本文專欄:Linux網絡編程
目錄
一,狀態碼
重定向狀態碼
1,永久重定向(301 Moved Permanently)
2,臨時重定向(302 Found)
二,常見請求方法
1,HTTP常見Header
2,GET方法?
3,POST方法
4,總結
3,session
?4,總結
源碼
?
一,狀態碼
HTTP狀態碼:是服務器響應客戶端請求時返回的三位數字代碼,用于表示請求的處理結果。
以下列舉幾種常見狀態碼的表格:
| 狀態碼 | 含義 | 應用樣例 |
| 100 | Continue | 表示請求已接受,需要繼續處理。例如,上傳大文件時,服務器告訴客戶端可以繼續上傳。 |
| 200 | OK | 表示請求已被成功處理 |
| 201 | Create | 資源創建成功。例如,發布新文章,服務器返回文章創建成功的信息 |
| 204 | Not? Content | 刪除文章后,服務器返回“無內容”表示操作成功 |
| 301 | Moved Permanently | 網站更換域名后,自動跳轉到新的域名。搜索引擎更換網站鏈接時使用 |
| 302 | Found或 See Other | 用戶登錄成功后,自動跳轉到用戶首頁 |
| 304 | Not Midified | 瀏覽器緩存機制 |
| 400 | Bad Request | 填寫表單時,格式不正確導致的錯誤 |
| 401 | Unauthorized | 訪問需要登陸的頁面時,未登錄或者認證失敗 |
| 404 | Not Found | 訪問的鏈接不存在 |
| 500 | Internal Server Error | 服務器崩潰或數據庫錯誤導致頁面無法加載 |
| 502 | Bad Gateway | 使用代理服務器時,收到無效響應 |
| 503 | Service Unavaliable | 服務不可用(維護中或過載) |
重定向狀態碼
- 關于重定向相關的狀態碼,可以大概分為兩類,永久重定向和臨時重定向。
- 在本文中以301永久重定向和302臨時重定向為例,進行討論。
- 簡單的理解重定向,就是當我們想訪問一個網址時,會跳轉到其他的網址。
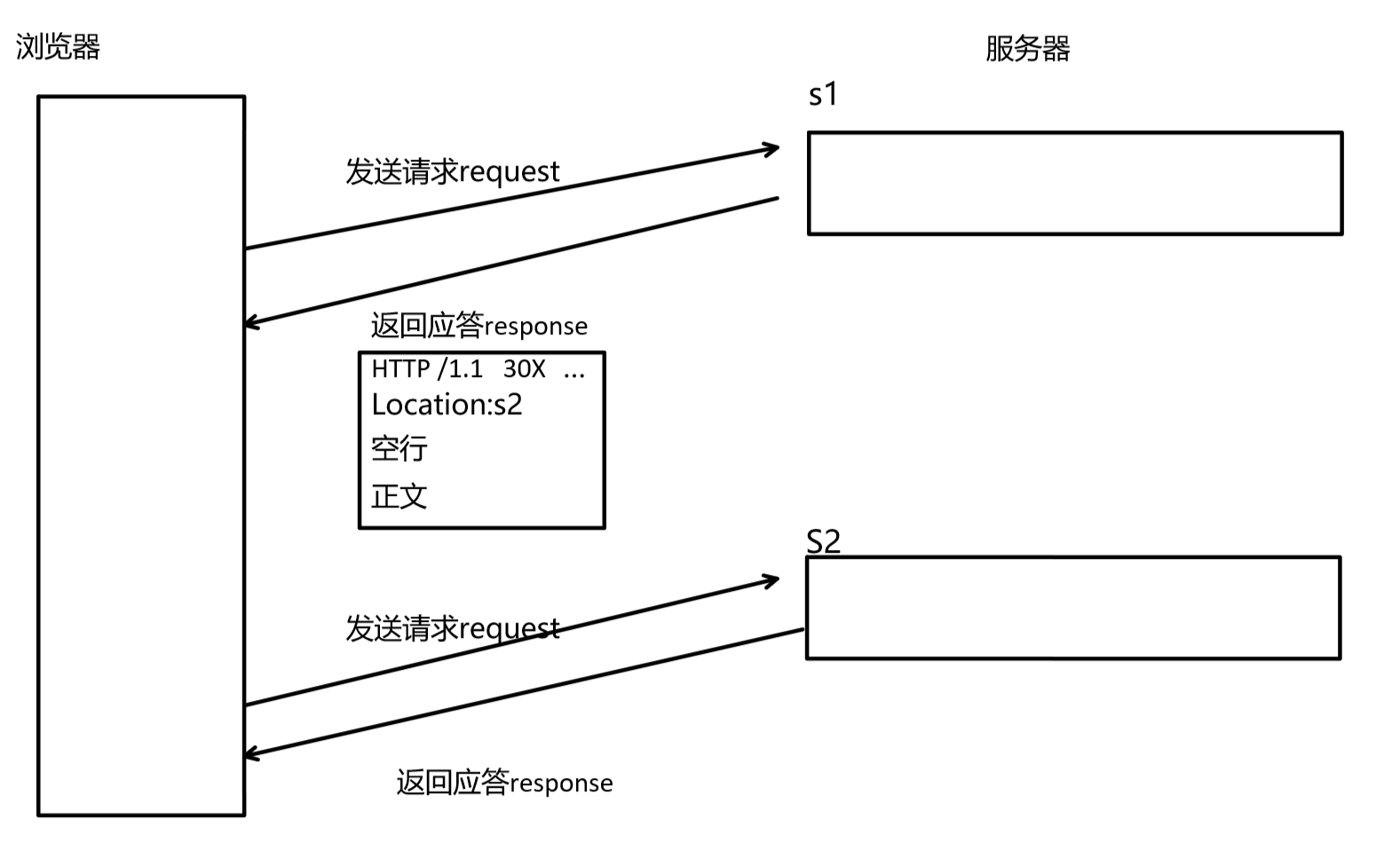
具體看下圖:
當使用瀏覽器訪問s1時,接收到s1發送的應答報文,發現它的狀態碼是30x(301或者302),就知道是需要重定向到新的網址,新的網址是報文中Location后面的內容。提取到到新的網址后,瀏覽器會發送二次請求訪問新的網址。這就是重定向的大致過程。
1,永久重定向(301 Moved Permanently)
- 所謂永久重定向,就是我們想訪問的資源的域名發生更改,當我們使用原網址進行訪問的時候,會直接跳轉到新的網址下。并且瀏覽器會更改內部的數據,用新的網址覆蓋掉原來的網址,下次訪問的時候就直接使用新的網址了。
- 永久重定向(301)的價值是用來給搜索引擎更新網站鏈接的。
- 在我們使用搜索引擎訪問資源的時候,其實就是獲取到目標資源的域名。但是如果有些域名發生改變,就可能會導致訪問失敗。
- 所以,對于搜索引擎,會不定時的向目標資源發送請求,當收到目標的應答時,如果發現報文中狀態碼是301,并且報文中包含Location: XXX選項。搜索引擎就會將自己內部保保存原來的域名用新的XXX域名替換掉,所以下次訪問的時候,直接使用新的域名。
2,臨時重定向(302 Found)
有了對永久重定向的理解,臨時重定向就很簡單。當我們訪問一個網址時,會跳轉到新的網址,最常見的就是我們用戶的登錄操作,當我們登錄完成后,就會跳轉到用戶首頁。而下次訪問時,還是需要先訪問登錄頁面。
二,常見請求方法
最常見的兩種方法:GET和POST
- POST:上傳資源,比如登錄操作,需要上傳我們的用戶名和密碼。
- GET:獲取資源,獲取網頁,圖片,視頻等等各種資源。同時也可以上傳資源。
1,HTTP常見Header
Content-Type:數據類型,就是正文部分的內容是什么類型的,html,css或者是純文本等等類型
Content-Length:正文部分的長度
Host:客戶端告訴服務器,所請求的資源在哪個主機的哪個端口上。
User-Agent:聲明用戶的操作系統的瀏覽器版本信息
refer:當前頁面是從哪個頁面跳轉過來的
Location:在上面狀態碼部分提到過。告訴客戶端接下來要去哪里訪問。
Cookie:這個 內容在本文下面講解。
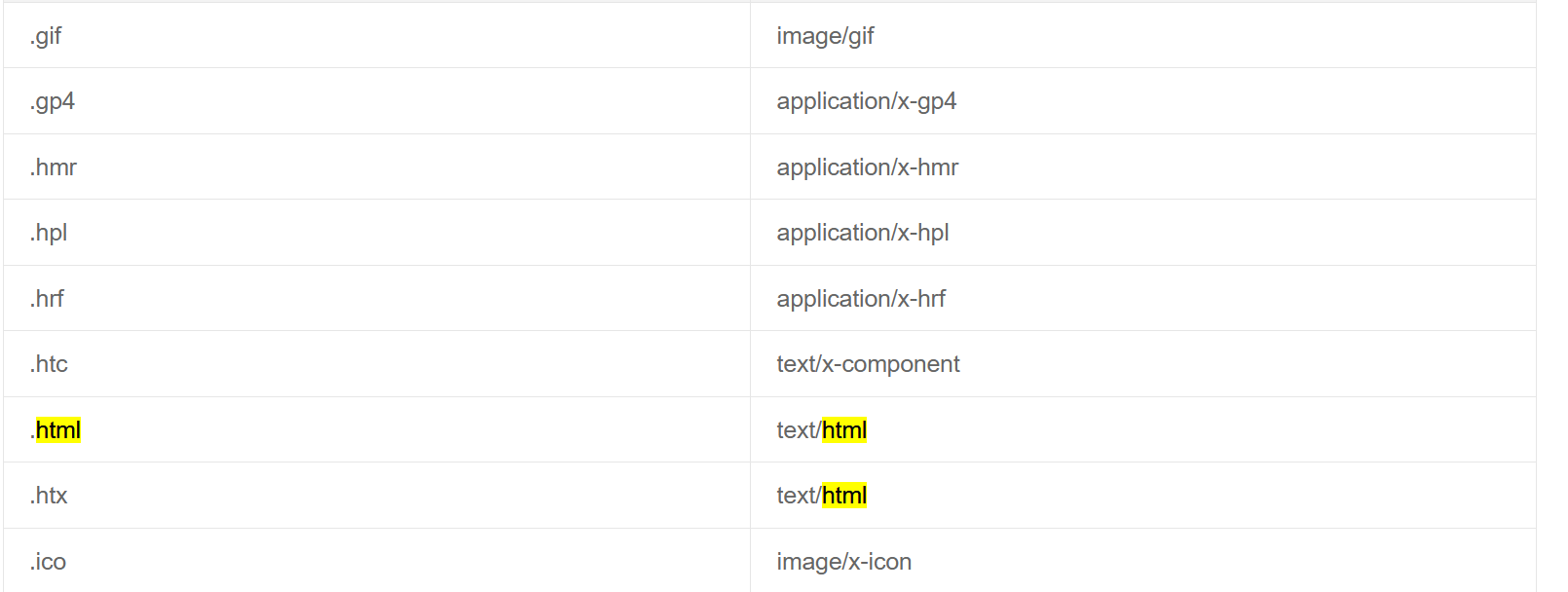
其中需要注意的是Content-Type數據類型,當服務器端給客戶端返回數據時,需要帶上這個屬性,告訴瀏覽器該怎么解釋(其實也可以不用帶了,因為現在的瀏覽器已經很強大了,可以解析出來)。關于Content-Type,有一張對照表:
鏈接:HTTP Content-type 對照表 | content type
比如如果正問部分為html格式,那么報頭中應該包含 Content-Type:text/html
2,GET方法?
- 方法部分需要配合代碼才好理解。這里我寫了一個簡單的http服務器(源碼在文章末尾),以該http服務器為例子來理解GET方法。
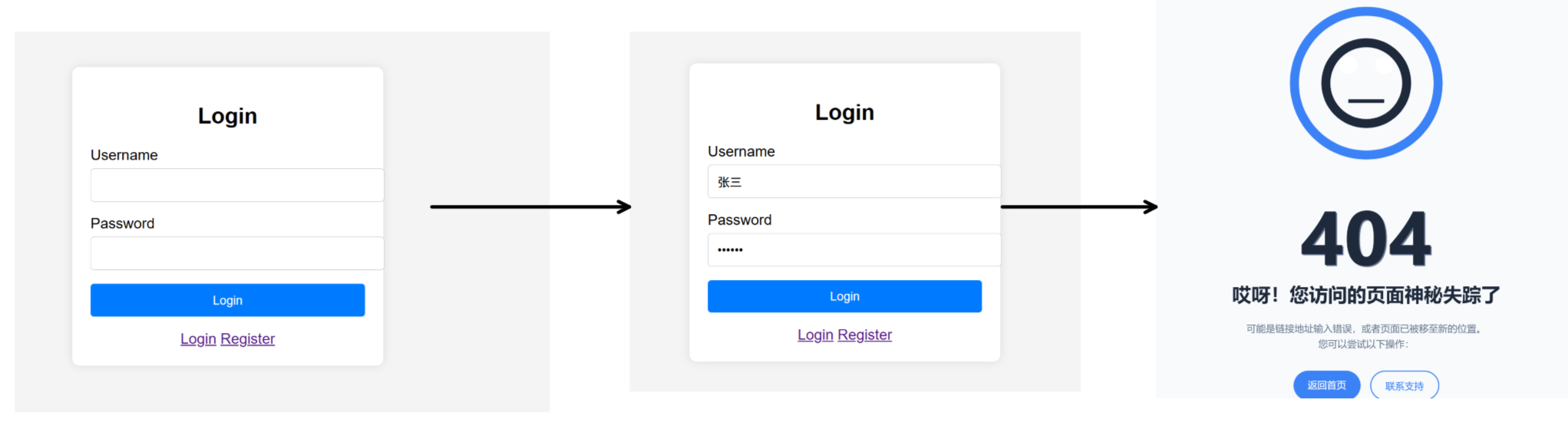
- 在服務器中設置了4個html網頁:首頁,登錄頁面,注冊頁面,404頁面。
- 其中首頁可以跳轉到登錄頁面和注冊頁面。
當我們想要進入登錄頁面,進行登陸時會出現如下問題:
此時的uri內容是:

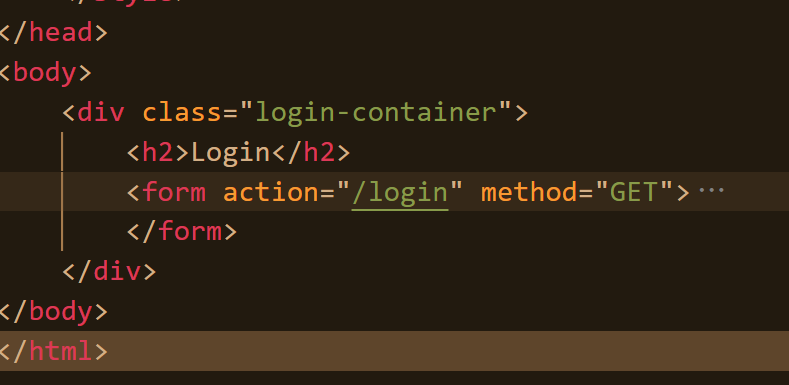
同時登錄頁面的html內容是:
 ?
?
可以得出結論:uri中?之前的部分表示http提供的服務,?之后的內容表示用戶輸入的參數。只不過現在我們的http服務器還沒有實現這個服務,所以最后會進入404頁面。
- ?之前我們訪問網頁都是在訪問呢靜態資源,圖片視頻什么的。而現在需要實現login服務,也就是讓我們的服務器實現動他交互的功能。
- 實現方法:在對瀏覽器發送過來的uri進行解析時,判斷是否帶有問號,如果帶有問號,表示需要進行動態交互,然后提取服務名(也就是問號之前的參數),再提取用戶上傳的參數(?之后的內容)
當我們實現好后,添加一個登錄的操作,這里只是簡單的將用戶輸入的數據以純文本的形式發送回去,將來我們繼續登陸后,不會訪問404頁面,而是收到同樣的數據,以文本的形式展示出來。
//實現login一個服務
void Login(HttpRequest& req,HttpResponse& resp)
{//構建resp的內容//這里直接將req的內容以純文本的形式發送回去std::string text="hello :"+req.Args();resp.setCode(200);resp.setHeader("Content-Type","text/plain");resp.setHeader("Content-Length",std::to_string(text.size()));resp.setText(text);
}
在http協議基礎之上,我們新增了一個Login服務,我們將來就可以使用域名+服務名來訪問對應的服務,這就相當于http給我們提供了一種微服務的接口。這種風格的網絡接口稱為RESTful風格的網絡接口。所以未來我們還可以新增各種服務接口。比如注冊接口,統計在線人數接口等等。
最后,其實我們早就知道了,GET方法的提參是通過uri提交的。?
3,POST方法
POST方法,我們看一段正文就可以知道了。
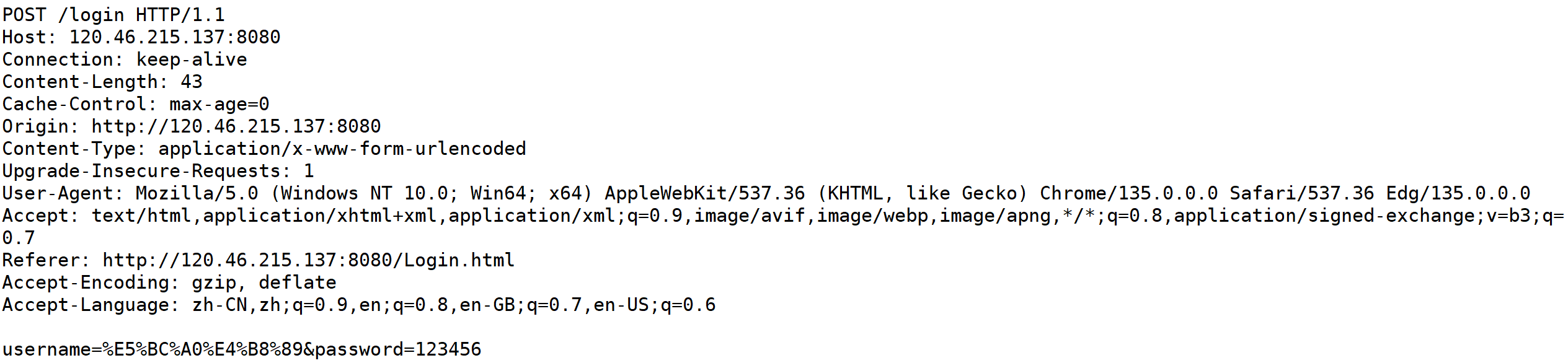
上面的報文是通過POST方法進行登錄,可以發現再提交參數的時候,是將參數增加到正文部分的?
4,總結
?GET方法:
- 獲取靜態資源或者網頁
- 提交參數,以uri形式提交
- GET提交參數一般不建議太長,因為uri長度是有限的
- GET傳參,參數是會顯示出來的。
POST方法:
- 提交參數,以正文部分參數
- 參數不會回顯,相對私密
不管是GET還是POST,都是明文傳送,可以抓取,是不安全的。
要做到真正的安全,必須要把報文進行加密,就要用到https協議。
三,cookie-session
1,cookie
HTTP協議是無連接,無狀態的協議,即每次請求都需要建立新的連接,且服務器不會保存客戶端的狀態信息。
- HTTP底層是基于tcp的,所謂無連接,是指HTTP不管通信部分,只負責接受請求和發送應答的事情,連接是底層tcp管理的。所以說HTTP是無連接的。
- 無狀態,是指當我們訪問服務器時,服務器不會記錄我們狀態的信息。比如我們訪問某個網頁一次,就給我返回該網頁一次。所以說是無狀態的。(但實際上,為了提高效率,當我們訪問一次后,瀏覽器會記錄數據,下次訪問時直接找瀏覽器拿即可)
有了上面的理解,看下面的一個例子:
如下圖所示,當我們項訪問某個網站資源時,需要登錄認證 。
- 第一次登錄認證成功后,會給我們返回網站首頁。
- 拿到網站首頁后,當我們想要訪問某個資源時,就需要再次進行登錄認證,因為HTTP是無狀態的,他不會記錄當前你這個用戶是否登錄過,所以需要再次登錄認證。
- 那么從今往后,你每訪問一個資源,就需要登錄認證一次,這對用戶的肯定不友好。
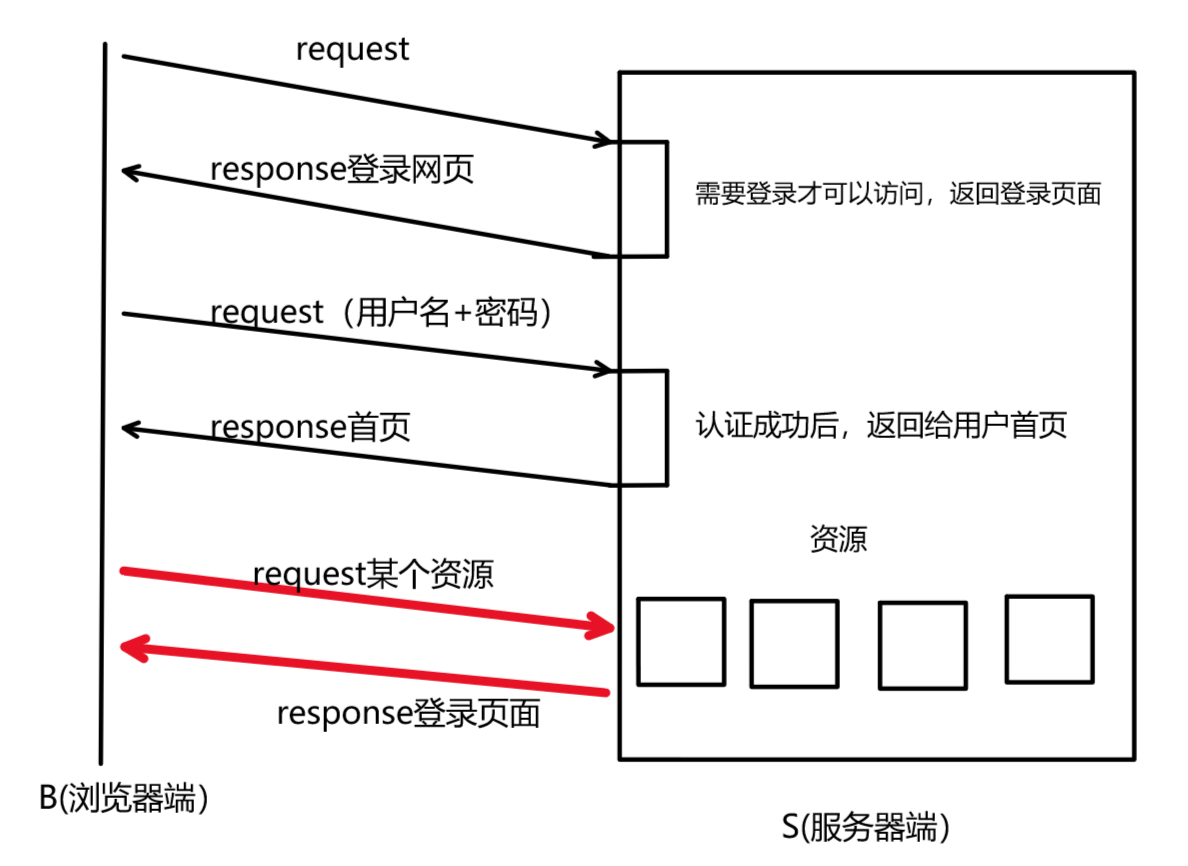
所以,為了解決上述問題,就引入了cookie功能。
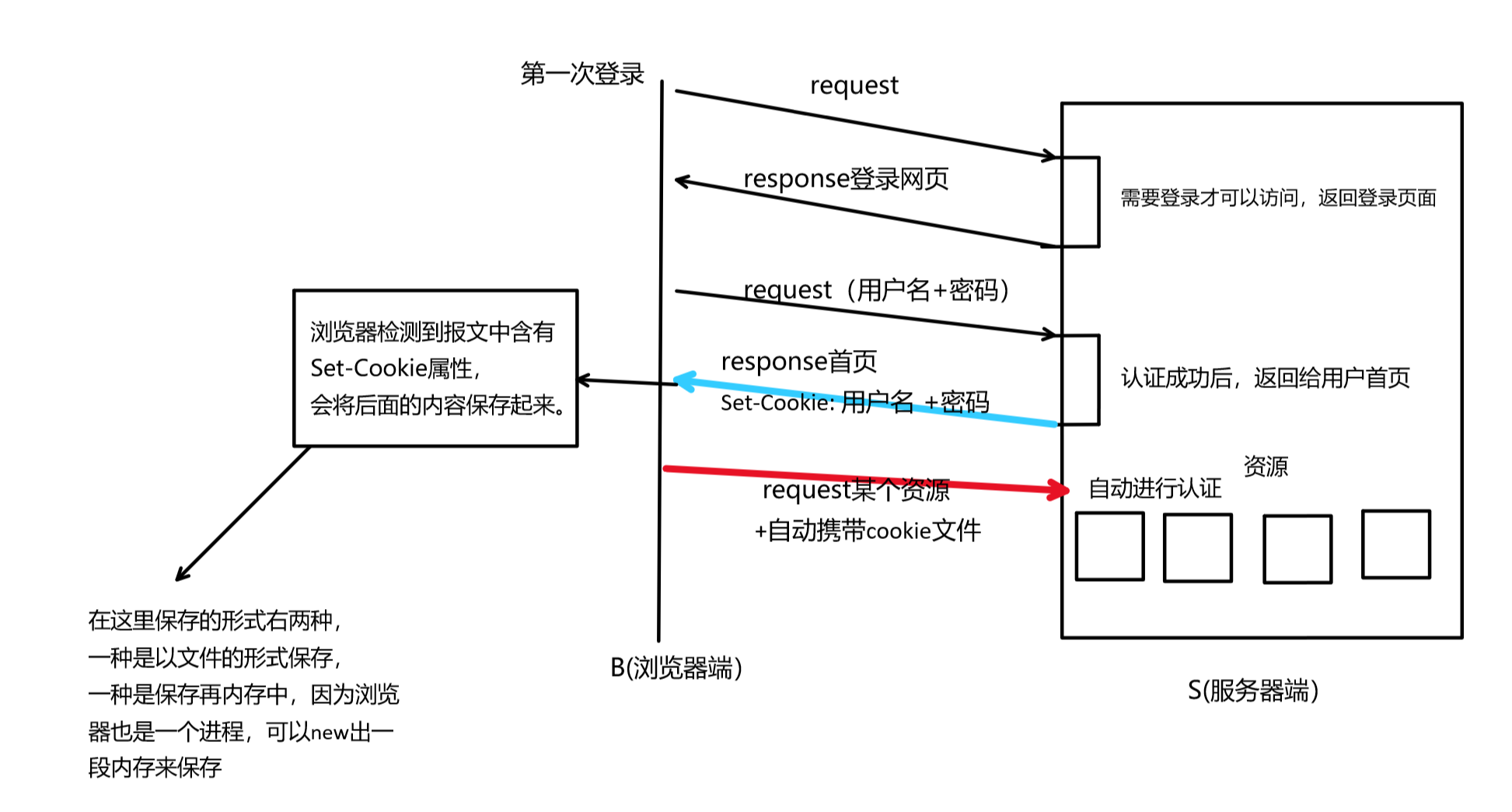
在進行完一次認證操作后,服務器返回應答,應答報文中會包含Set-Cookie屬性,記錄用戶輸入的內容。瀏覽器檢測到Set-Cookie屬性,會將該部分內容保存下來,形成一個cookie文件,下次訪問的時候直接攜帶該cookie文件,不需要再次認證了。
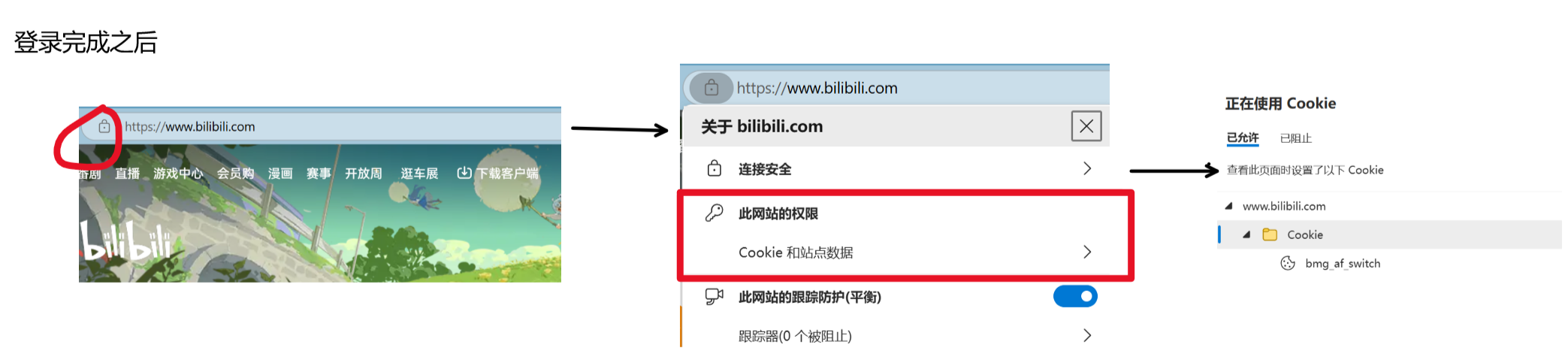
?驗證cookie的存在,以登錄bilibili為例:
?2,cookie問題
如果我們的電腦被植入了木馬程序,那么黑客就可以獲取到我們瀏覽器內的cookie文件。此時在他自己的電腦上訪問同樣的網站,使用我們的cookie,那么黑客就可以以我們的身份登錄,訪問服務器了。這樣我們的賬號就會被盜取,同時cookie中記錄的私密數據(用戶名,用戶密碼等等)也會泄漏。所以說,單純使用cookie是不安全的。
總結一下,會存在兩個問題:用戶的賬號丟失,用戶的私密信息泄漏。
為了一定程度的解決該問題,就引入了session。
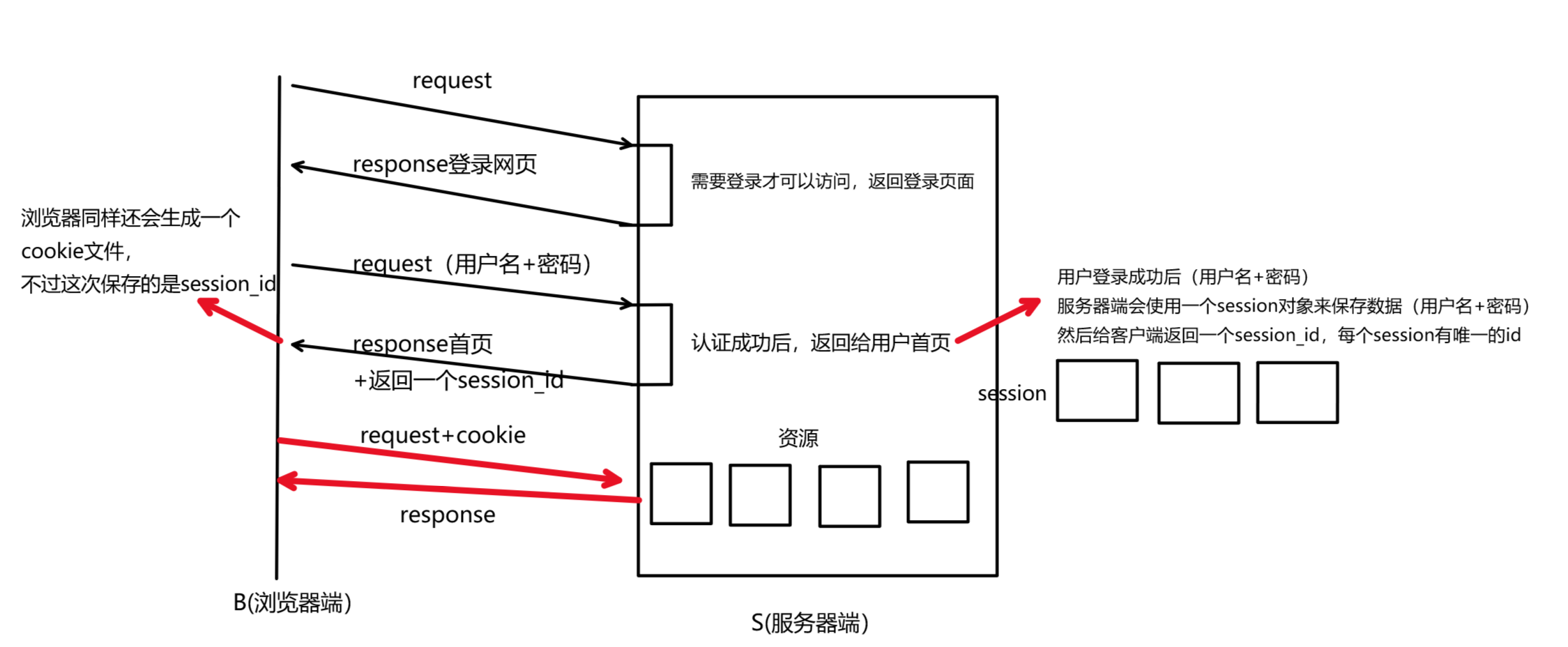
3,session
?為了一定程度的解決上述問題,就引入了session
- 當我們登錄認證成功后,我們輸入的數據(用戶名+密碼),服務器端會生成一個session對象,來保存我們的密碼和數據。然后給瀏覽器端返回一個session_id。下次訪問時,直接攜帶cookie,cookie中保存了session_id,服務器端檢查session_id是否存在即可。這樣將用戶的信息保存在服務器端,不保存在客戶端,就解決了用戶私密信息泄漏的問題。
- 而對于賬號丟失的問題,不能完全解決,只能采取一定的輔助方案,比如溯源ip,地址的變更等等。比如,上次登錄是在北京,5秒后再次登錄,ip變為云南了,此時服務器就會檢測到異常,將保存的session對象釋放掉,要求用戶重新登錄,重新輸入用戶名和密碼。就在一定程度上解決了這些問題。
?4,總結
cookie和session:是用來負責會話管理與會話保持的。是HTTP的附加功能,不嚴格屬于HTTP。
源碼
myhttp2 · 小鬼/linux學習 - 碼云 - 開源中國![]() https://gitee.com/wang-junyanxx/linux-learning/tree/master/myhttp2
https://gitee.com/wang-junyanxx/linux-learning/tree/master/myhttp2






![[STM32] 4-2 USART與串口通信(2)](http://pic.xiahunao.cn/[STM32] 4-2 USART與串口通信(2))



詳解)



 13980+真車 超跑 大型載具MOD整合包+最新GTA6大型地圖MOD 5月最新更新)



)
