本文代碼和配置文件實現了一個基于 Streamlit 和 FastAPI 的前后端分離的應用程序,用于管理和展示 VLLM(Very Large Language Model)實例的信息。以下是代碼和配置文件的總結摘要:
概要
功能概述
-
前后端啟動方式:
- 使用 Streamlit 啟動前端界面,可通過默認端口或指定端口和 IP 啟動。
- 使用 Uvicorn 啟動 FastAPI 后端服務,用于提供模型數據的 API 接口。
-
前端功能(Streamlit):
- 支持可選的登錄認證功能,通過 YAML 配置文件控制是否啟用。
- 展示 VLLM 模型的概覽信息,包括模型名稱、路徑、IP 地址、端口、任務 ID、啟動時間等。
- 從后端 API 獲取模型數據,并動態展示模型的詳細信息。
- 提供刷新按鈕,用于重新從后端獲取數據并更新前端顯示。
-
后端功能(FastAPI):
- 提供
/models和/models/{model_name}兩個 API 接口。 /models接口返回所有 VLLM 模型的列表信息。/models/{model_name}接口根據模型名稱返回特定模型的詳細信息。- 使用
ps命令解析系統進程信息,提取 VLLM 模型的運行參數和啟動時間。
- 提供
-
配置文件:
counter.yaml:用于配置后端 API 的端口號和是否啟用前端登錄認證。.streamlit/secrets.toml:存儲前端登錄認證的用戶名和密碼。
-
模型信息展示:
- 模型信息通過
st.expander展開式組件展示,包含模型的基本信息和參數。 - 計算模型的運行時間(
uptime),并以友好的格式顯示。
- 模型信息通過
技術棧
- 前端:Streamlit,用于快速搭建交互式 Web 界面。
- 后端:FastAPI,用于構建高效的 API 服務。
- 數據解析:通過
ps命令獲取系統進程信息,并解析出 VLLM 模型的運行參數。 - 配置管理:使用 YAML 和 TOML 文件分別管理后端配置和前端認證信息。
使用場景
該應用適用于管理和監控運行在服務器上的 VLLM 模型實例,通過前端界面直觀地展示模型的運行狀態和參數配置,方便用戶進行管理和調試。
代碼展示
應用前后端啟動方式
#默認啟動
streamlit run app.py
#Local URL: http://localhost:8501#指定端口 ip
streamlit run app.py --server.address 0.0.0.0 --server.port 8501# unicorn啟動后端fastapi
uvicorn api:app --reload --port 8880
Streamlit 代碼(前端頁面)
import streamlit as stimport requestsfrom datetime import datetime# 設置頁面配置st.set_page_config(page_title="VLLM 概覽",page_icon="📊")# 登錄認證try:import yamlwith open('counter.yaml') as f:config = yaml.safe_load(f)need_auth = config.get('web.auth', False)except Exception as e:need_auth = Falseif need_auth:if 'authenticated' not in st.session_state:st.session_state['authenticated'] = Falseif not st.session_state['authenticated']:st.header("請登錄")username = st.text_input("用戶名")password = st.text_input("密碼", type="password")if st.button("登錄"):if username == st.secrets["auth"]["vstu"] and password == st.secrets["auth"]["vstp"]:st.session_state['authenticated'] = Truest.rerun()else:st.error("用戶名或密碼錯誤")st.stop()# 頁面標題st.header("📊 VLLM 模型概覽")# 模擬API獲取數據函數def fetch_vllm_models():# 從配置文件讀取端口號try:import yamlwith open('counter.yaml') as f:config = yaml.safe_load(f)port = config.get('vllm.api.port', 8880)except Exception as e:port = 8880# 調用本地API獲取數據response = requests.get(f"http://localhost:{port}/models")if response.status_code == 200:return response.json()return []# 獲取數據models = fetch_vllm_models()# 計算運行時間def calculate_uptime(start_time_str):start_time = datetime.fromisoformat(start_time_str)uptime = datetime.now() - start_timereturn str(uptime).split('.')[0]# 展示模型信息for model in models:uptime = calculate_uptime(model['start_time'])with st.expander(f"模型: {model['sname']} ({model['name']}) [?? {uptime}]"):col1, col2 = st.columns(2)with col1:st.write(f"**路徑**: {model['path']}")st.write(f"**地址**: {model['ip']}")st.write(f"**端口**: {model['port']}")st.write(f"**任務ID**: {model['pid']}")st.write(f"**啟動時間**: {model['start_time']}")with col2:st.write("**參數**:")for param, value in model['params'].items():st.write(f"- {param}: {value}")# 刷新按鈕if st.button("刷新數據"):st.rerun()
API 代碼
from fastapi import FastAPIfrom datetime import datetimefrom pydantic import BaseModelimport osapp = FastAPI()class ModelInfo(BaseModel):name: strsname: strpath: strip: strport: intstart_time: strparams: dict# 模擬數據models = [{"name": "model1","sname": "model1","path": "/path/to/model1","ip": "192.168.1.100","port": 8000,"start_time": "2023-01-01T10:00:00","params": {"temperature": 0.7, "max_tokens": 100}},{"name": "model2","sname": "model2","path": "/path/to/model2","ip": "192.168.1.101","port": 8001,"start_time": "2023-01-02T11:00:00","params": {"temperature": 0.8, "max_tokens": 200}}]def parse_ps_time(ps_time_str):"""將ps命令返回的時間字符串轉換為ISO格式"""return datetime.strptime(ps_time_str, "%a %b %d %H:%M:%S %Y").isoformat()def parse_vllm_ps_output():"""從ps命令輸出解析vllm模型信息"""try:# 使用os.popen直接執行ps命令process = os.popen('ps aux | grep "vllm serve" | grep -v grep')output = process.read()process.close()if not output:print("No vllm processes found")return []models = []for line in output.splitlines():if "vllm serve" not in line:continue# 提取PIDpid = int(line.split()[1])# 提取完整命令cmd_start = line.find("vllm serve")cmd = line[cmd_start:]# 提取模型路徑model_path = cmd.split("vllm serve ")[1].split()[0]# 提取參數params = {}ip = "localhost" # 默認IP地址port = 8000 # 默認端口sname = model_path.split('/')[-1]parts = cmd.split()for i, part in enumerate(parts):if part == "--host":ip = parts[i+1]elif part == "--port":port = int(parts[i+1])elif part == "--task":params["task"] = parts[i+1]elif part == "--tensor-parallel-size":params["tensor_parallel_size"] = int(parts[i+1])elif part == "--pipeline-parallel-size":params["pipeline_parallel_size"] = int(parts[i+1])elif part == "--trust-remote-code":params["trust_remote_code"] = Trueelif part == "--api-key":params["api_key"] = Trueelif part == "--served-model-name":sname = parts[i+1]# 獲取進程啟動時間time_process = os.popen(f'ps -p {pid} -o lstart=')start_time_str = time_process.read().strip()time_process.close()models.append({"name": model_path.split('/')[-1],"sname": sname,"path": model_path,"pid": pid,"ip": ip,"port": port,"start_time": parse_ps_time(start_time_str) if start_time_str else datetime.now().isoformat(),"params": params})return modelsexcept Exception as e:print(f"Error parsing ps output: {e}")return []@app.get("/models")async def get_models():return parse_vllm_ps_output()@app.get("/models/{model_name}")async def get_model(model_name: str):for model in models:if model["name"] == model_name:return modelreturn {"error": "Model not found"}
配置文件的內容示例
# counter.yaml
vllm.api.port: 8880
web.auth: false
密碼文件的內容示例
# .streamlit\secrets.toml
[auth]
vstu = "admin"
vstp = "your_password"
效果展示
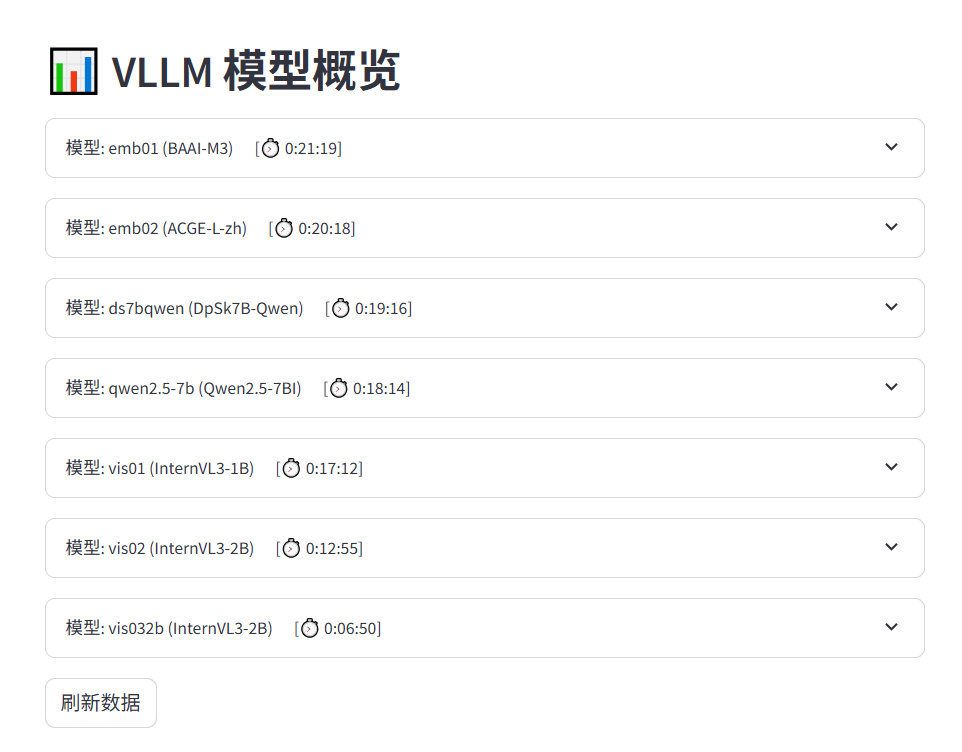
展示所有的運行中的模型信息,包括當前模型已運行的時間。
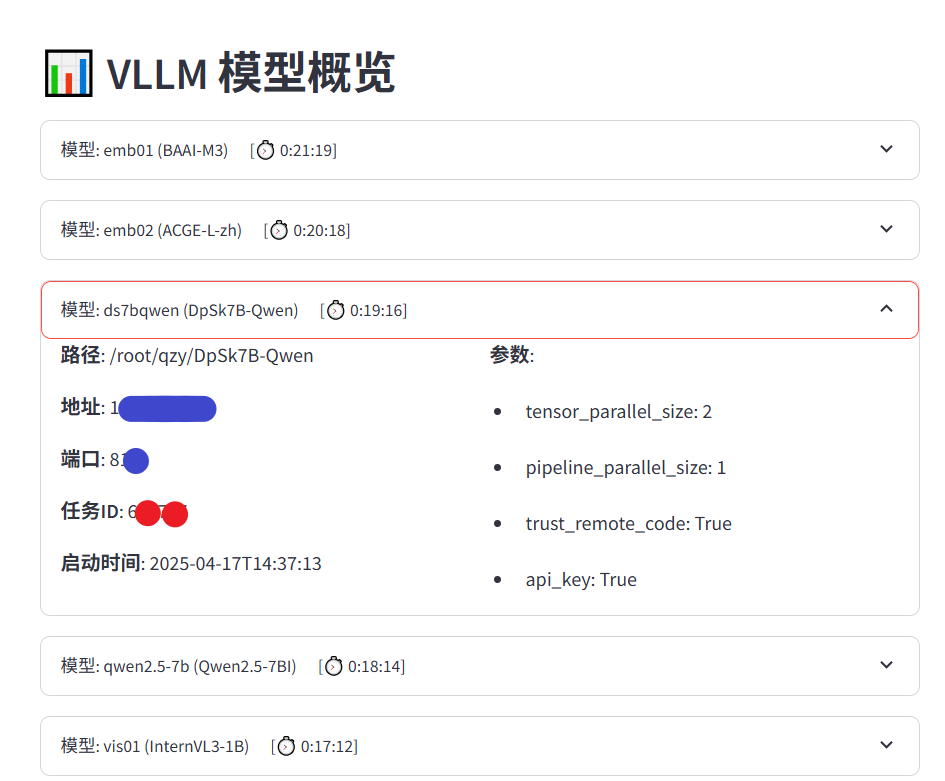
下拉菜單可以展示模型的詳細信息,如參數、地址、端口等信息。
總結
這段代碼實現了一個基于 Streamlit 和 FastAPI 的應用,用于管理和展示 VLLM 模型實例的信息。前端通過 Streamlit 提供交互式界面,支持登錄認證和模型信息的動態展示;后端使用 FastAPI 提供 API 接口,從系統進程解析模型數據。配置文件用于設置端口和認證信息。整體功能包括模型概覽、運行時間計算和數據刷新,適合用于監控和管理 VLLM 模型實例。


)








![[Java] 方法和數組](http://pic.xiahunao.cn/[Java] 方法和數組)


閃存讀寫保護法 加密與解密)



