一、日志管理
5.7版本自定義路徑時的文件需要自己提前創建好文件,不會自動創建,否則啟動mysql會報錯

錯誤日志
rpm包(yum)? ? /var/log/mysql.log? 默認錯誤日志
###查詢日志路徑
[root@db01 ~]# mysqladmin -uroot -pEgon@123 variables | grep -w log_error?
或者
[root@db01t ~]# mysql -uroot -pEgon@123
mysql> show variables like '%log_error%';
###設置錯誤日志路徑
[root@localhost ~]# vim /etc/my.cnf
[mysqld]
#絕對路徑
log_error=/var/log/mysql.errlog
#相對路徑
#log_error=mysql.errlog
?
[root@localhost ~]# touch /var/log/mysql.errlog
[root@localhost ~]# chmod 640 /var/log/mysql.errlog?
[root@localhost ~]# chown mysql.mysql /var/log/mysql.errlog?
[root@localhost ~]# systemctl restart mysqld
###log_warnings參數
mysql5.6
log_warnings的值為0,表示不記錄警告信息。
log_warnings的值為1,表示警告信息一并記錄到錯誤日志中。
log_warnings的值大于1,表示"失敗的連接"的信息和創建新連接時"拒絕訪問"類的錯誤信息也會被記錄到錯誤日志中。
###?
mysql5.5中log_warnings參數的默認值為1
mysql5.7中log_warnings參數的默認值為2
mysql> show variables like "%log_warnings%";###log_error_verbosity參數
mysql5.7
# 它有三個可選值, 分別對應:
# log_error_verbosity=1:錯誤信息;
# log_error_verbosity=2:錯誤信息和告警信息;(推薦)
# log_error_verbosity=3(默認值就是3):錯誤信息、告警信息和通知信息。
事務日志
詳見mysql數據庫進階
查詢日志?
1.默認是關閉的
一般不會開啟,因為哪怕你開啟事務一頓操作,最后不提交也會記錄,生產上程序跑sql很多,會非常非常占地方,從來都不啟動,要看操作去binlog
?
2.開啟
[root@db01 ~]# vim /etc/my.cnf
general_log=on
general_log_file=/var/log/select.log
#可以使用set global general_log=on;設置
?
[root@localhost ~]# touch /var/log/select.log
[root@localhost ~]# chmod 640 /var/log/select.log
[root@localhost ~]# chown mysql.mysql /var/log/select.log
[root@localhost ~]# systemctl restart mysqld3.查看一般查詢日志
[root@db01 ~]# mysqladmin -uroot -pEgon@123 variables|grep general_log?
或者
[root@db01 ~]# mysql -uroot -pEgon@123
mysql> show variables like '%gen%';
慢查詢日志
- 將mysql服務器中影響數據庫性能的相關SQL語句(不論是什么語句,增刪改查)記錄到日志文件
- 通過對這些特殊的SQL語句分析并改進,提高數據庫性能
- 全表掃描日志一定記錄到慢日志
- 慢日志+explain工具=快速定位進行sql分析并優化? (慢日志--定位? explain--分析)
配置
#默認慢日志是不開啟的?
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
#指定是否開啟慢查詢日志
slow_query_log = 1
#指定慢日志文件存放位置(默認在data)
slow_query_log_file=/var/log/slow.log
#設定慢查詢的閥值(默認10s)
long_query_time=0.05
#不使用索引的慢查詢日志是否記錄到日志
log_queries_not_using_indexes=ON
#查詢檢查返回少于該參數指定行的SQL不被記錄到慢查詢日志,少于100行的sql語句查詢慢的話不記錄,一般不使用
#min_examined_row_limit=100 ?# 雞肋
?
執行下述命令
touch /var/log/slow.log
chmod 640 /var/log/slow.log
chown mysql.mysql /var/log/slow.log
systemctl restart mysqld
測試
測試:BENCHMARK(count,expr)
SELECT BENCHMARK(50000000,2*3);?
#執行卡死,查看執行的sql執行時間,如果停不下來 可以 kill id
show processlist;
kill 3;或者用
insert city_new select * from city;
insert city_new select * from city_new;
insert city_new select * from city_new;
insert city_new select * from city_new;
查看
mysqldumpslow -s r -t 10 /var/log/slow.log?
得到按照時間排序的前10條里面含有左連接的查詢語句
參數說明:
-s:指定排序方式
? ? c、t、l、r分別是按照記錄次數、時間、查詢時間、
? ? 返回的記錄數來排序,ac、at、al、ar,表示相應的倒敘?
-t:是top n的意思,即為返回前面多少條的數據;?
-g:后邊可以寫一個正則匹配模式,大小寫不敏感的;tail -f?/var/log/slow.log?
二、binlog日志

? ? ? ? ? ? ?
? ? ? ? ? ? ? ? ??
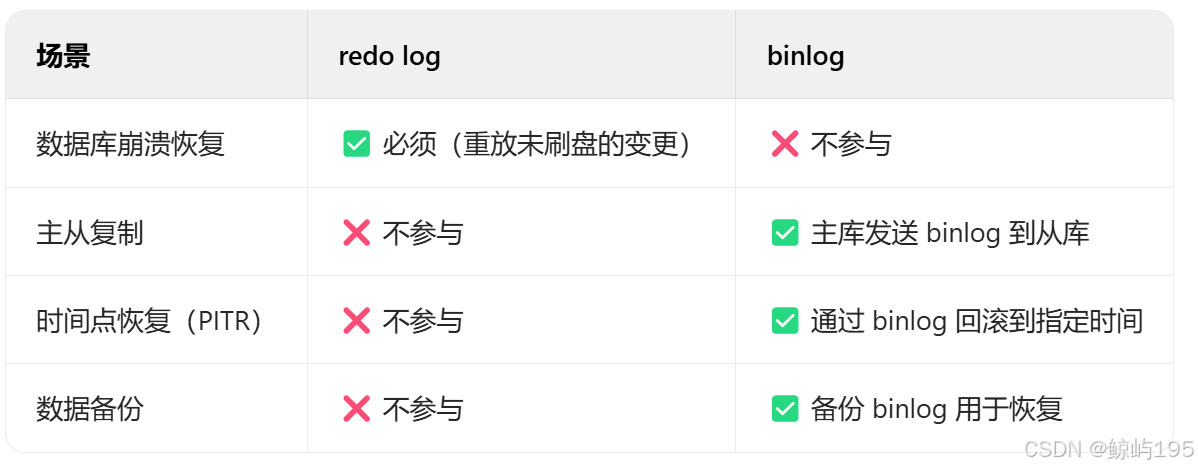
binlog的作用
(1)數據恢復:可以基于時間點恢復,以及根據其進行增量與差異備份(配合全量備份使用)
(2)mysql主從復制,通過binlog實現數據復制
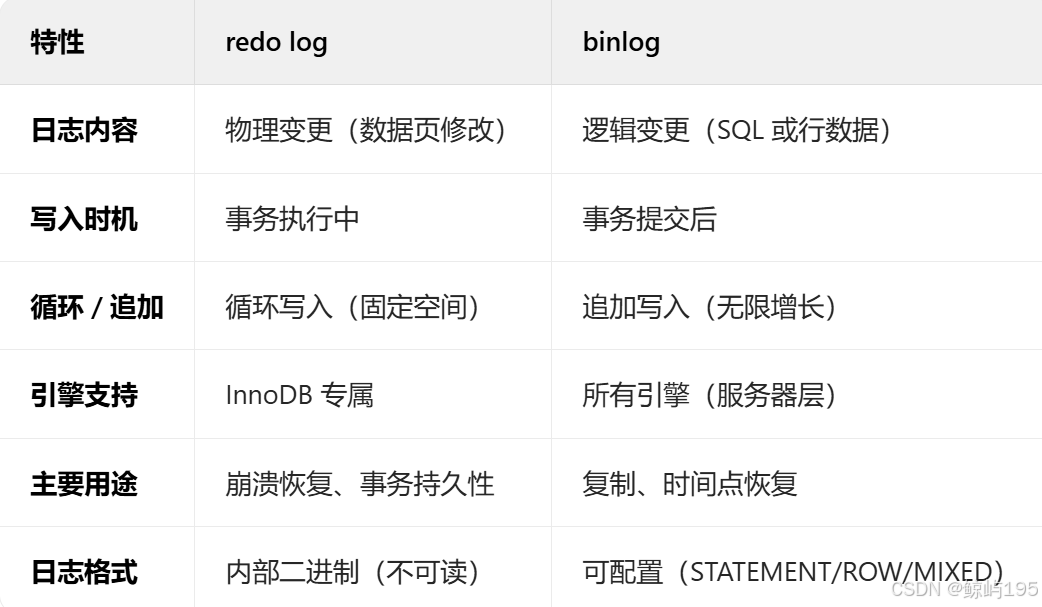
工作模式
1、語句模式
? ? ? binlog_format=statement(mysql5.7.6之前的默認級別)
# 語句模式介紹
只記錄對數據庫做出修改的sql語句,不記錄該sql的上下文信息# 優點
不需要記錄細到每一行數據的更改變化,因此,binlog日志量小,IO壓力小,性能較高?
例如:
? ? 一條語句修改了100萬行,該模式下只需要記錄下該條語句即可
?
# 缺點
日志中記錄的sql語句可能有上下文依賴,此時脫離了當前數據庫環就無法運行了,因此該模式下容易出現主從不一致的問題。
例如:
? ? 主庫記錄的某條sql語句引用了主庫中的函數、觸發器、存儲過程等特殊功能
? ? 在從庫上接收了該sql之后,可能就無法正確運行,從而主從庫數據不一致的問題。
?
ps:row模式是基于每一行來記錄變化的,所以不會出現類似的問題。
?
例如
開啟binlog日志后,我們在某個庫下自定義函數,若想定義成功需要先設置配置項
set global log_bin_trust_function_creators=TRUE; ??
但還是不推薦,因為你定義的函數后續語句再次進行調用時極度容易找不到,只存在于當前的位置
?
# 應用場景
sql語句對mysql內置功能依賴比較少:不使用存儲過程/觸發器/函數,可以使用該模式,否則還是推薦行級模式
2、行級模式
? ? ? binlog_format=row(mysql5.7.6之后+8.0默認級別)
# 行級模式介紹
記錄每一行數據修改的細節,即哪一條記錄被修改了,修改成什么樣了?
例如:執行語句(f1參照上例,此處略)
insert into t1(name) values(concat("egon",f1(1,2)));?
如果使用row模式,那么日志中會記錄插入了一條新記錄,記錄中的name字段值為'egon3'
?
# 優點
相當于把上下文依賴都記錄了下來,可以更方便查看每一條數據修改的細節,并且不會出現某些特定情況下的存儲過程或function以及trigger的調用和觸發無法被正確復制的問題,即該模式下主從復制強一致,數據最安全。
?
# 缺點
日志量大?
例如
? ? 一條語句修改了100萬行,語句模式下只需要記錄一條語句即可
? ? 而行級模式卻修改記錄下100萬行的修改記錄,binlog日志的量可能會大得驚人。
?
# 應用
sql語句對mysql內置功能依賴比較多,希望數據最安全,復制強一致的場景推薦行級模式
3、混合模式?
? ? ? binlog_format=mixed? 一般不用
相關概念及參數
- 事件events
binlog中的每一條記錄當作一個“事件”- 位置position(字節數)
把整個二進制文件想象成一個字節序列,從第一個字節開始記錄,每一個事件占對應據一個位置,依次類推
- server_id
服務ID,主從庫必須不一樣,建議數字為:ip+端口,5.7.3以后版本,必須指定- log-bin
此變量用于控制是否開啟二進制日志,而且這是一個只讀變量,默認值為OFF?
? ? ? ?當我們啟動數據庫以后,在當前數據庫連接中查看此變量的值,此變量值可能為OFF,表示不記錄二進制日志,如果想要記錄二進制日志,只需將此值設置為二進制日志的文件名即可
示例:
log-bin=/var/lib/mysql/mybinlog #絕對路徑
# log-bin=mybinlog #也可以用相對路徑, 會在$datadir下產生mysqlbinlog-00000N- log_bin_index
不設置的話,會根據log_bin值名稱自動生成mybinlog.index
log_bin_index=var/lib/mysql/mybinlog.index?- sql_log_bin
默認為ON
此變量用于標識當前會話中的操作是否會被記錄于二進制日志- binlog_format
此變量的值決定了二進制日志的記錄方式,此變量的值可以設置為statement、row、mixed,分別表示以語句的形式記錄二進制日志,以數據修改的形式記錄二進制日志,以混合的方式記錄二進制日志,安全保險起見,推薦使用row的方式記錄- sync_binlog
binlog刷盤策略- 其他參數
#打開才能查看詳細記錄,默認為off
binlog_rows_query_log_events=on??
#表示自動刪除10天以前的日志
expire_logs_days=10??
# full,minimal,noblob分別表示binlog中內容全記錄,只記錄被操作的,和不記錄二進制
binlog_row_image=full #(full,minimal,noblob)
管理
查看配置項
show variables like '%log_bin%';? ? #查看xxx變量
show variables like '%binlog%';
show variables like '%binlog_format%';
show variables like '%server%';
show variables like 'expire_logs_days'; -- 過期日志天數
?
# 或者
[root@db01 ~]# mysqladmin -uroot -pEgon@123 variables |grep -w log_bin
開啟
1.默認是關閉的?
2.配置開啟binlog
vim /etc/my.cnf
[mysqld]
server_id=1
log-bin=/var/lib/mysql/mybinlog?
binlog_format='row' #(row,statement,mixed),不建議隨意去修改binlog工作模式 ? ?
binlog_rows_query_log_events=on?
max_binlog_size=100M?
查看
#查看日志名、狀態、事件
show binary logs;? ?show master logs; #等效
show master status;? ? ? ? ? ? ? ? ? ? ? ? ? #查詢當前正在用的binlog
show binlog events in 'mybinlog.000002';? #顯示指定二進制日志文件中的所有事件詳情
show binlog events in 'mybinlog.000002' limit 3;
###查看日志內容
mysqlbinlog mybinlog.000002?
按時間:
# mysqlbinlog mybinlog.000002 --start-datetime="2022-11-05 10:02:56"
# mysqlbinlog mybinlog.000002 --stop-datetime="2022-11-05 11:02:54"
# mysqlbinlog mybinlog.000002 --start-datetime="2022-11-05 10:02:56" --stop-datetime="2022-11-05 11:02:54"??
按字節數:
# mysqlbinlog mybinlog.000002 --start-position=337
# mysqlbinlog mybinlog.000002 --stop-position=662
# mysqlbinlog mybinlog.000002 --start-position=337 --stop-position=662
?如果是行級模式,想要看懂詳細內容則需要加上額外參數,但是僅用于看懂內容,如果要用于還原數據,還是應該去掉額外的參數并將內容定位到文件中
#mysqlbinlog --base64-output=decode-rows -vvv mybinlog.000002 ?# 僅用于查看,不能用于日后的數據恢復#mysqlbinlog mybinlog.000002 ?--start-position=100 > /tmp/1.sql # /tmp/1.sql可用于日后的數據恢復
?如果查看過程報錯
unknown variable?'default-character-set=utf8mb4'?
原因是mysql5.6中,mysqlbinlog這個工具無法識別binlog中的配置中的default-character-set=utf8mb4這個配置項目。?
兩個方法可以解決這個問題
一是在MySQL的配置/etc/my.cnf中
將default-character-set=utf8mb4 修改為 character-set-server = utf8mb4,但是這需要重啟MySQL服務,如果你的MySQL服務正在忙,那這樣的代價會比較大。?
二是用mysqlbinlog --no-defaults mysql-bin.000001 命令打開
恢復數據
###恢復數據庫的時候關閉binlog的記錄功能
set sql_log_bin=1;? #在數據庫內臨時關閉,退出當前終端失效且設置僅在當前終端有效
set sql_log_bin=0; #恢復完成后再開啟
示例:
#修改數據
begin;
update user set name="XXX" where name="egon2";
commit;
#發現自己修改錯了
select * from user;
#回滾,回滾不了,已經提交了
rollback;
select * from user;
#一怒之下刪表
drop table user;
?
#恢復數據:查看binlog數據的起始點與要恢復到的位置點,導出成SQL
mysqlbinlog mybinlog.000002 --stop-position=772 > /tmp/binlog.sql?
mysql -uroot -pEgon@123 < /tmp/binlog.sql? ? #將文件導入mysql(數據庫外恢復)
或者
#source /tmp/binlog.sql? ?#在數據庫內恢復數據
刷新與清除binlog
# 清除二進制日志原則
- 在存儲能力范圍內,能多保留則多保留
- 基于上一次全備前的可以選擇刪除
?
1) 刪除所有binlog,相當于重置
reset master;
?
2) 刪除指定binlog名之前的所有binlog(保留指定的binlog)
purge binary logs to 'mybinlog.00003'; -- mybinlog.00003之前的都刪除掉
?
3)刪除日期之前的日志:手動執行
PURGE {MASTER | BINARY} LOGS BEFORE 'date' --用于刪除日期之前的日志,BEFORE變量的date自變量可以為'YYYY-MM-DD hh:mm:ss'格式
?
如:(MASTER 和BINARY 在這里都是等效的)
PURGE MASTER LOGS TO 'mybinlog.00003';
purge binary logs before '2021-07-13 19:11:00';?
還可以做減法:如只保留3天的
PURGE BINARY LOGS BEFORE now() - INTERVAL 3 day;
?4)刪除日期之前的日志:修改配置參數,讓mysql自動執行
刪除7天前的binlog
#臨時生效
SET GLOBAL expire_logs_days = 7;?
#永久生效
[root@db01 data]# vim /etc/my.cnf
[mysqld]
expire_logs_days = 7
三、備份與恢復
定義
為什么要備份
? ? ? ? ? 硬件故障? 軟件故障? 自然災害? 黑客攻擊? 誤操作(占比最大)
備份什么
? ? 數據
? ? 二進制日志,InnoDB事務日志
? ? 代碼(存儲過程、存儲函數、觸發器、事件調度器)
? ? 服務器配置文件
備份的類型
###根據備份時數據庫的運行狀態
1)冷備:停庫、停服務來備份
即當數據庫進行備份時, 數據庫不能進行讀寫操作, 即數據庫要下線?
2)溫備:不停庫、不停服務來備份,會(鎖表)阻止用戶的寫入 ??
即當數據庫進行備份時, 數據庫的讀操作可以執行, 但是不能執行寫操作?
3)熱備(建議):不停庫、不停服務來備份,也不會(鎖表)阻止用戶的寫入
即當數據庫進行備份時, 數據庫的讀寫操作均不是受影響?
注意:Innodb全都支持;MyISAM不支持熱備
###根據備份的內容
物理備份:直接將底層物理文件備份
邏輯備份:通過特定的工具從數據庫中導出sql語句或者數據,可能會丟失數據精度
###根據備份的數據量
# 1、差異備份(Differential Backup)
每次備份時,都是基于第一次完全備份的內容,只備份有差異的數據(新增的、修改的、刪除的),?
# 2、增量備份(Incremental Backup )
每次備份時,都是基于上一次備份的內容(注意是上一次,而不是第一次),只備份有差異的數據(新增的、修改的、刪除的),所以增量備份的結果是一條鏈# 1、全量備份的數據恢復
只需找出指定時間點的那一個備份文件即可,即只需要找到一個文件即可?
# 2、差異備份的數據恢復
需要先恢復第一次備份的結果,然后再恢復最近一次差異備份的結果,即需要找到兩個文件?
# 3、增量備份的數據恢復
需要先恢復第一次備份的結果,然后再依次恢復每次增量備份,直到恢復到當前位置,即需要找到一條備份鏈?
綜上,對比三種備份方案
1、占用空間:全量 > 差異 > 增量
2、恢復數據過程的復雜程度:增量 > 差異 > 全量
備份工具
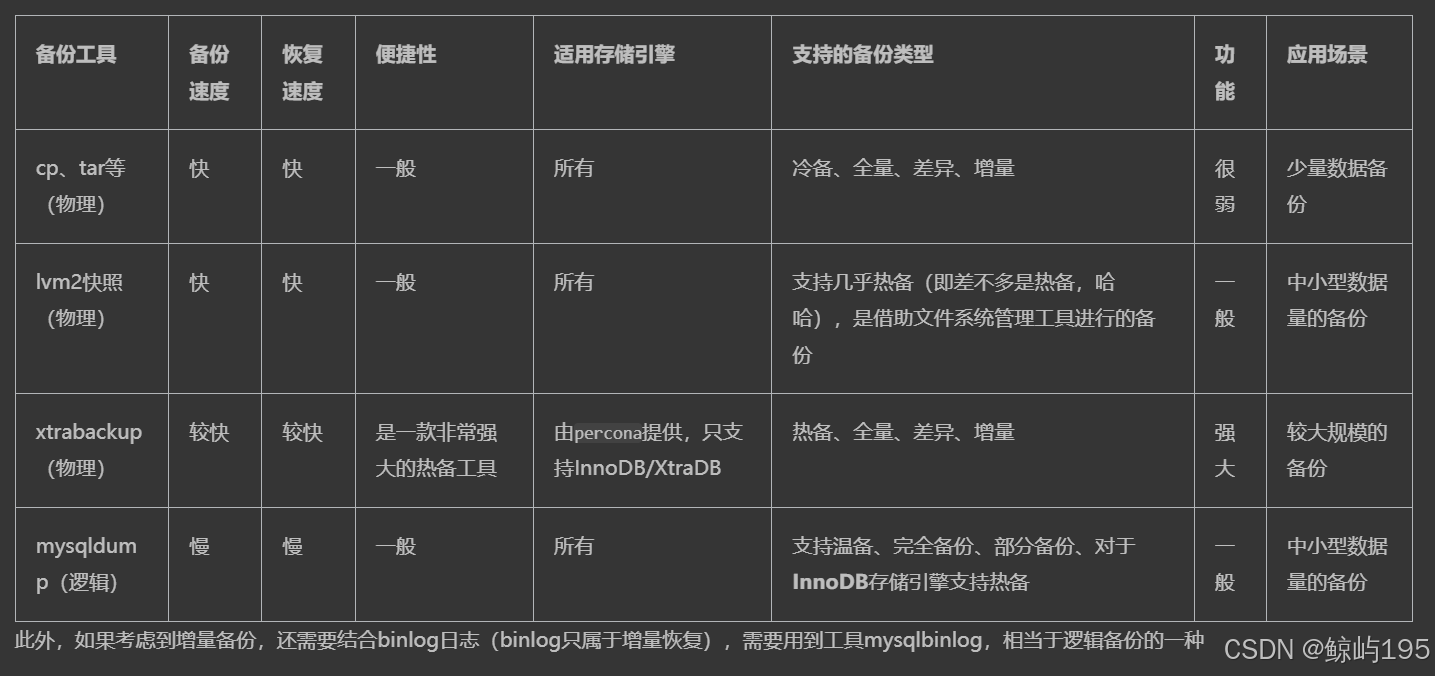
備份策略及應用場景
- 直接cp,tar復制數據庫文件
- mysqldump 全量 + 復制binlogs 增量
- lvm2快照 全量 +?復制binlogs 增量
- xtrabackup 全量+增量
xtrabackup 全量 + binlogs 增量
1.如果數據量較小, 可以使用第一種方式,直接復制數據庫文件,
2.如果數據量還行,可以使用第二種方式,先使用mysqldump對數據庫進行完全備份,然后定期備份BINARY LOG達到增量備份的效果
3.如果數據量一般,而又不過分影響業務運行,可以使用第三種方式,使用lvm2的快照對數據文件進行備份,而后定期備份BINARY LOG達到增量備份的效果
4.如果數據量很大,而又不過分影響業務運行,可以使用第四種方式,使用xtrabackup進行完全備份后,定期使用xtrabackup進行增量備份或差異備份
備份實踐
每天或者每周全備一次,全備之后那個位置點之前的binlog全都可以刪除
cp
#1、向所有表施加讀鎖
FLUSH TABLES WITH READ LOCK; ??
#2、備份數據文件
mkdir /egon_bak
cp -a /var/lib/mysql/* /egon_bak
# 數據丟失
rm -rf /var/lib/mysql/*?
# 恢復數據
cp -a /egon_bak/* /var/lib/mysql
# 重啟服務
systemctl restart mysql
mysqldump
#==========語法
mysqldump ?-h 服務器 ?-u用戶名 ?-p密碼 ?選項與參數 > 備份文件.sql
?
===選項與參數
1、-A/--all-databases ? ? ? ? ? ? 所有庫
2、-B/--databases bbs db1 db2 ? ? 多個數據庫
3、db1 ? ? ? ? ? ? ? ? ? ? ? ? ?數據庫名
4、db1 t1 t2 ? ? ? ? ? ? ? ? db1數據庫的表t1、t2
5、-F ? ? ? ? ? ? ? ? ? ? ? ? ? 備份的同時刷新binlog;做完全量刷新一個新的binlog文件進行備份方便查找
6、-R 備份存儲過程和函數數據(如果開發寫了函數和存儲過程,就備,沒寫就不備)
7、--triggers 備份觸發器數據(現在都是開發寫觸發器)
8、-E/--events 備份事件調度器
9、-d 僅表結構
10、-t 僅數據
11、--master-data=1 ?備份文件中 change master語句是沒有注釋的,默認為1
用于已經制作好了主從,現在想擴展一個從庫的時候使用
如此備份,擴展添加從庫時導入備份文件后
便不需要再加mater_pos了
change matser to
master_host='10.0.0.111'
master_user='rep'
master_password=123
master_log_pos=120
master_log_file='master-bin.000001'?
12、--master-data=2 ?備份文件中 change master語句是被注釋的?
?
13、--lock-all-tables 備份過程中所有表從頭鎖到尾,簡單粗暴
在mysqldump導出的整個過程中以read方式鎖住數據庫中所有表,類似 flush tables with read lock 的全局鎖),這是一個全局讀鎖,只允許讀不允許寫,以此保證數據一致性。所以生產數據庫的備份策略上,也很少使用該參數。該參數本身默認off,但使用該參數的話,也會自動將 --single-transaction 及 --lock-tables 參數置于 off 狀態,他們是互斥的。
??
14、--single-transaction: 快照備份 (搭配--master-data可以做到熱備)
保證各個表具有數據一致性快照。
指定 --single-transaction 參數,那么導出過程中只能保證每個表的數據一致性(利用多版本特性實現,目前只能針對InnoDB事務表)。
15、--lock-tables:如果是備份所有庫,那么備份到某個庫時只鎖某個庫,其他庫可寫,而--lock-all-tables是從始自終都全都鎖定
?
?
#==========完整語句?
mysqldump -uroot -pEgon@123 -A -E -R --triggers --master-data=2 --single-transaction > /backup/full.sql
?
#====文件太大時可以壓縮 gzip ,但是gzip不屬于mysql獨有的命令,可以利用管道
mysqldump -uroot -pEgon@123 -A -E -R --triggers --master-data=2 --single-transaction | gzip > /tmp/full$(date +%F).sql.gz
?
#====導出時壓縮了,導入時需要解壓,可以使用zcat命令,很方便
zcat /backup/full$(date +%F).sql.gz | mysql -uroot -p123
遠程連一個賬戶用for循環一直進行寫操作模擬數據庫使用場景(復現熱備,恢復數據)
### 增量恢復不一定是一次性恢復完的,中間可能會夾雜著一些刪除語句,提前查詢binlog確定好位置再恢復數據===> 1、grep過濾?
===> 2、檢查事件:依據End_log_pos的提示,來確定某一個事件的起始位置與結束位置
mysql> show binlog events in 'mybinlog.000001';?
如果事件很多,可以分段查看
mysql> show binlog events in 'mybinlog.000001' limit 0,30;?
mysql> show binlog events in 'mybinlog.000001' limit 30,30;?
mysql> show binlog events in 'mybinlog.000001' limit 60,30;??
===> 3、利用mysqlbinlog命令
### 生產中很多庫,只有一個庫的表被刪除,我不可能把所有的庫都導出來篩選,因為那樣子binlog內容很多,辨別復雜度高,我們可以利用?
[root@egon mysql]# mysqlbinlog -d db1 --start-position=123 --stop-position=154 mybinlog.000001 --base64-output=decode-rows -vvv | grep -v 'SET'
參數解釋:
1)-d 參數接庫名
mysqlbinlog -d database --base64-output=decode-rows -vvv mysql-bin.000002
2)--base64-output ?顯示模式
3)-vvv ? ? ? ? ?顯示詳細信息
###備份
# 先打開binlog日志
# 在命令行執行下述命令,進行全量備份
[root@egon mysql]mysqldump -uroot -pEgon@123 -A -R --triggers --master-data=2 --single-transaction | gzip > /tmp/full.sql.gz
# 全量備份完畢后的一段時間里,數據依然插入,寫入了mybinlog.000001中
# 然后我們在命令行刷新binlog,產生了新的mybinlog.000002
[root@egon mysql]mysql -uroot -pEgon@123 -e "flush logs"
# 此時數據依然在插入,但都寫入了最新的mybinlog.000002中,所以需要知道的是,增量的數據在mysqlbinlog.000001與mybinlog.000002中都有
###恢復
mysql> set sql_log_bin=0;
mysql> system zcat /tmp/full.sql.gz | mysql -uroot -pEgon@123
mysql> select * from db1.s1; -- 查看恢復到了id=28,剩下的去增量里恢復# 在命令行導出mybinlog.000001中的增量,然后登錄庫進行恢復
查找位置,發現@1=29即第一列等于29,即id=29的下一個position是10275
mysql> show binlog events in 'mybinlog.000001';
[root@egon mysql]# mysqlbinlog mybinlog.000001 --start-position=10038 --stop-position=11340 --base64-output=decode-rows -vvv | grep -v 'SET' | less在命令行中執行導出
[root@egon mysql]# mysqlbinlog mybinlog.000001 --start-position=10275 > /tmp/1.sql在庫內執行導入,發現恢復到了39
mysql> source /tmp/1.sql -- 最好是在庫內恢復,因為sql_log_bin=0,導入操作不會記錄
mysql> select * from db1.s1;# 在命令行導出mybinlog.000002中的增量,然后登錄庫進行恢復
上面恢復到了id=39,我們接著找id=40的進行恢復,查找位置
發現@1=40的position是432
發現@1=55的position是6464
mysql> show binlog events in 'mybinlog.000002';
[root@egon mysql]# mysqlbinlog --base64-output=decode-rows -vvv mybinlog.000002|grep -v 'SET'|grep -C20 -w '@1=40'
[root@egon mysql]# mysqlbinlog --base64-output=decode-rows -vvv mybinlog.000002|grep -v 'SET'|grep -C20 -w '@1=55'導出
[root@egon mysql]# mysqlbinlog mybinlog.000002 --start-position=432 --stop-position=6464> /tmp/2.sql在庫內執行導入,發現恢復到了55
mysql> source /tmp/2.sql
mysql> select * from db1.s1;# 開啟binlog
mysql> SET sql_log_bin=ON; lvm2快照備份
###創建快照卷并備份
mysql> FLUSH TABLES WITH READ LOCK; ? ? #鎖定所有表
Query OK, 0 rows affected (0.00 sec)[root@node1 lvm_data]# lvcreate -L 1G -s -n lv1_from_vg1_snap /dev/vg1/lv1 ? #創建快照卷mysql> UNLOCK TABLES; ?#解鎖所有表
Query OK, 0 rows affected (0.00 sec)[root@node1 lvm_data]# mkdir /snap1 ?#創建文件夾
[root@node1 lvm_data]# mount -o nouuid /dev/vg1/lv1_from_vg1_snap /snap1[root@localhost snap1]# cd /snap1/[root@localhost snap1]# tar cf /tmp/mysqlback.tar * ?[root@localhost snap1]# umount /snap1/ -l
[root@localhost snap1]# lvremove vg1/lv1_from_vg1_snap###恢復? ?rm -rf /var/lib/mysql/*
tar xf /tmp/mysqlback.tar -C /var/lib/mysql/xtrabackup
一種mysql數據庫備份工具----速度快、熱備、自動備份檢驗,配合inodb使用
mysql 5.7以下版本,可以采用percona xtrabackup 2.4版本?
mysql 8.0以上版本,可以采用percona xtrabackup 8.0版本,xtrabackup8.0也只支持mysql8.0以上的版本
比如,接觸過一些金融行業,mysql版本還是多采用mysql 5.7,當然oracle官方對于mysql 8.0的開發支持力度日益加大,新功能新特性迭代不止。生產環境采用mysql 8.0的版本比例會日益增加。
安裝
#第一種
# 安裝yum倉庫
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm -y# 安裝XtraBackup命令
yum install percona-xtrabackup-24 -y#第二種
#下載epel源
wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo#安裝依賴
yum -y install perl perl-devel libaio libaio-devel perl-Time-HiRes perl-DBD-MySQL#下載Xtrabackup
wget https://downloads.percona.com/downloads/Percona-XtraBackup-2.4/Percona-XtraBackup-2.4.23/binary/redhat/7/x86_64/percona-xtrabackup-24-2.4.23-1.el7.x86_64.rpm# 安裝
yum localinstall -y percona-xtrabackup-24-2.4.4-1.el6.x86_64.rpm命令
xtrabackup ? ? ?以前使用該命令
innobackupex ? ?現在使用該命令
innobackupex是xtrabackup的前端配置工具,使用innobackupex備份時, 會調用xtrabackup備份所有的InnoDB表, 復制所有關于表結構定義的相關文件(.frm)、以及MyISAM、MERGE、CSV和ARCHIVE表的相關文件, 同時還會備份觸發器和數據庫配置文件信息相關的文件, 這些文件會被保存至一個以時間命名的目錄.
備份方式
1.對于非innodb表(比如myisam)是直接鎖表cp數據文件,屬于一種溫備。?
2.對于innodb的表(支持事務),不鎖表,cp數據頁最終以數據文件方式保存下來,并且把redo和undo一并備走,屬于熱備方式。
3.備份時讀取配置文件/etc/my.cnf
###全量
#1、創建備份目錄,會把mysql的datadir中的內容備份到改目錄中
mkdir /backup
#2、全備
#2.1 在本地執行下述命令,輸入登錄數據的本地賬號與密碼
#2.2 指定備份目錄為/backup下的full目錄
innobackupex --user=root --password=123 /backup/full?
#3、查看:默認會在備份目錄下生成一個以時間戳命名的文件夾
[root@localhost ~]# cd /backup/full/
[root@localhost full]# ls
2021-07-16_16-09-47
[root@localhost full]# ls 2021-07-16_16-09-47/ #備份目錄
。。。
[root@localhost full]# ls /var/lib/mysql # 數據目錄
。。。?
# 4、去掉時間戳,讓備份數據直接放在備份目錄下
我們在寫備份腳本和恢復腳本,恢復的時候必須指定上一次備份的目錄,如果備份目錄帶著時間戳,該時間戳我們很難在腳本中確定,為了讓腳本編寫更加方便,我們可以使用選項--no-timestamp去掉時間戳,讓備份內容直接放置于我們指定的目錄下
[root@localhost full]# rm -rf 2021-07-16_17-45-53/
[root@localhost full]# innobackupex --user=root --password=123 --no-timestamp /backup/full?
# 補充:關于備份目錄下新增的文件說明,可用cat命令查看
xtrabackup_checkpoints 存儲系統版本號,增備的時候會用到
xtrabackup_info 存儲UUID,數據庫是由自己的UUID的,如果相同,做主從會有問題
xtrabackup_logfile 就是redo
###增量#一 基于上一次備份進行增量,參數說明:
--incremental:開啟增量備份功能
--incremental-basedir:上一次備份的路徑?
#二 加上上一次命令
innobackupex --user=root --password=123 --no-timestamp --incremental --incremental-basedir=/backup/full/ /backup/xtra
?
#三 判斷數據備份是否銜接
cat /backup/full/xtrabackup_checkpoints
? ? backup_type = full-backuped
? ? from_lsn = 0
? ? to_lsn = 1808756
? ? last_lsn = 1808756
? ? compact = 0
? ? recover_binlog_info = 0
? ? flushed_lsn = 1808756
?
cat /backup/xtra/xtrabackup_checkpoints?
? ? backup_type = incremental
? ? from_lsn = 1808756 ?# 值應該與全被的to_lsn一致
? ? to_lsn = 1808756
? ? last_lsn = 1808756
? ? compact = 0
? ? recover_binlog_info = 0
? ? flushed_lsn = 1808756
四、快速的導出和導入、數據遷移
select into outfile? 導出
load data infile? 導入
12G的數據導入約4分鐘,導出約3分鐘(十幾個G需要十分鐘左右)
快速導出
語法:
SELECT... INTO OUTFILE 導出文本文件
要想導出成功,需要設置安全目錄才行
vim /etc/my.cnf
[mysqld]
secure-file-priv=/tmp
?
示例:
SELECT * FROM db1.t1
? ? INTO OUTFILE '/tmp/db1_t1.txt'
? ? FIELDS TERMINATED BY ',' ? ? ?-- 定義字段分隔符,不指定默認為空格
? ? OPTIONALLY ENCLOSED BY '"' ? ?-- 定義字符串使用什么符號括起來
? ? LINES TERMINATED BY '\n'; ? ? -- 定義換行符
快速導入
(新表與舊表的表結構應該保持一致)
語法
LOAD DATA INFILE 導入的文本文件路徑
?
示例
mysql> DELETE FROM student1;
mysql> create table new_t1(表結構與文件中數據保持一致);
mysql> LOAD DATA INFILE '/tmp/db1_t1.txt'
? ? ? ? ? ? INTO TABLE new_db.new_t1
? ? ? ? ? ? FIELDS TERMINATED BY ','
? ? ? ? ? ? OPTIONALLY ENCLOSED BY '"'
? ? ? ? ? ? LINES TERMINATED BY '\n';
導出其他格式
mysql 命令導出文本文件
示例:
# mysql -u root -pEgon123 -e 'select * from db1.t1' > /tmp/db1_t1.txt
# mysql -u root -pEgon123 --xml -e 'select * from db1.t1' > /tmp/db1_t1.xml? ? #給別人用
#?xml? ----跨平臺交互數據格式
# mysql -u root -pEgon123 --html -e 'select * from db1.t1' > /tmp/db1_t1.html? ?#給別人看
數據遷移
方案一:數據庫導出,拷貝到新服務器,再導入
(數據遷移是因為業務瓶頸或項目改造等需要變動數據表結構的只能用此法)
#例如
(1)基于mysqldump(數據量小)
###在源主機執行下述命令,需要目標主機開啟遠程賬號權限
mysqldump -h 遷移源IP -uroot -p123 --databases bbs | mysql -h 目標IP -uroot -p456?
(2)基于LOAD DATA INFILE(數據量大)
?
#優點:
會重建數據文件,減少數據文件的占用空間(釋放undo段),兼容性最好(版本兼容),導出導入很少發生問題,需求靈活?
#缺點:
導入導出都需要很長的時間,并且導出后的文件還要經過網絡傳輸,也要占用一定的時間。
方案二:第三方遷移工具
#例如
使用【MySQL GUI Tools】中的 MySQLMigrationTool。
?
#優點:
設置完成后傳輸無人值守,自動完成?
#缺點:
1、不夠靈活,設置繁瑣
2、傳輸時間長,
3、傳輸中網絡出現異常,不能及時的被發現,并且會一直停留在數據傳輸的狀態不能被停止,如不仔細觀察不會被發現異常。
4、異常后很難從異常的位置繼續傳輸。
方案三:數據文件和庫表結構文件直接拷貝到新服務器,掛載到同樣配置的mysql服務下
優點:
時間占用最短,文件可斷點傳輸,操作步驟少。?
缺點:
新舊服務器中MySQL版本及配置必須相同,可能引起未知問題。
1、保證Mysql版本一致,安裝配置基本一致(注意:這里的數據文件和庫表結構文件都指定在同一目錄data下)
2、停止兩邊的Mysql服務(A服務器--遷移-->B服務器)
3、刪除B服務器Mysql的data目錄下所有文件
4、拷貝A服務器Mysql的data目錄下除了ib_logfile和.err之外的文件到B服務器data下
5、啟動B服務器的Mysql服務,檢測是否發生異常
五、Mysql主從
定義
將主服務器的binlog日志復制到從服務器上執行一遍,達到主從數據的一致狀態,稱之為主從復制。
作用
為什么要做主從
- 為實現數據庫服務器的負載均衡/讀寫分離做鋪墊,提升訪問速度
- 通過復制實現數據的異地備份,保障數據安全
- 提高數據庫系統的可用性
從庫臨時取代主庫,但只用來讀(要求高安全性的場景)
從庫永久取代主庫,負責讀、寫(新舊服務器數據的安全策略應相同)
補充:讀寫分離
#1、什么是讀寫分離
有了主從保持數據一致作為大前提,我們便可以可以分離讀寫操作,其中Master負責寫操作的負載,也就是說一切寫的操作都在Master上進行,而讀的操作則分攤到Slave上進行。
#2、讀寫分離的作用
先說答案:讀寫分離可以大大提高讀取的效率。?
讀/寫的比例大概在 10:1左右 ,也就是說寫操作非常少,大量的數據操作是集中在讀的操作
寫操作涉及到鎖的問題,不管是行鎖還是表鎖還是塊鎖,都是比較降低系統執行效率的事情。
?
#3、具體做法
方案一:
就是主庫寫,從庫讀?
方案二:
主庫負責寫,還有部分讀,從庫只負責讀,而且是讀操作的主力
?
即當主服務器比較忙時,部分查詢請求會自動發送到從服務器中,以降低主服務器的工作負荷。
但哪些重要的數據還是用主庫來讀交給開發負責
主從復制的原理
master主? slave從
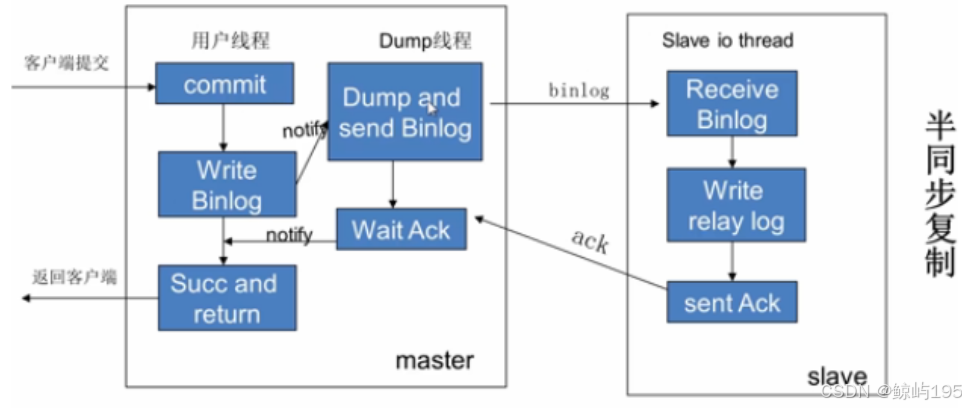
限制:客戶在master上的寫請求是并發的,但dump線程的提交(同步操作)是串行的
整體復制步驟:
- master將改變記錄到binlog中
- slave的io線程將master的binlog拷貝到它的中繼日志relaylog
- slave的sql線程解析中繼日志的事件并執行,保持與主庫一致
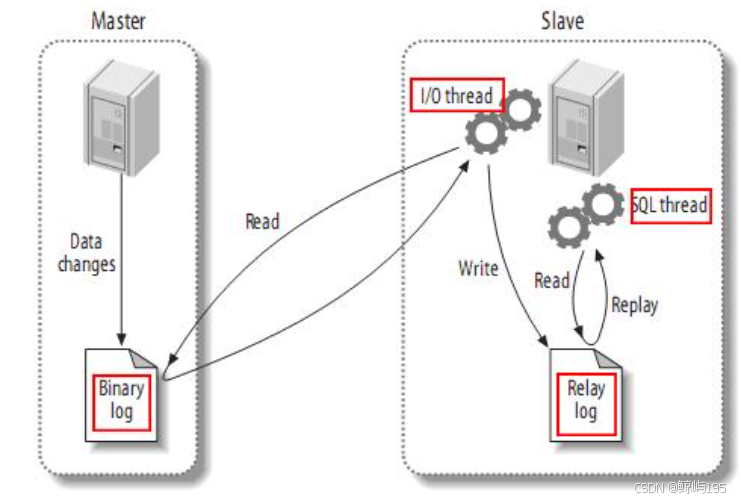
詳解:
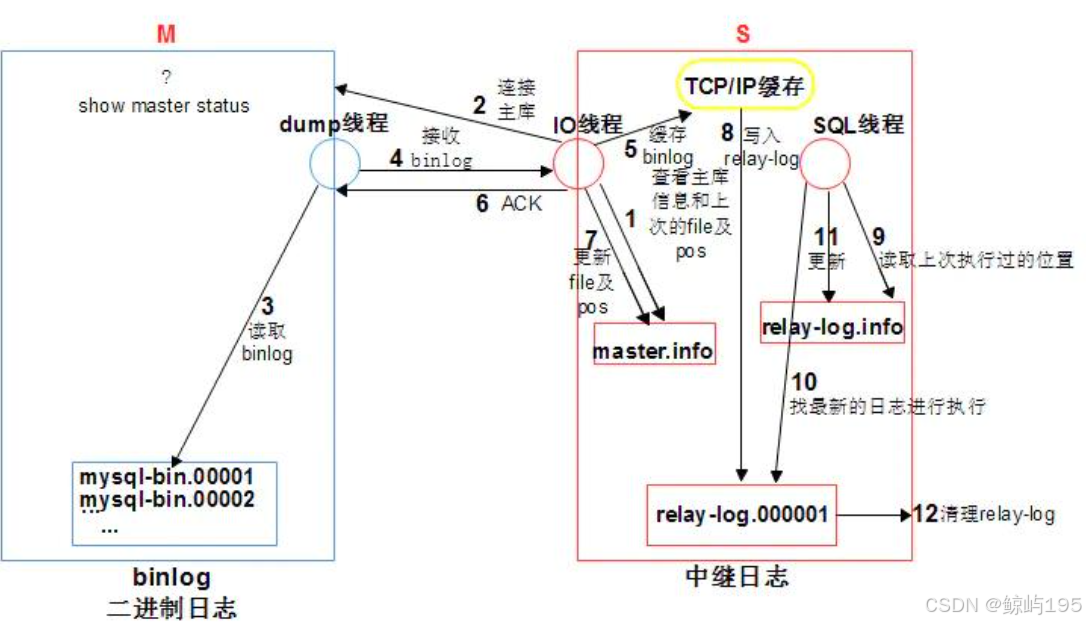
# 從庫準備
(1)從庫change master to 時,ip port user password binlog position寫入到master.info進行記錄
(2)從庫 start slave 時,會啟動IO線程和SQL線程
?
# 同步的過程
1.從庫的IO線程,讀取master.info信息,獲取主庫信息并連接主庫
2.主庫接收從庫的鏈接請求后,會生成一個準備binlog DUMP的線程,來響應從庫
3.主庫一旦有新的日志生成,會發送“信號”給主庫的binlog dump線程,然后binlog dump線程會讀取binlog日志的更新
4.TP(傳送)給從從庫的IO線程
5.IO線程將收到的日志存儲到了TCP/IP 緩存
6.寫入TCP/IP緩存后,立即返回ACK給主庫 ,此時主庫工作完成
7.IO線程更新master.info文件binlog 文件名和postion
8.IO線程將緩存中的數據,存儲到relay-log日志文件,此時io線程工作完成
9.從庫SQL線程讀取relay-log.info文件,獲取到上次執行到的relay-log的位置,作為起點
10.從庫SQL線程基于從步驟9中獲取到的起點,去中繼日志relay-log.000001獲取后續操作,在從庫回放relay-log
11.SQL線程回放完成之后,會更新relay-log.info文件,把當前操作的位置記入,作為下一次操作的起點。
12. relay-log會有自動清理的功能。
主從復制的日志格式
等于binlog日志(二進制日志)的日志格式
主從復制的方式
雙主---互相開啟binlog與relaylog
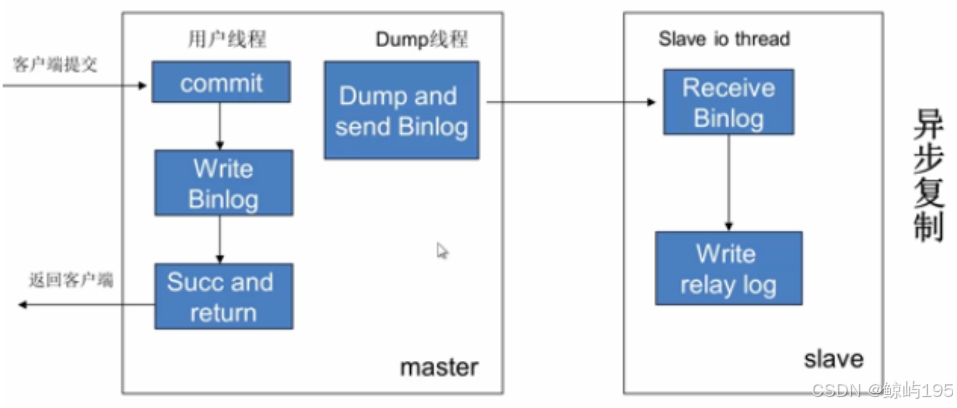
異步復制
客戶端線程提交一個寫操作,寫入主庫的binlog日志后就立即返回,不等從庫完成同步操作,主庫的dump線程會監測binlog日志的變量然后主動將更新推送給從庫。
- 客戶端的寫請求是并發的,但dump線程的提交(同步操作)是串行的且數據量一大或者網絡延遲,會造成延遲現象;也會存在數據丟失的問題,主庫寫入binlog后數據還沒推送到從庫就丟了,但返回給客戶端的是操作成功
- Mysql主從復制默認為異步復制
- 一次寫操作刷入一個日志
- 適用于追求效率高的場景
部署異步復制
前提:主從數據庫版本一致
主庫停服時制作主從(無讀寫操作)?
rm -rf /var/lib/mysql/*? #在測試環境下做實驗時初始化數據庫
主庫192.168.15.101:
創建一個用于復制的賬號并賦予replication slave權限
mysql> grant replication slave on *.* to 'egon'@'%' identified by '123';
mysql> flush privileges;修改主庫配置文件,開啟主庫binlog,并設置server-id
[mysqld]
# 節點ID,確保服務器的唯一性
server-id = 1 #開啟mysql的binlog日志功能
log-bin = mysql-bin
#控制數據庫的binlog刷到磁盤上去 , 0 不控制,性能最好,1每次事物提交都會刷到日志文件中,性能最差,最安全
sync_binlog = 1
#binlog日志格式
binlog_format = row
#binlog過期清理時間
expire_logs_days = 7
#binlog每個日志文件大小
max_binlog_size = 100m
#binlog緩存大小
binlog_cache_size = 4m
#最大binlog緩存大小
max_binlog_cache_size= 512m #不生成日志文件的數據庫,多個忽略數據庫可以用逗號拼接,或者 復制黏貼下述配置項,寫多行
binlog-ignore-db=mysql # 表中自增字段每次的偏移量
auto-increment-offset = 1
# 表中自增字段每次的自增量
auto-increment-increment = 1
#跳過從庫錯誤
slave-skip-errors = all 重啟主庫
systemctl restart mysql備份主庫,備份時鎖表保證備份一致?
mysqldump -uroot -pEgon@123 -A -E -R --triggers --triggers --master-data=2 --single-transaction > /tmp/all.sql發送給從庫
scp /tmp/all.sql root@192.168.15.100:/tmp從庫:192.168.15.100
測試復制賬號并導入初始數據
mysql -uegon -p123 -h 192.168.15.101
mysql -uroot -pEgon@123 < /tmp/all.sql 修改從庫配置文件增加server-id(唯一)并重啟從庫
[mysqld]
server-id = 2relay-log = mysql-relay-bin
replicate-wild-ignore-table=mysql.%
replicate-wild-ignore-table=test.%
replicate-wild-ignore-table=information_schema.%# 從庫也可以開啟binlog,但通常關閉
# log-bin=mysql-binsystemctl restart mysqld去主庫查看binlog日志名與位置在從庫進行配置并開啟slave線程
#主庫
show master status;#從庫
[root@slave1 ~]# mysql -uroot -pEgon@123 # 登錄然后執行
change master to
master_host='192.168.15.101', -- 庫服務器的IP
master_port=3306, -- 主庫端口
master_user='egon', -- 主庫用于復制的用戶
master_password='123', -- 密碼
master_log_file='mysql-bin.000001', -- 主庫日志名
master_log_pos=120; -- 主庫日志偏移量,即從何處開始復制#啟動slave線程并檢查
mysql> start slave;
Query OK, 0 rows affected (0.01 sec)show slave status\G
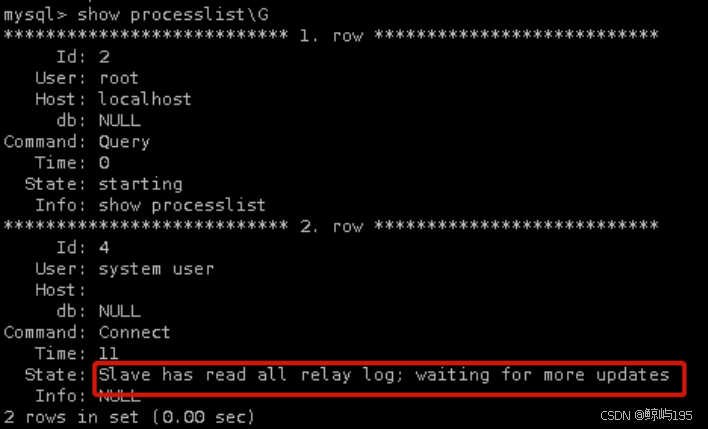
##io線程與sql線程為yes狀態即可? ? ? ??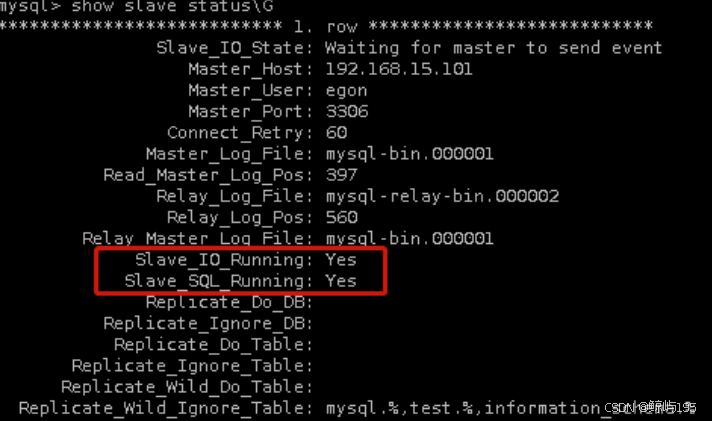
? ? ? ??
??
主庫運行時制作主從
先做全量備份,備份完成后進行打點記錄,從庫配置完成后在進行增量備份與主庫同步的時候從做完全量備份時打點的位置開始同步數據,防止中間一段時間主庫寫入數據的丟失
打點備份:記錄做完全量備份的時候binlog記錄的位置position
1.準備純凈的從庫環境
主庫:192.168.15.101
從庫:192.168.15.100
?
2.修改主庫配置文件(略)
3.重啟主庫(略)
4.主庫創建賬號(略)
5.模擬主庫運行,有數據寫入、
for i in `seq 1 1000000`
do?
? ? mysql -uroot -p123 -e "insert db1.t1 values($i)";
? ? sleep 1;
done
?
6.主庫全備數據
#不打點備份(no)
mysqldump -uroot -p123 -A -R --triggers > /tmp/all.sql
#打點備份(yes)
mysqldump -uroot -p123 -A -R --triggers --master-data=2 --single-transaction > /tmp/all.sql
?
7.將熱備數據傳達從庫
scp /tmp/all.sql 192.168.15.100:/tmp
?
8.修改從庫配置文件(略)
?
9.重啟從庫(略)
?
10.在從庫導入全備數據(導入打點備份)
11.查看sql文件中的位置點(如果是打點備份的話)
該位置即主庫剛剛做完全量備份時,主庫binlog日志所處的位置
[root@egon ~]# head -50 /tmp/all.sql|grep 'MASTER_LOG_POS'
-- CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=129005;
?
12.從庫配置同步
[root@slave1 ~]# mysql -uroot -pEgon@123 # 登錄然后執行
change master to
master_host='192.168.15.101',
master_port=3306,?
master_user='egon',
master_password='123',
master_log_file='mysql-bin.000001',?
master_log_pos=129005;?
?
13.開啟SQL線程和IO線程
? ? start slave;
14.查看主從狀態
? ? show slave status;
半同步復制(Mysql5.5開始)
1、一個事務操作的完成需要記完兩份日志,即主從的binlog是同步的
半同步復制,當主庫每提交一個事務后,不會立即返回,而是等待其中一個從庫接收到Binlog并成功寫入Relay-log中才返回客戶端,所以這樣就保證了一個事務至少有兩份日志,一份保存在主庫的Binlog,另一份保存在其中一個從庫的Relay-log中,從而保證了數據的安全性和一致性。
?
2、半同步即并非完全同步
從庫的數據對于主庫來說還是有延時的,這個延時就是從庫sql線程執行Relay-log的時間。所以只能稱為半同步。
?
3、半同步復制超時則會切換回異步復制,正常后則切回半同步復制
在半同步復制時,如果主庫的一個事務提交成功了,在推送到從庫的過程當中,從庫宕機了或網絡故障,導致一段時間內從庫并沒有接收到這個事務的Binlog,此時主庫會等待一段時間(這個時間由rpl_semi_sync_master_timeout的毫秒數決定),如果這個時間過后還無法推送到從庫,那MySQL會自動從半同步復制切換為異步復制先返回給用戶操作成功的信息,當從庫恢復正常連接到主庫后,主庫又會自動切換回半同步復制。
- 一次寫操作刷入兩次日志? 主庫的binlog與從庫的relaylog
- 主從之間不存在數據丟失,問題出現在從庫的sql線程讀取上,sql運行過慢會出現延遲
- 適用于對數據一致性要求高的場景,例如做負載均衡
- 可靠性大于異步復制
部署半同步復制
通過使用插件實現,主從庫使用的插件不一樣
確認mysql服務器是否支持動態增加插件
mysql> select @@have_dynamic_loading;
+------------------------+
| @@have_dynamic_loading |
+------------------------+
| YES |
+------------------------+
1 row in set (0.00 sec)主從分別安裝插件
# 插件一般默認在MySQL安裝目錄/lib/plugin下,可以去查看一下是否存在
ls /usr/lib64/mysql/plugin/ | grep semisync# 主庫的插件是semisync_master.so,從庫是semisync_slave.so主庫> install plugin rpl_semi_sync_master soname 'semisync_master.so';從庫> install plugin rpl_semi_sync_slave soname 'semisync_slave.so';# 安裝完成后,在plugin表(系統表)中查看一下
select * from mysql.plugin;開啟半同步復制
###主庫
#啟動插件
mysql> set global rpl_semi_sync_master_enabled=1;
#設置超時
mysql> set global rpl_semi_sync_master_timeout=30000;#修改配置文件
[root@db01 ~]# vim /etc/my.cnf
#在[mysqld]標簽下添加如下內容(不用重啟庫,因為上面已經開啟了)
[mysqld]
rpl_semi_sync_master_enabled=1
rpl_semi_sync_master_timeout=1000###從庫
#啟動插件
mysql> set global rpl_semi_sync_slave_enabled=1;#重啟io線程使其生效
mysql> stop slave io_thread;
mysql> start slave io_thread;#編輯配置文件(不需要重啟數據庫)
[root@mysql-db02 ~]# vim /etc/my.cnf#在[mysqld]標簽下添加如下內容
[mysqld]
rpl_semi_sync_slave_enabled =1
查看狀態
mysql>show status like '%semi_sync';在輸出信息中,我們重點關注三個參數:#ON表示半同步復制打開,OFF表示關閉
rpl_semi_sync_master_status OFF/ON#這個數字表示主庫當前有幾個事務說通過半同步復制到從庫的
rpl_semi_sync_master_yes_tx [number] #表示有幾個事務不是通過半同步復制到從庫的
rpl_semi_sync_master_no_tx [number] 全同步復制
(效率過低)----等11步完成后才回復給客戶端確認消息
延遲從庫
- 我們說用延時從庫可以做備份,主庫執行刪除的時候,從庫還沒有刪除,可以把表數據拿出來恢復回去
- 企業中一般會延時3-6小時
- 延時從庫是在SQL線程做的手腳,IO線程已經把數據放到relay-log里了.
SQL線程在執行的時候,會延遲你設定的時間長度
配置
- 已經存在主從
1.停止主從
? ? mysql> stop slave;
2.設置延時為180秒
? ? mysql> CHANGE MASTER TO MASTER_DELAY = 180;
3.開啟主從
? ? mysql> start slave;
4.查看狀態
? ? mysql> show slave status \G
? ? SQL_Delay: 180
5.主庫創建數據,會看到從庫值變化,創建的庫沒有創建
? ? SQL_Remaining_Delay: 170
? - 主從還未建立
1.修改主庫,從庫配置文件
? ? server_id
? ? 開啟binlog
?
2.保證從庫和主庫的數據一致
?
3.執行change語句
? ? change master to
? ? master_host='172.16.1.50',
? ? master_user='rep',
? ? master_password='123',
? ? master_log_file='mysql-bin.000001',
? ? master_log_pos=2752,
? ? master_delay=180;
? - 延時從庫的停止
1.停止主從
mysql> stop slave;
?
2.設置延時為0
mysql> CHANGE MASTER TO MASTER_DELAY = 0;
?
3.開啟主從
mysql> start slave;
?
#注:做延時從庫只是為了備份,不提供服務
延時從庫進行數據恢復
1、場景
總數據量級500G,正常備份去恢復需要1.5-2小時
1)配置延時3600秒
mysql> CHANGE MASTER TO MASTER_DELAY = 3600;?
2)主庫
drop database db;?
3)怎么利用延時從庫,恢復數據?
2、環境準備
1.進行每日的全備
mysqldump -uroot -p123 -A -R --triggers --master-data=2 –single-transaction > /backup/full.sql?
2.調整延時從庫延時時間為60分鐘
? ? stop slave;
? ? CHANGE MASTER TO MASTER_DELAY = 3600;
? ? start slave;?
3.主庫寫入新數據
? ? create database yanshi;
? ? use yanshi;
? ? create table yanshi(id int);
? ? insert into yanshi values(1),(2),(3),(4);
?
? ? create database yanshi2;
? ? use yanshi2;
? ? create table yanshi2(id int);
? ? insert into yanshi2 values(1),(2),(3),(4);
3、模擬刪除數據
? ? 刪除一個庫,可以是之前的,也可以是剛創建的
? ? #因為剛我們看了,只要我執行了,從庫已經寫到了relay-log,跟我數據庫里的數據關系不大
? ? drop database world;
4、恢復
1.停止從庫sql線程
? ? stop slave sql_thread;
2.查看狀態
? ? show slave status;
3.備份從庫數據
? ? mysqldump -uroot -p123 -B world > /backup/congku.sql
4.截取一下relay-log
? ? 1)確認起點,查看relay-log.info即可
? ? ? ? [root@db02 data]# cat relay-log.info
? ? ? ? ./db02-relay-bin.000005
? ? ? ? 283
? ? 2)確認終點,找到drop語句之前
? ? ? ? [root@db02 data]# mysqlbinlog --base64-output=decode-rows -vvv db02-relay-bin.000005
?
? ? 3)截取數據
? ? ? ? [root@db02 data]# mysqlbinlog --start-position=283 --stop-position=1112 db02-relay-bin.000005 > /tmp/yanshi.sql
5.將從庫全備的數據與relaylog截取數據拷貝到主庫
? ? scp /tmp/yanshi.sql 172.16.1.51:/tmp/
? ? scp /backup/congku.sql 172.16.1.51:/tmp/
6.將數據導入主庫
? ? #導入前不要停掉binlog,
? ? mysql < /tmp/yanshi.sql
? ? mysql < /tmp/congku.sql
7.開啟從庫的sql線程
? ? start slave sql_thread;
?
#主庫那邊執行到刪除的時候沒關系,因為還有創建的部分,他會再次把數據創建回來
過濾復制
需求:數據庫同步時只同步指定的部分信息,不適用于做負載均衡
黑名單
不記錄黑名單列出的庫的二進制日志
?
#參數
replicate-ignore-db=test? ? ?#先庫后表,表依賴于庫
replicate-ignore-table=test.t1
replicate-wild-ignore-table=test.t% ?支持通配符,t開頭的表
?
注意:
replicate-ignore-table依賴參數replicate-ignore-db
即如果想忽略某個庫下的某張表,需要一起配置? ??
replicate-ignore-db=test
replicate-ignore-table=test.t1
白名單
只執行白名單中列出的庫或者表的中繼日志
?
#參數:
replicate-do-db=test
replicate-do-table=test.t1
replicate-wild-do-table=test.t%
?
注意:
replicate-do-table依賴參數replicate-do-db
即如果想只接收某個庫下的某張表,需要一起配置
replicate-do-db=test
replicate-do-table=test.t1
補充:
# 1、黑白名單對主庫的影響是:是否記錄binlog日志
在主庫上設置白名單:只記錄白名單設置的庫或者表、相關的SQL語句到binlog中
在主庫上設置黑名單:不記錄黑名單設置的庫或者表、相關的SQL語句到binlog中
?
# 2、黑白名單對從庫的影響是:sql線程是否執行io線程拿到的binlog
IO線程一定會拿到所有的binlog,但
?
如果在從庫上設置白名單:SQL線程只執行白名單設置的庫或者表相關的SQL語句
如果在從庫上設置黑名單:SQL線程不執行黑名單設置的庫或者表相關的SQL語句
配置測試
###先做好一主兩從
# 如果查看從庫show slave status\G報錯
A slave with the same server_uuid/server_id as this slave has connected to the master;
# 解決方案如下
如果server_id相同,請修改/etc/my.cnf中server_id的配置如果server_uuid相同,請刪除auto.cnf文件(auto.cnf文件在/etc/my.cnf中datadir配置的目錄下),然后重啟數據庫,數據庫會重新生成server_uuid和auto.cnf文件#從庫1
[root@db02 ~]# vim /etc/my.cnf
[mysqld]
replicate-do-db=big_egon[root@db02 ~]# systemctl restart mysql#查看主從狀態
show slave status;#從庫2
[root@db03 ~]# vim /etc/my.cnf
[mysqld]
replicate-wild-do-table=big_egon.t%
replicate-do-db=small_egon
replicate-do-table=small_egon.t1[root@db03 ~]# systemctl restart mysql#查看主從狀態
show slave status;#主庫創建表測試
create database big_egon;
create database small_egon;use big_egon;
create table t1(id int); -- 表名以t開頭
create table t2(id int); -- 表名以t開頭
create table x3(id int);use small_egon;
create table t1(id int);
create table t2(id int);
create table t3(id int);#從庫查看表
從庫1上只能看到big_egon庫下的所有表:t1、t2、x3從庫2上只能看到big_egon庫下t開頭的那兩張表,看不到表x3small_egon庫下的t1表主從復制架構
- ? ?主備架構,只有主庫提供讀寫服務,備庫僅留做備用? ? ?
1、高可用分析:高可用,主庫掛了,keepalive(只是一種工具)會自動切換到備庫。這個過程對業務層是透明的,無需修改代碼或配置
2、高性能分析:讀寫都操作主庫,很容易產生瓶頸。大部分聯網應用讀多寫少,讀會先成為瓶頸,進而影響寫性能。另外,備庫只是單純的備份,資源利用率50%,這點方案二可解決。
3、一致性分析:讀寫都操作主庫,不存在數據一致性問題。
4、擴展性分析:無法通過加從庫來擴展讀性能,進而提高整體性能。
5、可落地分析:兩點影響落地使用。第一,性能一般,這點可以通過建立高效的索引和引入緩存來增加讀性能,進而提高性能。這也是通用的方案。第二,擴展性差,這點可以通過分庫分表來擴展。
? - 雙主架構,兩個主庫同時提供服務,負載均衡? ? ? ?
1、高可用分析:高可用,一個主庫掛了,不影響另一臺主庫提供服務。這個過程對業務層是透明的,無需修改代碼或配置。
2、高性能分析:讀寫性能相比于方案一都得到提升,提升一倍。
3、一致性分析:存在數據一致性問題。請看,一致性解決方案
4、擴展性分析:當然可以擴展成三主循環,但不建議(會多一層數據同步,這樣同步的時間會更長)。如果非得在數據庫架構層面擴展的話,擴展為方案四。
5、可落地分析:兩點影響落地使用。第一,數據致性問題,一致性解決方案可解決問題。第二,主鍵沖突問題,ID統一地由分布式ID生成服務來生成可解決問題。
? - 主從架構,一主多從,讀寫分離? ?
1、高可用分析:主庫單點,從庫高可用。一旦主庫掛了,寫服務也就無法提供。
2、高性能分析:大部分互聯網應用讀多寫少,讀會先成為瓶頸,進而影響整體性能。讀的性能提高了,整體性能也提高了。另外,主庫可以不用索引,線上從庫和線下從庫也可以建立不同的索引(線上從庫如果有多個還是要建立相同的索引,不然得不償失;線下從庫是平時開發人員排查線上問題時查的庫,可以建更多的索引)
3、一致性分析:存在數據一致性問題。請看,一致性解決方案。
4、擴展性分析:可以通過加從庫來擴展讀性能,進而提高整體性能。(帶來的問題是,從庫越多需要從主庫拉取binlog日志的端就越多,進而影響主庫的性能,并且數據同步完成的時間也會更長)
5、可落地分析:兩點影響落地使用。第一,數據一致性問題,一致性解決方案可解決問題。第二,主庫單點問題。? ? ? ? ?
? - 級聯復制架構? ? ? ? ? ? ? ? ?
級聯復制----擴大從庫的規模,讓主庫的從庫充當下一級從庫的主庫,減小了主庫的壓力
但它的缺點就是Binlog日志要經過兩次復制才能到達從庫,增加了復制的延時。
我們可以通過在二級從庫上應用Blackhol存儲引擎(黑洞引擎)來解決這一問題,降低多級復制的延時。
黑洞引擎”就是寫入Blackhole表中數據并不會寫到磁盤上,所以這個Blackhole表永遠是個空表,對數據的插入/更新/刪除操作僅在Binlog中記錄,并復制到從庫中去。
? - 雙主+雙從架構
1、高可用分析:高可用。
2、高性能分析:高性能。
3、一致性分析:存在數據一致性問題。請看,一致性解決方案
4、擴展性分析:可以通過加從庫來擴展讀性能,進而提高整體性能。(帶來的問題同方案二)
5、可落地分析:同方案二,但數據同步又多了一層,數據延遲更嚴重。
一致性解決方案
只要進行數據同步,就會出現延時一致性的問題
硬件優化
1.采用好服務器,比如4u比2u性能明顯好,2u比1u性能明顯好。
?
2.存儲用ssd或者盤陣或者san,提升隨機寫的性能。
?
3.主從間保證處在同一個交換機下面,并且是萬兆環境。
?
總結,硬件強勁,延遲自然會變小。一句話,縮小延遲的解決方案就是花錢和花時間。
文件系統優化
master端修改linux、Unix文件系統中文件的etime屬性,由于每當讀文件時OS都會將讀取操作發生的時間回寫到磁盤上,對于讀操作頻繁的數據庫文件來說這是沒必要的,只會增加磁盤系統的負擔影響I/O性能。可以通過設置文件系統的mount屬性,組織操作系統寫atime信息
? ? 在linux上的操作為:
? ? ? ? 打開/etc/fstab
? ? ? ? 加上noatime參數/dev/sdb1 /data reiserfs noatime 1 2
? ? ? ? 然后重新mount文件系統 #mount -oremount /data
MySQL參數優化
1、logs-slave-updates 從服務器從主服務器接收到的更新不記入它的二進制日志。
?
2、sync_binlog在slave端設置為0或禁用slave端的binlog
?
3、slave端,如果使用的存儲引擎是innodb,innodb_flush_log_at_trx_commit =2
?
對數據安全性較高,需要設置
sync_binlog=1
innodb_flush_log_at_trx_commit = 1?
而對于slave則不需要這么高的數據安全,完全可以設置為
sync_binlog=0或者關閉binlog
innodb_flush_log_at_trx_commit =0或2
主從都開啟GTID復制模式,使用MHA
MHA
1、支持binlogserver? 專門負責同步主庫的binlog的服務器
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?----解決commit之后更新還沒推送給從庫主庫就掛掉了
- 重啟mysql重新同步
- 主庫如果是物理層面的損壞,使用binlogserver對從庫進行數據恢復? ? ? ? ? ? ? ? ? ? ? ? ?
2、一主多從更新推給多臺從服務器的先后一致性問題
? ? ? ? ? 基于GTID解決(不用也可以,查誰的binlog最新即可)
? ? ? ? ? 看誰身上的數據量大數據新就跟誰同步數據,(如果主庫故障了)綜合選舉出一個新的主庫,進行vip飄移
架構方面
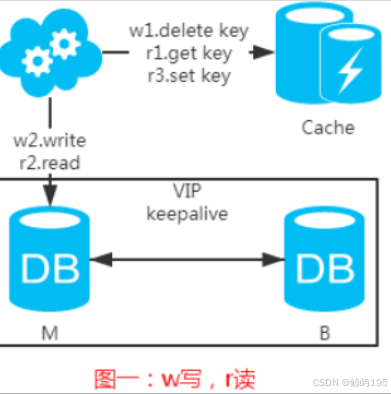
1、強制讀主----讀寫都走主庫,不存在一致性問題
為了緩解主庫的讀壓力,可以引入緩存。
但是有一點需要知道:如果緩存掛了,可能會產生雪崩現象,不過一般分布式緩存都是高可用的。
在本架構中,從庫的作用是,主庫一旦掛掉,vip則漂移到從庫上,從庫可以投入使用。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ?
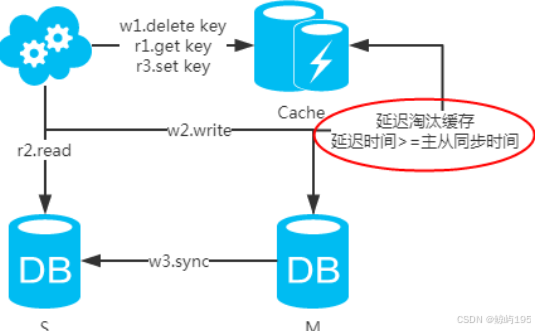
2、選擇讀主
緩存數據庫的數據過期超時時間的設置一定要大于數據庫主從一致的時間----保證請求去數據庫讀數據的時候在從庫上能讀到從而減輕主庫的壓力
? ? ? ? ? ? ? ??
3、選擇半同步復制
4、引入數據庫中間件
六、企業環境介紹
- 開發環境
開發開發完自己測試
? - 測試環境
1)性能測試
2)功能測試
? - 預發布環境(beta,內測不刪檔)
(1)、只是一臺服務器
?
(2)、沒有真實的流量
?
(3)、連的是線上數據庫
?
疑問:如果有一個待上線需求,需要改動數據庫表結構,怎么處理?
?
先把預發布環境使用的數據庫切換為測試環境使用的數據庫
然后有針對性的測試下數據庫的變更是否會影響線上當前代碼程序的運行,測試通過后再上線
? - 灰度環境
(1)、1臺或多臺線上主機
?
(2)、鏈接的是線上數據庫
?
(3)、真實流量
?
灰度發布,又稱金絲雀發布。
金絲雀發布這一術語源于煤礦工人把籠養的金絲雀帶入礦井的傳統。礦工通過金絲雀來了解礦井中一氧化碳的濃度,如果一氧化碳的濃度過高,金絲雀就會中毒,從而使礦工知道應該立刻撤離。
?
灰度發布發生在預發布環境之后,生產環境之前。
對應到軟件開中,則是指在發布新的產品特性時通過少量的用戶試點確認新特性沒有問題,確保無誤后推廣到更大的用戶使用群體。
?
生產環境一般會部署在多臺機器上,以防某臺機器出現故障,這樣其他機器可以繼續運行,不影響用戶使用。灰度發布會發布到其中的幾臺機器上,驗證新功能是否正常。如果失敗,只需回滾這幾臺機器即可。
? - 沙盒環境
沙盒環境又稱測試環境和開發環境,是提供給開發者開發和測試用的環境。
沙盒通常嚴格控制其中的程序所能訪問的資源,比如,沙盒可以提供用后即回收的磁盤及內存空間。在沙盒中,網絡訪問、對真實系統的訪問、對輸入設備的讀取通常被禁止或是嚴格限制。
?
也就是說所謂的沙盒測試就是在產品未上線前在內部環境或網絡下進行的測試,此時在正常的線上環境是無法看到或查詢到該產品或項目的,只有產品在測試環境下無問題上傳到生產環境之后,用戶才能看到該產品或功能
? - 生產環境
除了生產和預發布其他的環境都是虛擬機測試用的
?
測試環境有很多游戲,我就想一個從庫同步一種游戲,還有合服,建新服,其實就是一個庫或者一個表而已.
七、MHA高可用
支持binlogserver? 專門負責同步主庫的binlog的服務器
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ----解決commit之后更新還沒推送給從庫主庫就掛掉了
- 重啟mysql重新同步
- 主庫如果是物理層面的損壞,使用binlogserver對從庫進行數據恢復? ? ? ? ? ? ? ? ? ? ? ? ?
一主多從更新推給多臺從服務器的先后一致性問題
? ? ? ? ? 基于GTID解決(不用也可以,查誰的binlog最新即可)
? ? ? ? ? 看誰身上的數據量大數據新就跟誰同步數據,(如果主庫故障了)綜合選舉出一個新的主庫,進行vip飄移
MHA程序的組成
node數據節點
? ? ? ? ? 相當于監控客戶端,所有數據庫機器都需要部署node
manager管理節點
Manager相當于服務端,MHA Manager會定時探測集群中的master節點,當master出現故障時,它可以自動將最新數據的slave提升為新的master,然后將所有其他的slave重新指向新的master(如果原主庫恢復,只能當從庫)
- 通常單獨部署在一臺獨立機器上管理多個 master/slave 集群(組),每個master/slave 集群稱作一個 application,用來管理統籌整個集群
- Manager應該盡量避免部署在主庫上,否則主機一掛則全掛,不僅主庫完蛋了負責自動遷移的Manager也完蛋了,也沒人負責自動故障遷移了,導致架構不可用了。
- 可以考慮部署在某一個slave上,此時這臺主機掛掉了,只是掛了一個slave,以及Manager,如果此時你不是倒了霉,(主庫也掛了),那還不至于架構不可用。但有一點需要注意的是:如果Manager部署在slave上,那么該slave就無法被升級為主庫;
MHA自動故障切換的步驟
- 每隔3秒探測一次主庫是否存活
ping_interval 控制間隔時間;?
ping_type 控制探測方式,SELECT(執行SELECT 1)和CONNECT(創建連接/斷開連接)
? - 如果發現故障,進行如下操作
1、從其他node發起ssh連接,檢查主庫是否能夠SSH上去;?
2、從其他node發起mysql連接,檢查MASTER庫是否能夠登陸;
? - 如果所有node節點ssh連接、MySQL主庫連接均失敗,則開始故障轉移
1.找到數據最新的從庫(通過對比relay-log,show slave status即可)
2.將最新的從庫上的新數據同步到其他從庫
3.提升一個從庫為主庫(一般情況提升數據最新的,二般情況提升我們指定的從庫為主庫)
4.通過原來主庫的binlog補全新的主庫數據(丟失了使用binlogserver)
5.其他從庫以新的主庫為主做主從復制
MHA優點
1、自動的故障檢測與轉移,通常在10-30秒以內;
2、MHA還提供在線主庫切換的功能,能夠安全地切換當前運行的主庫到個新的主庫中(通過將從庫提升為主庫),大概0.5-2秒內即可完成。
3、很好地解決了主庫崩潰數據的一致性問題
4、不需要對當前的mysql環境做重大修改
5、不需要在現有的復制框架中添加額外的服務器,僅需要-個manager節點,而一個Manager能管理多套復制,所以能大大地節約服務器的數量;
6、性能優秀,可以工作在半同步和異步復制框架,支持gtid,當監控mysq狀態時,僅需要每隔N秒向master發送ping包(默認3秒),所以對性能無影響。你可以理解為MHA的性能和簡單的主從復制框架性能一樣。
7、只要replication支持的存儲引擎都支持MHA,不會局限于innodb
8、對于一般的keepalived高可用,當vip在一臺機器上的時候,另一臺機器是閑置的,而MHA中并無閑置主機。
GTID主從復制
定義
? ? ? ? MHA可以與半同步復制結合起來。如果只有一個slave已經收到了最新的二進制日志,MHA可以將最新的二進制日志應用于其他所有的slave服務器上,因此可以保證所有節點的數據一致性。
GTID------為每個事務定制一個全局唯一的ID號,并且該ID是趨勢遞增的,以此我們便可以方便地順序讀取、不丟事務,是取binlog的一種方式。其實GTID就是一種很好的分布式ID實踐方案,它滿足分布ID的兩個基本要求,
1)全局唯一性
2)趨勢遞增
?
由UUID+TID兩部分組成
? ? UUID是數據庫實例的標識符
? ? TID表示事務提交的數量,會隨著事務的提交遞增
- 當 MySQL 執行一個事務時,在事務提交階段生成 GTID。生成的 GTID 會被記錄到二進制日志(binlog)中,與事務的其他信息(如 SQL 語句、數據修改等)一起存儲。這保證了每個事務在其生命周期內都有一個唯一且固定的 GTID 與之關聯,無論該事務在主從復制環境中如何傳播。
- 從庫的 SQL 線程在應用relayog中繼日志中的事務時,首先檢查事務的 GTID。它會維護一個已應用 GTID 的集合(通常存儲在?
gtid_executed?表或文件中)。當讀取到一個新事務的 GTID 時,SQL 線程會在這個集合中查找。如果 GTID 已存在,說明該事務已經應用過,SQL 線程會跳過這個事務;如果 GTID 不存在,SQL 線程會應用該事務,并將其 GTID 添加到已應用 GTID 集合中
優缺點
優點
1、一個事務對應一個唯一ID,一個GTID在一個服務器上只會執行一次,強化了一致性
2、GTID是用來代替傳統復制的方法,GTID復制與普通復制模式的最大不同就是不需要指定二進制文件名和位置,直接自動查找
3、GTID會開啟多個SQL線程,每一個庫,開啟一個SQL線程
4、支持延時復制
缺點
1.不支持非事務引擎
2.不支持create table t1(...) select* from t2; 語句復制(主庫直接報錯)
? ? ? ? ? 原理:(會生成兩個sql,一個是DDL創建表SQL,一個是insert into插入數據的sql。
? ? ? ? ? ? ? ?由于DDL會導致自動提交,所以這個sql至少需要兩個GTID,但是GTID模式下,只能給這個sql生成一個GTID)
3.不允許一個SQL同時更新一個事務引擎表和非事務引擎表
4.在一個復制組中,必須要求統一開啟GTID或者是關閉GTID
5.開啟GTID需要重啟(5.7除外)
6.開啟GTID后,就不再使用原來的傳統復制方式
7.對于create temporary table 和 drop temporary table語句不支持
8.不支持sql_slave_skip_counter
9.mysqldump 備份起來很麻煩,需要額外加參數 -set-gtid=on
基于GTID的主從復制部署(一主多從)
- 主庫和從庫都要開啟binlog
- 主庫和從庫server-id必須不同
- 要有主從復制用戶
實現
###主:mysql5.6? 192.168.15.100
[mysqld]
。。。。。。。server-id=100
binlog_format=row
log-bin=mysql-bin
skip-name-resolve # 跳過域名解析(非必須)
gtid-mode=on # 啟用gtid類型,否則就是普通的復制架構
enforce-gtid-consistency=true #強制GTID的一致性
log-slave-updates=1 # slave更新是否記入日志(5.6必須的)
relay_log_purge = 0 # 關閉relay_log自動清除功能,保障故障時的數據一致###從1 mysql5.6 192.168.15.101 只有server-id與主不同
[mysqld]
。。。。。。。
server-id=101
binlog_format=row
log-bin=mysql-bin
skip-name-resolve # 跳過域名解析(非必須)
gtid-mode=on # 啟用gtid類型,否則就是普通的復制架構
enforce-gtid-consistency=true #強制GTID的一致性
log-slave-updates=1 # slave更新是否記入日志(5.6必須的)
relay_log_purge = 0 # 關閉relay_log自動清除功能,保障故障時的數據一致###從2 192.168.15.102
[mysqld]
。。。。。。。
server-id=102
binlog_format=row
log-bin=mysql-bin
skip-name-resolve # 跳過域名解析(非必須)
gtid-mode=on # 啟用gtid類型,否則就是普通的復制架構
enforce-gtid-consistency=true #強制GTID的一致性
log-slave-updates=1 # slave更新是否記入日志(5.6必須的)
relay_log_purge = 0 # 關閉relay_log自動清除功能,保障故障時的數據一致###在主庫創建復制賬戶
mysql> GRANT REPLICATION SLAVE ON *.* TO egon@'%' IDENTIFIED BY '123';
Query OK, 0 rows affected (0.00 sec)mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)###兩個從庫開啟復制
change master to master_host='192.168.15.100',master_user='egon',master_password='123',MASTER_AUTO_POSITION=1;###啟動從庫復制
start slave;
show slave status\G
show variables like '%gtid%';測試主從,結束###如需改為雙主架構
# 找一臺從庫,假設為192.168.15.101,在該主機上創建賬號
GRANT REPLICATION SLAVE ON *.* TO egon@'%' IDENTIFIED BY '123';
flush privileges;# 在主庫上執行下述操作,指向從庫192.168.15.101(把主庫當從庫)
change master to master_host='192.168.15.101',master_user='egon',master_password='123',MASTER_AUTO_POSITION=1;# 開啟主庫的slave(把主庫當從庫)
start slave;MHA的部署
1、配置環境
在一主兩從的基礎上,所有主從服務器開啟binlog、relaylog,關閉relay_log_purge,并設置從庫relaylog只讀read_only=1,增加一臺manager服務器管理(多個)MHA集群
- 所有服務器設置主從復制用戶(主庫創建從庫同步)
GRANT REPLICATION SLAVE ON *.* TO egon@'%' IDENTIFIED BY '123';
flush privileges;- 主庫設置一個管理用戶便于日后MHA的管理
# 在主庫上執行即可,從庫會同步過去同時創建
grant all on *.* to 'mhaadmin'@'%' identified by '666';
flush privileges;
?- #1、在從庫上進行操作
#設置只讀,不要添加配置文件,因為從庫以后可能變成主庫
mysql> set global read_only=1;
?
#2、在所有庫上都進行操作
#關閉MySQL自動清除relaylog的功能
mysql> set global relay_log_purge = 0;?
#編輯配置文件
[root@mysql-db02 ~]# vim /etc/my.cnf
[mysqld]
#禁用自動刪除relay log永久生效
relay_log_purge = 0
?- ssh免密登錄
#創建秘鑰對
#正常創建 ssh-keygen 需要交互 按回車,用以下方法跳過交互
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa >/dev/null 2>&1
#發送公鑰,包括自己
ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.15.200
ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.15.100
ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.15.101
ssh-copy-id -i /root/.ssh/id_dsa.pub root@192.168.15.102
#測試
ssh root@192.168.13.200?hostname
ssh root@192.168.13.100 hostname
ssh root@192.168.13.101?hostname
ssh root@192.168.13.102?hostname
#如果認證慢的話可以嘗試修改/etc/ssh/sshd.conf中的UseDNS=no
?- 安裝軟件包(所有機器)
# 安裝yum源
wget http://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
rpm -ivh epel-release-latest-7.noarch.rpm
?
# 安裝MHA依賴的perl包
yum install -y perl-DBD-MySQL perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager
#先在所有機器安裝node包
wget https://qiniu.wsfnk.com/mha4mysql-node-0.58-0.el7.centos.noarch.rpm --no-check-certificate
rpm -ivh mha4mysql-node-0.58-0.el7.centos.noarch.rpm
#再去manager主機安裝manager包(.200)
wget https://qiniu.wsfnk.com/mha4mysql-manager-0.58-0.el7.centos.noarch.rpm --no-check-certificate
rpm -ivh mha4mysql-manager-0.58-0.el7.centos.noarch.rpm
2、配置MHA Manager
#建立單個MHA集群管理目錄
mkdir -p /service/mha/
mkdir /service/mha/app1#修改配置
#vim /service/mha/app1.cnf
[server default]
#日志存放路徑
manager_log=/service/mha/manager.log
#定義工作目錄位置
manager_workdir=/service/mha/app1#設置ssh的登錄用戶名
ssh_user=root
#如果端口修改不是22的話,需要加參數,不建議改ssh端口
#否則后續如負責VIP漂移的perl腳本也都得改,很麻煩
ssh_port=22#管理用戶
#在配置文件中設置管理用戶的賬號可以讓其進行如下操作
#例如選擇新的主庫后將選的從庫的選項?gobal read_only=1只讀設置為0
#stop slave
#chage master
user=mhaadmin
password=666#復制用戶
repl_user=egon
repl_password=123#檢測主庫心跳的間隔時間
ping_interval=1[server1]
# 指定自己的binlog日志存放目錄
master_binlog_dir=/var/lib/mysql
hostname=192.168.15.100
port=3306[server2]
#暫時注釋掉,先不使用
#candidate_master=1
#check_repl_delay=0
master_binlog_dir=/var/lib/mysql
hostname=192.168.15.101
port=3306[server3]
master_binlog_dir=/var/lib/mysql
hostname=192.168.15.102
port=3306# 1、設置了以下兩個參數,則該從庫成為候選主庫,優先級最高
# 不管怎樣都切到優先級高的主機,一般在主機性能差異的時候用
candidate_master=1
# 不管優先級高的備選庫,數據延時多久都要往那切
check_repl_delay=0# 2、上述兩個參數詳解如下:
# 設置參數candidate_master=1后,則判斷該主機為為候選master,發生主從切換以后將會將此從庫提升為主庫,即使這個主庫不是集群中事件最新的slave。# 默認情況下如果一個slave落后master 100M的relay logs的話,MHA將不會選擇該slave作為一個新的master,因為對于這個slave的恢復需要花費很長時間,通過設置check_repl_delay=0,MHA觸發切換在選擇一個新的master的時候將會忽略復制延時,這個參數對于設置了candidate_master=1的主機非常有用,因為這個候選主在切換的過程中一定是新的master# 3、應該為什么節點設置這倆參數,從而把該節點的優先級調高
# (1)、多地多中心,設置本地節點為高權重
# (2)、在有半同步復制的環境中,設置半同步復制節點為高權重
# (3)、你覺著哪個機器適合做主節點,配置較高的 、性能較好的3、檢測MHA配置
#測試免密連接
1.使用mha命令檢測ssh免密登錄
masterha_check_ssh --conf=/service/mha/app1.cnf# ALL SSH ... successfilly 表示ok了2.使用mha命令檢測主從狀態
masterha_check_repl --conf=/service/mha/app1.cnf# ... Health is OK#如果出現問題,可能是反向解析問題,配置文件加上skip-name-resolve
#還有可能是主從狀態,mha用戶密碼的情況4、啟動與測試
nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
?
命令參數:
--remove_dead_master_conf ? ? ? 該參數代表當發生主從切換后,宕機庫的配置信息將會從配置文件中移除。
--manger_log ? ? ? ? ? ? ? ? ? ?日志存放位置
--ignore_last_failover ? ? ? ? ?在缺省情況下,如果MHA檢測到連續發生宕機,且兩次宕機間隔不足8小時的話,則不會進行Failover,之所以這樣限制是為了避免ping-pong效應。該參數代表忽略上次MHA觸發切換產生的文件,默認情況下,MHA發生切換后會在日志目錄,也就是上面設置的manager_workdir目錄中產生app1.failover.complete文件,下次再次切換的時候如果發現該目錄下存在該文件將不允許觸發切換,除非在第一次切換后收到刪除該文件,為了方便,這里設置為--ignore_last_failover。
?
#MHA的安全機制:(防止出現乒乓效應)
? ? 1.完成一次切換后,會生成一個鎖文件在工作目錄中
? ? 2.下次切換之前,會檢測鎖文件是否存在
? ? 3.如果鎖文件存在,8個小時之內不允許第二次切換
5、測試自動切換與恢復


)
)
)







)






