目錄
一、196. 刪除重復的電子郵箱 - 力扣(LeetCode)
二、602. 好友申請 II :誰有最多的好友 - 力扣(LeetCode)
三、176. 第二高的薪水 - 力扣(LeetCode)
一、196. 刪除重復的電子郵箱 - 力扣(LeetCode)
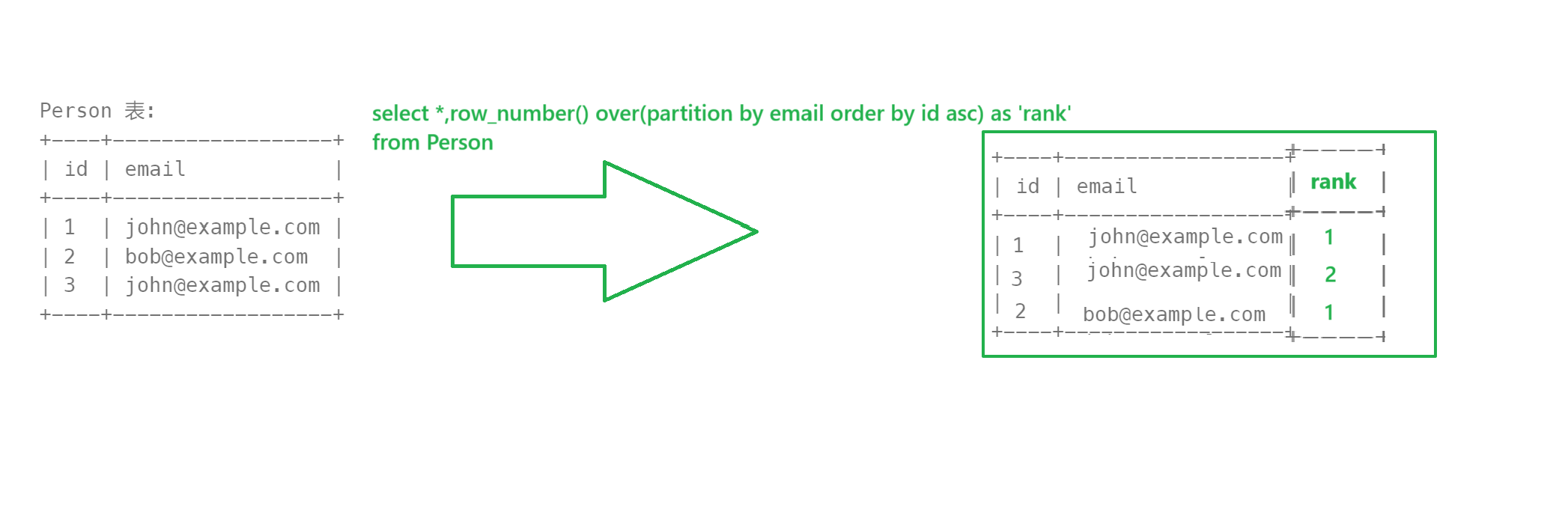
題意就是刪除刪除重復的郵箱
很容易可以想到 delete from person where id in (一坨)
繞了個彎子 讓你寫刪除語句本質還是寫查詢語句
- 第一層查詢使用窗口函數 分組加排序
select *, row_number() over(partition by email order by id asc) as 'rank' from Person
- 可以顯然得出 臨時表中rank >1 的都是重復的,嵌套一層查id出來
select id from (select *,row_number() over(partition by email order by id asc) as 'rank' from Person) temp where temp.rank = 1- 執行刪除語句
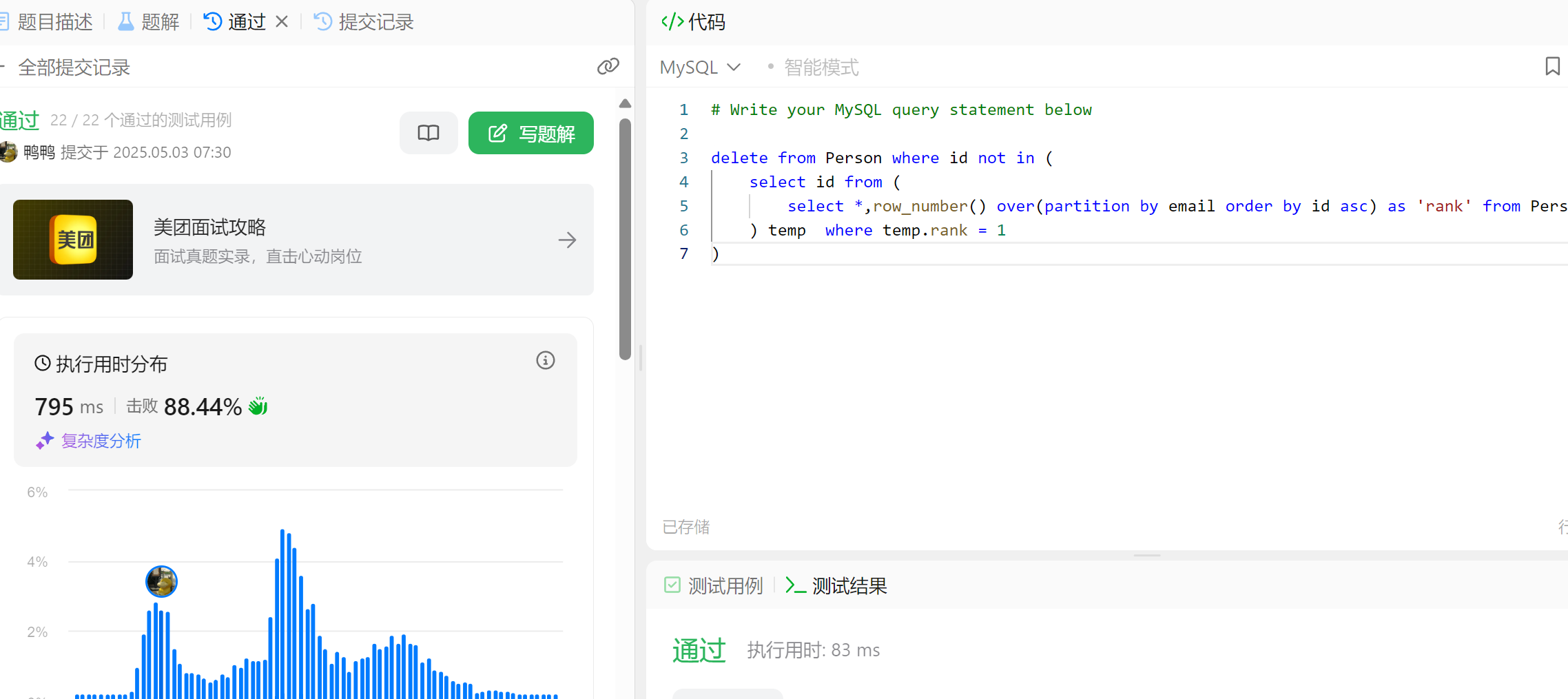
delete from Person where id not in (select id from (select *,row_number() over(partition by email order by id asc) as 'rank' from Person) temp where temp.rank = 1 )
二、602. 好友申請 II :誰有最多的好友 - 力扣(LeetCode)
?
with t1 as(select requester_id as 'id' from RequestAcceptedunion allselect accepter_id as 'id' from RequestAccepted
),
t2 as(select id,count(id) over(partition by id rows between unbounded preceding and unbounded following) as 'num'from t1
),
t3 as(select *,dense_rank() over(partition by null order by num desc) as 'rank'from t2
)
select id,num
from t3
where t3.rank = 1
limit 1理解就是加好友是相互的!!!!!!!!
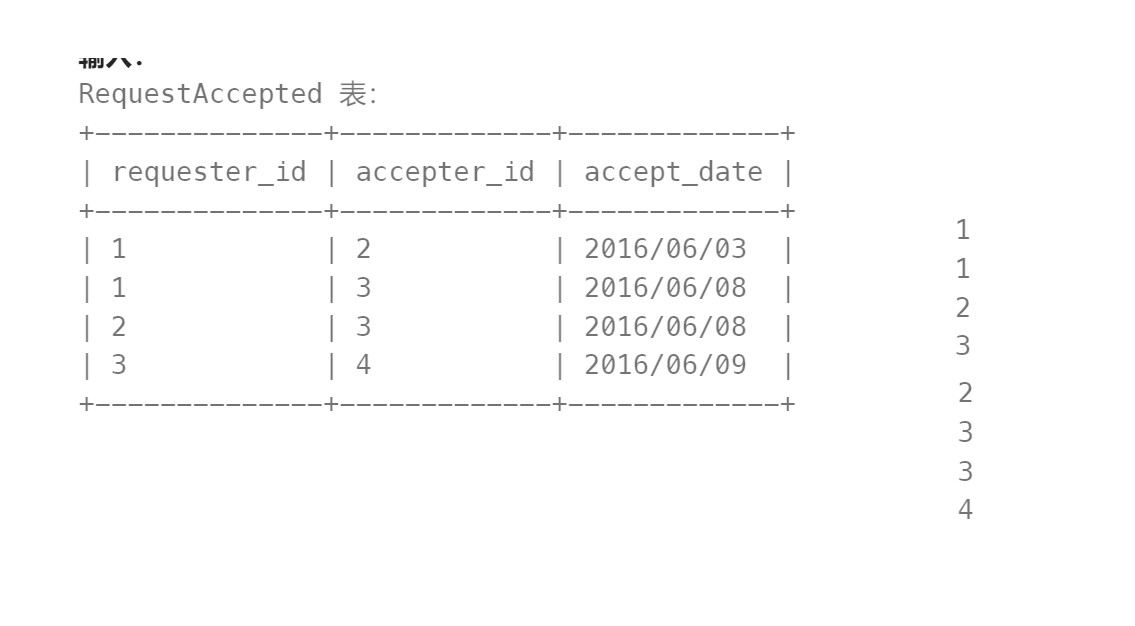
?把兩列數據并成一列? 然后窗口函數分組排序
三、176. 第二高的薪水 - 力扣(LeetCode)
也是窗口函數分組排序? 但是這個題就比較麻煩 需要考慮空結果集輸出null
select ifnull((with t1 as(select *,dense_rank() over(partition by null order by salary desc) as 'rank'from Employee),t2 as(select distinct salary as 'SecondHighestSalary' from t1where t1.rank = 2)select SecondHighestSalary from t2
),null) as 'SecondHighestSalary'
結束三道sql!



用websocket顯示大模型的流式輸出)






)
)



(support))

)

