參考鏈接:
GitHub - ultralytics/yolov5: YOLOv5 🚀 in PyTorch > ONNX > CoreML > TFLite
TFLite,ONNX,CoreML,TensorRT Export -Ultralytics YOLO Docs
使用Neural Magic 的 DeepSparse 部署YOLOv5 -Ultralytics YOLO 文檔
sparseml/integrations/ultralytics-yolov5/tutorials/sparse-transfer-learning.md at main · neuralmagic/sparseml · GitHub
一、轉化格式加速推理
1.YOLOv5 正式支持 12 種格式的推理:
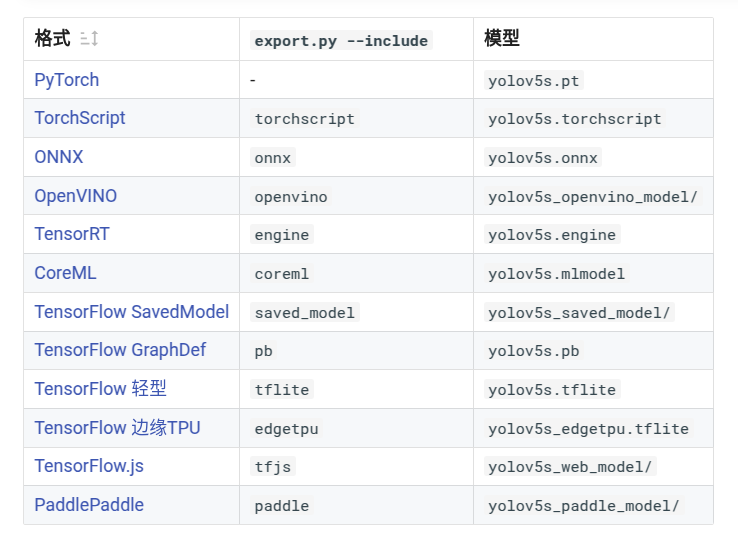
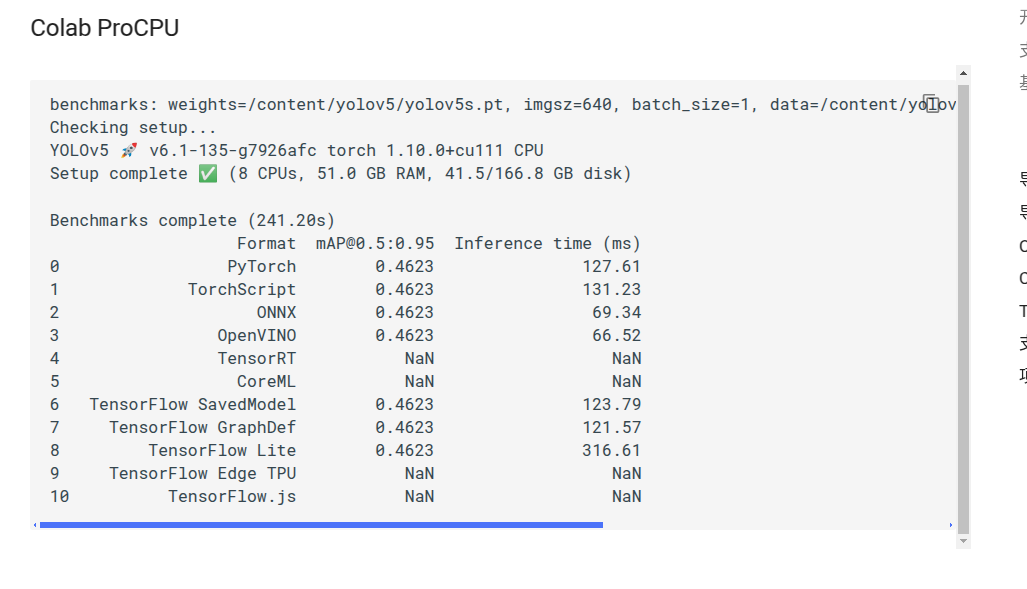
2.導出訓練有素的YOLOv5 模型
將自己訓練好的模型文件如yolov5s.pt導出為torchscript onnx。經過我的測試onnx和openvino是最快的。
python export.py --weights yolov5s.pt --include torchscript onnx3.導出后使用示例
二、使用DeepSparse + onnx加速推理
1.安裝 DeepSparse
pip install "deepsparse[server,yolo,onnxruntime]"2.Python 應用程序接口
將model_path替換為自己的onnx模型所在的位置。
import cv2
import time
from deepsparse import Pipeline# 視頻文件路徑,需替換為你的實際視頻路徑
video_path = "/home/yzh/yolo_v5/yolov5/2.mp4"
cap = cv2.VideoCapture(video_path)# create Pipeline
# 使用自定義 ONNX 模型路徑
# model_path = "/home/yzh/yolo_v5/yolov5/runs/train/exp6/weights/best_1.onnx"
model_path = "/home/yzh/yolo_v5/yolov5/yolov5_runs/train/exp6/DeepSparse_Deployment/model.onnx"yolo_pipeline = Pipeline.create(task="yolo",model_path=model_path,# image_size=(320, 320), # 輸入圖像大小# batch_size=32, # 批處理大小
)prev_time = 0
# 初始化總推理時間和總推理次數
total_inference_time = 0
total_inference_count = 0while cap.isOpened():ret, frame = cap.read()if not ret:break# 將 BGR 格式的 OpenCV 圖像轉換為 RGB 格式rgb_frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)# 執行推理start_time = time.time()pipeline_outputs = yolo_pipeline(images=[rgb_frame], iou_thres=0.6, conf_thres=0.2)end_time = time.time()inference_time = (end_time - start_time) * 1000print(f"推理時間: {inference_time:.2f} ms")# 更新總推理時間和總推理次數total_inference_time += inference_timetotal_inference_count += 1# 計算實時平均推理速度average_inference_speed = total_inference_time / total_inference_countprint(f"實時平均推理速度: {average_inference_speed:.2f} ms")# 獲取檢測結果boxes = pipeline_outputs.boxes[0] # 假設只有一個圖像輸入scores = pipeline_outputs.scores[0]labels = pipeline_outputs.labels[0]# 繪制邊界框和標簽for box, score, label in zip(boxes, scores, labels):x1, y1, x2, y2 = map(int, box)confidence = float(score)class_id = int(label)# 繪制邊界框cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)# 繪制標簽和置信度label_text = f"{class_id}: {confidence:.2f}"cv2.putText(frame, label_text, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)# 計算 FPSfps = 1 / (end_time - start_time)prev_time = end_time# 在幀上繪制 FPScv2.putText(frame, f"FPS: {fps:.2f}", (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)# 顯示幀cv2.imshow('Video Inference', frame)# 按 'q' 鍵退出循環if cv2.waitKey(1) & 0xFF == ord('q'):break# 釋放資源
cap.release()
cv2.destroyAllWindows()
之后直接運行這個腳本那文件,就可以使用DeepSparse加速了。加速效果明顯,大概1.5倍。
三、DeepSparse 稀疏性能
文檔上介紹效率很高,但是我實際使用感覺除了模型變小了一點,其他沒有什么太大區別。
1.安裝python庫文件
pip install "sparseml[yolov5]"2.開始訓練
(1)語法

(2)一個例子
recipe_type 這個是稀疏化的配置直接從官網下,weights這個稀疏化權重也是直接從官網下,你只需要把--data改成自己的數據集的配置文件就可以了。如果太卡,還要改--batchsize。
sparseml.yolov5.train \--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none?recipe_type=transfer_learn \--recipe zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned75_quant-none?recipe_type=transfer_learn \--data VOC.yaml \--patience 0 \--cfg yolov5s.yaml \--hyp hyps/hyp.finetune.yaml3.導出模型
sparseml.yolov5.export_onnx \--weights yolov5_runs/train/exp/weights/last.pt \--dynamic模型導出后,將onnx的路徑加到上述二的腳本文件里面,直接運行。但是確實效率沒提升多少,onnx的規模確實是下降了。

)
)












:C 語言強制類型轉換詳解)


 吳恩達版提示詞工程 6. 轉換 (翻譯,通用翻譯,語氣風格變換,文本格式轉換,拼寫檢查和語法檢查))
