
文章目錄
- 裝袋法(Bagging)和提升法(Boosting)
- 利用集成學習創建強大的模型
- 裝袋法(Bagging):為機器學習模型增加穩定性
- 裝袋法示例
- 提升法(Boosting):減少弱學習器的偏差
- 預測先前的殘差
- 樹的數量
- 樹的深度
- 學習率
- 裝袋法 vs. 提升法——核心差異解析
- 總結
裝袋法(Bagging)和提升法(Boosting)
裝袋法(Bagging)和提升法(Boosting)是機器學習中兩種強大的集成技術——它們是數據科學家必須掌握的知識!讀完本文后,你將深入理解裝袋法和提升法的工作原理以及何時使用它們。我們將涵蓋以下主題,并大量使用示例來直觀展示關鍵概念:
- 集成學習(Ensembling):如何助力創建強大的模型
- 裝袋法(Bagging):為機器學習模型增添穩定性
- 提升法(Boosting):減少弱學習器的偏差
- 裝袋法(Bagging)與提升法(Boosting)——何時使用以及原因
利用集成學習創建強大的模型
在機器學習(Machine Learning領域,集成學習(Ensembling) 是一個寬泛的術語,指的是任何通過組合多個模型的預測結果來進行預測的技術。如果在進行預測時涉及多個模型,那么這種技術就屬于集成學習!
集成學習方法通常可以提升單個模型的性能。集成學習有助于減少:
- 方差(Variance):通過對多個模型進行平均。
- 偏差(Bias):通過迭代改進誤差。
- 過擬合(Overfitting):因為使用多個模型可以增強對虛假關系的魯棒性。
裝袋法(Bagging)和提升法(Boosting)都是集成方法,它們的表現通常比單個模型要好得多。現在讓我們深入了解它們的細節!
裝袋法(Bagging):為機器學習模型增加穩定性
裝袋法(Bagging)是一種特定的集成學習技術,用于降低預測模型的方差。這里所說的方差是機器學習意義上的,即模型隨訓練數據集變化的程度,而不是統計學意義上衡量分布離散程度的方差。由于裝袋法有助于降低機器學習模型的方差,因此它通常可以改進高方差(High Variance)模型(如決策樹(Decision Trees)和K近鄰算法(KNN)),但對低方差(Low Variance)模型(如線性回歸(Linear Regression))的作用不大。
既然我們已經了解了裝袋法在何時起作用(高方差模型),讓我們深入了解其內部工作原理,看看它是如何發揮作用的!裝袋算法本質上是迭代的,它通過重復以下三個步驟來構建多個模型:
- 從原始訓練數據中進行自助采樣(Bootstrap),生成新的數據集。
- 在自助采樣得到的數據集上訓練一個模型。
- 保存訓練好的模型。
這個過程中創建的模型集合稱為集成(Ensemble)。當需要進行預測時,集成中的每個模型都會做出自己的預測,最終的裝袋預測結果是所有模型預測結果的平均值(用于回歸問題)或多數投票結果(用于分類問題)。
現在我們了解了裝袋法的工作原理,讓我們花幾分鐘時間來直觀理解它為什么有效。我們可以借鑒傳統統計學中的一個熟悉概念:抽樣估計總體均值。
在統計學中,從分布中抽取的每個樣本都是一個隨機變量。小樣本量往往具有高方差,可能無法很好地估計真實均值。但隨著我們收集的樣本增多,這些樣本的平均值就會更接近總體均值。
同樣,我們可以將每個單獨的決策樹視為一個隨機變量,畢竟每棵樹都是在不同的隨機樣本數據上訓練的!通過對多棵樹的預測結果進行平均,裝袋法降低了方差,并產生了一個能夠更好捕捉數據中真實關系的集成模型。
裝袋法示例
我們將使用Scikit-learn Python包中的load_diabetes數據集來說明一個簡單的裝袋法示例。該數據集有10個輸入變量——年齡(Age)、性別(Sex)、身體質量指數(BMI)、血壓(Blood Pressure)以及6種血清水平指標(S1 - S6),還有一個表示疾病進展程度的輸出變量。下面的代碼導入數據并進行了簡單的清理。數據集準備好后,我們就可以開始建模了!
# 導入并格式化數據
from sklearn.datasets import load_diabetesdiabetes = load_diabetes(as_frame=True)
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names)
df.loc[:, 'target'] = diabetes.target
df = df.dropna()
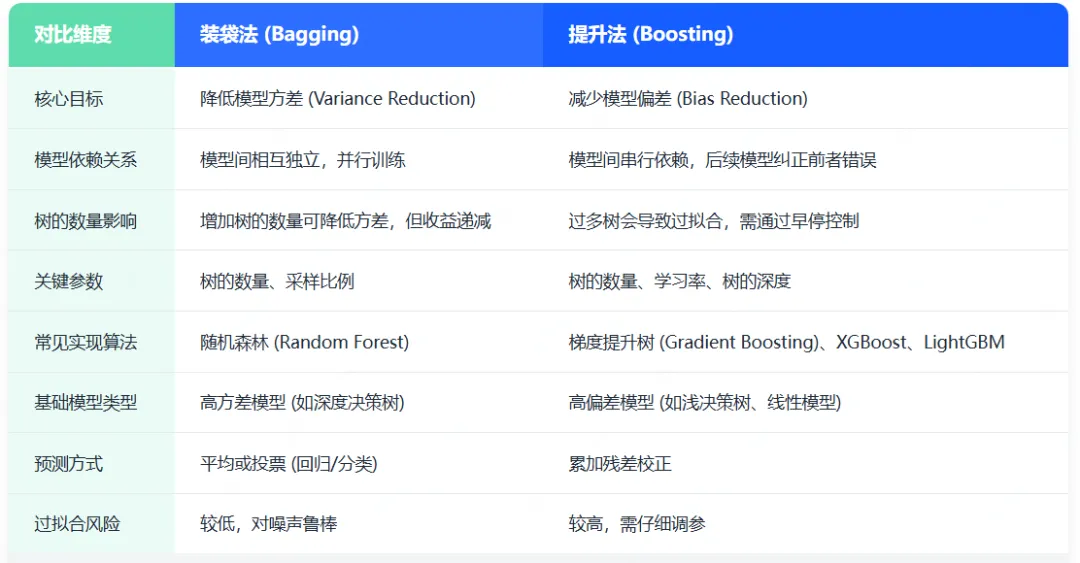
在我們的示例中,我們將使用基本的決策樹作為裝袋法的基礎模型。首先,讓我們驗證一下我們的決策樹確實是高方差模型。我們將通過在不同的自助采樣數據集上訓練三棵決策樹,并觀察測試數據集預測結果的方差來進行驗證。下面的圖表展示了三棵不同的決策樹在同一測試數據集上的預測結果。每條垂直虛線代表測試數據集中的一個單獨觀測值。每條線上的三個點分別是三棵不同決策樹的預測結果。
在上面的圖表中,我們可以看到,當在自助采樣數據集上進行訓練時,單個決策樹可能會給出非常不同的預測結果(每條垂直線上三個點的分布情況)。這就是我們一直在討論的方差!
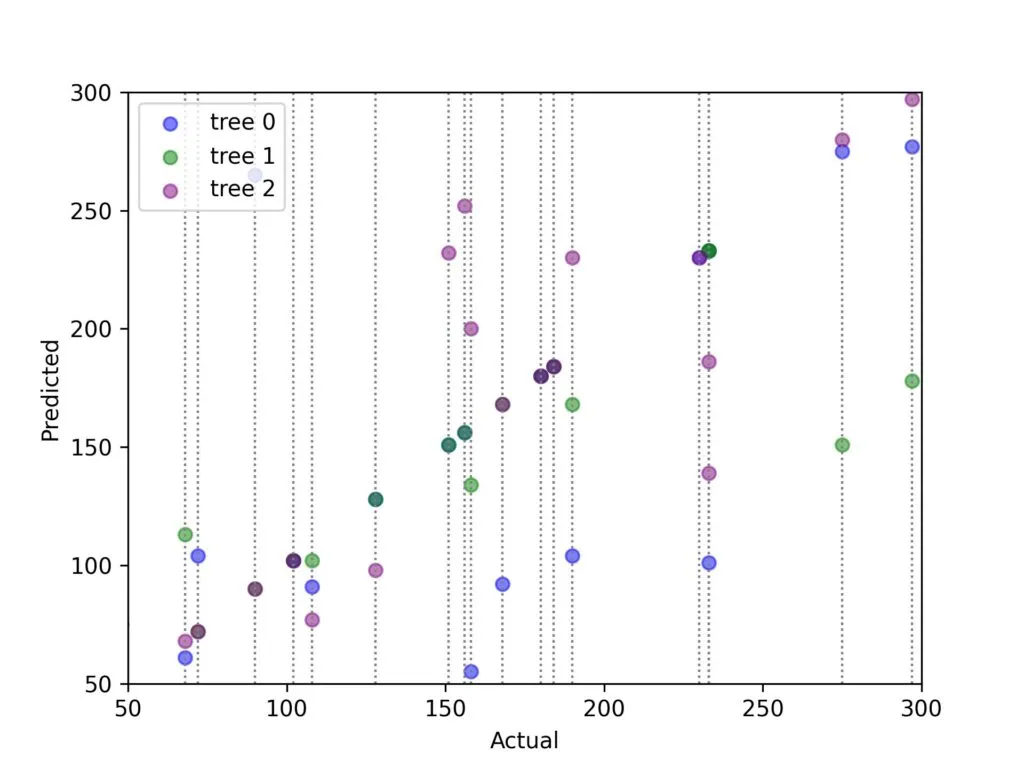
既然我們已經看到我們的決策樹對訓練樣本的魯棒性不強,讓我們對預測結果進行平均,看看裝袋法能起到什么作用!下面的圖表展示了三棵樹預測結果的平均值。對角線代表完美的預測結果。正如你所見,使用裝袋法后,我們的數據點更加緊密地圍繞在對角線周圍。
僅僅對三棵樹的預測結果進行平均,我們就已經看到了模型性能的顯著提升。讓我們增加更多的樹來強化我們的裝袋算法!
以下是一個可以根據我們的需求訓練任意數量決策樹的代碼:
def train_bagging_trees(df, target_col, pred_cols, n_trees):'''通過在自助采樣數據上訓練多個決策樹來創建一個裝袋決策樹模型。輸入:df (pandas DataFrame) : 包含目標列和輸入列的訓練數據target_col (str) : 目標列的名稱pred_cols (list) : 預測列名稱的列表n_trees (int) : 集成中要訓練的樹的數量輸出:train_trees (list) : 訓練好的樹的列表'''train_trees = []for i in range(n_trees):# 自助采樣訓練數據temp_boot = bootstrap(train_df)# 訓練樹temp_tree = plain_vanilla_tree(temp_boot, target_col, pred_cols)# 將訓練好的樹保存到列表中train_trees.append(temp_tree)return train_treesdef bagging_trees_pred(df, train_trees, target_col, pred_cols):'''接受一個裝袋樹的列表,并通過對每棵單獨樹的預測結果進行平均來創建預測。輸入:df (pandas DataFrame) : 包含目標列和輸入列的訓練數據train_trees (list) : 集成模型 - 即訓練好的決策樹列表target_col (str) : 目標列的名稱pred_cols (list) : 預測列名稱的列表輸出:avg_preds (list) : 集成樹的預測結果列表'''x = df[pred_cols]y = df[target_col]preds = []# 使用每棵決策樹對數據進行預測for tree in train_trees:temp_pred = tree.predict(x)preds.append(temp_pred)# 獲取樹的預測結果的平均值sum_preds = [sum(x) for x in zip(*preds)]avg_preds = [x / len(train_trees) for x in sum_preds]return avg_preds
上面的函數非常簡單,第一個函數用于訓練裝袋集成模型,第二個函數接受集成模型(簡單來說就是一個訓練好的樹的列表),并根據給定的數據集進行預測。
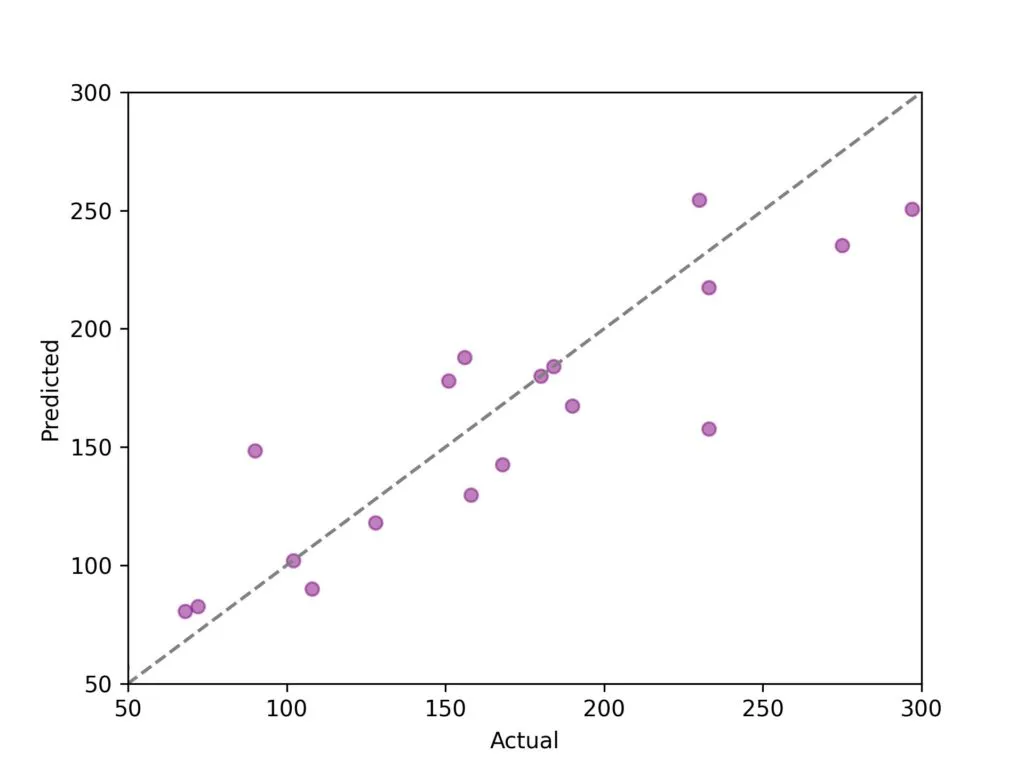
代碼準備好后,讓我們運行多個集成模型,看看隨著樹的數量增加,我們的袋外預測(Out-of-bag Predictions)會發生怎樣的變化。
不得不承認,這個圖表看起來有點復雜。不要過于糾結于每個單獨的數據點,虛線才是關鍵!這里我們有一個基本的決策樹模型和三個裝袋決策樹模型——分別包含3棵、50棵和150棵樹。顏色編碼的虛線標記了每個模型殘差(Residuals)的上下范圍。這里有兩個主要的結論:(1) 隨著樹的數量增加,殘差的范圍會縮小;(2) 增加更多的樹帶來的收益會逐漸減少——當我們從1棵樹增加到3棵樹時,范圍縮小了很多,但當我們從50棵樹增加到150棵樹時,范圍只縮小了一點。
現在我們已經成功完成了一個完整的裝袋法示例,接下來我們準備開始學習提升法(Boosting)!讓我們快速回顧一下本節所涵蓋的內容:
- 裝袋法通過對多個單獨模型的預測結果進行平均,降低了機器學習模型的方差。
- 裝袋法對高方差模型最為有效。
- 裝袋的模型越多,集成模型的方差就越低,但方差降低的收益會逐漸減少。
好了,讓我們開始學習提升法吧!
提升法(Boosting):減少弱學習器的偏差
在裝袋法中,我們創建多個獨立的模型——模型的獨立性有助于平均掉單個模型的噪聲。提升法(Boosting)也是一種集成學習技術;與裝袋法類似,我們也會訓練多個模型……但與裝袋法非常不同的是,我們訓練的模型將是相互依賴的。提升法是一種建模技術,它首先訓練一個初始模型,然后依次訓練額外的模型,以改進先前模型的預測結果。提升法的主要目標是減少偏差——盡管它也可以幫助減少方差。
我們已經知道提升法可以迭代地改進預測結果,現在讓我們深入了解它是如何做到的。提升算法可以通過兩種方式迭代地改進模型的預測結果:
- 直接預測上一個模型的殘差,并將其添加到先前的預測結果中——可以將其視為殘差校正。
- 對上一個模型預測效果較差的觀測值賦予更多的權重。
由于提升法的主要目標是減少偏差,因此它適用于通常具有較大偏差的基礎模型(如淺決策樹(Shallow Decision Trees))。在我們的示例中,我們將使用淺決策樹作為基礎模型——為了簡潔起見,本文僅介紹殘差預測方法。讓我們開始提升法的示例吧!
預測先前的殘差
殘差預測方法從一個初始模型開始(有些算法提供一個常數,有些則使用基礎模型的一次迭代結果),然后我們計算該初始預測的殘差。集成中的第二個模型預測第一個模型的殘差。有了殘差預測后,我們將殘差預測添加到初始預測中(這就得到了經過殘差校正的預測結果),并重新計算更新后的殘差……我們繼續這個過程,直到創建出指定數量的基礎模型。這個過程相當簡單,但僅用文字解釋有點困難——下面的流程圖展示了一個簡單的包含4個模型的提升算法。
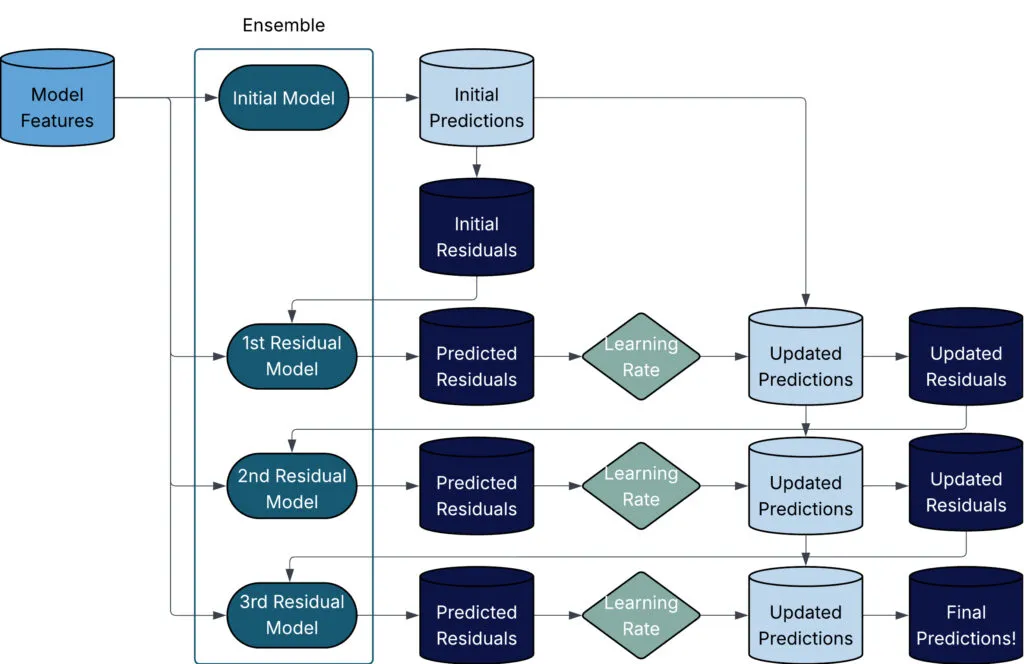
在進行提升法時,我們需要設置三個主要參數:(1) 樹的數量,(2) 樹的深度,(3) 學習率(Learning Rate)。現在讓我們花點時間來討論一下這些參數。
樹的數量
對于提升法來說,樹的數量與裝袋法中的含義相同——即集成中要訓練的樹的總數。但與裝袋法不同的是,我們不應該一味地增加樹的數量!下面的圖表展示了糖尿病數據集的測試均方根誤差(RMSE)與樹的數量之間的關系。

這表明,在大約200棵樹之前,測試均方根誤差隨著樹的數量增加而迅速下降,然后開始逐漸上升。這看起來像是一個典型的“過擬合”圖表——我們達到了一個點,超過這個點后,增加更多的樹對模型反而不利。這是裝袋法和提升法之間的一個關鍵區別——在裝袋法中,增加更多的樹最終會不再有幫助,而在提升法中,增加更多的樹最終會開始產生負面影響!
在裝袋法中,增加更多的樹最終會不再有幫助,而在提升法中,增加更多的樹最終會開始產生負面影響!
我們現在知道,樹的數量過多不好,過少也不好。我們將使用超參數調優(Hyperparameter Tuning)來選擇樹的數量。需要注意的是,超參數調優是一個非常大的主題,遠遠超出了本文的范圍。稍后我將通過一個包含訓練集和測試集的簡單網格搜索(Grid Search)示例來進行演示。
樹的深度
這是集成中每棵樹的最大深度。在裝袋法中,樹通常可以長得盡可能深,因為我們需要的是低偏差、高方差的模型。然而,在提升法中,我們使用順序模型來解決基礎學習器的偏差問題,因此我們不太關心生成低偏差的樹。那么我們如何確定最大深度呢?我們將使用與選擇樹的數量相同的技術——超參數調優。
學習率
樹的數量和樹的深度是我們在裝袋法中熟悉的參數(盡管在裝袋法中我們通常不會對樹的深度進行限制)——但這個“學習率”是一個新面孔!讓我們花點時間來了解一下。學習率是一個介于0和1之間的數字,在將當前模型的殘差預測添加到總體預測之前,會將其乘以這個學習率。
下面是一個學習率為0.5時預測計算的簡單示例。在理解了學習率的工作原理后,我們將討論為什么學習率很重要。
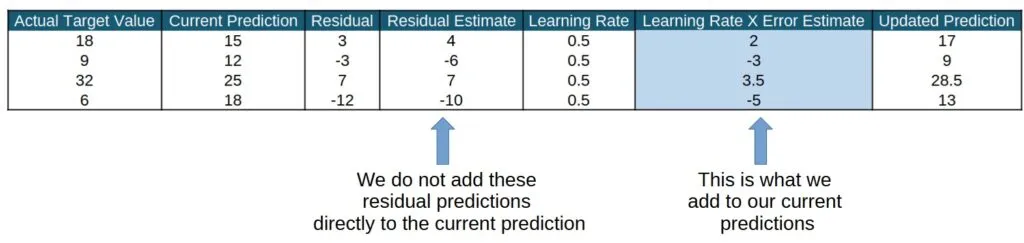
那么,為什么我們要對殘差預測進行“折扣”處理呢?這樣做不會使我們的預測結果變差嗎?嗯,答案是有好有壞。對于單次迭代來說,這可能會使我們的預測結果變差——但我們進行的是多次迭代。在多次迭代中,學習率可以防止模型對單棵樹的預測結果反應過度。它可能會使我們當前的預測結果變差,但不用擔心,我們會多次進行這個過程!最終,學習率通過降低集成中任何單棵樹的影響,有助于減輕提升模型的過擬合問題。你可以將其想象成慢慢轉動方向盤來糾正駕駛方向,而不是猛地轉動。實際上,樹的數量和學習率之間存在相反的關系,即學習率降低時,樹的數量需要增加。這是很直觀的,因為如果我們只允許每棵樹的殘差預測的一小部分添加到總體預測中,那么在總體預測看起來良好之前,我們就需要更多的樹。
最終,學習率通過降低集成中任何單棵樹的影響,有助于減輕提升模型的過擬合問題。
好了,現在我們已經介紹了提升法中的主要參數,讓我們開始編寫Python代碼吧!我們需要幾個函數來實現提升算法:
- 基礎決策樹函數——一個簡單的函數,用于創建和訓練單棵決策樹。我們將使用上一節中名為
plain_vanilla_tree的函數。 - 提升訓練函數——這個函數會按照用戶指定的數量依次訓練決策樹并更新殘差。在我們的代碼中,這個函數名為
boost_resid_correction。 - 提升預測函數——這個函數接受一系列提升模型,并進行最終的集成預測。我們將這個函數稱為
boost_resid_correction_pred。
以下是用Python編寫的函數:
# 與上一節相同的基礎樹函數
def plain_vanilla_tree(df_train,target_col,pred_cols,max_depth = 3,weights=[]):X_train = df_train[pred_cols]y_train = df_train[target_col]tree = DecisionTreeRegressor(max_depth = max_depth, random_state=42)if weights:tree.fit(X_train, y_train, sample_weights=weights)else:tree.fit(X_train, y_train)return tree# 殘差預測
def boost_resid_correction(df_train,target_col,pred_cols,num_models,learning_rate=1,max_depth=3):'''創建提升決策樹集成模型。輸入:df_train (pd.DataFrame) : 包含訓練數據target_col (str) : 目標列名稱pred_cols (list) : 預測列名稱列表num_models (int) : 提升過程中使用的模型數量learning_rate (float, 默認為1) : 對殘差預測的折扣系數(取值范圍:(0, 1])max_depth (int, 默認為3) : 每棵樹模型的最大深度輸出:boosting_model (dict) : 包含模型預測所需的所有信息(包括集成中的樹列表)'''# 創建初始預測model1 = plain_vanilla_tree(df_train, target_col, pred_cols, max_depth = max_depth)initial_preds = model1.predict(df_train[pred_cols])df_train['resids'] = df_train[target_col] - initial_preds # 計算初始殘差# 創建多個模型,每個模型預測更新后的殘差models = []for i in range(num_models):temp_model = plain_vanilla_tree(df_train, 'resids', pred_cols) # 訓練殘差預測樹models.append(temp_model)temp_pred_resids = temp_model.predict(df_train[pred_cols]) # 預測當前殘差# 更新殘差(學習率控制當前殘差預測的貢獻度)df_train['resids'] = df_train['resids'] - (learning_rate * temp_pred_resids)boosting_model = {'initial_model': model1, # 初始模型'models': models, # 殘差預測模型列表'learning_rate': learning_rate, # 學習率'pred_cols': pred_cols # 預測列名稱}return boosting_model# 該函數使用殘差提升模型對數據進行評分
def boost_resid_correction_predict(df,boosting_models,chart = False):'''根據提升模型對數據集進行預測。輸入:df (pd.DataFrame) : 待預測的數據boosting_models (dict) : 包含提升模型參數的字典chart (bool, 默認為False) : 是否生成性能圖表輸出:pred (np.array) : 提升模型的預測結果rmse (float) : 預測的均方根誤差'''# 獲取初始預測initial_model = boosting_models['initial_model']pred_cols = boosting_models['pred_cols']pred = initial_model.predict(df[pred_cols]) # 初始預測值# 計算每個模型的殘差預測并累加(乘以學習率)models = boosting_models['models']learning_rate = boosting_models['learning_rate']for model in models:temp_resid_preds = model.predict(df[pred_cols])pred += learning_rate * temp_resid_preds # 殘差校正if chart:plt.scatter(df['target'], pred) # 繪制實際值與預測值散點圖plt.show()rmse = np.sqrt(mean_squared_error(df['target'], pred)) # 計算均方根誤差return pred, rmse太棒了,我們在裝袋法部分使用的糖尿病數據集上訓練一個模型。我們將進行快速網格搜索(同樣,這里不進行復雜的調優)來調整三個參數,然后使用boost_resid_correction函數訓練最終模型。
# 網格搜索調參
n_trees = [5, 10, 30, 50, 100, 125, 150, 200, 250, 300]
learning_rates = [0.001, 0.01, 0.1, 0.25, 0.50, 0.75, 0.95, 1]
max_depths = list(range(1, 16)) # 生成1到15的深度列表# 創建字典保存每個網格點的測試RMSE
perf_dict = {}
for tree in n_trees:for learning_rate in learning_rates:for max_depth in max_depths:# 訓練提升模型temp_boosted_model = boost_resid_correction(train_df,'target',pred_cols,tree,learning_rate=learning_rate,max_depth=max_depth)temp_boosted_model['target_col'] = 'target'# 在測試集上預測并計算RMSEpreds, rmse = boost_resid_correction_predict(test_df, temp_boosted_model)# 生成字典鍵(參數組合字符串)dict_key = '_'.join(str(x) for x in [tree, learning_rate, max_depth])perf_dict[dict_key] = rmse# 找到RMSE最小的參數組合
min_key = min(perf_dict, key=perf_dict.get)
print(perf_dict[min_key]) # 輸出最小RMSE值
我們的獲勝者是 🥁 ——50棵樹、學習率0.1和最大深度1!讓我們看看預測效果如何。
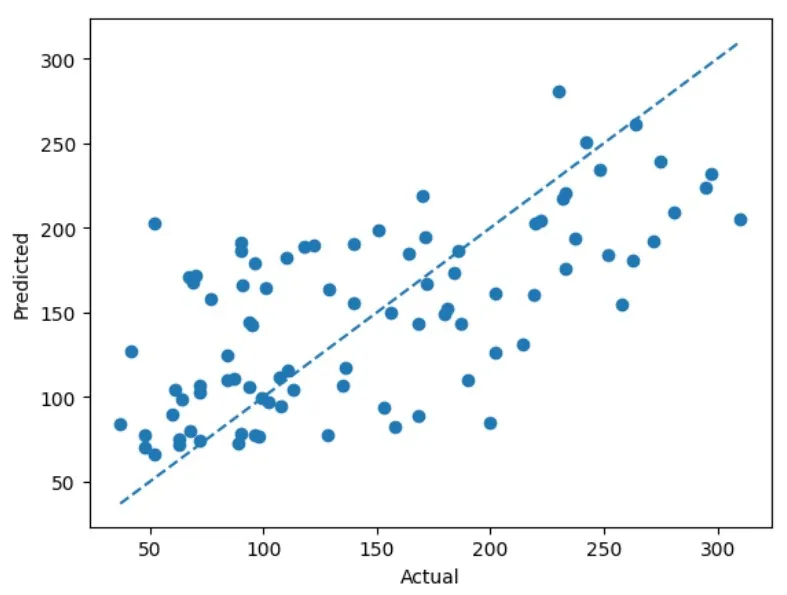
雖然我們的提升集成模型似乎合理捕捉了趨勢,但直觀來看其預測效果不如裝袋模型。我們可能需要更多時間調優——但也有可能是裝袋法更適合該特定數據集。至此,我們已理解裝袋法和提升法的核心原理,接下來進行對比總結:
裝袋法 vs. 提升法——核心差異解析
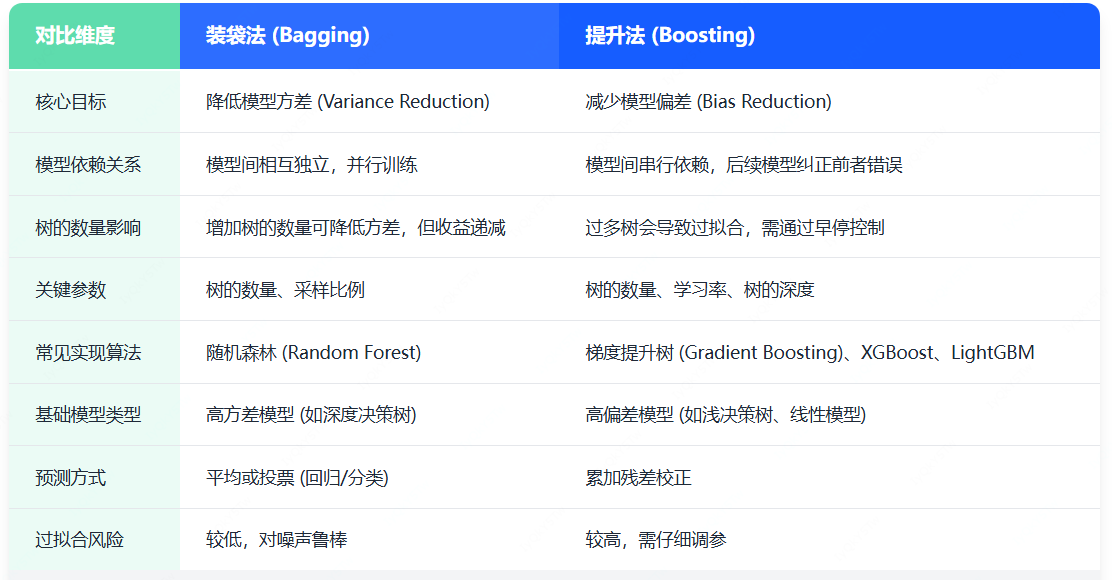
我們已分別介紹了裝袋法和提升法,下表總結了兩者的關鍵區別:
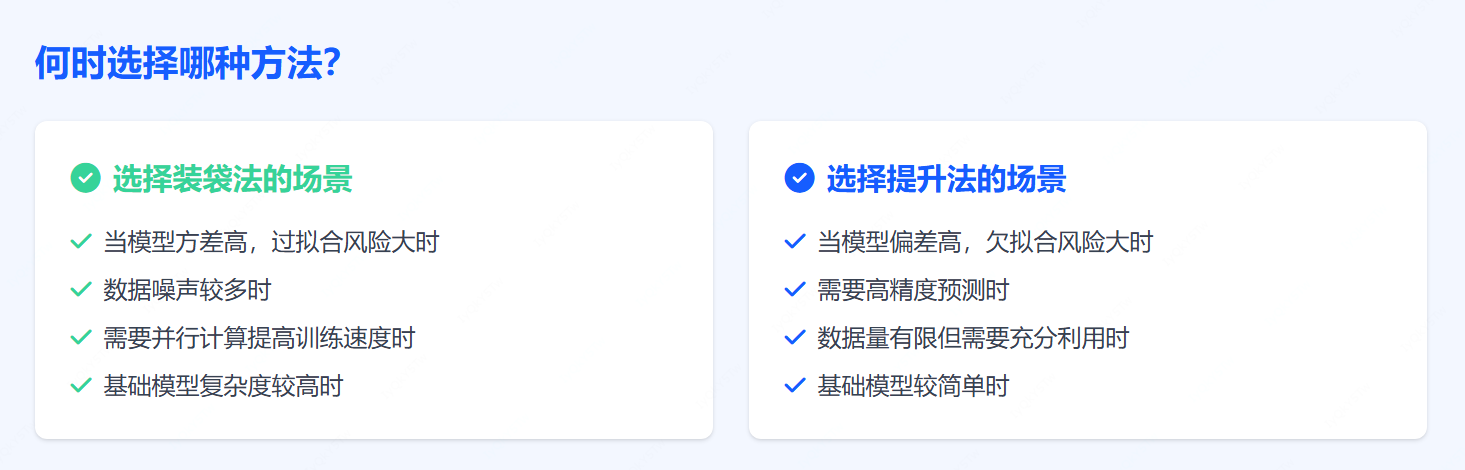
注意:本文為教學目的編寫了自定義裝袋和提升代碼,實際應用中應直接使用Python庫(如scikit-learn)中的成熟實現。此外,純裝袋法或提升法很少單獨使用,更常見的是采用改進后的高級算法(如隨機森林、XGBoost)來優化性能。
總結
裝袋法和提升法是改進弱學習器(如靈活的決策樹)的強大實用技術。兩者均通過集成學習解決不同問題——裝袋法降低方差,提升法減少偏差。實際中,幾乎總是使用預封裝代碼來訓練結合裝袋/提升思想并經過多重優化的高級機器學習模型。










.openEndDrawer();不生效問題)


)


)

實現路徑損耗預測)
