Agents
在智能體開發套件(ADK)中,智能體(Agent)是一個獨立的執行單元,旨在自主行動以實現特定目標。智能體能夠執行任務、與用戶交互、使用外部工具,并與其他智能體協同工作。
在ADK中,所有智能體的基礎都是BaseAgent類,它充當著核心藍圖的作用。開發者通常通過以下三種主要方式擴展BaseAgent,以滿足不同需求——從智能推理到結構化流程控制,從而創建出功能完備的智能體。
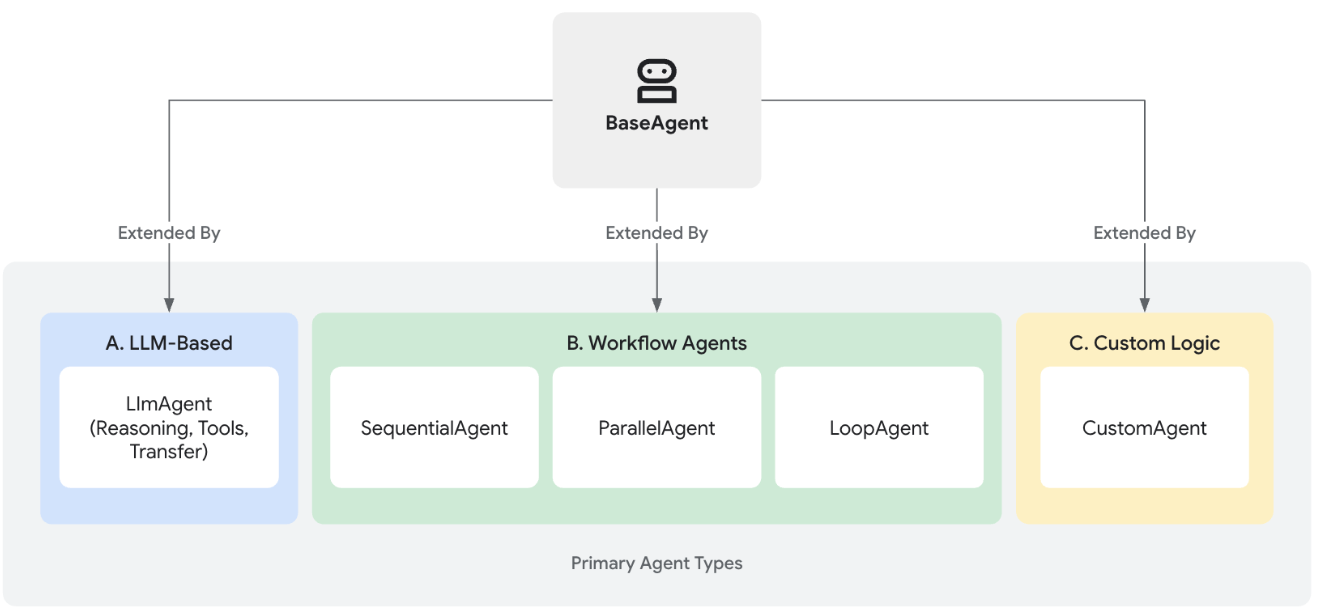
核心智能體類型
ADK 提供多種核心智能體類型,用于構建復雜應用場景:
大語言模型智能體(LlmAgent/Agent):以大型語言模型(LLM)為核心引擎,具備自然語言理解、邏輯推理、任務規劃、內容生成等能力,并能動態決策執行路徑與工具調用,特別適合需要靈活語言處理的任務。
工作流智能體(SequentialAgent/ParallelAgent/LoopAgent):通過預定義模式(順序/并行/循環)精確控制其他智能體的執行流程,其流程調度機制不依賴LLM,適用于需要確定性執行的結構化流程。
自定義智能體 (Custom Agents):通過直接擴展BaseAgent實現,可開發具有獨特業務邏輯、定制化控制流或特殊集成的智能體,滿足高度定制化需求。
選擇適合的智能體類型
下表提供了高層次對比,幫助區分不同智能體類型。隨著您在后續章節深入了解每種類型,這些差異將更加清晰。
| 功能對比 | LLM Agent (LlmAgent) | Workflow Agent | Custom Agent (BaseAgent subclass) |
|---|---|---|---|
| 核心功能 | 推理/生成/工具調用 | 控制智能體執行流程 | 實現獨特邏輯與集成 |
| 驅動引擎 | 大型語言模型(LLM) | 預定義邏輯(順序/并行/循環) | 自定義Python代碼 |
| 確定性 | 非確定性(靈活響應) | 確定性(可預測執行) | 可自定義(取決于實現) |
| 典型場景 | 語言任務/動態決策 | 結構化流程/任務編排 | 定制化需求/特定工作流 |
LlmAgent
LlmAgent(通常簡稱為Agent)是ADK中的核心組件,充當應用程序的"大腦"。它利用大型語言模型(LLM)的強大能力,實現推理、自然語言理解、決策制定、內容生成以及工具調用等功能。
與遵循預定義執行路徑的確定性工作流智能體不同,LlmAgent具有非確定性特征。它依托LLM解析指令和上下文,動態決策后續操作(包括工具調用選擇、是否移交控制權等),實現靈活的任務處理。
構建高效的LlmAgent需要明確定義其身份標識,通過指令精準引導行為,并配置必要的工具與能力集。
創建智能體
from google.adk.agents import LlmAgentagent = LlmAgent(name="",model="",description="",# instruction and tools will be added next
)參數說明:
name(必填): 每個智能體需具備唯一字符串標識符。該名稱在內部運維中至關重要,尤其涉及多智能體系統中的任務互調時。應選擇體現功能特征的描述性名稱(如customer_support_router、billing_inquiry_agent),避免使用user等保留名稱。
description(可選,多智能體場景推薦): 提供智能體能力的簡明概述。該描述主要用于其他LLM智能體判斷是否路由任務至本智能體。需具備足夠特異性以區分同類(例如"處理當前賬單查詢",而非籠統的"賬單智能體")。
model(必填): 指定驅動智能體推理的底層LLM模型。采用字符串標識符如"gemini-2.0-flash"。模型選擇直接影響智能體能力、成本及性能表現。可選模型及考量因素詳見模型列表。
instruction 參數說明
引導智能體行為:instruction參數是塑造LlmAgent行為最關鍵的核心配置。該參數接受字符串或字符串生成函數,用于向智能體明確以下行為準則:
-
其核心任務與目標:明確智能體需要完成的主要工作及成功標準。
-
角色設定與人格特征:例如:"你是一個樂于助人的助手"、"你扮演幽默的海盜角色",通過人格模板塑造交互風格。
-
行為約束規范:限定操作范圍(如"僅回答X相關問題"),設置禁忌條款(如"嚴禁透露Y信息")。
-
工具調用策略:說明每個工具的設計用途及調用條件,需補充工具自身的描述不足處,包含觸發閾值、參數規范等工程細節。
-
輸出格式要求:結構化輸出(如"以JSON格式響應"),呈現形式規范(如"使用項目符號列表"),包含數據類型、字段說明等約束。
設計要訣:
-
清晰明確性原則:規避歧義,精確聲明預期行為與輸出標準。
-
采用Markdown結構化:運用標題/列表等元素提升復雜指令可讀性
-
少樣本示例集成:針對復雜任務或特定輸出格式,應在指令中直接內嵌范例
-
工具調用引導規范:超越工具枚舉,明確調用時機與決策邏輯
可在字符串模板中使用動態變量
-
指令作為字符串模板,支持通過{var}語法插入動態變量值。
-
{var} 用于插入名為 var 的狀態變量值
-
{artifact.var} 用于插入名為 var 的工件文本內容
-
若狀態變量或工件不存在,智能體將拋出錯誤。如需忽略錯誤,可在變量名后添加 ?,如 {var?}。
# Example: Adding instructions
capital_agent = LlmAgent(model="gemini-2.0-flash",name="capital_agent",description="解答用戶關于各國首都的查詢",instruction="""您正在使用【首都查詢智能體】當用戶查詢某國首都時,請按以下標準流程響應:1. 從用戶查詢中識別國家名稱2. 調用 get_capital_city 工具獲取首都數據3. 向用戶清晰反饋首都信息示例查詢:"法國的首都是哪里?"示例回復:“法國的首都是巴黎。”""",# tools will be added next
)(注:對于適用于系統中所有智能體的指令,可考慮在根智能體上配置 global_instruction 參數,具體用法詳見《多智能體系統》章節。)
配置智能體工具Tools
工具集賦予LlmAgent超越LLM內置知識與推理的能力,使其能夠:
-
與外部系統交互
-
執行精準計算
-
獲取實時數據流
-
觸發特定操作
tools(可選):配置智能體可使用的工具列表。列表中的每個工具可以是以下任意一種形式:
-
Python函數(將自動封裝為FunctionTool)
-
繼承自 BaseTool 的類實例
-
其他智能體的實例(通過AgentTool實現智能體間任務委托 - 詳見《多智能體系統》)
大語言模型(LLM)會根據函數/工具的名稱、描述(來自文檔字符串或描述字段)以及參數模式,結合當前對話內容和自身指令,來決定調用哪個工具。
# Define a tool function
def get_capital_city(country: str) -> str:"""Retrieves the capital city for a given country."""# Replace with actual logic (e.g., API call, database lookup)capitals = {"france": "Paris", "japan": "Tokyo", "canada": "Ottawa"}return capitals.get(country.lower(), f"Sorry, I don't know the capital of {country}.")# Add the tool to the agent
capital_agent = LlmAgent(model="gemini-2.0-flash",name="capital_agent",description="Answers user questions about the capital city of a given country.",instruction="""You are an agent that provides the capital city of a country... (previous instruction text)""",tools=[get_capital_city] # Provide the function directly
)高級配置與控制
精細化調控 LLM 生成(generate_content_config)
您可以通過 generate_content_config 參數深度調整底層大語言模型(LLM)的響應生成方式,具體支持以下維度的精細化控制:
temperature(隨機性控制):
-
取值范圍 0.0 ~ 2.0,默認值通常為 0.9
-
低值(如 0.2):輸出更確定、保守,適用于事實性回答
-
高值(如 1.0):增強創造性,適合創意生成或開放式對話
max_output_tokens(響應長度限制):
-
設定生成內容的最大 token 數量(如 300),避免冗長響應
top_p & top_k(候選詞篩選):
-
top_p(0.0 ~ 1.0):動態截斷概率分布(如 0.8 保留前 80% 可能詞)
-
top_k(整數):限制每步采樣候選詞數量(如 40 僅考慮前 40 個最佳詞)
safety_settings(內容安全過濾):
-
配置敏感內容攔截等級(如 BLOCK_LOW/BLOCK_MEDIUM/BLOCK_HIGH)
-
支持按類別過濾(如 HARM_CATEGORY_HATE_SPEECH 仇恨言論檢測)
from google.genai import typesagent = LlmAgent(# ... other paramsgenerate_content_config=types.GenerateContentConfig(temperature=0.2, # More deterministic outputmax_output_tokens=250)
)結構化數據控制
(input_schema / output_schema / output_key)
在需要結構化數據交互的場景中,您可以通過 Pydantic 模型 實現嚴格的輸入/輸出控制,確保數據格式的規范性和類型安全。
input_schema(可選參數)
通過定義 Pydantic 的 BaseModel 類,嚴格規范輸入數據的結構。啟用后,所有傳入該 Agent 的用戶消息內容必須是符合此模型的 JSON 字符串,系統會自動執行校驗與轉換。
output_schema(可選)
定義一個表示預期輸出結構的 Pydantic BaseModel 類。如果設置此項,智能體的最終響應必須是符合此模式的 JSON 字符串。使用 output_schema 會啟用大語言模型(LLM)的受控生成功能,但同時會禁用智能體調用工具或將控制權轉移給其他智能體的能力。您需要通過指令明確引導 LLM 直接生成符合該模式的 JSON。
output_key(可選參數)
當設置此參數時,Agent 的最終文本響應會自動保存到會話狀態字典中(session.state[output_key]),實現跨 Agent 或工作流步驟的數據傳遞。
from pydantic import BaseModel, Fieldclass CapitalOutput(BaseModel):capital: str = Field(description="The capital of the country.")structured_capital_agent = LlmAgent(# ... name, model, descriptioninstruction="""若輸入國家為"中國",則嚴格按 {"capital": "北京"} JSON格式返回,不包含任何額外文本或解 釋。""",output_schema=CapitalOutput, # Enforce JSON outputoutput_key="found_capital" # Store result in state['found_capital']# Cannot use tools=[get_capital_city] effectively here
)上下文管理(include_contents)
控制智能體是否接收歷史對話記錄
include_contents(可選,默認值:'default'):控制是否將對話歷史內容傳遞給大語言模型(LLM)。
-
'default'(默認模式): 智能體會接收到相關的對話歷史,使其能夠基于上下文進行連貫的多輪交互(例如,理解指代或延續之前的任務)。
-
'none'(無歷史模式): 智能體不會接收任何先前的對話內容,僅根據當前指令和本輪輸入生成響應(適用于無狀態任務或強制限定上下文場景)。
stateless_agent = LlmAgent(# ... other paramsinclude_contents='none'
)案例:完整代碼
# 獲取國家首都的示例代碼
# --- 以下是演示 LlmAgent 使用工具(Tools)與輸出模式(Output Schema)對比 的完整示例代碼及說明 ---
import asyncio
import json # Needed for pretty printing dictsfrom google.adk.agents import LlmAgent
from google.adk.models.lite_llm import LiteLlm
from google.adk.runners import Runner
from google.adk.sessions import InMemorySessionService
from google.genai import types
from pydantic import BaseModel, Field# --- 1. 定義常量 ---
APP_NAME = "agent_comparison_app"
USER_ID = "test_user_456"
SESSION_ID_TOOL_AGENT = "session_tool_agent_xyz"
SESSION_ID_SCHEMA_AGENT = "session_schema_agent_xyz"
MODEL_NAME = "gemini-2.0-flash"# --- 2. 使用LiteLLM調用在線模型 ---
model_client = LiteLlm(model="deepseek/deepseek-chat",api_base="https://api.deepseek.com",api_key="sk-xxxxxx",
)# --- 3. 定義數據模型 ---
# Input schema used by both agents
class CountryInput(BaseModel):country: str = Field(description="要獲取相關信息的國家。")# Output schema ONLY for the second agent
class CapitalInfoOutput(BaseModel):capital: str = Field(description="該國家的首都城市。")# Note: 人口數據為示意值;由于設定了輸出格式(output_schema),# 大語言模型(LLM)將自行推斷或估算該數值(此時無法調用外部工具獲取真實數據)。population_estimate: str = Field(description="該首都城市的估計人口數量。")# --- 4. 定義工具 ---
def get_capital_city(country: str) -> str:"""獲取指定國家的首都城市名稱。"""print(f"\n-- Tool Call: get_capital_city(country='{country}') --")country_capitals = {"美國": "華盛頓哥倫比亞特區","加拿大": "渥太華","法國": "巴黎","日本": "東京",}result = country_capitals.get(country.lower(), f"Sorry, I couldn't find the capital for {country}.")print(f"-- Tool Result: '{result}' --")return result# --- 5. 配置 Agents ---# Agent 1: Uses a tool and output_key
capital_agent_with_tool = LlmAgent(model=model_client,name="capital_agent_tool",description="調用指定工具獲取國家首都城市信息",instruction="""您是一個智能助手,專門通過工具查詢國家首都信息。工作流程:1、接收用戶輸入的JSON格式數據:{"country": "國家名稱"}2、自動提取country字段值3、調用get_capital_city工具查詢首都4、以清晰語句向用戶返回查詢結果示例:用戶輸入:{"country": "法國"} 助手響應:根據查詢結果,法國的首都是巴黎。""",tools=[get_capital_city],input_schema=CountryInput,output_key="capital_tool_result", # Store final text response
)# Agent 2: Uses output_schema (NO tools possible)
structured_info_agent_schema = LlmAgent(model=model_client,name="structured_info_agent_schema",description="提供以特定JSON格式標注的首都及預估人口數據。",instruction=f"""你是一個提供國家信息的智能體用戶將以JSON格式提供國家名稱,如{{“country”:“country_name”}}。僅使用與此確切模式匹配的JSON對象進行響應:EXAMPLE JSON OUTPUT:{{"capital": "日本","population_estimate": "1萬"}}用你已有知識判斷其首都并估算人口。不要使用任何工具。""",# *** NO tools parameter here - using output_schema prevents tool use ***input_schema=CountryInput,output_schema=CapitalInfoOutput, # Enforce JSON output structureoutput_key="structured_info_result", # Store final JSON response
)# --- 6. 設置會話管理器Session與運行器 ---
session_service = InMemorySessionService()# 為清晰起見創建獨立會話(若上下文管理得當則非必需)
session_service.create_session(app_name=APP_NAME, user_id=USER_ID, session_id=SESSION_ID_TOOL_AGENT)
session_service.create_session(app_name=APP_NAME, user_id=USER_ID, session_id=SESSION_ID_SCHEMA_AGENT)# 為每個智能體創建獨立的運行器
capital_runner = Runner(agent=capital_agent_with_tool,app_name=APP_NAME,session_service=session_service
)
structured_runner = Runner(agent=structured_info_agent_schema,app_name=APP_NAME,session_service=session_service
)# --- 7. 定義智能體交互邏輯 ---
async def call_agent_and_print(runner_instance: Runner,agent_instance: LlmAgent,session_id: str,query_json: str
):"""向指定的 Agent/Runner 發送查詢并打印結果。"""print(f"\n>>> Calling Agent: '{agent_instance.name}' | Query: {query_json}")user_content = types.Content(role='user', parts=[types.Part(text=query_json)])final_response_content = "No final response received."async for event in runner_instance.run_async(user_id=USER_ID, session_id=session_id, new_message=user_content):# print(f"Event: {event.type}, Author: {event.author}") # Uncomment for detailed loggingif event.is_final_response() and event.content and event.content.parts:# For output_schema, the content is the JSON string itselffinal_response_content = event.content.parts[0].textprint(f"<<< Agent '{agent_instance.name}' Response: {final_response_content}")current_session = session_service.get_session(app_name=APP_NAME,user_id=USER_ID,session_id=session_id)stored_output = current_session.state.get(agent_instance.output_key)# 如果存儲的輸出類似 JSON(可能來自 output_schema),則進行格式化美化打印。print(f"--- Session State ['{agent_instance.output_key}']: ", end="")try:# 若內容為 JSON 格式,則嘗試解析并美化輸出parsed_output = json.loads(stored_output)print(json.dumps(parsed_output, indent=2))except (json.JSONDecodeError, TypeError):# Otherwise, print as stringprint(stored_output)print("-" * 30)# --- 7. Run Interactions ---
async def main():print("--- Testing Agent with Tool ---")await call_agent_and_print(capital_runner, capital_agent_with_tool, SESSION_ID_TOOL_AGENT, '{"country": "日本"}')#await call_agent_and_print(capital_runner, capital_agent_with_tool, SESSION_ID_TOOL_AGENT, '{"country": "加拿大"}')print("\n\n--- Testing Agent with Output Schema (No Tool Use) ---")await call_agent_and_print(structured_runner, structured_info_agent_schema, SESSION_ID_SCHEMA_AGENT, '{"country": "日本"}')#await call_agent_and_print(structured_runner, structured_info_agent_schema, SESSION_ID_SCHEMA_AGENT, '{"country": "日本"}')if __name__ == "__main__":asyncio.run(main())運行結果:
--- Testing Agent with Tool --->>> Calling Agent: 'capital_agent_tool' | Query: {"country": "日本"}-- Tool Call: get_capital_city(country='日本') --
-- Tool Result: '東京' --
<<< Agent 'capital_agent_tool' Response: 根據查詢結果,日本的首都是東京。
--- Session State ['capital_tool_result']: 根據查詢結果,日本的首都是東京。
--------------------------------- Testing Agent with Output Schema (No Tool Use) --->>> Calling Agent: 'structured_info_agent_schema' | Query: {"country": "日本"}
<<< Agent 'structured_info_agent_schema' Response: {"capital": "東京","population_estimate": "1.26億"
}
--- Session State ['structured_info_result']: {'capital': '東京', 'population_estimate': '1.26億'}
------------------------------Process finished with exit code 0


(support))

)


 堆指令部件模塊實驗)
——閱讀版——仔細閱讀題)

-上下文壓縮與過濾)




4*3蝴蝶拼圖(圓形、三角、正方、半圓的凹凸小塊+參考圖灰色))


