本次通過對雙十一淘寶美妝數據的分析實踐,我系統掌握了數據處理與分析的完整流程,從數據初步認知到深度挖掘,再到可視化呈現與結論提煉,收獲頗豐。以下是具體的學習總結:
一、數據初步了解:奠定分析基礎
在分析初期,我們首先對數據進行了全面 “掃描”。通過df.head()查看前五行數據,直觀了解了每條數據包含的 7 個特征:update_time(更新時間)、id(商品 ID)、title(商品標題)、price(價格)、sale_count(銷量)、comment_count(評論數)、店名(店鋪名稱)。
借助df.info()和df.shape,明確了數據規模為 27598 條記錄,且發現sale_count和comment_count存在缺失值,其他特征無缺失,這為后續的數據清洗指明了方向。而df.describe()則提供了數值型特征的統計量,如價格均值為 362.83 元,銷量均值為 12301.77 件等,讓我們對數據的分布有了初步判斷。
二、數據清洗:保障數據質量
數據清洗是分析的關鍵環節,直接影響后續結果的準確性,主要完成了以下工作:
- 重復值處理:使用
drop_duplicates刪除了 86 條重復數據,得到 27512 條有效數據,并通過reset_index重置行索引,確保數據結構規范。 - 缺失值處理:觀察發現
sale_count和comment_count的缺失值可能代表銷量或評論數為 0,因此采用fillna(0)用 0 填補缺失值,經檢查后確認無空值殘留。 - 新特征挖掘:這是本次分析的亮點之一。首先用
jieba對商品標題進行分詞,生成subtitle列,為后續分類做準備;然后基于自定義的分類字典,將商品劃分為 “護膚品”“化妝品” 等主類別和 “乳液類”“口紅類” 等子類別,新增main_type和sub_type列;此外,根據標題是否含 “男士”“男生” 等關鍵詞,新增是否男士專用列;最后,通過price * sale_count計算出銷售額列,豐富了分析維度。
三、數據分析及可視化:洞察數據規律
借助matplotlib和seaborn工具,我們對數據進行了多維度分析與可視化呈現,得出了諸多有價值的結論:
1. 品牌維度分析
- 商品數量:悅詩風吟的商品數量遙遙領先,但銷量和銷售額并非頂尖,說明商品數量多并不一定等同于市場表現好。
- 銷量與銷售額:相宜本草在銷量和銷售額上均位居第一,且銷量約為第二名的兩倍,但銷售額遠不到兩倍,反映出其商品均價較低的特點。
- 平均單價:將品牌按平均單價分為 A(0-100 元)、B(100-200 元)、C(200-300 元)、D(300 元以上)四類,發現 A 類品牌銷售額占比最高,D 類最低,且定價越低的品牌平均銷售額越高,印證了 “價格親民的品牌更易獲得高銷售額” 的推測。
2. 類別維度分析
- 大類表現:護膚品的銷量和銷售額占比遠高于化妝品及其他類別,是美妝市場的主力。
- 小類表現:清潔類和補水類護膚品銷量領先,且各類別的銷量與銷售額占比基本正相關,符合市場常識。
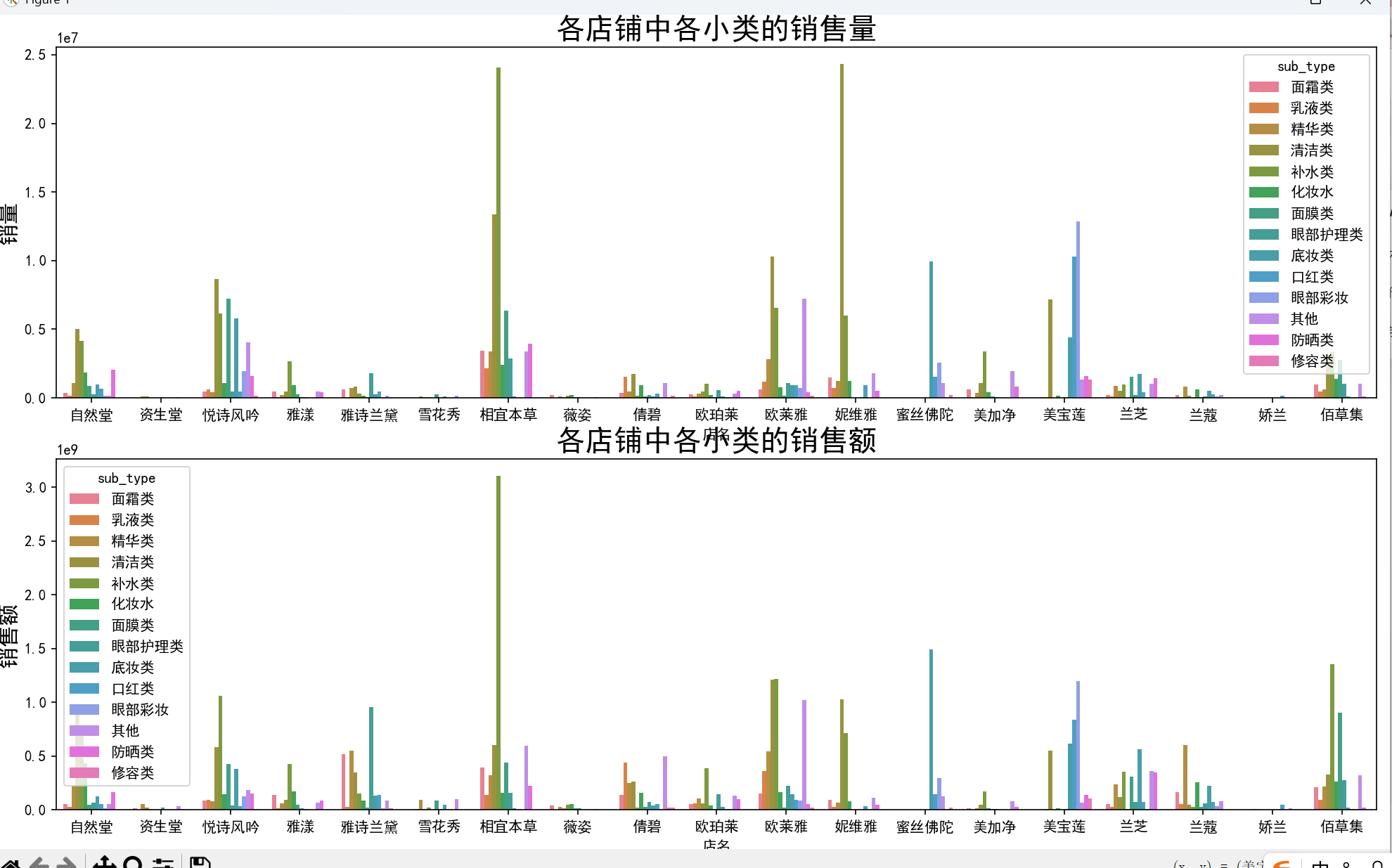
- 品牌與類別結合:相宜本草在面霜、乳液、補水等多個小類中銷量最高,美寶蓮在口紅、眼部彩妝類表現突出,妮維雅則在清潔類中占據絕對優勢。
3. 性別維度分析
- 男士專用商品占比:男士專用商品的銷量和銷售額占比均較低,說明美妝市場仍以女性消費者為主。
- 男士商品類別偏好:男士專用商品中,清潔類和補水類銷量占比較高,反映出男性在美妝消費上更注重基礎清潔和保濕需求。
四 、代碼及圖片
import numpy as np
import pandas as pd
import jieba
import matplotlib.pyplot as plt
import seaborn as sns
# 設置中文顯示
plt.rcParams['font.sans-serif'] = [u'SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 數據讀取與初步了解
df = pd.read_csv('雙十一淘寶美妝數據.csv')
print("數據前五行:")
print(df.head())
print("\n數據特征信息:")
print(df.info())
print("\n數據形狀:", df.shape)
print("\n數值型特征統計量:")
print(df.describe())
# 2. 數據清洗
# 2.1 重復值處理
data = df.drop_duplicates(inplace=False)
data.reset_index(inplace=True, drop=True)
print("\n去重后數據形狀:", data.shape)
# 2.2 缺失值處理
print("\n缺失值填補前情況:")
print(data.loc[data['sale_count'].isnull()].head())
print(data.loc[data['comment_count'].isnull()].tail())
data = data.fillna(0)
print("\n缺失值填補后是否還有空值:")
print(data.isnull().any())
# 2.3 數據挖掘與新特征生成
# 對標題進行分詞
subtitle = []
for each in data['title']:
k = jieba.lcut_for_search(each) # 搜索引擎模式分詞
subtitle.append(k)
data['subtitle'] = subtitle
print("\n標題分詞結果示例:")
print(data[['title', 'subtitle']].head())
# 商品分類(主類別與子類別)
basic_data = """護膚品 乳液類 乳液 美白乳 潤膚乳 凝乳 柔膚液 亮膚乳 菁華乳 修護乳
護膚品 眼部護理類 眼霜 眼部 眼膜
護膚品 面膜類 面膜
護膚品 清潔類 洗面 潔面 清潔 卸妝 潔顏 洗顏 去角質 磨砂
護膚品 化妝水 化妝水 爽膚水 柔膚水 補水露 凝露 柔膚液 精粹水 亮膚水 潤膚水 保濕水 菁華水 保濕噴霧 舒緩噴霧
護膚品 面霜類 面霜 日霜 晚霜 柔膚霜 滋潤霜 保濕霜 凝霜 日間霜 晚間霜 乳霜 修護霜 亮膚霜 底霜 菁華霜
護膚品 精華類 精華液 精華水 精華露 精華素 精華
護膚品 防曬類 防曬
護膚品 補水類 補水
化妝品 口紅類 唇釉 口紅 唇彩 唇膏
化妝品 底妝類 散粉 蜜粉 粉底液 定妝粉 氣墊 粉餅 BB CC 遮瑕 粉霜 粉底膏 粉底霜
化妝品 眼部彩妝 眉粉 染眉膏 眼線 眼影 睫毛膏 眉筆
化妝品 修容類 鼻影 修容粉 高光 腮紅"""
# 構建分類字典
dcatg = {}
catg = basic_data.split('\n')
for i in catg:
parts = i.strip().split('\t')
if len(parts) >= 3:
main_cat = parts[0]
sub_cat = parts[1]
keywords = parts[2:]
for j in keywords:
if j: # 跳過空字符串
dcatg[j] = (main_cat, sub_cat)
# 生成主類別和子類別特征
sub_type = []
main_type = []
for i in range(len(data)):
exist = False
for j in data['subtitle'][i]:
if j in dcatg:
sub_type.append(dcatg[j][1])
main_type.append(dcatg[j][0])
exist = True
break
if not exist:
sub_type.append('其他')
main_type.append('其他')
data['sub_type'] = sub_type
data['main_type'] = main_type
print("\n分類為'其他'的商品數量:", data.loc[data['sub_type'] == '其他'].shape[0])
# 生成"是否男士專用"特征
sex = []
for i in range(len(data)):
subtitle = data['subtitle'][i]
if '男士' in subtitle or '男生' in subtitle:
sex.append('是')
elif '男' in subtitle and '女' not in subtitle and '斬男' not in subtitle:
sex.append('是')
else:
sex.append('否')
data['是否男士專用'] = sex
print("\n男士專用商品數量統計:")
print(data['是否男士專用'].value_counts())
# 生成"銷售額"特征
data['銷售額'] = data['price'] * data['sale_count']
print("\n添加銷售額后的數據示例:")
print(data.head())
# 3. 數據分析及可視化
# 3.1 各店鋪基本情況分析
plt.figure(figsize=(12, 10))
# 各店鋪商品數量
plt.subplot(2, 2, 1)
plt.tick_params(labelsize=15)
data['店名'].value_counts().sort_values().plot.bar()
plt.title('各品牌商品數', fontsize=20)
plt.ylabel('商品數量', fontsize=15)
plt.xlabel('店名')
# 各店鋪總銷量
plt.subplot(2, 2, 2)
plt.tick_params(labelsize=15)
data.groupby('店名')['sale_count'].sum().sort_values().plot.bar()
plt.title('各品牌所有商品的銷量', fontsize=20)
plt.ylabel('商品總銷量', fontsize=15)
# 各店鋪總銷售額
plt.subplot(2, 2, 3)
plt.tick_params(labelsize=15)
data.groupby('店名')['銷售額'].sum().sort_values().plot.bar()
plt.title('各品牌總銷售額', fontsize=20)
plt.ylabel('商品總銷售額', fontsize=15)
# 各品牌平均每單單價
plt.subplot(2, 2, 4)
plt.tick_params(labelsize=15)
avg_price = data.groupby('店名')['銷售額'].sum() / data.groupby('店名')['sale_count'].sum().replace(0, np.nan)
avg_price.sort_values().plot.bar()
plt.title('各品牌平均每單單價', fontsize=20)
plt.ylabel('售出商品的平均單價', fontsize=15)
plt.tight_layout()
plt.show(block=True)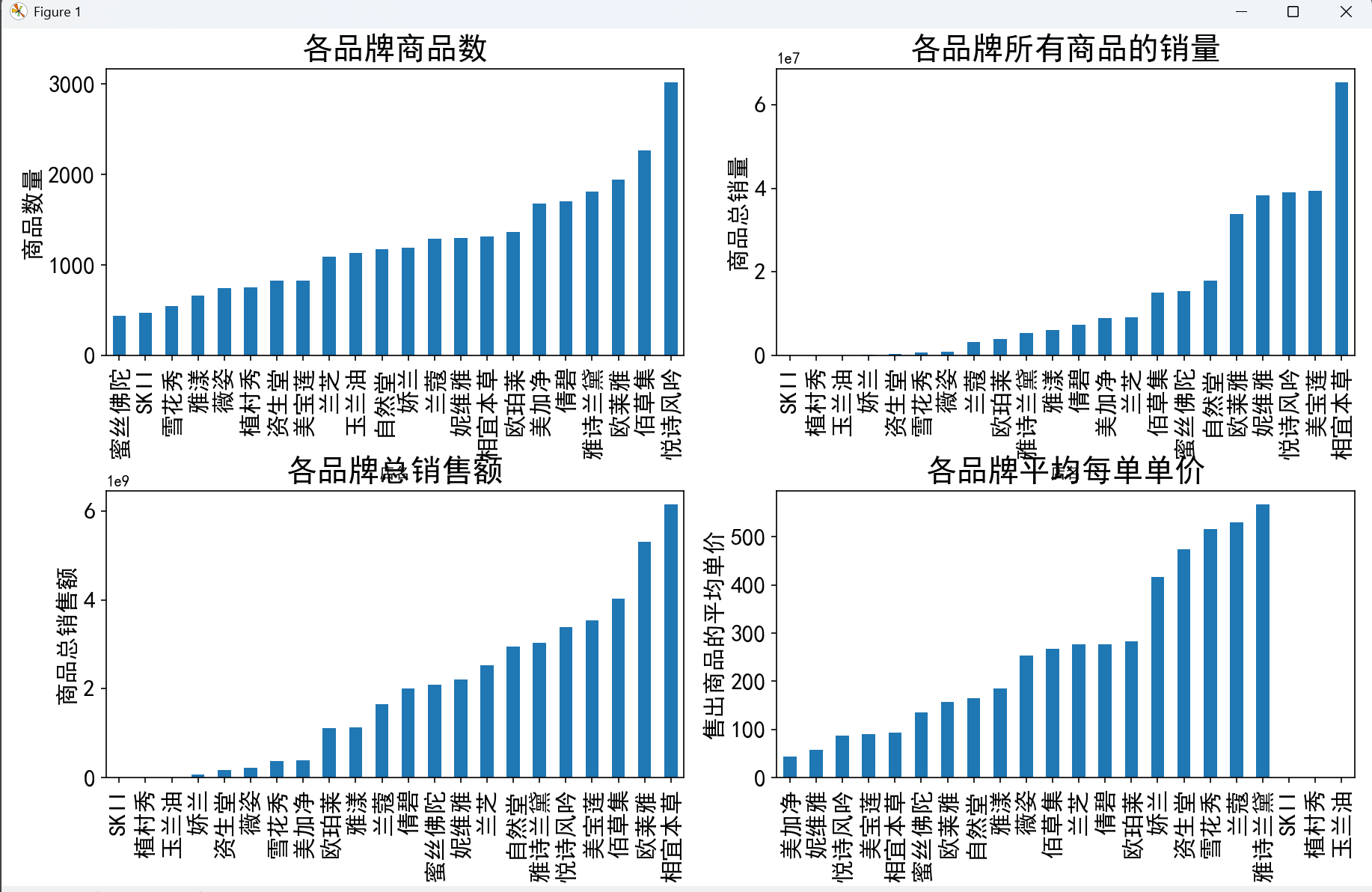
# 3.2 不同價格區間品牌的銷售情況
A = avg_price[(avg_price <= 100) & (avg_price > 0)].index
B = avg_price[(avg_price <= 200) & (avg_price > 100)].index
C = avg_price[(avg_price <= 300) & (avg_price > 200)].index
D = avg_price[avg_price > 300].index
sum_sale = data.groupby('店名')['銷售額'].sum()
plt.figure(figsize=(16, 8))
# 各類別品牌銷售額占比
plt.subplot(1, 2, 1)
sum_sale_byprice = pd.concat([sum_sale[A].sort_values(),
sum_sale[B].sort_values(),
sum_sale[C].sort_values(),
sum_sale[D].sort_values()])
colors = ['grey'] * len(A) + ['g'] * len(B) + ['y'] * len(C) + ['m'] * len(D)
plt.pie(x=sum_sale_byprice, labels=sum_sale_byprice.index, colors=colors,
autopct='%0f%%', pctdistance=0.9)
plt.title('不同均價區間品牌的銷售額占比')
# 各類別平均每個店銷售額
plt.subplot(1, 2, 2)
plt.tick_params(labelsize=15)
plt.bar('均價0-100元', np.mean(sum_sale[A]) if not A.empty else 0, color='grey')
plt.bar('均價100-200元', np.mean(sum_sale[B]) if not B.empty else 0, color='g')
plt.bar('均價200-300元', np.mean(sum_sale[C]) if not C.empty else 0, color='y')
plt.bar('均價300元以上', np.mean(sum_sale[D]) if not D.empty else 0, color='m')
plt.title('不同類別的平均每個店銷售額', fontsize=20)
plt.ylabel('平均銷售額', fontsize=20)
plt.tight_layout()
plt.show(block=True)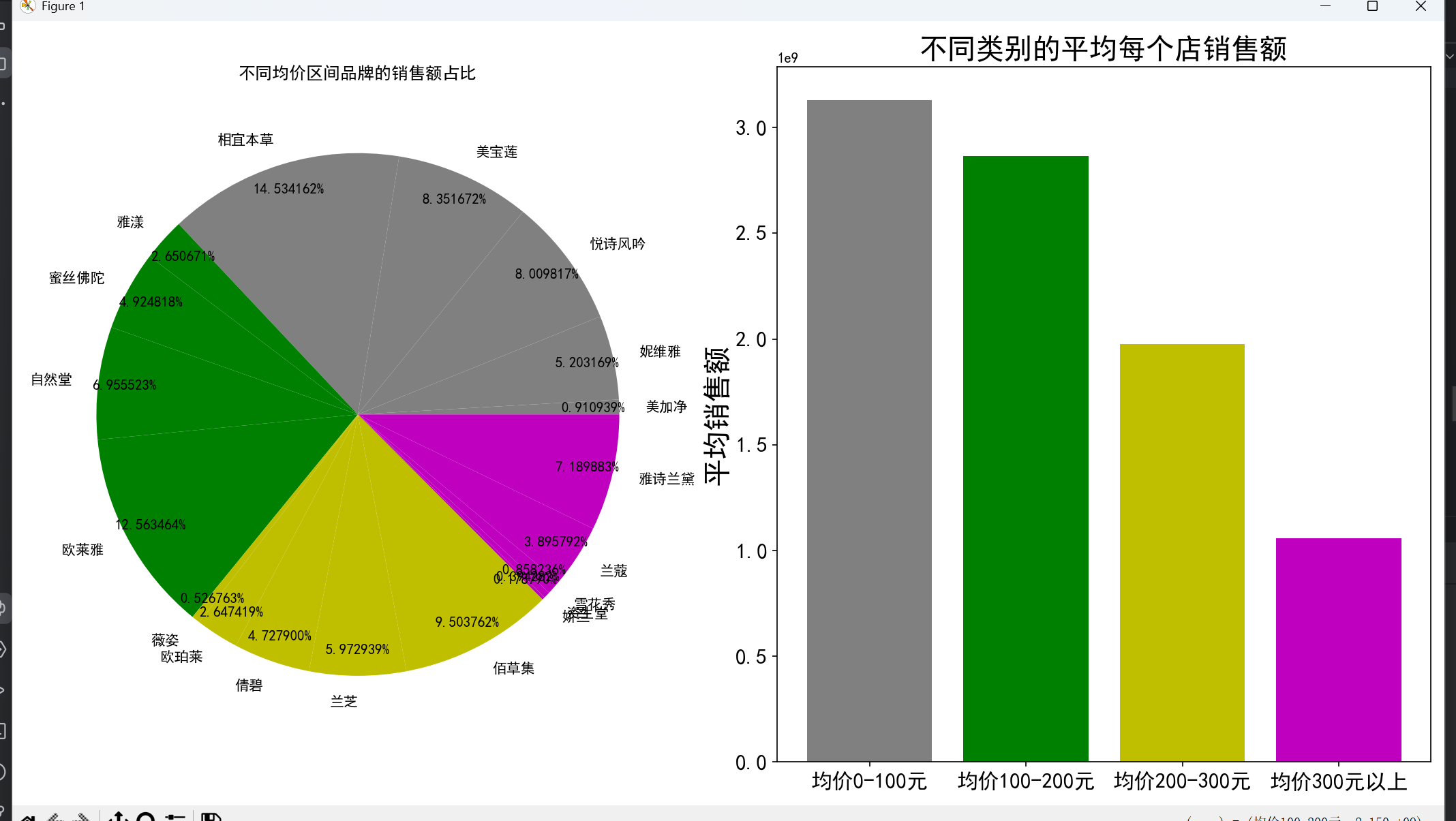
# 3.3 各類別銷售情況分析
plt.figure(figsize=(12, 12))
# 大類銷售量占比
plt.subplot(2, 2, 1)
data.groupby('main_type')['sale_count'].sum().plot.pie(autopct='%0f%%', title='各大類銷售量占比')
# 大類銷售額占比
plt.subplot(2, 2, 2)
data.groupby('main_type')['銷售額'].sum().plot.pie(autopct='%0f%%', title='各大類銷售額占比')
# 小類銷售量占比
plt.subplot(2, 2, 3)
data.groupby('sub_type')['sale_count'].sum().plot.pie(autopct='%0f%%', title='各小類銷售量占比')
# 小類銷售額占比
plt.subplot(2, 2, 4)
data.groupby('sub_type')['銷售額'].sum().plot.pie(autopct='%0f%%', title='各小類銷售額占比')
plt.tight_layout()
plt.show(block=True)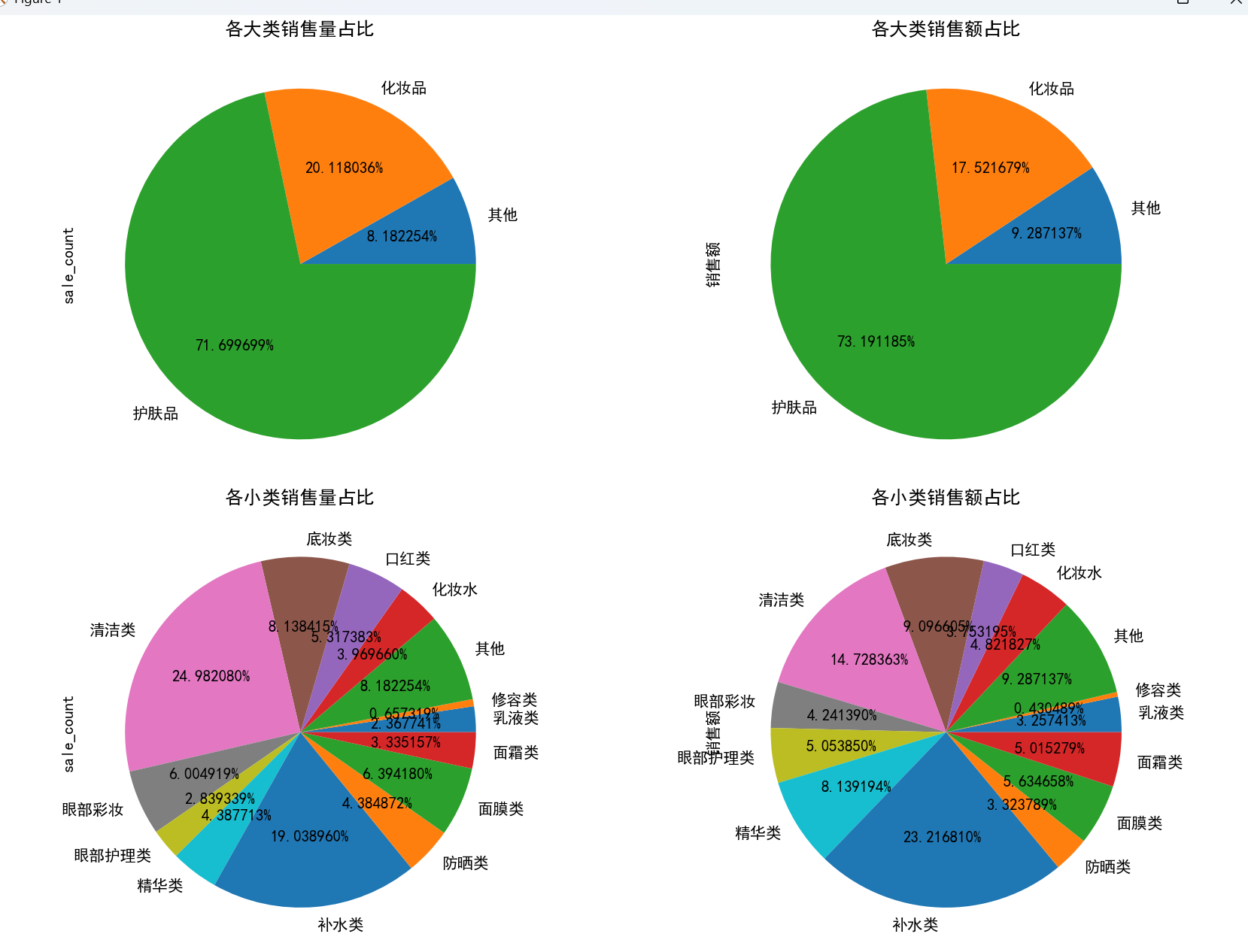
# 3.4 各店鋪不同類別銷售情況(去除銷量為0的店鋪)
data1 = data.drop(index=data[data['店名'].isin(
data.groupby('店名')['sale_count'].sum()[data.groupby('店名')['sale_count'].sum() == 0].index
)].index)
# 各店鋪中各大類的銷量與銷售額
plt.figure(figsize=(16, 12))
plt.subplot(2, 1, 1)
plt.tick_params(labelsize=10)
sns.barplot(x='店名', y='sale_count', hue='main_type', estimator=np.sum, data=data1, ci=0)
plt.title('各店鋪中各大類的銷售量', fontsize=20)
plt.ylabel('銷量', fontsize=15)
plt.subplot(2, 1, 2)
plt.tick_params(labelsize=10)
sns.barplot(x='店名', y='銷售額', hue='main_type', estimator=np.sum, data=data1, ci=0)
plt.title('各店鋪中各大類的銷售額', fontsize=20)
plt.tight_layout()
plt.show(block=True)
# 各店鋪中各小類的銷量與銷售額
plt.figure(figsize=(16, 12))
plt.subplot(2, 1, 1)
plt.tick_params(labelsize=10)
sns.barplot(x='店名', y='sale_count', hue='sub_type', estimator=np.sum, data=data1, ci=0)
plt.title('各店鋪中各小類的銷售量', fontsize=20)
plt.ylabel('銷量', fontsize=15)
plt.subplot(2, 1, 2)
plt.tick_params(labelsize=10)
sns.barplot(x='店名', y='銷售額', hue='sub_type', estimator=np.sum, data=data1, ci=0)
plt.title('各店鋪中各小類的銷售額', fontsize=20)
plt.ylabel('銷售額', fontsize=15)
plt.tight_layout()
plt.show(block=True)
# 各小類中各店鋪的銷量與銷售額
plt.figure(figsize=(16, 12))
plt.subplot(2, 1, 1)
plt.tick_params(labelsize=10)
sns.barplot(x='sub_type', y='sale_count', hue='店名', estimator=np.sum, data=data1, ci=0)
plt.title('各小類中各店鋪的銷售量', fontsize=20)
plt.ylabel('銷量', fontsize=15)
plt.subplot(2, 1, 2)
plt.tick_params(labelsize=10)
sns.barplot(x='sub_type', y='銷售額', hue='店名', estimator=np.sum, data=data1, ci=0)
plt.title('各小類中各店鋪的銷售額', fontsize=20)
plt.ylabel('銷售額', fontsize=15)
plt.tight_layout()
plt.show(block=True)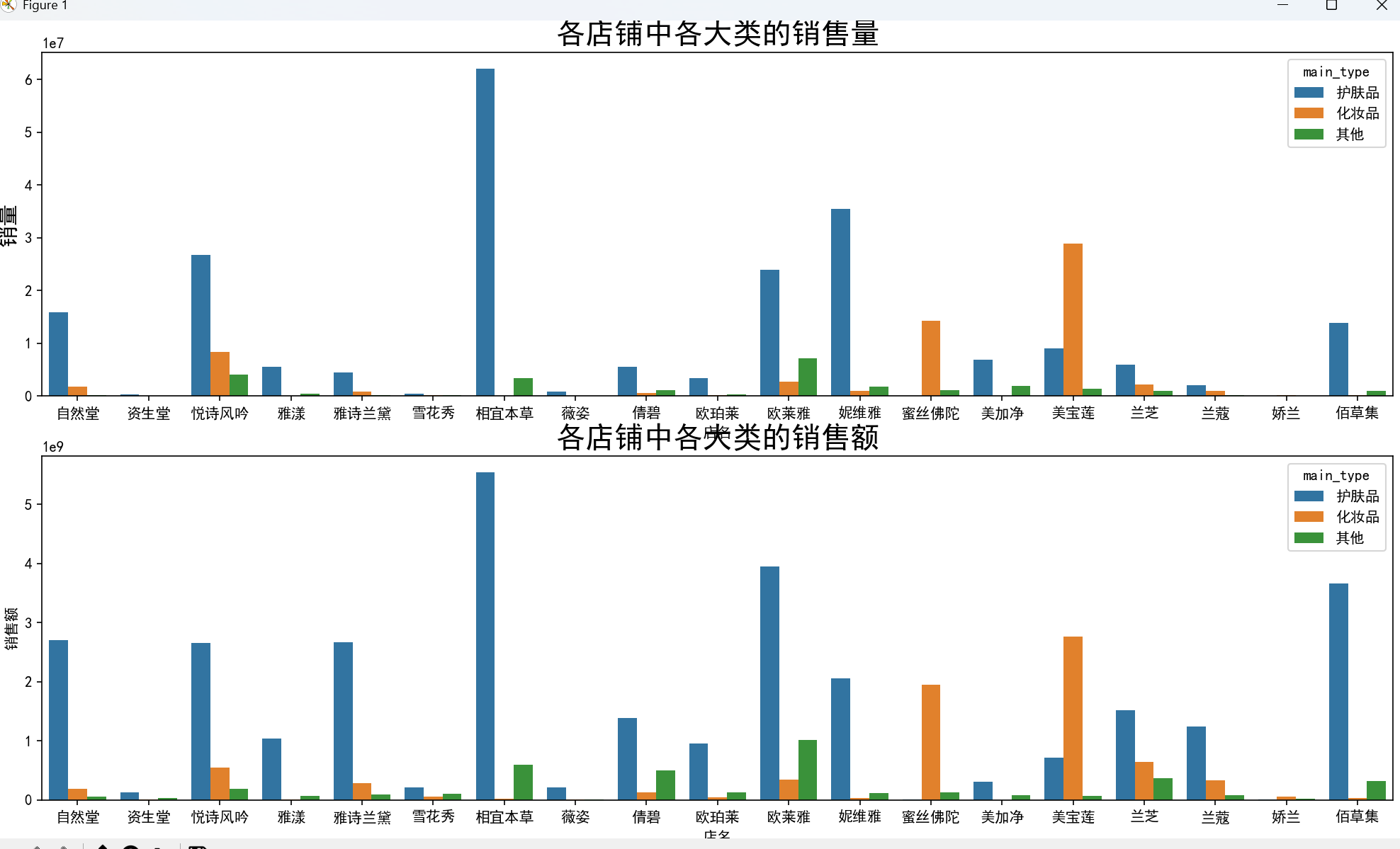
# 3.5 性別因素對銷售的影響
plt.figure(figsize=(16, 16))
# 男士專用各小類銷售量占比
plt.subplot(2, 2, 1)
data.loc[data['是否男士專用'] == '是'].groupby('sub_type')['sale_count'].sum().plot.pie(
autopct='%0f%%', title='男士各小類銷售量占比', pctdistance=0.8)
# 非男士專用各小類銷售量占比
plt.subplot(2, 2, 2)
data.loc[data['是否男士專用'] == '否'].groupby('sub_type')['sale_count'].sum().plot.pie(
autopct='%0f%%', title='非男士專用各小類銷售量占比', pctdistance=0.8)
# 男士專用銷售量占總銷售量比例
plt.subplot(2, 2, 3)
data.groupby('是否男士專用')['sale_count'].sum().plot.pie(
autopct='%0f%%', title='男士專用銷售量占比', pctdistance=0.8)
# 男士專用銷售額占總銷售額比例
plt.subplot(2, 2, 4)
data.groupby('是否男士專用')['銷售額'].sum().plot.pie(
autopct='%0f%%', title='男士專用銷售額占比', pctdistance=0.8)
plt.tight_layout()
plt.show(block=True)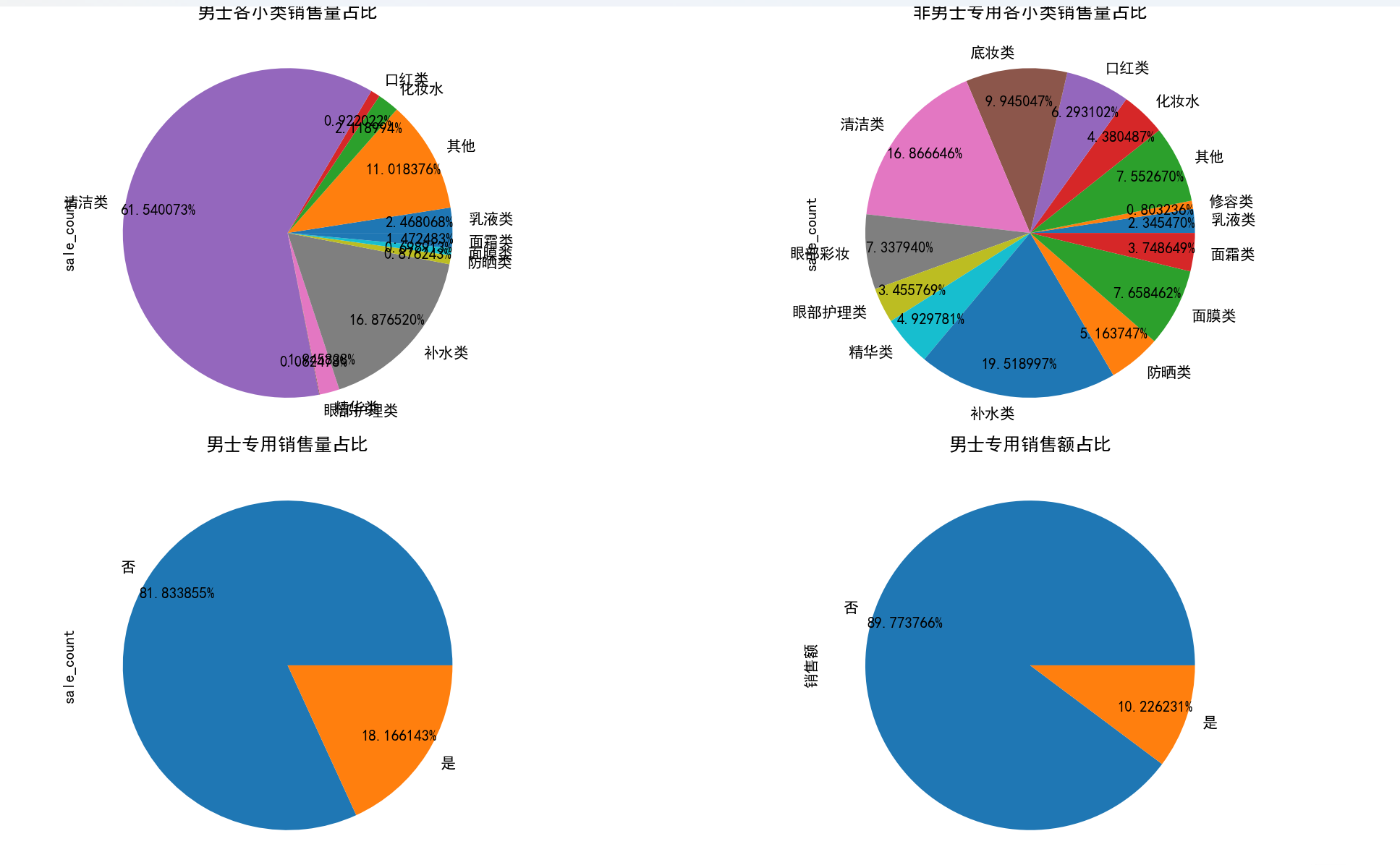
五、學習收獲與反思
通過本次實踐,我不僅熟練掌握了pandas的數據處理方法(如去重、填補缺失值、新增特征等)和matplotlib、seaborn的可視化技巧,更重要的是學會了從數據中挖掘有價值的信息,形成分析思路。
同時也認識到,數據分析需要結合業務場景進行合理推測,例如對缺失值的處理邏輯、商品類別的劃分標準等,都需要基于對美妝行業的基本認知。此外,可視化圖表的選擇應服務于分析目的,清晰、直觀地呈現結論是關鍵。
未來,在數據分析中可進一步引入更多維度(如時間對銷量的影響、評論情感分析等),使分析更加全面深入。






![[4.2-2] NCCL新版本的register如何實現的?](http://pic.xiahunao.cn/[4.2-2] NCCL新版本的register如何實現的?)




讀書筆記 23)

;declare -i /-x)





