范式
第一范式
- 數據庫表的每一列都是不可分割的原子數據項,而不能是集合,數組,對象等非原子數據。
- 在關系型數據庫的設計中,滿足第一范式是對關系模式的基本要求。不滿足第一范式的數據庫就不能被稱為關系數據庫。
第一范式實際上只要用普通的數據類型描述每一個元素,就可以滿足第一范式。
如下就不滿足第一范式 ,因為學校中有多個數據類型。
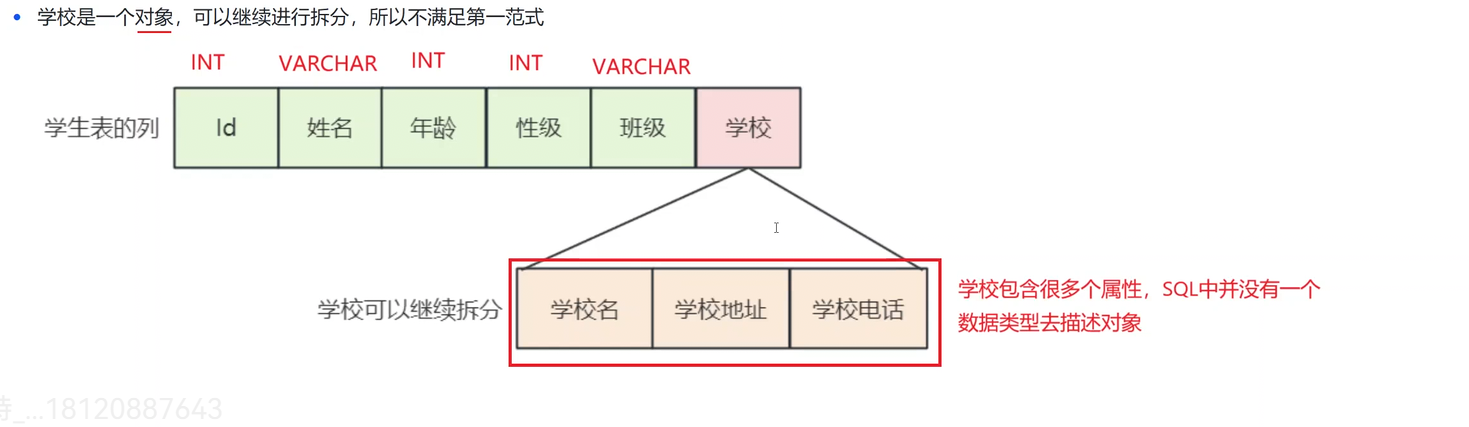
修改之后就滿足第一范式,雖然有很多冗余項。

第二范式

候選鍵實際上就是標識數據唯一性的。
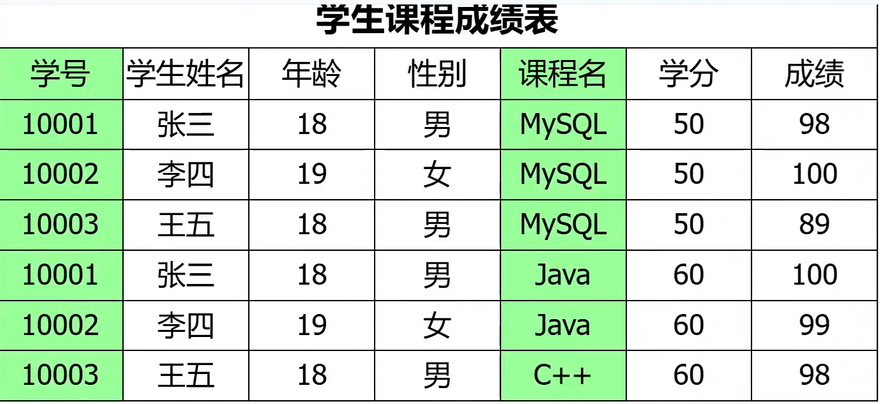
如圖內容就不滿足第二范式,
- 這張表中使用學號 + 課程名定義復合主鍵來唯一標識一個學生某門課程的成績,這也是這張表的主要作用。
- 學生是通過學號來確定的,學生的姓名、年齡和性別和課程沒有關系,即學生的信息只依賴學號,不依賴課程名;學分是通過課程來確定的,課程的學分與學生沒有關系,即學分只依賴課程名,不依賴學生
- 對于使用復合主鍵的表,如果一行數據中的有些列只與復合主鍵中的一個或其中幾個列有關系,那么就說他存在部分函數依賴,也就不滿足第二范式
簡單來說,學生姓名年齡,性別都只依賴于學號,課程名的學分只依賴于課程名。但是成績同時依賴于學號和課程名。
解決方法:應該要設計三張表,即學生表,課程表,成績表。
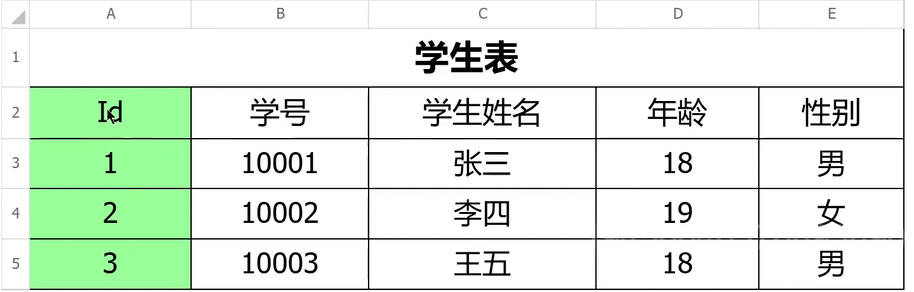
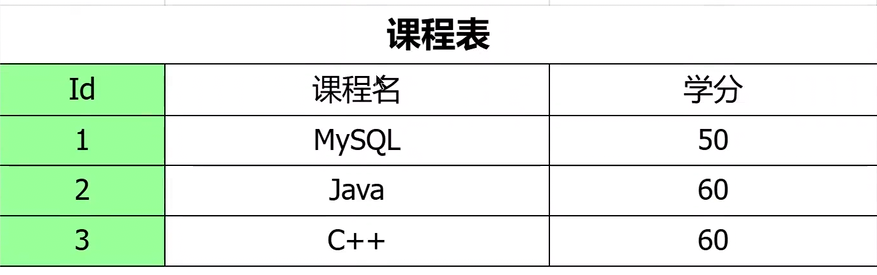
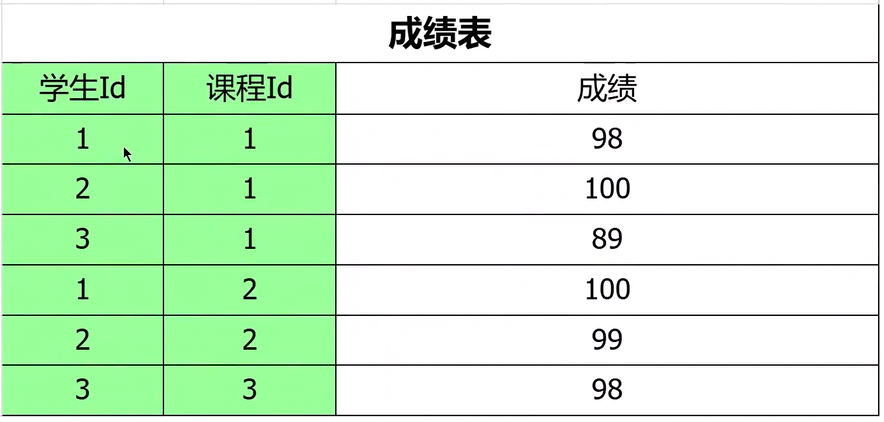
這時候就可以通過三張表將學生內容組合在一起了,排除了部分函數依賴,不存在復合主鍵就天生滿足第二范式。
可能會出現的問題:
數據冗余
學生的姓名、年齡、性別和課程的學分在每行記錄中重復出現,造成了大量的數據冗余。(多個考試有個記錄)更新異常
如果要調整 MySQL 的學分,那么就需要更新表中所有關于 MySQL 的記錄,一旦執行中斷導致某些記錄更新成功,某些數據更新失敗,就會造成表中同一門課程出現不同學分的情況,出現數據不一致問題。插入異常
目前這樣的設計,成績與每一門課和學生都有對應關系,也就是說只有學生參加選修課程考試取得了成績才能生成一條記錄。當有一門新課還沒有學生參加考試取得成績之前,那么這門新課在數據庫中是不存在的,因為成績為空時記錄沒有意義。刪除異常
把畢業學生的考試數據全都刪除,此時課程和學分的信息也會被刪除掉,有可能導致一段時間內,數據庫里沒有某門課程和學分的信息。
第三范式
在滿足第二范式的情況下,不存在非關鍵字段,對任一候選鍵的依賴傳遞。
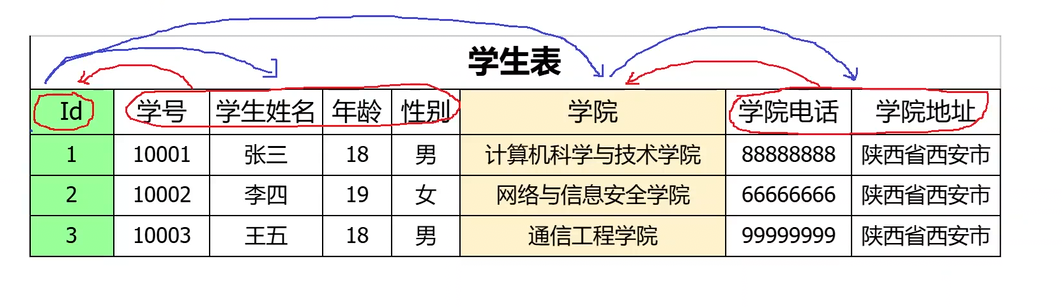
實際上像學院就可以通過學號找到,也就是學院依賴于學號,因為找到了學號也就是找到了學生所屬的學院。所以此時就可以對表進行拆分。
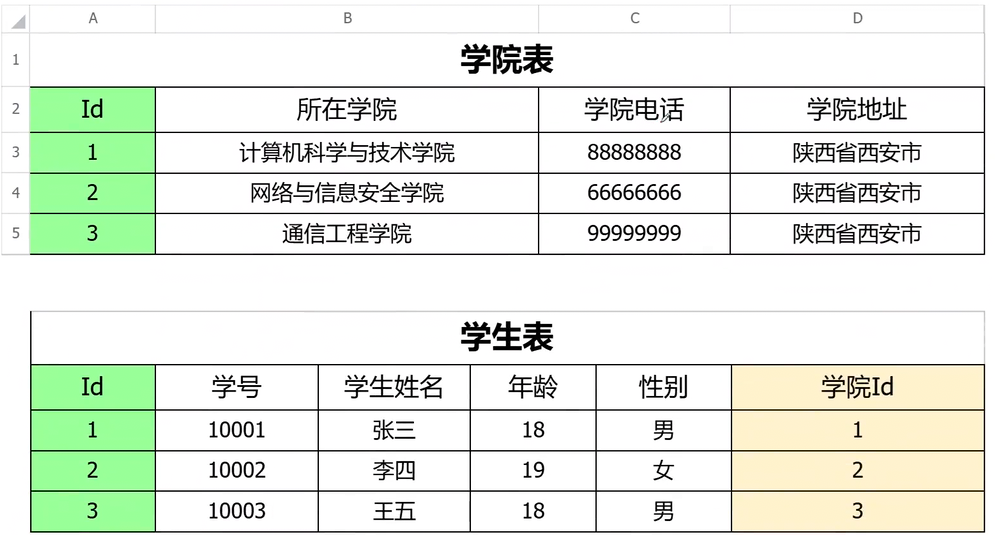
把表進行拆分,通過學院Id來進行關聯就可以了,第三范式我認為是第二范式的擴充,從一個關系找到另外一個關系就是依賴。
反范式設計
當我們不想要太多次表關聯查詢,就可以使用反范式進行設計表結構,比如我不想關聯表進行查詢學院名稱,就可以直接在學生表進行字段的增加。減少表連接操作,提升效率。

數據庫設計過程
我們一般通過E-R圖來表示實體和實體之間的關系。
E-R 圖包含了以下三種基本成分:
- 實體:即數據對象,用矩形框表示,比如用戶、學生、班級等。
- 屬性:實體的特性,用橢圓形或圓角矩形表示,如學生的姓名、年齡等。
- 關系:實體之間的聯系,用菱形框表示,并標明關系的類型,并用直線將相關實體與關系連接起來。
一對一
我們可以在drawio上繪制這些關系圖,E-R圖有一對一,一對多,多對多的關系
一對多
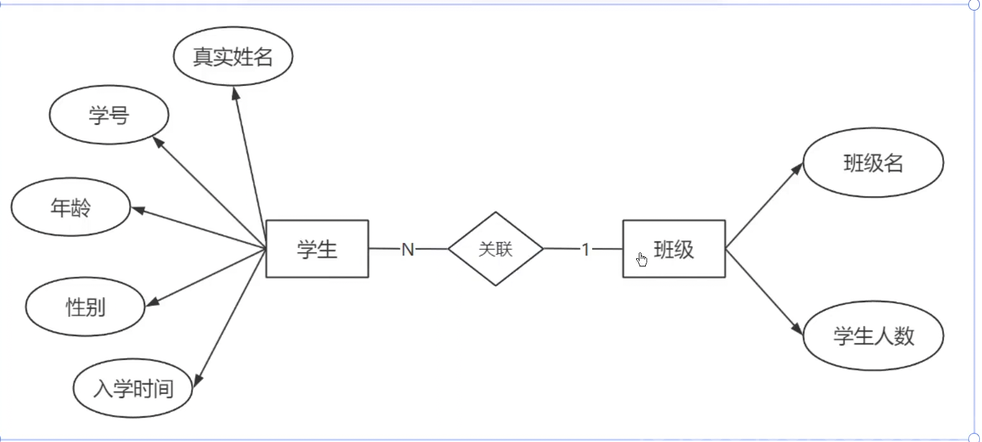
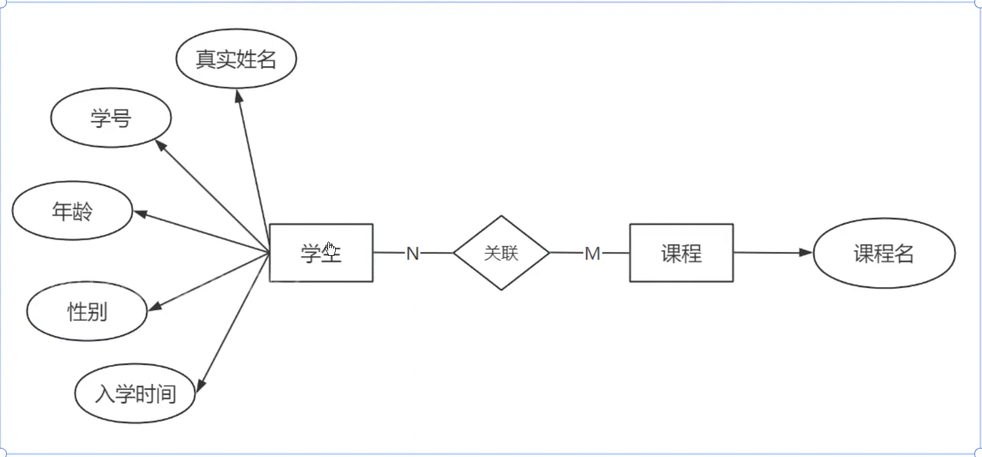
多對多
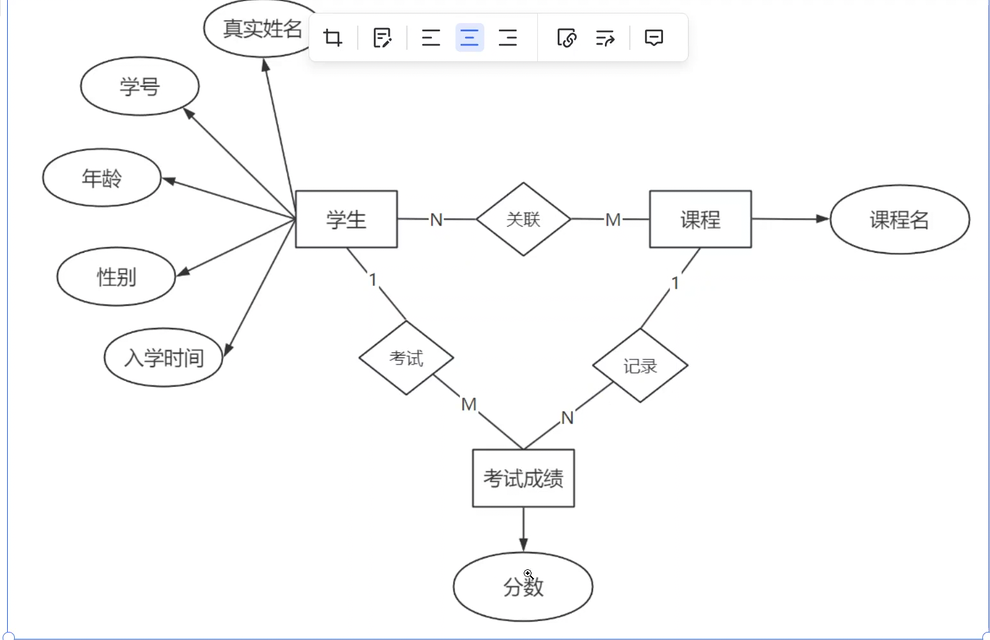
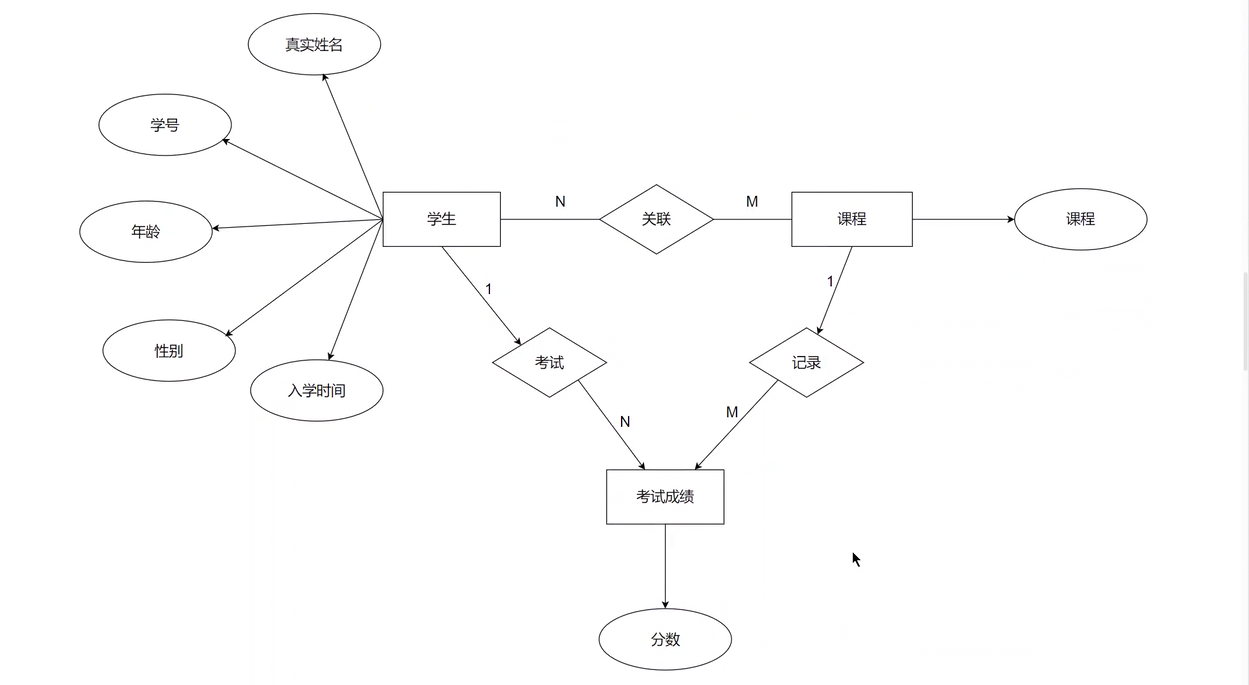
如果我們生成多張表,并且滿足三個范式,就可以畫出如下的關系圖,根據考試的成績關聯在一起。
數據庫設計練習
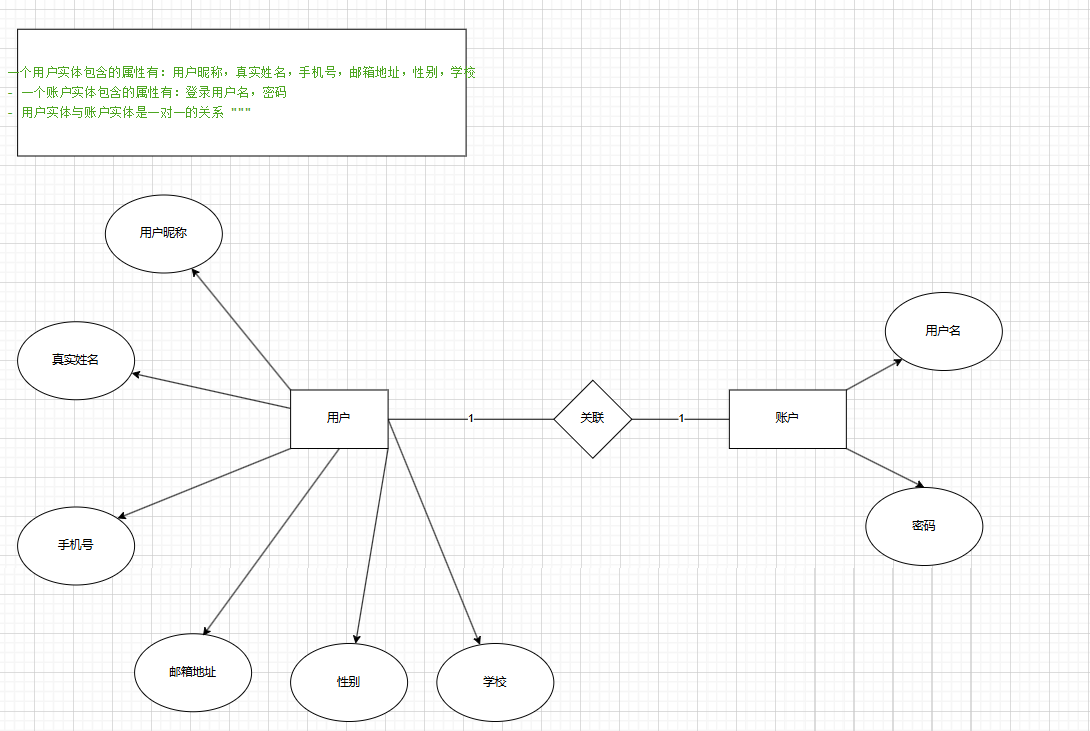
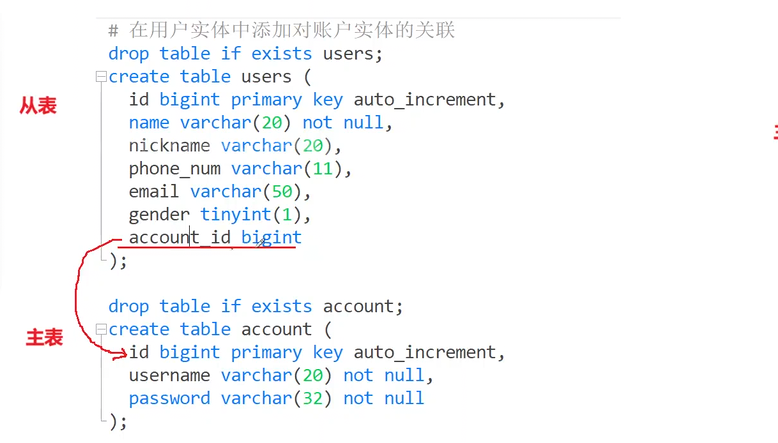
用戶表和賬戶表一對一
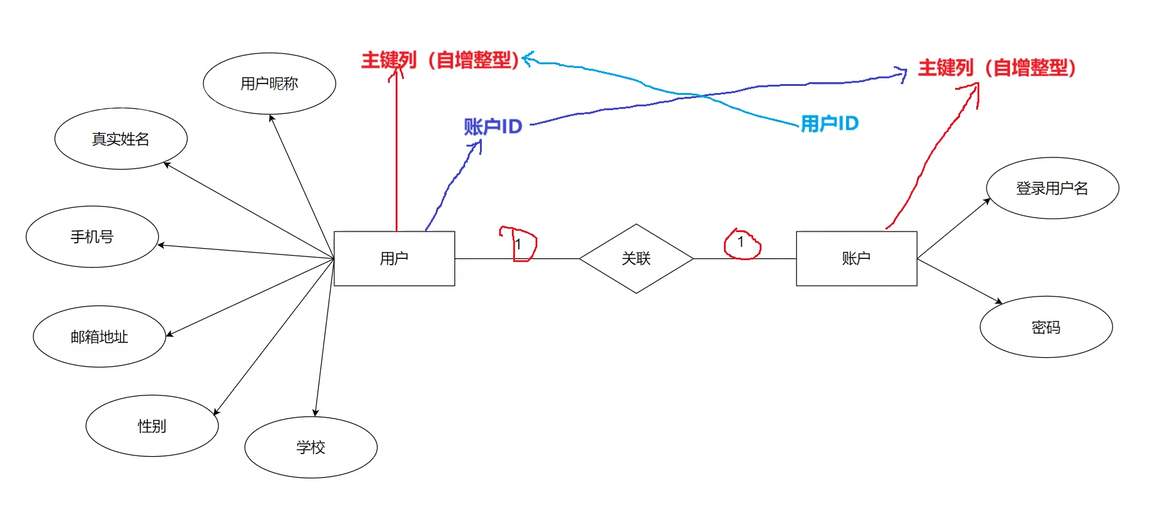
當用戶賬戶表一對一的時候,我們就可以在用戶表中多創建一個賬戶主鍵id進行維護,這樣就能通過該id查找到賬戶表中的內容。
一對多的關系
如果一個班級對應著多個學生,那么學生表中就要創建一個字段來存儲對應的班級id。在多方的表中增加字段。
多對多的關系
如果是學生和課程多對多的話,我們建立關系就要進行增加另外一張表的方式來進行操作,多建立一張成績表,分別記錄學生和課程的關系。
逆向導出EE-R圖
 ?如圖即為逆向導出EER圖,就能看到表之間的關聯關系。
?如圖即為逆向導出EER圖,就能看到表之間的關聯關系。






)






鎖)
—— 適老化烹飪中心詳細構思)
)



