摘要:大型語言模型(LLMs)已經展現出非凡的能力,尤其是最近在推理方面的進步,如o1和o3,推動了人工智能的發展。盡管在數學和編碼方面取得了令人印象深刻的成就,但在需要密碼學專業知識的領域,LLMs的推理能力仍然有待探索。 在本文中,我們介紹了CipherBank,這是一個全面的基準,旨在評估LLM在密碼解密任務中的推理能力。 CipherBank由2358個精心設計的問題組成,涵蓋了5個域和14個子域中的262個獨特的明文,重點關注需要加密的隱私敏感和現實場景。 從密碼學的角度來看,CipherBank采用了3大類加密方法,涵蓋9種不同的算法,從經典密碼到定制加密技術。 我們在CipherBank上評估了最先進的LLM,例如GPT-4o、DeepSeek-V3和以推理為重點的尖端模型,如o1和DeepSeek-R1。 我們的研究結果顯示,不僅在通用聊天LLM和以推理為重點的LLM之間,而且在當前以推理為重點的模型應用于經典密碼解密任務時的性能方面,推理能力都存在顯著差距,突顯了這些模型在理解和操縱加密數據方面面臨的挑戰。 通過詳細的分析和錯誤調查,我們提供了幾個關鍵的觀察結果,揭示了密碼推理中LLM的局限性和潛在的改進領域。 這些發現強調了LLM推理能力不斷進步的必要性。Huggingface鏈接:Paper page,論文鏈接:2504.19093
研究背景和目的
研究背景
隨著大型語言模型(LLMs)的迅速發展,它們在自然語言處理(NLP)領域的各項任務中展現出了前所未有的能力。特別是在理解和生成人類語言方面,LLMs已經取得了顯著的突破。然而,盡管LLMs在數學、編碼等邏輯和計算密集型任務上表現出色,它們在處理需要特定領域專業知識的任務時仍面臨挑戰。特別是在密碼學領域,由于加密和解密過程涉及復雜的算法和邏輯推理,傳統上被視為是計算機科學和數學領域的難題。隨著數字時代的到來,密碼學在保護信息安全方面發揮著至關重要的作用,而LLMs在密碼學推理能力上的表現卻鮮有研究。
密碼學不僅要求模型具備識別和理解加密模式的能力,還需要能夠準確推斷出解密密鑰并應用相應的解密算法。這種能力對于開發能夠處理涉及加密信息的現實世界應用至關重要,如隱私保護通信、安全身份驗證和數據完整性驗證等。然而,現有的LLM基準測試主要集中在數學、邏輯推理和編碼能力上,缺乏對密碼學推理能力的全面評估。
研究目的
本文旨在填補這一研究空白,通過引入CipherBank這一綜合基準測試,全面評估LLMs在密碼解密任務中的推理能力。CipherBank旨在模擬現實世界中需要加密的場景,通過提供一系列精心設計的密碼問題,挑戰LLMs在解密過程中的模式識別、算法反向工程和上下文安全約束理解等關鍵能力。通過這一基準測試,本文希望揭示當前LLMs在密碼學推理方面的局限性,并為未來的模型改進提供指導。
研究方法
CipherBank基準測試構建
CipherBank基準測試由2358個密碼問題組成,這些問題基于262個獨特的明文,涵蓋了5個域(如個人隱私數據、企業敏感數據、公共安全數據、金融資產數據和互聯網記錄)和14個子域(如身份信息、健康信息、商業信息等)。為了確保基準測試的實用性和現實性,CipherBank采用了多種加密算法,包括替代密碼(如Rot13、Atbash、Polybius和Vigenère)、轉置密碼(如Reverse和SwapPairs)以及自定義混合算法。這些算法的難度級別從基礎到專家級不等,以確保測試能夠全面評估LLMs在不同復雜度下的解密能力。
模型評估與實驗設置
為了全面評估LLMs的密碼推理能力,本文選取了18種最先進的LLM模型進行實驗,包括開源聊天模型(如Mixtral-8x22B、Qwen2.5-72B-Instruct、Llama-3.1-70B-Instruct等)、閉源模型(如GPT-4o、Gemini-1.5-Pro、Claude-Sonnet-3.5等)和以推理為重點的模型(如QwQ-32B-Preview、DeepSeek-R1、o1等)。在評估過程中,本文采用了3-shot測試方法,即向模型提供三個明文-密文對作為示例,然后要求模型根據這些示例推斷出加密規則并解密新的密文。
為了量化模型的解密性能,本文采用了準確率作為主要評價指標,同時還計算了Levenshtein相似度以提供更細致的性能評估。準確率衡量的是模型正確解密的案例占總測試案例的比例,而Levenshtein相似度則通過計算解密輸出與原始明文之間的編輯距離來評估兩者之間的相似度。
研究結果
LLMs在密碼推理中的表現差異
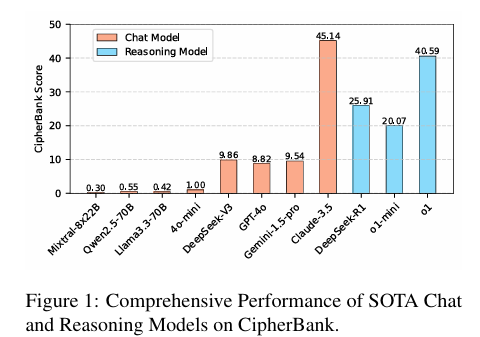
實驗結果顯示,不同類型的LLM在密碼解密任務中的表現存在顯著差異。以推理為重點的模型(如o1和DeepSeek-R1)在解密任務中普遍表現優于通用聊天模型(如GPT-4o和DeepSeek-V3)。然而,即使是表現最好的模型,在解密人類密碼分析師可以輕松解決的任務時,準確率也遠低于人類水平,這表明LLMs在密碼推理方面仍有很大的提升空間。
密碼類型和長度對解密性能的影響
本文還分析了密碼類型和明文長度對LLM解密性能的影響。結果顯示,隨著明文長度的增加,大多數模型的解密性能顯著下降。此外,不同類型的密碼對模型性能的影響也不同。例如,替代密碼通常比轉置密碼更容易被模型解密,而自定義混合算法則對模型提出了更高的挑戰。
錯誤分析
通過對解密錯誤的詳細分析,本文揭示了LLMs在密碼推理中的幾種常見錯誤類型,包括遺漏/插入錯誤、名稱解密錯誤、語義推斷錯誤、重組錯誤和推理失敗等。這些錯誤類型不僅反映了模型在密碼推理中的局限性,也為未來的模型改進提供了有價值的見解。
研究局限
盡管本文在評估LLMs的密碼推理能力方面取得了重要進展,但仍存在一些局限性。首先,由于閉源模型的訪問限制,本文只能通過API調用來評估這些模型,這可能引入潛在的可變性。其次,CipherBank主要關注經典加密算法,而現代加密技術可能引入更復雜的挑戰,這些挑戰超出了當前模型的能力范圍。因此,隨著加密技術的不斷發展,CipherBank需要不斷更新和擴展以涵蓋更廣泛的加密場景。
未來研究方向
基于本文的研究結果和發現,未來的研究可以從以下幾個方面展開:
-
增強LLMs的密碼推理能力:通過改進模型架構、訓練策略或引入額外的知識表示方法,增強LLMs在理解和解密加密信息方面的能力。
-
擴展CipherBank基準測試:隨著加密技術的不斷發展,CipherBank需要不斷更新和擴展以涵蓋更廣泛的加密場景和算法。此外,還可以引入更多的評價指標和測試方法來更全面地評估LLMs的密碼推理能力。
-
跨領域知識整合:探索如何將密碼學領域的專業知識與其他領域的知識相結合,以提高LLMs在解決跨領域問題時的綜合能力。例如,可以將密碼學知識與自然語言處理、邏輯推理和數學計算等領域的知識相結合,以開發更強大的多模態LLMs。
-
提高模型的魯棒性和可解釋性:通過引入魯棒性訓練和可解釋性技術,提高LLMs在處理復雜和不確定性任務時的穩定性和可解釋性。這將有助于增強用戶對LLMs的信任度并推動其在現實世界中的應用。
綜上所述,本文通過引入CipherBank基準測試,全面評估了LLMs在密碼解密任務中的推理能力,并揭示了當前模型在這一領域的局限性和未來的研究方向。隨著LLMs技術的不斷發展和完善,我們有理由相信它們將在更廣泛的領域中發揮更大的作用。

)
--TextField)




)



里使用iview的注意事項)




)

)
)