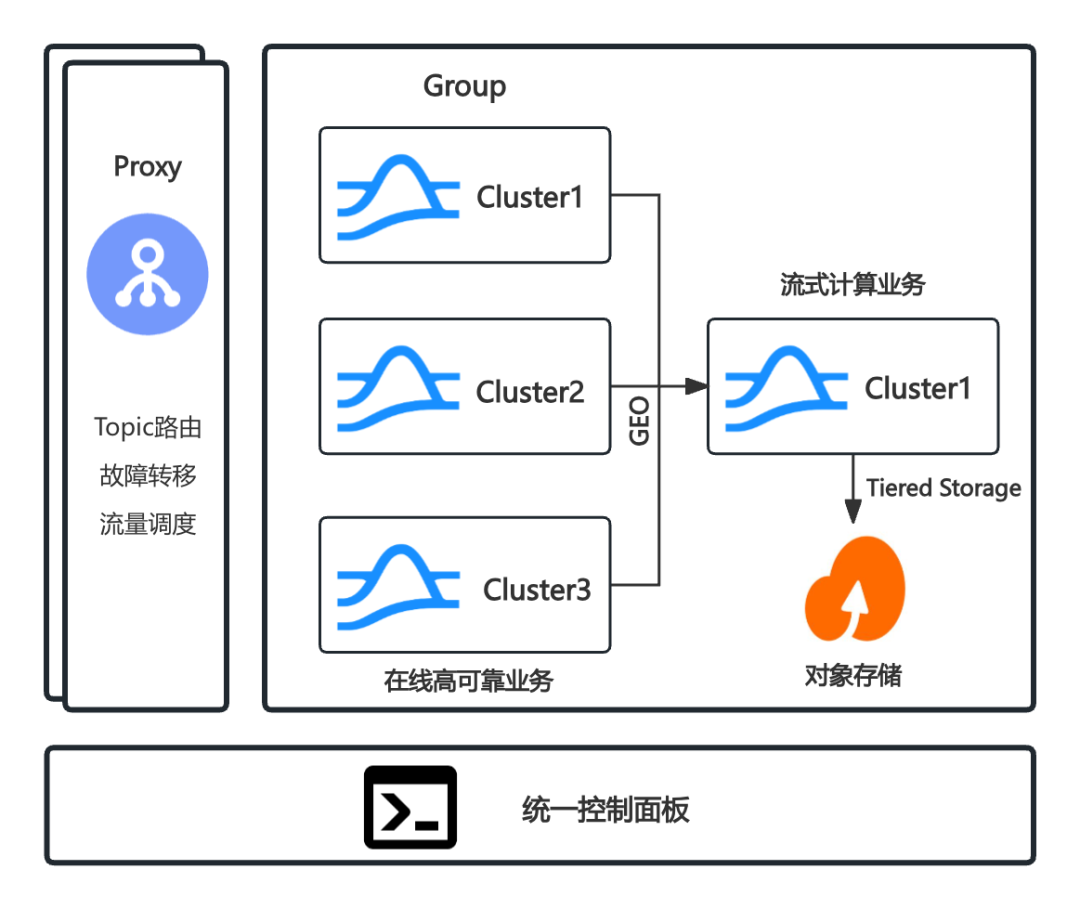
對于 Prism Proxy 和 uForwarder 模塊是構建在消息中間件之上的配套能力,通過 Proxy 代理實現全局 Topic 的路由、故障轉移以及流量調度能力;通過 GEO-Replication 能力高效可靠地匯聚數據,為流式計算業務提供統一的數據消費視圖;基于 Tiered Storage 實現冷熱數據分層存儲,支持低成本長期數據保留(滿足 PB 級存儲需求);通過統一控制面板,以業務視角對集群組進行全生命周期管理。
結語

OpenAI 的 Kafka 代理層架構,是在業務爆發增長與基礎設施瓶頸間的一次成功權衡——它通過創新的解耦設計將可用性推向極致,同時驗證了“以業務需求反哺架構迭代”的實踐哲學。
而 Pulsar 的云原生基因與高階特性,則揭示了下一代消息流平臺在 AI 時代的為更好的選擇,本質上是對「規模、效率、成本」核心命題的持續求解。
參考文獻
[1] OpenAI’s Kafka throughput grew 20x in the last year across 30+ clusters,?https://www.linkedin.com/posts/stanislavkozlovski_openai-kafka-activity-7331683326195331073-cxN6/
[2] Building Stream Processing Platform at OpenAI,?https://current.confluent.io/post-conference-videos-2025/building-stream-processing-platform-at-openai-lnd25
[3] Changing engines mid-flight: Kafka migrations at OpenAI,?https://current.confluent.io/post-conference-videos-2025/changing-engines-mid-flight-kafka-migrations-at-openai-lnd25
[4] How OpenAI Simplifies Kafka Consumption,?https://current.confluent.io/post-conference-videos-2025/changing-engines-mid-flight-kafka-migrations-at-openai-lnd25
[5]支持異構消息引擎!滴滴開源消息中間件DDMQ

Apache Pulsar 作為一個高性能、分布式的發布-訂閱消息系統,正在全球范圍內獲得越來越多的關注和應用。如果你對分布式系統、消息隊列或流處理感興趣,歡迎加入我們!
Github:?
https://github.com/apache/pulsar

掃碼添加pulsarbot,加入Pulsar社區交流群
最佳實踐
互聯網
騰訊BiFang?|?騰訊云?|?微信?|?騰訊?|?BIGO?|?360?|?滴滴? |?騰訊互娛?|?騰訊游戲?|?vivo?|?科大訊飛?|?新浪微博?|?金山云?|?STICORP?|?雅虎日本?|?Nutanix Beam?|?智聯招聘?
金融/計費
騰訊計費?|?平安證券?|?拉卡拉?|?Qraft?|?甜橙金融?
電商
Flipkart?|?誼品生鮮?|?Narvar?|?Iterable?
機器學習
騰訊Angel PowerFL
物聯網
云興科技智慧城市?|?科拓停車?|?華為云?|?清華大學能源互聯網創新研究院?|?涂鴉智能
通信
江蘇移動?|?移動云?
教育
網易有道?|?傳智教育
推薦閱讀
資料合集?|?實現原理?|?BookKeeper儲存架構解析?|?Pulsar運維?|?MQ設計精要?|?Pulsar vs Kafka?|?從RabbitMQ 到 Pulsar?|?內存使用原理?|?從Kafka到Pulsar?|?跨地域復制?|?Spring + Pulsar?|?Doris + Pulsar?|?SpringBoot + Pulsar?











技術構建的數據可視化大屏展示頁面)





)
)

