文章目錄
- 引論
- 數據庫用戶
- Casual users
- Naive users
- Application programmers
- Database administrators
- 關系模型
- CAP數據庫
- 兩種描述關系數據庫的方式
- 簡單總結
- 第一范式規則
- 第二范式規則
- 舉個例子
- 符合第二規則的操作
- 不符合第二規則的操作
- 第三范式規則
- key,superkey,null values,主鍵,候選鍵
- 1. 什么是Keys(鍵)?
- 2. 什么是Superkeys(超鍵)?
- 3. 什么是Null Values(空值)?
- 4. 什么是主鍵(Primary Key)?
- 5. 什么是候選鍵?
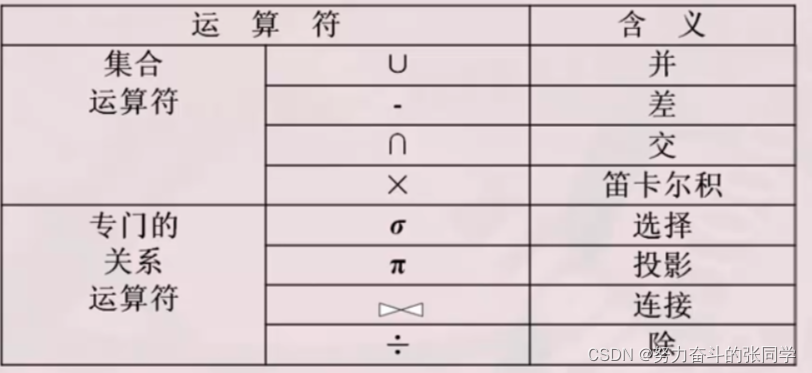
- 集合運算
- 1. **并(Union)**
- 2. **交(Intersection)**
- 3. **差(Difference)**
- 4. **笛卡爾積(Cartesian Product)**
- 5. **投影(Projection)**
- 6. **選擇(Selection)**
- 7. **自然連接(Natural Join)**
- 8. **除(Division)**
- sql語言查詢
- DDL
- 1. **主要功能**
- 2. **常見 DDL 語句**
- (1) **CREATE** - 創建數據庫對象
- (2) **ALTER** - 修改數據庫對象
- (3) **DROP** - 刪除數據庫對象
- (4) **TRUNCATE** - 清空表數據
- 3. **特點**
- 數據類型
- 實體完整性規則和參照完整性規則
- 1. **實體完整性規則**(Entity Integrity Rule)
- 2. **參照完整性規則**(Referential Integrity Rule)
- 相關語句
- count
- sum
- avg
- max,min
- group by
- 需求:只看人數大于 1 的班級
- order by
- into
- in
- 相關子查詢
- 子查詢比較關鍵詞
- join
- **INNER JOIN**(默認 JOIN)
- **LEFT JOIN**(LEFT OUTER JOIN)
- **RIGHT JOIN**(RIGHT OUTER JOIN)
- **FULL JOIN**(FULL OUTER JOIN)
- **CROSS JOIN**(交叉連接)
- exists
- union
- INTERSECT 運算符
- EXCEPT運算符
- 聯接查詢
- 等值聯接
- 自然聯接
- 非等值連接
- 自身連接
- 外聯接
- 復合條件聯接
- update
- delete
- 索引
- 唯一索引 (Unique Index)
- 聚集索引(CLUSTERED INDEX)
- 非簇索引 (Nonclustered Index)
- 存儲程序和觸發器
- 存儲過程
- 啥是 Stored Procedure(存儲過程)?
- 觸發器
- 啥是觸發器?
- 觸發器的類型
- 啥是 inserted 和 deleted 表?
- 它們在啥時候有數據?
- 數據庫設計
- 數據庫設計是啥?
- 概念模型設計(基于 E-R 圖)
- 范式設計(基于規范化理論)
- 啥是依賴?
- ER相關概念
- 單值 (Single-Valued) 和 多值 (Multi-Valued)
- 對方實體 (Other Entity)
- max-card(E, R)(最大基數)
- min-card(E, R)(最小基數)
- 二元關系轉換
- 弱實體
- 啥是弱實體?
- 啥是泛化層次結構?
- 約束條件
- 函數依賴
- 先復習:啥是函數依賴?
- Armstrong 公理(三大基本規則)
- (1) 自反律 (Reflexivity Rule)
- (2) 增補律 (Augmentation Rule)
- (3) 傳遞律 (Transitivity Rule)
- (1) 并規則 (Union Rule)
- (2) 分解規則 (Decomposition Rule)
- (3) 偽傳遞律 (Pseudo-Transitivity Rule)
- 閉包 (Closure) 的概念
- 覆蓋和最小覆蓋
- 1. 啥是覆蓋 (Cover)?
- 2. 啥是最小覆蓋 (Minimal Cover)?
- 求最小覆蓋的步驟
- 步驟 1:分解右邊(單屬性化)
- 步驟 2:去掉冗余屬性(簡化左邊)
- 步驟 3:去掉冗余依賴
- 最終最小覆蓋:
- 再來個復雜點的例子
- 關系模式的分解
- 關系模式分解的兩個關鍵性質
- 1. 無損連接 (Lossless Join)
- 2. 依賴保持 (Dependency Preservation)
- 完整性約束,視圖,安全,系統目錄
- 完整性約束 (Integrity Constraints)
- 視圖 (Views)
- 安全 (Security)
- 數據庫安全的四個等級
- 1. 系統級安全 (System-Level Security)
- 2. 數據庫級安全 (Database-Level Security)
- 3. 對象級安全 (Object-Level Security)
- 數據級安全 (Data-Level Security)
- 系統目錄 (System Catalogs)
- 練習題
- 文件系統和DBMS的四個主要區別
- 解釋物理獨立性,以及它在數據庫系統中的重要性。
- 找出候選鍵
- 根據筆者的學習過程的記錄,如果你的學校所學內容與這些不符合,沒必要花大精力在上面。
引論
數據庫用戶
Casual users
臨時用戶,對sql語言有一定了解并能查詢
Naive users
本地用戶,通過菜單應用程序執行sql,無需sql語句
Application programmers
應用程序員,負責編寫本地用戶使用的程序
Database administrators
數據庫管理員,負責設計和維護數據庫的專業人員
工作包括:
- 創建數據庫
- 創建表格
- 執行幕后任務
- 頁面的物理布局
關系模型
CAP數據庫

兩種描述關系數據庫的方式
在關系型數據庫里,描述數據的方式有兩套術語,雖然說的是一回事,但名字聽起來有點不同:
- 第一套術語:表(Tables)、列(Columns)、行(Rows)
- 表(Tables):就像一張Excel表格,里面裝了一堆數據。比如“學生表”存了所有學生的信息。
- 列(Columns):表里的每一列,就像Excel的標題,比如“姓名”“學號”“年齡”,每列存一種信息。
- 行(Rows):表里的每一行,就是一條具體的數據記錄。比如“張偉, 001, 18”是一行,代表一個學生的信息。
- 第二套術語:關系(Relations)、元組(Tuples)、屬性(Attributes)
- 關系(Relations):其實就是“表”的學名。因為表里的數據是通過“關系”組織起來的,所以叫關系。跟“表”是一個意思。
- 元組(Tuples):就是“行”的學名。每行數據是一個完整的記錄,數學上叫“元組”。比如“張偉, 001, 18”就是一個元組。
- 屬性(Attributes):就是“列”的學名。每列表示數據的一個特性,數學上叫“屬性”。比如“姓名”“學號”就是屬性。
簡單總結
- 表 = 關系:都是指整個表格。
- 行 = 元組:都是指表格里的一條記錄。
- 列 = 屬性:都是指表格里的一個字段(標題)。
第一范式規則
第一范式是關系型數據庫的一個基本規則,它要求表的每一列(字段)里的數據必須是單一的、不可再分的原子值。換句話說:
- 不能在一列里塞多個值(比如一個格子里放一堆東西)。
- 不能讓一列的值有復雜的內部結構(比如嵌套一個表格或記錄)。
只有滿足這個要求的表,才算是達到了第一范式。
要滿足1NF,如果一個格子內的屬性是同一標簽,得把多值拆開,讓每列只存單一值。
假如有個表這樣:
| 學號 | 姓名 | 聯系方式 |
|---|---|---|
| 001 | 張偉 | 電話:123456, 郵箱:zw@xx.com |
| 002 | 李明 | 電話:789012, 郵箱:lm@yy.com |
聯系方式列有內部結構(電話和郵箱混在一起),不符合1NF。改成1NF可以拆成兩列:
| 學號 | 姓名 | 電話 | 郵箱 |
|---|---|---|---|
| 001 | 張偉 | 123456 | zw@xx.com |
| 002 | 李明 | 789012 | lm@yy.com |
第二范式規則
這個規則說,在關系型數據庫里,你想找表里的某一行數據(記錄),只能通過行里的內容(也就是每一列的具體值)來查找。換句話說,你得告訴數據庫“我要找哪些值”,而不是靠其他方式(比如行的位置或順序)來挑數據。
舉個例子
假設你有一個學生表:
| 學號 | 姓名 | 年齡 |
|---|---|---|
| 001 | 張偉 | 18 |
| 002 | 李明 | 19 |
| 003 | 王芳 | 18 |
符合第二規則的操作
如果你想找某個學生,可以用列里的值作為條件,比如:
- “找出姓名是‘張偉’的行” → 數據庫返回:001, 張偉, 18。
- “找出學號是‘002’的行” → 數據庫返回:002, 李明, 19。
- “找出年齡是18的行” → 數據庫返回:001, 張偉, 18 和 003, 王芳, 18。
這些操作都是通過內容(學號、姓名、年齡的具體值)來找數據,符合第二規則。
不符合第二規則的操作
如果你說:
- “給我表里第2行的數據” → 數據庫會說“啥?不行!” 因為它不認行的位置。
- “給我按插入順序的第1條數據” → 也不行,因為數據庫不關心數據插入的順序。
為什么不行?因為數據庫里的行可能會因為排序、分布式存儲或其他原因,位置隨時變。如果靠位置找數據,結果可能不靠譜。
第三范式規則
第三規則說,在關系型數據庫的同一個表里,不能有兩行數據完全一模一樣。也就是說,表里的每一行(元組)在所有列的值上都得是獨一無二的,不能有“雙胞胎”行。
在實際中,這通常靠主鍵(Primary Key)來保證。主鍵是一列(或幾列),它的值在每行都不同,用來區分每一行。
key,superkey,null values,主鍵,候選鍵
1. 什么是Keys(鍵)?
鍵是數據庫表中用來唯一標識一行數據或建立表之間關系的列(或幾列)。它就像一個“標簽”,讓數據庫能快速找到或區分特定的行。
- 作用
- 確保每行數據獨一無二(區分行)。
- 幫助表之間建立聯系(比如通過外鍵)。
- 例子:在一個學生表里,“學號”可以是鍵,因為每個學生的學號都不一樣,能用來找特定學生。
2. 什么是Superkeys(超鍵)?
超鍵是能唯一標識表中每一行的列的集合,可以包含一列或多列。簡單說,超鍵是“夠用”的鍵,可能包含了比實際需要更多的列。
-
特點
- 超鍵只要能保證每行唯一就行,哪怕包含了不必要的列。
- 超鍵可能有很多個。
-
例子
假設學生表有這些列:
學號,姓名, 年齡
- {學號} 是一個超鍵,因為學號本身就能唯一標識每行。
- {學號, 姓名} 也是超鍵,因為學號加姓名肯定也能唯一標識(雖然姓名其實沒必要)。
- {學號, 姓名, 年齡} 還是超鍵,包含了所有列,肯定唯一。
但超鍵可能“太胖”,包含多余的列,所以我們會從中挑出更精簡的鍵(比如候選鍵或主鍵)。
3. 什么是Null Values(空值)?
空值(Null)表示數據缺失或未知,不是0,也不是空字符串,而是一個特殊的標記,表示“這里沒值”。
4. 什么是主鍵(Primary Key)?
主鍵是表中唯一標識每一行的列(或幾列),是從超鍵中挑出來的一個最精簡、最合適的鍵。每個表只能有一個主鍵。
- 特點:
- 唯一性:主鍵的值在每行都不同,不能重復。
- 非空:主鍵列不能有空值(Null)。
- 唯一選擇:一個表只能定一個主鍵。
- 作用:
- 區分表中的每一行(像身份證號)。
- 作為其他表的外鍵,建立表之間的關系。
5. 什么是候選鍵?
候選鍵是關系型數據庫中能唯一標識表中每一行的列(或列的組合),而且是最精簡的。換句話說,它是“夠用且不浪費”的鍵,能保證每行不重復,但沒有多余的列。
- 特點
- 唯一性:候選鍵的值在每行都不同,不能重復。
- 非空:候選鍵的列不能有空值(Null)。
- 最精簡:不能去掉任何一列,否則就沒法唯一標識行了。
- 一個表可以有多個候選鍵,但最終只會選一個作為主鍵。
- 和超鍵的區別
- 超鍵(Superkey)可能包含多余的列,比如“學號+姓名”也能唯一標識,但“姓名”其實沒必要。
- 候選鍵是超鍵的“瘦身版”,只保留最必要的列。
- 和主鍵的區別
- 候選鍵是“候選人”,表里可能有好幾個。
- 主鍵是從候選鍵中挑一個“上崗”的,只有一個。
集合運算
-
表 R (學生信息)
學號 (ID) 姓名 (Name) 1 張三 2 李四 3 王五 -
表 S (選課信息)
學號 (ID) 姓名 (Name) 2 李四 4 趙六
1. 并(Union)
-
定義:合并 R 和 S的所有元組,去除重復。
-
操作: R ∪ S R∪S R∪S
-
結果
學號 (ID) 姓名 (Name) 1 張三 2 李四 3 王五 4 趙六
SELECT * FROM R
UNION
SELECT * FROM S;
2. 交(Intersection)
-
定義:返回 R 和 S 共有的元組。
-
操作:R ∩ S
-
結果
學號 (ID) 姓名 (Name) 2 李四
SELECT R.* FROM R
INNER JOIN S ON R.ID = S.ID AND R.Name = S.Name;
3. 差(Difference)
-
定義:返回在 R 中但不在 S 中的元組。
-
操作:R?S
-
結果
學號 (ID) 姓名 (Name) 1 張三 3 王五
4. 笛卡爾積(Cartesian Product)
-
定義:將 R 和 S 的每對元組組合。
-
操作:R×S
-
結果
R.ID R.Name S.ID S.Name 1 張三 2 李四 1 張三 4 趙六 2 李四 2 李四 … … … …
SELECT * FROM R CROSS JOIN S;
5. 投影(Projection)
-
定義:從 R 中選擇“姓名”列,去除重復。
-
操作: π N a m e ( R ) πName(R) πName(R)
-
結果
姓名 (Name) 張三 李四 王五 -
SQL
SELECT DISTINCT Name FROM R; -
說明:僅返回唯一的姓名。
6. 選擇(Selection)
-
定義:從 R 中選擇學號大于 1 的元組。
-
操作: σ I D > 1 ( R ) σID>1(R) σID>1(R)
-
結果
學號 (ID) 姓名 (Name) 2 李四 3 王五
7. 自然連接(Natural Join)
-
定義:按同名屬性(ID 和 Name)連接 R 和 S 。
-
操作: R ? S R?S R?S
-
結果
學號 (ID) 姓名 (Name) 2 李四 -
SQL
SELECT * FROM R NATURAL JOIN S; -
說明:只保留 ID 和 Name 均相等的元組。
8. 除(Division)
-
場景:假設新表T
記錄學生選課:
-
表 T (選課記錄)
學號 (ID) 課程 (Course) 1 數學 1 英語 2 數學 -
表 U (必修課)
課程 (Course) 數學 英語
-
-
定義:找出選修了 U 中所有課程的學生。
-
操作: T ÷ U T÷U T÷U
-
結果
學號 (ID) 1 SELECT ID FROM T GROUP BY ID HAVING COUNT(DISTINCT Course) = (SELECT COUNT(*) FROM U) AND NOT EXISTS (SELECT Course FROM UWHERE Course NOT IN (SELECT Course FROM T WHERE T.ID = T.ID) );
sql語言查詢
DDL
SQL 的 DDL(Data Definition Language,數據定義語言) 用于定義和管理數據庫結構,包括創建、修改、刪除數據庫對象(如表、視圖、索引等)。DDL 語句主要操作數據庫的模式(Schema),不涉及數據內容操作。以下是 DDL 的簡單介紹及常見語句:
1. 主要功能
- 創建數據庫對象(如表、數據庫、索引)。
- 修改現有對象的結構(如添加列、修改數據類型)。
- 刪除對象(如刪除表、視圖)。
- 定義約束(如主鍵、外鍵、唯一約束)。
2. 常見 DDL 語句
(1) CREATE - 創建數據庫對象
-
用途:創建數據庫、表、視圖、索引等。
-
示例
-- 創建數據庫 CREATE DATABASE school; -- 創建表 CREATE TABLE students ( id INT PRIMARY KEY, name VARCHAR(50) NOT NULL, age INT ); -
說明:定義表結構,指定列名、數據類型和約束(如 PRIMARY KEY、NOT NULL)。
(2) ALTER - 修改數據庫對象
-
用途:修改表結構,如添加列、刪除列、更改數據類型等。
-
示例
-- 添加列 ALTER TABLE students ADD email VARCHAR(100); -- 修改列數據類型 ALTER TABLE students MODIFY age SMALLINT; -- 刪除列 ALTER TABLE students DROP COLUMN email; -
說明:用于調整已有對象的定義。
-
在sql-server中添加列不需要添加列名,但刪除需要
(3) DROP - 刪除數據庫對象
-
用途:刪除表、數據庫、索引等。
-
示例
-- 刪除表 DROP TABLE students; -- 刪除數據庫 DROP DATABASE school; -
說明:刪除操作不可恢復,需謹慎使用。
(4) TRUNCATE - 清空表數據
-
用途:刪除表中所有數據,但保留表結構。
-
示例
TRUNCATE TABLE students; -
說明:與 DELETE 不同,TRUNCATE 不記錄日志,執行更快,但無法回滾。
3. 特點
- 自動提交:DDL 語句執行后自動提交(COMMIT),無法回滾(ROLLBACK)。
- 結構操作:只操作數據庫或表的結構,不涉及數據內容(數據操作由 DML 負責)。
- 權限要求:通常需要較高的權限(如管理員權限)來執行 DDL。
數據類型
| 數據類型 | 描述 | 示例值 | 適用場景 |
|---|---|---|---|
| INT | 整數(通常 4 字節,范圍約 -2^31 到 2^31-1) | 123, -456 | 存儲整數,如 ID、年齡 |
| BIGINT | 大整數(通常 8 字節,范圍更大) | 123456789012 | 存儲大范圍整數,如計數器 |
| FLOAT | 單精度浮點數(近似值) | 3.14, -0.001 | 存儲小數,精度要求不高 |
| DOUBLE | 雙精度浮點數(更高精度) | 3.1415926535 | 存儲高精度小數,如科學計算 |
| DECIMAL(m,d) | 定點小數(m 位總長度,d 位小數) | 123.45 (DECIMAL(5,2)) | 存儲精確小數,如貨幣金額 |
| CHAR(n) | 固定長度字符串,最大 n 個字符 | "ABC " (CHAR(5)) | 固定長度文本,如狀態碼、郵編 |
| VARCHAR(n) | 可變長度字符串,最大 n 個字符 | “ABC” (VARCHAR(5)) | 可變長度文本,如姓名、地址 |
| TEXT | 大文本數據,無固定長度限制(視數據庫而定) | “This is a long text…” | 存儲大段文本,如文章、描述 |
| DATE | 日期(年-月-日) | 2023-04-27 | 存儲日期,如生日、注冊日期 |
| DATETIME | 日期和時間 | 2023-04-27 14:30:00 | 存儲時間戳,如創建時間 |
| BOOLEAN | 布爾值(真/假) | TRUE, FALSE | 存儲開關狀態,如啟用/禁用 |
| BLOB | 二進制大對象,用于存儲二進制數據 | 圖像、文件數據 | 存儲圖片、視頻等二進制文件 |
varchar和char的區別在于,varchar占用的存儲空間是根據當前字符長度動態申請的,加上一個數據長度標識符,優點是節約空間,缺點是查找時需要通過標識符進行一定的計算,會比char略慢。
實體完整性規則和參照完整性規則
1. 實體完整性規則(Entity Integrity Rule)
啥意思?
- 實體完整性是保證數據庫里每條記錄(行)都有一個唯一標識,而且這個標識不能是空的。簡單說,就是每行數據得有個“身份證號”,而且不能缺。
咋做到?
-
主要靠
主鍵(Primary Key)
- 每張表的主鍵列(比如 id)必須唯一,不能有兩行數據的主鍵值一樣。
- 主鍵列不能是 NULL(空值),因為 NULL 代表“不知道”,沒法當標識。
2. 參照完整性規則(Referential Integrity Rule)
啥意思?
- 參照完整性是保證表之間的關系靠譜。簡單說,如果一張表里的某個值(外鍵)引用了另一張表的數據,那引用的值必須在另一張表里真實存在,或者是空的。
咋做到?
- 靠**外鍵(Foreign Key)**約束:
- 外鍵列的值要么是主表中主鍵的合法值,要么是 NULL。
- 如果主表的數據被刪了或改了,子表的外鍵得跟著調整(比如刪除、置空,或禁止操作)。
為啥重要?
- 防止“孤兒數據”。比如,訂單表里的 customer_id 必須對應客戶表里存在的客戶,不然訂單就不知道是誰的了。
3.用戶定義完整性
錄入的數據必須在用戶定義的范圍內
相關語句
插入多條數據
insert into test values('2','enoch',19),('3','llk',20);
去重選擇
select distinct name from test;
選擇前幾條記錄,order默認從小到大排序
select top 4 * from test order by age;
count
用 test 表來試試:
SELECT COUNT(*) AS 總行數, COUNT(phone) AS phone列非空個數, COUNT(DISTINCT phone) AS phone列不重復個數
FROM test;
結果:
總行數 | phone列非空個數 | phone列不重復個數
2 | 2 | 2
sum
SELECT SUM(distinct CAST(id AS INT)) AS id總和
FROM test;
cast函數將字符轉為數字,去重后求和
avg
求平均值
SELECT AVG(id) AS id平均值,AVG(DISTINCT id) AS id不重復平均值
FROM test;
max,min
同理

group by
需求:只看人數大于 1 的班級
SELECT
class_id, COUNT(*) AS 人數
FROM test
GROUP BY class_id
HAVING COUNT(*) > 1;
結果:
class_id | 人數
---------|------
1 | 2
2 | 2
咋算的?
- 先按 class_id 分組:1 班 2 人,2 班 2 人,3 班 1 人。
- HAVING COUNT(*) > 1 篩選,只留下人數大于 1 的組,所以 3 班被過濾掉了。
group by,相當于把之前的表按照一定的限制條件分成更小的幾個表,count函數在這些小表中分別執行

order by
select * from test order by grade desc
改為從大到小排序(默認是升序
into
select * from test into new_table
將查詢數據輸出到新表中
in
... in (select ...)
in找集合里的東西,()中是子查詢
作用域問題,主查詢和子查詢看不到對方執行查詢的列的細節,只能看到執行后返回的結果
相關子查詢
子查詢需要依賴主查詢中的一些數據
SELECT name, class_id,(SELECT COUNT(*) FROM test t2 WHERE t2.class_id = t1.class_id) AS 班級人數
FROM test t1;
通過建立別名,每次都拿到外圍的t1.class_id作為限制條件
子查詢比較關鍵詞
列名 比較符 (ANY|ALL) (子查詢)
- 列名:你要比較的值(比如 id)。
- 比較符:像 >、<、>= 啥的。
- 子查詢:返回一堆值(比如一列 id)。
- ANY/SOME:ANY 和 SOME 是一個意思(SQL Server 里一樣),表示“跟子查詢里的任意一個值比”。
- ALL:表示“跟子查詢里的所有值比”。
eg.
SELECT name
FROM test
WHERE id > ANY (SELECT min_id FROM classes);
join
SELECT t.name
FROM test t
JOIN classes c ON t.id > c.min_id;
這句 SQL 是在查 test 表和 classes 表,挑出 test 表里的 name,但有個條件:test 表里的 id 要大于 classes 表里的 min_id。
簡單說,就是找“學生 ID 比某些班級的 min_id 大的學生名字”。每一行對應匹配
-
JOIN 是 SQL 里的“連表神器”,專門把兩張表(或更多)按條件拼起來,生成新的結果。
-
就像你有兩個名單,一個是學生名單(test),一個是班級名單(classes),你想把學生的班級信息拼到一起,JOIN 就能干這活兒。
SELECT t.name, c.class_name
FROM test t
INNER JOIN classes c ON t.class_id = c.class_id;
保留左表(test)的所有行,右表(classes)匹配不上的就填 NULL。
就像“所有學生都列出來,找不到班級的就寫空”。
name | class_name
------|------------
enoch | Class A
lally | Class A
alice | Class B
bob | Class B
cathy | NULL
保留右表(classes)的所有行,左表(test)匹配不上的填 NULL。
就像“所有班級都列出來,找不到學生的就寫空”。
| name | class_name |
|---|---|
| enoch | Class A |
| lally | Class A |
| alice | Class B |
| bob | Class B |
| cathy | Class C |
| NULL | Class D |
兩邊表的所有行都保留,匹配不上的填 NULL。
就像“學生和班級都列出來,找不到對應信息的就寫空”。
不寫 ON 條件,把兩張表每行都組合一次,生成“笛卡爾積”。test 有 5 行,classes 有 4 行,生成 5 × 4 = 20 行:
exists
簡單說:
- EXISTS 是個“有沒有”的檢查工具,用來判斷子查詢有沒有返回結果。
- 如果子查詢有哪怕一行結果,EXISTS 就返回 TRUE(真);如果子查詢沒結果,就返回 FALSE(假)。
- 通常跟子查詢一起用,寫成 WHERE EXISTS (子查詢)。
union
union語句聯合查詢,要求列數必須相同,默認去重,如果要保留重復數據,可以使用union all select
INTERSECT 運算符
啥是 INTERSECT?
- INTERSECT 是個“找交集”的工具,把兩個查詢的結果比一比,只留下兩邊都有的行。
- 就像你有兩份名單,一個是籃球隊的,一個是足球隊的,INTERSECT 能挑出既打籃球又踢足球的人。
咋用?
-
語法:
查詢1 INTERSECT 查詢2; -
關鍵點
- 兩個查詢的列數得一樣,類型得兼容(跟 UNION 一樣)。
- 自動去重(只留一份重復的)。
EXCEPT運算符
啥是 EXCEPT?
- EXCEPT 是個“找差集”的工具,把第一個查詢的結果拿出來,減去第二個查詢的結果,只留下第一個查詢獨有的行。
- 就像你有兩份名單,一個是全校學生,一個是籃球隊的,EXCEPT 能挑出不在籃球隊的學生。
聯接查詢
等值聯接
啥意思?
- 等值聯接就是用“等于”(=)來匹配兩張表的列,找兩邊值相等的行。
- 就像找“學生和班級匹配的記錄”,用 class_id 相等來連。
SELECT t.name, c.class_name
FROM test t
JOIN classes c ON t.class_id = c.class_id;
自然聯接
啥意思?
- 自然聯接(NATURAL JOIN)是一種特殊的等值聯接,自動用兩張表里同名列來做等值匹配。
- 不用寫 ON,SQL 自己找同名列(像 class_id)來連,還會把重復的列去掉(結果里只留一份 class_id)。
- 相當于是自動的等值連接
SELECT t.name, c.class_name
FROM test t
NATURAL JOIN classes c;
非等值連接
就是把=號換成><這樣的比較符號
SELECT t.name, c.class_name
FROM test t
JOIN classes c ON t.id > c.min_id;
自身連接
啥意思?
- 自身聯接是自己跟自己連(同一張表),用別名區分兩份“自己”。
- 就像找“同一個班級的學生對”(學生跟學生比)。
SELECT t1.name AS 學生1, t2.name AS 學生2, t1.class_id
FROM test t1
JOIN test t2 ON t1.class_id = t2.class_id
WHERE t1.id < t2.id;
t1 和 t2 是 test 表的兩個副本。
t1.class_id = t2.class_id:找同班的。
t1.id < t2.id:避免重復對(比如 enoch-lally 和 lally-enoch 只留一個)。
為啥用?
- 找表內關系,比如“同班學生”、“員工和他的上級”。
外聯接
啥意思?
- 外聯接(OUTER JOIN)保留至少一張表的所有行,匹配不上的填 NULL。
- 有三種:
- LEFT OUTER JOIN:左表全留,右表沒匹配填 NULL。
- RIGHT OUTER JOIN:右表全留,左表沒匹配填 NULL。
- FULL OUTER JOIN:兩表都留,沒匹配填 NULL。
復合條件聯接
啥意思?
-
復合條件聯接是用多個條件(用 AND、OR 組合)來匹配兩張表。
-
就像“班級匹配且 ID 大于某個值”。
-
SELECT t.name, c.class_name FROM test t JOIN classes c ON t.class_id = c.class_id AND t.id > 2;
update
update test
set age=3
where name='lally';
delete
delete from test
where name='lally';
索引
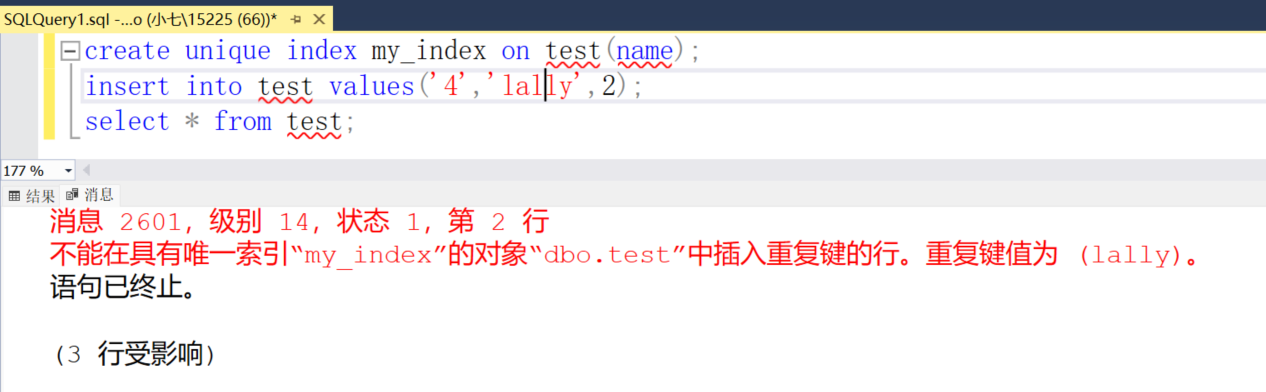
唯一索引 (Unique Index)
啥意思?
- 唯一索引保證索引列(或多列組合)的值不能重復。
- 就像給學生編號(id),每個人的編號必須唯一,不能有重復。
create unique index my_index on test(name);
聚集索引(CLUSTERED INDEX)
啥意思?
- 簇索引(聚集索引)決定表數據的物理存儲順序,有點像按字母順序排書的書架。
- 一張表只能有一個簇索引(因為物理順序只能有一種)。
CREATE CLUSTERED INDEX idx_clustered_class_id ON test(class_id);
通常自動創建:如果你給表加了 PRIMARY KEY,SQL Server 默認會建一個簇索引(除非你指定主鍵用非簇索引)。
特點:
- 決定數據物理順序,查詢范圍(如 WHERE class_id BETWEEN 1 AND 2)超快。
- 一張表只能有一個簇索引。
- 插入數據時可能慢(因為要保持順序,可能會移動數據)。
為啥用?
- 適合經常按某列排序或范圍查詢的場景(像 class_id 這種)。
- 主鍵默認用簇索引(比如 id)。
非簇索引 (Nonclustered Index)
啥意思?
- 非簇索引(非聚集索引)是個“獨立目錄”,不改變數據物理順序,只存一份“指引”。
- 就像書后面加了個索引頁,告訴你“名字”在哪頁,但書本身還是按章節排。非聚集索引將數據在內存中的索引位置記錄下來,查找的時候就會很快。
CREATE NONCLUSTERED INDEX idx_nonclustered_name ON test(name);
為啥用?
- 適合經常查但不排序的列(像 name、phone)。
- 配合 WHERE、JOIN 加速查詢。
存儲程序和觸發器
存儲過程
啥是 Stored Procedure(存儲過程)?
簡單說:
- 存儲過程是一堆預先寫好的 SQL 語句,存成一個“程序”,放在數據庫里,隨時可以調用。
- 就像你把做蛋糕的步驟(加面粉、打雞蛋、烤)寫成一個食譜,存起來,啥時候想吃蛋糕就直接拿出來用,不用每次都重新寫步驟。
CREATE PROCEDURE 存儲過程名字
AS
BEGIN-- 你的 SQL 語句
END;
然后用exec或execute調用
用@傳入參數
輸入輸出參數的區別
CREATE PROCEDURE 存儲過程名字@參數1 數據類型, -- 輸入參數@參數2 數據類型 OUTPUT -- 輸出參數
AS
BEGIN-- 邏輯
END;
結合返回值和if語句使用存儲過程
create procedure find3@findid varchar(10)
as
begindeclare @status int;if not exists (select * from test where id=@findid)beginset @status=0;return @status;end;set @status=1;return @status;
end;declare @sta int;
exec @sta=find3 @findid=1;
if @sta=1print '查到了';
else if @sta=0print '查不到';
調用輸出需要需要先聲明一個變量存儲
DECLARE @Count INT; -- 聲明變量接輸出
EXEC CountStudentsByClass @ClassID = 1, @StudentCount = @Count OUTPUT;
PRINT 'Number of students: ' + CAST(@Count AS VARCHAR(10));
修改存儲過程可以使用alter
觸發器
啥是觸發器?
簡單說:
- 觸發器是一段特殊的存儲過程,綁定在表上,當表發生特定操作(比如插入、更新、刪除)時自動“觸發”運行。
- 就像你家裝了個門鈴,有人開門(操作表)時,門鈴自動響(觸發器跑起來),還能順手干點事(比如記錄誰開了門)。
- 綁定到特定的表上
CREATE TRIGGER 觸發器名字
ON 表名
FOR/AFTER/INSTEAD OF [INSERT, UPDATE, DELETE]
AS
BEGIN-- 你的 SQL 邏輯
END;
觸發器的類型
SQL Server 里有三種觸發器:
-
AFTER 觸發器
(也叫 FOR 觸發器):
- 在操作(INSERT、UPDATE、DELETE)完成后再跑。
- 最常用,比如記錄操作日志。
-
INSTEAD OF 觸發器
- 代替操作執行,操作本身不執行,觸發器里的邏輯跑。
- 比如想阻止刪除,改成“假裝刪”。
-
DDL 觸發器
(不針對表,針對數據庫操作):
- 響應數據庫級操作(像 CREATE TABLE、DROP TABLE),這里不細講。
create trigger my_tri
on test
after insert,update
as
beginupdate testset remark='kid'where age<3;
end;insert test values(4,'jjj',1,null)
select * from test;
啥是 inserted 和 deleted 表?
簡單說:
- inserted 和 deleted 是 SQL Server 在觸發器里提供的兩個臨時虛擬表,用來記錄表數據的變化。
- 它們只在觸發器運行時存在,觸發器跑完就沒了。
作用:
- inserted:存“新數據”(插入或更新后的數據)。
- deleted:存“舊數據”(刪除或更新前的數據)。
- 就像你改作業,deleted 是改之前的草稿,inserted 是改完的新稿。
關鍵點:
- 這倆表的結構跟原表(觸發器綁定的表)一樣。
- 只在觸發器里能用,存儲過程或其他地方用不了。
它們在啥時候有數據?
inserted 和 deleted 表的內容取決于觸發器的操作類型(INSERT、UPDATE、DELETE):
| 操作 | inserted 表 | deleted 表 |
|---|---|---|
| INSERT | 新插入的行 | 空 |
| UPDATE | 更新后的行 | 更新前的行 |
| DELETE | 空 | 被刪除的行 |
數據庫設計
數據庫設計是啥?
簡單說:
- 數據庫設計就是規劃怎么存數據,設計表結構,確保數據好存、好查、不亂。
- 就像建房子,先畫圖紙(概念模型),再按規則砌墻(范式設計),讓房子結實又好用。
目標:
- 數據不重復(節省空間)。
- 查詢快(性能好)。
- 好維護(改數據不出錯)。
概念模型設計(基于 E-R 圖)
找實體(Entity):
- 實體是現實世界的東西,比如“學生”、“班級”。
- 每個實體變成一張表(像 test 表、classes 表)。
- 實體有屬性(比如學生有 id、name、class_id)。
找關系(Relationship):
- 實體之間的關系,比如“學生屬于班級”(一對多)。
- 關系可能變成外鍵(class_id 關聯 classes 表),或者獨立表(多對多關系)。
畫 E-R 圖:
- 用矩形表示實體(Student、Class)。
- 用菱形表示關系(BelongsTo)。
- 用線連接,標明關系類型(1:1、1:N、N:M)。
轉成表:
- 實體變成表,屬性變成列。
- 關系用外鍵或中間表實現。
范式設計(基于規范化理論)
常見范式:
-
第一范式 (1NF)
:列不可再分,所有值是原子值。
- 比如不能存 name 列為 “enoch, lally”,得拆成兩行。
-
第二范式 (2NF)
:非主鍵列完全依賴主鍵。
啥是依賴?
簡單說:
- 依賴(Dependency)是數據庫里的一種關系,描述“一個值能不能決定另一個值”。
- 就像你知道學生的 id,就能查到他的 name,這就是 name 依賴于 id。
啥叫“不完全依賴”?
-
如果主鍵是多列(復合主鍵),非主鍵列只依賴主鍵的一部分,就不滿足 2NF。
-
比如主鍵是 (student_id, course_id),student_name 只依賴 student_id,這就是“不完全依賴”。
-
比如 test 表有 id(主鍵)、name、class_name,class_name 只依賴 class_id(不是主鍵),不滿足 2NF。
-
解決:拆成兩表,test (id, name, class_id) 和 classes (class_id, class_name)。
-
第三范式 (3NF)
:非主鍵列不能傳遞依賴。
- 比如 test 表有 id(主鍵)、class_id、class_name,class_name 依賴 class_id,class_id 依賴 id,不滿足 3NF。
- 解決:把 class_name 放到 classes 表。
啥意思?
- 第三范式要求:表滿足 2NF,并且非主鍵列之間不能有傳遞依賴。
- 傳遞依賴:如果非主鍵列 A 依賴主鍵,B 依賴 A,那 B 間接依賴主鍵,不滿足 3NF。
ER相關概念
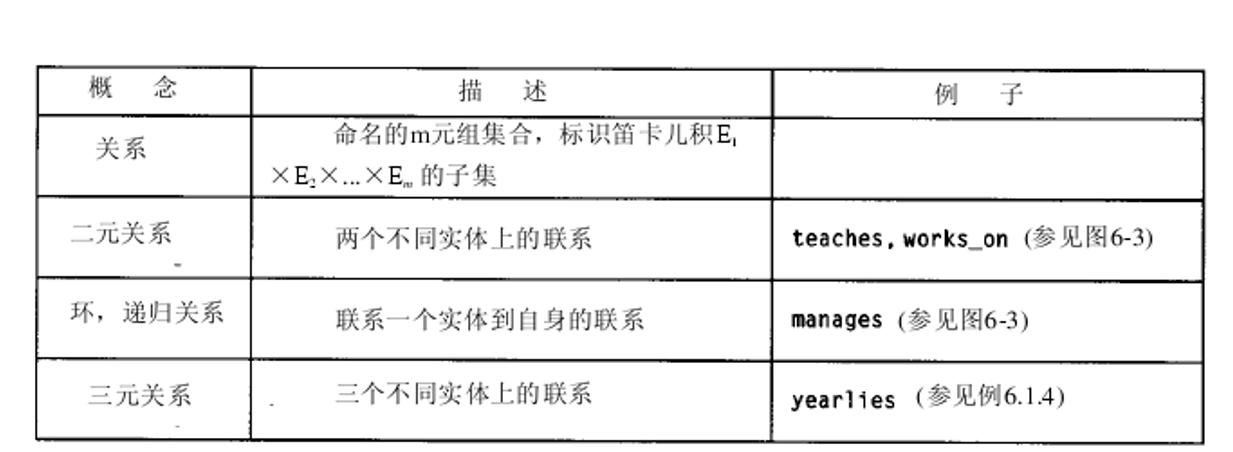
單值 (Single-Valued) 和 多值 (Multi-Valued)
-
單值
:一個實體在關系里最多對應 1 個對方實體。
- 比如:一個學生只能屬于 1 個班級。
-
多值
:一個實體在關系里可以對應多個對方實體。
- 比如:一個班級可以有多個學生。
對方實體 (Other Entity)
啥意思?
-
對方實體是指關系中“另一邊的實體”。
-
關系是兩個實體之間的聯系(二元關系),比如
Student和 Class 的關系
- 如果你在看 Student,那“對方實體”就是 Class。
- 如果你在看 Class,那“對方實體”就是 Student。
max-card(E, R)(最大基數)
-
啥意思
max-card(E, R)
表示實體 E 在關系 R 里最多能連幾個對方實體。
- max-card(E, R) = 1:E 是“單值”的,一個 E 最多連 1 個對方。
- max-card(E, R) = N:E 是“多值”的,一個 E 可以連多個對方。
-
例子
- 關系:“學生屬于班級”。
- 一個學生只能屬于 1 個班級:max-card(Student, BelongsTo) = 1(單值)。
- 一個班級可以有多個學生:max-card(Class, BelongsTo) = N(多值)。
- 關系:“學生屬于班級”。
min-card(E, R)(最小基數)
-
啥意思
min-card(E, R)
表示實體 E 在關系 R 里最少得連幾個對方實體。
- min-card(E, R) = 1:E 必須至少連 1 個對方實體(強制)。
- min-card(E, R) = 0:E 可以不連對方實體(可選)。
-
之前講過
max-card(E, R)
(最大基數),表示最多連幾個:
- max-card 決定單值/多值(1 是單值,N 是多值)。
- min-card 決定強制/可選(1 是強制,0 是可選)。
二元關系轉換
二元關系:兩個實體間的關系(Student BelongsTo Class)。
轉換規則:
- 一對多:多的一方加外鍵(Student 加 class_id)。
- 一對一:任選一方加外鍵,加 UNIQUE 約束(Person 加 idcard_id)。
- 多對多:建中間表(StudentCourse 存 student_id 和 course_id)。
強制/可選:
- 強制參與(min-card = 1):外鍵 NOT NULL。
- 可選參與(min-card = 0):外鍵允許 NULL。
弱實體
啥是弱實體?
簡單說:
- 弱實體(Weak Entity)是不能獨立存在的實體,必須依賴另一個實體(強實體)才能存在。
- 就像“訂單明細”依賴“訂單”:沒有訂單,就不會有訂單明細。
比喻:
- 強實體像“人”,可以獨立存在(有身份證號)。
- 弱實體像“人的手”,得依附于人(沒有獨立身份證號,得靠人來標識)。
關鍵特點:
- 弱實體沒有自己的主鍵(Primary Key),需要借強實體的主鍵來一起組成自己的標識。
- 弱實體和強實體之間的關系通常是“一對多”(強實體是“一”,弱實體是“多”)。
啥是泛化層次結構?
簡單說:
- 泛化層次結構(也叫“泛化/特化”或“繼承層次”)是 E-R 圖里的一種結構,用來表示實體之間的“父子關系”(類似于面向對象里的繼承)。
- 泛化(Generalization):從多個子類型實體抽象出一個父類型實體(從下往上)。
- 特化(Specialization):把一個父類型實體細分成多個子類型實體(從上往下)。
- 就像“人”可以分成“學生”和“老師”,“人”是父類型(泛化),而“學生”和“老師”是子類型(特化)。
約束條件
- 完整約束 (Total Specialization)
- 父類型的每個實體必須屬于某個子類型(不能只有父類型數據)。
- 用雙線連接父類型和子類型。
- 比如:每個 Person 必須是 Student 或 Teacher。
- 部分約束 (Partial Specialization)
- 父類型的實體可以不屬于任何子類型。
- 用單線連接。
- 比如:Person 可以只是 Person,不一定是 Student 或 Teacher。
- 不相交約束 (Disjoint
- 一個父類型實體只能屬于一個子類型(Student 和 Teacher 不重疊)。
- 用三角形里寫 d(disjoint)。
- 重疊約束 (Overlapping)
- 一個父類型實體可以屬于多個子類型。
- 用三角形里寫 o(overlapping)。
- 比如:一個 Person 可以既是 Student 又是 Teacher。
函數依賴
先復習:啥是函數依賴?
簡單說:
- 函數依賴(Functional Dependency,簡稱 FD)是描述表里列之間的“決定關系”。
- 符號:X → Y,意思是如果 X 的值確定,就能唯一決定 Y 的值。
- 比如:id → name,知道 id 就能確定 name。
Armstrong 公理(三大基本規則)
Armstrong 公理是函數依賴的基礎,總是成立。
(1) 自反律 (Reflexivity Rule)
- 規則:如果 Y 是 X 的子集(Y ? X),那么 X → Y。
- 通俗解釋:如果 Y 包含在 X 里,X 當然能決定 Y,因為 Y 就是 X 的一部分。
- 例子
- X = {id, name},Y = {id}。
- Y 是 X 的子集,所以 id, name → id 成立。
- 意義:這個規則很簡單,主要用來推導“顯然”的依賴。
(2) 增補律 (Augmentation Rule)
- 規則:如果 X → Y,那么對于任意屬性集 Z,XZ → YZ(XZ 表示 X ∪ Z)。
- 通俗解釋:如果 X 能決定 Y,那加點無關的屬性 Z 進去,X 加 Z 也能決定 Y 加 Z。
- 例子
- 已知 id → name。
- 加個屬性 Z = {class_id}。
- 根據增補律:id, class_id → name, class_id。
- 意義:可以“擴展”依賴,加入額外的屬性。
(3) 傳遞律 (Transitivity Rule)
- 規則:如果 X → Y 且 Y → Z,那么 X → Z。
- 通俗解釋:如果 X 能決定 Y,Y 能決定 Z,那 X 也能間接決定 Z。
- 例子
- 已知 id → class_id,class_id → class_name(因為 classes 表里有 class_id → class_name)。
- 根據傳遞律:id → class_name。
- 意義:用來發現間接依賴(也是第三范式要消除的傳遞依賴)。
基于三大公理,可以推導出一些更實用的規則,方便計算依賴。
(1) 并規則 (Union Rule)
- 規則:如果 X → Y 且 X → Z,那么 X → YZ。
- 通俗解釋:如果 X 能決定 Y,也能決定 Z,那 X 能決定 Y 和 Z 一起。
- 例子
- 已知 id → name 和 id → class_id。
- 根據并規則:id → name, class_id。
- 推導:可以用增補律和自反律證明。
(2) 分解規則 (Decomposition Rule)
- 規則:如果 X → YZ,那么 X → Y 且 X → Z。
- 通俗解釋:如果 X 能決定 Y 和 Z 一起,那 X 也能單獨決定 Y 和 Z。
- 例子
- 已知 id → name, class_id。
- 根據分解規則:id → name 和 id → class_id。
- 推導:可以用自反律和傳遞律證明。
- 注意:分解規則是并規則的逆向。
(3) 偽傳遞律 (Pseudo-Transitivity Rule)
- 規則:如果 X → Y 且 WY → Z,那么 WX → Z。
- 通俗解釋:如果 X 能決定 Y,而 Y 和 W 一起能決定 Z,那 X 和 W 一起也能決定 Z。
- 例子
- 已知 id → class_id,class_id, teacher_id → class_name。
- 根據偽傳遞律:id, teacher_id → class_name。
- 推導:可以用增補律和傳遞律證明。
閉包 (Closure) 的概念
-
啥是閉包:給定一組函數依賴 F 和屬性集 X,X 的閉包 X? 是 X 能決定的所有屬性的集合。
-
咋算閉包:用 Armstrong 公理和推導規則,從 X 開始,逐步推導能決定的屬性。
-
算法
(簡單版):
- 初始化:X? = X。
- 重復:對于每個依賴 U → V(U 是 X? 的子集),把 V 加到 X?。
- 直到 X? 不變。
-
例子
- 表:test (id, name, class_id)。
- 函數依賴:F = {id → name, id → class_id}。
- 求 id的閉包 id?
- 初始:id? = {id}。
- id → name:加 name,id? = {id, name}。
- id → class_id:加 class_id,id? = {id, name, class_id}。
- 結束:id? = {id, name, class_id}。
-
意義:閉包用來判斷 X 能不能決定某個屬性,或者是不是候選鍵。
覆蓋和最小覆蓋
1. 啥是覆蓋 (Cover)?
簡單說:
- 覆蓋(也叫等價覆蓋,Equivalent Cover)是另一組函數依賴 G,它和原來的函數依賴集 F 等價,也就是說,F 和 G 能推導出的所有依賴(閉包)是一樣的。
- 符號:F? = G?,表示 F 和 G 的閉包相同。
通俗解釋:
- 就像你有兩份“說明書”(F 和 G),內容不同,但能干的事(推導的依賴)完全一樣。
- 覆蓋的目標是找到一個更“簡潔”的函數依賴集,但效果不變。
例子:
- 已知 F = {id → name, id → class_id, class_id → class_name}。
- 用傳遞律:id → class_id,class_id → class_name,推出 id → class_name。
- 構造一個新依賴集 G = {id → name, id → class_id, id → class_name}。
- 檢查:F? 和 G? 都包含 {id → name, id → class_id, id → class_name},所以 G 是 F 的一個覆蓋。
意義:
- 覆蓋可以用來驗證兩個依賴集是否等價,或者簡化依賴集。
2. 啥是最小覆蓋 (Minimal Cover)?
簡單說:
-
最小覆蓋(Minimal Cover,也叫 Canonical Cover,記作 Fc)是函數依賴集 F
的一個“最簡”覆蓋,滿足以下條件:
- 等價:Fc 和 F 的閉包相同(Fc? = F?)。
- 每個依賴的右邊(Y)只有一個屬性(單屬性依賴)。
- 沒有冗余依賴(去掉任何一個依賴都不等價)。
- 沒有冗余屬性(每個依賴的左邊和右邊都不能再簡化)。
通俗解釋:
- 最小覆蓋就像把說明書“精簡”到最短:去掉多余的廢話,每句話都很關鍵,但功能和原來一樣。
- 目標是讓函數依賴集盡可能簡單,方便規范化設計(比如計算范式)。
求最小覆蓋的步驟
給定函數依賴集 F,求最小覆蓋 Fc 的步驟如下:
步驟 1:分解右邊(單屬性化)
- 把每個依賴的右邊拆成單一屬性(用分解規則:X → YZ 拆成 X → Y 和 X → Z)。
- 例子:
- F = {id → name, class_id; class_id → class_name}。
- 拆分:id → name, class_id 變成 id → name 和 id → class_id。
- 新 F = {id → name, id → class_id, class_id → class_name}。
步驟 2:去掉冗余屬性(簡化左邊)
-
檢查每個依賴的左邊,看看能不能去掉某些屬性。
- 對于每個依賴 X → Y,檢查 X 里的每個屬性 A,如果去掉 A 后(X - {A})依然能決定 Y(用閉包計算),就把 A 去掉。
-
例子:
-
假設有 F = {id, class_id → name, id → class_id, class_id → class_name}。
-
檢查
id, class_id → name:
- 去掉 class_id,用 {id} 算閉包:id? = {id, class_id, name}(包含 name),所以 class_id 冗余。
- 簡化成 id → name。
-
新 F = {id → name, id → class_id, class_id → class_name}。
-
步驟 3:去掉冗余依賴
-
檢查每個依賴,看看去掉后是否還等價。
- 對于每個依賴 X → Y,去掉它,計算剩余依賴的閉包,看 X? 里是否還有 Y。
-
例子
-
當前 F = {id → name, id → class_id, class_id → class_name}。
-
去掉
id → class_id,剩余
{id → name, class_id → class_name}
- 算 id?:只有 {id, name},不包含 class_id,說明 id → class_id 不能去。
-
去掉
class_id → class_name,剩余
{id → name, id → class_id}
- 算 class_id?:只有 {class_id},不包含 class_name,說明 class_id → class_name 不能去。
-
沒有冗余依賴,Fc = {id → name, id → class_id, class_id → class_name}。
-
最終最小覆蓋:
- Fc = {id → name, id → class_id, class_id → class_name}。
再來個復雜點的例子
表:R(A, B, C, D)。 函數依賴:F = {A → BC, B → C, A → D}。
求最小覆蓋:
- 分解右邊:
- A → BC 拆成 A → B 和 A → C。
- B → C(已單屬性)。
- A → D(已單屬性)。
- 新 F = {A → B, A → C, B → C, A → D}。
- 去掉冗余屬性:
- A → B:A 不可簡化。
- A → C:A 不可簡化。
- B → C:B 不可簡化。
- A → D:A 不可簡化。
- 沒有冗余屬性。
- 去掉冗余依賴:
- 去掉 A → C,剩余 {A → B, B → C, A → D}:
- 算 A?:A → B,B → C,所以 A? = {A, B, C, D},包含 C,A → C 冗余。
- 新 F = {A → B, B → C, A → D}。
- 再檢查:
- 去掉 A → B,剩余 {B → C, A → D},A? = {A, D},不包含 B,不能去。
- 去掉 B → C,剩余 {A → B, A → D},B? = {B},不包含 C,不能去。
- 去掉 A → D,剩余 {A → B, B → C},A? = {A, B, C},不包含 D,不能去。
- 沒有更多冗余依賴。
- 去掉 A → C,剩余 {A → B, B → C, A → D}:
- 最小覆蓋:
- Fc = {A → B, B → C, A → D}。
求閉包的例子

關系模式的分解
簡單說:
- 關系模式分解是把一個大表(關系模式)拆成多個小表的過程,目的是滿足更高的范式(比如 3NF、BCNF),減少數據冗余和異常。
- 就像把一個大雜物間整理成幾個小柜子,東西放得更有序,找起來也方便。
目標:
- 消除冗余(比如重復數據)。
- 避免更新異常(插入、刪除、更新時不一致)。
- 保持數據的完整性(不能丟數據,不能改邏輯)。
關系模式分解的兩個關鍵性質
分解時要保證兩個性質,否則可能會丟數據或改邏輯。
1. 無損連接 (Lossless Join)
-
啥意思:分解后,通過連接(JOIN)能完全恢復原表的數據,不丟數據。
-
咋判斷
:用函數依賴檢查:
- 給定關系模式 R,分解成 R1 和 R2。
- 如果 R1 ∩ R2 → R1 或 R1 ∩ R2 → R2 成立(基于函數依賴),就是無損連接。
-
例子
:
- 原表 R(id, name, class_id, class_name)。
- 函數依賴:F = {id → name, class_id; class_id → class_name}。
- 分解:
- R1(id, class_id, class_name)。
- R2(id, name, class_id)。
- 交集:R1 ∩ R2 = {id, class_id}。
- 檢查:id, class_id → class_name(成立),所以 id, class_id → R1,是無損連接。
2. 依賴保持 (Dependency Preservation)
- 啥意思:分解后,原來的函數依賴還能通過新表的依賴推導出來(不丟失約束)。
- 咋判斷:
- 給定函數依賴集 F,分解成 R1 和 R2,分別算 F 在 R1 和 R2 上的投影(只包含 R1 和 R2 屬性的依賴)。
- 如果這些投影能覆蓋 F,就是依賴保持。
- 例子:
- 原依賴:F = {id → name, class_id; class_id → class_name}。
- 分解:
- R1(id, class_id, class_name):投影得 id → class_id, class_id → class_name。
- R2(id, name, class_id):投影得 id → name, class_id。
- 合并投影:{id → name, class_id; class_id → class_name},覆蓋了 F,依賴保持。
完整性約束,視圖,安全,系統目錄
完整性約束 (Integrity Constraints)
-
啥意思:保證數據“正確”和“一致”的規則,約束是完整性約束的一部分。
-
種類:
- 實體完整性:主鍵不能重復且不能為 NULL(比如 id)。
- 參照完整性:外鍵值必須存在(比如 class_id 必須在 classes 表里)。
- 用戶定義完整性:業務規則,比如 CHECK (class_id > 0)。
-
例子:class_id 不能為 NULL(如果強制參與),且必須在 classes 表里有對應值。
-
約束(Constraint)是數據庫里的一套規則,用來限制表里的數據,確保數據的正確性和一致性。
-
就像學校的規章制度,約束讓數據“守規矩”,避免亂七八糟的情況。
常見約束類型:
- 主鍵約束 (PRIMARY KEY):確保每行唯一且不為空(比如 id)。
- 唯一約束 (UNIQUE):列值不能重復(但可以為空)。
- 非空約束 (NOT NULL):列不能為 NULL。
- 外鍵約束 (FOREIGN KEY / REFERENCE):保證引用值存在。
- 檢查約束 (CHECK):限制值的范圍或條件。
- 默認約束 (DEFAULT):給列設置默認值。
CREATE TABLE 表名 (列名 數據類型 CHECK (條件),...
);
或單獨加
ALTER TABLE test
ADD CONSTRAINT chk_name_length CHECK (LEN(name) > 2);
外鍵約束語法
CREATE TABLE 表名 (列名 數據類型,CONSTRAINT 約束名 FOREIGN KEY (列名) REFERENCES 另一表(列名),...
);
discnt real constraint discnt_max check (discnt<=15.0)
discnt的類型是(real),加一個check限制discnt
視圖 (Views)
- 啥意思:視圖是一個“虛擬表”,基于實際表(物理表)的查詢結果,簡化數據訪問。
- 作用:
- 隱藏復雜查詢:用戶只看到需要的部分。
- 保護數據:限制用戶訪問某些列。
CREATE VIEW student_class_view AS
SELECT t.name, c.class_name
FROM test t
JOIN classes c ON t.class_id = c.class_id;
SELECT * FROM student_class_view;
安全 (Security)
-
啥意思:控制誰能訪問或修改數據庫里的數據,保護敏感信息。
-
方法:
-
用戶權限:用 GRANT和 REVOKE
分配權限。
-
比如只允許某用戶讀 test表:
GRANT SELECT ON test TO user1; -
禁止更新:
REVOKE UPDATE ON test FROM user1;
-
-
角色:給一組用戶分配角色,比如 db_reader角色。
CREATE ROLE db_reader; GRANT SELECT ON test TO db_reader; -
視圖保護:用視圖限制可見數據(比如上面的 student_class_view 只暴露 name 和 class_name)。
-
-
例子:
-
假設 class_name是敏感數據,只允許管理員看:
GRANT SELECT ON classes TO admin; DENY SELECT ON classes TO public;
-
數據庫安全的四個等級
1. 系統級安全 (System-Level Security)
-
啥意思:
- 系統級安全是最外層的防護,關注數據庫運行的整個系統環境(操作系統、網絡等)。
- 目的是防止未經授權的用戶進入數據庫所在的系統。
-
咋做:
-
操作系統權限
:限制誰能登錄數據庫服務器。
- 比如:只有 DBA(數據庫管理員)能登錄服務器,其他人不能。
-
網絡安全
:保護數據庫的網絡訪問。
- 用防火墻限制訪問(比如只允許特定 IP 訪問 SQL Server 的 1433 端口)。
- 用 SSL/TLS 加密網絡傳輸,防止數據被攔截。
-
身份驗證
:驗證用戶身份。
- SQL Server 支持兩種身份驗證:
- Windows 身份驗證:用 Windows 用戶登錄(更安全)。
- SQL Server 身份驗證:用用戶名和密碼(比如 sa 用戶)。
- SQL Server 支持兩種身份驗證:
-
2. 數據庫級安全 (Database-Level Security)
- 啥意思:
- 數據庫級安全關注整個數據庫的訪問控制,確保只有合法用戶能訪問數據庫。
- 咋做:
- 用戶管理:創建數據庫用戶,分配權限。
3. 對象級安全 (Object-Level Security)
-
啥意思:
- 對象級安全關注數據庫里的具體對象(表、視圖、存儲過程等),控制用戶對這些對象的操作。
-
咋做:
-
權限分配:用 GRANT和 REVOKE控制權限。
-
比如只允許 user1 讀 test 表:
GRANT SELECT ON test TO user1;DENY UPDATE ON classes TO user1;
-
-
限制用戶只能訪問某些行和對某些列進行加密等操作,一定程度上保護數據安全
系統目錄 (System Catalogs)
- 啥意思:系統目錄是一組特殊的表,存儲數據庫的“元數據”(Metadata),也就是數據庫里所有對象(表、視圖、約束等)的描述信息。
- 作用:
- DBA 可以查系統目錄,了解數據庫結構。
- 比如:有哪些表、表的列、約束、權限等。
- 在 SQL Server 中:
- 系統目錄包括 sys.tables、sys.columns、sys.foreign_keys 等。
練習題
文件系統和DBMS的四個主要區別
| 方面 | 文件系統 | DBMS |
|---|---|---|
| 數據組織 | 文件分散,無結構化關系 | 表結構,有關系(外鍵等) |
| 一致性完整性 | 無約束,易不一致 | 有約束、事務,保證一致性 |
| 訪問查詢 | 手寫代碼,效率低 | SQL 查詢,高效有優化 |
| 并發安全 | 無并發控制,安全粗糙 | 并發控制強,細粒度安全 |
解釋物理獨立性,以及它在數據庫系統中的重要性。
物理獨立性是指應用程序和用戶查詢(邏輯層)不受數據庫底層物理存儲結構(物理層)變化的影響。
也就是說,數據庫的存儲方式(比如文件、索引、磁盤分布)變了,應用程序和 SQL 查詢不用改,照樣能正常工作。
數據庫系統通常分三層(ANSI-SPARC 架構):
- 外部層(External Level):用戶看到的數據視圖(比如視圖)。
- 邏輯層(Conceptual/Logical Level):表的邏輯結構(比如 test 表的列和關系)。
- 物理層(Physical Level):底層存儲(文件、索引、分區)。
物理獨立性是邏輯層和物理層之間的隔離。
其實就是邏輯層(用戶查詢,表結構)不受物理層(存儲,索引)的變化迎新
重要性:
- 靈活性:隨便更改物理存儲位置,用戶不受影響
- 省成本:應用不用改
- 性能好:支持底層優化
- 可擴展:數據量大也可以輕松調整
找出候選鍵
| A | B | C | D | E |
|---|---|---|---|---|
| a1 | b1 | c1 | d1 | e4 |
| a1 | b1 | c2 | d2 | e3 |
| a1 | b2 | c3 | d1 | e1 |
| a1 | b2 | c4 | d2 | e2 |
候選鍵都是有潛力成為主鍵的,必須要最簡潔,可以用一列就絕對不用兩列




估計算法原理以及相具體的應用實例附C++代碼示例)





)

)






