參考:如何讓機器讀懂圖片上的文字?飛槳助您快速了解OCR - 知乎
OCR(Optical Character Recognition),譯為光學字符識別,是指通過掃描等光學輸入方式將各種票據、報刊、書籍、文稿及其它印刷品的文字轉化為圖像信息,再利用文字識別技術將圖像信息轉化為可以使用的計算機輸入技術。
OCR技術的應用場景非常廣泛:
(1)拍照/截圖識別
使用OCR技術,實現拍照文字識別、相冊圖片文字識別和截圖文字識別,可應用于搜索、書摘、筆記、翻譯等移動應用中,方便用戶進行文本的提取或錄入,有效提升產品易用性和用戶使用體驗。
(2)內容審核與監管
(3)視頻內容分析
(4)紙質文檔電子化
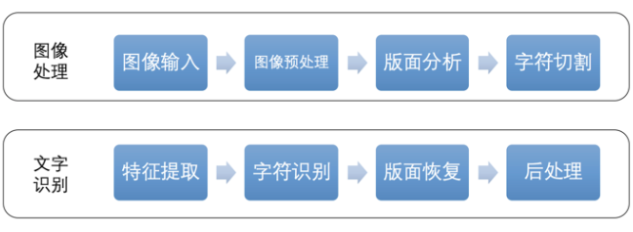
OCR技術原理
圖像處理階段:包含圖像輸入、圖像預處理、版面分析、字符切割等子步驟。
文字識別階段:包含特征提取、字符識別、版面恢復、后處理等子步驟。
?
【文本檢測】
圖像輸入:讀取不同格式的圖像文件。
圖像預處理:包含灰度化、二值化、圖像降噪、傾斜矯正等預處理步驟。
版面分析:針對左右兩欄等特殊排版,進行版面分析并劃分段落。
字符切割:對圖像中的文本進行字符級的切割,尤其注意字符粘連等問題。
【文本識別】
特征提取:對字符圖像提取關鍵特征并降維,用于后續的字符識別算法。
字符識別:依據特征向量,基于模版匹配分類法或深度神經網絡分類法,識別出字符。
版面恢復:識別原文檔的排版,按照原排版的格式將識別結果輸出。
后處理:引入語言模型或人工檢查,修正“分”和“兮”等形近字。
參考:OCR二次開發寶典:飛槳聯合多家企業和高校發布《OCR產業范例20講》 - 知乎
基于PaddleOCR完成一個范例的完整流程一般包含數據準備、模型訓練、推理部署三個部分,具體來說:
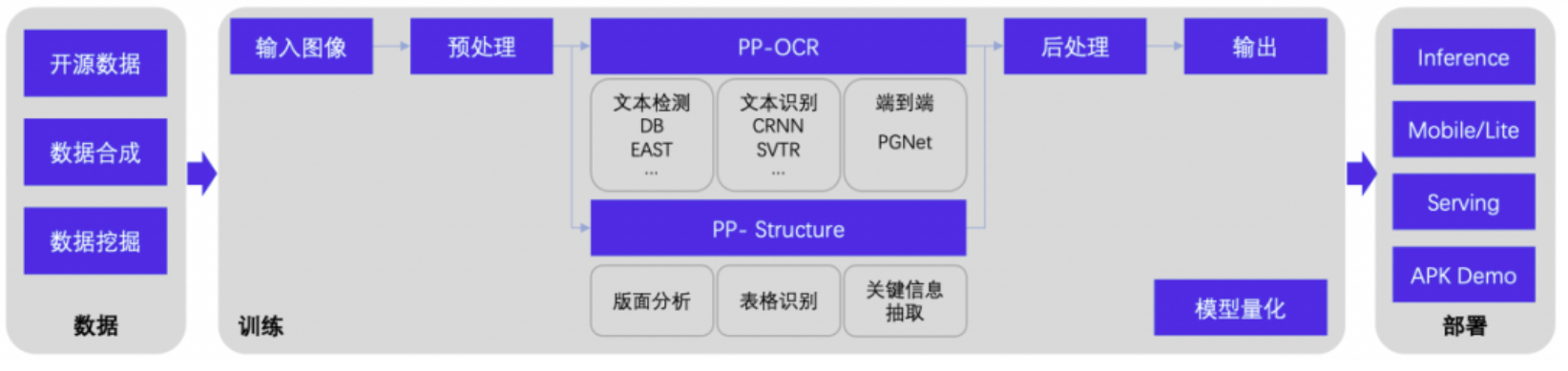
模型訓練
PP-OCR和PP-Structure系列模型都使用了大量訓練數據,在通用場景可以一定程度地保證精度和泛化性,因此一般建議基于飛槳PP系列模型進行模型微調(finetune),從而實現使用較少的業務數據達到預期效果。基于不同場景業務數據訓練的模型,有時需要針對前后處理進行任務適配,往往能進一步提升整體效果,偶爾甚至有“奇效”。如車牌識別范例中,通過后處理優化特殊符號的識別結果,大幅提升了整體識別精度。
銀行回單是企業財務記賬的重要原始憑證之一。目前是由財務人員進行人工讀取,提取賬單中的收付款人、流水單號、金額等關鍵信息,結合財務記賬規則進行處理,加工成記賬憑證、資產負債表、開具發票。針對該場景,本范例基于PP-Structure訓練命名實體識別、關系抽取模型并基于Hub Serving完成關鍵信息抽取的服務化部署,實現代替記賬公司實現自動化記賬報稅功能。
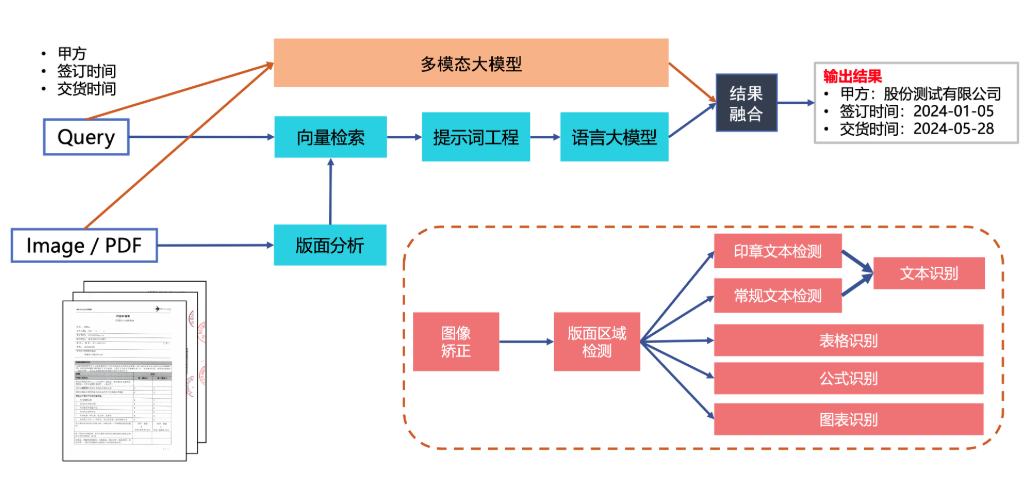
文檔場景信息抽取v4產線 - PaddleX 文檔
通用OCR產線 - PaddleX 文檔
OCR(光學字符識別,Optical Character Recognition)是一種將圖像中的文字轉換為可編輯文本的技術。它廣泛應用于文檔數字化、信息提取和數據處理等領域。OCR 可以識別印刷文本、手寫文本,甚至某些類型的字體和符號。
通用 OCR 產線用于解決文字識別任務,提取圖片中的文字信息以文本形式輸出,本產線集成了業界知名的 PP-OCRv3 和 PP-OCRv4 的端到端 OCR 串聯系統,支持超過 80 種語言的識別,并在此基礎上,增加了對圖像的方向矯正和扭曲矯正功能。基于本產線,可實現 CPU 上毫秒級的文本內容精準預測,使用場景覆蓋通用、制造、金融、交通等各個領域。本產線同時提供了靈活的服務化部署方式,支持在多種硬件上使用多種編程語言調用。不僅如此,本產線也提供了二次開發的能力,您可以基于本產線在您自己的數據集上訓練調優,訓練后的模型也可以無縫集成。
通用OCR產線中包含必選的文本檢測模塊和文本識別模塊,以及可選的文檔圖像方向分類模塊、文本圖像矯正模塊和文本行方向分類模塊。其中,文檔圖像方向分類模塊和文本圖像矯正模塊作為文檔預處理子產線被集成到通用OCR產線中。
如果您更注重模型的精度,請選擇精度較高的模型;如果您更在意模型的推理速度,請選擇推理速度較快的模型;如果您關注模型的存儲大小,請選擇存儲體積較小的模型。




:從設計模式到實戰應用)

)








估計算法原理以及相具體的應用實例附C++代碼示例)



