目錄
- 前言
- 1. 概念
- 2. HTTP基本格式
- 2.1 抓包原理
- 2.2 抓包軟件使用
- 2.3 抓包結果
- 3. HTTP請求
- 3.1 URL
- 3.2 方法
- 3.3 版本號
- 3.4 HTTP報頭
- 3.4 正文部分
- 4. HTTP響應
- 4.1 HTTP狀態碼
- 4.2 其他部分
- 總結
前言
本篇文章介紹HTTP的基本結構。
1. 概念
HTTP全稱為超文本傳輸協議,是一種應用非常廣泛的應用層協議。誕生于1991年,目前已經發展為最主流使用的應用層協議。超文本的意思是,文本中包含了更復雜的內容(例如圖片、視頻、音頻、特殊字體、鏈接等)。
2. HTTP基本格式
HTTP是一種文本格式的協議,我們需要使用抓包軟件來觀察HTTP的協議格式。這里使用fiddler進行抓包。
2.1 抓包原理
抓包軟件本質上是一個“代理程序”這里以fiddler為例,在瀏覽器訪問界面時,就會把HTTP請求先發給Fiddler,Fiddler再把請求轉發給對應的服務器,服務器返回數據時,Fiddler拿到返回數據,再把數據交給瀏覽器,所以Fiddler對于瀏覽器和服務器的交互細節是非常清楚的,所以抓包軟件就可以監聽網卡上通過的數據了。
2.2 抓包軟件使用
以fiddler為例,在這個地址進行安裝: fiddler安裝。
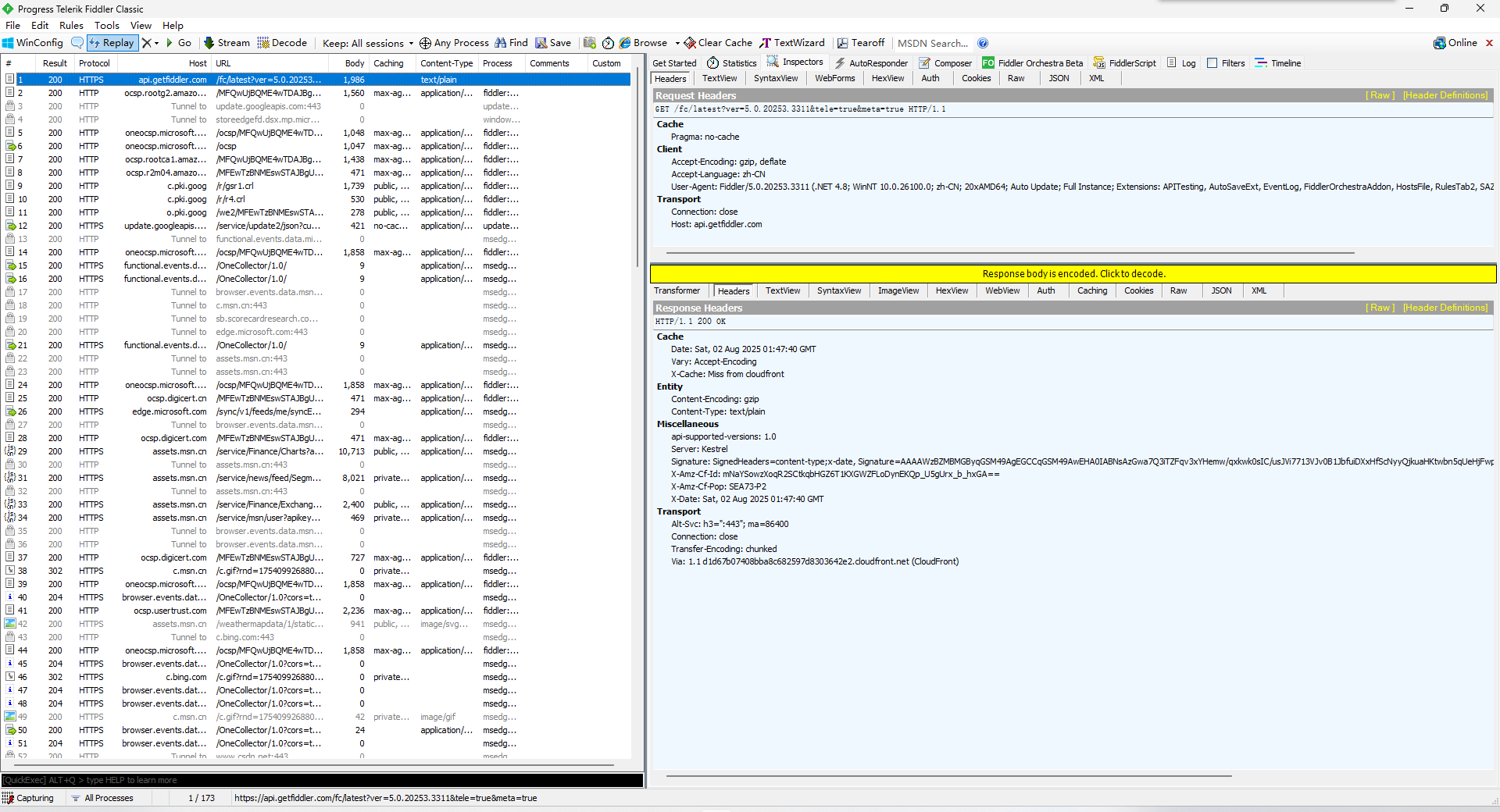
左側窗口顯示了所有的HTTP請求/響應,可以選中某個請求來觀看詳細內容,右側上方顯示HTTP請求的報文內容,右下方顯示了HTTP響應的報文內容。點擊Raw可以看到詳細的數據格式。
2.3 抓包結果
請求基本格式:
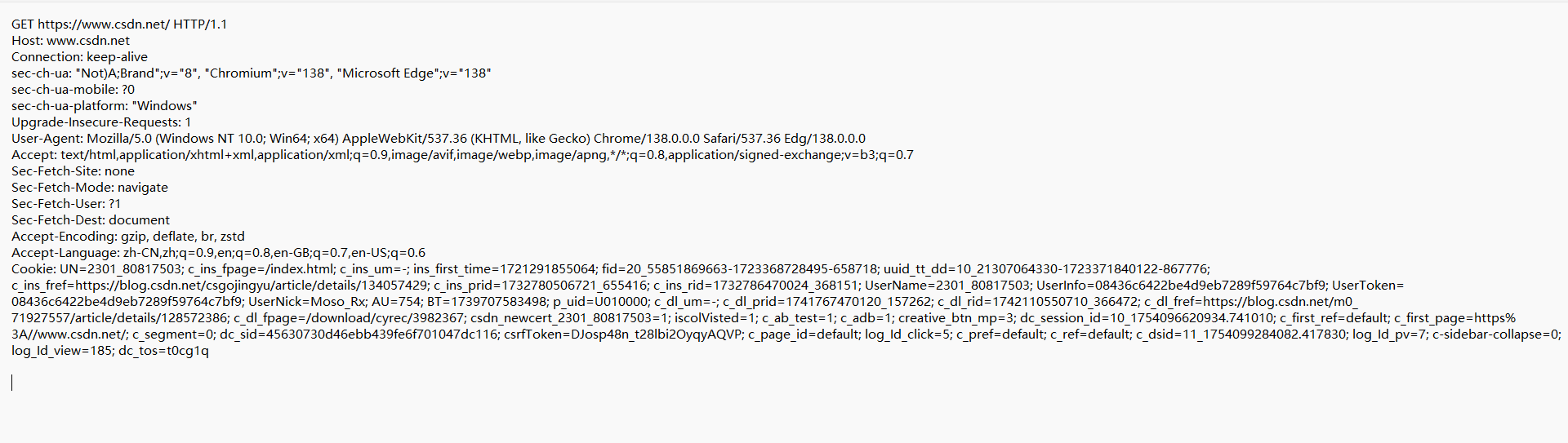
- 首行:請求中的第一行我們稱為首行。
- 請求頭:第二行開始往后若干行我們稱為請求頭。
- 空行:空行為請求頭的結束標記
- 正文:空行之后的內容(這里的請求沒有)
響應基本格式:
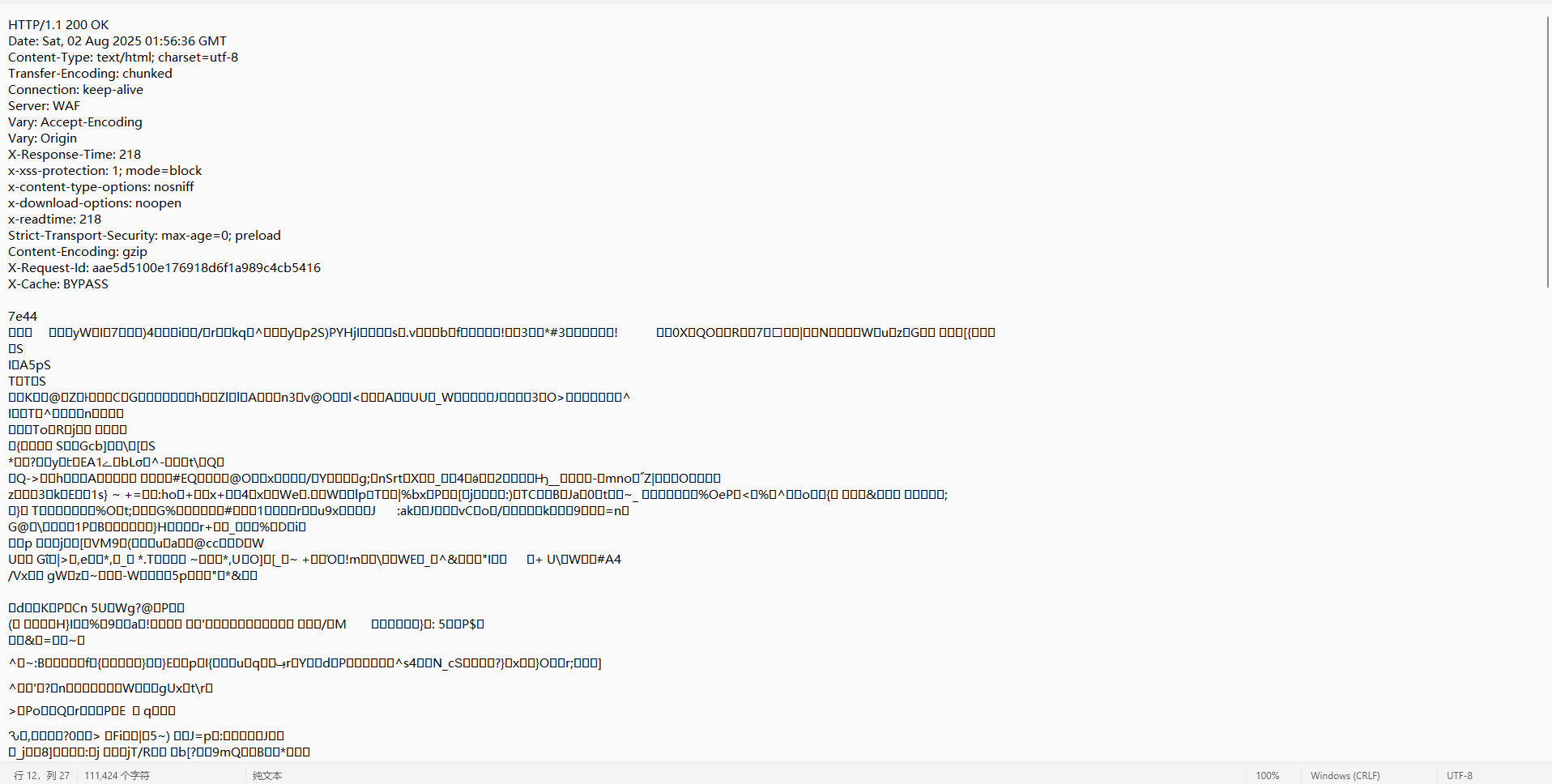
- 首行:請求中的第一行我們稱為首行。
- 響應頭:第二行后的若干行。
- 空行:空行為請求頭的結束標記。
- 正文:空行之后的內容
這里的正文可以看到是二進制內容,這是把文本壓縮成二進制了,用來節省資源。
解壓縮后:
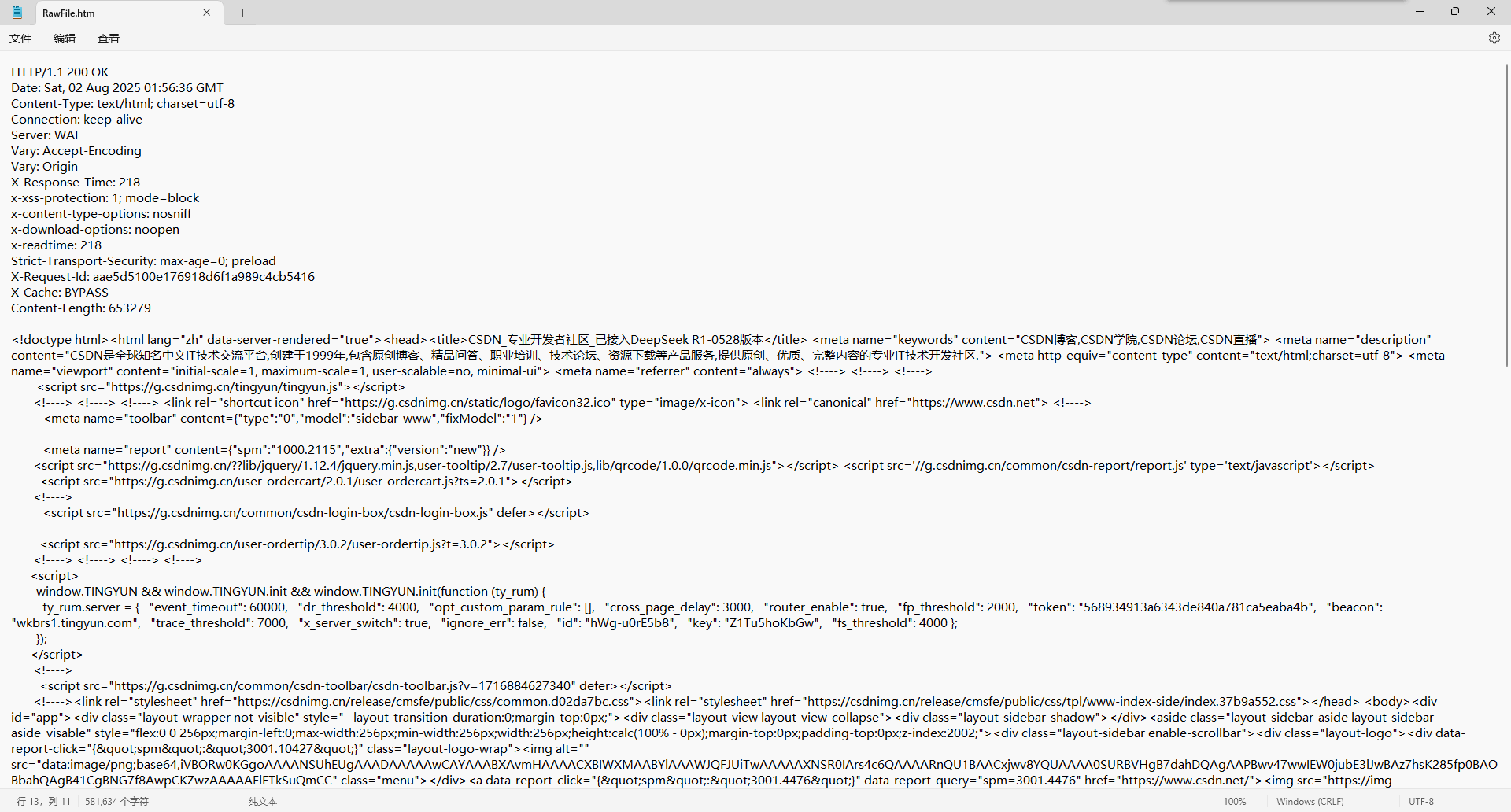
可以看到,正文部分包含了網頁的HTML。
3. HTTP請求
先看請求的首行:
GET https://www.csdn.net/ HTTP/1.1
這里分成了三個部分,GET稱為方法,HTTP/1.1這個部分稱為版本號,中間這個部分我們稱為URL。我們著重講這三個部分。
3.1 URL
URL全稱”唯一資源定位符“,描述了網絡上某個資源的具體位置。互聯網每個文件都有唯一的URL,它包含的信息指出了文件的位置以及瀏覽器對其的處理方式。
URL的完整結構:

協議方案名:常見的由http和https。
登錄信息:這里登錄信息(認證)的內容已經淘汰,現在已經沒有網站采取URL進行認證了。
服務器地址:是IP地址,一般填的是域名,會通過DNS系統解析成一個具體的IP地址。
端口號:如果省略,會根據協議自動決定使用哪個端口。
帶層次的文件路徑:一個機器上的一個服務器程序可能管理者很多資源,可能是真實的文件,也可能是一些動態生成的資源(根據請求計算出來的響應)。
查詢字符串:是鍵值對(query string)的格式,通過‘=”分割鍵和值。通過“&”分割多個鍵值對,這里鍵值對的含義由程序員來自定義。通過查詢字符就可以讓客戶端給服務器傳遞一些參數。
片段標識符:標識網頁的某個部分,實現“頁面內跳轉”功能,在一些文檔類網站,會帶有這個。
URL一些部分可以省略:
協議名:可以省略,省略后默認為http://
ip地址/域名:在HTML中可以省略。省略后標識服務器的ip/域名與當前HTML所屬的ip/域名一致。
端口號:可以省略。省略后如果是http協議,自動設為80;如果是https協議,自動設置為443
帶層次的文件路徑:可以省略。省略后相當于/。一些服務器在發現“/”路徑的時候自動訪問/index.html。
查詢字符串和片段標識也都可以省略。
關于URL encode
url的query string中的value部分可能需要進行轉義。規則是把特殊符號的 ascii碼取出來,按照字節維度插入一些“%”。
中文也需要轉義,這是因為中文通過uft8/gbk之類的編碼格式表示,可能某個漢字的utf8/gbk編碼中的某個字節,恰好和某個特殊符號的ascii碼相同了。
query string的內容,程序員可以自定義(尤其是value),如果value中包含特殊符號,就可能使url的解析出現錯誤。這是因為url中的特殊符號有特定含義。
3.2 方法
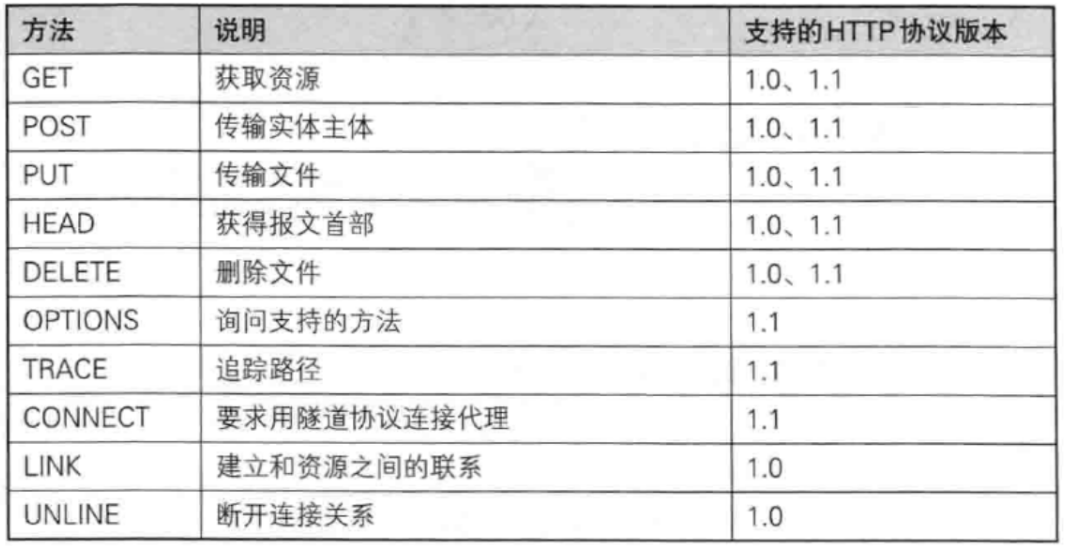
HTTP方法表達的是一種語義,介紹上圖幾個常用的:
- GET:從服務器獲取某個資源。
GET方法是HTTP中最常見的方法,很多操作都會觸發HTTP的GET請求:
直接在瀏覽器輸入url;
頁面上點擊一些跳轉鏈接;
HTML間接加載其他資源的時候(CSS,JS,圖片等 );
通過js/java/C++/Python等代碼手動構造GET請求。
GET請求特點:
GET請求一般沒有body;
GET請求要給服務器傳遞數據,往往是通過路徑/query string來進行傳遞。 - POST:向服務器上傳一些資源。
登錄時或者上傳資源/文件時會觸發。登陸時提交填寫的用戶和密碼。上傳資源/文件時提交傳輸資源的內容。
POST帶有body,通過body給服務器傳遞數據,通常下不使用query string傳遞數據。 - PUT:向服務器上傳某個資源(文件)。和POST差不多一樣。
- DELETE:刪除服務器的某個資源。和GET類似,也是一般不帶有body,通過quert string傳遞參數。
3.3 版本號
HTTP1.1是目前最主流的HTTP版本號。與請求不同的是,響應的版本號在首行的前面。
3.4 HTTP報頭
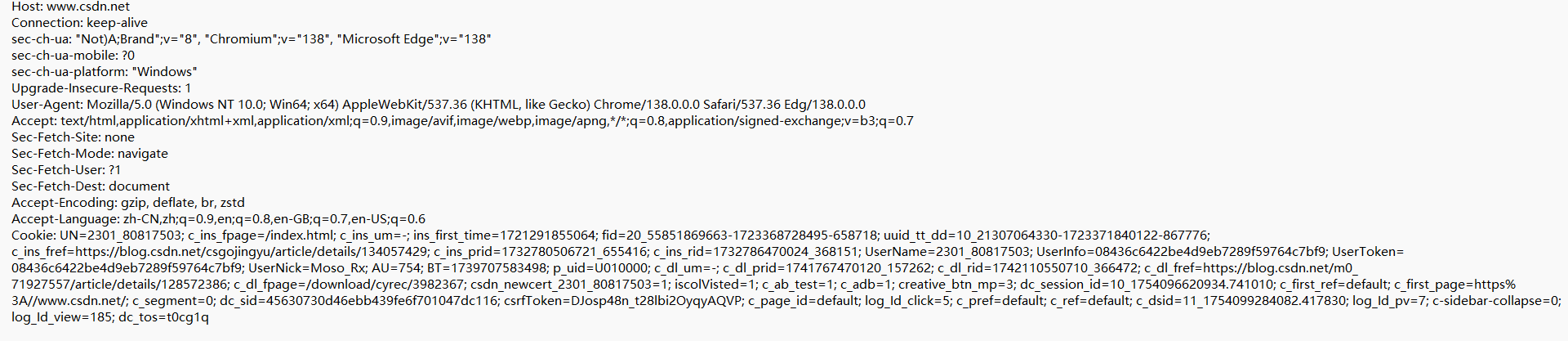
報頭的形式是行文本,每一行是一個鍵值對,鍵和值之間用 “ :加一個空格"(: ) 來分割。
介紹簡單一下header的一些key:
- Host:描述了訪問的服務器的IP(域名)和端口 (可以省略)
- Content-Length和Content-Type:前一個描述了body的長度,后一個描述了body的數據格式,所以在請求/響應中包含body時才會有這兩個key。Contet-Length這一個key解決了“粘包問題”。如果一個請求/響應,有body但沒有這其中一個key,那么這就是一個非法的“請求/響應”。
- User-Agent:表示瀏覽器/操作系統的屬性。
- Referer:表示這個界面是從哪個界面跳轉過來的。內容是一個網址。
- Cookie:Cookie中的內容是鍵值對,使用分號(;)來分割多個鍵值對,使用等號(=)來分割鍵和值。Cookie本質是瀏覽器在本地存儲數據的一種機制。此外,瀏覽器本地存儲cookie時,按照域名維度進行管理。
瀏覽器為了把控安全,瀏覽器會限制一個網站的權限,比如會禁止網站訪問硬盤,禁止網站調用電腦上的其他應用程序。所以網站如果在電腦上存儲一些數據,就需要用到Cookie,其中的內容是服務器返回給瀏覽器的,瀏覽器會把Cookie保存到本地,由于不允許網站隨意訪問硬盤,所以只能按照“鍵值對”形式來存儲簡單數據。
在服務器響應header中可能會包含set-cookie這樣的報頭,每一個set-cookie就對應一個cookie鍵值對。
Cookie鍵值對是自定義的,我們可以通過Cookie保存一些沒那么重要但是有用的信息,如“上次訪問時間”。
3.4 正文部分
請求的body部分,簡單介紹一下一些常見的數據格式,有application/json,text/html,text/css,application/JavaScript,image/png。
4. HTTP響應
4.1 HTTP狀態碼
在響應的首行就是HTTP的狀態碼。
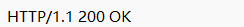
不同的狀態碼表示不同的含義,在官方文檔中有很多狀態碼,下面介紹幾種常用的:
- 200 OK:表示訪問成功,這里的成功表示HTTP層的成功,不代表業務層面的成功,比如注冊賬號,提交用戶名,由于用戶名重復,導致注冊失敗,這就是業務失敗,但也可以通過200這樣的狀態碼表示。
- 404 Not Found:客戶端要訪問的資源不存在,即URL中層次結構的路徑不存在。
- 403 Forbidden:訪問被拒絕(沒有權限訪問)
- 500 Internal Server Error:服務器拋出異常,崩潰了
- 504 Gateway TimeOut:服務器負載大,處理請求超時。
- 302 Move temporarily:臨時重定向,跳轉到另一個界面,例如登錄頁面登錄成功后自動跳轉到主頁。響應報文header部分會包含一個Location字段,表示要跳轉到哪個界面。
- 301 Moved Permanently:永久重定向,瀏覽器收到這種響應時,后續的請求都會被自動改成新的地址。
4.2 其他部分
響應報頭響應正文和上面請求對應的部分差不多,不再講述。
總結
本篇文章較為詳細的介紹了HTTP的基本結構,同時還順帶介紹了fiddle抓包工具,看完這篇文章后,希望你能對HTTP能夠有較為深入的理解。














Day15——性能監控與調優(二))

)


