1 聚合
1.1 簡介
- 在SQL中我們經常使用
GROUP BY將某個字段,按不同的取值進行分組,在Pandas中也有groupby()函數; - 分組之后,每組都會有至少1條數據,將這些數據進一步處理返回單個值的過程就是聚合,比如分組之后計算算術平均值,或者分組之后計算頻數,都屬于聚合。
1.2 單變量分組聚合
-
加載數據:
-
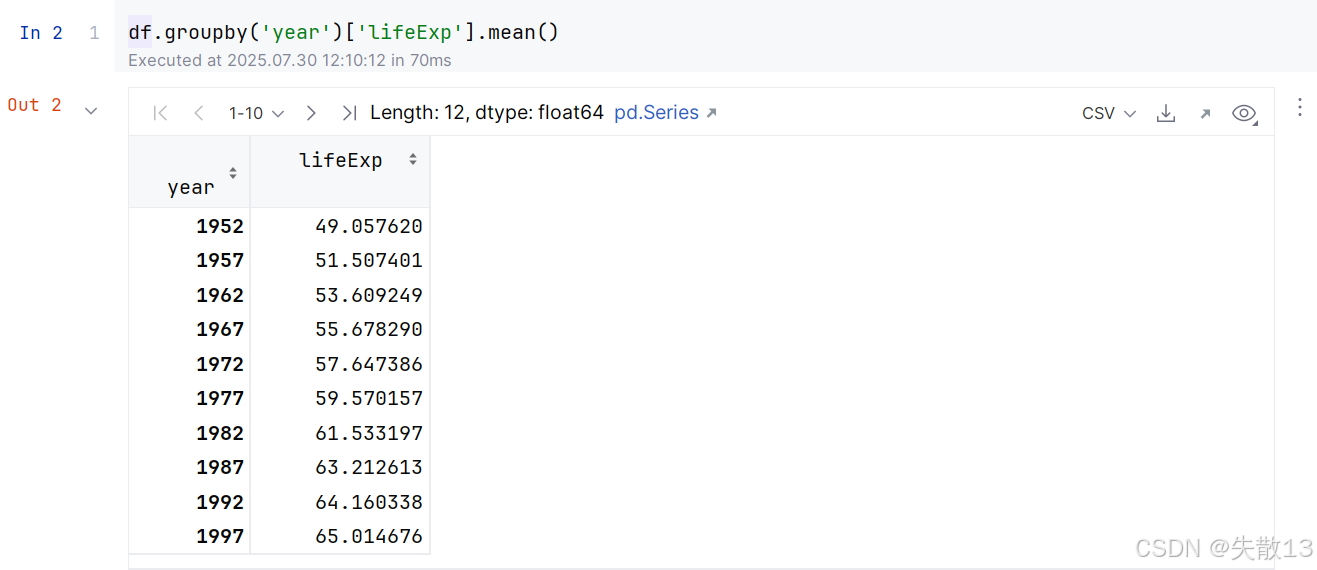
按照年份分組,計算平均壽命
-
查詢年份:
-
對 1952 年進行聚合,計算平均壽命:

1.3 聚合函數
1.3.1 常用聚合函數
| Pandas 方法 | Numpy 函數 | 說明 |
|---|---|---|
| count | np.count_nonzero | 頻率統計 (不包含 NaN 值) |
| size | 頻率統計 (包含 NaN 值) | |
| mean | np.mean | 求平均值 |
| std | np.std | 標準差 |
| min | np.min | 最小值 |
| quantile() | np.percentile() | 分位數 |
| max | np.max | 求最大值 |
| sum | np.sum | 求和 |
| var | np.var | 方差 |
| describe | 計數、平均值、標準差,最小值、分位數、最大值 | |
| first | 返回第一行 | |
| last | 返回最后一行 | |
| nth | 返回第 N 行 (Python 從 0 開始計數) |
-
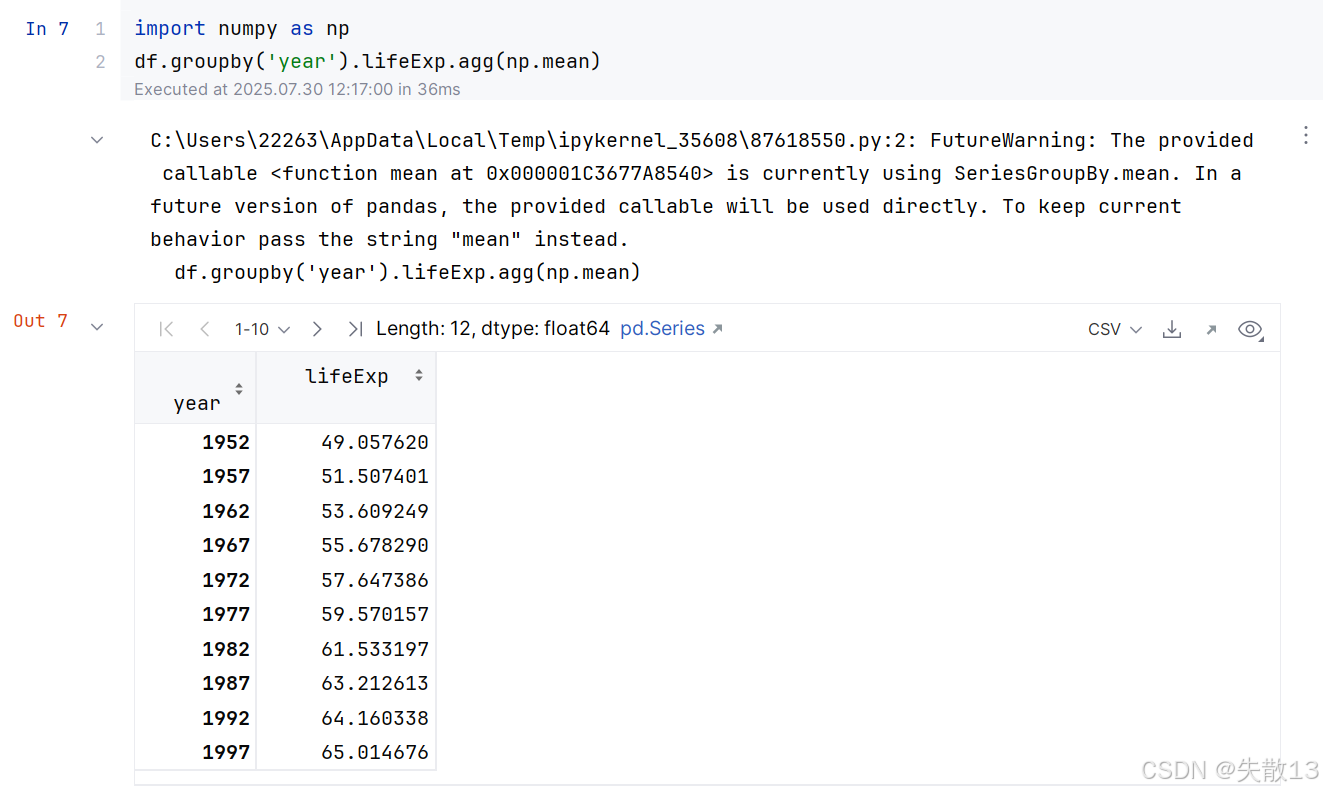
例:使用 Numpy 的求平均值方法
FutureWarning:提示在未來的 Pandas 版本中,提供的可調用對象(這里是np.mean)將直接被使用。為了保持當前的行為,應該傳遞字符串"mean"而不是np.mean。也就是說,建議將代碼修改為df.groupby('year').lifeExp.agg("mean");
1.3.2 agg()函數
-
在 Python 的 Pandas 庫中,
agg(是aggregate的縮寫)是一個用于數據聚合操作的方法; -
agg方法常用于在分組操作(groupby)之后,對每個分組的數據進行聚合計算,比如計算每個分組的總和、平均值、最大值、最小值等;也可以在沒有分組的情況下,直接對整個數據對象(如Series或DataFrame)進行聚合操作; -
對
Series對象使用agg:直接對Series對象調用agg方法,傳入一個聚合函數(可以是內置函數,也可以是自定義函數),對整個Series的數據進行聚合;import pandas as pddata = [1, 2, 3, 4, 5] s = pd.Series(data) result = s.agg(sum) print(result) -
結合
groupby對DataFrame使用agg:先使用groupby對DataFrame進行分組,然后對每個分組調用agg方法,傳入一個或多個聚合函數,對分組后指定列的數據進行聚合;import pandas as pddata = {'category': ['A', 'A', 'B', 'B'],'value': [10, 20, 30, 40] } df = pd.DataFrame(data) # 按category列分組,對value列求平均值 result = df.groupby('category').value.agg('mean') print(result) -
自定義函數:用戶可以定義自己的聚合函數,然后傳遞給
agg方法;-
自定義函數若被
agg()函數當做聚合函數來使用時,自定義函數中有且至少要有一個參數。但agg()函數傳遞給自定義聚合函數的是一個Series對象,若想得到Series的每一個值,需要再自定義聚合函數中需要通過for循環迭代才能實現;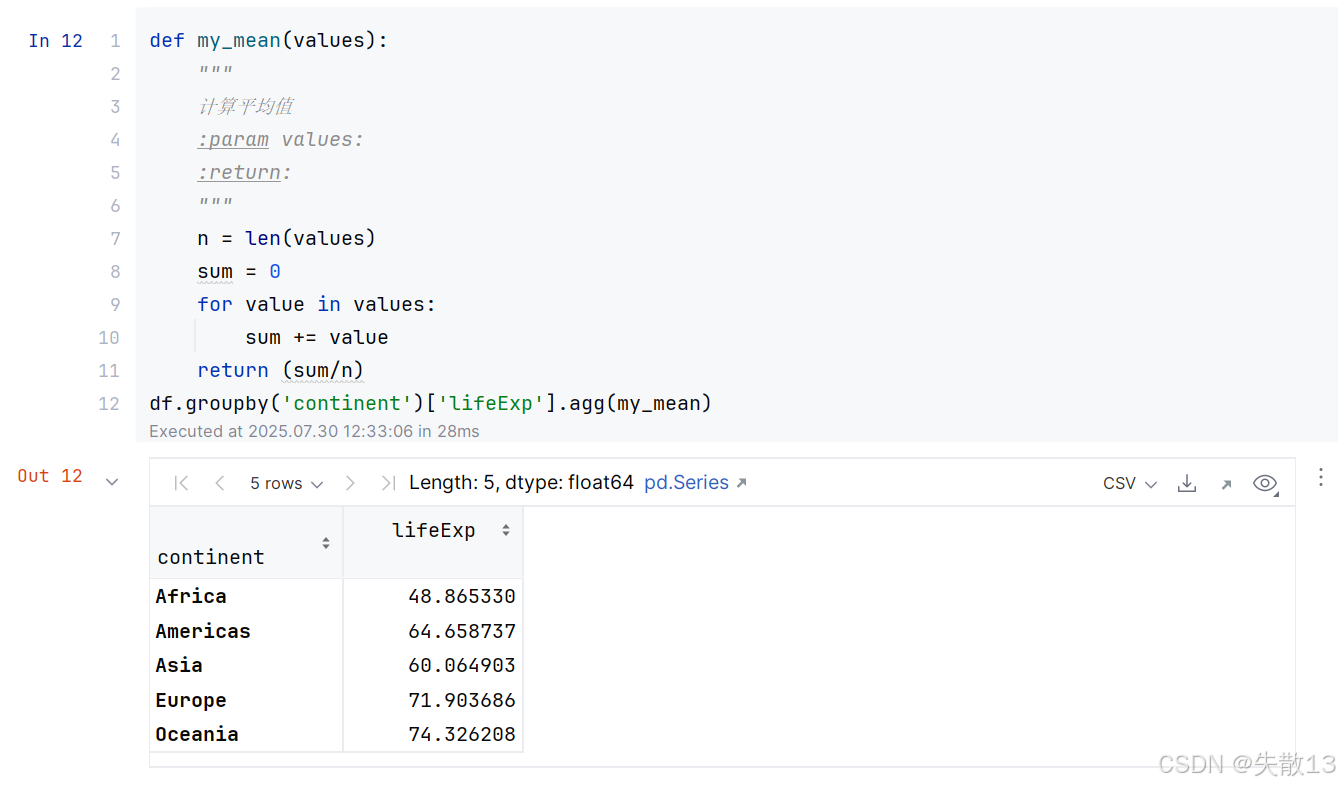
-
當然在自定義聚合函數中允許有多個參數,第一個參數用來接收DataFrame分組之后的值,其余參數可以自定義;
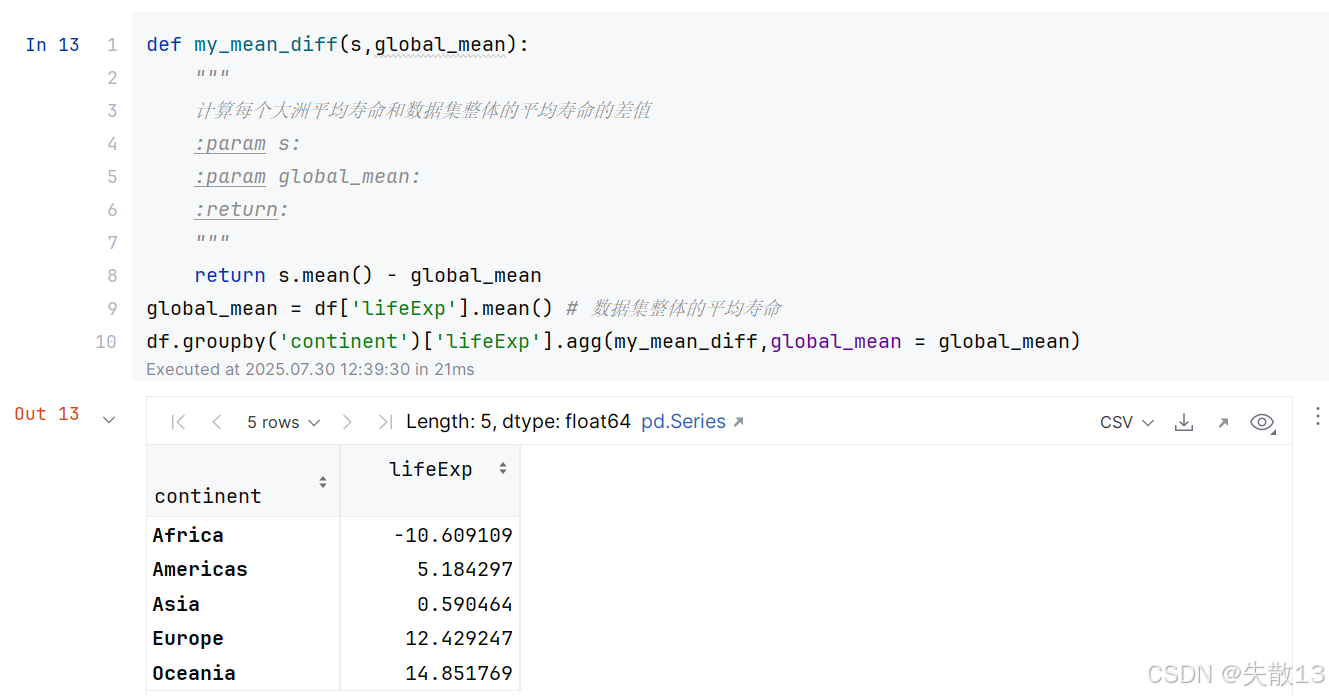
-
-
agg和aggregate效果一樣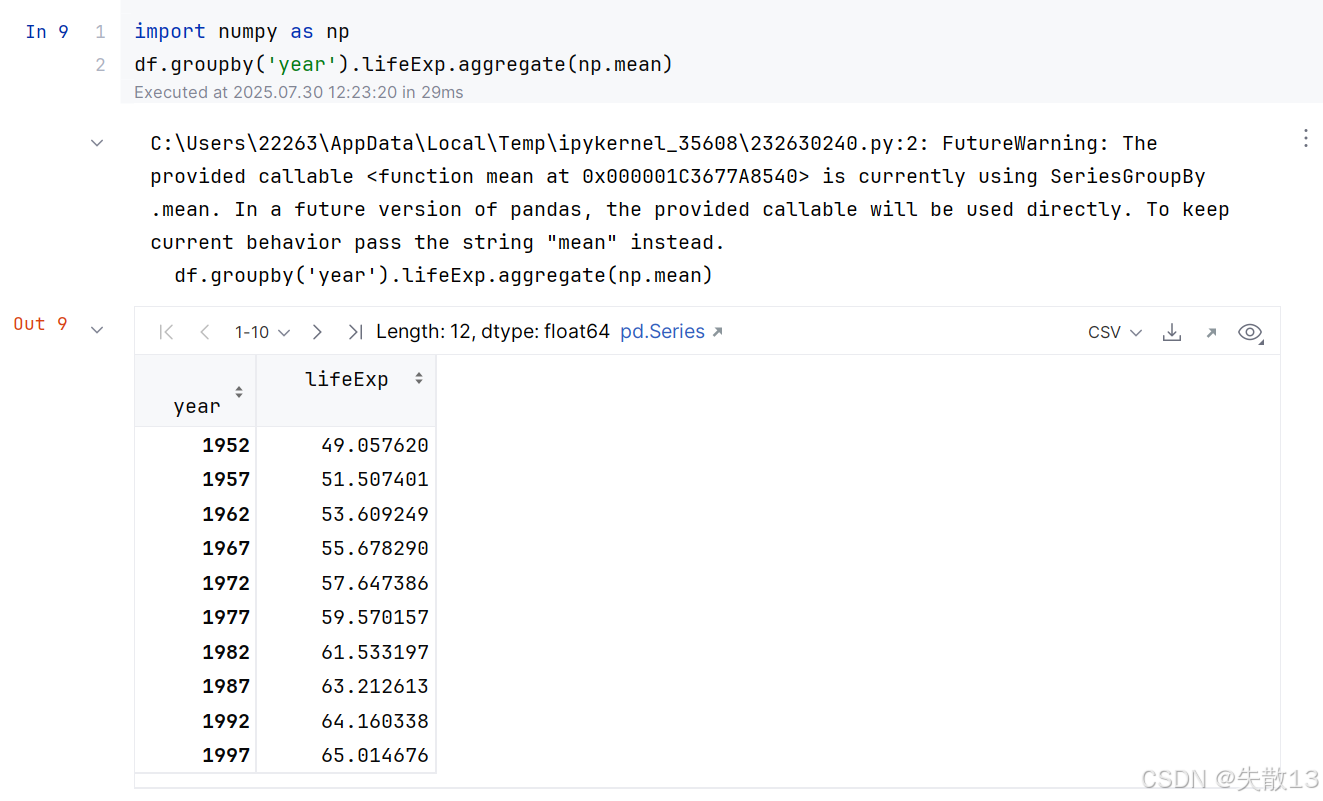
-
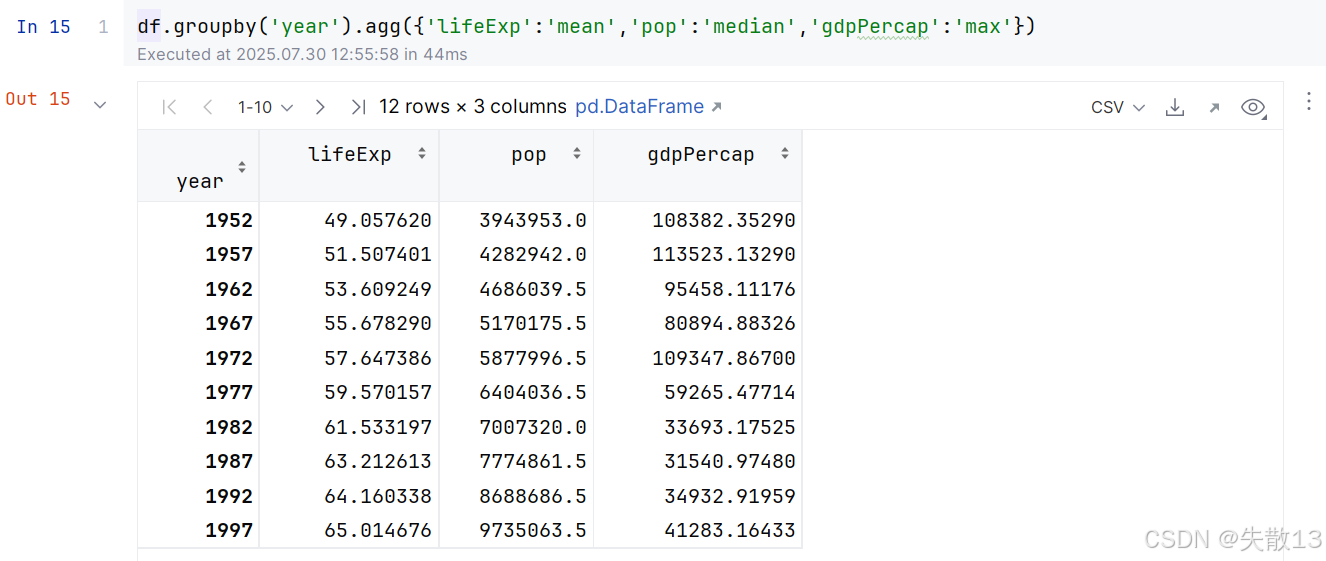
若想要對多個字段用不同的聚合方式,可以使用Python的字典數據類型,key是要聚合的字段,value是要使用的聚合方式;
1.3.3 同時使用多個聚合函數
-
若
groupby后面想接多個聚合函數,可以把這些聚合函數放入一個 Python 列表中,然后將這個列表傳遞給agg()函數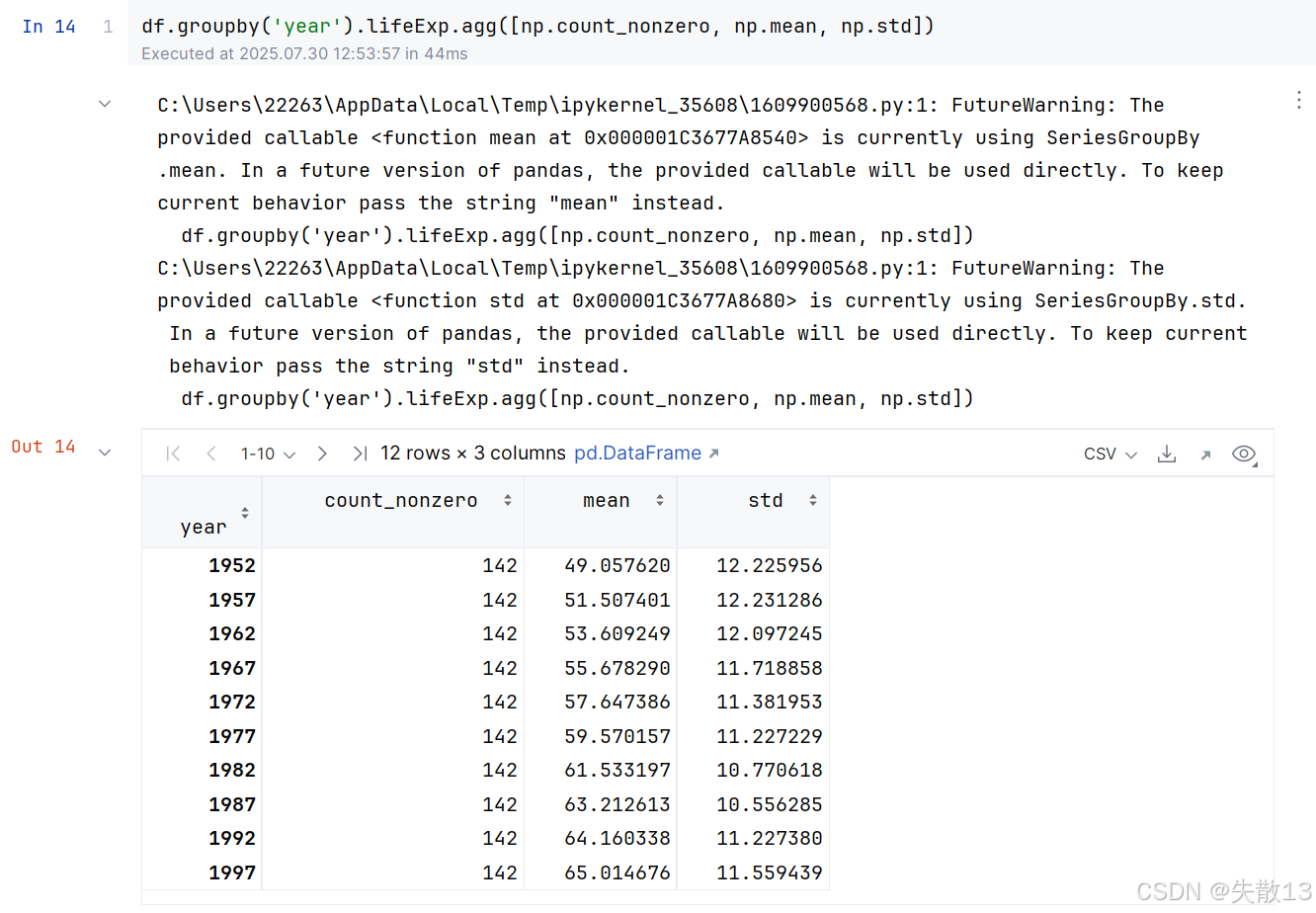
2 轉換
2.1 簡介
-
transform()函數- 功能:它會把 DataFrame 中的值傳遞給一個函數,然后由該函數對數據進行 “轉換” 操作;
- 特點:轉換后的數據與原始數據的形狀(行數和列數等)相同,不會減少數據量。例如,對一個包含多組數據的列進行某種轉換后,該列的行數和列數不會改變,只是每個數據的值按照函數規則發生了變化;
-
transform()VSaggregate()-
transform側重于對數據進行轉換,保持數據的原始結構和規模不變,不會減少數據量; -
aggregate側重于對數據進行匯總,得到一個或少數幾個關鍵的聚合結果,會減少數據量。
-
2.2 例:使用transform()計算z分數
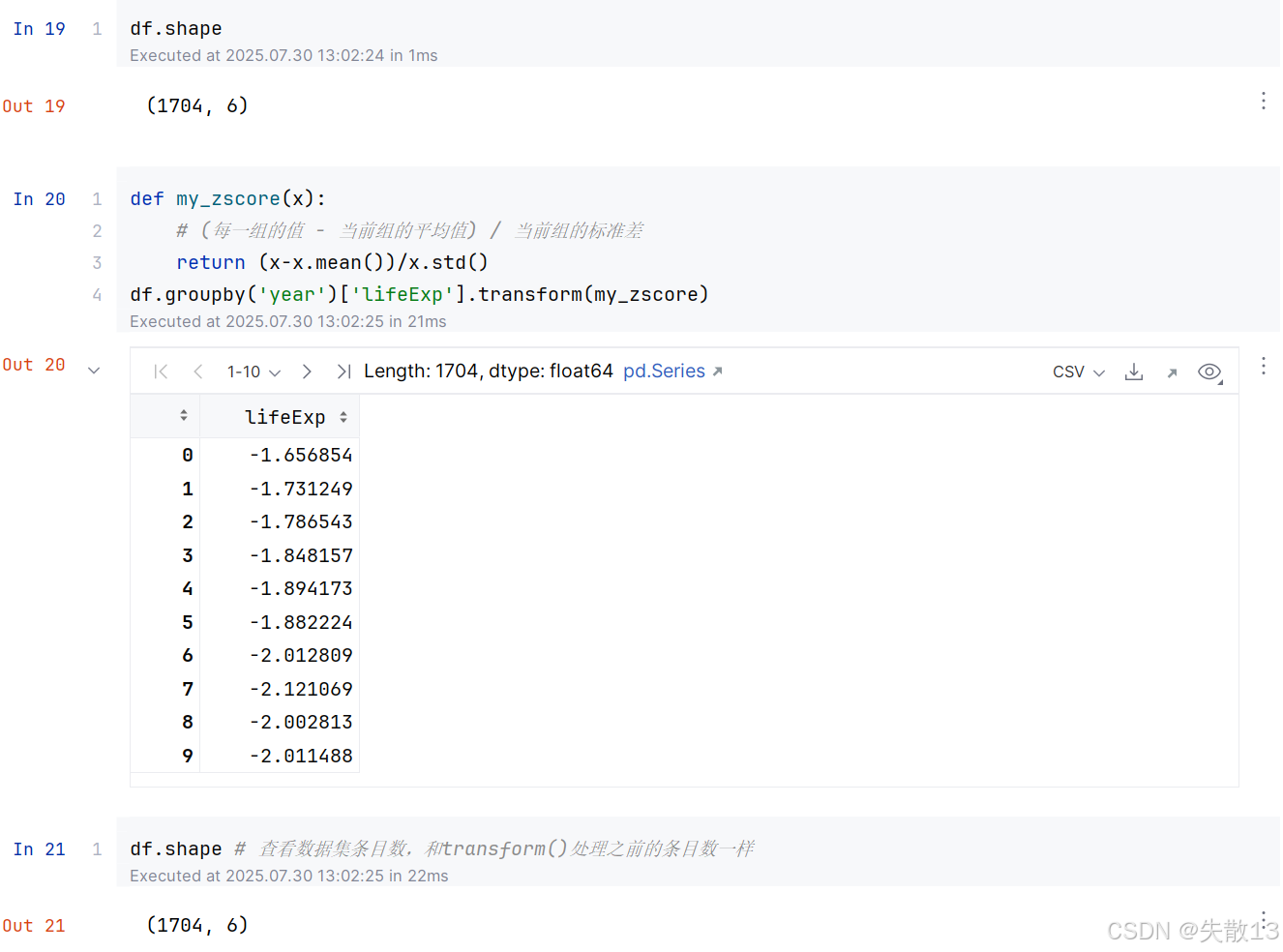
2.3 transform()填充缺失值
-
之前介紹了填充缺失值的各種方法,對于某些數據集,可以使用列的平均值來填充缺失值。某些情況下,可以考慮將列進行分組,分組之后取平均再填充缺失值;
-
加載數據:
-
構建缺失值
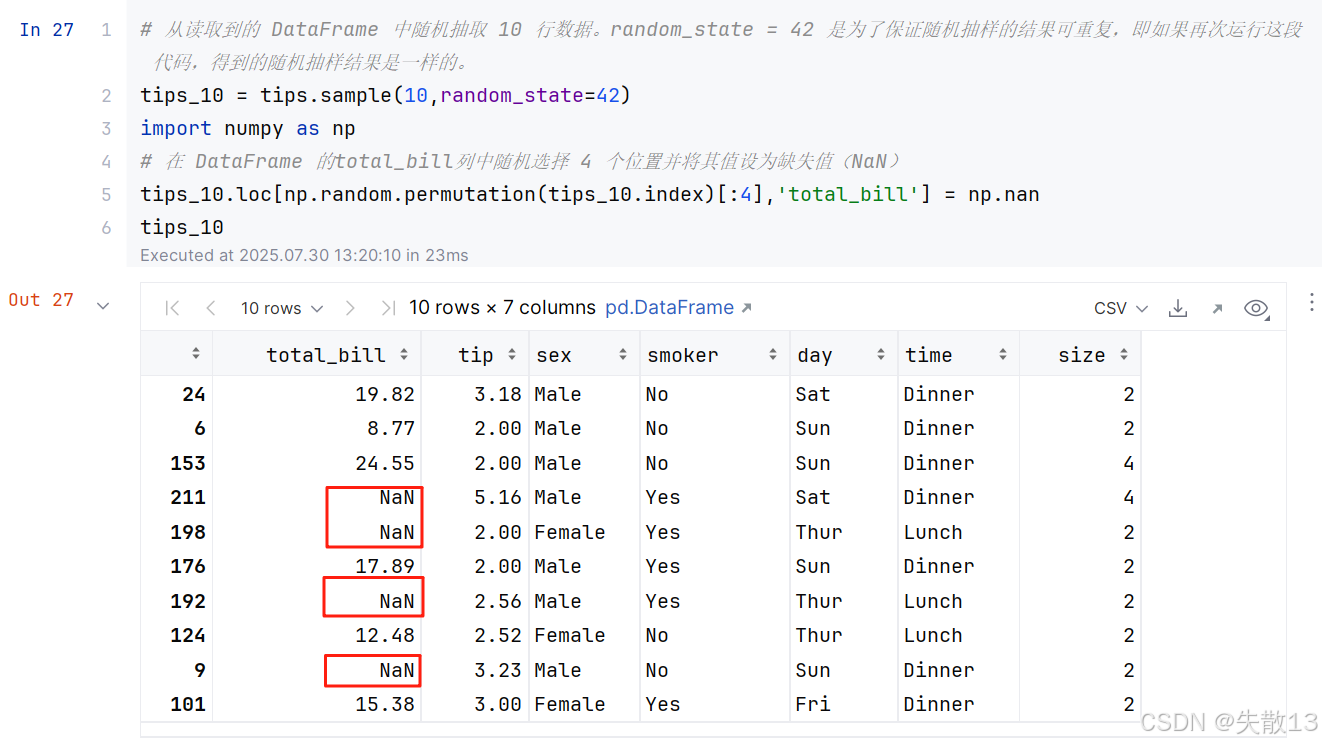
-
定義函數來填充缺失值
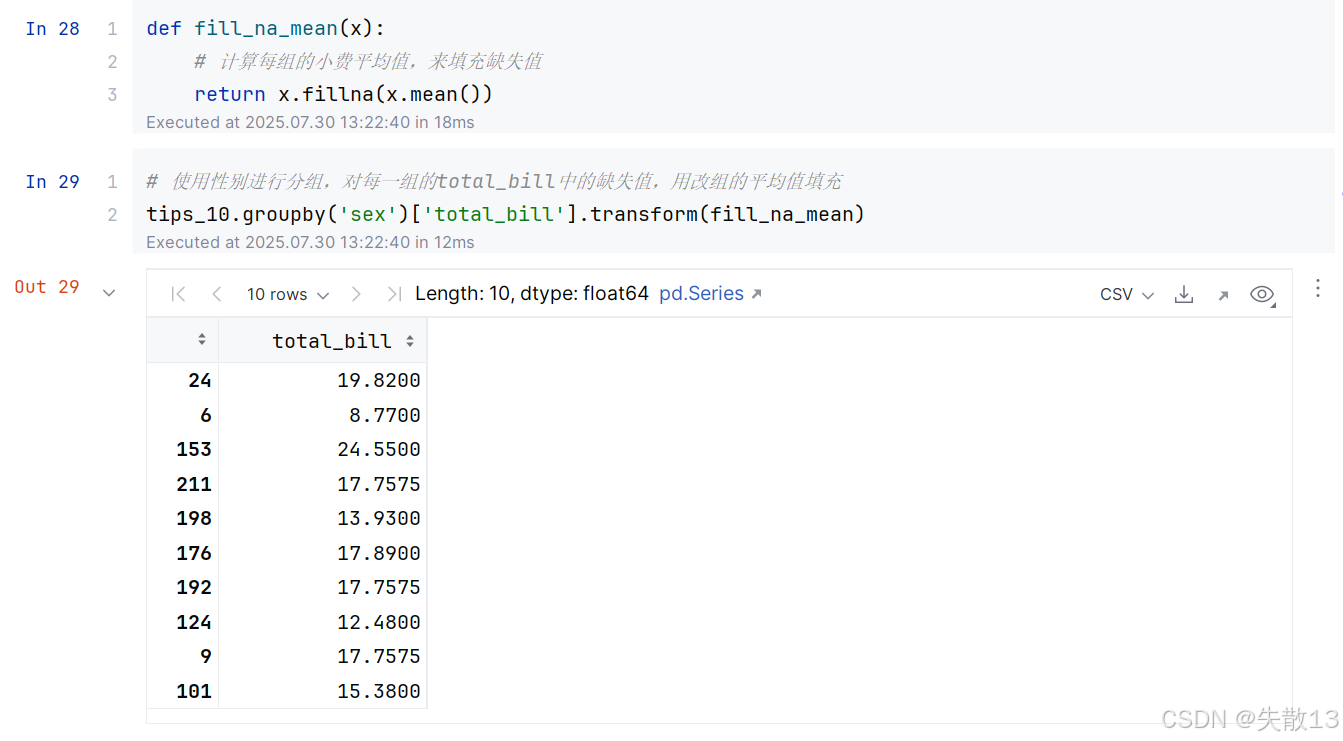
3 過濾
-
查看數據:
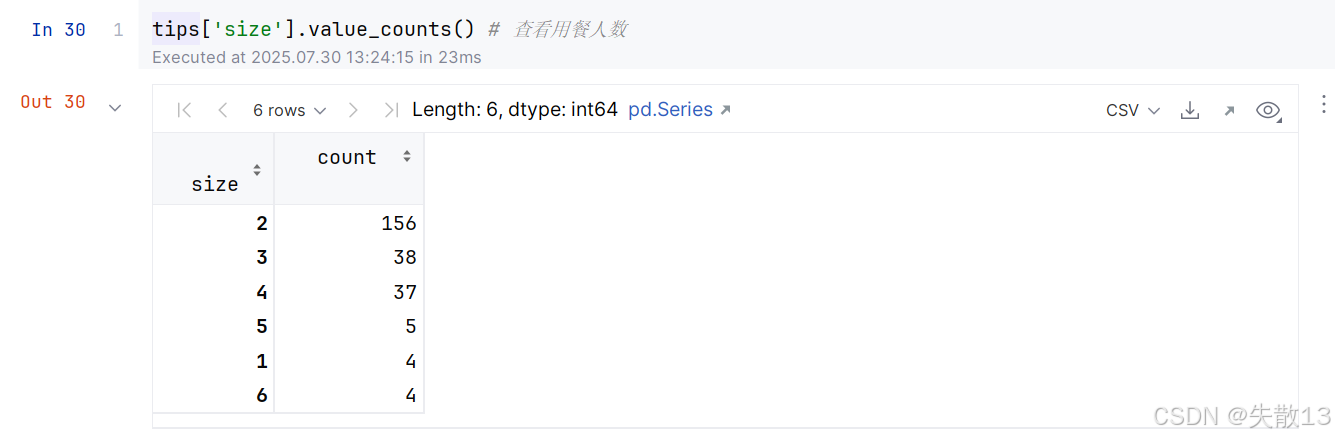
-
人數為1、5和6人的數據比較少,可以將這部分數據過濾掉。調用
filter()函數,傳入一個返回布爾值的函數,返回False的數據會被過濾掉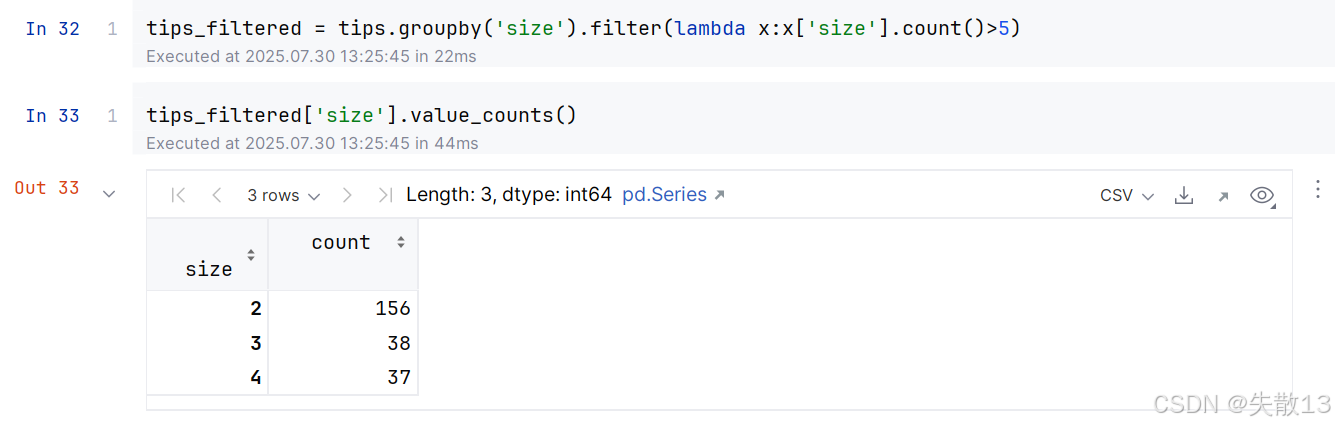
4 DataFrameGroupBy對象
4.1 分組
-
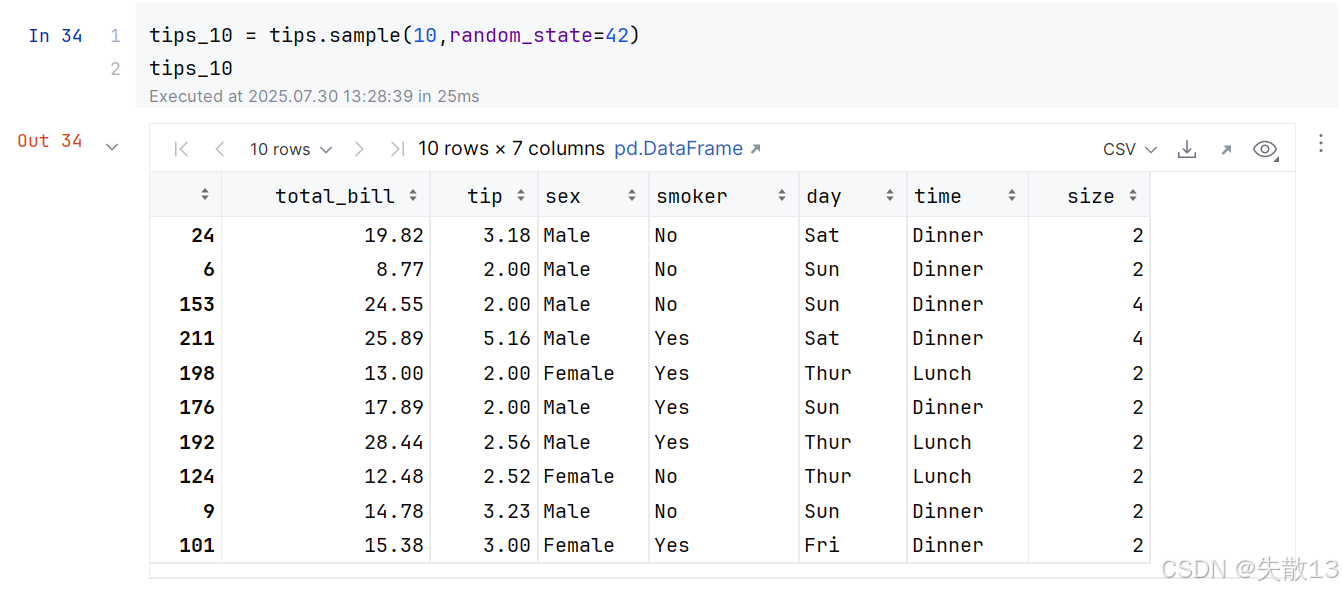
準備數據:
-
創建分組對象:

-
通過
groups屬性查看計算過的分組
- 返回值是一個字典;
- 鍵(key):是分組的類別,也就是
sex列中的不同取值; - 值(value):是一個列表,包含了每個分組類別對應的行索引。例如,
'Female'對應的行索引是[198, 124, 101],'Male'對應的行索引是[24, 6, 153, 211, 176, 192, 9];
-
分組后,就可以在分組的結果上進行
aggregate、transform計算了; -
可以從分組對象中獲取指定分組:
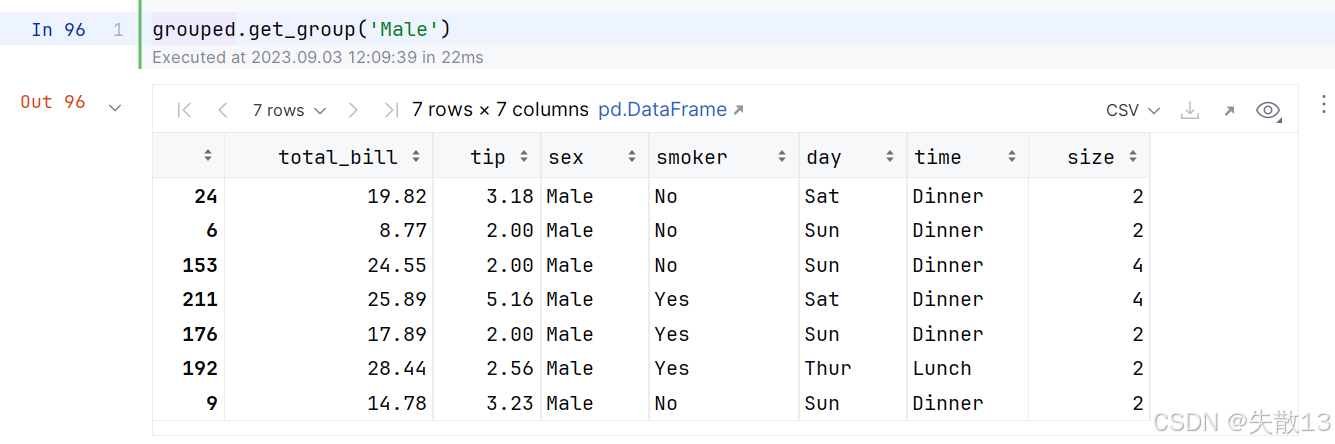
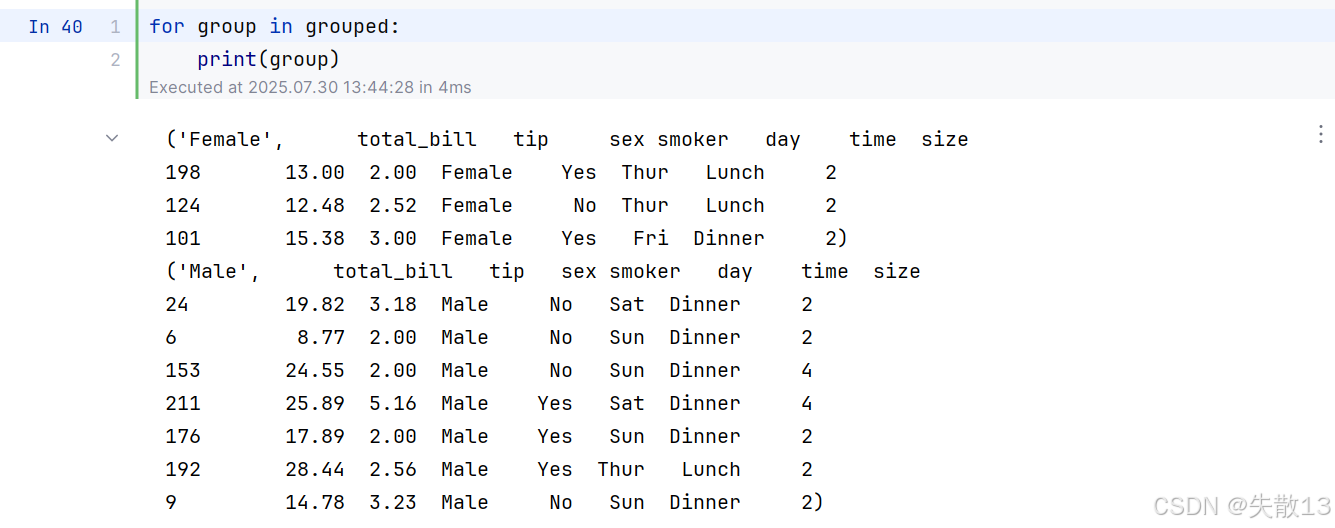
4.2 遍歷分組
4.3 多個分組
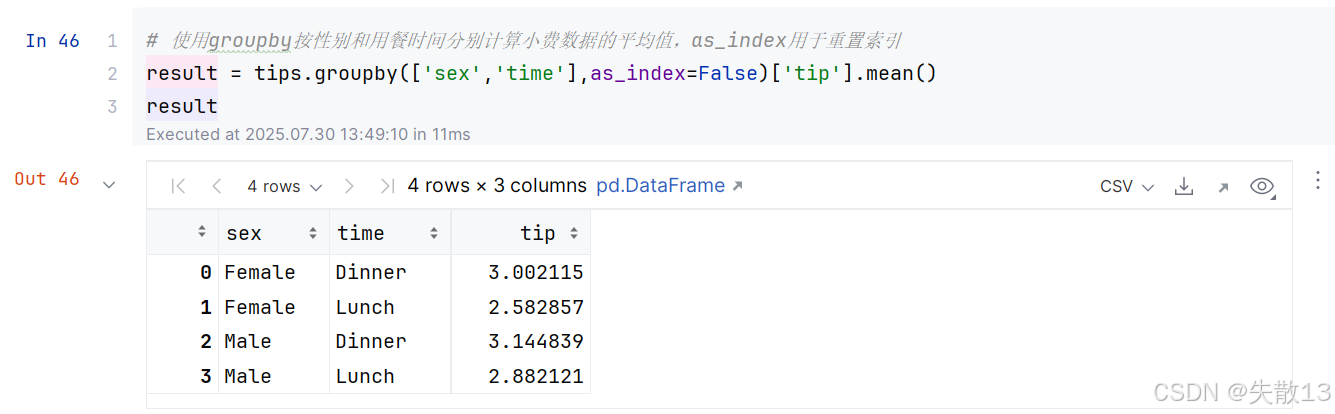
- 若不使用
as_index=False,可以使用result.reset_index()函數,都是重置索引。
——快速排序:三路劃分、自省排序)
)






)






鎖)
—— 適老化烹飪中心詳細構思)
)

