YOLO — YOLOv5模型以及項目詳解
文章目錄
- YOLO --- YOLOv5模型以及項目詳解
- 一,開源地址
- 二,改進點
- Focus 模塊
- 三,網絡結構
- 3.1 CSP1_X 與 CSP2_X
- 3.2 自適應Anchor的計算
- 3.3 激活函數
- 3.3.1 SiLU
- 3.3.2 Swish
- 3.4 Bottleneck
- 3.5 C3
- 3.5.1 BottleneckCSP
- 3.5.2 C3
- 3.6 SPPF
- 四,開源項目
- 4.1 項目構建
- 4.2 項目流程
- 4.2.1 下載源碼
- 4.2.2 新建環境
- 4.2.3 安裝包
- 4.2.4 下載推理文件
- 4.2.5 常用命令
- 4.2.6 數據集
- 4.2.7 模型訓練
- 4.2.8 恢復訓練
- 4.2.9 導出onnx
- 4.2.10 推理
- 4.2.11 onnx推理
- 4.3 模型應用
- 4.3.1 實例分割
- 4.3.2 圖像分類
- 五,優缺點
一,開源地址
-
YOLOV5并沒有學術論文,是一個開源項目,是 Ultralytics 公司于 2020 年6月9 日發布的
-
項目可以在 github 搜到:https://github.com/ultralytics/yolov5
二,改進點
- 主干網絡是修改后的 CSPDarknet53,后面跟了 SPPF 模塊
- 網絡最開始增加 Focus 結構
- 頸部網絡采用 PANet、FPN
- 激活函數換成了 SiLU、Swish
- 采用 CloU 損失
Focus 模塊
-
YOLOv5 剛推出時,為了提升模型效率,采用了 Focus 模塊 作為網絡的初始特征提取層,傳統卷積下采樣會丟失部分空間信息,Focus 模塊旨在在不丟失信息的前提下進行高效下采樣
-
**核心目標:**將高分辨率圖像的空間信息通過切片操作轉換為通道信息,從而實現高效、無信息損失的下采樣
-
Focus 模塊是一種用于特征提取的卷積神經網絡層,用于將輸入特征圖中的信息進行壓縮和組合,從而提取出更高層次的特征表示,它被用作網絡中的第一個卷積層,用于對輸入特征圖進行下采樣,以減少計算量和參數量
-
Focus 層在 YOLOv5 中是圖片進入主干網絡前,對圖片進行切片操作,原理與 Yolov2 的 passthrough 層類似,采用切片操作把高分辨率的圖片(特征圖)拆分成多個低分辨率的圖片(特征圖),即隔列采樣+拼接
-
具體操作是在一張圖片中每隔一個像素拿到一個值,類似于鄰近下采樣,這樣就拿到了 4 張圖片,4 張圖片互補,但是沒有信息丟失,這樣一來,將空間信息就集中到了通道空間,輸入通道擴充了 4 倍,即拼接起來的圖片相對于原先的 RGB 3 通道模式變成了 12 個通道,最后將得到的新圖片再經過卷積操作,最終得到了沒有信息丟失情況下的二倍下采樣特征圖
-
案例:假設輸入一張圖像大小為 640x640x3
-
第一步:640 x 640 x 3的圖像輸入Focus結構,采用切片操作
-
第二步:然后進行一個連接(concat),變成 320 x 320 x 12 的特征圖
-
第三步:經過一次 32 個卷積核的卷積操作,最終輸出 320 x 320 x 32 的特征圖
-
-
在 YOLOv5 剛提出來的時候,有 Focus 結構,從 YOLOv5 第六版開始, 就舍棄了這個結構,改用 k=6×6,stride=2 的常規卷積
三,網絡結構
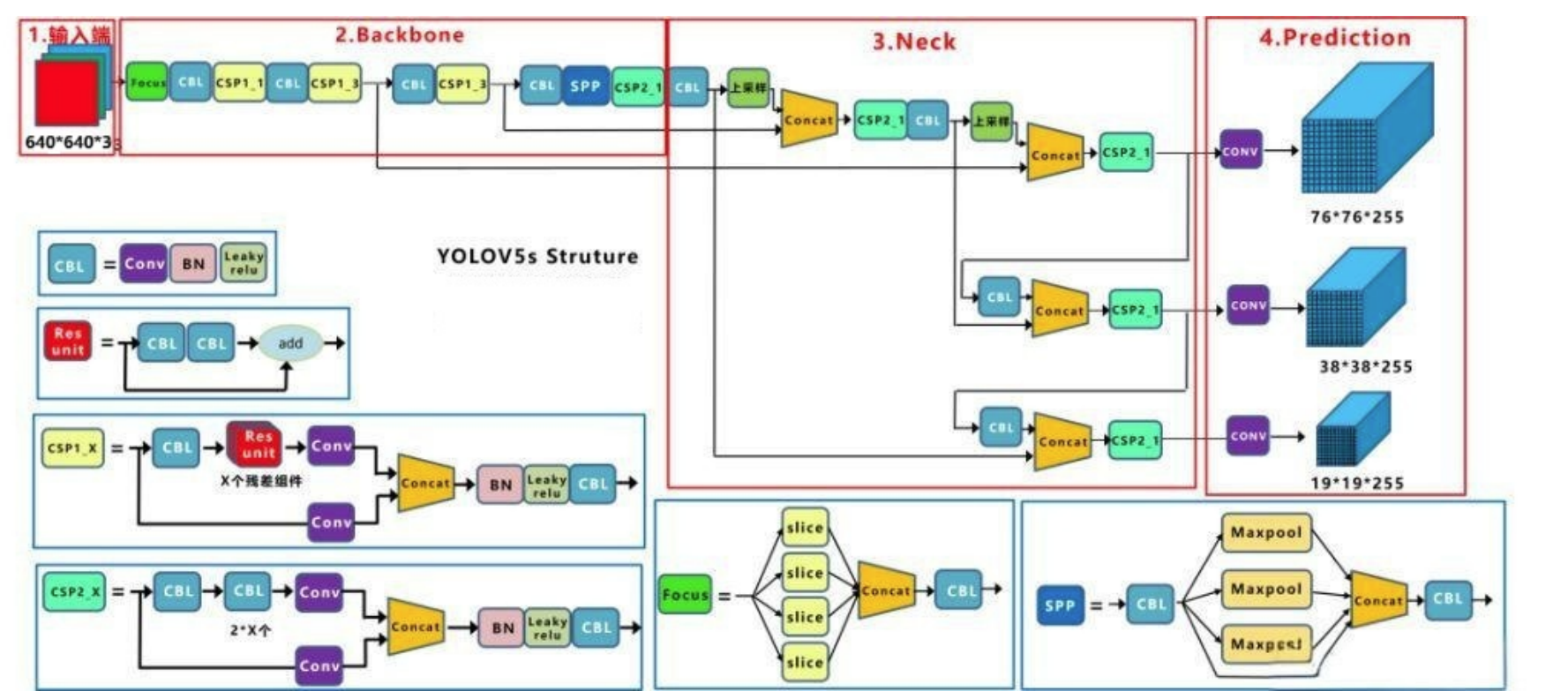
3.1 CSP1_X 與 CSP2_X
| 模塊名稱 | CSP1_X | CSP2_X |
|---|---|---|
| 定義 | 帶 shortcut(殘差連接)的 CSP 模塊 | 不帶 shortcut 的 CSP 模塊 |
| 結構特點 | 內部包含帶有 shortcut 的 Bottleneck 結構 | 內部沒有 shortcut 連接,僅通過卷積操作進行特征提取 |
| 應用場景 | 主要用于 backbone 部分,如 CSPDarknet53,增強特征提取能力 | 主要用于 neck 部分,如 PANet(Path Aggregation Network),進行特征聚合 |
| X 的含義 | 表示 bottleneck 的數量 | 表示 bottleneck 或其他卷積模塊的數量 |
3.2 自適應Anchor的計算
- 在 YOLOv3、YOLOv4 中,訓練不同的數據集時,計算初始 Anchor 的值是通過單獨的程序運行的。但 YOLOv5 中將此功能嵌入到代碼中,每次訓練時會自適應的計算不同訓練集中的最佳 Anchor 值
- 實現方式:
- 在訓練開始前,YOLOv5 會自動加載訓練集中的標注框
- 使用 K-Means 聚類算法計算 Anchor
- 將結果作為初始 Anchor 值用于模型初始化
3.3 激活函數
激活函數:使用了 SiLU 激活函數、Swish 激活函數兩種激活函數
3.3.1 SiLU
- YOLOv5 的 Backbone 和 Neck 模塊和 YOLOv4 中大致一樣,都采用 CSPDarkNet 和 FPN+PAN 的結構,但是網絡中其他部分進行了調整,其中 YOLOv5 使用的激活函數是 SiLU
- SiLU(x)=x?σ(x)SiLU(x) = x·\sigma(x)SiLU(x)=x?σ(x),具備無上界有下屆、平滑、非單調的特性
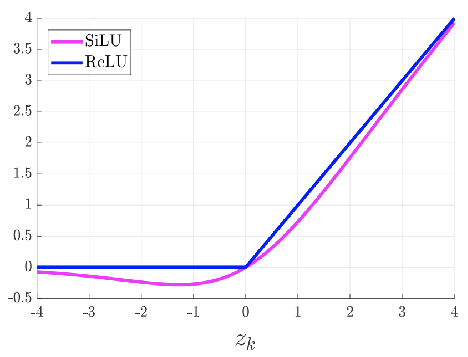
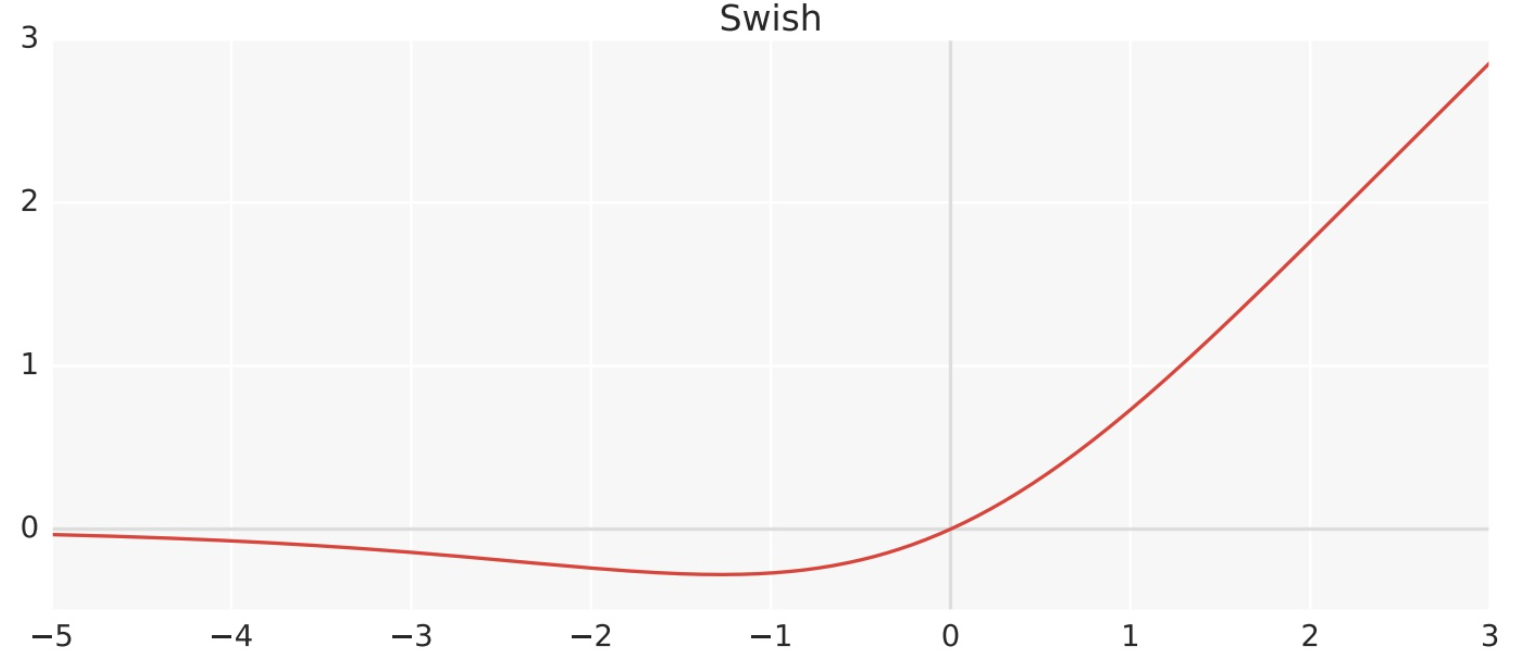
3.3.2 Swish
Swish 激活函數是一個近似于 SiLU 函數的非線性激活函數
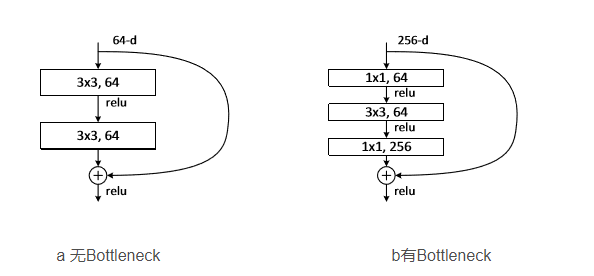
3.4 Bottleneck
Bottleneck 是用于減少參數和計算量的結構,其設計靈感來自于ResNet,結構如下:
- 1x1卷積:用于減少特征圖的通道數
- 3x3卷積:用于提取特征,后接一個 Batch Normalization 層和 ReLU 激活函數
- 1x1卷積:用于恢復特征圖的通道數,后接一個BN層
- 跳躍連接(Shortcut):將輸入直接加到輸出上,以形成殘差連接
3.5 C3
- YOLOv5 中的 C3 模塊在 CSP上進行了優化,非常相似但略有不同:
- YOLOv5 一共使用過兩種 CSP 模塊
- v4.0 版本之前的 BottleneckCSP,用的 LeakyReLU 作為激活函數
- v4.0 版本之后的 C3,用的 SiLU 作為激活函數
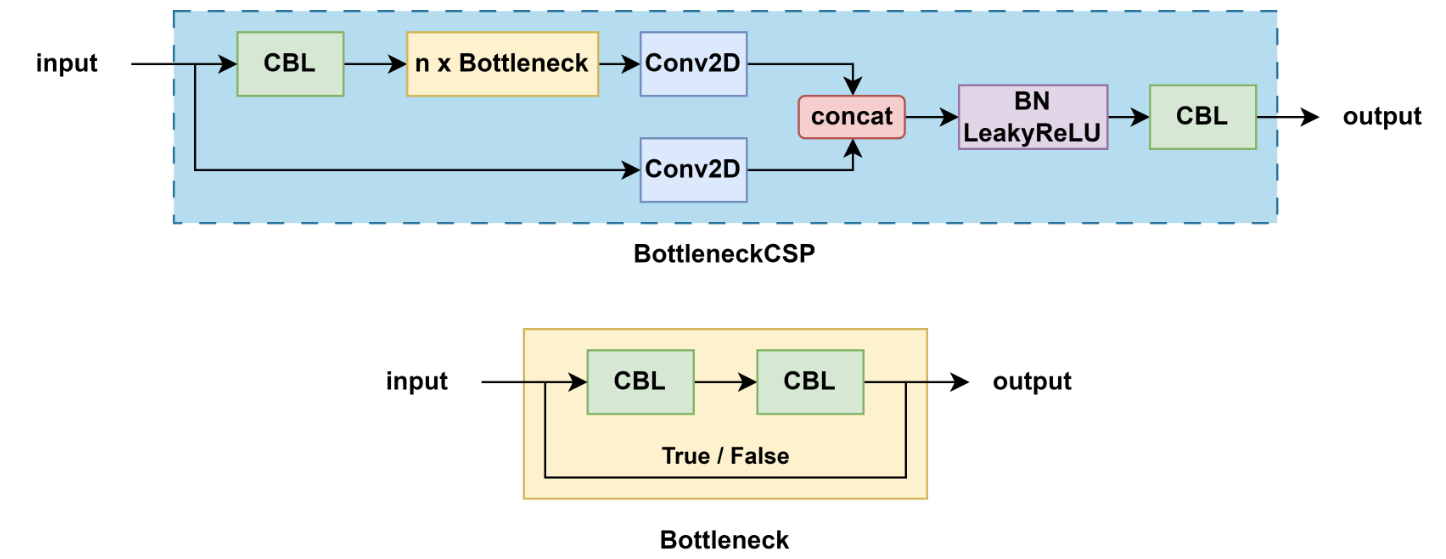
3.5.1 BottleneckCSP
- 結構特點:
- 包含多個帶 shortcut 的 Bottleneck
- 輸入通道被劃分,一部分直接傳遞,一部分經過 Bottleneck 塊
- 激活函數:LeakyReLU
- 用途:主要用于早期 YOLOv5 的 backbone
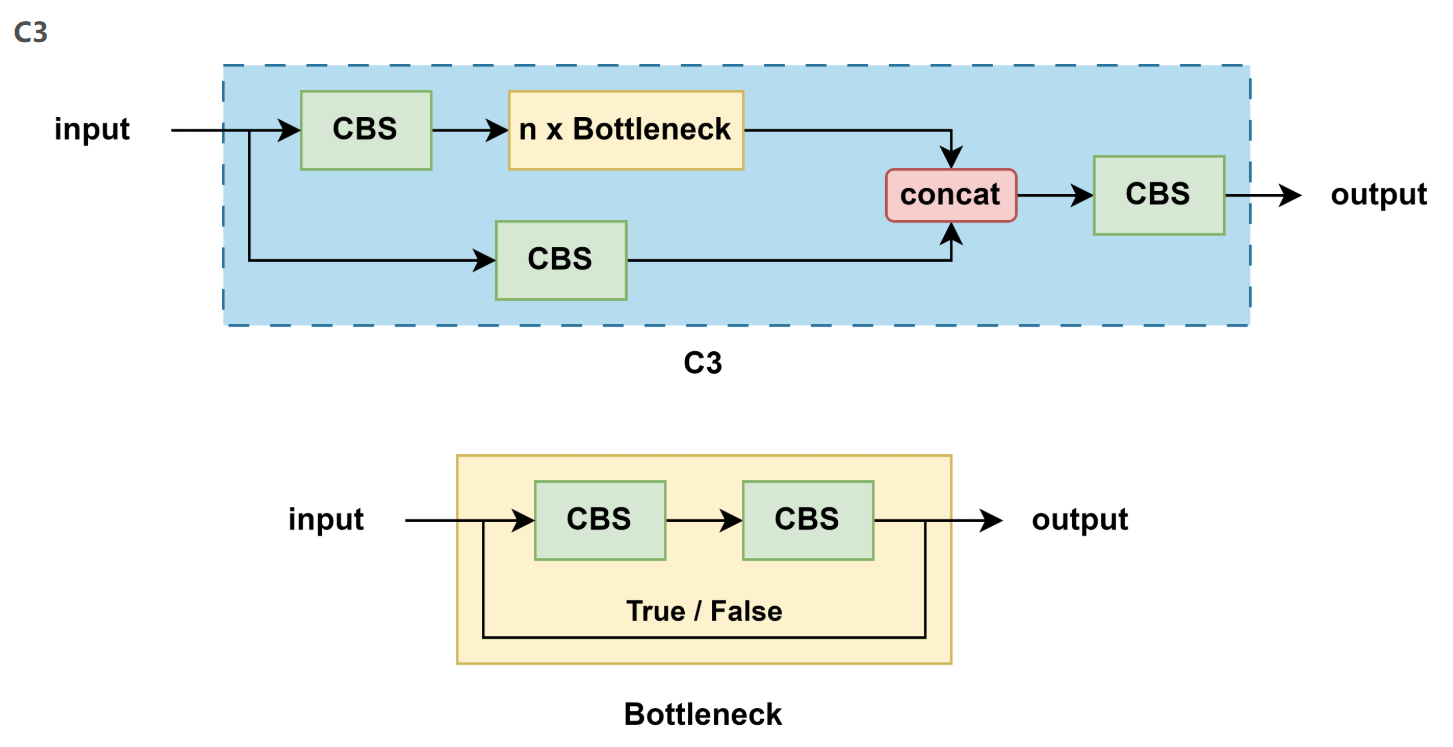
3.5.2 C3
- 結構特點:
- 不再使用 shortcut(即 Bottleneck 不帶殘差連接)
- 更加簡潔,更適合部署
- 激活函數:SiLU
- 用途:廣泛用于 backbone 和 neck(如 PANet)
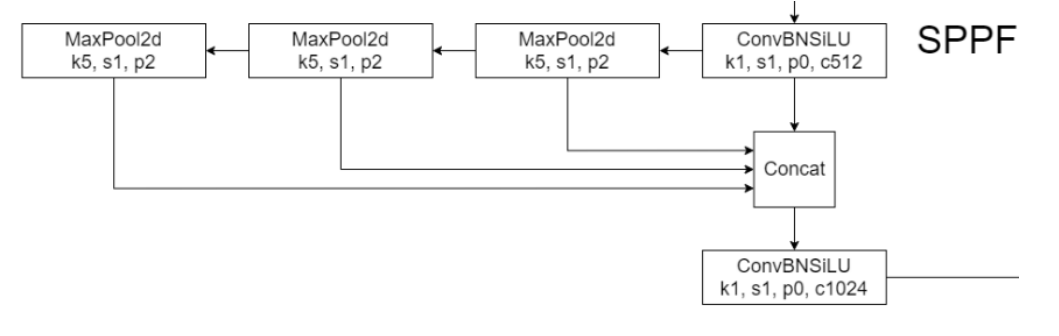
3.6 SPPF
- 將卷積核大小變成相同,然后將并行變成了串行+并行,2個K5池化=1個K9池化,3個K5池化=1個K13池化,也就是結果相同的基礎上,速度更快,計算量更小
- 對于連續堆疊 n 層,每層使用大小為 k 的核的操作(例如卷積或池化),其等效感受野大小可以通過以下公式計算:K等效=1+n(k?1)K_{等效}=1+n(k?1)K等效?=1+n(k?1)
| 層數 n | 卷積核大小 k | 等效感受野 |
|---|---|---|
| 1 | 5 | 1+1×(5?1)=5 |
| 2 | 5 | 1+2×(5?1)=9 |
| 3 | 5 | 1+3×(5?1)=13 |
四,開源項目
4.1 項目構建
使用github或者gitee
-
GitHub 官方倉庫:
https://github.com/ultralytics/yolov5 -
Gitee 鏡像地址:
https://gitee.com/mirrors/YOLOv5
4.2 項目流程
4.2.1 下載源碼
第一步:下載 yolov5 源碼,前面的步驟已經完成
4.2.2 新建環境
第二步:新建環境,見
https://blog.csdn.net/m0_73338216/article/details/146123256
4.2.3 安裝包
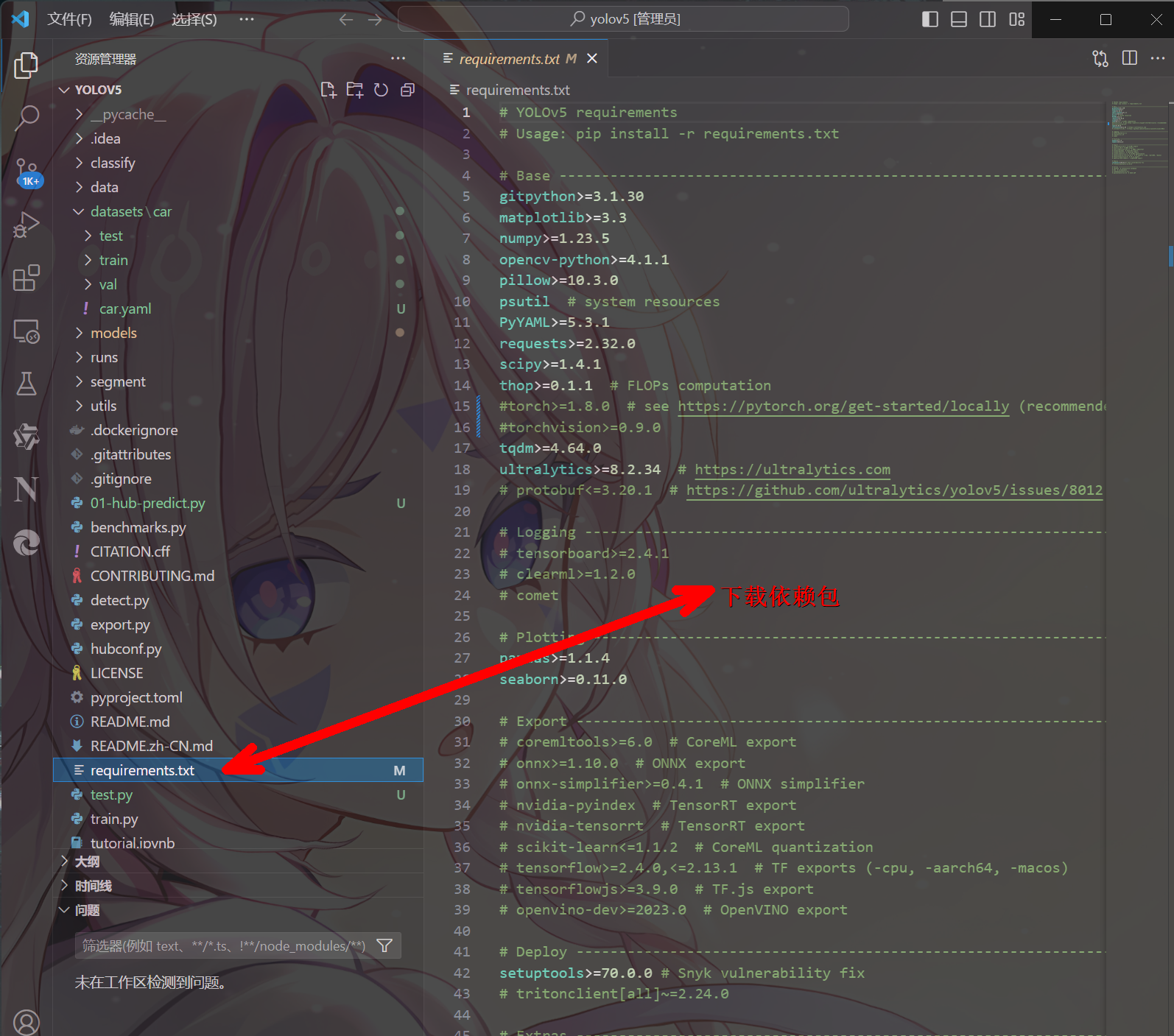
第三步:在 Python>=3.8.0 環境中安裝 requirements.txt,且要求 PyTorch>=1.8,命令pip install -r requirements.txt,可以加上鏡像地址提高下載速度,命令:pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple

- 詳細安裝的內容信息可以打開 yolov5 源碼中的 requirements.txt 文件查看
- **注意:**因為 pytorch 框架對應的內容,我們事先已經通過命令的方式安裝好了,所以在安裝 requirements.txt 內容之前,我們需要把安裝 pytorch 框架相關的內容注釋掉,如下:
4.2.4 下載推理文件
第四步:下載 yolov5 推理模型,地址https://github.com/ultralytics/yolov5/tree/master/models
- YOLOv5的一些主要模型變體:
- YOLOv5n:
- 這是最小的變體,適用于嵌入式設備或資源受限的環境
- 犧牲了一定的準確性以換取更快的速度
- YOLOv5s:選擇
- 較小的模型,適合在邊緣設備上使用
- 相比于更大的模型,它提供了更好的速度,但在精度上有所降低
- YOLOv5m:
- 中等大小的模型,平衡了速度和精度
- 適用于大多數常規硬件
- YOLOv5l:
- 較大的模型,提供了更高的檢測精度
- 在高端硬件上可以運行良好,但速度較慢
- YOLOv5x:
- 最大的模型,具有最高的精度
- 需要高性能的硬件來保證實時處理速度
- YOLOv5n:
- 各個模型測試速度參數:
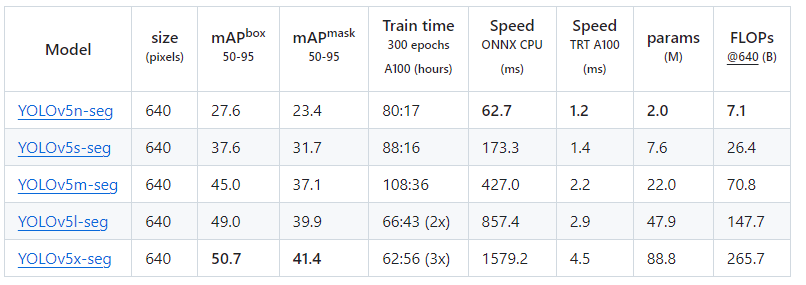
下載好模型后將其復制在主目錄下
4.2.5 常用命令
第五步:執行命令python detect.py --weights <weights_path> --source <source>,完成推理,結果默認保存到 runs/detect
| 參數 | 作用 | 示例與說明 |
|---|---|---|
detect.py | YOLOv5 提供的目標檢測腳本 | 運行檢測的主入口 |
--weights <weights_path> | 指定模型權重文件路徑 | --weights yolov5s.pt 使用 YOLOv5-s 預訓練權重 |
--source <source> | 指定輸入源,支持多種形式 | 見下表,按類型分列 |
| 輸入源類型 | 示例 | 說明 |
|---|---|---|
| 默認攝像頭 | 0 | 使用電腦默認攝像頭(內置或外接) |
| 單張圖像 | img.jpg | 直接指定一張圖片 |
| 單個視頻 | vid.mp4 | 直接指定一個視頻文件 |
| 屏幕截圖 | screen | 實時截取屏幕作為輸入(部分版本需驗證支持) |
| 目錄 | path/ | 目錄下所有支持的圖像/視頻文件均作為輸入 |
| 文本列表 | list.txt | 每行一個圖像/視頻路徑 |
| 流媒體列表 | list.streams | 每行一個流媒體鏈接 |
| Glob 模式 | 'path/*.jpg' | 匹配目錄下所有 .jpg 圖片 |
| YouTube 視頻 | 'https://youtu.be/LNwODJXcvt4' | 直接從 YouTube URL 讀取視頻流 |
| 網絡流 | 'rtsp://example.com/media.mp4' | 通過 RTSP / RTMP / HTTP 協議讀取實時或點播視頻 |
4.2.6 數據集
第六步:數據集標注
-
模型訓練的數據、驗證的數據都是由專門的人標注制作的,常用的標注工具labelImg、labelme。 這里介紹 labelImg 的使用
- 新建虛擬環境,略 -
激活環境,輸入命令
pip install labelimg -i https://pypi.tuna.tsinghua.edu.cn/simple安裝 labelimg 庫
在激活環境下,執行命令labelimg打開 labelimg
標注完成后的數據集,圖示: -
images:存放需要被標注的圖片信息
-
labels:存放標注的圖片的位置、類型信息
4.2.7 模型訓練
執行以下命令訓練模型,結果默認保存到 runs/train
python train.py --data .\data\coco.yaml --img 640 --epochs 25 --weights .\yolov5s.pt --cfg .\models\yolov5s.yaml --batch-size 2 --device 0
| 參數 | 說明 | 示例/取值解釋 |
|---|---|---|
train.py | 主訓練腳本:負責加載數據、構建模型、設置優化器、定義損失函數并執行訓練循環。 | 直接運行 python train.py … |
--data | 數據集配置文件路徑(YAML),內含訓練/驗證集路徑、類別數等信息。 | --data coco.yaml 或自定義 --data mydata.yaml |
--img | 輸入圖像尺寸(正方形邊長,像素)。 | --img 640 表示 640×640 |
--epochs | 訓練總輪數(完整遍歷數據集的次數)。 | --epochs 25 表示訓練 25 個 epoch |
--weights | 初始權重文件路徑;空串 '' 表示從零開始訓練。 | --weights ./yolov5s.pt 加載預訓練權重 |
--cfg | 模型架構配置文件路徑(YAML)。 | --cfg yolov5s.yaml 使用 YOLOv5-small 結構 |
--batch-size | 每輪迭代使用的樣本數量;越大越穩定,但顯存占用高。 | --batch-size 2 |
--device | 訓練設備選擇。 ? 0:第 0 塊 GPU? cpu:強制使用 CPU? -1:自動選擇可用 GPU | --device 0 |
-
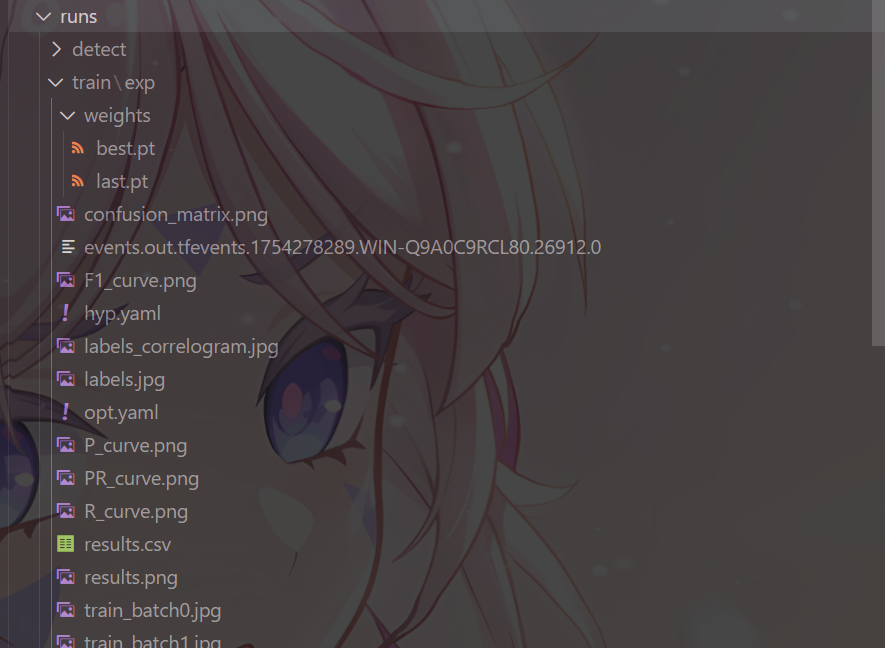
訓練結果,這個文件夾中包含了很多文件,重要內容如下:
-
weights 文件夾下,有兩個后綴名為
.pt的文件best.pt:表示在整個訓練過程中性能最佳的模型權重,用于推理last.pt:表示訓練結束時的最后一個模型權重,用于設置下次訓練基于這個基礎上繼續訓練,但是需要修改很多參數
4.2.8 恢復訓練
如果訓練過程中意外停止,在訓練指令后面加上 --resume 參數可以恢復訓練,并且不需要同時指定 --weights 參數。--resume 會自動加載最近一次保存的檢查點(包括模型權重、優化器狀態等)
python train.py --weights runs/train/exp/weights/last.pt --resume
4.2.9 導出onnx
python export.py --weights yolov5s.pt --img 640 --batch 1 --device 0 --include onnx
4.2.10 推理
使用 detect.run 進行推理:
from yolov5 import detect
detect.run(weights='yolov5s.onnx', # 權重文件路徑source='data/images', # 輸入源路徑img_size=640, # 輸入圖像尺寸conf_thres=0.25, # 置信度閾值iou_thres=0.45, # IoU閾值max_det=1000, # 最大檢測數量device='0', # 設備view_img=False, # 顯示檢測結果save_txt=False, # 保存檢測結果為txt文件save_conf=False, # 保存置信度到txt文件save_crop=False, # 裁剪并保存檢測到的對象nosave=False, # 保存圖像/視頻classes=None, # 檢測所有類agnostic_nms=False, # 類無關的非極大值抑制augment=False, # 推理增強visualize=False, # 可視化特征圖update=False, # 更新所有模型project='runs/detect', # 結果保存目錄name='exp', # 結果保存子目錄exist_ok=False, # 允許現有目錄line_thickness=3, # 畫框線條粗細hide_labels=False, # 隱藏標簽hide_conf=False, # 隱藏置信度half=False, # 半精度推理dnn=False # 使用OpenCV DNN模塊
)
4.2.11 onnx推理
import onnxruntime as ort
import numpy as np
import cv2# 創建ONNX Runtime推理會話
providers = ['CUDAExecutionProvider'] # ['CPUExecutionProvider'] 這是指定CPU
session = ort.InferenceSession('yolov5s.onnx', providers=providers)
# 讀取輸入圖像
img = cv2.imread('data/images/bus.jpg')
img = cv2.resize(img, (640, 640))
img = img.transpose((2, 0, 1)) # HWC to CHW
img = np.expand_dims(img, axis=0).astype(np.float32) / 255.0
# 進行推理
outputs = session.run(None, {'images': img})
print(outputs[0].shape)
4.3 模型應用
4.3.1 實例分割
下載yolov5s-seg.pt文件
python segment/predict.py --weights yolov5s-seg.pt --source data/images/bus.jpg
4.3.2 圖像分類
下載yolov5s-cls.pt文件
python classify/predict.py --weights yolov5s-cls.pt --source data/images/bus.jpg
五,優缺點
| 維度 | 優點 | 缺點 |
|---|---|---|
| 速度 | ? 單階段架構,推理極快,可達數百 FPS ? 輕量級,適合實時應用與邊緣部署 | ? 計算量仍高于 YOLOv8-nano 等輕量模型 |
| 精度 | ? COCO mAP≈56.8%,處于同期 SOTA 水平 ? 數據增強 + 自適應錨框,泛化能力較強 | ? 小目標檢測、密集重疊場景、旋轉/傾斜目標易漏檢 ? 極端遮擋、低光照環境下精度下降 |
| 模型與訓練 | ? 代碼開源完整,社區生態豐富 ? 支持多 scale 訓練、斷點續訓、混合精度 | ? anchor-based,需預設錨框,對形狀不規則目標不友好 ? 在新數據集上往往需要額外微調 |
| 部署 | ? 支持 ONNX、TensorRT、OpenVINO、ncnn 等多種格式,跨平臺方便 | ? 對顯存/內存仍有要求,極低算力嵌入式設備需做剪枝或量化 |
| 易用性 | ? pip 一鍵安裝,命令行/腳本接口簡單 | ? 超參數較多,新手調參門檻高于 YOLOv8 的“零參”模式 |







:重構威脅追溯體系)




![[特殊字符] TTS格局重塑!B站推出Index-TTS,速度、音質、情感表達全維度領先](http://pic.xiahunao.cn/[特殊字符] TTS格局重塑!B站推出Index-TTS,速度、音質、情感表達全維度領先)






