作業:
kaggle找到一個圖像數據集,用cnn網絡進行訓練并且用grad-cam做可視化
劃分數據集
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import os
from sklearn.model_selection import train_test_split
from shutil import copyfile
import cv2
from torch.nn import functional as F# 數據集劃分
data_root = "flowers" # 數據集根目錄
classes = ["daisy", "tulip", "rose", "sunflower", "dandelion"]for folder in ["train", "val", "test"]:os.makedirs(os.path.join(data_root, folder), exist_ok=True)for cls in classes:cls_path = os.path.join(data_root, cls)imgs = [f for f in os.listdir(cls_path) if f.lower().endswith((".jpg", ".jpeg", ".png"))]# 劃分數據集(測試集20%,驗證集20% of 剩余數據,訓練集60%)train_val, test = train_test_split(imgs, test_size=0.2, random_state=42)train, val = train_test_split(train_val, test_size=0.25, random_state=42)# 復制到train/val/test下的類別子文件夾(關鍵修正!)for split, imgs_list in zip(["train", "val", "test"], [train, val, test]):split_class_path = os.path.join(data_root, split, cls)# 創建子文件夾:train/chamomile/os.makedirs(split_class_path, exist_ok=True)for img in imgs_list:copyfile(os.path.join(cls_path, img), os.path.join(split_class_path, img))數據預處理
# 數據預處理(新增旋轉增強)# 設置中文字體支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解決負號顯示問題# 檢查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")print(f"使用設備: {device}")# 訓練集數據增強(彩色圖像通用處理)
train_transform = transforms.Compose([transforms.Resize((224, 224)), # 調整尺寸為224x224(匹配CNN輸入)transforms.RandomCrop(224, padding=4), # 隨機裁剪并填充,增加數據多樣性transforms.RandomHorizontalFlip(), # 水平翻轉(概率0.5)transforms.RandomRotation(15), # 新增旋轉transforms.ColorJitter(brightness=0.2, contrast=0.2), # 顏色抖動transforms.ToTensor(), # 轉換為張量transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225)) # ImageNet標準歸一化
])# 測試集僅歸一化,不增強
test_transform = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
]))加載數據集
# 數據加載器(保持不變)data_root = "flowers" # 數據集根目錄,需包含5個子類別文件夾train_dataset = datasets.ImageFolder(os.path.join(data_root, "train"), transform=train_transform)val_dataset = datasets.ImageFolder(os.path.join(data_root, "val"), transform=test_transform)test_dataset = datasets.ImageFolder(os.path.join(data_root, "test"), transform=test_transform)# 創建數據加載器
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=2)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=2)# 獲取類別名稱(自動從文件夾名獲取)
class_names = train_dataset.classesprint(f"檢測到的類別: {class_names}") # 確保輸出5個類別名稱定義模型
# 模型定義(新增第4卷積塊)
class FlowerCNN(nn.Module):def __init__(self, num_classes=5):super().__init__()# 卷積塊1self.conv1 = nn.Conv2d(3, 32, 3, padding=1)self.bn1 = nn.BatchNorm2d(32)self.relu1 = nn.ReLU()self.pool1 = nn.MaxPool2d(2, 2) # 224→112# 卷積塊2self.conv2 = nn.Conv2d(32, 64, 3, padding=1)self.bn2 = nn.BatchNorm2d(64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(2, 2) # 112→56# 卷積塊3self.conv3 = nn.Conv2d(64, 128, 3, padding=1)self.bn3 = nn.BatchNorm2d(128)self.relu3 = nn.ReLU()self.pool3 = nn.MaxPool2d(2, 2) # 56→28# 卷積塊4self.conv4 = nn.Conv2d(128, 256, 3, padding=1) # 新增卷積塊self.bn4 = nn.BatchNorm2d(256)self.relu4 = nn.ReLU()self.pool4 = nn.MaxPool2d(2, 2) # 28→14# 全連接層self.fc1 = nn.Linear(256 * 14 * 14, 512) # 計算方式:224->112->56->28->14(四次池化后尺寸)self.dropout = nn.Dropout(0.5)self.fc2 = nn.Linear(512, num_classes) # 輸出5個類別def forward(self, x):x = self.pool1(self.relu1(self.bn1(self.conv1(x))))x = self.pool2(self.relu2(self.bn2(self.conv2(x))))x = self.pool3(self.relu3(self.bn3(self.conv3(x))))x = self.pool4(self.relu4(self.bn4(self.conv4(x)))) # 新增池化x = x.view(x.size(0), -1) # 展平特征圖x = self.dropout(self.relu1(self.fc1(x)))x = self.fc2(x)return x# 初始化模型并移至設備# 訓練配置(增加輪數,使用StepLR)
model = FlowerCNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)訓練模型
def train_model(epochs=30):best_val_acc = 0.0train_loss, val_loss, train_acc, val_acc = [], [], [], []for epoch in range(epochs):model.train()running_loss, correct, total = 0.0, 0, 0for data, target in train_loader:data, target = data.to(device), target.to(device)optimizer.zero_grad()outputs = model(data)loss = criterion(outputs, target)loss.backward()optimizer.step()running_loss += loss.item()_, pred = torch.max(outputs, 1)correct += (pred == target).sum().item()total += target.size(0)# 計算 epoch 指標epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100 * correct / total# 驗證集評估model.eval()val_running_loss, val_correct, val_total = 0.0, 0, 0with torch.no_grad():for data, target in val_loader:data, target = data.to(device), target.to(device)outputs = model(data)val_running_loss += criterion(outputs, target).item()_, pred = torch.max(outputs, 1)val_correct += (pred == target).sum().item()val_total += target.size(0)epoch_val_loss = val_running_loss / len(val_loader)epoch_val_acc = 100 * val_correct / val_totalscheduler.step()# 記錄歷史數據train_loss.append(epoch_train_loss)val_loss.append(epoch_val_loss)train_acc.append(epoch_train_acc)val_acc.append(epoch_val_acc)print(f"Epoch {epoch+1}/{epochs} | 訓練損失: {epoch_train_loss:.4f} 驗證準確率: {epoch_val_acc:.2f}%")# 保存最佳模型if epoch_val_acc > best_val_acc:torch.save(model.state_dict(), "best_model.pth")best_val_acc = epoch_val_acc# 繪制曲線plt.figure(figsize=(12, 4))# 損失曲線plt.subplot(1, 2, 1); plt.plot(train_loss, label='訓練損失'); plt.plot(val_loss, label='驗證損失'); plt.legend()# 準確率曲線plt.subplot(1, 2, 2); plt.plot(train_acc, label='訓練準確率'); plt.plot(val_acc, label='驗證準確率'); plt.legend()plt.show()return best_val_acc# 訓練與可視化(保持不變)
print("開始訓練...")
train_model(epochs=30)
print("訓練完成,開始可視化...")開始訓練...
Epoch 1/30 | 訓練損失: 5.8699 驗證準確率: 47.05%
Epoch 2/30 | 訓練損失: 1.3307 驗證準確率: 53.76%
Epoch 3/30 | 訓練損失: 1.3045 驗證準確率: 52.95%
Epoch 4/30 | 訓練損失: 1.2460 驗證準確率: 55.38%
Epoch 5/30 | 訓練損失: 1.2342 驗證準確率: 49.48%
Epoch 6/30 | 訓練損失: 1.2442 驗證準確率: 54.10%
Epoch 7/30 | 訓練損失: 1.2309 驗證準確率: 50.75%
Epoch 8/30 | 訓練損失: 1.2172 驗證準確率: 56.65%
Epoch 9/30 | 訓練損失: 1.2025 驗證準確率: 56.53%
Epoch 10/30 | 訓練損失: 1.1733 驗證準確率: 56.53%
Epoch 11/30 | 訓練損失: 1.1167 驗證準確率: 61.04%
Epoch 12/30 | 訓練損失: 1.0763 驗證準確率: 64.28%
Epoch 13/30 | 訓練損失: 1.0564 驗證準確率: 63.12%
Epoch 14/30 | 訓練損失: 1.0469 驗證準確率: 62.31%
Epoch 15/30 | 訓練損失: 1.0295 驗證準確率: 65.09%
Epoch 16/30 | 訓練損失: 1.0365 驗證準確率: 65.78%
Epoch 17/30 | 訓練損失: 1.0091 驗證準確率: 66.71%
Epoch 18/30 | 訓練損失: 1.0152 驗證準確率: 65.32%
Epoch 19/30 | 訓練損失: 0.9794 驗證準確率: 65.43%
Epoch 20/30 | 訓練損失: 0.9875 驗證準確率: 68.90%
Epoch 21/30 | 訓練損失: 0.9496 驗證準確率: 69.94%
Epoch 22/30 | 訓練損失: 0.9608 驗證準確率: 69.71%
Epoch 23/30 | 訓練損失: 0.9342 驗證準確率: 69.71%
Epoch 24/30 | 訓練損失: 0.9586 驗證準確率: 69.25%
Epoch 25/30 | 訓練損失: 0.9554 驗證準確率: 69.60%
Epoch 26/30 | 訓練損失: 0.9463 驗證準確率: 69.83%
Epoch 27/30 | 訓練損失: 0.9373 驗證準確率: 69.94%
Epoch 28/30 | 訓練損失: 0.9282 驗證準確率: 69.48%
Epoch 29/30 | 訓練損失: 0.9130 驗證準確率: 69.36%
Epoch 30/30 | 訓練損失: 0.9585 驗證準確率: 69.94%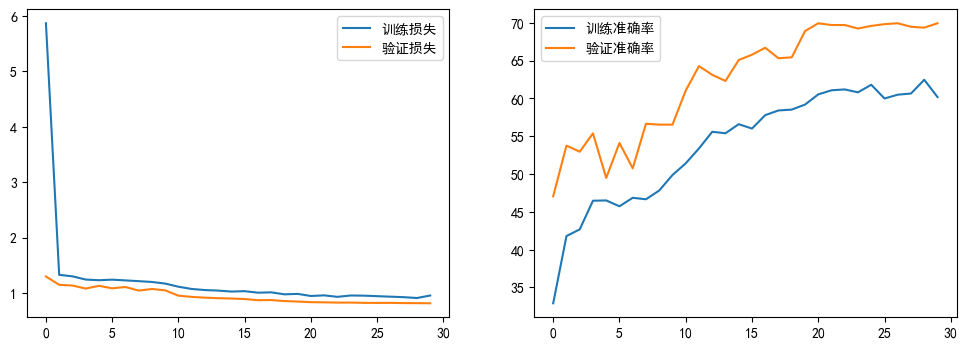
Grad-CAM可視化
class GradCAM:def __init__(self, model, target_layer_name="conv3"):self.model = model.eval() # 設置模型為評估模式self.target_layer_name = target_layer_name # 目標卷積層名稱(需與模型定義一致)self.gradients, self.activations = None, None # 存儲梯度,激活值# 注冊前向和反向鉤子函數for name, module in model.named_modules():if name == target_layer_name:module.register_forward_hook(self.forward_hook)module.register_backward_hook(self.backward_hook)breakdef forward_hook(self, module, input, output):"""前向傳播時保存激活值"""self.activations = output.detach() # 不記錄梯度的激活值def backward_hook(self, module, grad_input, grad_output):"""反向傳播時保存梯度"""self.gradients = grad_output[0].detach() # 提取梯度(去除批量維度)def generate(self, input_image, target_class=None):"""生成Grad-CAM熱力圖"""# 前向傳播獲取模型輸出outputs = self.model(input_image) # 輸出形狀: [batch_size, num_classes]target_class = torch.argmax(outputs, dim=1).item() if target_class is None else target_class# 反向傳播計算梯度self.model.zero_grad()one_hot = torch.zeros_like(outputs); one_hot[0, target_class] = 1outputs.backward(gradient=one_hot)# 計算通道權重(全局平均池化)weights = torch.mean(self.gradients, dim=(2, 3))# 生成類激活映射(CAM)cam = torch.sum(self.activations[0] * weights[0][:, None, None], dim=0)cam = F.relu(cam); cam = (cam - cam.min()) / (cam.max() - cam.min() + 1e-8) cam = F.interpolate(cam.unsqueeze(0).unsqueeze(0), size=(224, 224), mode='bilinear').squeeze()return cam.cpu().numpy(), target_class# 可視化函數(關鍵修改:增加圖像尺寸統一和顏色通道轉換)
def visualize_gradcam(img_path, model, class_names, alpha=0.6):"""可視化Grad-CAM結果:param img_path: 測試圖像路徑:param model: 訓練好的模型:param class_names: 類別名稱列表:param alpha: 熱力圖透明度(0-1)"""# 加載圖像并統一尺寸為224x224(解決尺寸不匹配問題)img = Image.open(img_path).convert("RGB").resize((224, 224))img_np = np.array(img) / 255.0# 預處理圖像(與模型輸入一致)transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])input_tensor = transform(img).unsqueeze(0).to(device)# 生成Grad-CAM熱力圖grad_cam = GradCAM(model, target_layer_name="conv3")heatmap, pred_class = grad_cam.generate(input_tensor)# 熱力圖后處理(解決顏色通道問題)heatmap = np.uint8(255 * heatmap); heatmap = cv2.applyColorMap(heatmap, cv2.COLORMAP_JET) / 255.0; heatmap_rgb = heatmap[:, :, ::-1]# 疊加原始圖像和熱力圖(尺寸和通道完全匹配)superimposed = cv2.addWeighted(img_np, 1 - alpha, heatmap, alpha, 0)# 繪制結果plt.figure(figsize=(12, 4))plt.subplot(1, 3, 1); plt.imshow(img_np); plt.title(f"原始圖像\n真實類別: {img_path.split('/')[-2]}"); plt.axis('off')plt.subplot(1, 3, 2); plt.imshow(heatmap_rgb); plt.title(f"Grad-CAM熱力圖\n預測類別: {class_names[pred_class]}"); plt.axis('off')plt.subplot(1, 3, 3); plt.imshow(superimposed); plt.title("疊加熱力圖"); plt.axis('off')plt.tight_layout(); plt.show()# 選擇測試圖像(需存在且路徑正確)
test_image_path = "flowers/tulip/100930342_92e8746431_n.jpg" # 執行可視化
visualize_gradcam(test_image_path, model, class_names)
@浙大疏錦行



















