目錄
一、概述
(一)series
1、組成
2、創建方式
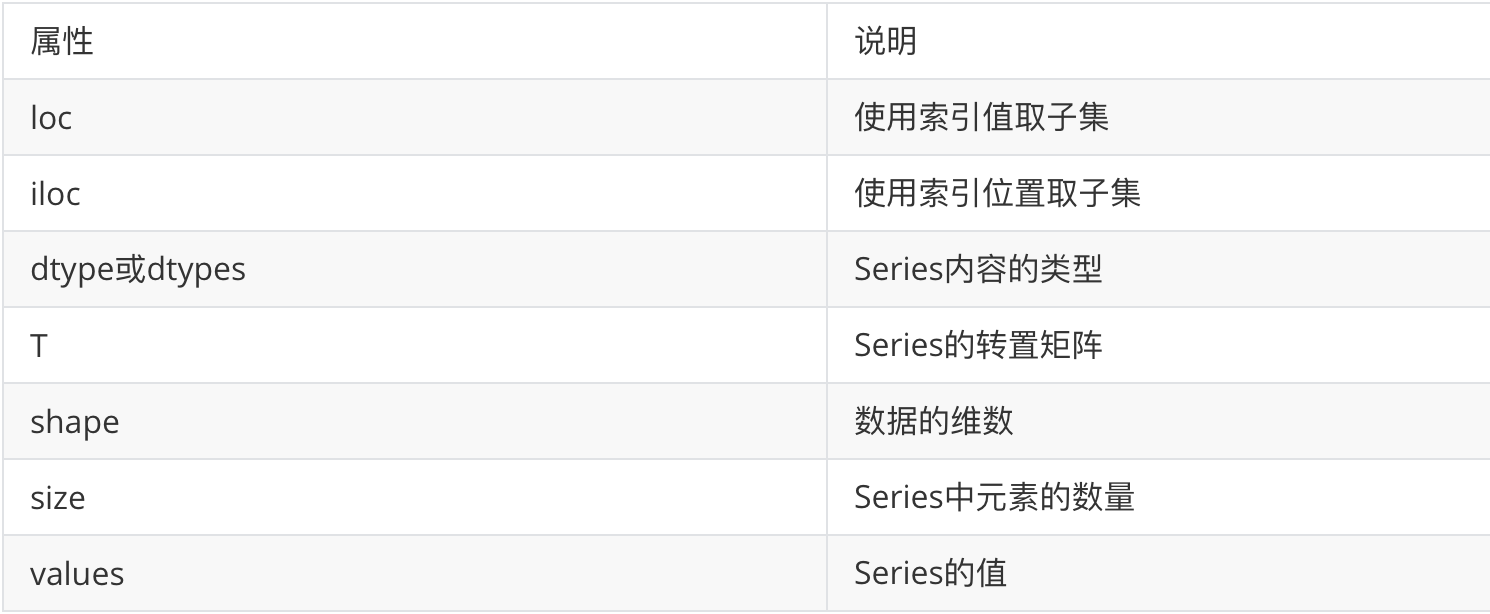
3、Series常用屬性
(二)DataFrame
1、組成:
2、構建方式
(三)數據導入和導出
二、加載數據集
加載部分數據
loc / iloc
三、分組和聚合計算
需求1:查詢每個大洲的平均年齡壽命
需求2:查詢各大洲的平均年齡和平均GDP
需求3:查詢各個大洲和國家各自的,平均年齡壽命和平均GDP
需求4:查詢各個大洲的,平均和最大GDP、年齡
需求5:查詢各個大洲的,平均GDP和最大年齡
需求6:每個大洲列出了多少個國家和地區(去重)
需求7:去重后,打印所有國家個數/打印所有國家名稱(去重后)
四、matplotlib繪圖
數據集網盤下載:
鏈接:https://pan.quark.cn/s/0e577858dba3?pwd=FJnb
提取碼:FJnb
一、概述
- DataFrame和Series是Pandas最基本的兩種數據結構
- Series和Python中的列表非常相似,但是它的每個元素的數據類型必須相同
- 在Pandas中,Series是一維容器,Series表示DataFrame的每一行或每一列
- 可以把DataFrame理解成一張表
- 可以把DataFrame看作由Series對象組成的字典,其中key是列名,值是Series
(一)series
1、組成
- 索引(一組與之關聯的標簽,如果不顯式的提供索引,pandas會自動創建一個從0開始的整數索引)
- 數據(一組值(可以是任意numPy支持的數據類型:int、float、string等);
2、創建方式
????????注意:index參數可以覆蓋自動創建的索引序列(自定義)
- 通過字典的方式創建
import pandas as pd s = pd.Series({'a':1,'b':2,'c':3,'d':4,'e':5}) print(s) print(type(s)) - 通過ndarray方式創建
import pandas as pd s = pd. Series([1,2,3,4,5]) print(s) print(type(s)) - 通過python的list方式創建
import pandas as pd import numpy as np arr = np.array([1,2,3,4,5]) print(arr) print(type(arr)) s = pd.Series(arr) print(s) print(type(s)) - 通過元祖對象的方式創建
import pandas as pd s = pd.Series((1,2,3,4,5)) print(s) print(type(s))
3、Series常用屬性
# 1.導入pandas模塊
import pandas as pd
import osprint(os.getcwd())
print("-------------------------------------------")# 2.創建series,創建一個csv文件
# 使用read_csv函數,返回的是DataFrame對象,而不是Series對象
df = pd.read_csv('data/nobel_prizes.csv', index_col='id')
# print(df.head()) # 獲取前5行數據# 3.創建series
# 獲取第一行數據
first = df.iloc[0]
print(first) # 獲取第一行數據
print("-------------------------------------------")
print(type(first))
print("-------------------------------------------")
print(first.dtype) # 獲取數據類型
print("-------------------------------------------")
print(first['year'],first['year'].dtype)
print("-------------------------------------------")
print(first.shape)
print("-------------------------------------------")
print(first.size)
print("-------------------------------------------")
print(first.index)
print("-------------------------------------------")
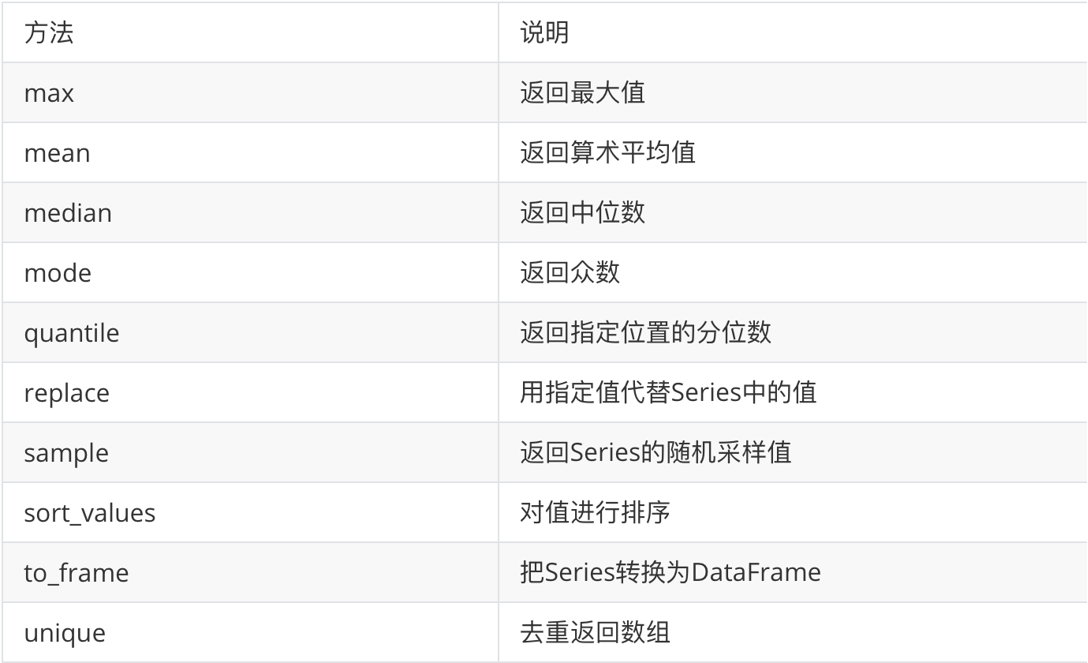
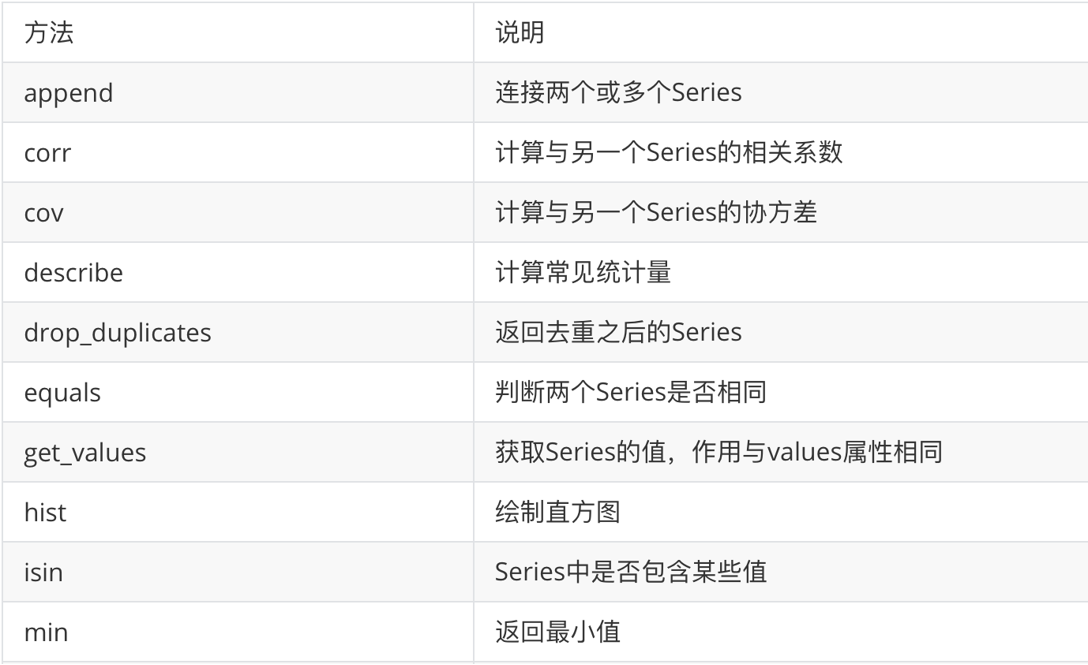
print(first.values)- 常用方法
# 1:導入pandas模塊
import pandas as pd# 2: 創建series對象
s1 = pd.Series([1, 2, 3, 4, 2, 3], index=['a', 'b', 'c', 'd', 'e', 'f'])
# """
# 核心區別:
# 形式 類型 行為 返回值
# s1.max 方法對象(沒有被調用) 返回方法本身 <bound method Series.max of
# s1.max() 方法調用 執行計算操作 實際的最大值
# """
# print(s1.max)
# print(s1.max())
# print(s1.size)
# print(s1.min())
print(s1)print(s1.max)
print("--------------")
print(s1.max())
print("--------------")
print(s1.to_list()) # [1, 2, 3, 4, 2, 3]
print("--------------")
print(s1.to_list) # [1, 2, 3, 4, 2, 3]# 3:演示series的常用方法
print(len(s1)) # 6
print(s1.size) # 6
print(s1.head()) # 默認打印前五條
print(s1.head(3)) # 打印前3條
print(s1.tail()) # 默認打印后5條
print(s1.tail(3)) # 打印后3條
print(s1.index) # Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')
print(s1.keys()) # Index(['a', 'b', 'c', 'd', 'e', 'f'], dtype='object')
print(s1.values) # [1 2 3 4 2 3]
print(s1.to_list()) # [1, 2, 3, 4, 2, 3]
print(type(s1.to_list())) # <class 'list'>print("---------------------------")
print(s1.describe()) # 統計信息
print(s1.max()) # 獲取series的元素最大值
print(s1.min()) # 獲取series的元素最小值
print(s1.mean()) # 獲取series的元素平均值
print(s1.median()) # 獲取series的元素中位數
print(s1.mode()) # 獲取series的元素眾數
print(s1.std()) # 獲取series的元素標準差print("---------------------------")
print(s1.drop_duplicates())# 刪除重復的元素
print(s1.sort_values())# 排序,根據值排序,默認是升序
print(s1.sort_values())# 排序,根據值排序,默認是升序
print(s1.sort_values(ascending=False))# 排序,根據值排序,降序
print(s1.sort_index()) # 排序,根據索引排序,默認是升序
print(s1.sort_index(ascending=False)) # 排序,根據索引排序,降序
print(s1.unique()) # 去重
print(s1.value_counts()) # 統計每個元素出現的次數(二)DataFrame
- 可以看成是一個二維表格(行列),類似于Excel表格
- 每一列就是一個series,所有列共享一個索引
1、組成:
- 列: 每一列就是一個series,所有的列共享同一個索引
- 行: 由索引標記的每一行數據(行索引)
- 索引: 行的標簽,稱之為行索引,如果不指定,pandas會自動創建(0,1,2....)
- 列索引(column): 列的標簽,也稱為列名。
2、構建方式
使用字典來創建DataFrame
import pandas as pd
s = {'name':['張三','李四','王五'],'age':[18,19,31],'sex':['男','女','男']}
df = pd.DataFrame(s)
print(df)
print(type(df))創建DataFrame的時指定列的順序和行索引
# 創建DataFrame的時指定列的順序和行索引
import pandas as pd
df = pd.DataFrame({'name':['張三','李四','王五'],'age':[18,19,31],'sex':['男','女','男']},index=['a','b','c'],columns=['name','age','sex','id'])
print(df)
print(type(df))(三)數據導入和導出
1、保存pickle文件
????????可以使用pd.read_pickle函數讀取.pickle文件中的數據
import pandas as pd
# 讀取movie.csv文件
movie_fd = pd.read_csv('data/movie.csv')
# 將讀取的數據保存為pickle文件
movie_fd.to_pickle('data/movie.pickle')
movie_fd.head()
2、保存csv文件
????????在CSV文件中,對于每一行,各列采用逗號分隔
????????CSV是數據協作和共享的首選格式
import pandas as pd
movie_fd.to_csv('data/movie2.csv')
movie_fd2 = pd.read_csv('data/movie2.csv')
movie_fd2.head()二、加載數據集
目的:
? ? ? ? 1、做數據分析首先要加載數據,并查看其結構和內容,對數據有初步的了解
? ? ? ? 2、查看行,列數據分布情況
? ? ? ? 3、查看每一列中存儲信息的類型
import pandas as pddata = pd.read_csv('data/movie.csv') # 讀取數據
print(data.head()) # 查看前5行數據# 也可以通過指定分隔符加載tsv文件
data = pd.read_csv('data/gapminder.tsv', sep='\t')
data.head()加載部分數據
加載一列數據,通過df['列名']方式獲取
print(df['movie_title'])加載多列數據,通過df[['列名1','列名2',...]]
print(df[['movie_title', 'imdb_score']])獲取第4行數據
獲取第1行和第62行和83行數據
print(df.loc[[3]])
print(df.loc[[0, 61, 82]]) loc / iloc
需要注意的是,iloc傳入的是索引的序號,loc是索引的標簽
????????如果loc 和 iloc 傳入的參數弄混了,會報錯
loc 只能接受行/列 的名字,iloc只能接受行/列的序號
# 獲取第1行和第62行和83行數據
print(df.iloc[[0, 61, 82]])
# 獲取前3行數據
print(df.iloc[:3])
# 使用iloc時可以傳入-1來獲取最后一行數據,使用loc的時候不行
print(df.iloc[[-1]])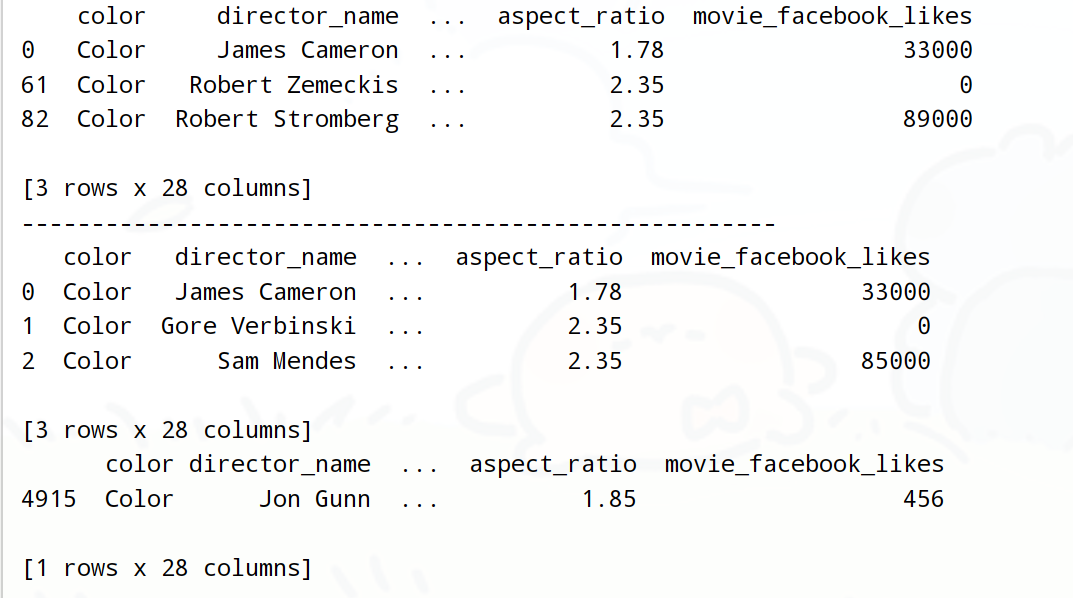
import pandas as pddf = pd.read_csv('data/scientists.csv')print(df.loc[0, ['Name', 'Age', 'Born']]) # 獲取第1行數據的三列數據
print("-----------------------------------------------------------------------")
print(df.loc[[0, 1], ['Name', 'Age', 'Born']]) # 獲取第1行和第2行數據,三列數據
print("-----------------------------------------------------------------------")
tmp_range = list(range(3, 5))
print(tmp_range) # 獲取連續多列數據
print(df.iloc[:, tmp_range])
print("-----------------------------------------------------------------------")
print(df.iloc[0, 1]) # 獲取第1行第2列數據
print("-----------------------------------------------------------------------")
print(df.iloc[[0, 1, 5], [1, 2]]) # 獲取第1行和第2行第6行、第2列和第3列數據
print("-----------------------------------------------------------------------")
print(df.iloc[0:3, 0:3]) # 獲取第1行到第3行、第1列到第3列數據
print("-----------------------------------------------------------------------")
print(df.iloc[:, 1:5:2]) # 獲取第2列到第5列、步長為2的數據
print("-----------------------------------------------------------------------")
# 獲取第1列、第3列、第4列的數據
print(df.iloc[:, [True, False, True, True, False]])知識點總結

三、分組和聚合計算
需求1:查詢每個大洲的平均年齡壽命
# 分組操作
print(df.groupby('continent'))
# 寫法一
print(df.groupby('continent')['lifeExp'].mean())
print("--------------------------------------------------")
# 寫法二
print(df.groupby('continent').lifeExp.mean())需求2:查詢各大洲的平均年齡和平均GDP
print(df.groupby('continent')[['lifeExp','gdpPercap']].mean())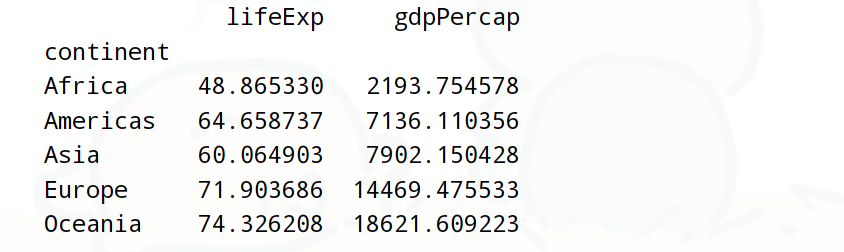
需求3:查詢各個大洲和國家各自的,平均年齡壽命和平均GDP
print(df.groupby(['continent','country'])[['lifeExp','gdpPercap']].mean())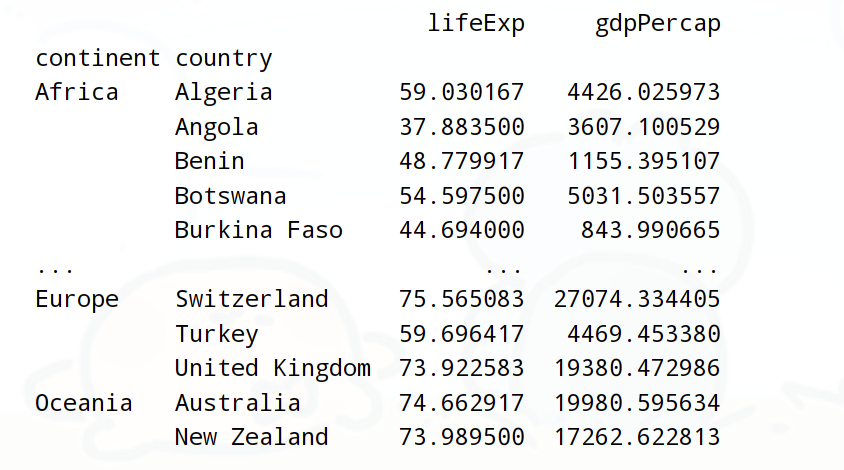
需求4:查詢各個大洲的,平均和最大GDP、年齡
# 寫法1:
print(df.groupby('continent')[['lifeExp','gdpPercap']].aggregate(['mean','max']))
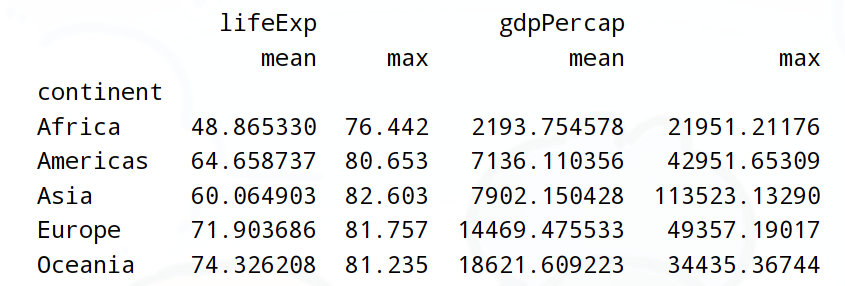
需求5:查詢各個大洲的,平均GDP和最大年齡
# 寫法2:
print(df.groupby('continent').aggregate({'lifeExp':'mean','gdpPercap':'max'}))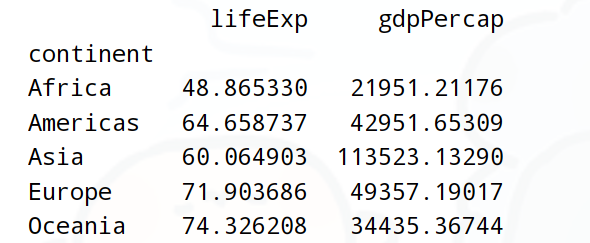
需求6:每個大洲列出了多少個國家和地區(去重)
print(df.groupby('continent')['country'].nunique())
print("--------------------------------------------------")
# 每個大洲列出了多少個國家(不去重)
print(df.groupby('continent')['country'].size())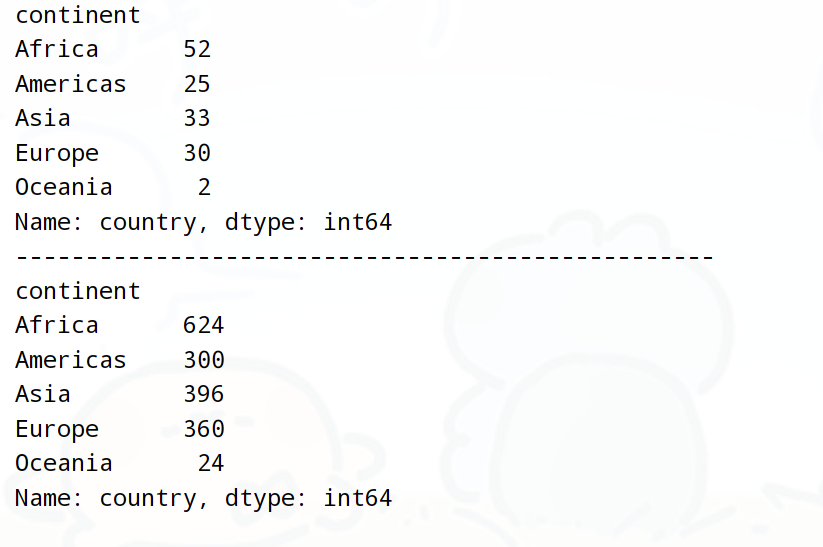
需求7:去重后,打印所有國家個數/打印所有國家名稱(去重后)
print(df['country'].nunique())
print(df['country'].unique()) 運行結果:
142
['Afghanistan' 'Albania' 'Algeria' 'Angola' 'Argentina' 'Australia''Austria' 'Bahrain' 'Bangladesh' 'Belgium' 'Benin' 'Bolivia''Bosnia and Herzegovina' 'Botswana' 'Brazil' 'Bulgaria' 'Burkina Faso''Burundi' 'Cambodia' 'Cameroon' 'Canada' 'Central African Republic''Chad' 'Chile' 'China' 'Colombia' 'Comoros' 'Congo, Dem. Rep.''Congo, Rep.' 'Costa Rica' "Cote d'Ivoire" 'Croatia' 'Cuba''Czech Republic' 'Denmark' 'Djibouti' 'Dominican Republic' 'Ecuador''Egypt' 'El Salvador' 'Equatorial Guinea' 'Eritrea' 'Ethiopia' 'Finland''France' 'Gabon' 'Gambia' 'Germany' 'Ghana' 'Greece' 'Guatemala' 'Guinea''Guinea-Bissau' 'Haiti' 'Honduras' 'Hong Kong(China)' 'Hungary' 'Iceland''India' 'Indonesia' 'Iran' 'Iraq' 'Ireland' 'Israel' 'Italy' 'Jamaica''Japan' 'Jordan' 'Kenya' 'Korea, Dem. Rep.' 'Korea, Rep.' 'Kuwait''Lebanon' 'Lesotho' 'Liberia' 'Libya' 'Madagascar' 'Malawi' 'Malaysia''Mali' 'Mauritania' 'Mauritius' 'Mexico' 'Mongolia' 'Montenegro''Morocco' 'Mozambique' 'Myanmar' 'Namibia' 'Nepal' 'Netherlands''New Zealand' 'Nicaragua' 'Niger' 'Nigeria' 'Norway' 'Oman' 'Pakistan''Panama' 'Paraguay' 'Peru' 'Philippines' 'Poland' 'Portugal''Puerto Rico' 'Reunion' 'Romania' 'Rwanda' 'Sao Tome and Principe''Saudi Arabia' 'Senegal' 'Serbia' 'Sierra Leone' 'Singapore''Slovak Republic' 'Slovenia' 'Somalia' 'South Africa' 'Spain' 'Sri Lanka''Sudan' 'Swaziland' 'Sweden' 'Switzerland' 'Syria' 'Taiwan(China)''Tanzania' 'Thailand' 'Togo' 'Trinidad and Tobago' 'Tunisia' 'Turkey''Uganda' 'United Kingdom' 'United States' 'Uruguay' 'Venezuela' 'Vietnam''West Bank and Gaza' 'Yemen, Rep.' 'Zambia' 'Zimbabwe']四、matplotlib繪圖
import pandas as pd
import matplotlib.pyplot as pltdf = pd.read_csv('data/gapminder.tsv', sep='\t')
globals_yearly_life_expectancy = df.groupby('year')['lifeExp'].mean()
print(globals_yearly_life_expectancy)
globals_yearly_life_expectancy.plot()
plt.show()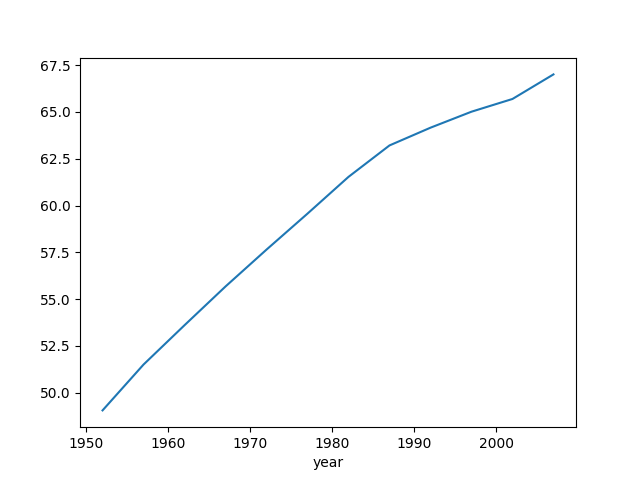





上部署Oracle 11g、19C RAC詳細圖文教程)


)
![6-7 TIM編碼器接口 [江科協STM32]](http://pic.xiahunao.cn/6-7 TIM編碼器接口 [江科協STM32])


)



 Python + 地球信息科學與技術 = 經典案例分析)


