2、時序差分法(TD)
核心思想
TD 方法通過 引導值估計來學習最優策略。它利用當前的估計值和下一個時間步的信息來更新價值函數, 這種方法被稱為“引導”(bootstrapping)。而不需要像蒙特卡羅方法那樣等待一個完整的 episode 結束才進行更新,也不需要像動態規劃方法那樣已知環境的轉移概率。
狀態價值函數更新
以最基本的 TD(0) 為例,狀態價值函數 V( s) 的更新公式為:
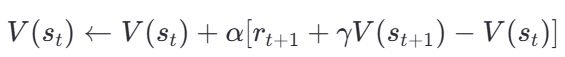
其中:
- st?:當前狀態;
- rt+1?:從狀態?stst??轉移到下一狀態?st+1st+1??所獲得的獎勵;
- γ:折扣因子,用于衡量未來獎勵的重要性;
- α:學習率,控制更新的步長。
動作價值函數更新
對于動作價值函數 Q(s,a) Q( s, a),常見的 TD 更新方式如 Q-learning:
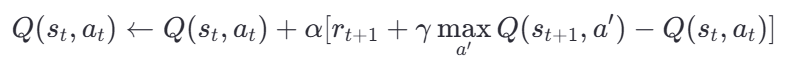
其中:
- maxa′?Q(st+1?,a′):在狀態st+1??下所有可能動作的最大 Q 值。
算法特點
在線學習
TD 方法可以在與環境交互的過程中實時學習,每經歷一個時間步即可進行一次價值函數更新,無需等到整個 episode 結束,適合實時性要求高的場景。
樣本效率高
相比蒙特卡羅方法,TD 方法利用了環境的時序信息,通過“引導”機制減少對大量樣本的依賴,在樣本有限的情況下也能取得較好的學習效果。
融合兩者優點
- 不需要環境模型(類似蒙特卡羅);
- 利用貝爾曼方程進行更新(類似動態規劃);
- 克服了蒙特卡羅方法中對完整 episode 的依賴,提高學習效率。
局限性
- 收斂性問題:在復雜環境中可能出現收斂慢或不收斂的問題,尤其在狀態空間大或獎勵稀疏時表現不佳。
- 對超參數敏感:算法性能受學習率?α、折扣因子?γ?等影響較大,需多次實驗調參。
- 模型泛化能力有限:通常只能針對特定環境學習最優策略,環境變化后需重新訓練。
1)TD learning of state values
核心思想
TD(0) 是最基礎的狀態值學習方法。它通過比較當前狀態的價值估計與基于后續狀態的價值估計來更新當前狀態的價值估計。
算法公式:
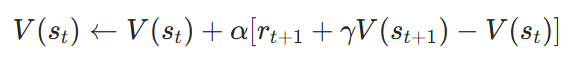
- TD Target:rt+1?+γV(st+1?)(基于下一狀態的預估價值)。
- TD Error:δt?=rt+1?+γV(st+1?)?V(st?)(當前估計的偏差)。
2)TD learning of action values : Sarsa
核心思想
Sarsa 是一種在線策略(on - policy)的 TD 算法, 它直接使用行為策略生成的數據進行評估和改進該策略, 估計動作價值函數? Q(s, a) 。
算法公式:
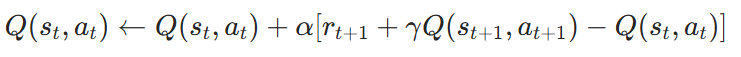
- 策略依賴:動作?at+1??由當前策略(如ε-貪婪策略)生成。
偽代碼
對于每一個 episode,執行以下操作:
如果當前狀態 s t? 不是目標狀態,執行以下步驟:
經驗收集(Collect the experience)
獲取經驗元組( s t?, a t?, r t+1?, s t+1?, a t+1?):
具體來說,按照當前策略 π t?( s t?) 選擇并執行動作 a t?,得到獎勵 r t+1? 和下一狀態 s t+1?;
然后按照當前策略 π t?( s t+1?) 選擇下一個動作 a t+1?。
Q 值更新(Update q-value)(根據上述公式)
策略更新(Update policy)(使用ε-貪婪策略)
實現代碼
import time
import numpy as np
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未來獎勵的衰減程度self.env = envself.action_space_size = env.action_space_size #動作空間大小self.state_space_size = env.size ** 2 #狀態空間大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #獎勵self.state_value = np.zeros(shape=self.state_space_size) #狀態值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #動作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每個動作概率相等self.policy = self.mean_policy.copy()def sarsa(self, alpha=0.1, epsilon=0.1, num_episodes=80):while num_episodes > 0:done = Falseself.env.reset()next_state = 0num_episodes -= 1total_rewards = 0episode_length = 0while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size),p=self.policy[state]) #按照當前策略選擇動作_, reward, done, _, _ = self.env.step(action) #根據當前動作得到下一狀態和獎勵,在self.env.agent_locationepisode_length += 1total_rewards += rewardnext_state = self.env.pos2state(self.env.agent_location) #下一動作next_action = np.random.choice(np.arange(self.action_space_size),p=self.policy[next_state]) #按照當前策略選擇下一動作target = reward + self.gama * self.qvalue[next_state, next_action]error = target - self.qvalue[state, action] #估計偏差self.qvalue[state, action] = self.qvalue[state, action] + alpha * error #q值更新qvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size): #策略更新if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilondef show_policy(self):# 可視化策略(Policy):將智能體的策略(每次行動的方向標注為箭頭)以圖形化的方式渲染到環境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可視化狀態價值函數(State - ValueFunction):將每個狀態的價值(長期累積獎勵的預期)以文本形式渲染到環境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.sarsa()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
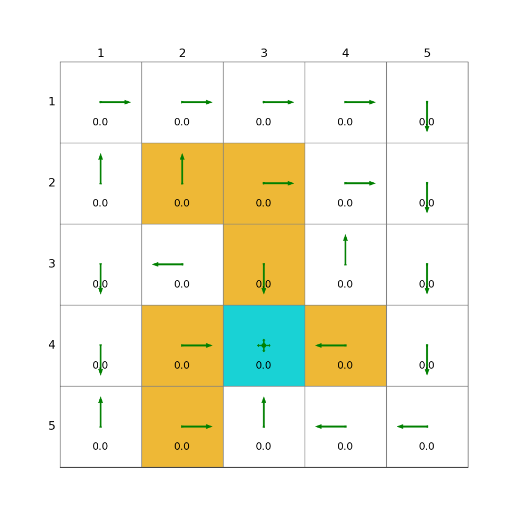
3)TD learning of action values: Expected Sarsa
核心思想
Expected Sarsa 也是一種用于學習動作價值函數?Q(s, a))的 TD 算法。與 Sarsa 不同的是,它在更新時考慮了下一個狀態下所有可能動作的期望價值,而不是僅僅使用一個特定的動作。
算法公式:
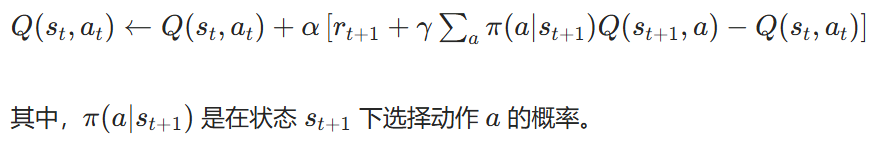
偽代碼
和Sarsa類似,只是在Q 值更新時使用的是期望價值。
實現代碼
import matplotlib.pyplot as plt
import numpy as np
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未來獎勵的衰減程度self.env = envself.action_space_size = env.action_space_size #動作空間大小self.state_space_size = env.size ** 2 #狀態空間大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #獎勵self.state_value = np.zeros(shape=self.state_space_size) #狀態值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #動作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每個動作概率相等self.policy = self.mean_policy.copy()def expected_sarsa(self, alpha=0.1, epsilon=1, num_episodes=1000):init_num = num_episodesqvalue_list = [self.qvalue, self.qvalue + 1]episode_index_list = []reward_list = []length_list = []while num_episodes > 0:if epsilon > 0.1:epsilon -= 0.01episode_index_list.append(init_num - num_episodes)done = Falseself.env.reset()next_state = 0total_rewards = 0episode_length = 0num_episodes -= 1while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size),p=self.policy[state])_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)expected_qvalue = 0episode_length += 1total_rewards += rewardfor next_action in range(self.action_space_size):expected_qvalue += self.qvalue[next_state, next_action] * self.policy[next_state, next_action]target = reward + self.gama * expected_qvalueerror = target - self.qvalue[state, action]self.qvalue[state, action] = self.qvalue[state, action] + alpha * errorqvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size):if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilonqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(episode_length)fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=length_list, subplot_position=212,xlabel='episode_index', ylabel='total_length')fig.show()def show_policy(self):# 可視化策略(Policy):將智能體的策略(每次行動的方向標注為箭頭)以圖形化的方式渲染到環境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可視化狀態價值函數(State - ValueFunction):將每個狀態的價值(長期累積獎勵的預期)以文本形式渲染到環境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.expected_sarsa()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
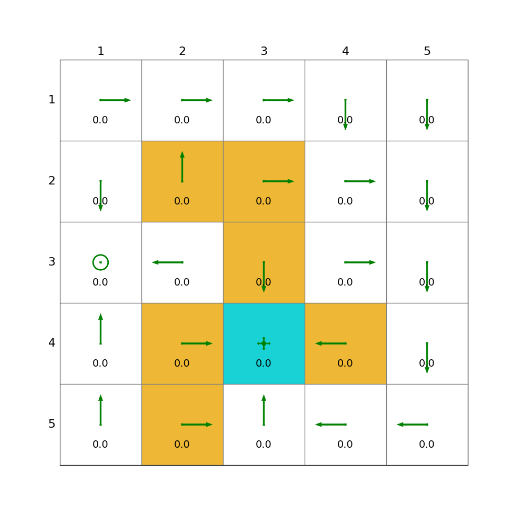
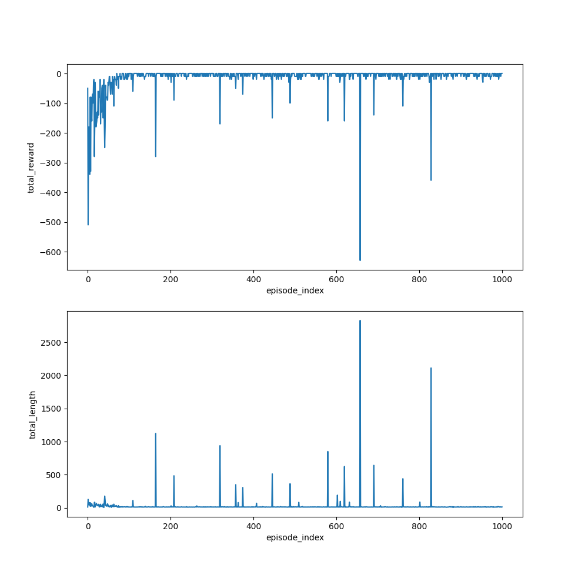
4)TD learning of action values: n-step Sarsa
核心思想
n - step Sarsa 是 Sarsa 算法的擴展,它不僅僅考慮下一個時間步的信息,而是考慮未來?n?個時間步的獎勵和狀態。這種方法結合了短期和長期的信息,以更準確地估計動作價值。
算法公式:

特點
- 平衡短期和長期信息:通過調整?n?的值,可以在短期和長期獎勵之間進行權衡。當?(n = 1)?時,n - step Sarsa 退化為普通的 Sarsa 算法;當?n?趨近于無窮大時,它類似于蒙特卡羅方法。
- 可以提高學習的穩定性和效率,尤其是在環境動態變化的情況下。
偽代碼
和Sarsa類似,只是在 Q 值更新時使用的上述公式。
實現代碼
import matplotlib.pyplot as plt
import numpy as np
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未來獎勵的衰減程度self.env = envself.action_space_size = env.action_space_size #動作空間大小self.state_space_size = env.size ** 2 #狀態空間大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #獎勵self.state_value = np.zeros(shape=self.state_space_size) #狀態值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #動作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每個動作概率相等self.policy = self.mean_policy.copy()def nsteps_sarsa(self, alpha=0.1, epsilon=1, num_episodes=1000, n=10):init_num = num_episodesqvalue_list = [self.qvalue.copy()]episode_index_list = []reward_list = []length_list = []while num_episodes > 0:if epsilon > 0.1:epsilon -= 0.01episode_index_list.append(init_num - num_episodes)done = Falseself.env.reset()next_state = 0total_rewards = 0episode_length = 0num_episodes -= 1# 存儲軌跡信息(狀態、動作、獎勵)trajectory = []while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size), p=self.policy[state])_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)trajectory.append((state, action, reward))total_rewards += rewardepisode_length += 1# 計算 n-step 回報T = len(trajectory) # 軌跡長度for t in range(T):# 獲取當前狀態、動作、獎勵state, action, reward = trajectory[t]target = 0# 計算 n-step 回報if t + n < T:# 如果軌跡足夠長,計算 n-step 回報for i in range(n-1,-1,-1):next_reward_n = trajectory[t + i][2]target = target*self.gama + next_reward_nnext_state_n = trajectory[t + n][0]next_action_n = trajectory[t + n][1]q_next = self.qvalue[next_state_n, next_action_n]target = target + q_nextelse:for i in range(T-t-1,-1,-1):next_reward_n = trajectory[t + i][2]target = target * self.gama + next_reward_nnext_state_n = trajectory[T-t-1][0]next_action_n = trajectory[T-t-1][1]q_next = self.qvalue[next_state_n, next_action_n]target = target + q_next# 更新 Q 值error = target - self.qvalue[state, action]self.qvalue[state, action] += alpha * error# 更新策略qvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size):if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilonqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(episode_length)fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=length_list, subplot_position=212,xlabel='episode_index', ylabel='total_length')fig.show()def show_policy(self):# 可視化策略(Policy):將智能體的策略(每次行動的方向標注為箭頭)以圖形化的方式渲染到環境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可視化狀態價值函數(State - ValueFunction):將每個狀態的價值(長期累積獎勵的預期)以文本形式渲染到環境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)solver.nsteps_sarsa()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
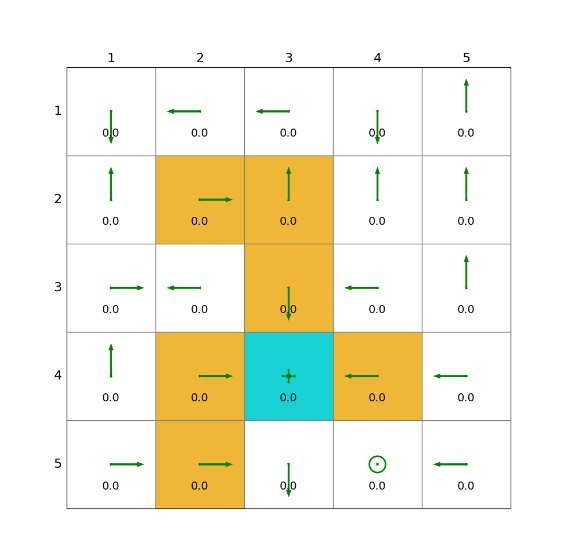
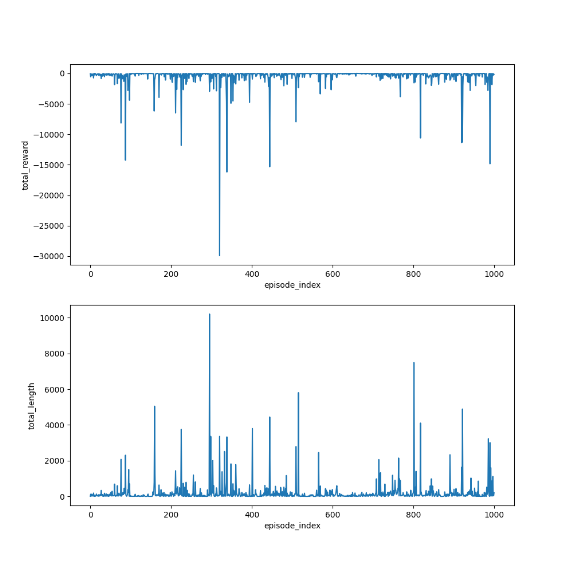
5)TD learning of optimal action values: Q-learning
核心思想
Q - learning 是一種異策略(off - policy)的 TD 算法,直接學習最優動作價值函數Q*(s, a)。異策略意味著它使用一個行為策略來生成行為,而使用另一個目標策略(通常是貪心策略)來更新動作價值。
算法公式:
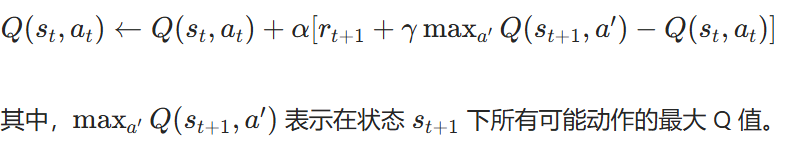
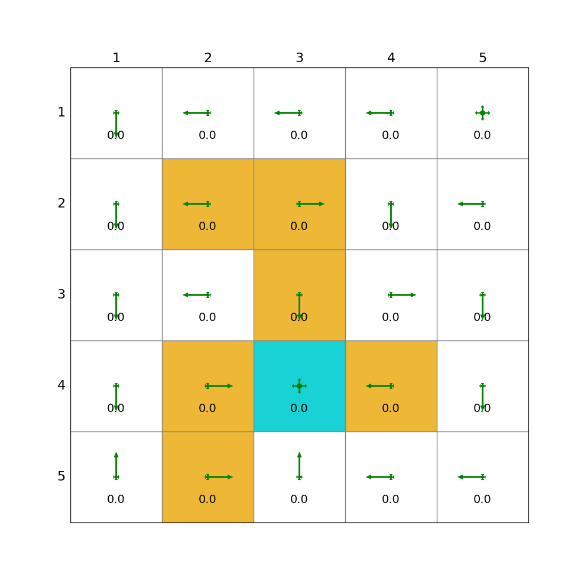
偽代碼
1)在線版本的Q-learning(on-policy)
對于每一個 episode,執行以下操作:
如果當前狀態st? 不是目標狀態,執行以下步驟:
經驗收集(Collect the experience)
獲取經驗元組(st?,at?,rt+1?,st+1?):
具體來說,按照當前策略πt?(st?) 選擇并執行動作at?,得到獎勵rt+1? 和下一狀態 st+1?。
Q 值更新(Update q-value):按照上述公式
策略更新(Update policy):用ε 貪婪策略
2)離線版本的Q-learning(off-policy)
對于由行為策略 πb? 生成的每一個 episode {s0?,a0?,r1?,s1?,a1?,r2?,…},執行以下操作:
對于該 episode 中的每一步t=0,1,2,…,執行以下操作:
Q 值更新(Update q-value):按照上述公式
策略更新(Update policy):用貪婪策略
實現代碼
import matplotlib.pyplot as plt
import numpy as np
import grid_envclass Solve:def __init__(self, env: grid_env.GridEnv):self.gama = 0.9 #折扣因子,表示未來獎勵的衰減程度self.env = envself.action_space_size = env.action_space_size #動作空間大小self.state_space_size = env.size ** 2 #狀態空間大小self.reward_space_size, self.reward_list = len(self.env.reward_list), self.env.reward_list #獎勵self.state_value = np.zeros(shape=self.state_space_size) #狀態值self.qvalue = np.zeros(shape=(self.state_space_size, self.action_space_size)) #動作值self.mean_policy = np.ones(shape=(self.state_space_size, self.action_space_size)) / self.action_space_size #平均策略,表示采取每個動作概率相等self.policy = self.mean_policy.copy()def q_learning_on_policy(self, alpha=0.001, epsilon=0.4, num_episodes=1000):init_num = num_episodesqvalue_list = [self.qvalue, self.qvalue + 1]episode_index_list = []reward_list = []length_list = []while num_episodes > 0:episode_index_list.append(init_num - num_episodes)done = Falseself.env.reset()next_state = 0total_rewards = 0episode_length = 0num_episodes -= 1while not done:state = next_stateaction = np.random.choice(np.arange(self.action_space_size),p=self.policy[state])_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)episode_length += 1total_rewards += rewardnext_qvalue_star = self.qvalue[next_state].max()target = reward + self.gama * next_qvalue_starerror = self.qvalue[state, action] - targetself.qvalue[state, action] = self.qvalue[state, action] - alpha * errorqvalue_star = self.qvalue[state].max()action_star = self.qvalue[state].tolist().index(qvalue_star)for a in range(self.action_space_size):if a == action_star:self.policy[state, a] = 1 - (self.action_space_size - 1) / self.action_space_size * epsilonelse:self.policy[state, a] = 1 / self.action_space_size * epsilonqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(episode_length)fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=length_list, subplot_position=212,xlabel='episode_index', ylabel='total_length')fig.show()def q_learning_off_policy(self, alpha=0.01, num_episodes=1000, episode_length=1000):qvalue_list = [self.qvalue, self.qvalue + 1]episode_index_list = []reward_list = []length_list = []init_num = num_episodeswhile num_episodes > 0:num_episodes -= 1total_rewards = 0episode_index_list.append(init_num - num_episodes)start_state = self.env.pos2state(self.env.agent_location)start_action = np.random.choice(np.arange(self.action_space_size),p=self.mean_policy[start_state])episode = self.obtain_episode(self.mean_policy.copy(), start_state=start_state, start_action=start_action,length=episode_length)for step in range(len(episode) - 1):reward = episode[step]['reward']state = episode[step]['state']action = episode[step]['action']next_state = episode[step + 1]['state']next_qvalue_star = self.qvalue[next_state].max()target = reward + self.gama * next_qvalue_starerror = self.qvalue[state, action] - targetself.qvalue[state, action] = self.qvalue[state, action] - alpha * erroraction_star = self.qvalue[state].argmax()self.policy[state] = np.zeros(self.action_space_size)self.policy[state][action_star] = 1total_rewards += rewardqvalue_list.append(self.qvalue.copy())reward_list.append(total_rewards)length_list.append(len(episode))fig = plt.figure(figsize=(10, 10))self.env.render_.add_subplot_to_fig(fig=fig, x=episode_index_list, y=reward_list, subplot_position=211,xlabel='episode_index', ylabel='total_reward')fig.show()def obtain_episode(self, policy, start_state, start_action, length):f""":param policy: 由指定策略產生episode:param start_state: 起始state:param start_action: 起始action:param length: episode 長度:return: 一個 state,action,reward,next_state,next_action 序列"""self.env.agent_location = self.env.state2pos(start_state)episode = []next_action = start_actionnext_state = start_statewhile length > 0:length -= 1state = next_stateaction = next_action_, reward, done, _, _ = self.env.step(action)next_state = self.env.pos2state(self.env.agent_location)next_action = np.random.choice(np.arange(len(policy[next_state])),p=policy[next_state])episode.append({"state": state, "action": action, "reward": reward, "next_state": next_state,"next_action": next_action})return episodedef show_policy(self):# 可視化策略(Policy):將智能體的策略(每次行動的方向標注為箭頭)以圖形化的方式渲染到環境中for state in range(self.state_space_size):for action in range(self.action_space_size):policy = self.policy[state, action]self.env.render_.draw_action(pos=self.env.state2pos(state),toward=policy * 0.4 * self.env.action_to_direction[action],radius=policy * 0.1)def show_state_value(self, state_value, y_offset=0.2):# 可視化狀態價值函數(State - ValueFunction):將每個狀態的價值(長期累積獎勵的預期)以文本形式渲染到環境中。for state in range(self.state_space_size):self.env.render_.write_word(pos=self.env.state2pos(state), word=str(round(state_value[state], 1)),y_offset=y_offset,size_discount=0.7)if __name__ == "__main__":env = grid_env.GridEnv(size=5, target=[2, 3],forbidden=[[2, 2], [2, 1], [1, 1], [3, 3], [1, 3], [1, 4]],render_mode='')solver = Solve(env)# solver.q_learning_on_policy()solver.q_learning_off_policy()solver.show_policy()solver.show_state_value(solver.state_value, y_offset=0.25)solver.env.render()效果
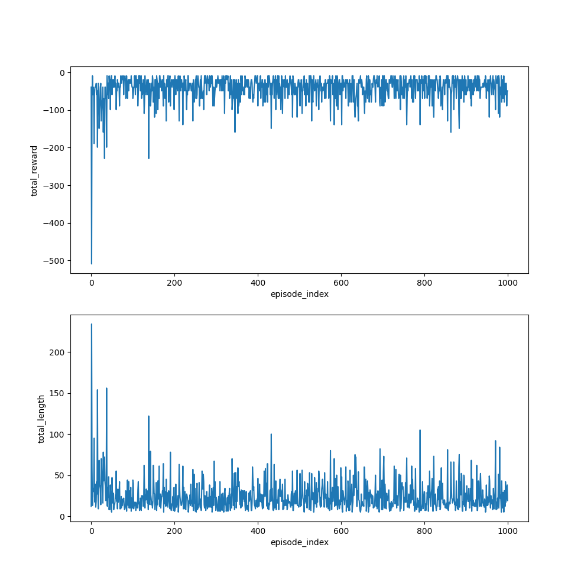
1)在線版本的Q-learning
2)離線版本的Q-learning(off-policy)
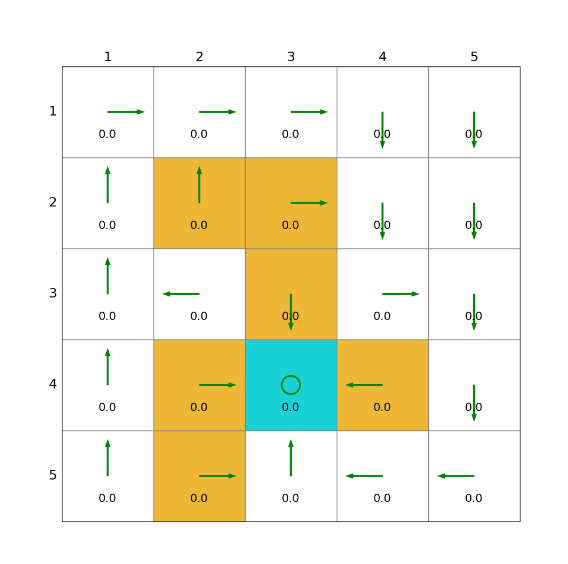
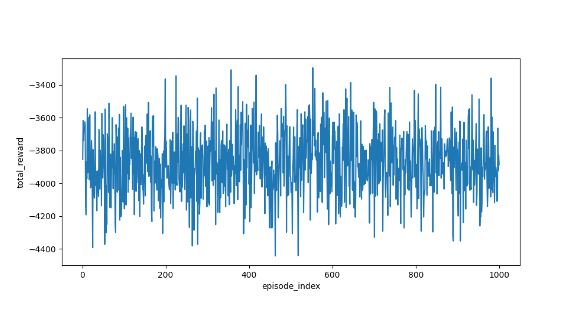








)

)






![[android]MT6835 Android 關閉selinux方法](http://pic.xiahunao.cn/[android]MT6835 Android 關閉selinux方法)

