最短路徑
先給出一些leetcode算法題,以后遇見了相關題目再往上增加
最短路徑的4個常用算法是Floyd、Bellman-Ford、SPFA、Dijkstra。不同應用場景下,應有選擇地使用它們:
- 圖的規模小,用Floyd。若邊的權值有負數,需要判斷負圈。
- 圖的規模大,且邊的權值非負,用Dijkstra。
- 圖的規模大,且邊的權值有負數,用SPFA,需要判斷負圈。
| 結點N、邊M | 邊權值 | 選用算法 | 數據結構 |
|---|---|---|---|
| n<200 | 允許有負 | Floyd | 鄰接矩陣 |
| n×m<107 | 允許有負 | Bellman-Ford | 鄰接表 |
| 更大 | 有負 | SPFA | 鄰接表、前向星 |
| 更大 | 無負數 | Dijkstra | 鄰接表、前向星 |
2.1、Floyd算法
- Floyed算法:主要是構建 二維矩陣:dp[i][j] 表示從節點 i 到節點 j 最短距離
- 初始化矩陣時:有方向性、并且同一節點的最短距離為0
// floyed 算法vector<vector<int>> dp(n + 1, vector<int>(n + 1, INT_MAX / 2));for (auto a : times) {dp[a[0]][a[1]] = a[2];}for (int i = 0; i <= n; i++) {dp[i][i] = 0;}for (int k = 0; k <= n; k++) for (int i = 0; i <= n; i++) for (int j = 0; j <= n; j++) if (dp[i][j] > dp[i][k] + dp[k][j]) dp[i][j] = dp[i][k] + dp[k][j];1、743. 網絡延遲時間
有 n 個網絡節點,標記為 1 到 n。
給你一個列表 times,表示信號經過 有向 邊的傳遞時間。 times[i] = (ui, vi, wi),其中 ui 是源節點,vi 是目標節點, wi 是一個信號從源節點傳遞到目標節點的時間。
現在,從某個節點 K 發出一個信號。需要多久才能使所有節點都收到信號?如果不能使所有節點收到信號,返回 -1 。
示例 1:
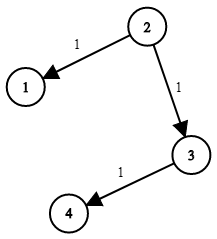
輸入:times = [[2,1,1],[2,3,1],[3,4,1]], n = 4, k = 2
輸出:2
示例 2:
輸入:times = [[1,2,1]], n = 2, k = 1
輸出:1
示例 3:
輸入:times = [[1,2,1]], n = 2, k = 2
輸出:-1
提示:
1 <= k <= n <= 1001 <= times.length <= 6000times[i].length == 31 <= ui, vi <= nui != vi0 <= wi <= 100- 所有
(ui, vi)對都 互不相同(即,不含重復邊)
// floyed 算法
class Solution {
public:int networkDelayTime(vector<vector<int>>& times, int n, int k) {vector<vector<int>> dp(n + 1, vector<int>(n + 1, INT_MAX / 2));for (auto a : times) {dp[a[0]][a[1]] = a[2];}for (int i = 0; i <= n; i++) {dp[i][i] = 0;}for (int k = 0; k <= n; k++) {for (int i = 0; i <= n; i++) {for (int j = 0; j <= n; j++) {if (dp[i][j] > dp[i][k] + dp[k][j]) {dp[i][j] = dp[i][k] + dp[k][j];}}}}int res = 0;for (int i = 1; i <= n; i++) {if (dp[k][i] == INT_MAX / 2)return -1;res = max(res, dp[k][i]);}return res;}
};
2、1334. 閾值距離內鄰居最少的城市
- 這個用floyed直接算即可。無向圖構造矩陣時重復操作即可
有 n 個城市,按從 0 到 n-1 編號。給你一個邊數組 edges,其中 edges[i] = [fromi, toi, weighti] 代表 fromi 和 toi 兩個城市之間的雙向加權邊,距離閾值是一個整數 distanceThreshold。
返回能通過某些路徑到達其他城市數目最少、且路徑距離 最大 為 distanceThreshold 的城市。如果有多個這樣的城市,則返回編號最大的城市。
注意,連接城市 i 和 j 的路徑的距離等于沿該路徑的所有邊的權重之和。
示例 1:
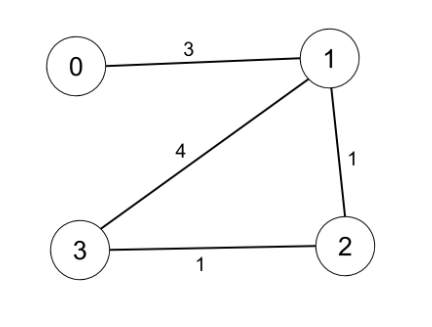
輸入:n = 4, edges = [[0,1,3],[1,2,1],[1,3,4],[2,3,1]], distanceThreshold = 4
輸出:3
解釋:城市分布圖如上。
每個城市閾值距離 distanceThreshold = 4 內的鄰居城市分別是:
城市 0 -> [城市 1, 城市 2]
城市 1 -> [城市 0, 城市 2, 城市 3]
城市 2 -> [城市 0, 城市 1, 城市 3]
城市 3 -> [城市 1, 城市 2]
城市 0 和 3 在閾值距離 4 以內都有 2 個鄰居城市,但是我們必須返回城市 3,因為它的編號最大。
示例 2:
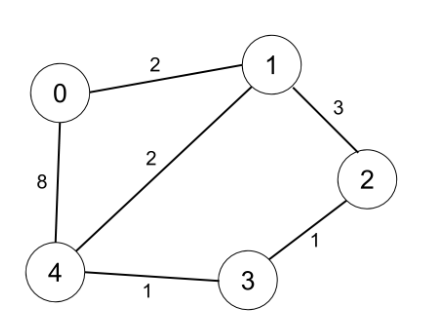
輸入:n = 5, edges = [[0,1,2],[0,4,8],[1,2,3],[1,4,2],[2,3,1],[3,4,1]], distanceThreshold = 2
輸出:0
解釋:城市分布圖如上。
每個城市閾值距離 distanceThreshold = 2 內的鄰居城市分別是:
城市 0 -> [城市 1]
城市 1 -> [城市 0, 城市 4]
城市 2 -> [城市 3, 城市 4]
城市 3 -> [城市 2, 城市 4]
城市 4 -> [城市 1, 城市 2, 城市 3]
城市 0 在閾值距離 2 以內只有 1 個鄰居城市。
class Solution {
public:int findTheCity(int n, vector<vector<int>>& edges, int distanceThreshold) {vector<vector<int>> dp(n, vector<int>(n, INT_MAX / 2));for (auto a : edges) {dp[a[0]][a[1]] = a[2];dp[a[1]][a[0]] = a[2];}for (int k = 0; k < n; k++)for (int i = 0; i < n; i++)for (int j = 0; j < n; j++)if (dp[i][j] > dp[i][k] + dp[k][j])dp[i][j] = dp[i][k] + dp[k][j];// floyed計算完畢,取次數判斷即可vector<int> cnt(n, 0);for (int i = 0; i < n; i++) {for (int j = 0; j < n; j++) {if (i == j)continue;if (dp[i][j] <= distanceThreshold)cnt[i]++;}}int min = *min_element(cnt.begin(), cnt.end());int res;for (int i = n - 1; i >= 0; i--) {if (min == cnt[i]) {res = i;break;}}return res;}
};
2.2、BellmanFord算法
- Bellman-ford算法的思路也很簡單,直接就是兩層循環,內層循環所有邊,外層循環就是循環所有邊的次數。
- 時間復雜度是O(n*m)顯然不如dijkstra快
- 優點:它可以處理負權邊和負權環的情況。并且可以處理限制次數的問題。
// dp[j] 表示節點k到j的最短路徑:并且注意每次更新最短路徑,是在上一次的dp上更新:
// a[0] 表示起始節點;a[1] 表示最終節點;a[2]表示a[0]到a[1] 的距離大小。
// a[0]->a[1]距離為a[2]:所以每次更新的都是 dp[a[1]] ,但是需要上一次的整體的predp,來取a[0]節點的最短距離// 最標準的形式有前一個的最小距離的predp
int networkDelayTime(vector<vector<int>>& times, int n, int k) {vector<int> dp(n+1,INT_MAX/2);dp[k] = 0;bool flag;while(1){flag = true;vector<int> predp(dp);for(auto a:times){if(dp[a[1]] > predp[a[0]]+a[2]){flag = false;dp[a[1]] = predp[a[0]]+a[2];}}if(flag) break;}int res = *max_element(dp.begin()+1,dp.end());return res==INT_MAX/2?-1:res;}// 然而沒有predp也可以,省下來空間
int networkDelayTime(vector<vector<int>>& times, int n, int k) {vector<int> dp(n+1,INT_MAX/2);dp[k ] = 0;bool flag;while(1){flag = true;for(auto a:times){if(dp[a[1]] > dp[a[0]]+a[2]){flag = false;dp[a[1]] = dp[a[0]]+a[2];}}if(flag) break;}int res = *max_element(dp.begin()+1,dp.end());return res==INT_MAX/2?-1:res;
}
1、743. 網絡延遲時間
示例 1:
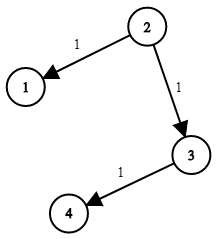
輸入:times = [[2,1,1],[2,3,1],[3,4,1]], n = 4, k = 2
輸出:2
// BellmanFord算法 算法復雜度為O(m*n)
class Solution {
public:int networkDelayTime(vector<vector<int>>& times, int n, int k) {vector<int> dp(n+1,INT_MAX/2);dp[k ] = 0;bool flag;while(1){flag = true;// vector<int> predp(dp);for(auto a:times){if(dp[a[1]] > dp[a[0]]+a[2]){flag = false;dp[a[1]] = dp[a[0]]+a[2];}}if(flag) break;}int res = *max_element(dp.begin()+1,dp.end());return res==INT_MAX/2?-1:res;}
};
2、787. K 站中轉內最便宜的航班
- 經典使用BellmanFord算法題目:最多經過
k站中轉的路線
有 n 個城市通過一些航班連接。給你一個數組 flights ,其中 flights[i] = [fromi, toi, pricei] ,表示該航班都從城市 fromi 開始,以價格 pricei 抵達 toi。
現在給定所有的城市和航班,以及出發城市 src 和目的地 dst,你的任務是找到出一條最多經過 k 站中轉的路線,使得從 src 到 dst 的 價格最便宜 ,并返回該價格。 如果不存在這樣的路線,則輸出 -1。
示例 1:
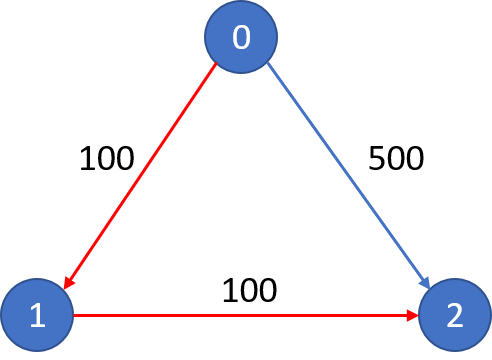
輸入:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 1
輸出: 200
解釋:
城市航班圖如下
從城市 0 到城市 2 在 1 站中轉以內的最便宜價格是 200,如圖中紅色所示。
示例 2:
輸入:
n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]]
src = 0, dst = 2, k = 0
輸出: 500
解釋:
城市航班圖如下
從城市 0 到城市 2 在 0 站中轉以內的最便宜價格是 500,圖中藍色所示。
提示:
1 <= n <= 1000 <= flights.length <= (n * (n - 1) / 2)flights[i].length == 30 <= fromi, toi < nfromi != toi1 <= pricei <= 104- 航班沒有重復,且不存在自環
0 <= src, dst, k < nsrc != dst
/*BellmanFord算法::外層的路徑就是中轉的次數,但是注意K++;是中轉1此,那么可以使用兩條路徑使用BellmanFord算法最標準形式:使用predp形式
*/
class Solution {
public:int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int k) {vector<int> dp(n, 1e5+1);dp[src] = 0;k++;while (k--) {vector<int> predp(dp);// 這里最好加&可以大大提高速度for (auto &a : flights) {if(dp[a[1]]>predp[a[0]]+a[2])dp[a[1]] =predp[a[0]]+a[2];}}return dp[dst] == 1e5+1? -1 : dp[dst];}
};
/*不使用BellmanFord算法最標準形式:無predp形式無法準確得到中轉次數:結果不對,但是不考慮次數的話,也能得到最短距離
*/// 結果不對
class Solution {
public:int findCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst,int k) {vector<int> dp(n, 1e5+1);dp[src] = 0;k++;while (k--) {// vector<int> predp(dp);for (auto &a : flights) {if(dp[a[1]]>dp[a[0]]+a[2])dp[a[1]] =dp[a[0]]+a[2];}}return dp[dst] == 1e5+1? -1 : dp[dst];}
};3、1514. 概率最大的路徑
- 本題重點是無向圖:兩邊都要操作一次,重復操作即可
- 無向圖:說白了就是條件是有向圖的兩倍,給反轉前后節點即可
給你一個由 n 個節點(下標從 0 開始)組成的無向加權圖,該圖由一個描述邊的列表組成,其中 edges[i] = [a, b] 表示連接節點 a 和 b 的一條無向邊,且該邊遍歷成功的概率為 succProb[i] 。
指定兩個節點分別作為起點 start 和終點 end ,請你找出從起點到終點成功概率最大的路徑,并返回其成功概率。
如果不存在從 start 到 end 的路徑,請 返回 0 。只要答案與標準答案的誤差不超過 1e-5 ,就會被視作正確答案。
示例 1:
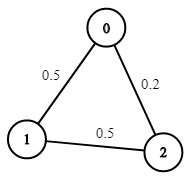
輸入:n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.2], start = 0, end = 2
輸出:0.25000
解釋:從起點到終點有兩條路徑,其中一條的成功概率為 0.2 ,而另一條為 0.5 * 0.5 = 0.25
示例 2:
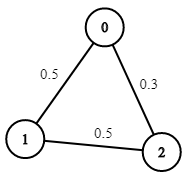
輸入:n = 3, edges = [[0,1],[1,2],[0,2]], succProb = [0.5,0.5,0.3], start = 0, end = 2
輸出:0.30000
示例 3:
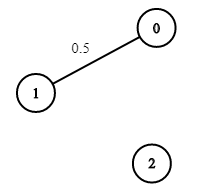
輸入:n = 3, edges = [[0,1]], succProb = [0.5], start = 0, end = 2
輸出:0.00000
解釋:節點 0 和 節點 2 之間不存在路徑
提示:
2 <= n <= 10^40 <= start, end < nstart != end0 <= a, b < na != b0 <= succProb.length == edges.length <= 2*10^40 <= succProb[i] <= 1- 每兩個節點之間最多有一條邊
class Solution {
public:double maxProbability(int n, vector<vector<int>>& edges,vector<double>& succProb, int start_node,int end_node) {vector<double> dp(n, 0);dp[start_node] = 1;while (1) {bool flag = true;for (int i = 0; i < succProb.size(); i++) {// 雙向圖:反轉前后再操作一次即可if (dp[edges[i][1]] < dp[edges[i][0]] * succProb[i]) {flag = false;dp[edges[i][1]] = dp[edges[i][0]] * succProb[i];}if (dp[edges[i][0]] < dp[edges[i][1]] * succProb[i]) {flag = false;dp[edges[i][0]] = dp[edges[i][1]] * succProb[i];}}if (flag) break;}return dp[end_node];}
};
3、1334. 閾值距離內鄰居最少的城市
- 這個用floyed直接算即可。使用bellmanFord可以做
有 n 個城市,按從 0 到 n-1 編號。給你一個邊數組 edges,其中 edges[i] = [fromi, toi, weighti] 代表 fromi 和 toi 兩個城市之間的雙向加權邊,距離閾值是一個整數 distanceThreshold。
返回能通過某些路徑到達其他城市數目最少、且路徑距離 最大 為 distanceThreshold 的城市。如果有多個這樣的城市,則返回編號最大的城市。
注意,連接城市 i 和 j 的路徑的距離等于沿該路徑的所有邊的權重之和。
示例 1:
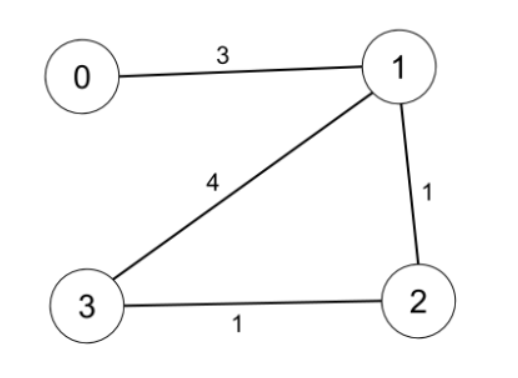
輸入:n = 4, edges = [[0,1,3],[1,2,1],[1,3,4],[2,3,1]], distanceThreshold = 4
輸出:3
解釋:城市分布圖如上。
每個城市閾值距離 distanceThreshold = 4 內的鄰居城市分別是:
城市 0 -> [城市 1, 城市 2]
城市 1 -> [城市 0, 城市 2, 城市 3]
城市 2 -> [城市 0, 城市 1, 城市 3]
城市 3 -> [城市 1, 城市 2]
城市 0 和 3 在閾值距離 4 以內都有 2 個鄰居城市,但是我們必須返回城市 3,因為它的編號最大。
示例 2:
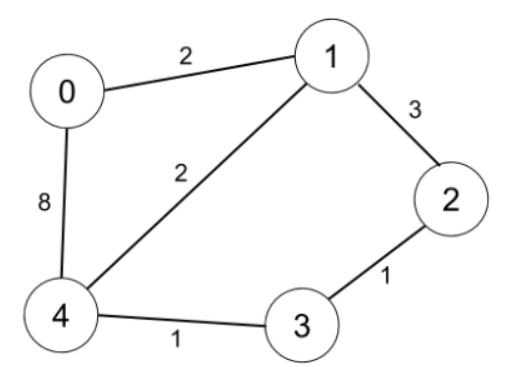
輸入:n = 5, edges = [[0,1,2],[0,4,8],[1,2,3],[1,4,2],[2,3,1],[3,4,1]], distanceThreshold = 2
輸出:0
解釋:城市分布圖如上。
每個城市閾值距離 distanceThreshold = 2 內的鄰居城市分別是:
城市 0 -> [城市 1]
城市 1 -> [城市 0, 城市 4]
城市 2 -> [城市 3, 城市 4]
城市 3 -> [城市 2, 城市 4]
城市 4 -> [城市 1, 城市 2, 城市 3]
城市 0 在閾值距離 2 以內只有 1 個鄰居城市。
class Solution {
public:int targetnum(int n, vector<vector<int>>& edges, int distanceThreshold,int k) {vector<int> dp(n, INT_MAX / 2);dp[k] = 0;while (1) {bool flag = true;vector<int> predp(dp);for (auto& a : edges) {if (dp[a[1]] > predp[a[0]] + a[2]) {flag = false;dp[a[1]] = predp[a[0]] + a[2];}if (dp[a[0]] > predp[a[1]] + a[2]) {flag = false;dp[a[0]] = predp[a[1]] + a[2];}}if (flag)break;}int res = 0;/*這里注意:這個是排除本身for (int i = 0; i < n; i++) {if (i == k)continue;if (dp[i] <= distanceThreshold) {res++;}}若改成:只要碰到i!=k,則跳出這個for循環,后面都不執行了for (int i = 0; i < n && i!=k; i++) {if (dp[i] <= distanceThreshold) {res++;}}*/for (int i = 0; i < n; i++) {if (i == k)continue;if (dp[i] <= distanceThreshold) {res++;}}return res;}// 找到最右邊的最小值及坐標。int findTheCity(int n, vector<vector<int>>& edges, int distanceThreshold) {int min_num = 200;int res = 0;for(int i = 0;i<n;i++){int mid = BellmabFord( n, edges, i, distanceThreshold);if(mid<=min_num){min_num = mid;res = i; }}return res;}// 直觀但臃腫。int findTheCity(int n, vector<vector<int>>& edges, int distanceThreshold) {int minn = INT_MAX / 2;vector<int> res;for (int i = 0; i < n; i++) {res.push_back(targetnum(n, edges, distanceThreshold, i));}int sul = 0;int minnub = *min_element(res.begin(), res.end());for (int i = n - 1; i >= 0; i--) {if (res[i] == minnub) {sul = i;break;}}return sul;}
};
2.3、dijkstra算法
- 基礎型:圖的規模大,且邊的權值非負,用Dijkstra。時間復雜度O(N*N)。可以看出時間復雜度 只和 n (節點數量)有關系。
// dijkstra算法基礎版/*基礎版:適用于題目中給出距離矩陣,給出矩陣
*/
vector<int> dijkstra(vector<vector<int>>& value, int start) {//需要一個二維矩陣從0到n,0基本上沒有用,無關的都是INT_MAX / 2//對角線為0//返回了一個value[i][j]表示從i到j的最短路徑,但是i,j不為0int len = value.size(); // len = n + 1;int n = len - 1;vector<int> res(len, INT_MAX);res[start] = 0;vector<bool> visit(len, false);for (int i = 1; i <= n; i++) {// 找到最小藍的位置int minbule = 0;for (int j = 1; j <= n; j++) {if (!visit[j] && res[minbule] > res[j]) {minbule = j;}}if(visited[blue]) continue;// 把最小藍變成白色visit[minbule] = true;// 更新所有最短距離for (int j = 1; j <= n; j++) {res[j] = min(res[j], res[minbule] + value[minbule][j]);}}return res;
}
- 堆優化型:使用邊數,邊數少的,堆優化比較好。時間復雜度:O(E * (N + logE)) E為邊的數量,N為節點數量。
- 適用條件:但 n 很大,邊 的數量 很小的時候(稀疏圖),是不是可以換成從邊的角度來求最短路呢?
int dijkstra_networkDelayTime2(vector<vector<int>>& times, int n, int k) {unordered_map<int, vector<pair<int, int > > > mp;for (auto a : times) {mp[a[0]].push_back({a[1], a[2]});}// 不一定要用map,使用vector效果一樣:只不過是保存a[0]點指向的節點和距離vector<vector<pair<int, int>>> g(n);for (auto &t : times) {int x = t[0] - 1, y = t[1] - 1;g[x].emplace_back(y, t[2]);}作者:力扣官方題解
鏈接:https://leetcode.cn/problems/network-delay-time/solutions/909575/wang-luo-yan-chi-shi-jian-by-leetcode-so-6phc/
來源:力扣(LeetCode)
著作權歸作者所有。商業轉載請聯系作者獲得授權,非商業轉載請注明出處。vector<int> dismin(n + 1, INT_MAX / 2);vector<bool> visited(n + 1, false);dismin[k] = 0;// 優先隊列<藍點的最短距離,藍點坐標>小頂堆priority_queue< pair<int, int>, vector<pair<int, int> >, greater<> > que;que.push({0, k});while (!que.empty()) {int minblue = que.top().second;que.pop();// 變成白點if (visited[minblue]) continue;visited[minblue] = true;// 增加這個白點會有什么影響對于 dismin// 遍歷所有與新白點連接的藍點for (pair<int, int > a : mp[minblue]) {if (!visited[a.first] && dismin[a.first] > a.second + dismin[minblue] ) {dismin[a.first] = a.second + dismin[minblue];que.push({dismin[a.first], a.first});}}}int res = *max_element(dismin.begin() + 1, dismin.end());return res == INT_MAX / 2 ? -1 : res;
}
-
時間復雜度:O(E * (N + logE)) E為邊的數量,N為節點數量
-
空間復雜度:O(log(N^2))
-
while (!pq.empty()) 時間復雜度為 E ,while 里面 每次取元素 時間復雜度 為 logE,和 一個for循環 時間復雜度 為 N 。所以整體是 E * (N + logE)
-
sort排序與大頂堆
- 優先隊列
- less<>表示從上到下是遞減的
- greater<>表示從上到下是遞增的
#include <bits/stdc.h> using namespace std;// priority_queue // less<>表示從上到下是遞減的 // greater<>表示從上到下是遞增的 // 默認 不加默認less<> 大頂堆就是less<> // 如果想要頭上最小需要加上greater<> void prio_int() {vector<int> strs = {5,8,2,6,1,8,2};priority_queue<int, vector<int>, less<>> que(strs.begin(),strs.end());while(que.empty()==0){cout<<que.top()<<endl;que.pop();}return; }// 優先隊列的自定義 // 優先隊列與傳統sort的相反 void prio_string() {vector<string> strs = {"xhh", "mmcy", "mi", "xhz", "abcdef"};struct cmp{bool operator()(string a,string b){return a.size()<b.size()||(a.size()==b.size() && a>b);}};priority_queue<string, vector<string>, cmp> que(strs.begin(),strs.end());while(que.empty()==0){cout<<que.top()<<endl;que.pop();}return; }// map自動排序,unordered_map 不排序,想排序直接用 // vector<pair<int,string>>來重新裝一下,再排序 void sort_map_int() {map<int, string> mp = {{1, "ab"}, {8, "zx"}, {5, "ac"}, {4, "ae"}};for (auto a : mp) {cout << a.first << "->" << a.second << endl;}return ; }// sort pair使用 a.first a.second // 類型使用auto肯定是對的,但是可能沒有提示first、second void sort_pair_int() {vector<pair<int, string>> test_vector = {{5, "abc"}, {1, "ac"}, {1, "ad"}, {2, "ac"}};sort(test_vector.begin(), test_vector.end(), [](auto a, auto b) {return (a.first > b.first || (a.first == b.first && a.second > b.second));});for (auto a : test_vector ) {cout << a.first << "->" << a.second << endl;}return ; }void sort_vector_int() {vector<int> test_vector = {5, 4, 9, 7};sort(test_vector.begin(), test_vector.end(), [](auto a, auto b) {return a > b;});for (auto a : test_vector ) {cout << a << " ";}cout << endl;return ; }void sort_vector_vector_int() {vector<vector<int>> test_vector = {{1, 2}, {9, 8}, {1, 3}, {8, 2}, {6, 5}};sort(test_vector.begin(), test_vector.end(), [](auto a, auto b) {return (a[0] < b[0] || (a[0] == b[0] && a[1] < b[1]));});for (auto a : test_vector ) {for (auto b : a) {cout << b << " ";}cout << endl;}return ; }int main() {sort_vector_int();cout << "****************" << endl;sort_vector_vector_int();cout << "****************" << endl;sort_pair_int();cout << "****************" << endl;sort_map_int();cout << "****************" << endl;prio_string();cout << "****************" << endl;prio_int(); }
1、743. 網絡延遲時間
有 n 個網絡節點,標記為 1 到 n。
給你一個列表 times,表示信號經過 有向 邊的傳遞時間。 times[i] = (ui, vi, wi),其中 ui 是源節點,vi 是目標節點, wi 是一個信號從源節點傳遞到目標節點的時間。
現在,從某個節點 K 發出一個信號。需要多久才能使所有節點都收到信號?如果不能使所有節點收到信號,返回 -1 。
示例 1:
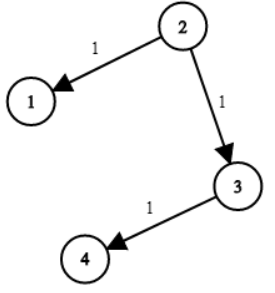
輸入:times = [[2,1,1],[2,3,1],[3,4,1]], n = 4, k = 2
輸出:2
示例 2:
輸入:times = [[1,2,1]], n = 2, k = 1
輸出:1
示例 3:
輸入:times = [[1,2,1]], n = 2, k = 2
輸出:-1
提示:
1 <= k <= n <= 1001 <= times.length <= 6000times[i].length == 31 <= ui, vi <= nui != vi0 <= wi <= 100- 所有
(ui, vi)對都 互不相同(即,不含重復邊)
/*普通版本
*/class Solution {
public:int networkDelayTime(vector<vector<int>>& times, int n, int k) {vector<int> dp(n + 1, INT_MAX / 2);dp[k] = 0;vector<vector<int>> dis(n + 1, vector<int>(n + 1, INT_MAX / 2));for (auto& a : times) {dis[a[0]][a[1]] = a[2];}vector<int> visited(n + 1, false);//for(int i = 0;i<=n;i++){while(1) {int blue = 0;for (int i = 0; i <= n; i++) {if (!visited[i] && dp[blue] > dp[i]) {blue = i;}}// 再次遇到說明最小值就是0了,結束了if(visited[blue]) break;visited[blue] = true;for (int i = 0; i <= n; i++) {if (dp[i] > dp[blue] + dis[blue][i]) {dp[i] = dp[blue] + dis[blue][i];}}}int res = *max_element(dp.begin() + 1, dp.end());return res == INT_MAX / 2 ? -1 : res;}
};// 堆優化版本
class Solution {
public:int networkDelayTime(vector<vector<int>>& times, int n, int k) {priority_queue<pair<int, int>, vector<pair<int, int>>, greater<>> que;// que.push({k,0});que.push({0, k});vector<bool> visited(n + 1, false);vector<int> dp(n + 1, INT_MAX / 2);dp[k] = 0;while (!que.empty()) {auto blue = que.top();que.pop();// 這里不用想那么多:看見置true直接在前面加判斷if( visited[blue.second]) continue;visited[blue.second] = true;for (auto& a : times) {// 這里直接取頭節點不是這個blue的直接跳過,已經為白的直接跳過// 目的是為了取最小的藍if (a[0] != blue.second || visited[a[1]] )continue;if (dp[a[1]] > dp[blue.second] + a[2]) {dp[a[1]] = dp[blue.second] + a[2];que.push({dp[a[1]], a[1]});}}}int res = *max_element(dp.begin() + 1, dp.end());return res == INT_MAX / 2 ? -1 : res;}
};
2、1334. 閾值距離內鄰居最少的城市
- 直接使用堆優化:注意雙向圖即可
有 n 個城市,按從 0 到 n-1 編號。給你一個邊數組 edges,其中 edges[i] = [fromi, toi, weighti] 代表 fromi 和 toi 兩個城市之間的雙向加權邊,距離閾值是一個整數 distanceThreshold。
返回能通過某些路徑到達其他城市數目最少、且路徑距離 最大 為 distanceThreshold 的城市。如果有多個這樣的城市,則返回編號最大的城市。
注意,連接城市 i 和 j 的路徑的距離等于沿該路徑的所有邊的權重之和。
示例 1:
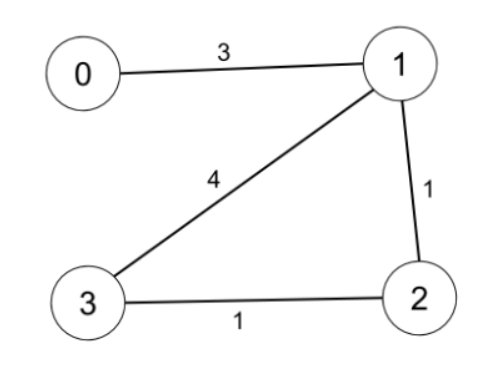
輸入:n = 4, edges = [[0,1,3],[1,2,1],[1,3,4],[2,3,1]], distanceThreshold = 4
輸出:3
解釋:城市分布圖如上。
每個城市閾值距離 distanceThreshold = 4 內的鄰居城市分別是:
城市 0 -> [城市 1, 城市 2]
城市 1 -> [城市 0, 城市 2, 城市 3]
城市 2 -> [城市 0, 城市 1, 城市 3]
城市 3 -> [城市 1, 城市 2]
城市 0 和 3 在閾值距離 4 以內都有 2 個鄰居城市,但是我們必須返回城市 3,因為它的編號最大。
示例 2:
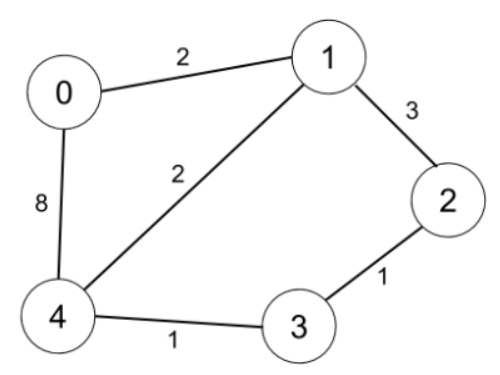
輸入:n = 5, edges = [[0,1,2],[0,4,8],[1,2,3],[1,4,2],[2,3,1],[3,4,1]], distanceThreshold = 2
輸出:0
解釋:城市分布圖如上。
每個城市閾值距離 distanceThreshold = 2 內的鄰居城市分別是:
城市 0 -> [城市 1]
城市 1 -> [城市 0, 城市 4]
城市 2 -> [城市 3, 城市 4]
城市 3 -> [城市 2, 城市 4]
城市 4 -> [城市 1, 城市 2, 城市 3]
城市 0 在閾值距離 2 以內只有 1 個鄰居城市。
/*無向圖的堆優化djikstra算法:
*/
class Solution {
public:int target(int n, vector<vector<int>>& edges, int distanceThreshold,int k) {priority_queue<pair<int, int>, vector<pair<int, int>>, greater<>> que;que.push({0, k});vector<int> dis(n, INT_MAX / 2);dis[k] = 0;vector<bool> visited(n, false);while (!que.empty()) {int blue = que.top().second;que.pop();if (visited[blue])continue;visited[blue] = true;for (auto& a : edges) {if (a[0]==blue && dis[a[1]] > dis[a[0]] + a[2]) {dis[a[1]] = dis[a[0]] + a[2];que.push({dis[a[1]], a[1]});}if (a[1]==blue && dis[a[0]] > dis[a[1]] + a[2]) {dis[a[0]] = dis[a[1]] + a[2];que.push({dis[a[0]], a[0]});}}}int res = 0;for (auto& a : dis) {if (a <= distanceThreshold)res++;}return res;}int findTheCity(int n, vector<vector<int>>& edges, int distanceThreshold) {int res = INT_MAX / 2;int resdex = 0;for (int i = 0; i < n; i++) {int mid = target(n, edges, distanceThreshold, i);if (mid <= res) {res = mid;resdex = i;}}return resdex;}
};
![[android]MT6835 Android 關閉selinux方法](http://pic.xiahunao.cn/[android]MT6835 Android 關閉selinux方法)







![[STM32] 4-2 USART與串口通信(2)](http://pic.xiahunao.cn/[STM32] 4-2 USART與串口通信(2))



詳解)



 13980+真車 超跑 大型載具MOD整合包+最新GTA6大型地圖MOD 5月最新更新)


