第一步:介紹
1)GLCIC-PyTorch是一個基于PyTorch的開源項目,它實現了“全局和局部一致性圖像修復”方法。該方法由Iizuka等人提出,主要用于圖像修復任務,能夠有效地恢復圖像中被遮擋或損壞的部分。項目使用Python編程語言編寫,并依賴于PyTorch深度學習框架。
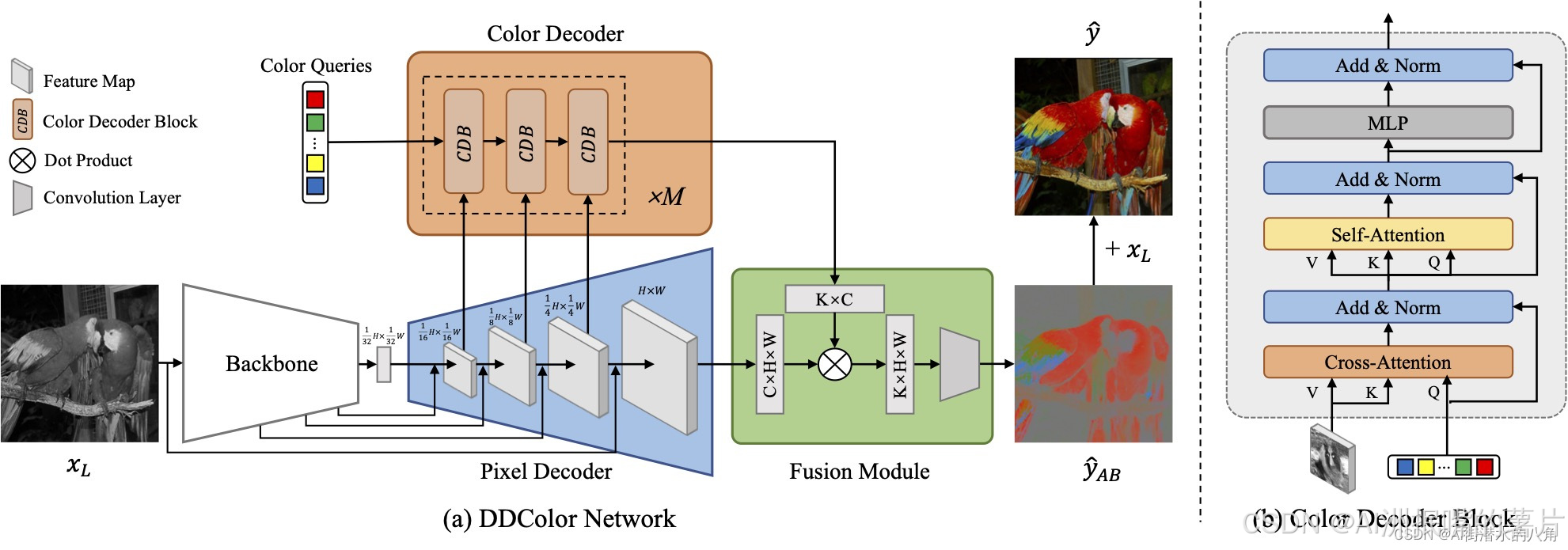
2)? DDColor 是最新的 SOTA 圖像上色算法,能夠對輸入的黑白圖像生成自然生動的彩色結果,使用 UNet 結構的骨干網絡和圖像解碼器分別實現圖像特征提取和特征圖上采樣,并利用 Transformer 結構的顏色解碼器完成基于視覺語義的顏色查詢,最終聚合輸出彩色通道預測結果。
核心思想:先GLCIC修復劃痕,再DDColor進行上色
第二步:網絡結構
1) GLCIC項目的核心功能是圖像修復,它通過訓練一個生成網絡(Completion Network)和一個判別網絡(Context Discriminator)來實現。生成網絡負責完成圖像修復任務,而判別網絡則用于提高修復質量,確保修復后的圖像在全局和局部上都與原始圖像保持一致性。主要特點如下:
????????圖像修復:利用生成網絡對圖像中缺失的部分進行修復。
????????全局與局部一致性:確保修復后的圖像既在全局上與原圖一致,又在局部細節上保持連貫。
????????判別網絡輔助:通過判別網絡對生成圖像進行評估,以提升修復質量。
2)DDColor算法整體流程如下圖,使用?UNet?結構的骨干網絡和圖像解碼器分別實現圖像特征提取和特征圖上采樣,并利用 Transformer 結構的顏色解碼器完成基于視覺語義的顏色查詢,最終聚合輸出彩色通道預測結果。
第三步:模型代碼展示
import os
import torch
from collections import OrderedDict
from os import path as osp
from tqdm import tqdm
import numpy as npfrom basicsr.archs import build_network
from basicsr.losses import build_loss
from basicsr.metrics import calculate_metric
from basicsr.utils import get_root_logger, imwrite, tensor2img
from basicsr.utils.img_util import tensor_lab2rgb
from basicsr.utils.dist_util import master_only
from basicsr.utils.registry import MODEL_REGISTRY
from .base_model import BaseModel
from basicsr.metrics.custom_fid import INCEPTION_V3_FID, get_activations, calculate_activation_statistics, calculate_frechet_distance
from basicsr.utils.color_enhance import color_enhacne_blend@MODEL_REGISTRY.register()
class ColorModel(BaseModel):"""Colorization model for single image colorization."""def __init__(self, opt):super(ColorModel, self).__init__(opt)# define network net_gself.net_g = build_network(opt['network_g'])self.net_g = self.model_to_device(self.net_g)self.print_network(self.net_g)# load pretrained model for net_gload_path = self.opt['path'].get('pretrain_network_g', None)if load_path is not None:param_key = self.opt['path'].get('param_key_g', 'params')self.load_network(self.net_g, load_path, self.opt['path'].get('strict_load_g', True), param_key)if self.is_train:self.init_training_settings()def init_training_settings(self):train_opt = self.opt['train']self.ema_decay = train_opt.get('ema_decay', 0)if self.ema_decay > 0:logger = get_root_logger()logger.info(f'Use Exponential Moving Average with decay: {self.ema_decay}')# define network net_g with Exponential Moving Average (EMA)# net_g_ema is used only for testing on one GPU and saving# There is no need to wrap with DistributedDataParallelself.net_g_ema = build_network(self.opt['network_g']).to(self.device)# load pretrained modelload_path = self.opt['path'].get('pretrain_network_g', None)if load_path is not None:self.load_network(self.net_g_ema, load_path, self.opt['path'].get('strict_load_g', True), 'params_ema')else:self.model_ema(0) # copy net_g weightself.net_g_ema.eval()# define network net_dself.net_d = build_network(self.opt['network_d'])self.net_d = self.model_to_device(self.net_d)self.print_network(self.net_d)# load pretrained model for net_dload_path = self.opt['path'].get('pretrain_network_d', None)if load_path is not None:param_key = self.opt['path'].get('param_key_d', 'params')self.load_network(self.net_d, load_path, self.opt['path'].get('strict_load_d', True), param_key)self.net_g.train()self.net_d.train()# define lossesif train_opt.get('pixel_opt'):self.cri_pix = build_loss(train_opt['pixel_opt']).to(self.device)else:self.cri_pix = Noneif train_opt.get('perceptual_opt'):self.cri_perceptual = build_loss(train_opt['perceptual_opt']).to(self.device)else:self.cri_perceptual = Noneif train_opt.get('gan_opt'):self.cri_gan = build_loss(train_opt['gan_opt']).to(self.device)else:self.cri_gan = Noneif self.cri_pix is None and self.cri_perceptual is None:raise ValueError('Both pixel and perceptual losses are None.')if train_opt.get('colorfulness_opt'):self.cri_colorfulness = build_loss(train_opt['colorfulness_opt']).to(self.device)else:self.cri_colorfulness = None# set up optimizers and schedulersself.setup_optimizers()self.setup_schedulers()# set real dataset cache for fid metric computingself.real_mu, self.real_sigma = None, Noneif self.opt['val'].get('metrics') is not None and self.opt['val']['metrics'].get('fid') is not None:self._prepare_inception_model_fid()def setup_optimizers(self):train_opt = self.opt['train']# optim_params_g = []# for k, v in self.net_g.named_parameters():# if v.requires_grad:# optim_params_g.append(v)# else:# logger = get_root_logger()# logger.warning(f'Params {k} will not be optimized.')optim_params_g = self.net_g.parameters()# optimizer goptim_type = train_opt['optim_g'].pop('type')self.optimizer_g = self.get_optimizer(optim_type, optim_params_g, **train_opt['optim_g'])self.optimizers.append(self.optimizer_g)# optimizer doptim_type = train_opt['optim_d'].pop('type')self.optimizer_d = self.get_optimizer(optim_type, self.net_d.parameters(), **train_opt['optim_d'])self.optimizers.append(self.optimizer_d)def feed_data(self, data):self.lq = data['lq'].to(self.device)self.lq_rgb = tensor_lab2rgb(torch.cat([self.lq, torch.zeros_like(self.lq), torch.zeros_like(self.lq)], dim=1))if 'gt' in data:self.gt = data['gt'].to(self.device)self.gt_lab = torch.cat([self.lq, self.gt], dim=1)self.gt_rgb = tensor_lab2rgb(self.gt_lab)if self.opt['train'].get('color_enhance', False):for i in range(self.gt_rgb.shape[0]):self.gt_rgb[i] = color_enhacne_blend(self.gt_rgb[i], factor=self.opt['train'].get('color_enhance_factor'))def optimize_parameters(self, current_iter):# optimize net_gfor p in self.net_d.parameters():p.requires_grad = Falseself.optimizer_g.zero_grad()self.output_ab = self.net_g(self.lq_rgb)self.output_lab = torch.cat([self.lq, self.output_ab], dim=1)self.output_rgb = tensor_lab2rgb(self.output_lab)l_g_total = 0loss_dict = OrderedDict()# pixel lossif self.cri_pix:l_g_pix = self.cri_pix(self.output_ab, self.gt)l_g_total += l_g_pixloss_dict['l_g_pix'] = l_g_pix# perceptual lossif self.cri_perceptual:l_g_percep, l_g_style = self.cri_perceptual(self.output_rgb, self.gt_rgb)if l_g_percep is not None:l_g_total += l_g_perceploss_dict['l_g_percep'] = l_g_percepif l_g_style is not None:l_g_total += l_g_styleloss_dict['l_g_style'] = l_g_style# gan lossif self.cri_gan:fake_g_pred = self.net_d(self.output_rgb)l_g_gan = self.cri_gan(fake_g_pred, target_is_real=True, is_disc=False)l_g_total += l_g_ganloss_dict['l_g_gan'] = l_g_gan# colorfulness lossif self.cri_colorfulness:l_g_color = self.cri_colorfulness(self.output_rgb)l_g_total += l_g_colorloss_dict['l_g_color'] = l_g_colorl_g_total.backward()self.optimizer_g.step()# optimize net_dfor p in self.net_d.parameters():p.requires_grad = Trueself.optimizer_d.zero_grad()real_d_pred = self.net_d(self.gt_rgb)fake_d_pred = self.net_d(self.output_rgb.detach())l_d = self.cri_gan(real_d_pred, target_is_real=True, is_disc=True) + self.cri_gan(fake_d_pred, target_is_real=False, is_disc=True)loss_dict['l_d'] = l_dloss_dict['real_score'] = real_d_pred.detach().mean()loss_dict['fake_score'] = fake_d_pred.detach().mean()l_d.backward()self.optimizer_d.step()self.log_dict = self.reduce_loss_dict(loss_dict)if self.ema_decay > 0:self.model_ema(decay=self.ema_decay)def get_current_visuals(self):out_dict = OrderedDict()out_dict['lq'] = self.lq_rgb.detach().cpu()out_dict['result'] = self.output_rgb.detach().cpu()if self.opt['logger'].get('save_snapshot_verbose', False): # only for verboseself.output_lab_chroma = torch.cat([torch.ones_like(self.lq) * 50, self.output_ab], dim=1)self.output_rgb_chroma = tensor_lab2rgb(self.output_lab_chroma)out_dict['result_chroma'] = self.output_rgb_chroma.detach().cpu()if hasattr(self, 'gt'):out_dict['gt'] = self.gt_rgb.detach().cpu()if self.opt['logger'].get('save_snapshot_verbose', False): # only for verboseself.gt_lab_chroma = torch.cat([torch.ones_like(self.lq) * 50, self.gt], dim=1)self.gt_rgb_chroma = tensor_lab2rgb(self.gt_lab_chroma)out_dict['gt_chroma'] = self.gt_rgb_chroma.detach().cpu()return out_dictdef test(self):if hasattr(self, 'net_g_ema'):self.net_g_ema.eval()with torch.no_grad():self.output_ab = self.net_g_ema(self.lq_rgb)self.output_lab = torch.cat([self.lq, self.output_ab], dim=1)self.output_rgb = tensor_lab2rgb(self.output_lab)else:self.net_g.eval()with torch.no_grad():self.output_ab = self.net_g(self.lq_rgb)self.output_lab = torch.cat([self.lq, self.output_ab], dim=1)self.output_rgb = tensor_lab2rgb(self.output_lab)self.net_g.train()def dist_validation(self, dataloader, current_iter, tb_logger, save_img):if self.opt['rank'] == 0:self.nondist_validation(dataloader, current_iter, tb_logger, save_img)def nondist_validation(self, dataloader, current_iter, tb_logger, save_img):dataset_name = dataloader.dataset.opt['name']with_metrics = self.opt['val'].get('metrics') is not Noneuse_pbar = self.opt['val'].get('pbar', False)if with_metrics and not hasattr(self, 'metric_results'): # only execute in the first runself.metric_results = {metric: 0 for metric in self.opt['val']['metrics'].keys()}# initialize the best metric results for each dataset_name (supporting multiple validation datasets)if with_metrics:self._initialize_best_metric_results(dataset_name)# zero self.metric_resultsif with_metrics:self.metric_results = {metric: 0 for metric in self.metric_results}metric_data = dict()if use_pbar:pbar = tqdm(total=len(dataloader), unit='image')if self.opt['val']['metrics'].get('fid') is not None:fake_acts_set, acts_set = [], []for idx, val_data in enumerate(dataloader):# if idx == 100:# breakimg_name = osp.splitext(osp.basename(val_data['lq_path'][0]))[0]if hasattr(self, 'gt'):del self.gtself.feed_data(val_data)self.test()visuals = self.get_current_visuals()sr_img = tensor2img([visuals['result']])metric_data['img'] = sr_imgif 'gt' in visuals:gt_img = tensor2img([visuals['gt']])metric_data['img2'] = gt_imgtorch.cuda.empty_cache()if save_img:if self.opt['is_train']:save_dir = osp.join(self.opt['path']['visualization'], img_name)for key in visuals:save_path = os.path.join(save_dir, '{}_{}.png'.format(current_iter, key))img = tensor2img(visuals[key])imwrite(img, save_path)else:if self.opt['val']['suffix']:save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,f'{img_name}_{self.opt["val"]["suffix"]}.png')else:save_img_path = osp.join(self.opt['path']['visualization'], dataset_name,f'{img_name}_{self.opt["name"]}.png')imwrite(sr_img, save_img_path)if with_metrics:# calculate metricsfor name, opt_ in self.opt['val']['metrics'].items():if name == 'fid':pred, gt = visuals['result'].cuda(), visuals['gt'].cuda()fake_act = get_activations(pred, self.inception_model_fid, 1)fake_acts_set.append(fake_act)if self.real_mu is None:real_act = get_activations(gt, self.inception_model_fid, 1)acts_set.append(real_act)else:self.metric_results[name] += calculate_metric(metric_data, opt_)if use_pbar:pbar.update(1)pbar.set_description(f'Test {img_name}')if use_pbar:pbar.close()if with_metrics:if self.opt['val']['metrics'].get('fid') is not None:if self.real_mu is None:acts_set = np.concatenate(acts_set, 0)self.real_mu, self.real_sigma = calculate_activation_statistics(acts_set)fake_acts_set = np.concatenate(fake_acts_set, 0)fake_mu, fake_sigma = calculate_activation_statistics(fake_acts_set)fid_score = calculate_frechet_distance(self.real_mu, self.real_sigma, fake_mu, fake_sigma)self.metric_results['fid'] = fid_scorefor metric in self.metric_results.keys():if metric != 'fid':self.metric_results[metric] /= (idx + 1)# update the best metric resultself._update_best_metric_result(dataset_name, metric, self.metric_results[metric], current_iter)self._log_validation_metric_values(current_iter, dataset_name, tb_logger)def _log_validation_metric_values(self, current_iter, dataset_name, tb_logger):log_str = f'Validation {dataset_name}\n'for metric, value in self.metric_results.items():log_str += f'\t # {metric}: {value:.4f}'if hasattr(self, 'best_metric_results'):log_str += (f'\tBest: {self.best_metric_results[dataset_name][metric]["val"]:.4f} @ 'f'{self.best_metric_results[dataset_name][metric]["iter"]} iter')log_str += '\n'logger = get_root_logger()logger.info(log_str)if tb_logger:for metric, value in self.metric_results.items():tb_logger.add_scalar(f'metrics/{dataset_name}/{metric}', value, current_iter)def _prepare_inception_model_fid(self, path='pretrain/inception_v3_google-1a9a5a14.pth'):incep_state_dict = torch.load(path, map_location='cpu')block_idx = INCEPTION_V3_FID.BLOCK_INDEX_BY_DIM[2048]self.inception_model_fid = INCEPTION_V3_FID(incep_state_dict, [block_idx])self.inception_model_fid.cuda()self.inception_model_fid.eval()@master_onlydef save_training_images(self, current_iter):visuals = self.get_current_visuals()save_dir = osp.join(self.opt['root_path'], 'experiments', self.opt['name'], 'training_images_snapshot')os.makedirs(save_dir, exist_ok=True)for key in visuals:save_path = os.path.join(save_dir, '{}_{}.png'.format(current_iter, key))img = tensor2img(visuals[key])imwrite(img, save_path)def save(self, epoch, current_iter):if hasattr(self, 'net_g_ema'):self.save_network([self.net_g, self.net_g_ema], 'net_g', current_iter, param_key=['params', 'params_ema'])else:self.save_network(self.net_g, 'net_g', current_iter)self.save_network(self.net_d, 'net_d', current_iter)self.save_training_state(epoch, current_iter)第四步:運行
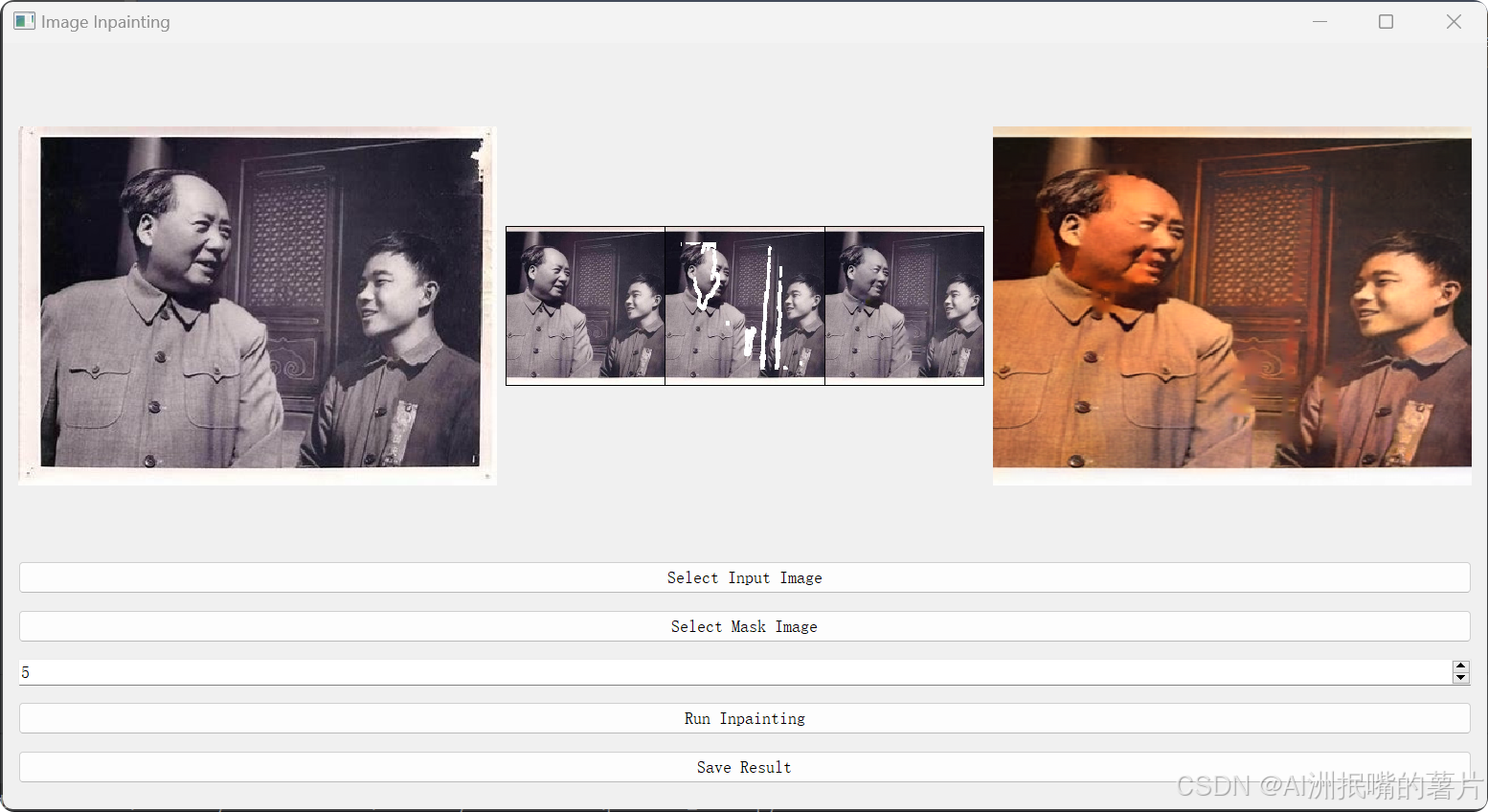
第五步:整個工程的內容
??項目完整文件下載請見演示與介紹視頻的簡介處給出:???
圖像修復:深度學習實現老照片劃痕修復+老照片上色_嗶哩嗶哩_bilibili
?



)


)

)



Task2 筆記:用戶新增預測挑戰賽 —— 從業務理解到技術實現)

)



STL:stack、queue簡單使用解析)
