轉自?NEON優化:性能優化經驗總結-CSDN博客
NEON優化:性能優化經驗總結
1. 什么是 NEON
????????Arm Adv SIMD 歷史
2. 寄存器
3. NEON 命名方式
4. 優化技巧
5. 優化 NEON 代碼(Armv7-A內容,但區別不大)
????????5.1 優化 NEON 匯編代碼
????????5.1.1 Cortex-A 處理器之間的 NEON 管道差異
????????5.1.2 內存訪問優化
?
Reference:
- NEON優化:性能優化經驗總結
- NEON官方內聯函數
- Arm NEON programming quick reference
- Learn the architecture - Neon programmers’ guide
如果覺得直接在 NEON 上編譯不太方便,可在SSE上編譯后轉NEON,可參考:https://github.com/DLTcollab/sse2neon
1. 什么是 NEON
NEON?技術是用于?Arm Cortex-A?系列處理器的先進 SIMD(單指令多數據)架構。它可以加速多媒體和信號處理算法,如視頻編碼器/解碼器、2D/3D圖形、游戲、音頻和語音處理、圖像處理、電話和聲音。
NEON 指令執行“打包 SIMD”處理:
- 寄存器被認為是相同數據類型元素的向量
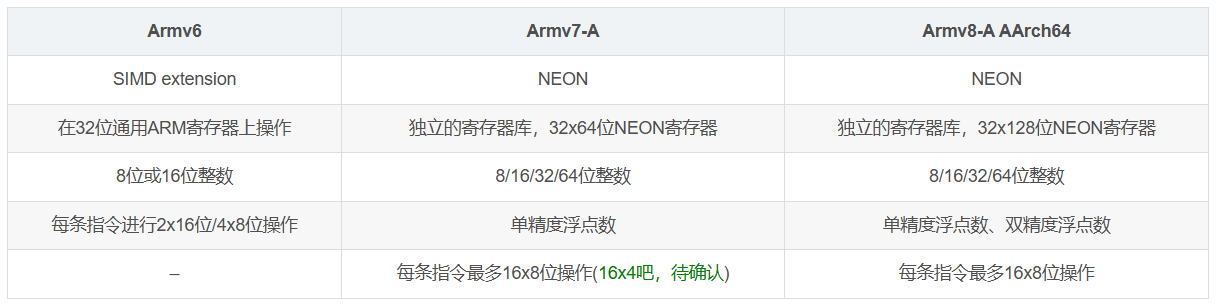
- 數據類型支持:帶符號/無符號 8 88 位,16 1616 位,32 3232 位,64 6464 位,ARM 32 3232位平臺上的單精度浮點數,ARM 64 6464位平臺上的單精度浮點數和雙精度浮點數。
- 指令在所有通道中執行相同的操作
Arm?Adv SIMD 歷史
?
2. 寄存器
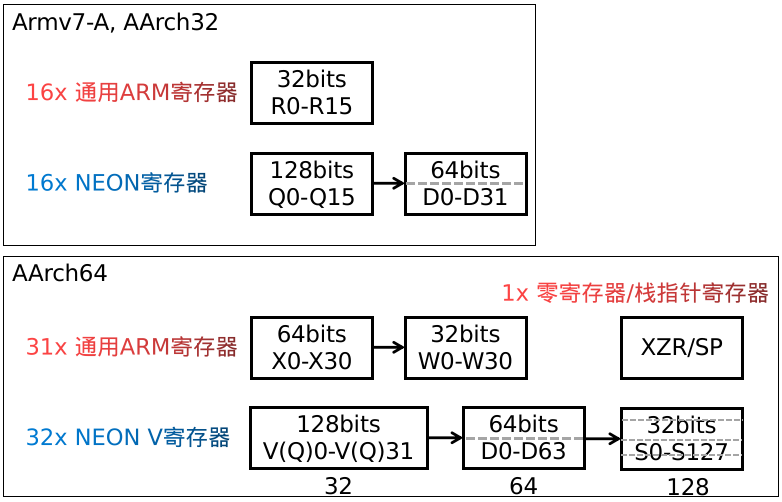
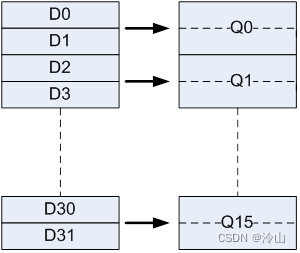
Armv7-A 和 AArch32 具有相同的通用 ARM 寄存器 - 16 1616 x 32 3232 位 通用ARM寄存器(R0-R15),以及 32 x 64 位 NEON寄存器(D0-D31)。這些寄存器也可以看作是 16 × 128 位寄存器(Quad-word, Q0-Q15)。每個 Q0-Q15 寄存器映射到一對 D寄存器,如下圖所示。
?
相比之下,AArch64 具有 31 3131 個 64 6464 位 通用ARM寄存器 和 1 11 個具有不同名稱的特殊寄存器(零寄存器/棧指針寄存器(XZR/SP)),這取決于使用它的上下文。這些寄存器可以被看作是 31 3131 個 64 6464 位寄存器(X0-X30) 或 31 3131 個32 3232 位寄存器(W0-W30)(高32位被忽略)。
AArch64 具有 32 3232 x 128 128128 位 NEON 寄存器(V0-V31,Vector Registers)(整個的寄存器被叫做V寄存器,即用來做向量化的寄存器,Vector Registers,但用作128位寄存器時,還是可以稱作 Q寄存器,這樣很明顯更有指向性)。這些寄存器也可以看作是 32 3232 位 Sn寄存器(Single-word Registers) 或 64 6464 位 Dn寄存器(Double-word Registers) 或 16 1616 位的 H寄存器(Half-precision Registers)。
?
(也就是說,V 寄存器有 128 位,D 寄存器 64 位,S寄存器 32 位,可以將 V 寄存器拆開使用)
3. NEON 命名方式
變量命名方式:
baseWxLxN_t- base:是基礎數據類型
- W:是基礎類型的寬度
- L:是向量的長度
- N:是向量數組的個數
- 如?
uint8x16_t、uint8x16x3_t
函數命名方式:
- ret v[p][q][r]name[u][n][q](args)
- ret:返回值類型
- v:表示vector
- q:飽和運算,溢位后,為自動限制在數據類型的最大范圍內
- r:圓整操作
- name:SIMD指令名稱
- u:unsigned
- n:narrow
- q:做后綴表示128位滿位寬寄存器運算 quarter*32
4. 優化技巧
-
熱點函數涉及到大量 IO 讀寫操作時,數據的內存地址盡量與 NEON 數組或系統位數對齊,如32位對齊,可降低訪問開銷;
-
重點優先搞 NEON 指令并行計算,能大幅降低開銷;
-
大部分的 NEON 問題會出在存取、移動指令的濫用、混亂使用上;
-
for?循環:- 如 for (b = 0; b < num; b++):
- 可改成 for (b = 0; b < num - 3; b += 4);
- 或者 for (b = num - 1; b >= 3; b -= 4);
- 需注意結尾不能整除的幾個還是用非SIMD方式計算:
- 原始:for (i = 0; i < size; i++);
- 并行:for (i = 0; i < size - 3; i += 4);
- 掃尾:for (; i < size; i ++)。
- 數組索引取值:
- 數組索引以及索引內部涉及運算的,盡量換成指針偏移加減來做;
- 避免大范圍索引跳躍,減少 cache miss。
- 內存使用:
- 優先用局部變量,而非 malloc 堆內存,減少 cache miss;
- 針對具體變量類型,手動 for 循環并行拷貝值,可能比 memcpy() 函數更高效,因為 memcpy 內部還涉及大量判斷,以保證平臺兼容性;
- 用NEON指令時,4 路運算的數組(128位=16字節),內存地址最好要 16 字節對齊。
- 指令運算
- 矩陣乘場景,在不大幅增加寄存器變量的前提下,外部的A也最好并行多讀幾路數據進來,跟B的各列運算,減少B各列的讀取次數;
- 乘加指令,add 和 mul 可以合并為 mla,一條指令完成乘加操作。
- C 語言編碼級考慮
- C 語言中一條事件的處理函數盡可能在一個源文件中(便于編譯器自動向量化);
switch?比?if else?快,而且代碼整潔。
- 深入理解計算機系統
- 組織代碼結構,善用 CPU 緩存,數據段/代碼段連續可以提高 CPU 緩存命中率
- 極簡函數時,盡量 inline 展開,減少函數調用棧的開銷;
- 消除不必要的存儲器引用,如 for 循環中 *dest = *dest - nums[i],可用中間變量替換 *dest,for 循環后再賦值給 *dest,可減少 for 內的一次讀寫操作;
- 簡單的循環展開,編譯器可以自己完成,優化選項 O2 及以上,或者命令 -funroll-loops(O2 及以上自帶),可調用 gcc 進行循環展開;
- 能用整型不用浮點,整數乘法/加法和浮點加法,只用一個周期,浮點乘法需要2個周期。
- NEON 與 SSE 在寄存器處理數據時有一些區別。在 NEON 中,通常需要先將要處理的數據加載到 NEON 寄存器,然后執行 SIMD 操作。這與 SSE 有一些不同,因為 SSE 寄存器(XMM 寄存器)可以直接與內存交互(這一步可能格外耗時,需要特別注意)。在 NEON 中,加載數據到 NEON 寄存器通常包括以下步驟:
- 從內存加載數據到通用寄存器(通常是ARM通用寄存器)。
- 將數據從通用寄存器傳送到 NEON 寄存器。
然后,您可以在 NEON 寄存器上執行 SIMD 操作,例如矢量加法、矢量乘法等。
?這與 SSE 不同,因為 SSE 寄存器可以直接從內存加載數據,而不需要中間步驟。這可以在 SSE 指令中實現,而不需要將數據先加載到通用寄存器中。
總之,NEON 需要額外的步驟來加載數據到寄存器,然后才能進行 SIMD 操作,而 SSE 可以更直接地在寄存器中操作數據。這是因為不同架構和指令集設計的差異。
5. 優化 NEON 代碼(Armv7-A內容,但區別不大)
5.1 優化 NEON 匯編代碼
考慮處理器如何集成 NEON 技術的實現定義方面,因為針對特定處理器優化的指令序列可能在不同的處理器上具有不同的時序特征,即使 NEON 指令周期時序相同。
為了從手寫的 NEON 代碼中獲得最佳性能,有必要了解一些底層硬件特性。特別是,程序員應該意識到流水線和調度問題、內存訪問行為和調度危害。
5.1.1 Cortex-A 處理器之間的 NEON 管道差異
Cortex-A8 和 Cortex-A9 處理器共享相同的基本 NEON 管道,盡管在如何將其集成到處理器管道中存在一些差異。Cortex-A5 處理器包含一個完全兼容的簡化 NEON 執行管道,但它是為盡可能最小和最低功耗的實現而設計的。
5.1.2 內存訪問優化
TLB(Translation Lookaside Buffer)?是計算機系統中的一種硬件緩存,用于加速虛擬地址到物理地址的轉換過程。TLB 的每個條目稱為?TLB entry(TLB條目),它存儲了一組?虛擬地址?和相應的?物理地址?之間的映射關系。TLB 通常位于 CPU 內部,用于提高內存訪問的速度。
當程序執行時,CPU 需要將虛擬地址(由程序使用)轉換為物理地址(在內存中實際存儲數據的地址)。這個地址轉換通常由操作系統的內存管理單元(MMU)來執行。MMU 將虛擬地址映射到物理地址,并在需要時將這些映射關系存儲在 TLB 中,以便以后的訪問可以更快地完成,而無需再次執行昂貴的地址轉換操作。
TLB entry 通常包括以下信息:
- 虛擬地址(Virtual Address):程序使用的地址。
- 物理地址(Physical Address):在內存中實際存儲數據的地址。
- 標志位(Flags):包括權限信息(例如,讀、寫、執行權限)和其他控制信息。
當 CPU 需要訪問內存中的數據時,它首先查看 TLB 來查找虛擬地址和物理地址之間的映射關系。如果找到了匹配的 TLB entry,那么物理地址將用于訪問內存,這將顯著提高內存訪問速度。如果沒有找到匹配的 TLB entry,CPU 將向 MMU 請求執行地址轉換,并將結果存儲在 TLB 中以供將來使用。
總之,TLB entry 是 TLB 中存儲的虛擬地址到物理地址映射的單元,用于加速計算機內存訪問的過程。這有助于提高系統的性能和效率。
L1 和 L2 緩存的概念可以看這篇文章,描述的更清楚:寄存器、緩存、內存(虛擬、物理地址)、DDR、RAM的關系
NEON 單元很可能會處理大量數據,例如數字圖像。一個重要的優化是確保算法以最適合緩存的方式訪問數據。這樣可以從 L1 和 L2 緩存中獲得最大的命中率(hit rate)。考慮活動內存位置的數量也很重要。在 Linux 下,每個 4KB 的頁面都需要一個單獨的 TLB 條目。Cortex-A9 處理器有多個 32 3232 個元素的 micro-TLB 和一個 128 128128 個元素的主 TLB,之后它將開始使用 L1 緩存來加載頁表條目(page table entry)。一種典型的優化是安排算法以適當的大小處理圖像數據,以最大限度地提高緩存和 TLB 命中率。
支持?交錯(interleaving)?和?反交錯(de-interleaving)?的指令可以為性能改進提供很大的空間。VLD1?從內存加載寄存器,沒有去交錯。然而,其他 VLDn 操作使我們能夠加載、存儲和反交錯包含兩個、三個或四個相同大小的 8 88、16 1616 或 32 3232 位元素的結構。VLD2?加載兩個或四個寄存器,去交錯的偶數和奇數元素。例如,這可以用于分割左通道和右通道立體聲音頻數據,如下圖所示。類似地,VLD3?可用于將 RGB 像素分割為單獨的通道,相應地,VLD4?可用于 ARGB 或 CMYK 圖像。
?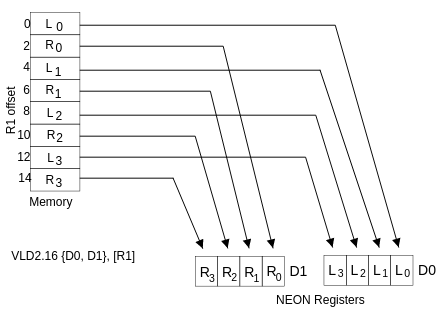
上圖顯示了用 VLD2.16(16字節) 從 R1 指向的內存中加載兩個 NEON 寄存器。這在第一個寄存器中產生 4 44 個 16 1616 位元素,在第二個寄存器中產生 4 個 16位元素,相鄰的成對左值和右值被分隔到每個寄存器中。









)


:音頻重采樣)

![【[特殊字符][特殊字符] 協變與逆變:用“動物收容所”講清楚 PHP 類型的“靈活繼承”】](http://pic.xiahunao.cn/【[特殊字符][特殊字符] 協變與逆變:用“動物收容所”講清楚 PHP 類型的“靈活繼承”】)





)