1. 磁盤?
? ?最小基本單位 扇區?
?機器磁盤的io效率 (讀和取)
2. 文件系統?
? ?對磁盤分區 ,最小的文件單位塊組,快組內部已經劃分好區域,巴拉巴拉,總之,每次使用數據,以操作系統的處理都是塊級的,而這些塊內部的區域已經劃分好了,所以需要提前對內存格式化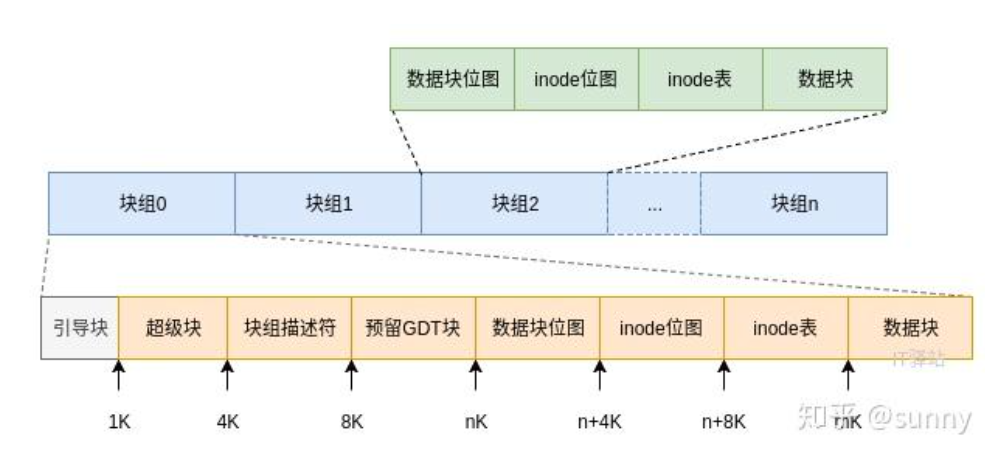
?
一 . 創建文件
? ?確定路徑,獲取
?
?
首先我已經理解了在文件系統中最小的邏輯單位是4kb 以快組位單位 而且快組內部已經被劃分號區域了 ,有塊組描述符: 里面放了當前塊組inode表使用的起始位置,空于數據塊的起始位置以便于創建文件的時候定位 位 : innode位圖表: 和inode表:這也是一塊內存而且是連續的:里面放的是一系列的inode的結構體指針,這個inode的結構體指針其中主要有: inode的編號,文件屬性,還有databloc[num]數組,這個數組里面都是直接或者間接存放著指向塊組的數據塊區的索引位置,指向的數據塊內容可能直接放著數據也可能是二級索引,又指向了其他的位置,舉例來說 如果是二級索引: datablock數組的大小是15x4: 也就是60個下標的話那可以指向60x4個kb的塊組(忽略其他區的大小因為他們很小),這些塊組的也會加入指定的inode, 每一個塊組有128MB的數據庫大小 ,一個索引int 類型也就4字節 這里有 128 x1024x1024 /4 個索引 15個塊組又可以存: 128 x1024x1024 /4 x15 個索引 每一個索引指向4kb:所以最終可以指向 : 128 x1024x1024 /4 x15 x4kb 的大小 現在這樣分析就理解透徹了整個區域劃分后的功能,補充的是 inode bit圖它存放的是inode表inode的使用情況, 所以 我們的inode位圖表 和block位圖表 像一個全局變量一樣來指向我們的inode和數據塊(128mb) ,然后inode結構體又又來指向數據內容和結構屬性。 有了這些我們可以很輕松的闡述關于創建文件和刪除文件的過程,創建一個文件 通過塊組描述符(確定inode和block塊的起始位置) 然后遍歷inode表和block表找到空于位置進行存入數據。 當我們想刪數據的時候,又可以通過innode表找到修改我們的innode位圖和塊位圖即可 不需要對數據塊修改 因為刪除只需要覆蓋即可,
?
?
?
?
創建一個文件是要確定當前的目錄路徑的,每一次都要往 會遞歸到根目錄 然后一步步的進入回到當前目錄才能找到當前目錄的inode 但是這樣效率太慢了 linux操作系統會對你最近常用的路徑信息進行緩存 叫做dentry緩存
?
?
? ls -li 可以看到文件的inode
?
創建硬連接以后他的文件屬性也是和之前一樣嗎
嗎軟鏈接不一樣
? ??
不允許給目錄建立硬連接舉個例子如果我們在某一個目錄建立了一個根目錄的硬連接當我們用find命令的時候從根目錄開始遞歸的訪問每一個目錄遇到這個硬連接的時候就會出現回路問題一直下去出現系統級別的錯誤?
? ?但是硬連接給目錄的還有..和.因為系統建立的這兩個是技術上允許也可以實習的,操作系統不相信用戶但是實現這兩個可以用來定位路徑同時也不會出現一個問題find命令不會對.和..進行查找的
?
?
?
?
?
















)

02)
之ShadowCaster)