Pipeline方法課堂筆記
一、Pipeline方法原理
pipeline方法是指在實體識別已經完成的基礎上再進行實體之間關系的抽取.
pipeline方法流程:
先對輸入的句子進行實體抽取,將識別出的實體分別組合;然后再進行關系分類.
注意:這兩個子過程是前后串聯的,完全分離.
pipeline方法的優缺點:
優點:
- 易于實現,實體模型和關系模型使用獨立的數據集,不需要同時標注實體和關系的數據集.
- 兩者相互獨立,若關系抽取模型沒訓練好不會影響到實體抽取.
缺點:- 關系和實體兩者是緊密相連的,互相之間的聯系沒有捕捉到.
- 容易造成誤差積累、實體冗余、交互缺失.
二、BiLSTM+Attention的模型原理
BiLSTM+Attention算法思想
BiLSTM+Attention模型最初由Zhou等人在2016年的論文《Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification》中提出.
該模型結合了雙向長短時記憶網絡 (Bidirectional LSTM) 和注意力機制 (Attention) ,用于處理輸入序列并提取關系信息. 該模型并被應用于關系分類任務.
BiLSTM+Attention模型架構:
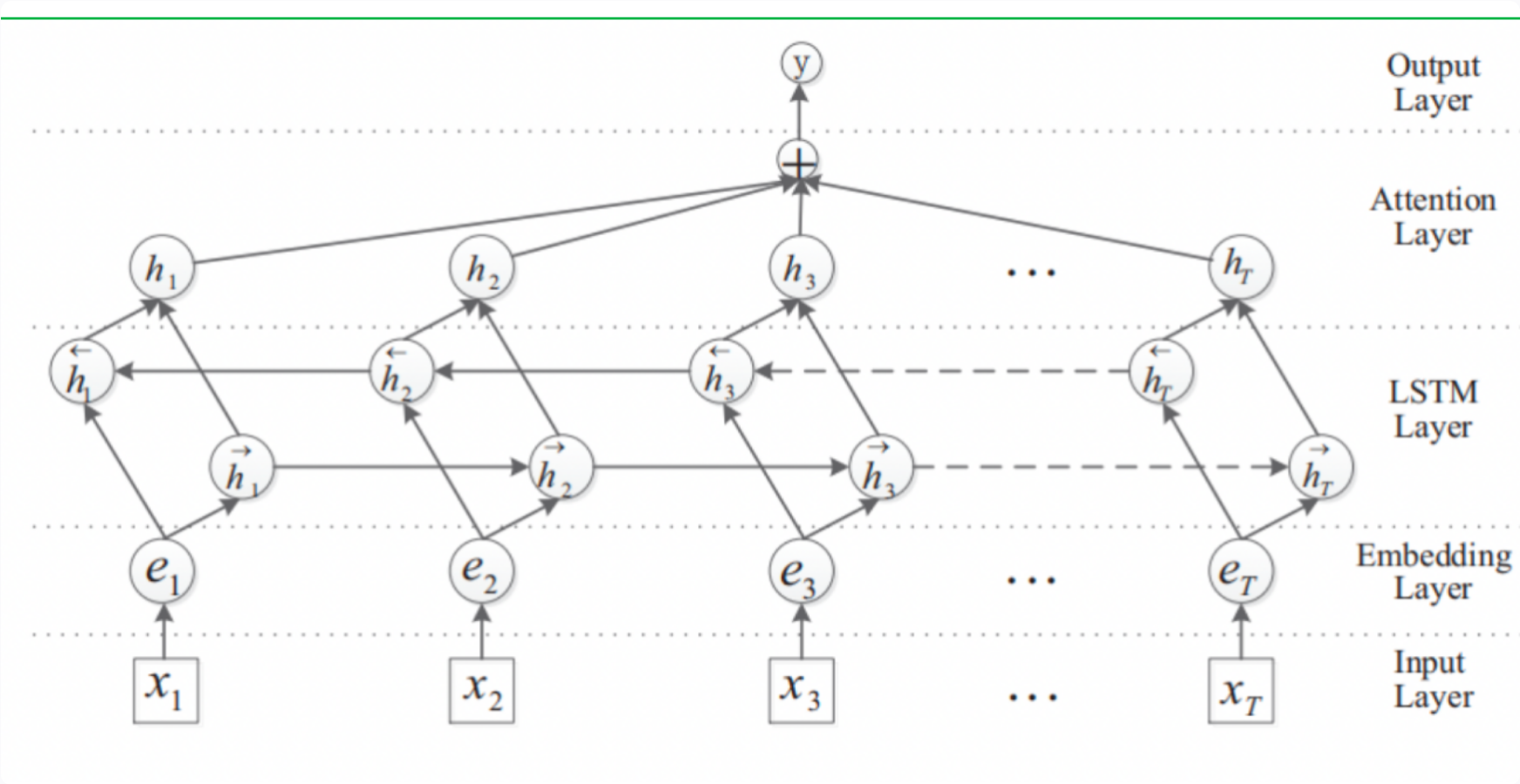
-
基于上圖模型架構所示: BiLSTM+Attention模型整體分為五個部分:
- 輸入層 (Input Layer) : 輸入的是句子,可以是字符序列也可以是單詞序列,或者兩者相結合. 此外,對于句子中的兩個實體,分別計算各個字符相對于實體的位置. 比如有如下樣本:
文本描述: “在《逃學威龍》這部電影中周星馳和吳孟達聯合出演” 在這個樣本中,實體1為周星馳,實體2為吳孟達. 關系為合作關系. 對于第一個字符“在”字來說,其相對于實體1的距離為: “在”字在字符序列中的索引-實體1在字符序列中的索引. 相對于實體2的距離為: “在”字在字符序列中的索引-實體2在字符序列中的索引. 因此,模型的輸入為子序列+字符的相對位置編碼-
詞嵌入層 (Embedding Layer) : 將每個單詞映射到一個高維向量表示,包括: 字符或詞嵌入以及相對位置編碼的嵌入,可以使用預訓練的詞向量或從頭開始訓練.
-
雙向LSTM層 (BiLSTM Layer) : LSTM是一種遞歸神經網絡,它可以對序列數據進行建模,用于從句子中提取特征. BiLSTM是一種雙向LSTM,它能夠同時捕捉上下文信息,包括前向和后向信息,因此在關系抽取任務中得到了廣泛應用.
-
注意力機制層 (Attention Layer) : 注意力機制可以讓模型集中注意力于關鍵詞或片段,有助于提高模型的性能. 這里注意力機制被用來確定每個句子中的單詞對于關系分類的重要性. 具體來說,對于輸入句子中的每個單詞,注意力機制會為其分配一個權重,表示該單詞對于關系分類的重要程度. 這些權重將被用于加權輸入句子中每個單詞的表示,以計算關系分類的輸出. 本次注意力機制的實現是采用的基于注意力權重的加權平均池化方式.
-
具體實現方式如下:
- 第一步: 將 BiLSTM 網絡的輸出 HHH 經過一個 tanhtanhtanh 激活函數,得到一個矩陣MMM
M=tanh(H) M = tanh(H) M=tanh(H)
- 第二步: 將 MMM 作為輸入,通過權重向量 wTw^TwT 和一個 softmax 函數,計算每個單詞對于關系分類的重要程度,得到的結果是一個權重向量 ααα .
α=softmax(wT?M) α = softmax(w^T*M) α=softmax(wT?M)
- 第三步: 將BiLSTM網絡的輸出 HHH 和注意力權重 ααα 相乘得到一個加權和 rrr
r=H?αT r = H * α^T r=H?αT
- 第四步: 將第三步得到的結果 rrr ,經過一個 tanhtanhtanh 激活函數,得到最終加權后的輸入句子中每個單詞的表示,以方便后續計算關系分類的輸出
h?=tanh(r) h^* = tanh(r) h?=tanh(r)
-
-
輸出層 (Output Layer) : 根據任務的不同,輸出層可以是分類層或回歸層. 在關系抽取任務中,輸出層通常是一個分類層,用于預測兩個實體之間的關系類型.
三、基于BiLSTM+Attention模型的數據預處理
關系抽取項目數據預處理
- 本項目中對數據部分的預處理步驟如下:
- 第一步: 查看項目數據集
- 第二步: 編寫Config類項目文件配置代碼
- 第三步: 編寫數據處理相關函數
- 第四步: 構建DataSet類與dataloader函數
第一步: 查看項目數據集
-
本次項目數據原始來源為公開的千言數據集https://www.luge.ai/#/,使用開源數據的好處,我們無需標注直接使用即可,本次項目的主要需要大家掌握實現關系抽取的思想。
-
項目的數據集包括3個文件:
-
第一個關系類型文件: relation2id.txt
導演 0
歌手 1
作曲 2
作詞 3
主演 4
- relation2id.txt中包含5個類別標簽, 文件共分為兩列,第一列是類別名稱,第二列為類別序號,中間空格符號隔開
- 第二個訓練數據集:train.txt
今晚會在哪里醒來 黃家強 歌手 《今晚會在哪里醒來》是黃家強的一首粵語歌曲,由何啟弘作詞,黃家強作曲編曲并演唱,收錄于2007年08月01日發行的專輯《她他》中似水流年 許曉杰 作曲 似水流年,由著名作詞家閆肅作詞,著名音樂人許曉杰作曲,張燁演唱交涉人 朝日電視臺 出品公司 《交涉人》是日本朝日電視臺制作并播出的8集懸疑推理電視劇生活啟示錄 閆妮 主演 05閆妮接到《生活啟示錄》之后,就向王麗萍推薦了胡歌北京北京 汪峰 歌手 ”汪峰我印象最深刻的是汪峰的《北京北京》蝕骨唱成燭骨千歲情人 王菲 主演 難怪春晚把那英秒成不一樣很多人都不知道 王菲演 的這部《千歲情人》,是1993年的一部穿越劇
天使的咒語 魏雪漫 歌手 魏雪漫專輯《天使的咒語》的同名主打歌曲與青春有關的日子 白百何 主演 白百何的處女座是《與青春有關的日子》,合作的演員是佟大為、陳羽凡高高至上 秋言 作詞 專輯曲目序號 曲目作詞作曲編曲1高高至上秋言秋言彭飛2高高至上(伴奏) 秋言秋言彭飛
train.txt 中包含18267行樣本, 每行分為4列元素,元素中間用空格隔開,第一列元素為實體1、第二列元素為實體2、第三列元素為關系類型、第四列元素是原始文本
- 第三個測試數據集:test.txt
三生三世十里桃花 安悅溪 主演 當《三生三世》4位女星換上現代裝: 第四,安悅溪在《三生三世十里桃花》中飾演少辛,安悅溪穿上現代裝十分亮眼,氣質清新脫俗失戀33天 白百何 主演 2011年,擔任愛情片《失戀33天》的編劇,該片改編自鮑鯨鯨的同名小說,由文章、白百何共同主演6愛人們的故事 裴勇俊 主演 《愛人們的故事》是全基尚導演,裴勇俊、李英愛、李慧英等主演的18集愛情類型的電視劇為你叫好 呂薇 歌手 基本資料 歌曲名稱: 為你叫好1歌手: 呂薇 所屬專輯: 《但愿人長久》歌詞 歌手: 呂薇 詞: 清風 曲: 劉青卡拉是條狗 路學長 導演 個人生活李佳璇和導演路學長因拍攝《卡拉是條狗》而相識,2003年兩人結婚上帝創造女人 簡-路易斯·特林提格南特 主演 《上帝創造女人》是羅杰·瓦迪姆執導的粉紅浪漫愛情影片,由碧姬·芭鐸和簡-路易斯·特林提格南特參加演出上帝創造女人 碧姬·芭鐸 主演 《上帝創造女人》是羅杰·瓦迪姆執導的粉紅浪漫愛情影片,由碧姬·芭鐸和簡-路易斯·特林提格南特參加演出
test.txt中包含5873行樣本, 每行分為4列元素,元素中間用空格隔開,第一列元素為實體1、第二列元素為實體2、第三列元素為關系類型、第四列元素是原始文本
第二步:編寫Config類項目文件配置代碼
- config.py
- config文件目的: 配置項目常用變量,一般這些變量屬于不經常改變的,比如: 訓練文件路徑、模型訓練次數、模型超參數等等
# coding:utf-8
import torchclass Config(object):def __init__(self):self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.train_data_path = "訓練文件絕對路徑名稱"self.test_data_path = "測試文件絕對路徑名稱" self.rel_data_path = "關系類型文件絕對路徑名稱" self.embedding_dim = 128self.pos_dim = 32self.hidden_dim = 200self.epochs = 50self.batch_size = 32self.max_len = 70self.learning_rate = 1e-3
第三步: 編寫數據處理相關函數
- 數據處理相關函數process.py
- 首選導入必備的工具包
# coding:utf-8
from config import *
from itertools import chain
from collections import Counterconf = Config()
# 獲取關系類型字典
relation2id = {}
with open(conf.rel_data_path, 'r', encoding='utf-8')as fr:for line in fr.readlines():word, id = line.rstrip().split(' ')if word not in relation2id:relation2id[word] = id
- 構建第一個數據處理相關函數sent_padding, 位于process.py中的獨立函數.
def sent_padding(words, word2id):"""把句子 words 轉為 id 形式,并自動補全為 max_len 長度。"""ids = []for word in words:if word in word2id:ids.append(word2id[word])else:ids.append(word2id['UNKNOW'])if len(ids) >= conf.max_len:return ids[:conf.max_len]ids.extend([word2id['BLANK']]*(conf.max_len-len(ids)))return ids
- 構建第二個數據處理相關函數pos, 位于process.py中的獨立函數.
def pos(num):'''將實體位置信息進行轉換,因為pos_embedding不能出現負數'''if num < -70:return 0if num >= -70 and num <= 70:return num+70if num > 70:return 142
- 構建第三個數據處理相關函數position_padding, 位于process.py中的獨立函數.
def position_padding(pos_ids):'''"""把 pos位置信息 轉為 id 形式,并自動補全為 max_len 長度。"""'''pos_ids = [pos(id) for id in pos_ids]if len(pos_ids) >= conf.max_len:return pos_ids[:conf.max_len]pos_ids.extend([142]*(conf.max_len - len(pos_ids)))return pos_ids
- 構建第四個數據處理相關函數get_train_data, 位于process.py中的獨立函數.
def get_txt_data(data_path):'''編碼訓練、測試數據集格式'''datas = []labels = []positionE1 = []positionE2 = []entities = []count_dict = {key: 0 for key, value in relation2id.items()}with open(data_path, 'r', encoding='utf-8')as tfr:for line in tfr.readlines():line = line.rstrip().split(' ', maxsplit=3)if line[2] not in count_dict:continueif count_dict[line[2]] > 2000:continueelse:entities.append([line[0], line[1]])sentence = []index1 = line[3].index(line[0])position1 = []index2 = line[3].index(line[1])position2 = []assert len(line) == 4for i, word in enumerate(line[3]):sentence.append(word)position1.append(i-index1)position2.append(i-index2)datas.append(sentence)labels.append(relation2id[line[2]])positionE1.append(position1)positionE2.append(position2)count_dict[line[2]] += 1return datas, labels, positionE1, positionE2, entities
- 構建第五個數據處理相關函數get_word_id, 位于 process.py 中的獨立函數.
def get_word_id(data_path):'''文本數字化表示處理,得到word2id, id2word'''datas, labels, positionE1, positionE2, entities = get_txt_data(data_path)data_list = list(set(chain(*datas)))word2id = {word: id for id, word in enumerate(data_list)}id2word = {id: word for id, word in enumerate(data_list)}word2id["BLANK"] = len(word2id)word2id["UNKNOW"] = len(word2id)id2word[len(id2word) + 1] = "BLANK"id2word[len(id2word) + 1] = "UNKNOW"return word2id, id2word
第四步: 構建DataSet類以及Dataloader函數
- 代碼路徑為: data_loader.py
- 首先導入相應的工具包
# coding:utf-8
import os
from torch.utils.data import DataLoader, Dataset
from utils.process import *
import torch
- 構建第一個數據處理相關類MyDataset, 位于data_loader.py中的獨立類.
class MyDataset(Dataset):def __init__(self, data_path):self.data = get_txt_data(data_path)def __len__(self):return len(self.data[0])def __getitem__(self, index):sequence = self.data[0][index]label = int(self.data[1][index])positionE1 = self.data[2][index]positionE2 = self.data[3][index]entites = self.data[4][index]return sequence, label, positionE1, positionE2, entites
- 構建第二個數據處理相關函數collate_fn, 位于data_loader.py中的獨立函數.
def collate_fn(datas):sequences = [data[0] for data in datas]labels = [data[1] for data in datas]positionE1 = [data[2] for data in datas]positionE2 = [data[3] for data in datas]entities = [data[4] for data in datas]word2id, id2word = get_word_id(conf.train_data_path)sequences_ids = []for words in sequences:ids = sent_padding(words, word2id)sequences_ids.append(ids)positionE1_ids = []positionE2_ids = []for pos_ids in positionE1:pos1_ids = position_padding(pos_ids)positionE1_ids.append(pos1_ids)for pos_ids in positionE2:pos2_ids = position_padding(pos_ids)positionE2_ids.append(pos2_ids)datas_tensor = torch.tensor(sequences_ids, dtype=torch.long, device=conf.device)positionE1_tensor = torch.tensor(positionE1_ids, dtype=torch.long, device=conf.device)positionE2_tensor = torch.tensor(positionE2_ids, dtype=torch.long, device=conf.device)labels_tensor = torch.tensor(labels, dtype=torch.long, device=conf.device)return datas_tensor, positionE1_tensor, positionE2_tensor, labels_tensor, sequences, labels, entities- 構建第三個數據處理相關函數get_loader_data, 位于data_loader.py中的獨立函數.
def get_loader_data():train_data = MyDataset(conf.train_data_path)train_dataloader = DataLoader(dataset=train_data,batch_size=conf.batch_size,shuffle=False,collate_fn=collate_fn,drop_last=True)test_data = MyDataset(conf.test_data_path)test_dataloader = DataLoader(dataset=test_data,batch_size=conf.batch_size,shuffle=False,collate_fn=collate_fn,drop_last=True)return train_dataloader, test_dataloader四、基于BiLSTM+Attention模型實現訓練
BiLSTM+Attention模型搭建
- 本項目中BiLSTN+Attention模型搭建的步驟如下:
- 第一步: 編寫模型類的代碼
- 第二步: 編寫訓練函數
- 第三步: 編寫使用模型預測代碼的實現.
第一步: 編寫模型類的代碼
- 構建BiLSTM_ATT模型類
- 代碼路徑: bilstm_atten.py
# coding:utf8
import torch
import torch.nn as nn
import torch.nn.functional as Fclass BiLSTM_ATT(nn.Module):def __init__(self, conf, vocab_size, pos_size, tag_size):super(BiLSTM_ATT, self).__init__()self.batch = conf.batch_sizeself.device = conf.deviceself.vocab_size = vocab_sizeself.embedding_dim = conf.embedding_dimself.hidden_dim = conf.hidden_dimself.pos_size = pos_sizeself.pos_dim = conf.pos_dimself.tag_size = tag_sizeself.word_embeds = nn.Embedding(self.vocab_size,self.embedding_dim)self.pos1_embeds = nn.Embedding(self.pos_size,self.pos_dim)self.pos2_embeds = nn.Embedding(self.pos_size,self.pos_dim)self.lstm = nn.LSTM(input_size=self.embedding_dim + self.pos_dim * 2,hidden_size=self.hidden_dim // 2,num_layers=1,bidirectional=True)self.linear = nn.Linear(self.hidden_dim,self.tag_size)self.dropout_emb = nn.Dropout(p=0.2)self.dropout_lstm = nn.Dropout(p=0.2)self.dropout_att = nn.Dropout(p=0.2)self.att_weight = nn.Parameter(torch.randn(self.batch,1,self.hidden_dim).to(self.device))def init_hidden_lstm(self):return (torch.randn(2, self.batch, self.hidden_dim // 2).to(self.device),torch.randn(2, self.batch, self.hidden_dim // 2).to(self.device))def attention(self, H):M = F.tanh(H)a = F.softmax(torch.bmm(self.att_weight, M), dim=-1)a = torch.transpose(a, 1, 2)return torch.bmm(H, a)def forward(self, sentence, pos1, pos2):init_hidden = self.init_hidden_lstm()embeds = torch.cat((self.word_embeds(sentence), self.pos1_embeds(pos1), self.pos2_embeds(pos2)), 2)embeds = self.dropout_emb(embeds)embeds = torch.transpose(embeds, 0, 1)lstm_out, lstm_hidden = self.lstm(embeds, init_hidden)lstm_out = lstm_out.permute(1, 2, 0)lstm_out = self.dropout_lstm(lstm_out)att_out = F.tanh(self.attention(lstm_out))att_out = self.dropout_att(att_out).squeeze()result = self.linear(att_out)return result第二步: 編寫訓練函數
-
實現訓練函數train.py
-
代碼位置: train.py
# coding:utf-8
from model.bilstm_atten import *
from utils.data_loader import *
from utils.process import *
import torch
import torch.nn as nn
import torch.optim as optim
import time
from tqdm import tqdmdef train(conf, vocab_size, pos_size, tag_size):# 加載數據集train_iter, test_iter = get_loader_data()print('訓練數據集長度', len(train_iter))# 實例化Bilstm+attention模型ba_model = BiLSTM_ATT(conf, vocab_size, pos_size, tag_size).to(conf.device)print(ba_model)# 實例化優化器optimizer = optim.Adam(ba_model.parameters(), lr=conf.learning_rate)# 實例化損失函數criterion = nn.CrossEntropyLoss()# 實現模型訓練ba_model.train()# 定義訓練模型參數start_time = time.time()train_loss = 0 # 已經訓練樣本的損失train_acc = 0 # 已經訓練樣本的準確率total_iter_num = 0 # 訓練迭代次數total_sample = 0 # 已經訓練的樣本數# 開始模型的訓練for epoch in range(conf.epochs):for sentence, pos1, pos2, label, _, _, _ in tqdm(train_iter):# 將數據輸入模型output = ba_model(sentence, pos1, pos2)# 計算損失loss = criterion(output, label)# 梯度清零optimizer.zero_grad()# 反向傳播loss.backward()# 梯度更新optimizer.step()# 計算總損失total_iter_num += 1train_loss += loss.item()# 計算總準確率train_acc = train_acc + sum(torch.argmax(output, dim=1) == label).item()total_sample = total_sample + label.size()[0]# print(f'total_sample--->{total_sample}')# 每25次訓練,打印日志if total_iter_num % 25 == 0:tmploss = train_loss / total_iter_numtmpacc = train_acc / total_sampleend_time = time.time()print('輪次: %d, 損失:%.6f, 時間:%d, 準確率:%.3f' % (epoch+1, tmploss, end_time-start_time, tmpacc))if epoch % 10 == 0:torch.save(ba_model.state_dict(), './save_model/20230228_new_model_%d.bin' % epoch)if __name__ == '__main__':word2id, id2word = get_word_id(conf.train_data_path)vocab_size = len(word2id)print(vocab_size)pos_size = 143tag_size = len(relation2id)train(conf, vocab_size, pos_size, tag_size)
- 模型訓練結果展示:
結論: BiLSTM+Attention模型在訓練集上的最終表現是ACC:80%








Day15——性能監控與調優(二))

)








的實用)