文章目錄
- 一、微調技術的底層邏輯
- 1.1 預訓練與微調的關系
- 1.2 核心目標:適配任務與數據
- 二、經典微調方法詳解
- 2.1 全量微調(Full Fine-Tuning)
- 2.2 凍結層微調(Layer-Freezing Fine-Tuning)
- 2.3 參數高效微調(Parameter-Efficient Fine-Tuning, PEFT)
- 2.4 超大規模參數模型的Prompt-Tuning方法
- 2.5 微調方法全面對比
- 三、微調技術的應用場景與挑戰
- 3.1 典型應用場景
- 3.2 面臨的挑戰
- 四、未來發展趨勢
一、微調技術的底層邏輯
1.1 預訓練與微調的關系
預訓練模型如同在"知識海洋"中遨游的學者,在海量無監督數據(如互聯網文本、百科知識等)里學習語言模式、語義理解、邏輯推理等通用能力。而微調,就是讓這位"學者"進入特定"專業領域"(如醫療診斷、金融分析),通過少量標注數據"進修",將通用知識轉化為專項任務的解決能力,實現從"博聞強識"到"術業專攻"的跨越。
1.2 核心目標:適配任務與數據
- 任務適配:讓大模型理解特定任務的目標,比如文本分類要區分情感正負、命名實體識別要精準提取實體類型,微調通過調整模型參數,強化模型對任務指令的響應邏輯。
- 數據適配:不同領域的數據有獨特的詞匯、表述和分布,微調使模型學習到當前數據的特征模式,例如法律文本中的專業術語、醫療報告的嚴謹表述,讓模型輸出更貼合領域需求。
二、經典微調方法詳解
2.1 全量微調(Full Fine-Tuning)
- 技術原理:對預訓練模型的所有參數(包括 Transformer 層、嵌入層等)進行更新,利用下游任務的標注數據,重新調整模型的權重,使模型全方位適配新任務。
- 優缺點分析
- 優點:能最大程度利用任務數據,對模型參數進行全面優化,在充足標注數據支持下,可取得很高的任務精度,適合數據豐富、追求極致性能的場景,如大規模文本分類競賽。
- 缺點:計算成本極高,需要強大的 GPU 算力支持,大模型全量參數更新耗時久;容易過擬合,尤其是數據量較少時,模型可能過度學習訓練數據的細節,泛化性下降;還可能"遺忘"預訓練階段的部分通用知識(災難性遺忘問題)。
2.2 凍結層微調(Layer-Freezing Fine-Tuning)
- 技術原理:凍結預訓練模型的部分層(通常是底層,因底層更多學習通用語法、基礎語義),僅對頂層(如輸出層、部分高層 Transformer 層)參數進行微調。利用頂層的靈活性適配新任務,底層保留通用知識。
- 優缺點分析
- 優點:降低計算量與顯存占用,訓練效率提升,適合算力有限或數據量適中的場景;一定程度緩解災難性遺忘,底層保留的通用知識更穩定。
- 缺點:適配效果依賴凍結層與微調層的劃分,若劃分不合理(如凍結過多關鍵層),會限制模型對任務的適配能力,需要反復調試層數配置。
2.3 參數高效微調(Parameter-Efficient Fine-Tuning, PEFT)
-
技術分支與原理
-
Adapter Tuning:在預訓練模型中插入小型 Adapter 模塊(如全連接層組成的瓶頸結構),僅訓練 Adapter 的參數,模型主體參數凍結。Adapter 學習任務特定的特征轉換,靈活適配任務。其結構通常包含down-project層(將高維度特征映射到低維特征)、非線性層和up-project結構(將低維特征映射回原來的高維特征),同時設計了skip-connection結構,確保在最差情況下能退化為identity(類似殘差結構)。
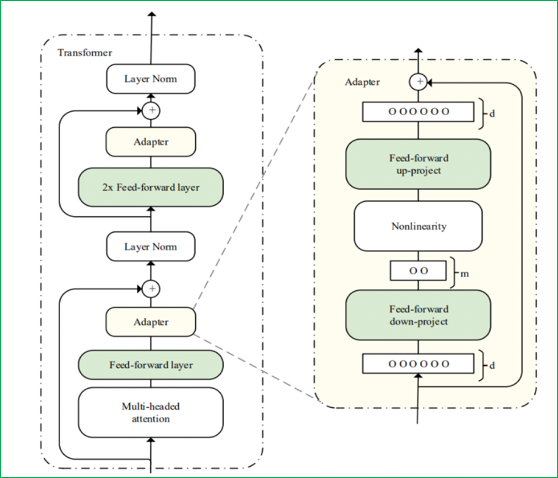
-
LoRA(Low-Rank Adaptation):
數學原理:基于矩陣低秩分解理論,假設權重更新矩陣 ΔW 可分解為兩個小矩陣的乘積:
ΔW=B×AΔW = B × AΔW=B×A,其中 B∈Rd×rB ∈ ?^{d×r}B∈Rd×r, A∈Rr×kA ∈ ?^{r×k}A∈Rr×k, r?min(d,k)r ? min(d,k)r?min(d,k)
工作機制:- 訓練階段:僅優化低秩矩陣 A、B,預訓練權重凍結。矩陣A使用隨機高斯分布初始化,矩陣B初始化為全零矩陣,確保訓練開始時LoRA模塊對模型輸出影響為零。
- 推理階段:將 Wnew=W0+BAW_{new} = W_0 + BAWnew?=W0?+BA 合并為單一權重,實現零延遲推理
核心優勢: - 參數效率:13B 模型全量微調需 130 億參數,LoRA 僅需 650 萬(r=8)
- 避免遺忘:凍結原權重保留通用知識
- 多任務切換:不同任務使用獨立 LoRA 權重
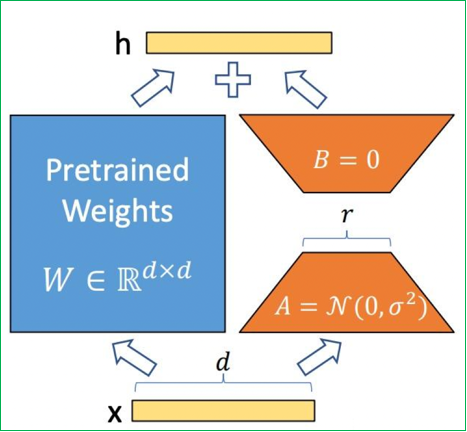
-
Prefix Tuning:在輸入序列前構造一段任務相關的偽tokens作為Prefix,訓練時只更新Prefix部分的參數,而Transformer中的其他部分參數固定。它在Transformer模型的每一層內部,注入可學習的“前綴”,這些前綴被添加到Attention機制中的Key(K)和Value(V)向量的計算中。由于直接更新Prefix的參數會導致訓練不穩定,通常在Prefix層前面加MLP結構,訓練完成后只保留Prefix的參數。
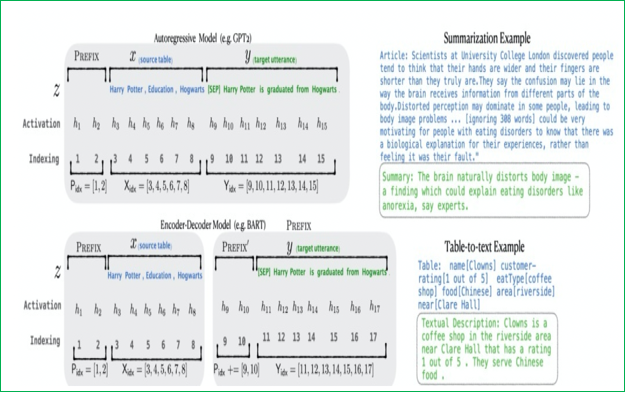
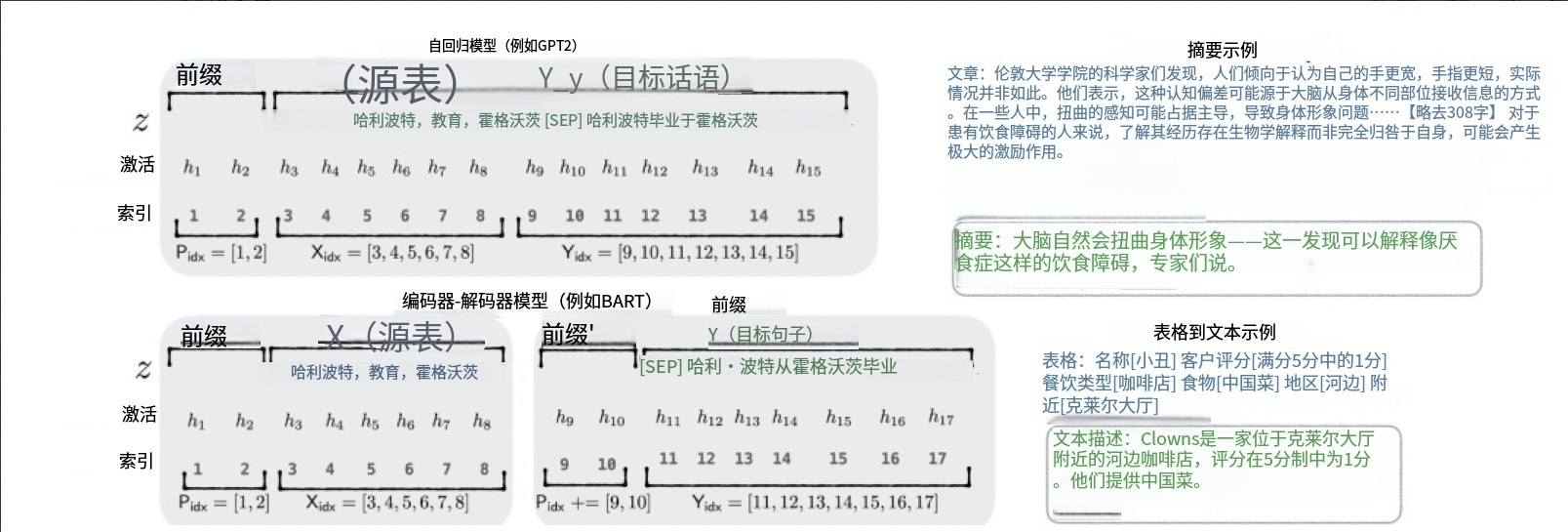
-
Prompt-Tuning:在不修改或更新大型預訓練語言模型自身大量參數的前提下,通過學習一小段連續的、可訓練的向量序列(即“軟提示”Soft Prompt),將其作為輸入的一部分,來引導模型在特定下游任務上產生期望的輸出。與Prefix-Tuning相比,Prompt-Tuning只在輸入層加入prompt tokens,可看作是Prefix-Tuning的簡化。
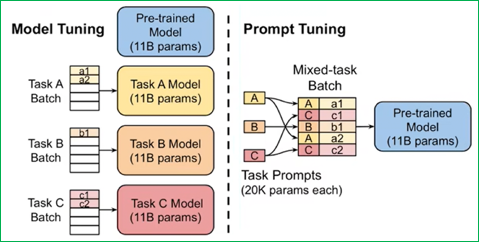
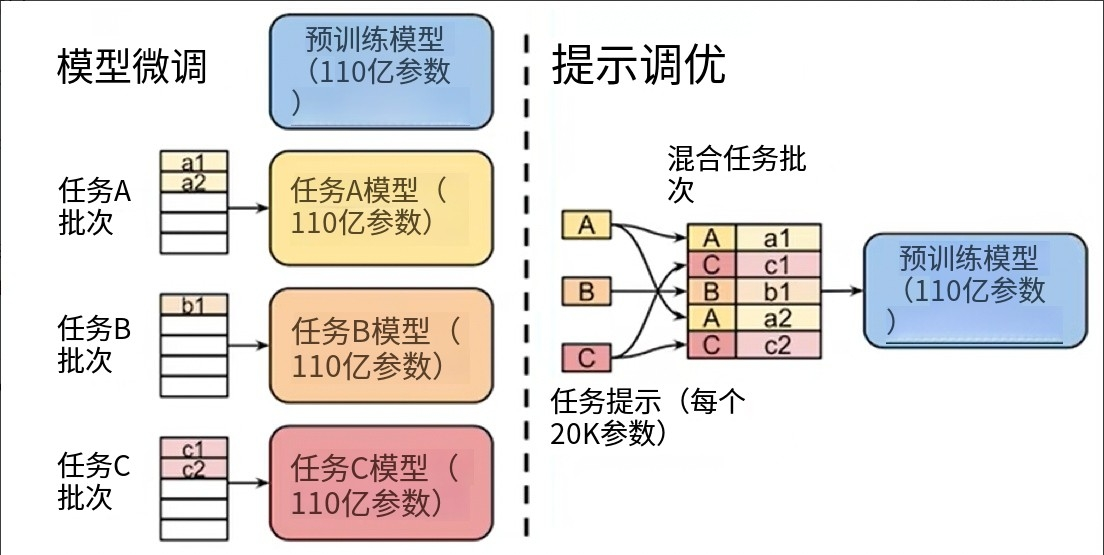
-
-
優缺點分析
- 優點:可訓練參數極少(如 LoRA 可減少至原參數的 0.1%-2%),大幅降低算力與顯存需求,能在消費級 GPU 甚至 CPU 環境嘗試微調大模型;適配多任務場景時,不同任務的 Adapter 或低秩矩陣可快速切換,靈活性高。
- 缺點:部分方法(如 Adapter Tuning)可能因 Adapter 與主體模型的融合問題,在復雜任務上性能略遜于全量微調;LoRA 的低秩分解假設若與模型實際參數分布偏差大,會影響效果,需要調整秩的設置;Prompt-Tuning在小樣本學習場景表現欠佳,收斂速度較慢且調參復雜。
2.4 超大規模參數模型的Prompt-Tuning方法
對于超過10億參數量的模型,Prompt-Tuning所帶來的增益往往高于標準的Fine-tuning,主要包括以下幾種方法:
-
上下文學習(In-Context Learning):從訓練集中挑選少量的標注樣本,設計任務相關的指令形成提示模板,用于指導測試樣本生成相應結果。包括零樣本學習(直接讓預訓練好的模型進行任務測試)、單樣本學習(插入一個樣本做指導后再測試)、少樣本學習(插入N個樣本做指導后再測試)。其優點是零樣本或少樣本學習、可快速適應不同任務且簡單易用;但性能受示例質量影響大,對模型規模要求高,受上下文長度限制且推理成本高。
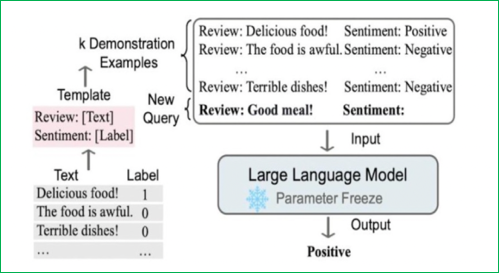
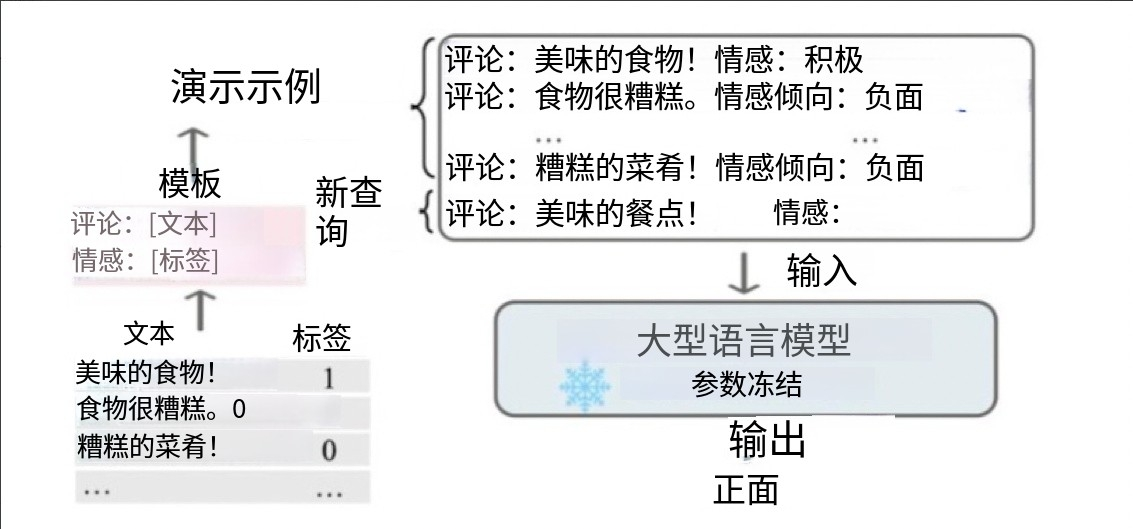
-
指令學習(Instruction-Tuning):為各種類型的任務定義指令并進行訓練,以提高模型對不同任務的泛化能力。通過給出更明顯的指令/指示,激發語言模型的理解能力,讓模型理解并做出正確的action。實現步驟包括收集大量覆蓋各種任務類型和語言風格的指令數據,然后在這些數據上對LLM進行微調。其優點是能提高模型對未見過任務的泛化能力、零樣本學習能力和指令遵循能力;但需要大量高質量指令數據,收集成本高且微調成本高。
-
思維鏈(Chain-of-Thought):一種改進的提示策略,用于提高LLM在復雜推理任務中的性能。相比傳統上下文學習,多了中間的推導提示。包括Few-shot CoT(將每個演示擴充為包含推理步驟的形式)和Zero-shot CoT(直接生成推理步驟導出答案)。其優點是能提高復雜推理能力且增強可解釋性;但需要人工設計CoT示例,對模型規模要求高且推理成本高。
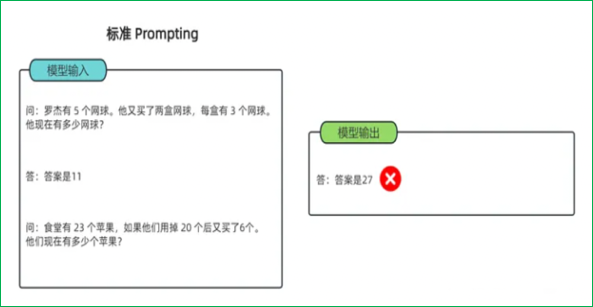
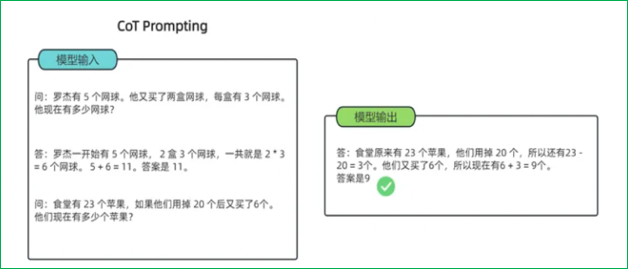
2.5 微調方法全面對比
| 方法 | 可訓練參數量 | 顯存占用 | 訓練速度 | 優點 | 缺點 | 適用場景 |
|---|---|---|---|---|---|---|
| 全量微調 | 100% | 極高 | 慢 | 性能最優 | 計算成本高,災難性遺忘 | 數據充足,追求極致性能 |
| 凍結微調 | 10%-20% | 高 | 中等 | 緩解遺忘,效率較高 | 層選擇敏感 | 任務與預訓練分布相似 |
| Adapter | 0.5%-5% | 中等 | 中等 | 多任務切換靈活 | 增加推理延遲 | 需要快速適配多任務 |
| Prefix-Tuning | 0.1%-1% | 中等 | 中等 | 無架構修改 | 序列長度受限 | 生成類任務(翻譯、摘要) |
| Prompt-Tuning | <0.1% | 低 | 中等 | 最輕量 | 僅適合簡單任務 | Few-shot 任務 |
| LoRA | 0.1%-2% | 低 | 快 | 零推理延遲,參數高效 | 秩選擇敏感 | 資源受限場景,多任務適配 |
| QLoRA | 0.1%-1% | 極低 | 快 | 4-bit量化,顯存需求降70% | 輕微精度損失 | 消費級GPU訓練大模型 |
核心結論:
- LoRA 在參數量 (0.1%~1%)、計算成本、顯存占用和靈活性上取得最佳平衡,是當前大模型微調的主流選擇。
- Prompt-Tuning 最輕量 (參數量<0.1%),但僅適合簡單任務。
- Full Fine-Tuning 效果最優但成本極高,適合算力充足的場景。
- Adapter 因引入推理延遲,逐漸被LoRA替代。
三、微調技術的應用場景與挑戰
3.1 典型應用場景
- 垂直領域適配:金融領域的輿情分析、醫療領域的病歷解讀、法律領域的合同審查,通過微調讓大模型掌握領域專業知識與任務流程。
- 小眾任務落地:如古籍文本的實體識別、方言情感分析,利用微調,以少量標注數據驅動大模型適配小眾、稀缺數據的任務。
- 多任務統一優化:在一個模型中適配文本分類、問答、摘要等多個任務,通過 PEFT 等方法,用不同 Adapter 或前綴向量,讓模型高效處理多任務場景。
3.2 面臨的挑戰
- 算力與資源限制:即使 PEFT 技術降低了需求,大模型微調仍對硬件有較高要求,中小企業或個人開發者難以獲取充足算力,限制技術落地。
- 數據質量與偏見:下游任務數據可能存在標注錯誤、樣本偏差(如某類情感樣本過多),微調會讓模型學習到錯誤或有偏的模式,影響輸出公正性與準確性。
- 知識遺忘與沖突:微調過程中,模型可能遺忘預訓練的通用知識,或新學的任務知識與通用知識產生沖突(如特定領域的表述與通用語義矛盾 ),需要更優的參數更新策略緩解。
四、未來發展趨勢
- 更高效的 PEFT 技術演進:不斷探索新的低秩分解、參數更新方式,進一步壓縮可訓練參數,同時提升適配效果,讓微調在極致算力限制下也能高效開展。
- 結合強化學習的微調:引入強化學習(RL),讓模型在微調過程中根據獎勵機制(如用戶反饋、任務效果指標)自主優化,提升模型的長期適應能力與決策質量。
- 跨模態微調拓展:大模型向多模態(文本 + 圖像 + 語音)發展,微調技術需適配跨模態任務,學習不同模態數據的融合與任務適配,如多模態情感分析、跨模態生成。
大模型微調技術正處于快速發展與迭代中,從全量微調的“全面革新”,到 PEFT 的“精準高效”,每一種方法都在適配不同的應用需求與資源條件。掌握這些技術,既能讓大模型在專業領域發揮價值,也為 AI 落地千行百業提供了可行路徑。未來,隨著技術突破與生態完善,微調將持續推動大模型從“通用智能體”向“專屬任務專家”轉變,解鎖更多 AI 應用的可能性。
)







![[激光原理與應用-254]:理論 - 幾何光學 - 自動對焦的原理](http://pic.xiahunao.cn/[激光原理與應用-254]:理論 - 幾何光學 - 自動對焦的原理)







——matplotlib庫)


