目錄
- 一、引言
- 1.1. 日常生活中的機器學習
- 1.2. 機器學習中的關鍵組件
- 1)數據
- 2)模型
- 3)目標函數
- 4)優化算法
一、引言
1.1. 日常生活中的機器學習
應用場景:
以智能語音助手(如Siri、Alexa)的喚醒詞識別為例,麥克風采集的音頻數據(每秒約4.4萬次采樣)無法通過傳統編程直接關聯到特定指令。機器學習通過分析大量標記數據(含/不含喚醒詞的音頻),自動構建輸入(音頻)到輸出(是否觸發)的映射關系。
圖1.1.1 識別喚醒詞

模型與參數:
模型是由參數控制的靈活算法,參數如同“旋鈕”,調整模型行為。例如,同一模型族可適配不同喚醒詞(“Alexa”或“Hey Siri”)。
數據集(dataset):批量數據樣本;
模型(model):任一調整參數后的程序;
模型族:所有不同程序(輸入-輸出映射)的集合;
學習算法(learning algorithm):使用數據集來選擇參數的元程序;
學習(learning):是一個訓練(train)模型的過程;指自主提高模型完成某些任務的效能。
機器學習本質:
通過數據編程(Programming with Data),用數據集而非硬編碼規則定義程序行為。例如,用大量貓狗圖片訓練分類器,使其輸出區分兩者的數值。
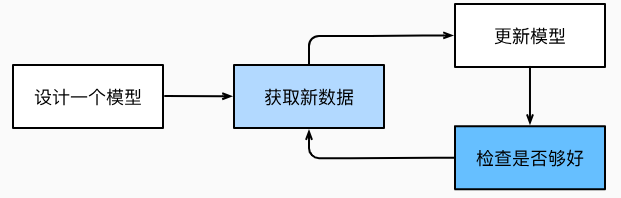
訓練過程:
-
從一個隨機初始化參數的“無智能”模型開始;
-
獲取一些數據樣本;
-
調整參數,使模型在這些樣本中表現得更好;
-
重復第(2)步和第(3)步,直到模型在表現良好。
圖1.1.2 一個典型的訓練過程
.
1.2. 機器學習中的關鍵組件
機器學習的關鍵組件:
-
可以用來學習的數據(data);
-
如何轉換數據的模型(model);
-
一個目標函數(objective function),用來量化模型的有效性;
-
調整模型參數以優化目標函數的算法(algorithm)。
.
1)數據
可以用來學習的數據(data);
每個數據集由一個個樣本(example, sample) 組成,大多時候,它們遵循獨立同分布(independently and identically distributed, i.i.d.)。
樣本有時也叫做數據點(data point) 或 數據實例(data instance); 通常每個樣本由一組稱為特征(features,或協變量(covariates))的屬性組成。 機器學習模型會根據這些屬性進行預測。在上面的監督學習問題中,要預測的是一個特殊的屬性,它被稱為標簽(label,或目標(target))。
當每個樣本的特征類別數量都是相同時,其特征向量是定長的,這個長度被稱為數據的維數 (dimensionality)。 固定長度的特征向量是一個方便的屬性,它可以用來量化學習大量樣本。
.
2)模型
轉換數據的模型(model);
大多數機器學習會涉及到數據的轉換。比如通過攝取到的一組傳感器讀數預測讀數的正常與異常程度。
深度學習與經典方法的區別主要在于:前者關注的功能強大的模型,這些模型由神經網絡錯綜復雜的交織在一起,包含層層數據轉換,因此被稱為深度學習(deep learning)。
.
3)目標函數
目標函數(objective function),用來量化模型的有效性;
“學習”是指自主提高模型完成某些任務的效能。
在機器學習中,我們需要定義模型的優劣程度的度量,這個度量在大多數情況是“可優化”的,這被稱之為目標函數(objective function)。
我們通常定義一個目標函數,并希望優化它到最低點。 因為越低越好,所以這些函數有時被稱為損失函數(loss function,或cost function)。 但這只是一個慣例,我們也可以取一個新的函數,優化到它的最高點。 這兩個函數本質上是相同的,只是翻轉一下符號。
當任務在試圖預測數值時,最常見的損失函數是平方誤差(squared error),即預測值與實際值之差的平方。 當試圖解決分類問題時,最常見的目標函數是最小化錯誤率,即預測與實際情況不符的樣本比例。
通常,損失函數是根據模型參數定義的,并取決于數據集。 在數據集上,通過最小化總損失來學習模型參數的最佳值。為訓練而收集數據集,稱為訓練數據集(training dataset,或訓練集(training set))。 然而,在訓練數據上表現良好的模型,并不一定在“新數據集”上有同樣的性能,這里的“新數據集”通常稱為測試數據集(test dataset,或測試集(test set))。
當一個模型在訓練集上表現良好,測試集上表現不好時,這個模型被稱為**過擬合(overfitting)**的。
.
4)優化算法
當獲得了一些數據源及其表示、一個模型和一個合適的損失函數,接下來就需要一種算法,它能夠搜索出最佳參數,以最小化損失函數。
深度學習中,大多流行的優化算法常基于的基本方法–-梯度下降(gradient descent)。 簡而言之,在每個步驟中,梯度下降法都會檢查每個參數,看看如果僅對該參數進行少量變動,訓練集損失會朝哪個方向移動。 然后,它在可以減少損失的方向上優化參數。
.
聲明:資源可能存在第三方來源,若有侵權請聯系刪除!
)
![[python] 輕量級定時任務調度庫schedule使用指北](http://pic.xiahunao.cn/[python] 輕量級定時任務調度庫schedule使用指北)
)

![[免費]蒼穹微信小程序外賣點餐系統修改版(跑腿點餐系統)(SpringBoot后端+Vue管理端)【論文+源碼+SQL腳本】](http://pic.xiahunao.cn/[免費]蒼穹微信小程序外賣點餐系統修改版(跑腿點餐系統)(SpringBoot后端+Vue管理端)【論文+源碼+SQL腳本】)






)







