磁盤文件系統
- 一、磁盤結構
- 1.1 認識一下基礎的硬件設備以及真實的機房環境
- 1.2 磁盤物理結構與存儲結構
- 1、磁盤物理結構
- 2、磁盤的存儲結構
- 3、CHS地址定位
- 4、磁盤的邏輯結構(LBA)
- 5 磁盤真實過程
- 5 CHS && LBA地址
- 二、理解分區、格式化
- 1 引?"塊"概念
- 2 引?"分區"概念
- 三、學習Ext*系列文件系統(inode號與inode)
- 四、理解系統中的文件、目錄
- inode與block如何映射?
- 相關問題
- 憑什么拿到inode?我們在系統層面訪問的好像都是文件名啊???
- 再次理解文件名
- 你怎么確定自己在哪一個分區?
- 五、深刻理解軟硬鏈接
- 5.1 軟鏈接
- 5.2 硬鏈接
- 5.3 理解軟硬鏈接
- 5.4 軟硬鏈接的使用場景
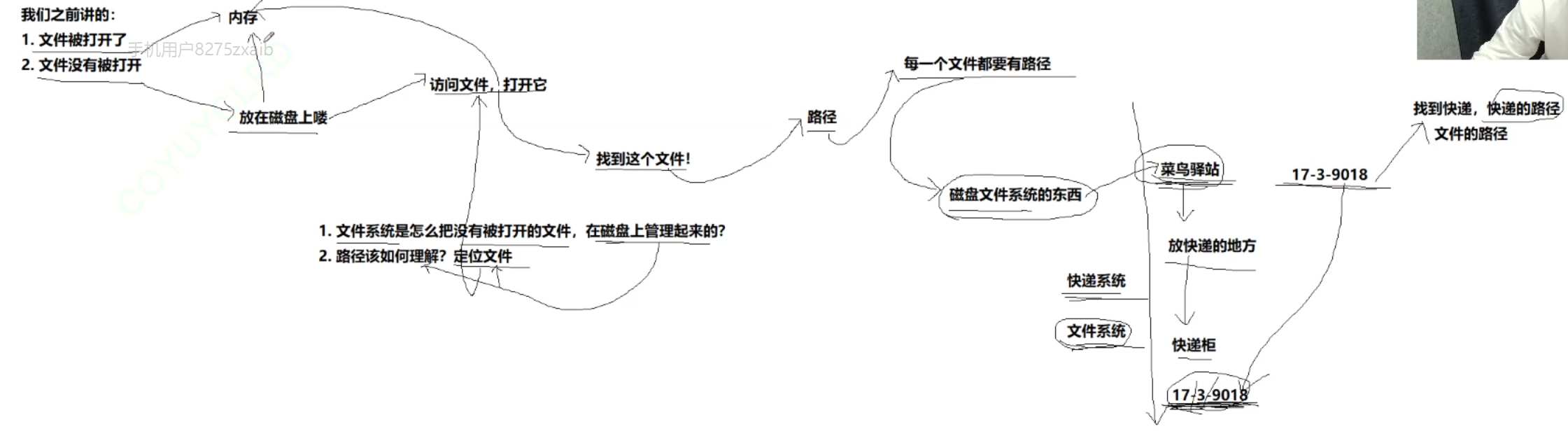
1、文件可以分為打開的文件和沒有被打開的文件,之前我們談的進程中的文件就是打開的文件,這一節的內容我們要講的就是沒有被打開的文件
2、首先我們需要明白對于所有的文件,其實沒有被打開的文件占大多數,所以對沒有被打開的文件的管理是非常重要的,其次我們需要知道打開的文件是被加載到內存的,那沒有被打開的文件在哪里?—很顯然就是磁盤
3、磁盤上的文件被打開的前提是什么?當然是需要找到這個文件的位置,也就是路徑,當然每一個文件都有自己的路徑,操作系統對每一個文件的路徑,屬性等的管理就叫做磁盤級文件系統,嚴格意義上文件系統分內存級、磁盤級兩種。
4、文件系統類似于我們生活中的菜鳥驛站,每一個快遞都有自己的貨柜號(例如,12-3-1012),驛站通過一系列方式管理我們的快遞,驛站我們可以簡單理解為快遞系統,管理文件的系統我們稱為文件系統,它們的管理方式類似,(12-3-1012)就類似于快遞路徑,文件的路徑也是類似的路徑,快遞系統的工作就是增加快遞,取走快遞,遺失快遞等進行管理,文件系統也是如此。
5、這一節的目的就是
(1)文件系統是怎樣管理未打開文件的?
(2)路徑怎么理解—(定位文件)
一、磁盤結構
1.1 認識一下基礎的硬件設備以及真實的機房環境
(1)磁盤(機械磁盤------便宜、但是容量大)-----唯一的機械設備

上圖打開圓盤后如下圖

我們所有的數據都被保存在圖二中的盤片上的,盤片上有一個探頭,叫做磁頭
(2)服務器

沒有鍵盤沒有顯示器,服務器上的許多空格就是存放磁盤的地方,如圖中的服務器就有24個盤
(3)服務器機柜(里面存放服務器)

(4)機房(存放許多服務器機柜)

(5)我們一直暢談二進制,那磁盤上的二進制我們該如何理解?
我們生活中磁鐵是很常見的吧,磁鐵分為N,S極,磁盤我們可以理解為上面有無數個小磁鐵,我們可以規定(N為1,S為0),向磁盤中寫入數據,其實就是更改某個小磁鐵的N/S極,當我們需要銷毀磁盤時,我們不能直接銷毀,比如我們將所有文件全部刪除,但是后面我們會學習到磁盤中的文件是可以恢復的,特別容易造成信息泄露,最好的方式是火燒消磁。
1.2 磁盤物理結構與存儲結構
1、磁盤物理結構

2、磁盤的存儲結構
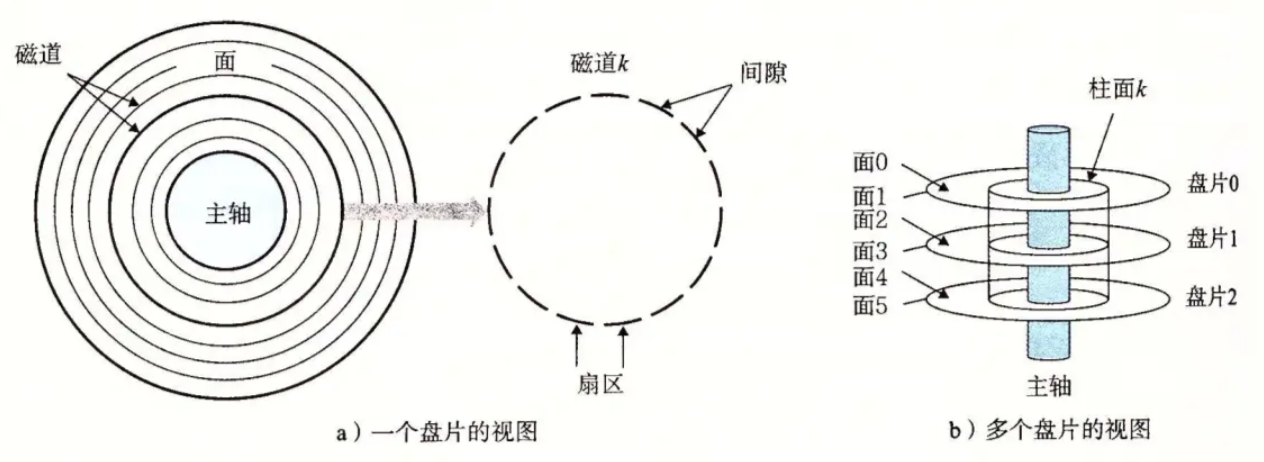

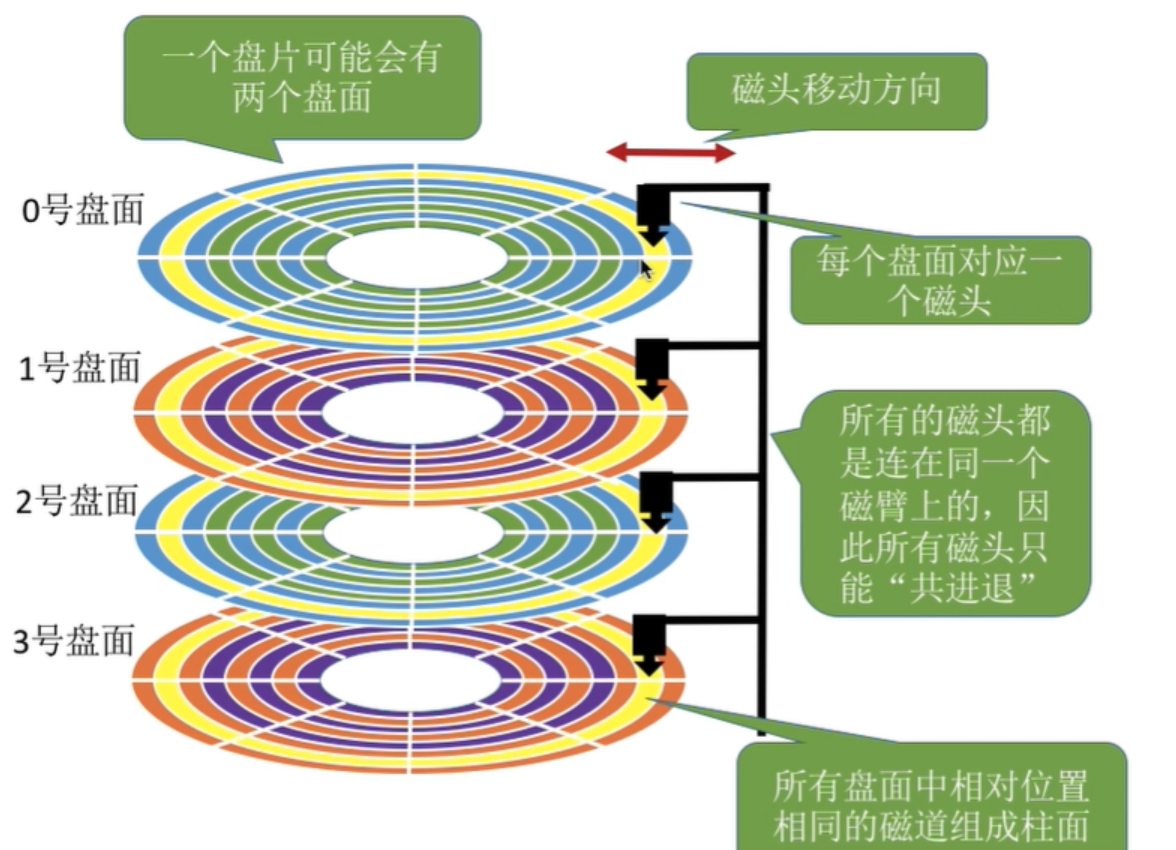
磁片每一面都有磁頭
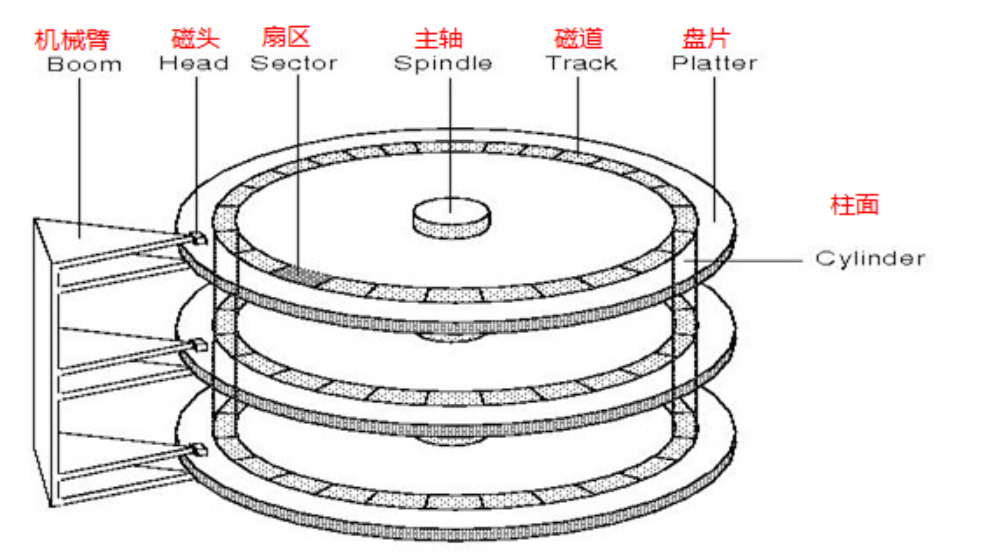
3、CHS地址定位
扇區:是磁盤存儲數據的基本單位,512字節,塊設備
磁頭擺動的本質:定位磁道或者(柱面)
磁盤盤片旋轉的本質:定位扇區
所以通過磁盤盤片的旋轉再加上磁頭左右的擺動,就可以在任意磁盤面、任意扇區上讀寫存取數據
如何定位?個扇區呢?
? 可以先定位磁頭(header)
? 確定磁頭要訪問哪?個柱?(磁道)(cylinder)
? 定位?個扇區(sector)
上面這種定位扇區的方法我們可以叫做CHS地址定位法
? CHS地址定位
?件 = 內容+屬性 都是數據,??就是占據那?個扇區的問題!能定位?個扇區了,能不能定位多個扇
區呢?當然是可以的
知識點:
? 扇區是從磁盤讀出和寫?信息的最?單位,通常??為 512 字節。
? 磁頭(head)數:每個盤??般有上下兩?,分別對應1個磁頭,共2個磁頭
? 磁道(track)數:磁道是從盤?外圈往內圈編號0磁道,1磁道…,靠近主軸的同?圓?于停靠磁
頭,不存儲數據
? 柱?(cylinder)數:磁道構成柱?,數量上等同于磁道個數
? 扇區(sector)數:每個磁道都被切分成很多扇形區域,每道的扇區數量相同
? 圓盤(platter)數:就是盤?的數量
? 磁盤容量=磁頭數 × 磁道(柱?)數 × 每道扇區數 × 每扇區字節數
? 細節:傳動臂上的磁頭是共進退的(這點?較重要,后?會說明)
4、磁盤的邏輯結構(LBA)
CHS地址定位是磁盤真實的地址操作方法,但設計師設計了一種更簡便的方法,下面我們來學習。

這個東西大家應該見過,里面黑色的帶子叫做磁帶,磁帶上?可以存儲數據,我們可以把磁帶“拉直”,形成線性結構

那么磁盤本質上雖然是硬質的,但是邏輯上我們可以把磁盤想象成為卷在?起的磁帶,那么磁盤的邏
輯存儲結構我們也可以類似于:

這樣每?個扇區,就有了?個線性地址(其實就是數組下標),這種地址叫做LBA
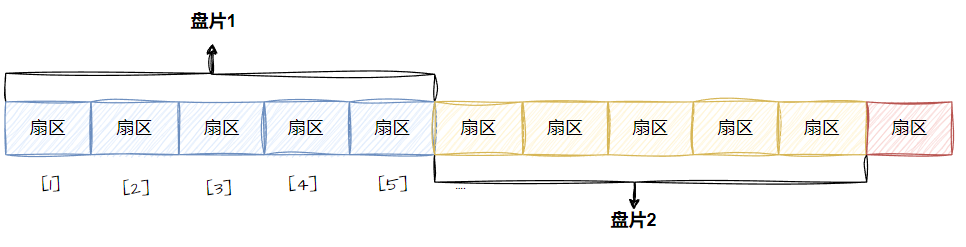
通過這種方式我們可以將磁盤抽象為一個特別大的線性數組,但是真正訪問磁盤還是CHS方式,所以我們需要將LBA<—>CHS
轉化
5 磁盤真實過程
上面我們說了傳動臂上的磁頭是共進退的,但沒有解釋原因,下面就給大家簡單回答一下:
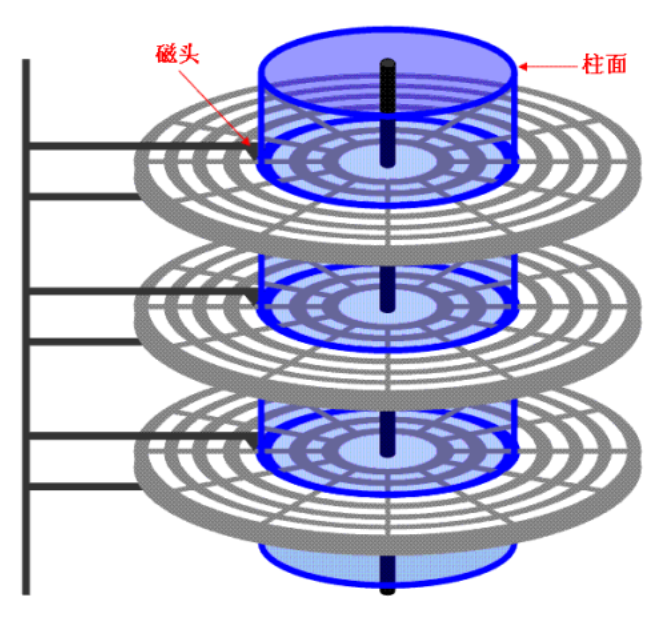
根據上面的理解我們或許會認為磁盤是一片一片的,但那只能是初步理解,真實的磁片其實是一圈一圈的,每一圈被稱為一個柱面
磁道:
某?盤?的某?個磁道展開:

即:?維數組
柱?:
整個磁盤所有盤?的同?個磁道,即柱?展開:
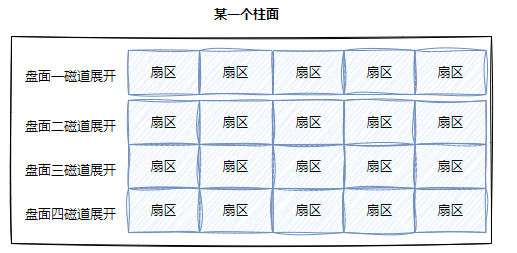
? 柱?上的每個磁道,扇區個數是?樣的
? 這不就是?維數組嗎
整盤:
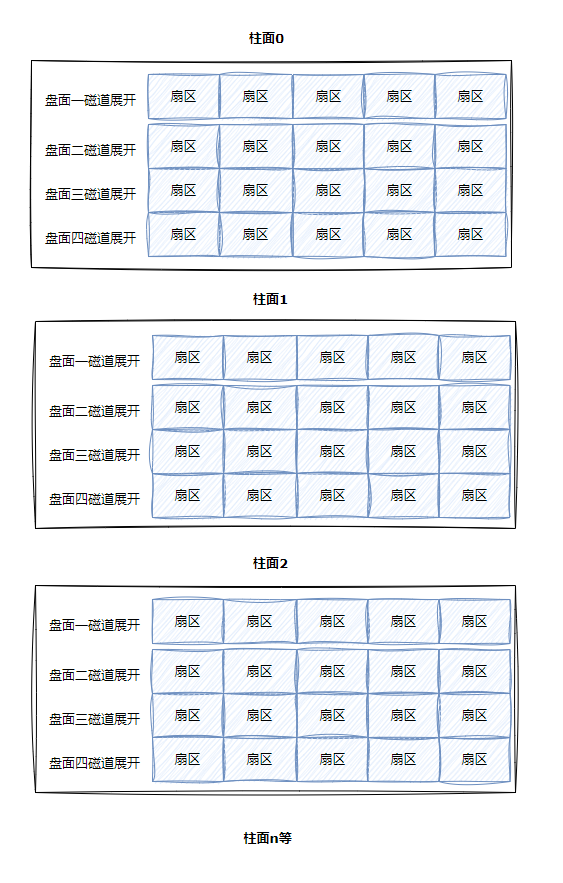
整個磁盤不就是多張?維的扇區數組表(三維數組?)
所有,尋址?個扇區:先找到哪?個柱?(Cylinder) ,在確定柱?內哪?個磁道(其實就是磁頭位置,
Head),在確定扇區(Sector),所以就有了CHS,CHS的順序就是查找扇區的順序。
我們之前學過C/C++的數組,在我們看來,其實全部都是?維數組:(二維數組本質也是一維數組)

所以,每?個扇區都有?個下標,我們叫做LBA(Logical Block Address)地址,其實就是線性地址。所以
怎么計算得到這個LBA地址呢?

OS只需要使?LBA就可以了!!LBA地址轉成CHS地址,CHS如何轉換成為LBA地址。誰做啊??磁盤
??來做!固件(硬件電路,伺服系統)
對于操作系統只需要LBA地址,但是對于磁盤來說CHS還是必須要的,所以我們需要兩者進行轉化.
5 CHS && LBA地址

二、理解分區、格式化
1 引?"塊"概念
OS與磁盤進行IO的時候,以扇區為基本單位,512字節,但是這是不是有點少啊,所以操作系統選擇以1k、2k、4k、8k等單位來IO的,大多數情況下操作系統以4k(8個扇區)為一個基本IO單位,我們稱這樣4k的區域叫做塊
? 知道LBA:塊號 = LBA/8
? 知道塊號:LAB=塊號*8 + n. (n是塊內第?個扇區)
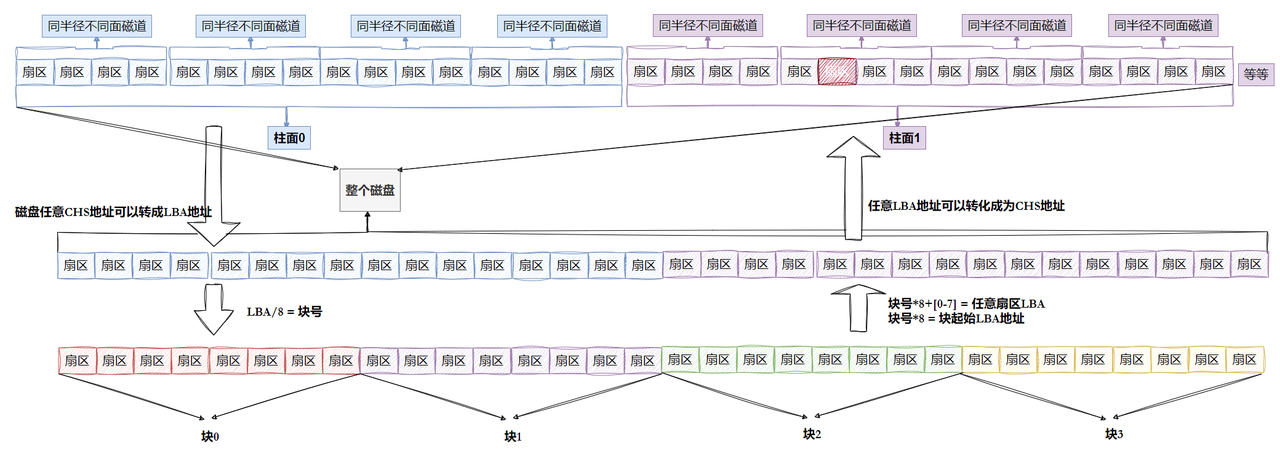
2 引?"分區"概念
學習這一部分之前我們先引入一個問題OS如何管理1000G、5000G、甚至50T的磁盤空間?
當操作系統要管理這么大的空間,成本非常的高,對于文件系統管理難度也是非常的高,那真實是如何管理的?
這種管理方式類似于我們現實生活中的省、市、縣的劃分,一個國家要一次性全部管理確實有難度,但我們分成市、縣,我們只需要管理好一個市、縣,其他市縣也按這種方式管理,就輕松很多,操作系統也類似。
磁盤要管理其實首先應該劃分區域(分區:c盤、d盤),分區與分區之前是可以使用不同的文件系統,這樣一個分區掛掉,不至于整個磁盤出問題
光是分區還不夠,操作系統又將一個分區分為不同的組,這樣管理好每一個組就等同于管理好一個區,管理好每一個區就等同于管理好整個磁盤空間,這種管理方式我們稱為分治
所以現在我們只需要學習管理每一個組:
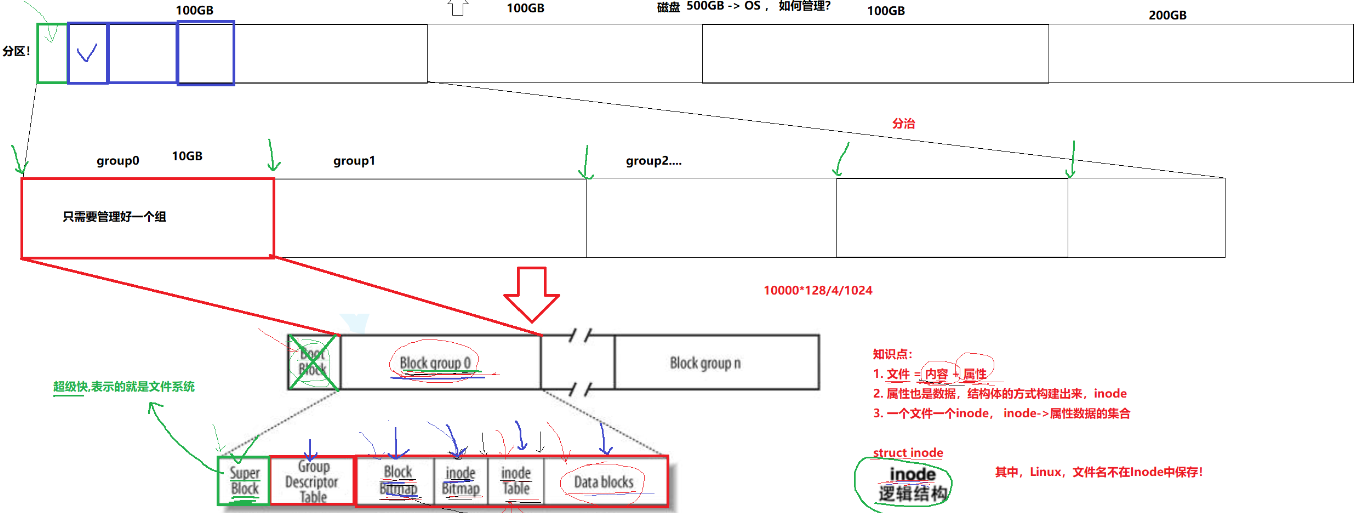
我們在Ext*文件系統中來學習分區
三、學習Ext*系列文件系統(inode號與inode)
補充知識:
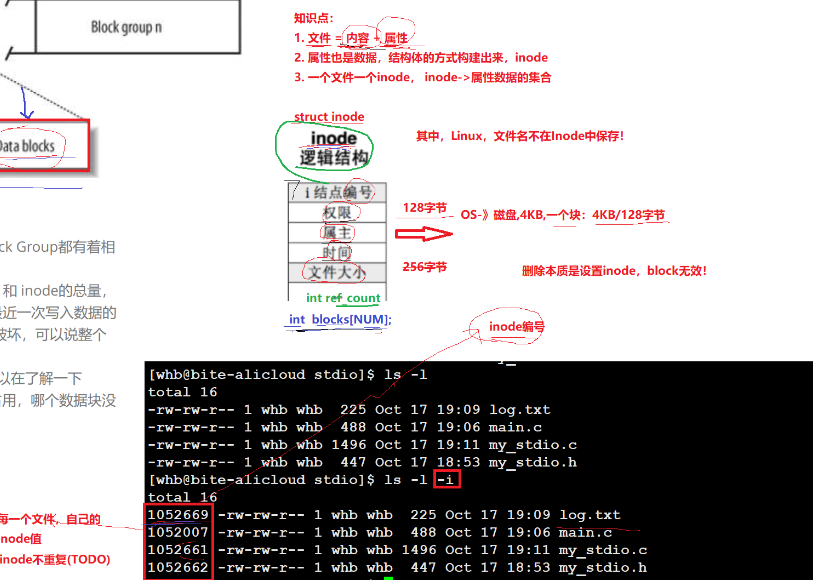
文件==內容+屬性(也是數據)屬性會以結構體的方式構建出來----inode
因此一個文件一個inode(一個文件的屬性集,128字節)互不重復
一個塊就(有4k/128字節)個inode
由于磁盤上的文件非常的多,為了存儲大量的inode所以我們需要一個inode table
當然磁盤更重要的還是儲存文件內容,所以磁盤還有數據塊,數據塊中每一個小塊都是4kb
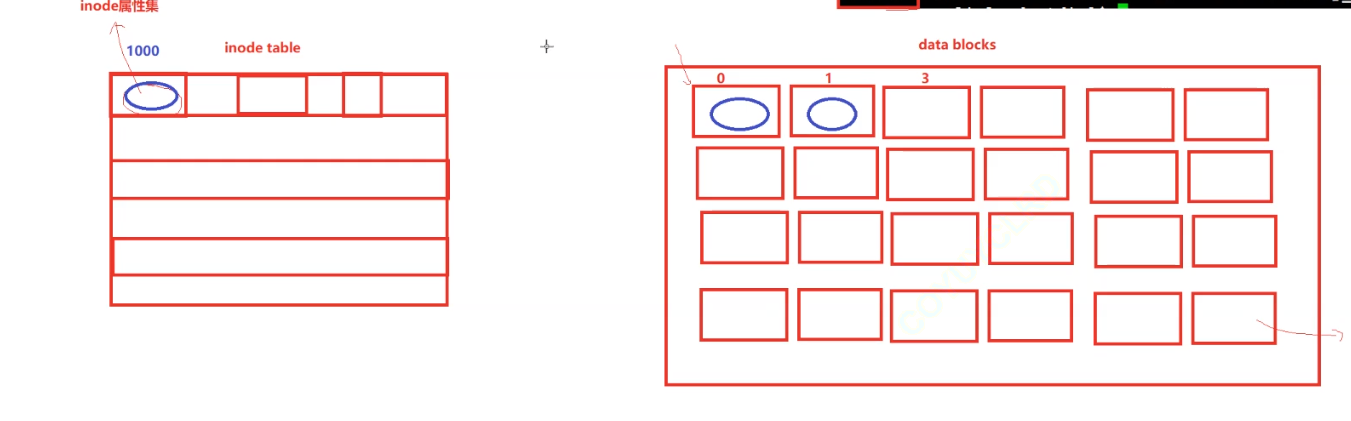
所以linux下文件屬性與文件內容分開存儲。其中inode與數據塊存在著映射關系,所以找到inode就找到了存儲數據的數據塊
一、inode bitmap類似于位圖,通過二進制位的值來查看此處有沒有inode存在,但是現在問題來了,我們上面說過磁盤是以塊為單位來存儲的,最小的訪問單位是扇區,磁盤與文件系統最小IO單位是4kb,我們根本就不能直接操作一個bit位,那我們該如何理解呢?
1、inode table也是以4kb(塊)為單位的方式存儲的
2、磁盤上的所有數據要修改都要讀到內存中(哪怕修改一個bit位都會讀到內存在操作,最后寫回)
根據我們上面的學習其實我們就可以簡單來談一下新建一個文件在磁盤上的過程:
1、分配一個inode(在inode bitmap中查找一個未被分配的位置),然后再向inode寫入文件屬性,例如時間,大小等
2、在block bitmap里申請一個塊,再向該塊寫入文件內容
3、最后在inode table中寫入inode號
所以我們找到inode編號就可以找到文件了。
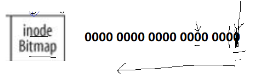
二、刪除文件的理解:
刪除一個文件根本不需要刪除屬性inode,和存儲內容的塊做清空,刪一個文件只需要在inode bitmap 和 block bitmap里把bit位由1->0 ,所以刪除一個文件可以恢復,所以只需要找到原本inode編號然后在inode bitmap和block bitmap里對應位置的bit位由0->1就恢復了,刪除本質就是inode, block無效
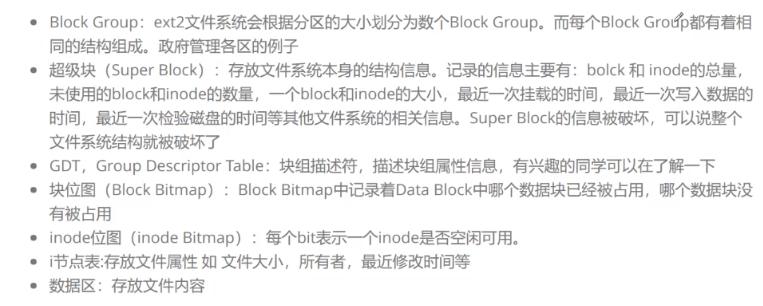
三、GDT:塊組描述符
描述當前區一共有多少inode,還剩多少inode,還剩多少block等等
四、super block:
我們的一個分區一共分了多少組?一個組的開始扇區,開始塊號,結束塊號,一共有多少個inode,多少個塊?。。。。。。
我們都需要知道,super block會把這些東西都記錄下來,所以super block表示對整個分區管理的數據結構,超級塊就表示文件系統。并不是一個分區一個super block,但也不是一個所有組都有super block,擁有super block的組是混雜在所有組之間的,并且所有的super block的內容完全一致,為什么?因為一個分區如果只有一個super block的話,一旦這個superblock掛掉后果太嚴重了,整個文件系統就等同于掛掉了,所以為了防止這種情況出現,會有多份
文件系統以分區為單位,每一個分區可以設置不同的文件系統
五、boot block:
在所有分組之前,它與磁盤啟動有關,這里我們不做了解,自己下來了解
文件名不在inode中,下面講解原因
格式化:向一個分區中寫入操作系統(將bit map,block map清空等)
四、理解系統中的文件、目錄
1、在一個分區中,每一個組的inode號的個數,block個數都是固定的,所以inode號個數等在整個文件系統中都是固定的,那有沒有inode用完了,block沒用完?這種情況是有可能的,這種情況其實很簡單就直接使用其他分區即可
2、關于inode
(1)inode以分區為單位,一套inode
(2)inode分配時,只需要確定每個組起始inode即可,所以每個組inode都是固定的,起始inode存于GDT里面
3、關于塊
(1)塊號也是統一分配的
(2)所以對于每一個組我們也只需記錄起始塊號就可以了,這個記錄與GDT中
4、所以對于一個具體的組,我們是如何分配inode?
每一個組都有各自的inode bitmap,我們用當前bitmap的值加上組起始inode,這個就是當前inode,再存于inode table
5、如何分配塊號的呢?
與上面相同-- start-block+block bitmap即可,之前我們知道inode與塊會存在映射關系(允許跨組),這兩者都是全局建立的,這允許我們跨組保存文件,故此允許我們大文件創建。
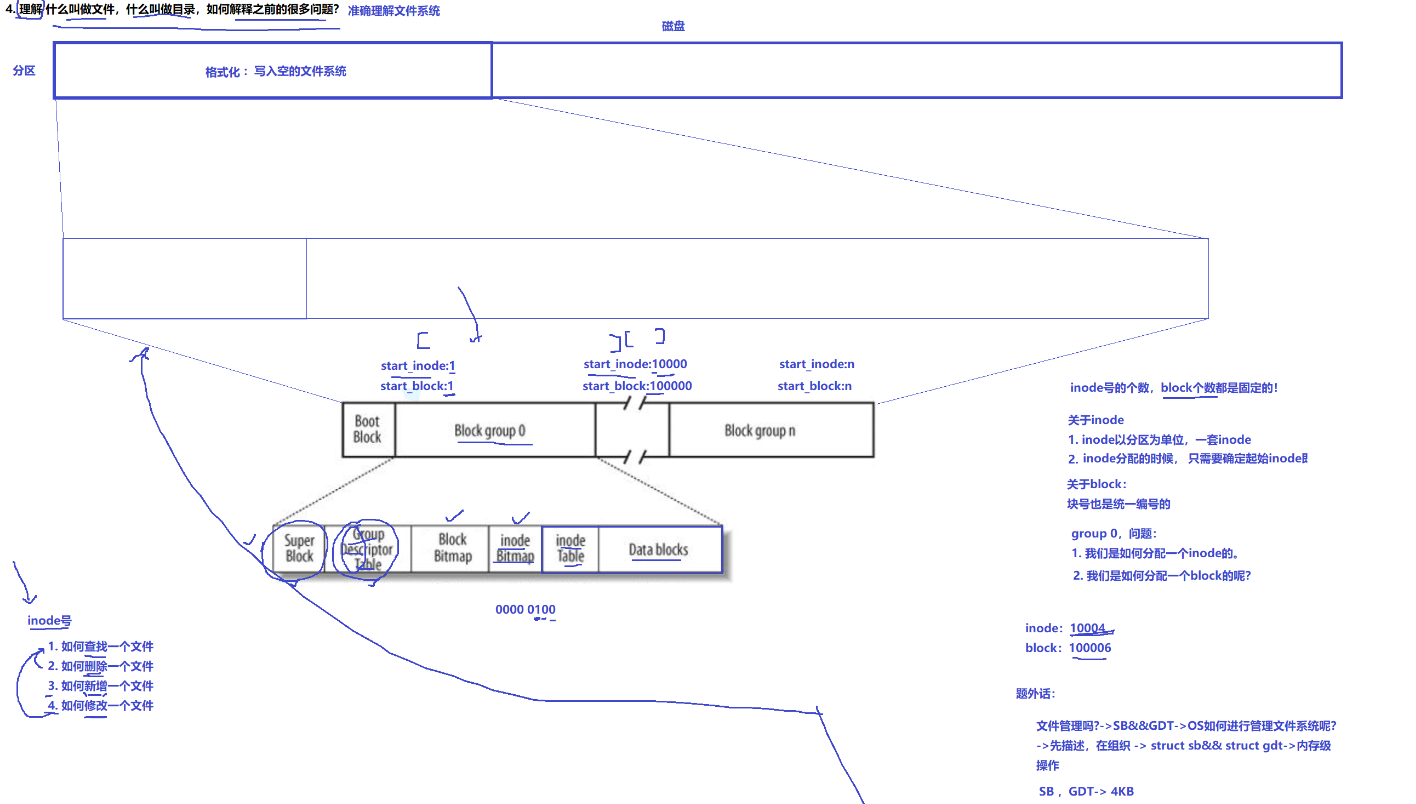
文件管理就是管理SB&&GDT
上面inode查找啊,分配inode啊全部都是內存級操作。
所以為了對應磁盤最小存儲單位為塊,其實內存也被劃分為4k的塊
如果我們知道inode如何增刪查改文件?
對于上面的四個操作,我認為只需要知道增和查,其他兩個操作就很簡單來了,增上面已經談過,找其實也就是將當前的inode號與每一個組中的其實inode對比,找所屬組,然后再用當前inode-起始inode就找到了其在當前組中的inode bitmap,然后在找到inode table,其他就知道了。
inode與block如何映射?
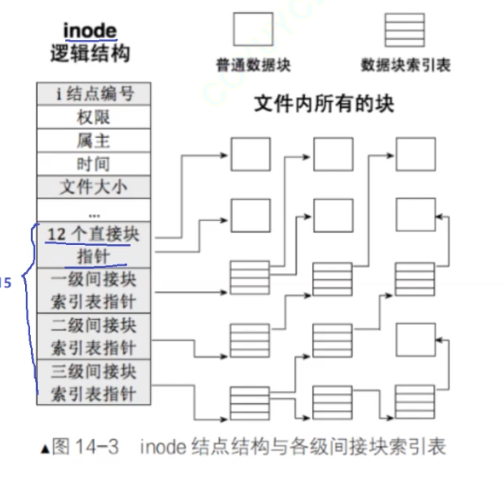
(1)一個inode映射有15個位置,前12個直接映射,也就是一個指針對應一個塊
(2)一級間接指針它不存文件數據,存其他塊號(4MB–4k*1024)
(3)二級間接指針,存其他索引的塊號 (4GB)
(4)三級間接指針同理
相關問題
憑什么拿到inode?我們在系統層面訪問的好像都是文件名啊???
上面我們說過文件名不在inode中,那它到底存于哪里?
首先我們由一個問題引入,我們上面一直都談論的是普通文件,但是我們知道還有一種文件叫做目錄啊?對于目錄也需要inode與data block,目錄的內容也要有對應的目錄塊(存文件名—inode的映射關系、互為映射)
所以我們來重新談一下文件屬性(rwx)
無r:無法讀取目錄的data block,拿不到inode
無w:無法將inode與文件映射關系寫到數據塊里
無x:打不開

再次理解文件名
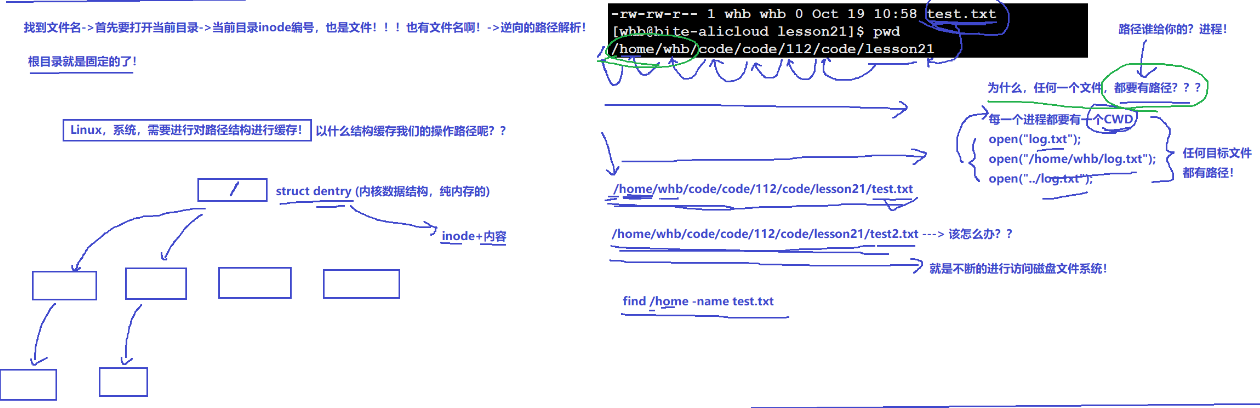
我們要操作文件需要找到文件名,首先要打開當前目錄,然后需要找到當前目錄的inode編號,但是當前inode編號也是由目錄inode存著的,也有文件名(/,根目錄的inode是固定寫死的)
所以為什么每一個進程都有CWD就是因為我們要訪問一個文件必須要找到完整的路徑
為了防止操作系統進行大量重復的路徑操作,linux需要對路徑進行緩存,linux以多叉樹的形式進行緩存我們的操作路徑(內存級)----dentry
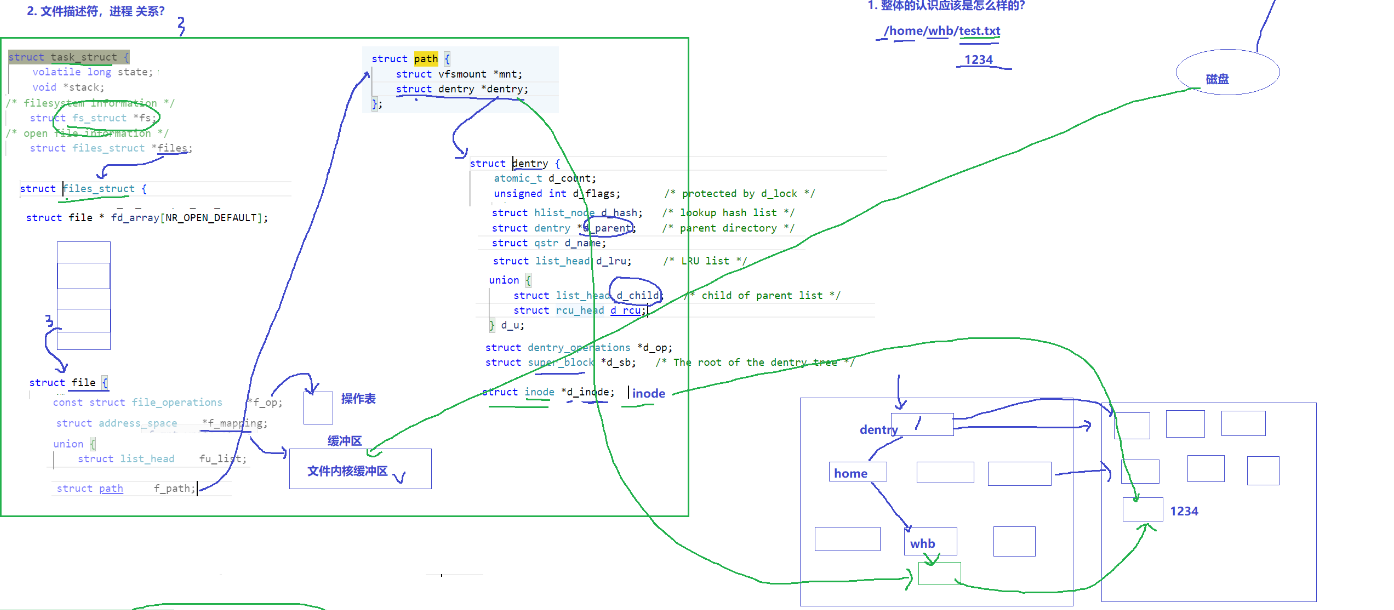
其中不光目錄有自己的dentry,其實普通文件也有自己的dentry
你怎么確定自己在哪一個分區?
多個分區,都會有自己的根目錄,其必須包含10個普通的目錄,在分區被分好之后,linux默認該分區無法使用(除了 / )
分區必須通過掛載,分區才能以路徑方式進行訪問。
ls /dev/vda* 查看分區
df -h 查看磁盤詳細情況
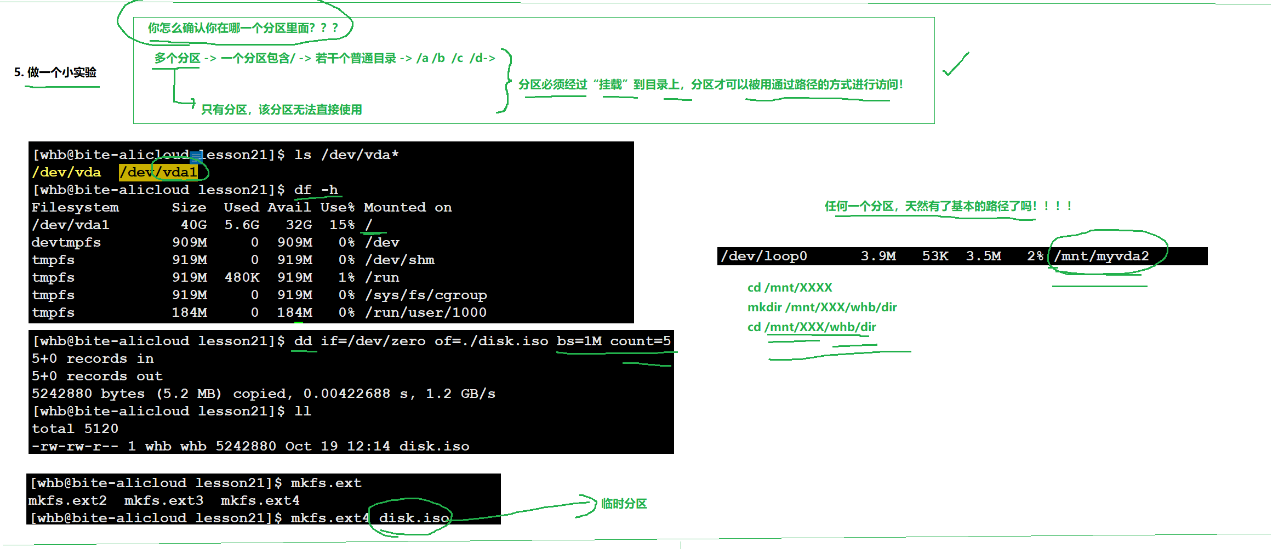
路徑的前綴就表示著自己在哪一個分區。
五、深刻理解軟硬鏈接
5.1 軟鏈接
1、命令:ln -s file.txt file-soft.link
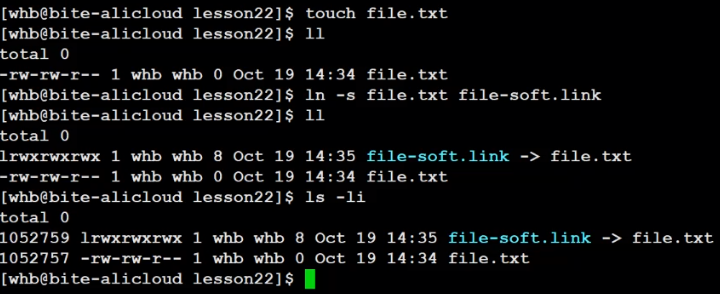
軟鏈接本質上是獨立的新建文件(在用戶層,軟鏈接的文件與原本文件具有相同的效應),我們可以將其理解為win上的快捷方式
5.2 硬鏈接
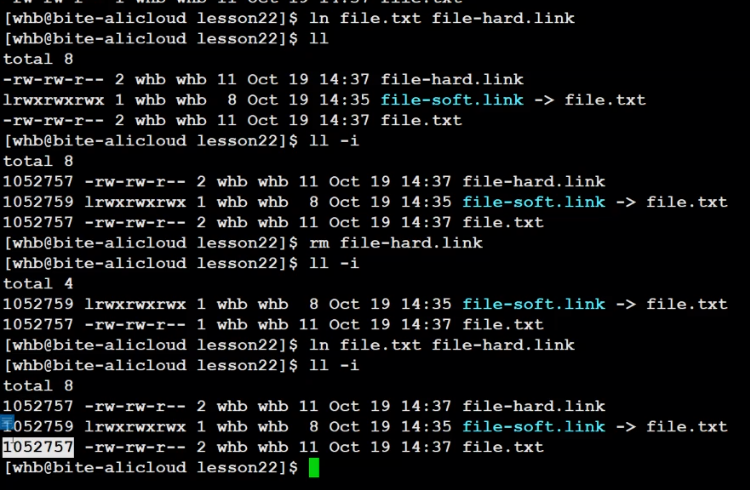
硬鏈接本質不是獨立文件
5.3 理解軟硬鏈接
1、軟鏈接有獨立的inode,軟鏈接內容上保存的是目標文件的路徑(win下的快捷方式)
2、硬鏈接不是獨立文件,無獨立inode,本質上是文件名和以及存在的文件的映射關系
3、硬鏈接權限后面的數字叫做inode的引用計數(硬鏈接數)
5.4 軟硬鏈接的使用場景
1、軟(目錄也可以建立軟鏈接):

讓我們的程序不帶 ./ 就能使用前面已經介紹過很多方法了,這里介紹一種–建立軟鏈接在user/bin目錄下

刪除軟鏈接
2、硬鏈接
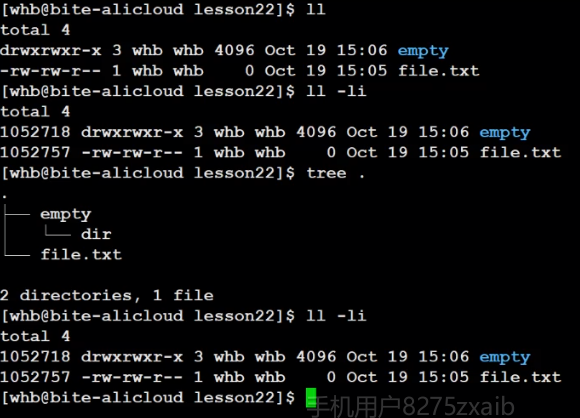
現在我們創建了一個目錄和一個文件,默認文件硬鏈接數是1,這個沒什么問題,但是目錄默認卻是2,并且我們在該目錄下又建一個目錄,鏈接數又變成3了?
我們之前不是學過隱藏文件. 和 … ,之前我們只知道 . 代表自己,但我們不知道為什么,今天就可以給大家解釋了 . 其實就是對自己的一個硬鏈接,所以目錄默認為2,新建目錄為什么變為3? 是因為dir目錄中還有一個 … ,它也指向該目錄
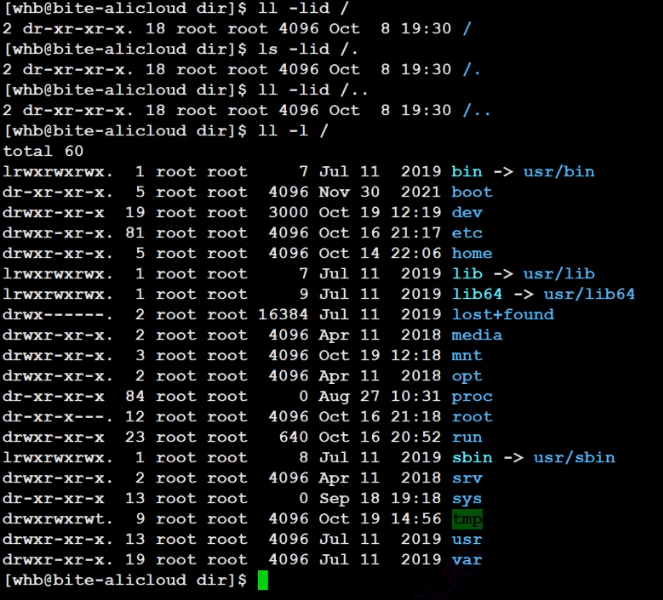
需要注意的是 根目錄下的 … 是被特殊處理的,并不是指向自己.
硬鏈接也可以用作硬鏈接,當我們刪除時只刪除的一個引用計數,只要不完全清空,就可以使用文件。
linux中,不允許對目錄新建硬鏈接(可能會出現環狀鏈接)
-上下文壓縮與過濾)




4*3蝴蝶拼圖(圓形、三角、正方、半圓的凹凸小塊+參考圖灰色))









優化器nestloop參數化路徑評估不準問題分析)



)