前言:
????????上次介紹完二叉搜索樹后,更新中斷了一段時間,先向大家致歉。最近學習狀態有些起伏,但我正在努力調整,相信很快會恢復節奏。今天我們繼續深入探討——關聯容器,它在算法和工程中都非常常見和重要。
1.之前的遺漏
????????我之前寫的二叉搜索樹其實沒有寫完,我僅僅寫了一個節點只能存儲一個值的二叉搜索樹。在我們日常的工作中,這種樹的使用率其實還是比較低的。最受歡迎的是里面存儲兩個值的二叉搜索樹,這個可以類比Python中的字典。相信學過python的讀者對此不陌生,字典其實存放了一對值,分別是Key和Value,類比英文字典中的英語和漢字,我們通過英文(Key)來找到對應的中文(Value)。這其實才是我們常使用到的二叉搜索樹,下面我通過舉例來幫助各位理解這兩棵樹的區別。
1.1.Key搜索場景
????????舉個例子,現在很多小區配有地下停車庫。業主的車牌號會錄入系統中,車輛進入時由系統識別并判斷是否允許進入。這就是典型的 Key 搜索場景 —— 只需根據一個關鍵字(車牌號)進行查找。
1.2.Key/Value搜索場景
????????還是以我們的生活舉例,如今我們進入各大商場的時候,如果開車的話難免會需要停進商場專用的停車場,此時這就是停車場計費系統,我們需要錄入兩個值:車子的車牌號以及入場時間,記錄好之后,當車輛想要離開停車場的時候,就會通過車牌(Key)來進行系統中管理的車輛信息進行檢索,檢索成功后會根據當前的時間減去入場的時間計算出車輛在停車場呆過的時間,從而計算出需要交付的金額。這邊是Key/Value的搜索場景,Key其實不是關鍵,其中的Value才是關鍵,Key更像是一個標識符,我們通過這個符號來進行真正數據的獲取。所以可以看出,它在我們日常的生活中使用的頻率更大。
1.3.Key/Value類型的二叉搜索樹的源碼
????????由于難度不大,小編就不講其中的細節了,其實它和上篇我們講述的Key類型的二叉搜索數一樣,只不過多了一個Value而已。
#include<iostream>
#include<vector>
?
using namespace std;
template<class K, class V>
struct BSTNode
{// pair<K, V> _kv;K _key;V _value;BSTNode<K, V>* _left;BSTNode<K, V>* _right;BSTNode(const K& key, const V& value):_key(key), _value(value), _left(nullptr), _right(nullptr){}
};
template<class K, class V>
class BSTree
{typedef BSTNode<K, V> Node;
public:BSTree() = default;BSTree(const BSTree<K, V>& t){_root = Copy(t._root);}BSTree<K, V>& operator=(BSTree<K, V> t){swap(_root, t._root);return *this;}~BSTree(){Destroy(_root);_root = nullptr;}bool Insert(const K& key, const V& value){if (_root == nullptr){_root = new Node(key, value);return true;}Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{return false;}}cur = new Node(key, value);if (parent->_key < key){parent->_right = cur;}else{parent->_left = cur;}return true;}Node* Find(const K& key){Node* cur = _root;while (cur){if (cur->_key < key){cur = cur->_right;}else if (cur->_key > key){cur = cur->_left;}else{return cur;}}return nullptr;}bool Erase(const K& key){Node* parent = nullptr;Node* cur = _root;while (cur){if (cur->_key < key){parent = cur;cur = cur->_right;}else if (cur->_key > key){parent = cur;cur = cur->_left;}else{if (cur->_left == nullptr){if (parent == nullptr){_root = cur->_right;}else{if (parent->_left == cur)parent->_left = cur->_right;elseparent->_right = cur->_right;}delete cur;return true;}else if (cur->_right == nullptr){if (parent == nullptr){_root = cur->_left;}else{if (parent->_left == cur)parent->_left = cur->_left;elseparent->_right = cur->_left;}delete cur;return true;}else{Node* rightMinP = cur;Node* rightMin = cur->_right;while (rightMin->_left){rightMinP = rightMin;rightMin = rightMin->_left;}cur->_key = rightMin->_key;if (rightMinP->_left == rightMin)rightMinP->_left = rightMin->_right;elserightMinP->_right = rightMin->_right;delete rightMin;return true;}}}return false;}void InOrder(){_InOrder(_root);cout << endl;}private:void _InOrder(Node* root){if (root == nullptr){return;}_InOrder(root->_left);cout << root->_key << ":" << root->_value << endl;_InOrder(root->_right);}void Destroy(Node* root){if (root == nullptr)return;Destroy(root->_left);Destroy(root->_right);delete root;}Node* Copy(Node* root){if (root == nullptr)return nullptr;Node* newRoot = new Node(root->_key, root->_value);newRoot->_left = Copy(root->_left);newRoot->_right = Copy(root->_right);return newRoot;}private:Node* _root = nullptr;};????????以上便就是對上節課知識點的補充,下面我們就進入本文章正式的部分。
2.序列式容器和關聯式容器
????????想必各位讀者看我文章的題目時,會有疑問:關聯式容器是什么玩意?其實很好理解,它的名字就點出了這個容器一個重要的特性:這個容器的數據應該是有關聯性!下面我就分別說說序列式容器和關聯式容器
1.序列式容器
????????小編在之前講述了很多STL的容器,就比如:vector,list,dequeue,array等等,這些有個統一的名稱:序列式容器,因為他們的邏輯結構是線性的,相鄰兩個位置存儲的元素一般是沒有關聯的,如果我們把第一個元素和最后一個元素交換之后,它還是序列式容器。順序容器中的元素是按他們在容器中的存儲位置來順序保存和訪問的。
2.關聯式容器
????????關聯式容器也是用來存儲數據的容器,和序列式容器不同的是,關聯式容器的邏輯結構通常是非線性的,它存儲的兩個元素是有很強的關聯關系的(map就是),如果我們把兩個位置的元素進行交換,那么存儲結構就被破壞了。順序容器中的元素是按關鍵字來保存和訪問的。關聯式容器有map/set系列,后續也有一個系列也是關聯式容器,這里我先淺淺的賣個關子,等到后期再給各位揭開謎底。
3.set容器的使用
3.1.set類的介紹
????????首先我們先進行set容器的講解,因為它對比map容器,它的很多功能都是很簡單的。它對應的是Key版本的二叉搜索樹,這就說明這個容器存儲的就是僅僅帶有關鍵字的容器,我們可以看一下set源碼的聲明。
template < class T, // set::key_type/value_type
class Compare = less<T>, // set::key_compare/value_compare
class Alloc = allocator<T> // set::allocator_type
> class set;????????其中的T代表著set存儲的類型,第二個參數代表著一個仿函數:這個仿函數是進行大小比較的,默認less代表著set所代表的樹存儲的值是左邊比右邊小;第三個是空間分配器,這個目前可以忽視。這邊是set的聲明,一般的情況下,后面兩個我們一般用不上,用默認的就好。
????????容器的講解我們往往會涉及到底層,set的底層其實是我們之后要學習的紅黑樹學習的,這是一顆比二叉搜索樹還牛逼的一種樹,set增刪查改的效率是O(logN),容器的遍歷是走的中序遍歷,所以我們存入數據后,遍歷一遍得到的數據為一組有序的數據。這些都是set的基礎知識,各位了解就好,下面我們進入更加重要的部分:相關接口的介紹。
3.2.相關的接口
1.構造函數
????????對于一個容器,我們最先講的自然就是如何構建它,所以構建函數的介紹往往是容器介紹的開始,下面小編分別說說他的構造函數。
1.無參構造
????????這個比較簡單,我們僅需定義好set類型對象的名字即可,下面我們先來看一下關于其源碼中構造函數是如何進行聲明的。
// empty (1) ?參默認構造
explicit set (const key_compare& comp = key_compare(),
const allocator_type& alloc = allocator_type());????????其用法如下:
std :: set<int> s1; //這個存儲的int類型的對象2.迭代器區間構造
// range (2) 迭代器區間構造
template <class InputIterator>
set (InputIterator first, InputIterator last,
const key_compare& comp = key_compare(),
const allocator_type& = allocator_type());????????相對于無參構造,迭代器區間構造使用的比較多一些,它的用法和vector迭代器區間構造是類似的,在這里我就不詳細介紹了,您只需知道,此時這個的區間構造類似于vector就好,下面我展示它的用法:
std :: set<int> s1({12,34,13,54,77}); ?
3.值得注意的點????????對了,小編剛才忘記講了,set和小編之前實現的二叉搜索樹一樣,它不支持相同的值插入(即不支持值冗余),所以當我們插入相同的值的時候,它就會覆蓋相同的值。這點請記住,如果想要冗余,那么就需要用到另一個類似set的容器——multiset,這個小編不打算精講,文章末我可能會講述。
4.拷貝構造函數
????????有構造函數,自然需要用到拷貝構造函數,如果沒有拷貝構造函數的話,那么我們就只能淺拷貝,淺拷貝往往會造成不可逆的錯誤,就比如析構同一塊空間等等,當然,這里涉及的知識點我之前講過,現在講就當溫故而知新了,下面看看源碼中拷貝構造函數的聲明。
// copy (3) 拷?構造
set (const set& x);????????此時我們僅需把一個set類型的對象傳給另一個需要拷貝構造的對象即可,這部分與前述類似,讀者可參考 vector 使用方法。
std :: set<int> s1({1,2,43,4,5,13});
std :: set<int> s2 = s1; ?//或者是s1(s2) 這樣我認為比較low,不優美5.列表構造
// initializer list (5) initializer 列表構造
set (initializer_list<value_type> il,const key_compare& comp = key_compare(),const allocator_type& alloc = allocator_type());????????在使用 C++ 中的 set 類進行列表構造時,實際上涉及到了拷貝構造函數和構造函數的相關知識。此時,我們可以通過使用一個用花括號 {} 包裹的初始化列表,其中包含我們希望插入到 set 中的元素。該初始化列表會作為參數傳遞給 set 的構造函數,從而構造出對應的 set 對象。最后通過拷貝構造給予我們定義的對象
std :: set<int> s1 = {1,2,43,4,5,13}; //這個用法其實走了一層拷貝構造函數以及構造函數,具體怎么走的,我會在后來的文章說明的2.迭代器
set 容器的迭代器是一個雙向迭代器,這一點可能讓不少讀者產生疑惑:“啥是雙向的?是不是能倒車?”別急,我們先來理一理 C++ 中迭代器的“家族譜系”,搞清楚它們的“社會階層”,你就明白了。
🧭 C++ 迭代器的五大家族
C++ 標準庫中,迭代器被按功能劃分為以下五類,從“最低級搬磚工”到“全能打工人”不等:
-
輸入迭代器(Input Iterator)
-
只能向前走一步,看一眼數據,過目即忘。
-
常用于只讀算法,如
std::istream_iterator。
-
-
輸出迭代器(Output Iterator)
-
也是只能向前走,但它不讀,只寫。
-
比如
std::ostream_iterator。
-
-
前向迭代器(Forward Iterator)
-
可以多次讀寫,也可以反復訪問一個位置,但依舊只能往前。
-
比如
std::forward_list的迭代器。
-
-
雙向迭代器(Bidirectional Iterator)
-
可以前進,也可以后退,一進一退如跳探戈。
-
std::set、std::list等容器的迭代器就屬于這一類。
-
-
隨機訪問迭代器(Random Access Iterator)
-
簡直就是迭代器界的“高鐵”——不僅能前后移動,還能跳躍式訪問任意位置。
-
std::vector、std::deque、原始數組用的就是它。
-
????????所以,set 的迭代器雖不能瞬間跳到任意元素(它不是“隨機訪問”的),但能前能后,足以在容器中靈活地來回走動,適合遍歷和查找等操作。別看它不會飛,但在平穩可靠這方面,表現還是相當不錯的!
????????下面我們來看一下set迭代器的源碼的聲明——
iterator -> a bidirectional iterator to const value_type????????因為set是雙向迭代器,所以它是有我們熟悉的四個迭代器相關的接口:begin()、end()【正向迭代器】、rbegin()、rend()【反向迭代器】,它的用法其實和我們之前容器的使用方法是一樣的,下面我通過一個簡單的例子來給各位展現它們的用法:
正向迭代器:
set<int> s1 = { 12,4,3,5,6,89 };
auto it = s1.begin();
while (it != s1.end())
{cout << *it << " ";it++;
}
?
//運行后的結果:
3 4 5 6 12 89 ?//可以看出set其實是自帶排序的,符合我們之前二叉搜索樹中序具有排序的功能反向迭代器:
set<int> s1 = { 12,4,3,5,6,89 };
auto it = s1.rbegin();
while (it != s1.rend())
{cout << *it << " ";it++;
}
?
//運行后的結果
89 12 6 5 4 3????????想必各位已經知曉了關于set一些基礎功能的認識,下面我們進入容器重要的部分——增刪查(沒有改)的講解~
3.set的增刪查
1.關于為啥沒有改
????????這個問題可以追溯到 set背后的底層結構——二叉搜索樹(Binary Search Tree,BST)。在這種數據結構中,節點的排列遵循特定的規則:左子樹中的所有節點小于根節點,右子樹中的所有節點大于根節點。正是由于這種有序的結構,set 才能高效地進行查找、插入和刪除操作。
????????然而,一旦我們隨意修改了某個元素的值,就可能破壞這種排序關系,使整棵樹變得不再符合二叉搜索樹的性質。比如,把一個本應在左子樹的值變成了比根節點還大,那它就“走錯片場”了。這不僅會導致查找失效,還可能引發更嚴重的邏輯錯誤。
????????因此,為了保持有序性和數據結構的完整性,std::set 不允許通過迭代器或引用來修改其中元素的值。這是語言層面對“動了樹根就塌房”的一種預防機制。就像蓋了一棟講究結構力學的別墅,你不能隨手把承重墻給拆了。同樣地,set 中的元素一旦被隨意修改,整棵“樹”可能就要歪了。C++ 為了不讓你干這種“拆墻”的事,干脆一開始就不給你錘子:禁止修改元素值。
2.增相關接口
1.單個數據的插入
// 單個數據插?,如果已經存在則插?失敗
pair<iterator,bool> insert (const value_type& val);????????這里涉及的pair各位先不用較真,關于pair,我會在之后的map講解中詳細講述它,因為set用到它的時候真的不多,至于為什么它也會有pair類型,這里涉及到紅黑樹實現set時我會詳細說的(不知不覺又埋了一個坑)。
????????其實源碼就解釋了set為什么會有去重的操作,因為當我們插入相同元素的時候,它不會插入,第二個模版參數會變成false,下面小編簡單展示它的用法。
set<int> s1;
s1.insert(1);
s1.insert(13);
s1.insert(12);
s1.insert(32);
//s1里面存儲的:
1 12 13 322.列表插入
// 列表插?,已經在容器中存在的值不會插?
void insert (initializer_list<value_type> il);????????列表插入的原理其實和列表構造差不多,里面的類型就是一個列表,它的實現會在后續文章體現,這里小編就不詳細講述了。老規矩,我還是通過一個例子來給各位展示用法。
set<int> s1;
s1.insert({1,13,12,32});
//存儲結果同上:
1 12 13 323.迭代器區間插入
// 迭代器區間插?,已經在容器中存在的值不會插?
template <class InputIterator>
void insert (InputIterator first, InputIterator last);????????它的用法也是和之前的容器類似,所以小編直接上用例了。
set<int> s1;
s1.insert({1,13,12,32});
set<int> s2;
s2.insert(s1.begin(), s1.end());
//里面存儲的還是和上面的一樣????????以上就是關于set的增相關接口的介紹,其實還是蠻簡單的。
2.查相關接口
1.查找并且返回相應迭代器
// 查找val,返回val所在的迭代器,沒有找到返回end()
iterator find (const value_type& val);????????它的用法也是和之前容器一樣,這里我就不多贅述了,下面我通過兩個例子分別展示它的用法。
set<int> s1;
s1.insert({ 1,13,12,32 });
auto it = s1.find(1);
cout << *it << endl;
//結果是:
//1
set<int> s1;
s1.insert({ 1,13,12,32 });
auto it = s1.find(111);
cout << *it << endl;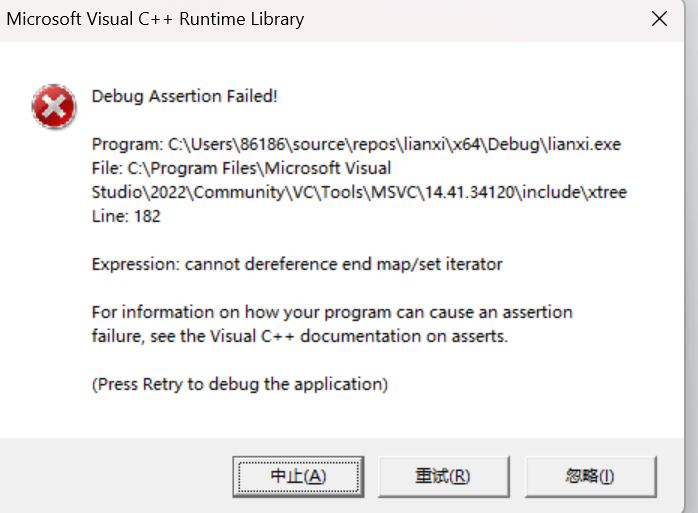
????????通過上圖就可以知道如果find里面要查的結果對象沒有,那么是會返回end()的,編譯的時候是沒有什么問題,因為語法沒有錯誤,但是當我們運行,程序直接就崩潰了~
2.查找并返回相應的迭代器
// 查找val,返回Val的個數
size_type count (const value_type& val) const;????????可能很多讀者到這就像吐槽小編:oi,狗小編,你不是說set里面的元素僅僅可以存放一個嗎?那還整什么 count 函數?你這不是忽悠人嗎?”別急別急,聽我慢慢說。雖然 std::set 是一個集合,每個元素最多只能出現一次,但 count 函數依然不是“多余的”。
set.count(x) 的作用就是:判斷元素 x 是否存在于集合中。
-
如果存在,返回
1; -
如果不存在,返回
0。
????????是的,它最多只能返回 1,但這其實就足夠用了。雖然 set 里每個元素只出現一次,但 count() 就像是一個“有沒有”檢查器,不是統計重復,而是確認存在。它不是沒用,而是剛剛好!
????????關于它的用法我就不在多展示了,和上面一樣,這里先透露一下后面的內容:后面一個算法題是會用到它的哦~
3.刪相關接口
1.根據迭代器刪除值
// 刪除?個迭代器位置的值
iterator erase (const_iterator position);????????此時雖然我們已經刪除了相應位置的值,但是我們依然會返回刪除值的迭代器,如果返回的是一個end()類型的迭代器,證明我們要刪除的值不存在;這個接口最好搭配著find接口一起食用,下面給出例子。
set<int> s1;
s1.insert({ 1,13,12,32 });
s1.erase(s1.find(13));
//很輕易2.根據值刪除
// 刪除val,val不存在返回0,存在返回1
size_type erase (const value_type& val);????????這個接口我們還是比較時常實用的,因為迭代器還是比較繁瑣的用起來,不過每個人有每個人的愛好,下面我直接展示用法:
set<int> s1;
s1.insert({ 1,13,12,32 });
s1.erase(13);
//很輕易3.刪除一段迭代器區間的值
// 刪除?段迭代器區間的值
iterator erase (const_iterator first, const_iterator last);????????這就是刪除?段迭代器區間的值 iterator erase (const_iterator first, const_iterator last);經典左閉右開區間,難度不大,下面我給出一個例子講解。
std::set<int> s = {1, 2, 3, 4, 5, 6};
auto it1 = s.find(2);
auto it2 = s.find(5);
s.erase(it1, it2); // 刪除 2、3、4????????以上就是關于set相關接口的介紹,下面為了各位更好的掌握set的用法,小編特意準備了一個算法題來幫助各位了解set在算法的使用。
4.一個算法題
? 題目 1:判斷數組中是否存在重復元素
描述: 給定一個整數數組,判斷其中是否存在重復元素。如果存在至少一個值出現至少兩次,返回 true;如果數組中每個元素都不相同,返回 false。
示例:
cpp復制編輯輸入: [1, 2, 3, 4] 輸出: false ? 輸入: [1, 2, 3, 1] 輸出: true
解法提示: 使用 std::set 自動去重的特性。
????????本題的解法其實也是蠻容易的,不知道上面的內容各位讀者是否認真閱讀了,小編在文章某個位置曾經說過,set是具有去重的能力的,此時我們就可以用到這個特性進行題目的解答。具體的步驟小編就不細說了,如果有看不懂的朋友可以加一下文末小編的微信,小編會給出解答的。
bool containsDuplicate(std::vector<int>& nums) { ? //這個題目應該來自力扣~std::set<int> s;for (int num : nums) {if (s.count(num)) return true;s.insert(num);}return false;
}5.總結
??set 是一個強大、高效、自動排序且不允許重復的關聯容器,適用于需要快速查找、無重復數據的場景,其底層紅黑樹結構保證了優秀的性能表現。如果你理解了 set,那么恭喜你,邁出了 STL 關聯容器的重要一步。接下來的 map 與 multiset、multimap 都會更加清晰易懂!
????????下節內容,我們將正式進入 map 的世界。作為 C++ STL 中最常用的鍵值對容器,map 的應用遠比 set 更廣泛,我們會重點解析其底層結構、插入/查找機制以及使用技巧,敬請期待!
? ? ? ? 本篇文章就到這里,各位大佬我們一篇文章見啦!




”no less than替代no fewer than的用法)









)





