Circuit Tracing: Revealing Computational Graphs in Language Models
![![[Pasted image 20250602202000.png]]](https://i-blog.csdnimg.cn/direct/be04273c158b481a96d85de8d4d217bb.png)
替代模型(Replacement Model):用更多的可解釋的特征來替代transformer模型的神經元。
歸因圖(Attribution Graph):展示特征之間的相互影響,能夠追蹤模型生成輸出時所采用的中間步驟。
Abstract
本文提出了一種方法,用于揭示語言模型行為背后的機制。該方法通過在一個“替代模型”中追蹤每一步計算,生成模型在特定提示上的計算過程圖。這個替代模型用一個更易解釋的組件(此處為“cross-layer transcoder”)來替代底層模型的一部分(此處為MLP),并通過訓練使其能夠近似原模型的功能。還開發了一套可視化與驗證工具,用于分析這些支持18層語言模型簡單行為的“歸因圖”,并為后續論文奠定基礎,該論文將把這些方法應用于前沿模型 Claude 3.5 Haiku 的研究中。
1 Introduction
深度學習模型通過一系列分布在眾多計算單元(人工“神經元”)上的變換來生成輸出。機制可解釋性(mechanistic interpretability)這一研究領域旨在用人類可理解的語言描述這些變換過程。到目前為止,采用的是一個“兩步法”:第一步,識別出模型在計算中使用的可解釋構建塊,即“特征”;第二步,描述這些特征之間如何交互形成模型輸出的過程,也就是“路徑”(circuit)。
模型神經元往往具有多義性(polysemantic),即一個神經元同時代表多個毫不相關的概念。導致這種多義性的重要原因之一被認為是“疊加現象”(superposition),即模型必須表示的概念數量超過了神經元的數量,因此不得不在多個神經元上“攤開”一個概念的表示。這種模型基本計算單元(神經元)與人類可理解概念之間的不匹配,嚴重阻礙了機制可解釋性研究的進展,尤其是在語言模型方面。
近年來,稀疏編碼模型(如稀疏自編碼器 sparse autoencoders,SAEs)、轉碼器(transcoders)和跨編碼器(crosscoders)等方法將模型的激活分解為稀疏激活的組成部分(即“特征”),這些特征在很多情況下與人類可理解的概念相對應。
盡管目前的稀疏編碼方法在特征識別方面還不夠完美,但它們所生成的結果已經足夠可解釋,因此我們有動力研究由這些特征組成的路徑。
本文介紹了目前采用的方法,該方法涉及多個關鍵的技術決策:
- 轉碼器(Transcoders):使用Transcoders的一種變體來提取特征,而不是使用SAEs。這能夠構建一個可解釋的“替代模型”,用來作為原始模型的代理進行研究,同時允許分析特征與特征之間的直接交互。
- 跨層結構(Cross-Layer):本文分析基于Cross-Layer Transcoder,其中每個特征從某一層的殘差流中讀取輸入,并對原始模型中所有后續的 MLP 層產生影響,這大大簡化了最終得到的路徑結構。值得注意的是,將學習到的 CLT 特征替代模型的 MLP 部分,并在約 50% 的數據下得到與原始模型相匹配的輸出。
- 歸因圖(Attribution Graphs):重點研究“歸因圖”,該圖描述了模型在特定提示詞下,為一個目標 token 生成輸出所經過的計算步驟。歸因圖中的節點代表活躍特征、提示詞中的 token 嵌入、重建誤差以及輸出 logits。圖中的邊代表節點之間的線性影響,因此每個特征的激活等于其輸入邊的總和(直到其激活閾值為止)。
- 特征之間的線性歸因:在特定輸入下,特征之間的直接交互為線性關系。這使得歸因操作有清晰且有理論依據的定義。關鍵在于凍結了注意力模式和歸一化分母,并使用transcoders來實現線性。特征之間也存在由其他特征介導的間接交互,對應于多步路徑。
- 剪枝(Pruning):盡管特征稀疏,在一個給定prompt下,仍然會有過多的活躍特征,導致歸因圖難以解釋。為了控制這一復雜度,通過識別在特定 token 位置上對模型輸出貢獻最大的節點和邊,對圖進行剪枝,生成稀疏、可解釋的模型計算圖。
- 驗證(Validation):研究路徑的方式是間接的——替代模型可能與原始模型使用了不同的機制。因此,驗證在歸因圖中發現的機制就顯得尤為重要。使用擾動實驗進行驗證,具體而言,測量在某一特征方向上施加擾動是否會引起其他特征激活(及模型輸出)中的變化,并檢查這些變化是否與歸因圖中的預測一致。
- 全局權重(Global Weights):盡管本文主要聚焦于研究單個提示詞的歸因圖,但我們的方法同樣可以直接研究替代模型中的權重(即“全局權重”),從而揭示適用于多個提示詞的機制。
2 Building an Interpretable Replacement Model
2.1 Architecture
![![[Pasted image 20250602222848.png]]](https://i-blog.csdnimg.cn/direct/6eac5f1c27b94a3983389991190ce53f.png)
圖1:CLT構成了替代模型的核心架構。
CLT由若干神經元(“特征”)構成,這些特征被劃分為與原始模型相同數量的 L L L層。該模型的目標是利用稀疏激活的特征來重建原始模型中 MLP 的輸出。每個特征從其所在層的殘差流(residual stream)中接收輸入,但其“跨層”特性在于它可以向所有后續層提供輸出。具體而言:
- 第 ? \ell ?層中的每個特征通過一個線性編碼器加上非線性激活,從該層的殘差流中“讀取”輸入。
- 第 ? \ell ?層的一個特征會參與重建第 ? , ? + 1 , … , L \ell, \ell+1, \dots, L ?,?+1,…,L層的 MLP 輸出,對每一個輸出層使用一組獨立的線性解碼器權重。
- 所有層中的所有特征是聯合訓練的。因此,某一層 ? ′ \ell' ?′的 MLP 輸出是由所有前層的特征共同重建的。
運行一個跨層轉碼器時,令 x ? x^\ell x?表示原始模型在第 ? \ell ?層的殘差流激活值,第 ? \ell ?層的 CLT 特征激活值 a ? a^\ell a?通過如下方式計算:
a ? = JumpReLU ( W enc ? x ? ) a^\ell=\text{JumpReLU}(W_\text{enc}^\ell x^\ell) a?=JumpReLU(Wenc??x?)
其中, W enc ? W_\text{enc}^\ell Wenc??是CLT在第 ? \ell ?層的編碼矩陣。
令 y ? y^\ell y?表示原始模型在第 ? \ell ?層的 MLP 輸出,CLT 對其的重建結果記作 y ^ ? \hat{y}^\ell y^??,使用 JumpReLU 激活函數進行計算:
y ^ ? = ∑ ? ′ = 1 ? W dec ? ′ → ? a ? ′ \hat{y}^\ell=\sum_{\ell'=1}^\ell W_\text{dec}^{\ell'\rightarrow \ell} a^{\ell'} y^??=?′=1∑??Wdec?′→??a?′
其中 W dec ? ′ → ? W_\text{dec}^{\ell'\rightarrow \ell} Wdec?′→??是從第 ? ′ \ell' ?′層的特征輸出到第 ? \ell ?層的CLT解碼器矩陣。
為了訓練CLT,最小化兩個損失的和。第一個是重建誤差損失(reconstruction error loss),在各層上求和:
L MSE = ∑ ? = 1 L ∥ y ^ ? ? y ? ∥ 2 L_\text{MSE}=\sum_{\ell=1}^L\|\hat{y}_\ell-y_\ell\|^2 LMSE?=?=1∑L?∥y^????y??∥2
第二個是稀疏性懲罰項(整體系數為超參數 λ \lambda λ,另一個超參數為 c c c)。在所有層上求和:
L sparsity = λ ∑ ? = 1 L ∑ i = 1 N tanh ? ( c ? ∥ W ? dec , i ∥ ? a ? i ) L_\text{sparsity}=\lambda\sum_{\ell=1}^L\sum_{i=1}^N\tanh(c\cdot\|W_\ell^{\text{dec},i}\|\cdot a_\ell^i) Lsparsity?=λ?=1∑L?i=1∑N?tanh(c?∥W?dec,i?∥?a?i?)
其中 N N N是每層的特征數量, W ? dec , i W_\ell^{\text{dec},i} W?dec,i?表示第 i i i個特征的所有解碼向量的拼接。
我們在一個小型的18層 Transformer 模型(稱為 “18L”)和 Claude 3.5 Haiku 模型上訓練了不同規模的 CLT。18L 的特征總數在 30 萬到 1000 萬之間,Haiku 的特征總數則在 30 萬到 3000 萬之間。
2.2 From Cross-Layer Transcoder to Replacement Model
在擁有一個已訓練好的CLT之后,可以定義一個“替代模型”,用CLT的特征來替代原始模型中的 MLP 神經元。這個替代模型的前向傳播過程與原始模型基本相同,只有兩個修改之處:
- 當執行到第 ? \ell ?層的 MLP 輸入時,我們計算編碼器位于第 ? \ell ?層的跨層轉碼器特征的激活;
- 當執行到第 ? \ell ?層的 MLP 輸出時,我們用來自當前層及之前各層的跨層轉碼器特征的解碼輸出總和,覆蓋掉原始的 MLP 輸出。
注意力層(Attention layers)依舊按照原樣執行,未做任何凍結或修改。盡管CLT 僅使用原始模型的輸入激活進行訓練,但在運行替代模型時,CLT 實際上是在處理來自替代模型自身的中間激活,也就是“分布外”(off-distribution)的輸入激活。
![![[Pasted image 20250603002241.png]]](https://i-blog.csdnimg.cn/direct/25d1db0ce9c04accbaebfc7328f60158.png)
圖2:替代模型是通過將原始模型的神經元替換為CLT中稀疏激活的特征而得到的。
我們衡量替代模型輸出的最可能 token 是否與原始模型一致的完成比例。該比例隨著模型規模的增加而提高,并且CLT的表現優于逐層transcoder的baseline(即每一層都有一個獨立訓練的標準單層轉碼器;所示的特征數量表示的是所有層的總特征數)。
還與一個baseline進行了對比:對神經元設置閾值,將低于該閾值的神經元置零(經驗上我們發現,激活值越高的神經元越容易解釋)。
最大的 18 層 CLT 在一個多樣化的預訓練風格提示詞數據集中(見 §R 附加評估細節)對下一個 token 的預測,與原始模型一致的比例達到了 50%。
![![[Pasted image 20250603002621.png]]](https://i-blog.csdnimg.cn/direct/af8c72cda2ca44248a03f63e102da714.png)
圖3:CLT、逐層transcoder和設定閾值的神經元在作為替代模型基礎時的top-1準確率和KL散度對比。可解釋性閾值通過排序與對比評估確定(見評估部分)。
2.3 The Local Replacement Model
替代模型與原始模型存在顯著差距,且重建誤差可能在各層之間累積。
最終目標是理解原始模型,因此希望盡可能準確地對其進行近似。為此,在研究一個固定的prompt p p p時,我們構建一個局部替代模型(local replacement model),該模型:
- 替換 MLP 層為 CLT(與替代模型相同);
- 使用原始模型在提示詞 p p p上前向傳播所得到的注意力模式和歸一化分母;
- 在每個(token位置,層)對上對CLT輸出加入一個誤差調整項,該誤差等于 CLT 對 p p p 的輸出與真實 MLP 輸出之間的差值。
進行誤差調整并凍結注意力與歸一化非線性之后,等效地用不同的基本單元“重寫”原始模型在提示詞 p p p上的計算;經過誤差修正的替代模型的所有激活值和 logit 輸出與原始模型完全一致。
然而,這不意味著局部替代模型和原始模型使用了相同的機制,可以通過比較模型對擾動的響應差異來衡量其機制差異;
將擾動行為的一致程度稱為“機制忠實度”(mechanistic faithfulness)。
局部替代模型可以被看作一個非常大的全連接神經網絡,跨越多個 token,可以在其上進行經典的路徑分析:
- 輸入是prompt中每個 token 的 one-hot 向量拼接而成;
- 神經元是所有 token 位置上激活的 CLT 特征的集合;
- 權重是從一個特征到另一個特征之間所有線性路徑的加和,包括通過殘差流和注意力路徑,但不包括 MLP 或 CLT 層。由于注意力模式和歸一化分母被凍結,從源特征的激活對目標特征的預激活的影響是線性的。有時稱這些為“虛擬權重”,因為它們并未在原始模型中顯式存在;
- 此外,該模型還包含類似偏置的節點,對應誤差項,并從每個偏置連接到模型中每個下游神經元;
- 局部替代模型中唯一的非線性操作是作用于特征預激活的函數。
局部替代模型是我們歸因圖(attribution graphs)的基礎,在這些圖中研究 CLT 特征之間在特定提示詞下的相互作用。這些圖是本文的主要研究對象。
![![[Pasted image 20250603010304.png]]](https://i-blog.csdnimg.cn/direct/0ed0c6a939384b7ea4317edf43391a94.png)
圖4:局部替代模型是在替代模型的基礎上,加入誤差項和固定的注意力模式,從而在特定提示詞上精確復現原始模型行為而得到的。
3 Attribution Graphs
本屆將在一個案例研究中介紹構建歸因圖的方法,該案例探討模型為任意標題生成縮略詞的能力。在研究的示例中,模型成功生成了一個虛構的縮略詞。
具體來說,給模型的提示是:The National Digital Analytics Group (N,并采樣其補全為:DAG。
模型使用的分詞器包含一個特殊的“大寫鎖定”符號,因此該提示和補全被分詞為:The National Digital Analytics Group ( ? n dag。
通過構建歸因圖來解釋模型如何計算并輸出 “DAG” 這個 token,歸因圖展示了信息如何從提示詞流向中間特征,最終到達輸出結果。
下圖展示了完整歸因圖的簡化示意圖。圖中底部是提示詞,頂部是模型生成的補全。方框代表一組相似的特征,懸停可以查看每個特征的可視化表示。
箭頭表示某組特征或 token 對其他特征及輸出 logit 的直接影響。
![![[Pasted image 20250603012023.png]]](https://i-blog.csdnimg.cn/direct/7635460defa747258e414fa6abe429ce.png)
圖5:18層模型生成虛構縮略詞的歸因圖簡化示意圖。
3.1 Constructing an Attribution Graph for a Prompt
為了理解局部替代模型所執行的計算過程,構建一個因果圖,描述它在特定提示詞上執行的一系列計算步驟。圖包含四類節點:
- 輸出節點:對應候選輸出詞元。我們僅為那些累計概率質量達到 95% 的詞元構建輸出節點,最多保留 10 個。
- 中間節點:對應在每個提示詞位置處被激活的CLT特征。
- 主輸入節點:對應提示詞詞元的嵌入向量。
- 附加輸入節點(“誤差節點”):對應底層模型中每個 MLP 輸出中未被 CLT 解釋的部分。
圖中的邊表示局部替代模型中的直接線性歸因。邊從特征節點、嵌入節點或誤差節點出發,終止于特征節點或輸出節點。
給定一個源特征節點 s s s和一個目標特征節點 t t t,它們之間的邊權定義為:
A s → t = a s w s → t A_{s\rightarrow t}=a_sw_{s\rightarrow t} As→t?=as?ws→t?
其中 w s → t w_{s\rightarrow t} ws→t?是虛擬權重, a s a_s as?是源特征的激活值。
在底層模型中, w s → t w_{s \rightarrow t} ws→t?是連接源特征的解碼向量到目標特征的編碼向量之間的所有線性路徑(例如通過注意力頭的輸出向量和殘差連接)的總和。
現在說明如何在實踐中使用反向 Jacobian 高效地計算這些邊權重。
設 s s s是處于第 ? s \ell_s ?s?層、上下文位置為 c s c_s cs?的源特征,令 t t t為處于 ? t \ell_t ?t?層、上下文位置為 c t c_t ct?的目標特征。記 J c s , ? s → c t , ? t ▼ J_{c_s,\ell_s\rightarrow c_t,\ell_t}^\blacktriangledown Jcs?,?s?→ct?,?t?▼?為底層模型的Jacobian,在對目標提示進行反向傳播時,對所有非線性部分(MLP 輸出、注意力模式、歸一化分母)施加 stop-gradient 操作,從 ? t \ell_t ?t?層的 c t c_t ct?位置的殘差流回傳至 ? s \ell_s ?s?層的 c s c_s cs?位置的殘差流。
從 s s s到 t t t的邊權為:
A s → t = a s w s → t = a s ∑ ? s ≤ ? < ? t ( W dec , s ? s → ? ) ? J c s , ? s → c t , ? t ▼ W enc , t ? t A_{s\rightarrow t}=a_sw_{s\rightarrow t}=a_s\sum_{\ell_s\leq\ell<\ell_t}(W_{\text{dec},s}^{\ell_s\rightarrow\ell})^\top J_{c_s,\ell_s\rightarrow c_t,\ell_t}^\blacktriangledown W_{\text{enc},t}^{\ell_t} As→t?=as?ws→t?=as??s?≤?<?t?∑?(Wdec,s?s?→??)?Jcs?,?s?→ct?,?t?▼?Wenc,t?t??
其中:
- W dec , s ? s → ? W_{\text{dec},s}^{\ell_s\rightarrow\ell} Wdec,s?s?→??是特征 s s s在寫入第 ? \ell ?層時的decoder向量;
- W enc , t ? t W_{\text{enc},t}^{\ell_t} Wenc,t?t??是特征 t t t在第 ? t \ell_t ?t?層的encoder向量。
對于其他類型的邊,計算公式類似。如嵌入-特征的邊權為 w s → t = Emb s ? J c s , ? s → c t , ? t ▼ W enc , t ? t w_{s\rightarrow t}=\text{Emb}_s^\top J_{c_s,\ell_s\rightarrow c_t,\ell_t}^\blacktriangledown W_{\text{enc},t}^{\ell_t} ws→t?=Embs??Jcs?,?s?→ct?,?t?▼?Wenc,t?t??。注意:誤差節點沒有入邊。
由于上述計算中對所有非線性模塊都施加了stop-gradient,任意特征節點 t t t的預激活值 h t h_t ht?可以通過其所有入邊直接線性求和得到: h t = ∑ S t w w → t h_t=\sum_{\mathcal{S}_t} w_{w\rightarrow t} ht?=∑St??ww→t?,其中 S t \mathcal{S}_t St?是所有出現在更早層或更早上下文位置的節點集合。因此,歸因圖的邊構成了每個特征激活的線性分解。
請注意,這些圖中不包含節點通過影響注意力模式對其他節點產生影響的信息,但包含通過凍結的注意力輸出在節點之間傳播的影響信息。換句話說,考慮了信息從一個 token 位置流向另一個位置的過程,但不考慮模型為何移動這些信息。
另請注意,跨層特征節點的出邊會聚合它在所有寫入層上對下游特征的解碼影響。
雖然替代模型中的特征是稀疏激活的(每個 token 位置大約有一百個激活特征),但歸因圖仍然過于龐大,難以完整可視化,特別是在提示長度增加時 —— 即使是較短的提示,其邊的數量也可能達到百萬級。幸運的是,一個小的子圖通常就能解釋大部分從輸入到輸出的重要路徑。
為了識別這樣的子圖,我們應用了一種剪枝算法,旨在保留那些直接或間接對 logit 節點產生顯著影響的節點和邊。
在默認參數下,通常能將節點數減少到原來的十分之一,同時僅減少約 20% 的可解釋行為。
3.4 Grouping Features into Supernodes
歸因圖中常常包含一組特征,它們共享與提示詞相關的某個方面。例如,在我們的提示詞中,“Digital”一詞上有三個活躍的特征,它們分別對“digital”這個詞在不同大小寫和上下文中作出響應。對于這個提示詞而言,唯一重要的方面是這個詞以字母 “D” 開頭;這三個特征都對同一組下游節點有正向影響。因此,在分析這個提示詞時,將這些特征歸為一組并作為一個整體來看是有意義的。
在可視化和分析過程中,發現將多個節點(即特征與上下文位置的組合)合并為一個“超級節點”更為方便。這些超級節點對應于我們上方展示的簡化示意圖中的方框,為方便起見,下方也再次展示了該圖。
![![[Pasted image 20250603025145.png]]](https://i-blog.csdnimg.cn/direct/9e77b350c88b43f6b2e28f9cbcd14c8d.png)
圖8:一個簡化的歸因圖示例,展示了18層模型在補全一個虛構縮略詞時的歸因過程。
用于對節點進行分組的策略取決于具體的分析任務,以及特征在給定提示中的作用。根據我們對機制的解釋重點不同,有時會將激活于相似上下文的特征、具有相似嵌入或logit影響的特征,或具有相似輸入/輸出邊的特征歸為一組。
通常希望超級節點中的各個節點彼此之間是促進關系,且它們對下游節點的影響具有相同的符號。雖然嘗試過一些自動化策略,例如基于解碼器向量或圖的鄰接矩陣進行聚類,但沒有一種自動方法能夠涵蓋說明某些機制性結論所需的各種特征分組。因此采用人工方式構建這些分組。
3.5 Validating Attribution Graph Hypotheses with Interventions
在歸因圖中,節點表示哪些特征對模型輸出具有重要作用,而邊則表示這些特征是如何發揮作用的。可以通過對底層模型中的特征進行擾動,并檢查其對下游特征或模型輸出的影響是否與歸因圖中的預測一致,從而驗證歸因圖中的結論。對特征的干預可以通過修改其計算得到的激活值,并用修改后的解碼結果替代原始重構來實現。
CLT中的特征會寫入多個輸出層,因此需要決定在哪些層中執行干預。該如何選擇這個層的范圍?可以像處理單層transcoder那樣,只在一個層上對特征的解碼結果進行干預,但歸因圖中的邊代表的是多個層的解碼累積效果,因此只在單層干預只能覆蓋某條邊的一個子集。此外,通常希望同時干預多個特征,而超級節點中的不同特征會在不同的層中被解碼。
為了在層范圍內執行干預,我們會在給定范圍內的每一層上修改目標特征的解碼結果,然后從該范圍的最后一層開始進行前向傳播。由于不會根據范圍中更早干預的結果重新計算某一層的MLP輸出,因此模型MLP輸出中唯一的變化就是我們的干預。
將這種方法稱為“受限補丁(constrained patching)”,因為它不允許干預在補丁范圍內產生二階效應。
下圖展示了“受限補丁”的一種乘法版本,其中我們在層范圍 [ ? ? 1 , ? ] [\ell-1,\ell] [??1,?]中將目標特征的激活乘以 M M M。需要注意的是,更后續層的 MLP 輸出不會被這個補丁直接影響。
![![[Pasted image 20250603030118.png]]](https://i-blog.csdnimg.cn/direct/5e826c184152479bb3f39460cad7a708.png)
圖9:乘法補丁的示意圖。
歸因圖是基于底層模型的注意力模式構建的,因此圖中的邊不考慮通過 QK 回路傳遞的影響。
同樣地,在擾動實驗中,將注意力模式固定為未經擾動的前向傳播中觀察到的值。這一方法選擇意味著我們的結果不包括擾動可能對注意力模式本身造成的影響。
回到我們構造的首字母縮略詞提示詞上,我們展示了對超級節點進行補丁處理的結果,首先是抑制“Group”超級節點。下圖中,將補丁效果疊加在超級節點示意圖上,以提高清晰度,顯示其對其他超級節點和 logit 分布的影響。請注意,在該圖中,節點的位置除非特別標注,否則不代表對應的 token 位置。
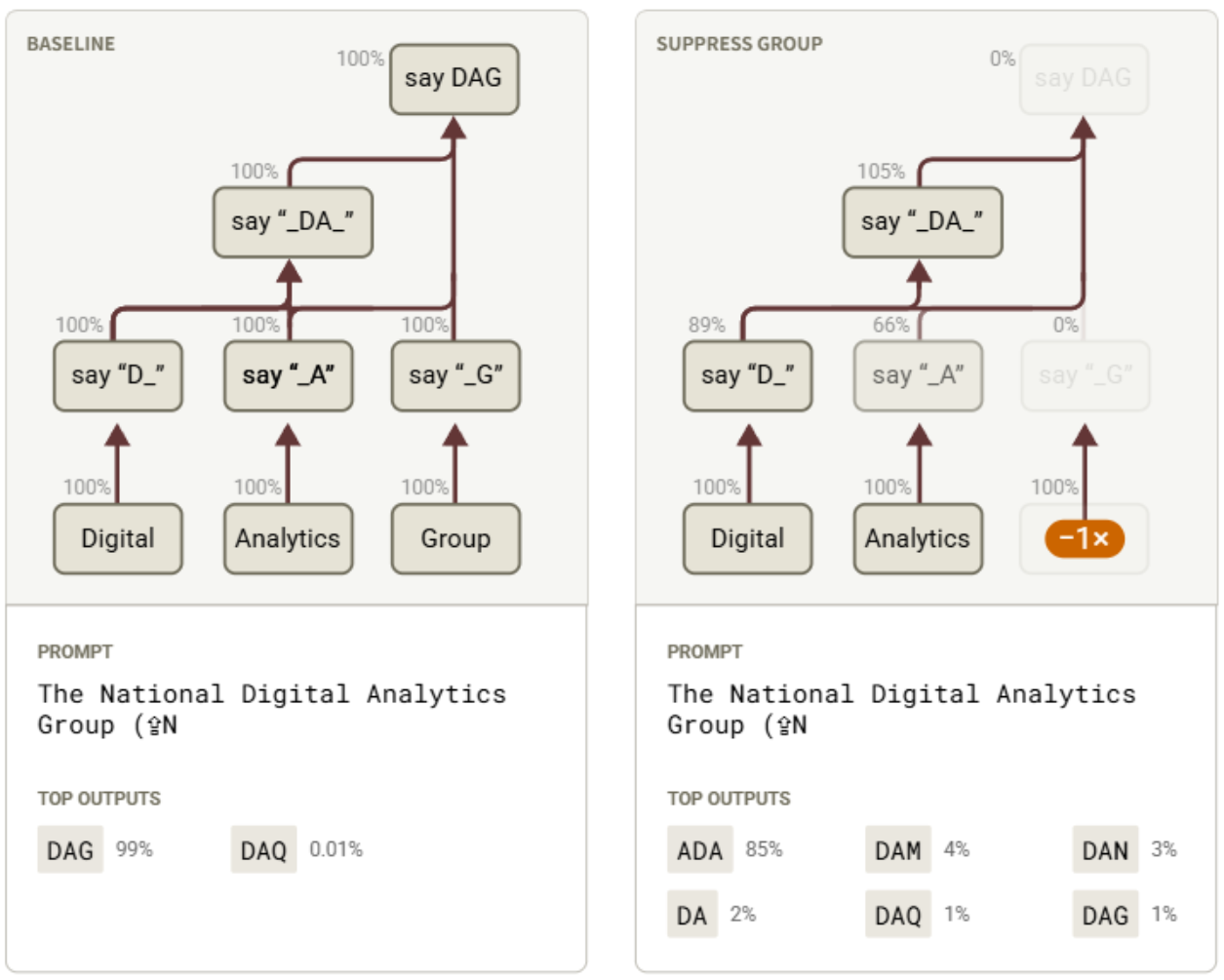
圖10:抑制虛構組織名稱中的單詞 “Group” 會導致 18L 輸出其他包含 “DA” 的縮略詞。
3.6 Localizing Important Layers
歸因圖還能夠識別出某一特征的解碼在哪些層級上對最終 logit 的下游影響最大。例如,“Analytics”(分析)超級節點中的特征,主要是通過中間特征群組間接影響 “dag” 的 logit,這些中間特征群組包括 “say A”、“say DA” 和 “say DAG”,它們主要分布在第 13 層及之后的層級中。
這一現象表明,特征的影響并非僅由其直接解碼位置決定,而是在網絡深層通過特征聯動與組合,在語義構建上形成更復雜的協同效應。這也是理解跨層特征行為和層級解碼依賴關系的關鍵所在。
因此,預計對“Analytics”特征進行負向引導時,對“dag” logit 的影響將在第13層之前達到平臺期,然后隨著接近最后一層而減弱。
影響減弱的原因在于干預方式的約束性。如果補丁范圍涵蓋了所有“say an acronym”特征,由于約束性補丁不允許產生連鎖反應,其激活狀態將不會改變。
下圖展示了對每個“Analytics”特征進行引導時的效果,起始層固定為1,補丁結束層逐層變化。
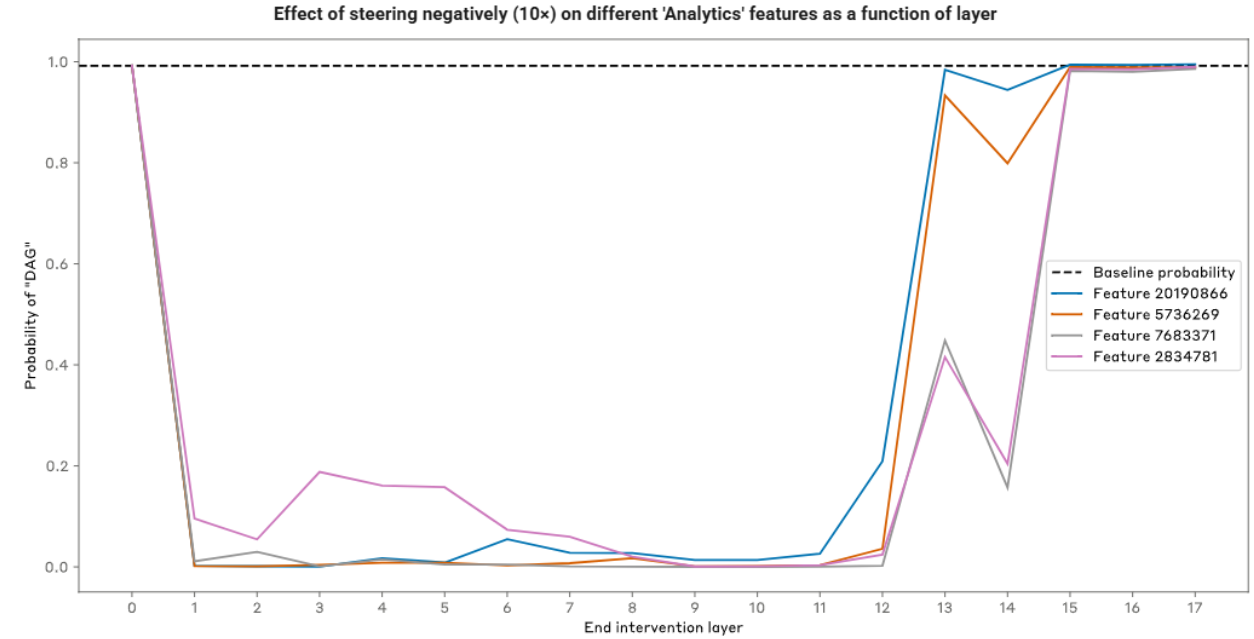
圖12:干預在包含“say an acronym”特征的層之前進行時效果最佳。
4 Global Weights
構建的歸因圖展示了特征如何在特定提示下相互作用以產生模型的輸出,但我們也對特征在所有上下文中如何相互作用的更全局圖景感興趣。
在經典的多層感知機中,全局交互由模型的權重提供:如果神經元位于連續層之間,一個神經元對另一個神經元的直接影響就是它們之間的權重;如果神經元相距較遠,一個神經元對另一個神經元的影響則通過中間層傳遞。
在本文設置中,特征之間的交互既包含上下文無關的成分,也包含上下文相關的成分。理想情況下,希望同時捕捉這兩者:希望獲得一組上下文無關的全局權重,同時也能反映網絡在所有可能上下文中的行為。
本節分析上下文無關的成分(一種“虛擬權重”)、它們存在的問題(存在無因果分布效應的大量“干擾”項),以及一種利用共激活統計來處理干擾的方法。
在一個特定的提示上,一個源 CLT 特征(記作?s)通過三種路徑影響一個目標特征(記作?t):
- 殘差-直接路徑(residual-direct):
s的解碼器將信息寫入殘差流,隨后被t的編碼器在后續層中讀取。 - 注意力-直接路徑(attention-direct):
s的解碼器將信息寫入殘差流,這些信息通過若干注意力頭的 OV 步傳遞,最終被t的編碼器讀取。 - 間接路徑(indirect):
從s到t的路徑由其他 CLT 特征進行中介。
注意到,殘差-直接路徑的影響可以簡化為:該提示上第一個特征的激活值乘以一個在不同輸入之間保持一致的虛擬權重。 這些虛擬權重因其一致性關系而構成了一種簡單形式的全局權重。
對于 CLT 特征,兩個特征之間的虛擬權重是下游特征的編碼器與兩者之間所有解碼器之和的內積。
不過,虛擬權重存在一個主要問題:干擾(interference)。
由于很多的特征都通過殘差流進行交互,它們之間都會有連接,哪怕某些特征在真實分布中從未同時激活,也可能存在(甚至很大的)虛擬權重。
當這種情況發生時,這些虛擬權重就不再適合作為全局權重,因為這些連接并不實際影響網絡的行為。
通過下面的例子看到干擾的作用:
選取一個第18層中的 “Say a game name” 特征,并畫出它與其他特征之間按虛擬權重絕對值排序的最大連接。
綠色條表示正向連接,紫色條表示負向連接。 其中許多連接最強的特征難以解釋,或與該概念并無明顯關系。
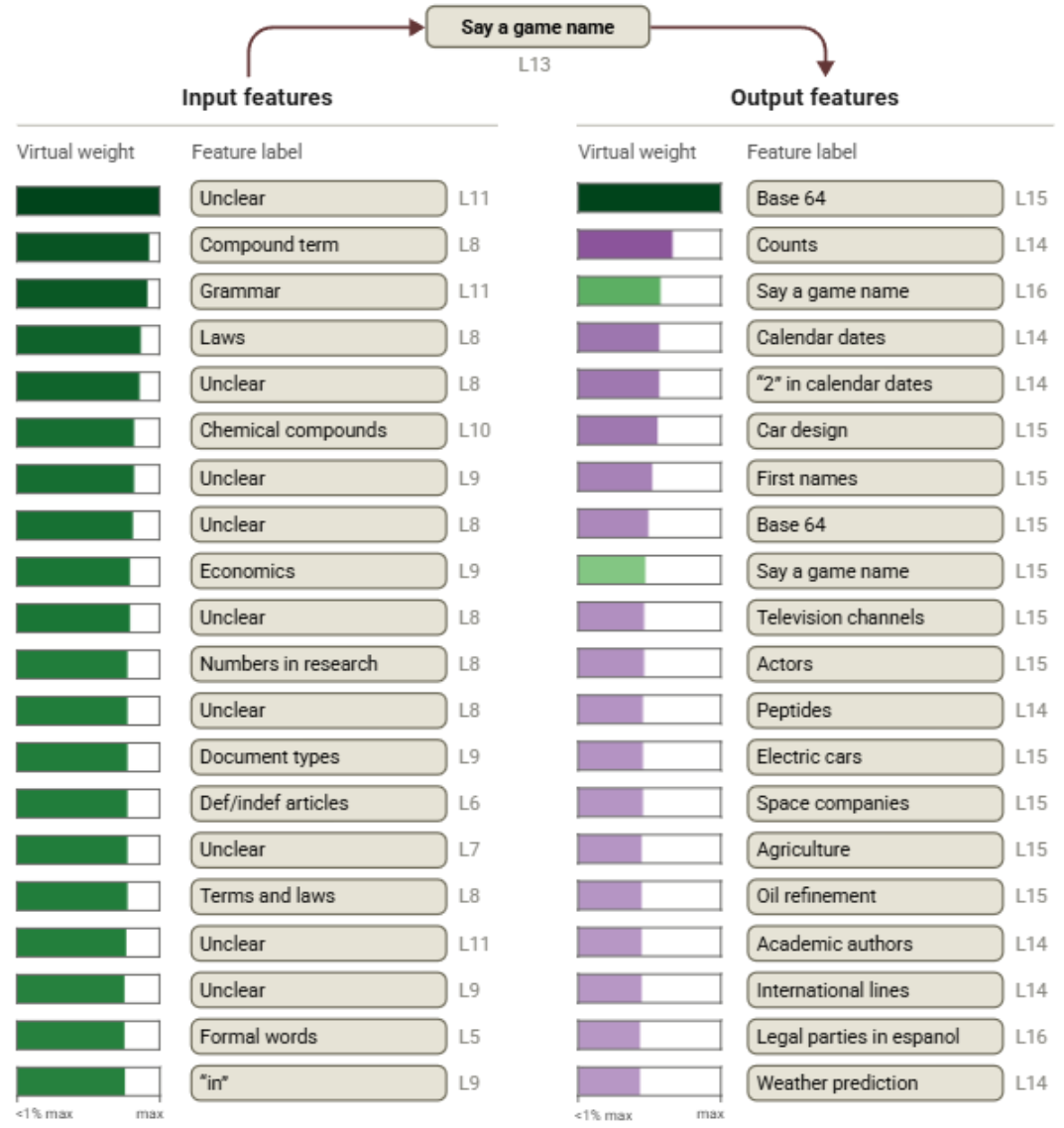
圖20:一個第18層特征的虛擬權重按絕對值排序的最大值示意圖。綠色條表示正向連接,紫色條表示負向連接。許多大的連接關系難以解釋。
看上去CLT 沒有捕捉到可解釋連接的一個跡象。然而,通過嘗試從這些權重中去除干擾,仍然可以發現許多具有可解釋性的連接。
這個問題有兩個基本的解決方案。一種是將研究的特征集限制在一個較小的領域內的活躍特征。另一種是引入關于特征之間在數據分布上共激活的信息。
例如,設 a i a_i ai?是特征 i i i的激活值。可以通過如下方式將虛擬權重與激活值相乘,計算一個期望的殘差歸因值:
V i j ERA = E [ 1 ( a j > 0 ) V i j a i ] = E [ 1 ( a j > 0 ) a i ] V i j V_{ij}^\text{ERA}=\mathbb{E}[\mathbb{1}(a_j>0)V_{ij}a_i]=\mathbb{E}[\mathbb{1}(a_j>0)a_i]V_{ij} VijERA?=E[1(aj?>0)Vij?ai?]=E[1(aj?>0)ai?]Vij?
這是分析的所有prompt中,一個殘差直接路徑的平均強度。這類似于在多個 token 的上下文位置中,對所有歸因圖求平均。
由于小的特征激活值通常具有多義性,改為使用目標激活值對歸因值加權:
V i j TWERA = E [ a j a i ] E [ a j ] V i j V_{ij}^\text{TWERA}=\frac{\mathbb{E}[a_ja_i]}{\mathbb{E}[a_j]}V_{ij} VijTWERA?=E[aj?]E[aj?ai?]?Vij?
將這種權重稱為目標加權期望殘差歸因(TWERA)。如公式所示,這兩種歸因值都可以通過將原始虛擬權重乘以(在分布上的)激活統計量來計算。
這次按照 TWERA 對連接進行排序。同時繪制了每個連接的“原始”虛擬權重用于對比。
可以看出,許多連接變得更具可解釋性,這表明虛擬權重中提取出了有用的信號,只是需要去除干擾才能看到它們。
之前虛擬權重圖中最容易解釋的特征(例如另一個“說一個游戲名稱”特征和“極限飛盤”特征)仍然被保留,而許多不相關的概念被過濾掉了。
![![[Pasted image 20250603042015.png]]](https://i-blog.csdnimg.cn/direct/01a40a0eaf09401e9407a953a4243fc2.png)
圖21:相同示例特征的最大 TWERA 值。
TWERA 并不是解決干擾問題的完美方案。將 TWERA 值與原始虛擬權重進行比較可以發現,許多極小的虛擬權重卻具有很高的 TWERA 值。這表明 TWERA 嚴重依賴于共激活統計數據,并且在決定哪些連接重要時會發生顯著變化,而不僅僅是去除較大的干擾權重。TWERA 也不擅長處理抑制效應(這在歸因方法中是普遍問題)。
5 Evaluations
本節對轉碼器特征及由其派生出的歸因圖進行了定性和定量評估,重點關注可解釋性和充分性。
我們的方法會生成模型在特定提示詞下機制的因果圖描述。如何量化這些描述在多大程度上真實反映了模型的運作?這個問題難以簡化為一個單一指標,因為其中涉及多個因素:
可解釋性。對單個特征“代表什么”的理解程度如何?
在下文中嘗試通過幾種方式對可解釋性進行量化;實際中,仍然大量依賴主觀評價。此外,將特征分組為“超級節點”的一致性同樣值得評估。在本文中我們并未嘗試量化這一點,而是留給讀者自行判斷我們的分組是否合理且可解釋。
還指出,在歸因圖的語境中,圖結構本身的可解釋性與單個特征的可解釋性同等重要。為此,我們量化了圖簡潔性的一個指標:平均路徑長度。
充分性。(經過剪枝的)歸因圖在多大程度上足以解釋模型的行為?
嘗試通過幾種方式來量化這一點。最直接的評估方式是我們在第 2.2 節“從CLT到替代模型”中討論的:衡量替代模型的輸出與原始模型的匹配程度。這是一種“嚴格”的評估方式,因為計算圖中任一位置的錯誤都可能嚴重影響整體性能。
還在下文中引入了幾種“寬松”的充分性指標,用于衡量歸因圖中錯誤節點的占比。需要注意的是,在許多情況下,展示的是經過剪枝的歸因圖的子圖示意圖,用于呈現我們認為最值得注意的部分。我們有意不對這些子圖的充分性進行評估,因為它們往往故意省略了一些“無趣但必要”的部分(例如,在加法類提示中表示“這是一個數學問題”的特征)。。
機制忠實性。識別出的機制在多大程度上是模型實際使用的?
為此進行了干擾實驗(例如抑制激活特征),并測量實驗結果是否與本地替代模型(即歸因圖所描述的對象)預測的結果一致。
在下文中嘗試對此進行定量分析,并在具體案例研究中驗證忠實性,特別關注我們認為有趣或重要的機制的忠實性。
需要說明的是,機制忠實性與“路徑組件是否是模型計算所必需的”這一概念密切相關。但“必需性”這一概念往往過于狹隘——即使某些機制不是模型輸出的嚴格“必需部分”,它們仍可能值得識別,尤其是在多個機制并行協作共同完成某一計算的情況下。
本文所采用的許多具體評估方法在以往研究中并未出現。這部分是因為我們的方法較為獨特,聚焦于單個提示詞下的歸因圖,而不是識別支撐整個任務表現的路徑結構。未來研究的重要方向是開發更好的自動化方法,來評估整個歸因流程(特征、超級節點、圖)的可解釋性、充分性和忠實性。

)









![BUUCTF[極客大挑戰 2019]EasySQL 1題解](http://pic.xiahunao.cn/BUUCTF[極客大挑戰 2019]EasySQL 1題解)






)
