| 項目 | 內容 |
|---|---|
| 論文標題 | NavRL: 在動態環境中學習安全飛行 (NavRL: Learning Safe Flight in Dynamic Environments) |
| 核心問題 | 解決無人機在包含靜態和動態障礙物的復雜環境中進行安全、高效自主導航的挑戰,克服傳統方法和現有強化學習方法的局限性。 |
| 核心算法 | 基于近端策略優化(PPO)的深度強化學習。 |
| 主要創新點 | 1. NavRL框架:提出了一個完整的端到端深度強化學習導航框架,專為動態環境設計。 2. 零樣本遷移:通過精心設計的狀態(分離的動/靜態障礙物表示)和動作(歸一化速度)表示,實現了從仿真到真實世界的零樣本(Zero-shot)遷移。 3. 安全護盾:引入一個基于速度障礙(Velocity Obstacle)概念的簡單有效安全護盾,用于在線修正策略網絡輸出的潛在危險動作,顯著提高安全性。 4. 高效訓練:利用NVIDIA Isaac Sim實現大規模并行訓練(數千個智能體),并結合課程學習策略,大幅加速了模型收斂并提升了性能。 |
| 實驗驗證 | 在仿真環境(Isaac Sim, Gazebo)和真實物理環境中進行了廣泛的實驗,并與主流的規劃器(EGO-Planner, ViGO)進行了性能對比。 |
| 主要成果 | 該方法能夠在動態環境中實現安全導航,碰撞次數顯著低于基準方法,尤其是在動態和混合環境中。成功驗證了零樣本遷移到真實世界的能力,且整個系統能在機載計算機(Jetson Orin NX)上實時運行。 |
具體實現流程
該論文提出的NavRL框架的實現流程可以分解為以下幾個關鍵步驟,其邏輯緊密圍繞圖2所示的架構:
-
輸入(Input):
- 傳感器數據:機載RGB-D相機提供的彩色圖像和深度圖像。
- 機器人狀態:通過機載里程計(如LIO)獲取的機器人自身狀態,包括當前位置 PrP_rPr?、速度 VrV_rVr?,以及預設的導航目標點位置PgP_gPg?。
-
感知模塊(Perception Module):此模塊負責處理原始輸入,并區分靜態與動態障礙物。
- 靜態障礙物處理:利用深度圖像,即時構建一個3D占用體素地圖(Occupancy Voxel Map),用于表示環境中的靜態結構,如墻壁、柱子等。
- 動態障礙物處理:
- 使用一個集成的輕量級檢測器(U-depth + DBSCAN)來從點云中檢測3D邊界框。
- 利用輕量級YOLO分類器,對3D檢測框在2D圖像上的投影進行分類,以區分動態障礙物(如行人)。
- 通過卡爾曼濾波器對連續檢測到的動態障礙物進行跟蹤,以估計其位置 PoP_oPo? 和速度 VoV_oVo?。
-
狀態表示(State Representation):將感知結果轉化為策略網絡可以理解的格式。
- 靜態狀態 (S_stat):從機器人當前位置向3D占用地圖進行360度多層光線投射(Ray Casting),將得到的各方向光線長度(到障礙物的距離)組成一個2D矩陣。
- 動態狀態 (S_dyn):將最接近的 NdN_dNd? 個動態障礙物的相對位置、范數、相對速度、尺寸等信息組織成一個2D矩陣。
- 內部狀態 (S_int):將機器人到目標點的單位方向向量、距離以及自身速度,組合成一個1D向量。所有向量都在“目標坐標系”下表示,以增強泛化能力。
-
策略網絡與動作生成(RL Policy Network):
- 特征提取:兩個獨立的CNN(卷積神經網絡)分別處理靜態和動態狀態的2D矩陣,提取其特征并輸出為1D的嵌入向量。
- 狀態融合:將靜態特征嵌入、動態特征嵌入和內部狀態向量拼接(Concatenate)成一個完整的狀態向量。
- PPO決策:將完整的狀態向量輸入到基于PPO算法的演員網絡(Actor Network)。網絡輸出Beta分布的兩個參數
(α, β)。 - 動作解碼:從Beta分布中采樣或取均值,得到一個
[0, 1]范圍內的歸一化速度 VctrlnormV_{ctrl}^{norm}Vctrlnorm?,然后將其線性映射到機器人的實際速度控制指令 VrlV_{rl}Vrl?。
-
安全護盾(Safety Shield - 僅在部署時使用):
- 危險評估:根據所有感知到的障礙物(靜態和動態)的位置和速度,計算出它們對應的速度障礙(VO)區域。
- 動作校驗:判斷策略網絡輸出的速度指令 VrlV_{rl}Vrl? 是否落入任何一個VO區域內。
- 動作修正:
- 如果 VrlV_{rl}Vrl? 是安全的(不在任何VO內),則直接輸出該指令。
- 如果 VrlV_{rl}Vrl? 是不安全的,則求解一個小型優化問題(如式13所示),找到一個離 VrlV_{rl}Vrl? 最近且在所有VO區域之外的安全速度 VsafeV_{safe}Vsafe?。
-
最終輸出(Final Output):
- 將經過安全護盾校驗或修正后的最終安全速度指令發送給無人機的底層飛行控制器(如PX4)執行。
訓練流程:在訓練階段,不使用安全護盾。機器人的動作直接由策略網絡生成,并與環境交互。根據預定義的獎勵函數(包含速度、安全、平滑度等項)計算獎勵值,然后通過PPO算法更新演員網絡和評論家網絡(Critic Network)的權重。這個過程在NVIDIA Isaac Sim中大規模并行進行,以加速學習。
文章目錄
- I. 引言
- II. 相關工作
- III. 方法論
- A. 障礙物感知系統
- B. 強化學習公式
- C. 網絡設計和策略訓練
- D. 策略動作安全護盾
- IV. 結果與討論
- A. RL訓練結果
- B. 仿真實驗
- C. 物理飛行測試
- V. 結論與未來工作
摘要 - 在動態環境中安全飛行要求無人機(UAV)在充滿移動障礙物的擁擠空間中導航時做出有效決策。傳統方法通常將決策過程分解為用于預測和規劃的分層模塊。盡管這些手工設計的系統在特定場景下可能表現良好,但如果環境條件發生變化,它們可能會失效,并且通常需要仔細的參數調整。此外,由于使用不精確的數學模型假設和為實現計算效率而進行的簡化,其解決方案可能是次優的。為了克服這些限制,本文介紹了NavRL框架,這是一種基于近端策略優化(PPO)算法的深度強化學習導航方法。NavRL利用我們精心設計的狀態和動作表示,使得學習到的策略能夠在存在靜態和動態障礙物的情況下做出安全決策,并實現從仿真到真實世界飛行的零樣本遷移。此外,該方法受到速度障礙概念的啟發,為訓練好的策略采用了一個簡單而有效的安全護盾,以減輕神經網絡黑盒特性相關的潛在故障。為了加速收斂,我們使用NVIDIA Isaac Sim實現了訓練流程,能夠與數千架四旋翼無人機進行并行訓練。仿真和物理實驗1表明,我們的方法確保了在動態環境中的安全導航,并且與基準方法相比,碰撞次數最少。
索引術語 - 航空系統:感知與自主,強化學習,碰撞避免
I. 引言
自主無人機(UAV)被廣泛應用于勘探[1]、搜救[2]和檢查[3]等領域。這些任務通常發生在動態環境中,需要有效的碰撞避免。傳統方法依賴于手工制作的算法和分層模塊,導致系統過于復雜,參數難以調整。相比之下,強化學習(RL)允許無人機通過經驗學習決策,提供了更好的適應性和改進的性能。開發基于RL的導航方法對于增強無人機在動態環境中的安全性至關重要。
開發適用于真實世界部署的基于RL的導航方法面臨幾個挑戰。首先,由于強化學習涉及通過碰撞經驗來訓練機器人,學習過程必須在仿真環境中進行。這在仿真和真實世界的感官信息(特別是相機圖像)之間造成了“仿真到現實”(sim-to-real)的遷移問題。先前的工作試圖通過開發方法來減少仿真與真實世界環境之間的差距[4][5][6],或直接在真實世界環境中訓練機器人[7][8][9]。然而,這些方法通常需要額外的訓練步驟,并且在真實世界場景中訓練時數據效率低下。其次,即使訓練出的RL策略表現出令人滿意的性能,由于神經網絡的黑盒特性,確保安全仍然具有挑戰性,這需要一個有效的安全機制來防止嚴重故障[10][11][12][13]。最后,訓練一個強化學習策略需要大量的機器人經驗,而一些先前使用單個機器人收集數據的方法[14][15][16]由于數據多樣性有限和并行探索機會減少,常常導致收斂速度緩慢。
為了解決這些問題,本文提出了一種名為NavRL的深度強化學習導航框架,該框架基于近端策略優化(PPO)算法[17]。所提出的框架采用了基于我們感知模塊構建的狀態和動作表示,該模塊專為在動態環境中進行碰撞避免而設計,實現了零樣本的“仿真到現實”遷移能力。此外,為防止嚴重故障,我們利用速度障礙(VO)[18]的概念,創建了一個簡單而有效的安全護盾,通過線性規劃來優化RL策略網絡的動作輸出。為了加速訓練收斂,我們設計了一個能夠使用NVIDIA Isaac Sim同時模擬數千架四旋翼無人機的并行訓練流程。我們通過廣泛的仿真和物理飛行實驗驗證了所提出的框架。

圖 1. 使用提出的NavRL框架,一架定制的四旋翼無人機在動態環境中導航。該機器人在靜態和動態障礙物中實現了安全導航和有效的碰撞避免。
在各種環境中展示了其確保安全導航的能力。圖1展示了我們的無人機使用提出的NavRL框架在動態環境中導航的一個例子。這項工作的主要貢獻如下:
- NavRL導航框架:本工作介紹了一種新穎的基于強化學習的無人機導航系統,以確保在動態環境中的安全自主飛行。NavRL導航框架已作為開源包在GitHub2上提供。
- 策略動作安全護盾:我們的方法在策略網絡的動作輸出中加入了一個安全護盾,以基于速度障礙概念增強安全性。
- 物理飛行實驗:在各種環境中進行了真實世界的實驗,以展示所提出方法的安全導航能力和零樣本“仿真到現實”遷移的有效性。
II. 相關工作
關于無人機在動態環境中的導航研究通常依賴于基于規則的方法和手工制作的算法[19][20][21],這些方法可能很復雜,并且在條件變化時需要仔細調整。相比之下,基于學習的方法降低了復雜性,并且能更好地適應變化的環境。本節主要將基于學習的導航方法分為監督學習和強化學習兩類,同時也承認其他方法的存在。
監督學習方法:這類方法使用標記數據集來訓練網絡。早期的方法[8][22]在真實世界環境中部署機器人,收集圖像,并手動用真實的動作進行標記。類似地,一些方法[7][23]預測輸入圖像的安全性,而不是輸出決策,然后使用手工制作的算法來控制機器人。
上述方法需要手動標記的真實世界數據,并且由于數據不足,常常存在泛化能力有限的問題。Loquercio等人[24]在一個自動駕駛數據集上訓練網絡以實現導航,受益于其龐大的數據量。Jung等人[25]使用基于學習的檢測器使無人機在競速中穿過門,而在[26]中,迭代學習控制被應用于減少此場景下的跟蹤誤差。基于基礎模型的視覺導航研究已經利用來自各種機器人的真實世界經驗得以發展[27][28][29]。Simon等人[30]使用一種深度估計方法[31],為配備單目相機的無人機展示了碰撞避免能力。在[32]中提出了一種基于語義圖像的命令式學習方法,以實現語義感知的局部導航。
強化學習方法:與監督學習方法相比,強化學習方法受益于仿真中豐富的數據。一些利用Q學習[14][15][33]或價值學習[34][35]的方法已經展示了成功的導航。然而,這些方法受限于離散的動作空間,可能導致次優性能。
策略梯度方法[16][36],使用演員-評論家結構,因其能夠在連續動作空間中實現機器人控制而廣受歡迎。Kaufmann等人[37]在仿真中訓練了一個策略,在無人機競速中擊敗了人類冠軍,其他研究則增強了其控制性能[38][39]。Song等人[6]通過從具有特權信息的教師策略中蒸餾知識,開發了一個基于視覺的網絡,而Xing等人[40]則應用對比學習來改善圖像編碼。在[41]中,為無人機相關任務呈現了一個全面的強化學習訓練流程。
為確保安全,[42]中引入了一種使用“到達-規避”網絡的恢復策略,以防止失敗。類似地,Kochdumper等人[13]利用可達性分析將不安全的策略動作投影到安全區域。然而,他們的方法需要一個預先計算的可達性集合,其計算成本隨動作維度呈指數級增長。
大多數現有方法是為靜態環境中的導航和碰撞避免而設計的。一些方法,如[36],展示了動態障礙物避免能力,但沒有解決復雜靜態場景中的碰撞避免問題。[42]中的方法可以處理靜態和動態障礙物,但通過將動態障礙物視為靜態障礙物,其性能可能會次優。最近關注安全的方法要么計算成本高昂,要么需要大量訓練。這些挑戰,加上“仿真到現實”遷移的困難,促使我們提出了一個能夠確保安全導航,同時避免靜態和動態障礙物的框架。
III. 方法論
提出的NavRL導航框架如圖2所示。障礙物感知系統處理RGB-D圖像和機器人狀態,為靜態和動態障礙物生成表示(第III-A節)。第III-B節詳細說明了如何將這些障礙物表示轉換為網絡輸入狀態,以及機器人動作和訓練獎勵的定義。在訓練期間,我們采用帶有演員-評論家網絡結構的PPO算法來訓練策略和價值網絡,如第III-C節所述。在部署時,一個安全護盾被應用于RL策略網絡的動作輸出,以確保安全(第III-D節)。
A. 障礙物感知系統
由于靜態和動態障礙物的屬性不同,我們的感知系統對它們進行分開處理,如圖2所示。靜態障礙物可以有任意的形狀和大小,使用離散化格式(如占用體素地圖)可以更準確地表示。相反,通常被建模為剛體的動態障礙物,則使用帶有估計速度信息的邊界框來表示。為靜態和動態障礙物使用不同表示的理由在于它們各自的特性。靜態障礙物有時具有不規則的幾何形狀,使得離散表示更適合準確描述其形狀。相比之下,動態障礙物(通常是剛體)需要一種能將其作為一個整體來捕捉其狀態的表示。此外,用動態障礙物更新占用地圖會引入噪聲和延遲。
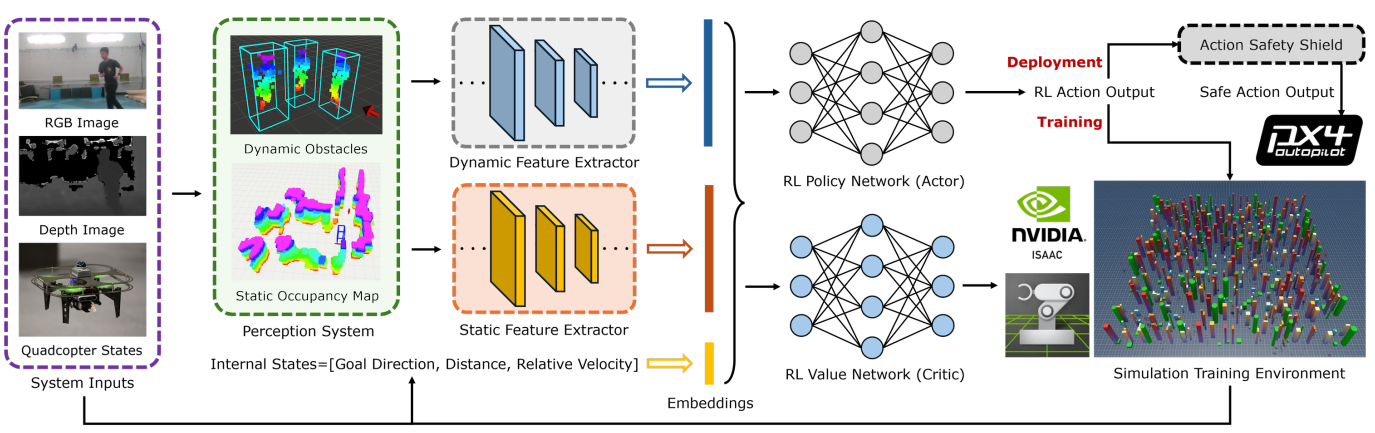
圖 2. 提出的NavRL框架。感知系統處理RGB-D圖像和機器人的內部狀態,為靜態和動態障礙物生成表示。然后,這些表示被送入兩個特征提取器,其產生的狀態嵌入與機器人的內部狀態拼接在一起。在訓練階段,使用演員-評論家結構在NVIDIA Isaac Sim環境中并行訓練機器人。在部署階段,策略網絡生成的動作會經過安全護盾機制的進一步精煉,以確保安全的機器人控制。
進一步證明了需要分離表示的合理性。對于靜態障礙物的感知,我們創建了一個具有固定內存大小的3D占用體素地圖,其大小由環境適用的最大體素數量決定。每個體素的占用數據存儲在預分配的數組中。這種設計使我們能夠以常數時間復雜度(O(1))訪問占用信息。在每個時間步,我們根據最新的深度圖像遞歸地更新每個體素的占用對數概率,并通過迭代它們檢測到的邊界框來清除動態障礙物的占用數據。需要注意的是,這個靜態占用地圖可以即時生成,無需任何預先構建的數據。
由于輕量級無人機相機的深度圖像噪聲較大以及機載計算機處理能力有限,檢測3D動態障礙物具有挑戰性。為了在最小計算需求下實現準確檢測,我們提出了一種結合了兩個基于[43]構建的輕量級檢測器的集成方法。第一個是U-depth檢測器[44],它將原始深度圖像轉換為U-depth圖(類似于俯視圖),并使用連續線分組算法來檢測3D障礙物邊界框。第二個是DBSCAN檢測器,它將DBSCAN聚類算法應用于深度圖像的點云數據,通過分析每個聚類內的邊界點來識別障礙物的中心和尺寸。然而,由于輸入數據噪聲大,這兩個檢測器都可能產生大量假陽性。我們提出的集成方法通過尋找兩個檢測器之間的一致結果來解決這個問題。此外,為了區分靜態和動態障礙物,我們采用一個輕量級的YOLO檢測器,通過檢查從3D檢測重新投影到圖像平面上的2D邊界框來對動態障礙物進行分類。
動態障礙物的速度由跟蹤模塊估計,該模塊分兩個階段運行:數據關聯和狀態估計。在數據關聯階段,目標是建立連續時間步之間檢測到的障礙物的對應關系。為了最小化檢測失配,我們為每個障礙物構建一個特征向量,包括其位置、邊界框尺寸、點云大小和點云標準差,然后根據潛在匹配障礙物之間的相似性得分來確定匹配。在狀態估計階段,使用卡爾曼濾波器來估計障礙物速度,并應用恒定加速度模型來解釋速度隨時間的變化。值得注意的是,雖然本框架中的感知系統是基于相機的,但如果其他傳感器能提供類似的障礙物表示,也可以使用它們。感知系統中的動態障礙物檢測和跟蹤基于[43]中提出的方法,讀者可以在其中找到更多細節和實現細節。
B. 強化學習公式
導航任務被形式化為一個馬爾可夫決策過程(MDP),由元組(S, A, P, R, γ)定義,其中S是狀態空間(機器人的內部和感官數據),A是動作空間,轉移函數P(st+1∣st,at)P(s_t+1|s_t, a_t)P(st?+1∣st?,at?)模擬環境動態,獎勵函數R(st,at)R(s_t, a_t)R(st?,at?)鼓勵達到目標的行為,同時懲罰碰撞和低效動作。目標是學習一個最優策略π?(at∣st)π^*(a_t|s_t)π?(at?∣st?),以最大化期望的累積獎勵:
π?=arg?max?πE[∑t=0TγtR(st,at)](1)\pi^* = \arg\max_\pi E[\sum_{t=0}^T \gamma^t R(s_t, a_t)] \quad (1) π?=argπmax?E[t=0∑T?γtR(st?,at?)](1)
其中γ ∈ [0, 1]是未來獎勵的折扣因子。這個公式使得可以使用強化學習來訓練機器人在動態環境中進行安全導航。
狀態:作為策略的輸入,狀態必須包含與導航和碰撞避免相關的所有信息。在我們的系統框架(圖2)中,設計的狀態由三部分組成:機器人的內部狀態、動態障礙物和靜態障礙物。機器人的內部狀態提供了關于機器人朝向導航目標的方向和距離的詳細信息,以及其當前速度,定義為:
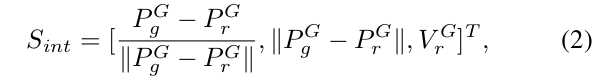
其中PrP_rPr?和PgP_gPg?分別代表機器人位置和目標位置,VrV_rVr?是機器人當前速度。上標(.)G(.)^G(.)G表示該向量在“目標坐標系”中表示,該坐標系的原點定義在機器人的起始位置。在這個坐標系中,x軸與從起始位置PsP_sPs?指向目標位置的向量對齊,而y軸平行于地平面。這種目標坐標系變換減少了對全局坐標系的依賴,提高了RL訓練的整體收斂速度,并且也將應用于障礙物狀態表示的定義中。
動態障礙物由一個2D矩陣表示:
Sdyn=[D1,...,DNd]T,Sdyn∈RNd×M,Di∈RM.(3)S_{dyn} = [D_1, ..., D_{N_d}]^T, \quad S_{dyn} \in \mathbb{R}^{N_d \times M}, D_i \in \mathbb{R}^M. \quad (3) Sdyn?=[D1?,...,DNd??]T,Sdyn?∈RNd?×M,Di?∈RM.(3)
在這個公式中,D_i表示第i個最接近的動態障礙物的狀態向量,表示為:
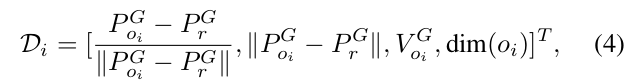
其中PoP_oPo?和VoV_oVo?分別代表動態障礙物的中心位置和速度,dim(ot)dim(o_t)dim(ot?)表示障礙物的高度和寬度。動態障礙物的數量NdN_dNd?是預定義的,如果實際檢測到的障礙物數量小于此預定義限制,則狀態向量的值設為零。內部狀態和障礙物狀態的相對位置向量被分解為單位向量和其范數,因為這種方法在我們的實驗中顯示出稍快的收斂速度。
與動態障礙物相比,靜態障礙物被表示為地圖體素,不能直接輸入到神經網絡中。因此,我們從機器人位置對地圖進行3D光線投射。在圖3a中,光線在最大范圍內以用戶定義的光線投射角度間隔向所有水平方向投射。類似地,圖3b展示了在垂直平面上的相同操作。對于垂直平面中的每個對角光線投射角度θiθ_iθi?,水平平面中所有光線的長度被記錄為一個向量RθR_θRθ?。任何超過最大范圍的光線都被賦予一個等于最大范圍加上一個小的偏移量的長度,從而可以識別出沒有障礙物的情況。靜態障礙物的表示是通過堆疊所有垂直平面中對角光線角度的光線長度向量來構建的:
Sstat=[Rθ0,...,RθNv],Sstat∈RNh×Nv,Rθi∈RNh,(5)S_{stat} = [R_{\theta_0}, ..., R_{\theta_{N_v}}], S_{stat} \in \mathbb{R}^{N_h \times N_v}, R_{\theta_i} \in \mathbb{R}^{N_h}, \quad (5) Sstat?=[Rθ0??,...,RθNv???],Sstat?∈RNh?×Nv?,Rθi??∈RNh?,(5)
其中NvN_vNv?和NhN_hNh?代表垂直和水平平面中的光線數量,由光線投射角度間隔和垂直視場決定。與使用圖像數據作為狀態表示不同,提出的RL狀態表示在仿真和真實世界之間的差異最小,這對于“仿真到現實”的遷移是有益的。
動作:在每個時間步,向機器人提供速度控制V_ctrl ∈ R3用于導航和碰撞避免。選擇速度控制是因為更高層次的控制在不同平臺之間提供了更好的可移植性和泛化性,便于“仿真到現實”的遷移。此外,與較低層次的控制相比,速度指令更具可解釋性,也更容易由人類監督。該策略不是直接輸出速度值,而是被設計為首先推斷一個歸一化的速度 V_ctrl^norm,最終的輸出速度表示為:
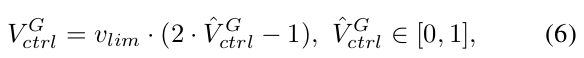
其中VlimV_{lim}Vlim?是用戶定義的最大速度。最終速度在目標坐標系中表示,如狀態公式中所述,需要對機器人應用坐標變換。這種方法比其他RL策略必須學習動作限制且不能輕易調整訓練好的動作范圍的公式提供了更大的靈活性。為了將網絡輸出限制在[0,1]范圍內,模型被設計為生成Beta分布的參數(α, β),如圖4所示。當RL動作空間受限時,基于Beta分布的策略已被證明是無偏的,并且與基于高斯分布的策略相比,能實現更快的收斂[45]。在訓練過程中,通過使用生成的參數從Beta分布中采樣來鼓勵探索。在部署時,我們使用Beta分布的均值作為歸一化的速度輸出。
獎勵:設計的RL獎勵函數在每個時間步計算,由多個部分組成:
r=λ1rvel+λ2rss+λ3rds+λ4rsmooth+λ5rheight,(7)r = \lambda_1 r_{vel} + \lambda_2 r_{ss} + \lambda_3 r_{ds} + \lambda_4 r_{smooth} + \lambda_5 r_{height}, \quad (7) r=λ1?rvel?+λ2?rss?+λ3?rds?+λ4?rsmooth?+λ5?rheight?,(7)
其中r_(.)表示由λ加權的一種獎勵類型。每種獎勵將在以下段落中解釋。
a) 速度獎勵r_vel:速度獎勵鼓勵機器人采用能導向目標位置的速度:
rvel=Pg?Pr∣∣Pg?Pr∣∣?Vr,其中?Pg,Pr,Vr∈R3.(8)r_{vel} = \frac{P_g - P_r}{||P_g - P_r||} \cdot V_r, \quad \text{其中 } P_g, P_r, V_r \in \mathbb{R}^3. \quad (8) rvel?=∣∣Pg??Pr?∣∣Pg??Pr???Vr?,其中?Pg?,Pr?,Vr?∈R3.(8)
這個公式獎勵那些與朝向目標位置的方向更一致且速度更快的速度。
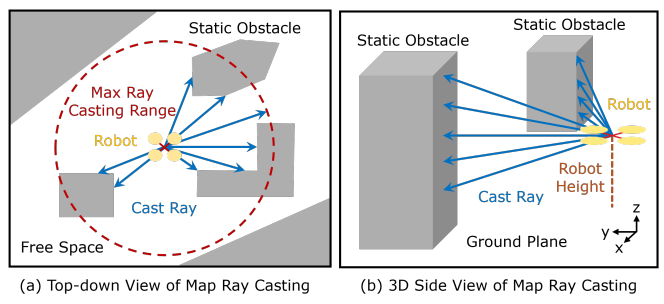
圖 3. 地圖光線投射示意圖。僅顯示最大范圍內的光線。(a) 具有360度投射角度的水平投射光線的俯視圖。(b) 顯示垂直平面中光線的側視圖。
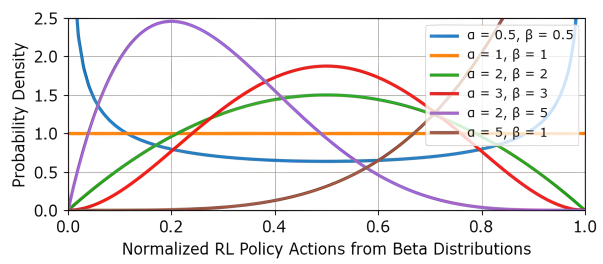
圖 4. Beta分布的示例RL策略動作可視化。
b) 靜態安全獎勵r_ss:靜態安全獎勵確保機器人與靜態障礙物保持安全距離。給定式(5)中的靜態障礙物狀態,其定義為:
rss=1NhNv∑i=1Nh∑j=1Nvlog?Sstat(i,j).(9)r_{ss} = \frac{1}{N_h N_v} \sum_{i=1}^{N_h} \sum_{j=1}^{N_v} \log S_{stat}(i, j). \quad (9) rss?=Nh?Nv?1?i=1∑Nh??j=1∑Nv??logSstat?(i,j).(9)
該公式使用光線距離計算到靜態障礙物的平均對數距離。當機器人與障礙物保持更大距離時,獎勵最大化。
c) 動態安全獎勵r_ds:與靜態安全獎勵類似,動態安全獎勵鼓勵機器人避開動態障礙物,表示為:
rds=1Nd∑i=1Ndlog?∣∣Pr?Poi∣∣.(10)r_{ds} = \frac{1}{N_d} \sum_{i=1}^{N_d} \log ||P_r - P_{o_i}||. \quad (10) rds?=Nd?1?i=1∑Nd??log∣∣Pr??Poi??∣∣.(10)
d) 平滑性獎勵rsmoothr_{smooth}rsmooth?:平滑性獎勵懲罰控制輸出的突然變化,寫作:
rsmooth=?∣∣Vr(ti)?Vr(ti?1)∣∣,(11)r_{smooth} = -||V_r(t_i) - V_r(t_{i-1})||, \quad (11) rsmooth?=?∣∣Vr?(ti?)?Vr?(ti?1?)∣∣,(11)
其中計算的是當前和前一個時間步機器人速度差異的L2范數。
e) 高度獎勵rheightr_{height}rheight?:高度獎勵旨在防止機器人通過飛得過高來避開障礙物。它可以寫成:
rheight=?(min?(∣Pr,z?Ps,z∣,∣Pr,z?Pg,z∣))2,(12)r_{height} = -(\min(|P_{r,z} - P_{s,z}|, |P_{r,z} - P_{g,z}|))^2, \quad (12) rheight?=?(min(∣Pr,z??Ps,z?∣,∣Pr,z??Pg,z?∣))2,(12)
當當前高度Pr,zP_{r,z}Pr,z?超出由起始高度P_{s,z}和目標高度P_{g,z}定義的范圍時,此獎勵適用。
C. 網絡設計和策略訓練
鑒于我們的狀態表示由多個部分組成,在將數據輸入RL策略網絡之前,需要一個預處理步驟。靜態和動態障礙物都表示為2D矩陣,因此我們利用卷積神經網絡(CNN)來提取它們的特征,并將其轉換為1D特征嵌入,如圖2所示。然后將這些嵌入與機器人的內部狀態拼接,形成策略和價值網絡的完整輸入特征。我們采用近端策略優化(PPO)算法[17]來訓練演員(策略)和評論家(價值)網絡,兩者都使用多層感知器實現。訓練過程在NVIDIA Isaac Sim中進行,我們通過同時從數千架四旋翼無人機收集數據來實現并行訓練。訓練環境具有一個森林般的設置,包含靜態和動態障礙物。每個機器人都在一個隨機位置生成,具有一個隨機目標,并在與障礙物碰撞或一集結束時重置。為了提高學習效率,我們采用課程學習策略。環境最初以相對較低的障礙物密度開始,隨著成功率超過指定閾值而逐漸增加。我們的實驗表明,這種方法允許RL策略在復雜的環境中實現更高的導航成功率。
D. 策略動作安全護盾
由于神經網絡的黑盒特性,我們設計了一個安全護盾機制來防止由訓練好的策略引起的嚴重故障。鑒于我們的策略輸出用于機器人控制的速度指令,我們結合了速度障礙(VO)[18]的概念來評估策略動作的安全性,并在可能導致碰撞時進行修正。速度障礙表示在指定未來時間范圍內會導致碰撞的機器人速度集合。在圖5a所示的場景中,機器人遇到障礙物,相應的速度障礙區域在圖5b中可視化。在這個例子中,有兩個以不同速度移動的障礙物,每個障礙物都與一個基于它們相對于機器人的相對位置和速度的速度障礙區域相關聯。每個速度障礙區域結合了一個以C1或C2為中心的圓形區域(其半徑等于機器人和障礙物尺寸之和加上用戶定義的安全空間),以及一個從原點延伸的錐形區域(不包括虛線)。機器人相對于障礙物1和障礙物2的相對速度(顯示為紅色和綠色箭頭)位于速度障礙區域內,表明未來會發生碰撞。受[46]的啟發,我們采用類似的方法來計算退出速度障礙區域所需的速度最小變化量(ΔV?和ΔV?)。由網絡產生的策略動作為V_rl。如果此動作不在任何速度障礙區域內,我們將安全動作V_safe設置為策略動作。否則,我們構建以下優化問題,將策略動作投影到安全區域:
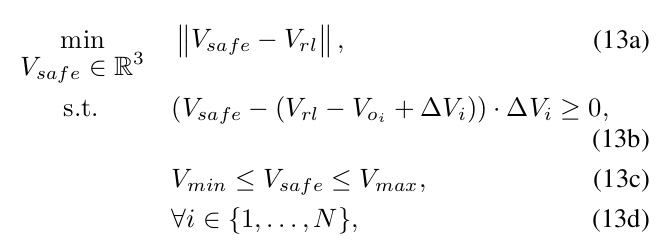
其中,式13b定義了一個基于所需速度變化的超平面,以確保安全動作位于速度障礙區域之外,式13c強制執行安全動作的控制限制。當存在許多障礙物時,將安全動作約束在超平面的一側可能過于保守。然而,由于策略動作只是偶爾失敗,這種保守性不會顯著影響整體性能,并且在大多數情況下有助于確保安全。對于靜態障礙物,我們使用每條投射的光線來確定障礙物的中心位置和半徑,并將其速度設為零。對于動態障礙物,我們用一個或多個球體將其包圍。
IV. 結果與討論
為了評估所提出的框架,我們展示了在不同配置下的訓練結果,并在各種環境中進行了仿真和物理飛行測試。策略在NVIDIA Isaac Sim中,使用一塊NVIDIA GeForce RTX 4090 GPU訓練了大約10小時。
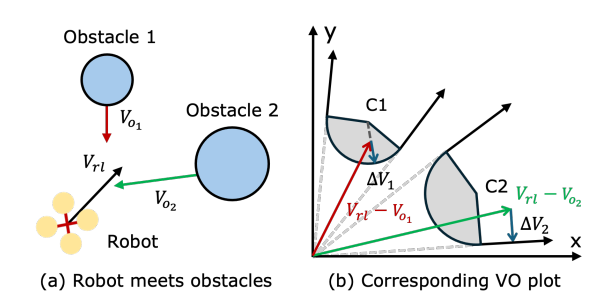
圖 5. 使用基于速度障礙的方法確定安全速度區域的示意圖。(a) 機器人遇到兩個障礙物的示例場景。(b) 對應的速度障礙圖,藍色箭頭顯示了退出VO區域所需的最小速度變化。
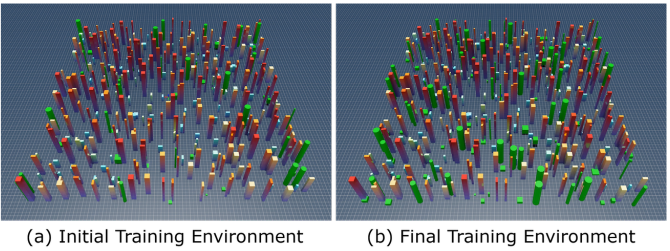
圖 6. 機器人訓練環境的可視化。環境大小為50m×50m,動態障礙物的數量在訓練期間逐漸增加。(a) 初始環境包含60個動態障礙物。(b) 最終環境包含120個動態障礙物。
表 I
在使用和不使用課程學習的情況下,訓練期間最高導航成功率的比較
| 障礙物數量 | 無課程學習 | 有課程學習 |
|---|---|---|
| static=350, dynamic=60 | 94.33% | 94.33% |
| static=350, dynamic=80 | 74.51% | 82.71% |
| static=350, dynamic=100 | 62.30% | 80.96% |
| static=350, dynamic=120 | 54.98% | 68.65% |
機器人的最大速度設定為2.0 m/s。仿真實驗在RTX 4090臺式機上進行,而物理飛行的計算則在我們四旋翼無人機的機載計算機(NVIDIA Jetson Orin NX)上執行。使用Intel RealSense D435i相機進行靜態和動態障礙物感知,并采用LIDAR慣性里程計(LIO)算法[47]進行精確的機器人狀態估計。靜態和動態特征提取器使用3層卷積神經網絡,輸出大小分別為128和64的嵌入。策略網絡由一個雙層多層感知器組成,PPO的裁剪率為0.1。使用ADAM優化器,學習率為5 × 10??。獎勵折扣因子設置為0.99。
A. RL訓練結果
我們的框架在RL策略訓練中采用課程學習策略,如圖6所示的初始和最終訓練環境。靜態障礙物以紅色顯示,顏色梯度表示高度,而動態障礙物以綠色表示。根據我們的觀察,動態障礙物在訓練中比靜態障礙物帶來更大的挑戰。因此,一旦導航成功率(定義為從起點到目標安全導航且無碰撞)超過80%,我們便以20為增量,將環境中動態障礙物的數量從60個逐漸增加到120個。為了證明課程學習的有效性,表I比較了在總訓練時間相同的情況下,有無課程學習所達到的最高導航成功率。該表顯示,隨著動態障礙物數量的增加,沒有課程學習的最高導航成功率下降得比有課程學習的訓練更急劇,凸顯了其有效性。我們在120個動態障礙物時停止了策略訓練,并保存了用100個動態障礙物訓練出的最佳模型,因為它在具有挑戰性的條件下取得了相對較高的成功率(80.96%)。
為了展示使用更多機器人進行訓練的重要性,圖8比較了部署不同數量機器人訓練時獲得的平均RL訓練回報。該圖顯示,使用更多機器人進行訓練不僅能帶來更快的收斂速度,還能獲得更高的RL回報。我們的實驗使用了1024個機器人,這利用了可用的最大GPU內存。
B. 仿真實驗
我們在Gazebo中進行了仿真實驗,以評估所提出框架的性能并展示其“仿真到仿真”的可遷移性。在類似真實世界室內場景的動態環境中進行了定量測試,其中機器人需要安全地繞過人類。圖7展示了一個安全軌跡的例子。結果證實了機器人成功地進行了無碰撞導航。
為了進行定量評估,我們生成了高障礙物密度的環境,模擬了我們訓練環境的條件,其中靜態和動態障礙物都是隨機放置的。鑒于開源的基于RL的導航基準算法有限,我們將我們的方法與流行的基于優化的靜態規劃器[48]和為動態環境設計的視覺輔助規劃器[20]進行比較。此外,我們還評估了我們的框架在有無安全護盾的情況下的性能,以驗證其有效性。具體來說,我們在三種類型的環境中進行測試:純靜態、純動態和混合環境。每種算法在每個環境中運行20次,計算出的平均每次運行的碰撞次數如表II所示。表II中的百分比值表示相對于基準方法[20]的平均碰撞次數。需要注意的是,這些環境旨在測試算法的極限,并且比真實世界場景要復雜得多。因此,發生碰撞并不一定意味著算法不安全。總的來說,我們的NavRL在動態和混合環境中表現出最低的碰撞次數,同時在靜態環境中保持與EGO規劃器相當的碰撞率。該表顯示,EGO規劃器在動態和混合環境中為N/A,因為其低效的地圖更新導致它在處理來自動態障礙物的過多噪聲時會卡住。在實驗中,當障礙物靠近時,ViGO未能為碰撞避免提供足夠反應靈敏的軌跡。
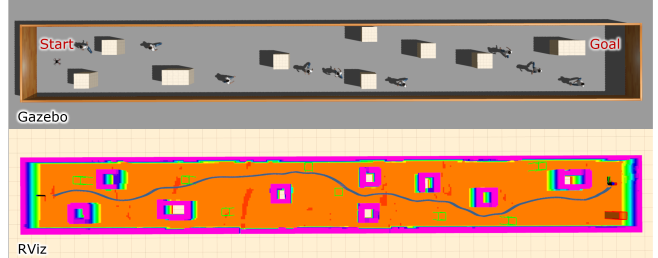
圖 7. 模擬走廊環境中安全導航軌跡的可視化。上圖展示了Gazebo中的環境,包含靜態障礙物和動態障礙物(行人)。下圖顯示了環境地圖和機器人的導航軌跡。

圖 8. 平滑的平均訓練回報曲線圖。使用更多數量的機器人進行訓練可以帶來更快的收斂速度和更高的回報。
相比之下,我們的方法可以生成更具反應性的控制,幫助機器人更有效地避免碰撞。通過比較有無安全護盾的框架,我們發現安全護盾持續減少了碰撞,特別是在動態環境中,它減輕了由神經網絡故障風險增加引起的錯誤。
表 II
在20m×40m地圖中,從20次樣本運行中評估的不同類型環境下平均碰撞次數的基準測試
| 基準 | 靜態環境 | 動態環境 | 混合環境 |
|---|---|---|---|
| EGO [48] | 0.45 (56.3%) | N/A | N/A |
| ViGO [20] | 0.80 (100%) | 3.15 (100%) | 4.40 (100%) |
| 我們的(無護盾) | 0.95 (118.8%) | 2.70 (85.7%) | 4.60 (104.5%) |
| 我們的(NavRL) | 0.65 (81.3%) | 0.85 (27.0%) | 2.10 (47.8%) |
C. 物理飛行測試
為了展示“仿真到現實”的遷移和安全導航能力,我們在各種設置下進行了物理飛行實驗,如圖9所示。環境中放置了靜態障礙物,并有幾名行人被引導走向機器人,要求它在到達目標的同時避免碰撞。結果顯示,機器人成功地避開了碰撞并安全到達目的地。
在仿真和真實世界飛行實驗期間,我們測量了所提出框架中每個模塊的計算時間,如表III所示。該表顯示了在NVIDIA GeForce RTX 4090和機載NVIDIA Jetson Orin NX計算機上的運行時間。靜態感知模塊在RTX 4090上完成需要8毫秒,在Orin NX上需要15毫秒,而動態感知模塊分別需要11毫秒和27毫秒。RL策略網絡在RTX 4090上運行需要1毫秒,在Orin NX上需要7毫秒,安全護盾模塊則分別運行2毫秒和16毫秒。這些測量結果表明,所有模塊即使在機載計算機上也能實現實時性能。
[圖片:兩張物理飛行測試的照片,顯示無人機在有靜態和動態障礙物(人)的室內環境中飛行]
圖 9. 物理飛行測試示例。我們的框架使機器人能夠在存在靜態和動態障礙物的情況下進行安全飛行和導航。
表 III
所提出系統各組件的運行時間
| 系統模塊 | GeForce RTX 4090 | Jetson Orin NX |
|---|---|---|
| 靜態感知 | 8 ms | 15 ms |
| 動態感知 | 11 ms | 27 ms |
| RL策略網絡 | 1 ms | 7 ms |
| 安全護盾 | 2 ms | 16 ms |
V. 結論與未來工作
本文提出了一種新穎的深度強化學習框架NavRL,旨在基于近端策略優化(PPO)算法實現動態環境中的安全飛行。該框架使用量身定制的狀態和動作表示,以在靜態和動態環境中實現安全導航,支持有效的零樣本“仿真到仿真”和“仿真到現實”的遷移。此外,一個基于速度障礙概念的安全護盾減輕了神經網絡黑盒特性帶來的故障。另外,使用NVIDIA Isaac Sim的并行訓練流程加速了學習過程。仿真和物理實驗的結果驗證了我們的方法在動態環境中實現安全導航的有效性。未來的工作將側重于改進和調整該框架,以部署到各種機器人平臺上。


Day15——性能監控與調優(二))

)








的實用)

)
技術與工程實戰詳解)


