關注gongzhonghao【CVPR頂會精選】
大語言模型+擴散Transformer的深度融合,讓文本到圖像生成更精準、細節更豐富;同時,專家軌跡正則化深度強化學習在自動對焦中的穩定加速表現,也展示了深度學習與軌跡建模結合的潛力。
這樣的組合正在多模態生成與智能控制領域悄然升溫,適合想快速產出高質量成果的同學。想沖高區,可嘗試探索跨模態生成的輕量化架構、動態軌跡約束策略,以及大模型與深度學習的聯合優化方向。今天小圖給大家精選3篇CVPR有關深度學習方向的論文,請注意查收!
論文一:Exploring the Deep Fusion of Large Language Models and Diffusion Transformers for Text-to-Image Synthesis
方法:
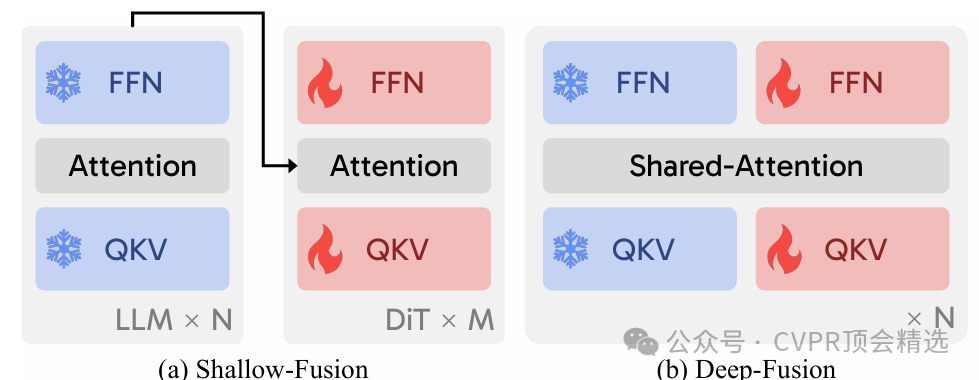
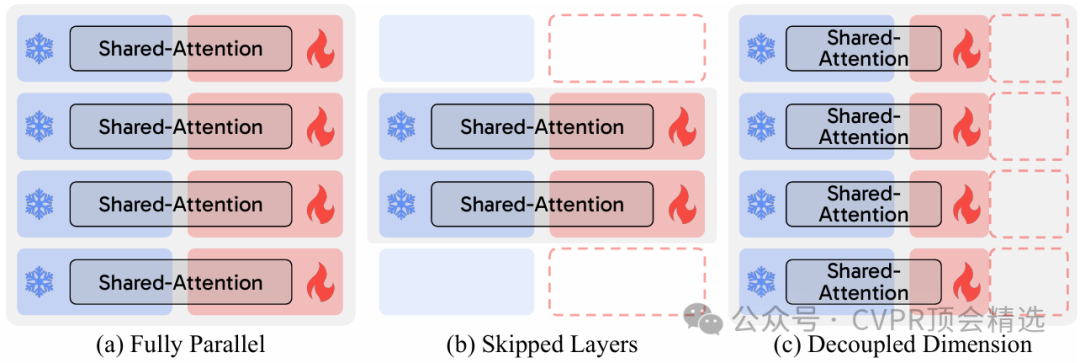
文章首先構建了多種融合架構,將大型語言模型的語言理解能力與擴散Transformer的圖像生成能力進行有機結合,通過模塊級設計與信息流動機制實現高效協作。作者設計了一套標準化訓練流程,涵蓋預處理、模型搭建、損失函數設定及多輪調優,并在多個公開數據集上進行系統實驗,實現方法的可復現性。最后,團隊通過詳細展示不同融合策略在文本與圖像關聯度、生成細節豐富性以及運算效率上的優劣,推動了領域內模型設計的進一步發展。
創新點:
首次系統性對比并梳理了大型語言模型與擴散Transformer在多種融合方式下的性能與表現。
提出了可復現的訓練范式和開源方法,推動了文本到圖像生成模型的透明化與標準化。
深入分析了不同融合策略對生成圖像質量、語義一致性和模型效率的影響,給出優化建議。
論文鏈接:
https://arxiv.org/abs/2505.10046
圖靈學術論文輔導
論文二:Stabilizing and Accelerating Autofocus with Expert Trajectory Regularized Deep Reinforcement Learning
方法:
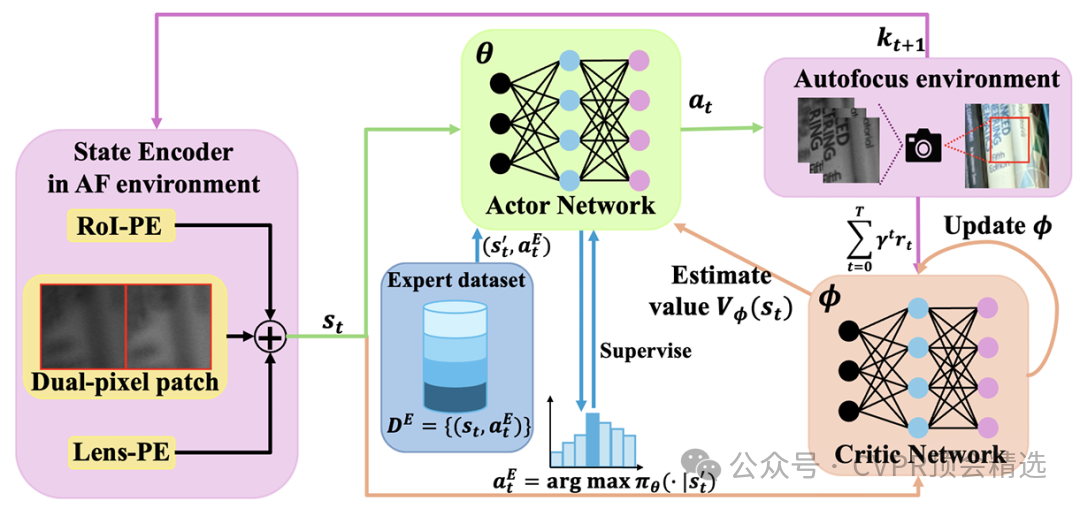
文章首先構建了一個以深度強化學習為核心的自動對焦模型,并將包含豐富對焦經驗的專家軌跡作為正則化項納入損失函數中以約束學習過程。研究團隊為該任務量身定制了獎勵函數,使模型在對焦過程中能夠自適應地減少無意義的搜索步驟,從而提升對焦速度和精度。整個方法通過大量實際和仿真數據訓練與測試,最終在多種復雜拍攝場景下展現出優于傳統和現有深度方法的穩定性和效率。

創新點:
引入專家軌跡數據作為正則項,有效指導深度強化學習對焦策略的收斂方向。
設計了專門針對對焦場景的獎勵機制,顯著減少對焦過程中的無效搜索。
通過端到端訓練框架,實現了自動對焦系統在多種實際場景下的高魯棒性和優越性能。
論文鏈接:
https://cvpr.thecvf.com/virtual/2025/poster/35124
圖靈學術論文輔導
論文三:Deep Fair Multi-View Clustering with Attention KAN
方法:
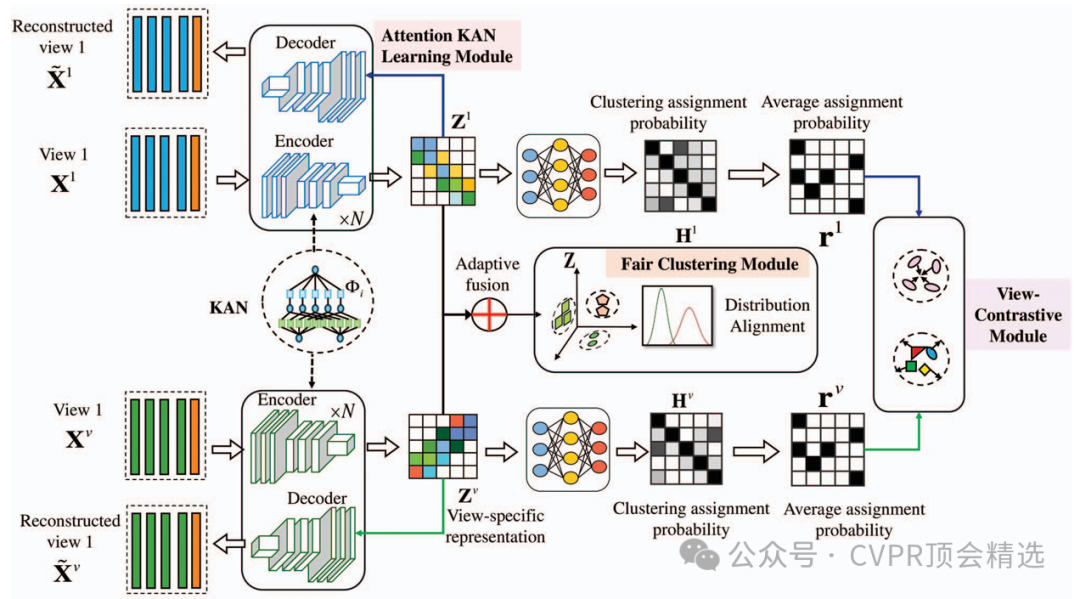
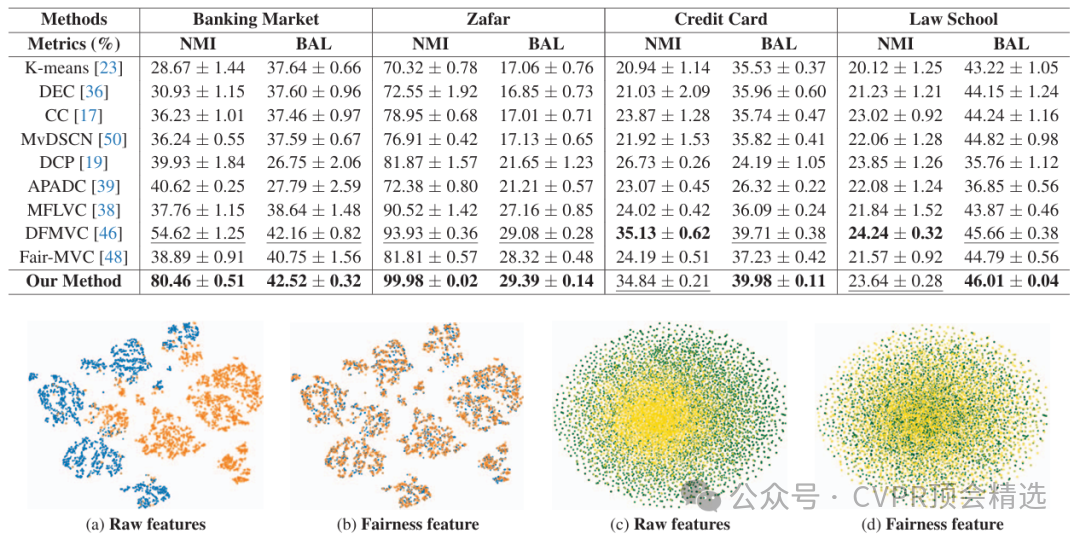
作者首先利用多視圖特征融合,將不同視角的數據輸入深度神經網絡,通過注意力KAN模塊動態分配特征權重,強化關鍵信息的表達。研究團隊引入公平性約束,針對不同群體或類別進行正則化處理,確保聚類結果在各視圖之間保持公正分布。整個方法以端到端方式訓練,并在多種復雜真實數據集上進行驗證,顯著提高了聚類的準確率和公平性。
創新點:
首次將Kolmogorov-Arnold網絡與注意力機制結合應用于多視圖聚類任務。
設計了公平性約束模塊,有效緩解了數據分布不均導致的聚類偏差。
提出深度多視圖聚類框架DFMVC-AKAN,實現了聚類性能和公平性的同步提升。
論文鏈接:
https://ieeexplore.ieee.org/document/11094477
本文選自gongzhonghao【CVPR頂會精選】
創建智能體的完整步驟)



)


)




)



))


