卷積神經網絡是一種專門用于處理具有網格結構數據(如圖像、音頻等)的深度學習模型。它通過卷積層自動提取數據中的特征,利用局部連接和參數共享的特性減少了模型的參數數量,降低了過擬合的風險,同時能夠有效地捕捉數據中的空間層次結構信息,使得模型在圖像識別、分類等任務中表現出色。而 LeNet 作為 CNN 的經典代表,具有開創性的意義。
LeNet 由 Yann LeCun 等人在 1998 年提出,最初是用于手寫數字識別任務。它的出現為后續 CNN 的發展奠定了基礎,展示了 CNN 在圖像識別領域的巨大潛力,引領了深度學習在圖像處理方面的發展潮流。
一般來說,高寬減少時,會把通道數加倍。即可以理解為:特征分成兩份。(紅且大==>紅 + 大)
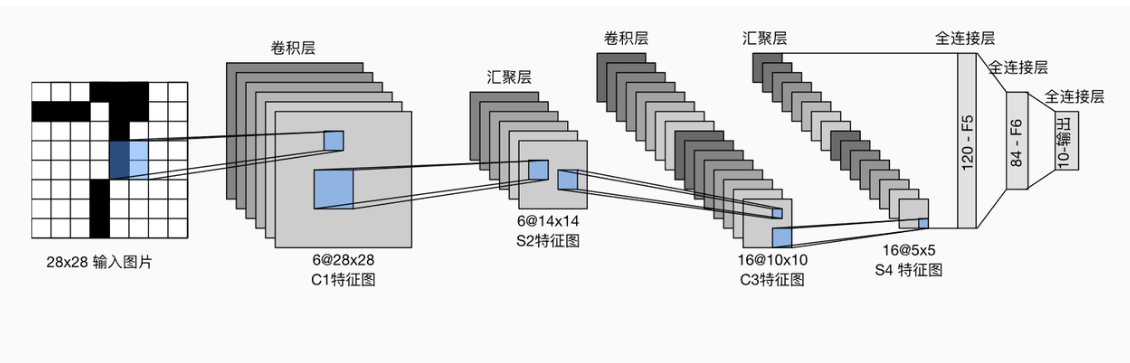
總體來看,LeNet(LeNet-5)由兩個部分組成:
卷積編碼器:由兩個卷積層組成;
全連接層密集塊:由三個全連接層組成。

網絡結構組成
輸入層:接收原始的手寫數字圖像,通常是 32×32 像素的灰度圖像。
卷積層1(C1):包含 6 個 5×5 的卷積核,用于提取圖像的邊緣、線條等低級特征。每個卷積核與輸入圖像進行卷積操作,產生 6 個特征圖,每個特征圖的大小為 28×28。卷積操作通過滑動窗口的方式對圖像進行掃描,計算卷積核與窗口內像素值的點積,從而實現特征提取。
池化層1(S2):采用平均池化,池化窗口大小為 2×2,步長為 2。對 C1 層輸出的 6 個特征圖分別進行池化操作,將每個特征圖的大小縮小為 14×14。池化的作用是降低特征圖的空間分辨率,減少計算量和參數數量,同時具有一定的平移不變性,使模型對圖像的微小位移具有魯棒性。
卷積層2(C3):包含 16 個 5×5 的卷積核,這些卷積核不僅與 S2 層的部分特征圖相連,而且每個卷積核連接的特征圖組合不同。這樣的設計可以提取更高級的特征,如紋理、角點等組合特征。卷積操作后得到 16 個大小為 10×10 的特征圖。
池化層2(S4):同樣采用平均池化,池化窗口大小為 2×2,步長為 2。對 C3 層的 16 個特征圖進行池化,得到 16 個 5×5 的特征圖。進一步縮小特征圖尺寸,提取更具有語義信息的特征。
全連接層(F5):將 S4 層輸出的 16 個 5×5 特征圖展平成一個向量,包含 400 個神經元。然后與本層的 120 個神經元進行全連接,主要用于對提取到的高級特征進行進一步的組合和抽象,實現更復雜的識別。
全連接層(F6):包含 84 個神經元,與前一層的 120 個神經元全連接。在實際應用中,根據具體的任務需求,如手寫數字識別,該層可以進一步連接到輸出層,即全連接層F7,輸出對應類別的概率分布,例如對于 10 個數字類別(0 - 9),輸出層可以使用 softmax 激活函數計算每個數字的概率。
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5, padding=2), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, kernel_size=5), nn.Sigmoid(),nn.AvgPool2d(kernel_size=2, stride=2),nn.Flatten(),nn.Linear(16 * 5 * 5, 120), nn.Sigmoid(),nn.Linear(120, 84), nn.Sigmoid(),nn.Linear(84, 10))
X = torch.rand(size=(1, 1, 28, 28), dtype=torch.float32)
for layer in net:X = layer(X)print(layer.__class__.__name__,'output shape: \t',X.shape)輸出:
Conv2d output shape: torch.Size([1, 6, 28, 28])
Sigmoid output shape: torch.Size([1, 6, 28, 28])
AvgPool2d output shape: torch.Size([1, 6, 14, 14])Conv2d output shape: torch.Size([1, 16, 10, 10])
Sigmoid output shape: torch.Size([1, 16, 10, 10])
AvgPool2d output shape: torch.Size([1, 16, 5, 5])Flatten output shape: torch.Size([1, 400])
Linear output shape: torch.Size([1, 120])
Sigmoid output shape: torch.Size([1, 120])
Linear output shape: torch.Size([1, 84])
Sigmoid output shape: torch.Size([1, 84])
Linear output shape: torch.Size([1, 10])在整個卷積塊中,與上一層相比,每一層特征的高度和寬度都減小了。
第一個卷積層使用2個像素的填充,來補償卷積核導致的特征減少。
相反,第二個卷積層沒有填充,因此高度和寬度都減少了4個像素。
隨著層疊的上升,通道的數量從輸入時的1個,增加到第一個卷積層之后的6個,再到第二個卷積層之后的16個。
同時,每個匯聚層的高度和寬度都減半。
最后,每個全連接層減少維數,最終輸出一個維數與結果分類數相匹配的輸出。
訓練過程:
代碼來自《動手學深度學習》
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
def evaluate_accuracy_gpu(net, data_iter, device=None): #@save """使用GPU計算模型在數據集上的精度"""if isinstance(net, nn.Module):net.eval() # 設置為評估模式if not device:device = next(iter(net.parameters())).device# 正確預測的數量,總預測的數量metric = d2l.Accumulator(2)with torch.no_grad():for X, y in data_iter:if isinstance(X, list):# BERT微調所需的(之后將介紹)X = [x.to(device) for x in X]else:X = X.to(device)y = y.to(device)metric.add(d2l.accuracy(net(X), y), y.numel())return metric[0] / metric[1]
#@save
def train_ch6(net, train_iter, test_iter, num_epochs, lr, device):"""用GPU訓練模型"""def init_weights(m):if type(m) == nn.Linear or type(m) == nn.Conv2d:nn.init.xavier_uniform_(m.weight)net.apply(init_weights)print('training on', device)net.to(device)optimizer = torch.optim.SGD(net.parameters(), lr=lr)loss = nn.CrossEntropyLoss()animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=['train loss', 'train acc', 'test acc'])timer, num_batches = d2l.Timer(), len(train_iter)for epoch in range(num_epochs):# 訓練損失之和,訓練準確率之和,樣本數metric = d2l.Accumulator(3)net.train()for i, (X, y) in enumerate(train_iter):timer.start()optimizer.zero_grad()X, y = X.to(device), y.to(device)y_hat = net(X)l = loss(y_hat, y)l.backward()optimizer.step()with torch.no_grad():metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])timer.stop()train_l = metric[0] / metric[2]train_acc = metric[1] / metric[2]if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:animator.add(epoch + (i + 1) / num_batches,(train_l, train_acc, None))test_acc = evaluate_accuracy_gpu(net, test_iter)animator.add(epoch + 1, (None, None, test_acc))print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, 'f'test acc {test_acc:.3f}')print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec 'f'on {str(device)}')
lr, num_epochs = 0.9, 10
train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())輸出:
loss 0.469, train acc 0.823, test acc 0.779
55296.6 examples/sec on cuda:0卷積神經網絡(CNN)是一類使用卷積層的網絡。
在卷積神經網絡中,我們組合使用卷積層、非線性激活函數和匯聚層。
為了構造高性能的卷積神經網絡,通常對卷積層進行排列,逐漸降低其表示的空間分辨率,同時增加通道數。
傳統的卷積神經網絡的卷積塊編碼得到的表征在輸出之前需由一個或多個全連接層進行處理。
LeNet是最早發布的卷積神經網絡之一。

















)

