來gongzhonghao【圖靈學術計算機論文輔導】,快速拿捏更多計算機SCI/CCF發文資訊~
在當下,機器人與深度學習的融合正成為AI領域的核心發展趨勢,相關研究在頂會頂刊上熱度居高不下。從ICLR到CoRL,諸多前沿成果不斷涌現,展現出該技術的巨大潛力。
本文精心整理了3篇聚焦機器人與深度學習融合的前沿論文,旨在助力大家洞悉前沿動態、把握研究思路,以便更好地應用于自身研究,有需要的讀者可自行取用 。
Incremental Language Understanding for Online Motion Planning of?Robot Manipulators
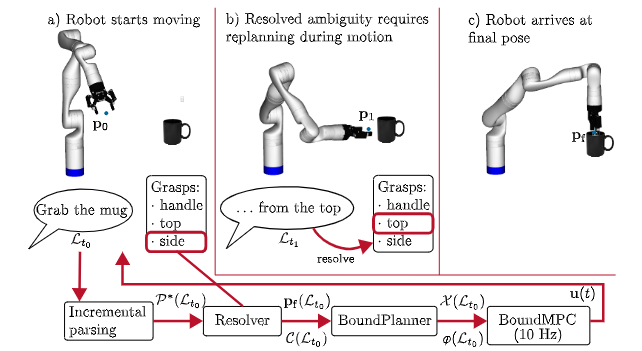
方法:作者設計了一個基于圖表結構的增量解析器,邊接收單詞邊構建并維護多個候選語義樹,同時把最新可信的語義片段實時送入 BoundPlanner 生成凸約束參考路徑,再由 BoundMPC 在 10 Hz 頻率下滾動優化關節軌跡;當后續口語引入新約束時,系統通過松弛變量和局部重規劃在 20 ms 內更新軌跡,保證機器人運動連貫且安全。
創新點:
首次將增量式語言解析器與在線運動規劃器深度耦合,實現毫秒級語言-動作閉環。
提出可回溯的多候選解析機制,機器人在聽到新詞后僅局部修正運動約束而無需重啟整段軌跡。
構建六類口語約束統一形式化框架,可直接映射到實時優化變量,使語音能在任意時刻插入并立即生效。
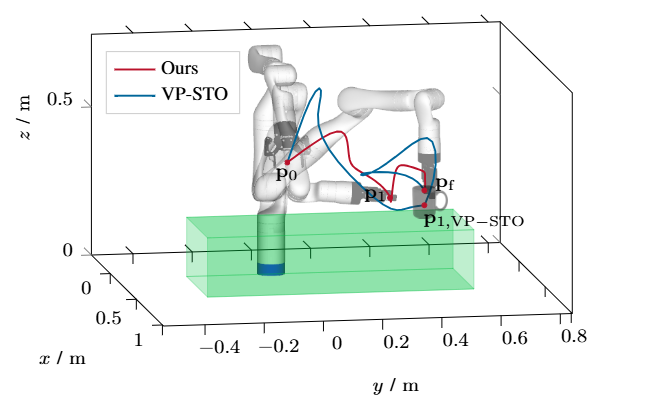
總結:這篇文章讓機器人像人一樣“邊聽邊改”,在手臂已經運動的過程中實時聽懂人類追加或糾正的口語指令,解決了傳統方法必須等完整指令、導致機器人頻繁停頓重規劃的痛點。
Improving Tactile Gesture Recognition with Optical Flow
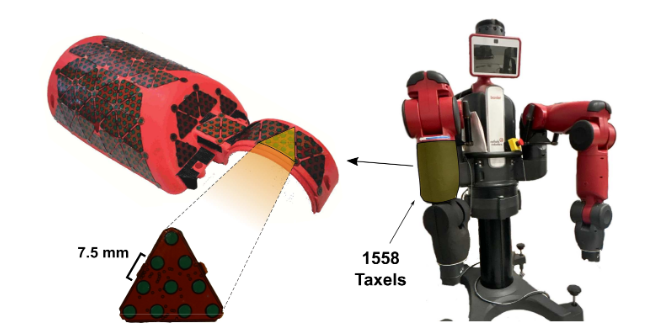
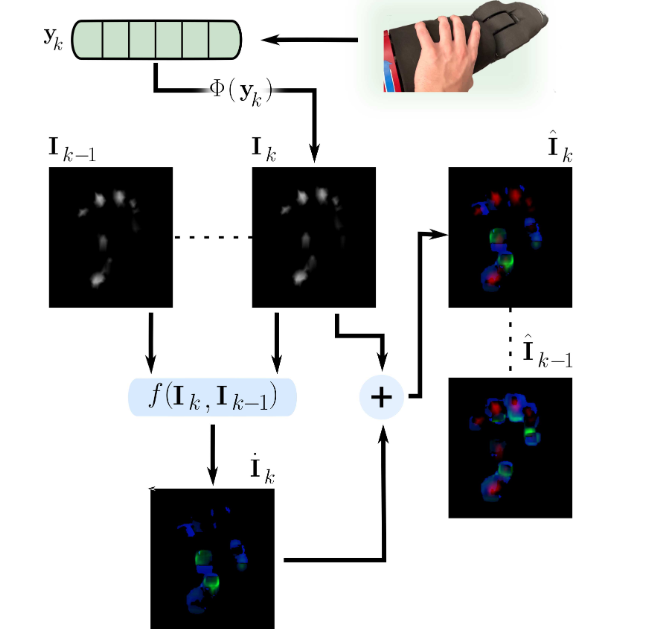
方法:作者先以 10 Hz 采集 1558 個電容式 taxel 的壓力陣列,將其空間插值為 357×334 的單通道觸覺圖像;接著用 Farneb?ck 算法在相鄰幀間計算稠密光流,把幅值與方向分別寫入綠、藍通道,與紅通道壓力合成 3 通道圖像;隨后用 ImageNet 預訓練的 EfficientNet-B0 逐幀提取空間特征,LSTM 捕捉時序關系,最后全連接層輸出五類手勢概率,整套流程在訓練與推理階段實時運行。
創新點:
首次將稠密光流嵌入觸覺圖像,把時序接觸動態壓縮成綠-藍兩通道,無需任何額外硬件即可顯著提升可分性。
構建 3 通道觸覺幀序列(紅通道壓力 + 綠藍光流),直接喂給 CNN-LSTM 架構,把“觸覺視頻”當視覺視頻處理,實現端到端訓練。
在包含 38 人、1900 樣本的新數據集上驗證,僅通過數據層面的光流增強就讓分類準確率從 80.7% 躍升到 89.1%,且輸入長度 L≥4 幀即可穩定獲益。
總結:這篇文章讓機器人“觸感也能看動態”,僅憑現有觸覺墊就解決了靜態壓力圖難以區分相似手勢的老大難問題。
糾結選題?導師放養?投稿被拒?對論文有任何問題的同學,歡迎來gongzhonghao【圖靈學術計算機論文輔導】,獲取頂會頂刊前沿資訊~
Language as Cost: Proactive Hazard Mapping using VLM?for Robot Navigation
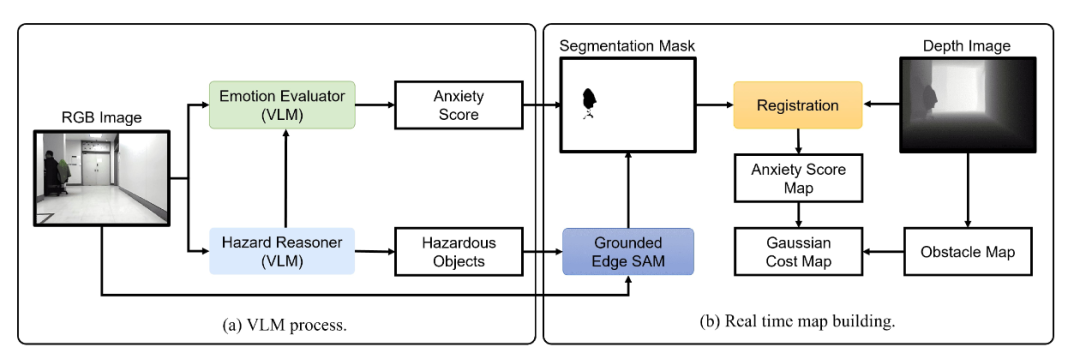
方法:系統先讓 GPT-4o 描述場景并列舉潛在危險,再由輕量 GPT-4o-mini 為每個危險對象給出 1–3 的焦慮分數;隨后 Grounded Edge SAM 依據危險名稱零 shot 生成分割掩膜,與深度圖融合后投影到 2D 柵格,每個危險單元以焦慮分數為權重生成高斯代價場;最終用 max-fusion 將代價場與傳統障礙圖合并,供 D*Lite + MPPI 實時規劃,實現“未見先避”的主動安全導航。
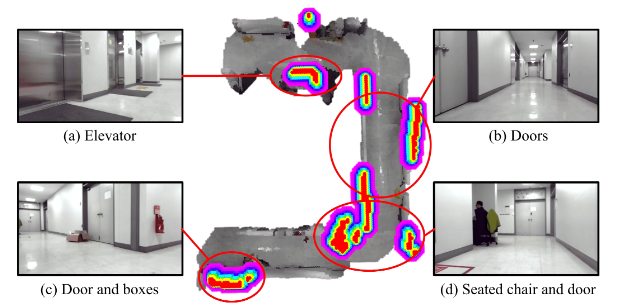
創新點:
首次提出“Language-as-Cost”零 shot 框架,直接拿 VLM 的文本風險描述生成連續代價圖,無需任何事先訓練或人工標注。
引入心理學啟發的“焦慮評分”機制,將 VLM 輸出的風險文字量化為 1–3 級數值,并通過高斯擴散動態調節風險空間影響范圍。
把零 shot 分割(Grounded Edge SAM)與 VLM 鏈式推理結合,實現對新物體、新場景的實時語義風險定位與在線地圖更新。
總結:這篇文章讓機器人像“焦慮人類”一樣提前腦補危險,用一句自然語言就能在地圖上畫出“隱形雷區”,徹底告別等碰撞才改道的被動導航。
關注gongzhonghao【圖靈學術計算機論文輔導】,快速拿捏更多計算機SCI/CCF發文資訊~
——在 CentOS 7 中配置阿里云鏡像源)



)
)







如何使用pt-query-digest進行查詢分析?)





WLAN熱點名稱修改不生效問題分析)