音視頻領域技術門檻高,學習資料稀缺,體系化書籍和開發工具有限,新手入門困難。
音視頻開發涉及眾多任務:音頻(采集、編解碼、降噪等)、視頻(采集、編解碼、圖像處理)、實時傳輸(RTP/RTCP、RTMP、HLS)、存儲與播放等,要求扎實的理論基礎和工程經驗,自學難度大。
本系列文章將圍繞?“C++音視頻流媒體高級開發面試題”?進行全面解析技術面試要點。由于篇幅限制,整個系列將分為多篇陸續發布,每篇為不同專題,本文為?第一篇 音視頻基礎面試題。
目錄:
一、音頻基礎面試題
二、視頻基礎面試題
Part1音頻基礎面試題
1、聲音采集的原理是什么,如何實現模數轉換?
聲音采集的基本原理涉及將自然界中的聲波轉換為電信號,再通過模數轉換(ADC, Analog-to-Digital Conversion)將這些模擬信號轉換為數字信號,以便計算機或其他數字設備進行處理。
聲音采集的原理
麥克風捕捉聲波:聲音是一種機械波,它通過空氣傳播。當聲波到達麥克風時,麥克風內部的膜片會根據聲波的壓力變化而振動。
聲電轉換:麥克風將膜片的機械運動轉換成相應的電信號。不同類型的麥克風使用不同的機制來完成這個轉換過程,如動圈式、電容式或駐極體等。
前置放大:由于從麥克風輸出的電信號非常微弱,通常需要經過一個前置放大器來增強信號強度,以便后續處理。
濾波處理:為了去除可能干擾音頻質量的不必要頻率成分,通常會對信號進行濾波處理。
模數轉換的實現
模數轉換是將連續的模擬信號轉換為離散的數字信號的過程,主要工作原理可以分為三個步驟:采樣、量化和編碼。
采樣:按照一定的時間間隔對模擬信號進行測量,這個過程稱為采樣。采樣的頻率必須至少是原始信號最高頻率的兩倍(根據奈奎斯特-香農采樣定理),以避免混疊現象的發生。
量化:將采樣得到的每個樣本值映射到最接近的可用數值上,這個過程會導致一定的誤差,即量化噪聲。選擇更高的位深度可以減少這種噪聲,提高音頻質量。
編碼:將量化的結果轉化為二進制代碼,以便于數字系統處理和存儲。
2、為何高品質音頻的采樣率需達到?44.1KHz?及以上?
高品質音頻采樣率達到 44.1kHz(CD標準)及以上 的根本原因在于 奈奎斯特采樣定理,但更深層次是為了無失真地捕捉人耳可聽的全部頻率范圍,并為關鍵的抗混疊濾波提供設計余量。
人類對于音頻信號聽覺范圍大致在20Hz到20kHz之間,為了捕捉到人耳能夠聽到的所有聲音頻率,采樣率需要至少為20kHz的兩倍,即40kHz。而44.1kHz作為一個標準值被廣泛采用,
特別是在CD音質中,它不僅滿足了奈奎斯特速率的要求,還提供了一些額外的空間來幫助簡化抗混疊濾波器的設計(這種濾波器用于去除高于可接受范圍的頻率成分)。
選擇44.1kHz作為標準還有歷史原因,與早期數字音頻系統的技術限制有關,包括視頻記錄設備的使用等。然而,隨著技術的發展,現在有更高的采樣率如48kHz、96kHz甚至192kHz被用于專業音頻錄制和回放,以進一步提高音質,尤其是在高端音頻應用中。更高的采樣率可以捕捉更精確的聲音細節,并有助于減少數字化過程中可能出現的各種失真。
3、什么是?PCM(脈沖編碼調制)?
PCM 是將模擬聲音信號數字化最直接、最基礎的方法,廣泛應用于音頻和電信領域。它通過采樣(時間離散化)、量化(幅度離散化)和編碼(二進制表示)三個步驟,將連續的聲波轉換為計算機可處理的?0?和?1?的序列。其核心參數是采樣率(決定頻率上限和時間精度)和位深度(決定動態范圍和幅度精度)。作為未壓縮的原始音頻數據,PCM 提供了最高的保真度,是數字音頻存儲(如 WAV, AIFF, CD)、傳輸和處理的基石。后續的有損壓縮(MP3, AAC)和無損壓縮(FLAC, ALAC)都是在 PCM 的基礎上進行的。
PCM 包含以下幾個關鍵步驟:
采樣:首先,模擬信號按照固定的時間間隔進行采樣。根據奈奎斯特-香農采樣定理,為了確保能夠重建原始信號而不丟失信息,采樣頻率需要至少是信號最高頻率的兩倍。
量化:采樣得到的數據值通常是一個連續范圍內的數值,量化過程將這些值映射到一個有限數量的離散級別上。這個過程中會引入量化誤差或稱為量化噪聲,它可以通過增加位深度(即每個樣本使用的比特數)來減少。
編碼:經過量化的樣本值會被轉換成二進制代碼。編碼不僅涉及到如何用二進制數表示量化后的值,還可能包括一些用于糾錯或數據壓縮的技術。
4、每個采樣點需要用多少位來表示?
每個采樣點所需的位數(即位深度或比特深度)決定了音頻的動態范圍和精度。常見的位深度包括:
16位(bit):這是CD音質的標準,提供了96dB的動態范圍。這意味著它可以捕捉從非常安靜到相對響亮的聲音,足以滿足大多數音樂和娛樂應用的需求。
24位:這種位深度常用于專業音頻錄制和處理,提供144dB的理論動態范圍。更高的動態范圍允許更精確地表示非常微小的聲音細節以及更大范圍的聲音強度,適合需要高保真度的專業場合。
32位及更高:一些高端音頻應用可能會使用32位甚至更高的位深度進行內部處理,以進一步提高精度和減少計算過程中的累積誤差。不過,最終這些高分辨率的數據通常會被轉換為較低位深度(如16位或24位)來分發給消費者,因為目前大部分消費級音頻設備支持的最大位深度為24位。
位深度如何影響音質?
參數 | 影響 |
動態范圍 | 每增加1位 ≈ 增加6dB動態范圍(公式:動態范圍(dB) ≈ 6.02 × 位深度 + 1.76) |
量化噪聲 | 位深度越低 → 量化步長越大 → 本底噪聲越高(聽感為“沙沙聲”) |
幅度精度 | 高位深度對小信號還原更精準(避免微弱細節被量化誤差淹沒) |
如何選擇位深度?
應用場景 | 推薦位深度 | 理由 |
專業錄音/混音 | 24-bit 或 32-bit | 保留最大動態余量,適配后期處理 |
CD/流媒體發布 | 16-bit | 符合消費端標準,文件體積適中 |
影視游戲音效設計 | 24-bit | 需處理極端動態(爆炸聲+環境音) |
電話語音 | 8-bit (μ-law) | 壓縮動態范圍,優化帶寬(實際使用對數量化) |
DSP內部處理 | 32-bit Float | 避免運算過程失真 |
5、采樣值究竟該采用整數,還是浮點數?
這個問題其實隱含了多個子問題:整數和浮點數在音頻處理中各有什么優劣?應用場景如何區分?為什么專業領域普遍用24-bit整數錄音卻用32-bit浮點數處理?
在音頻開發中,采樣值既可以使用整數也可以使用浮點數,具體選擇取決于使用場景:
- 整數
(如 16-bit、24-bit)適合音頻采集和播放,硬件兼容性好,占用資源少;
- 浮點數
(如 32-bit float)更適合音頻處理階段,動態范圍大、精度高,能避免溢出和精度丟失;
實際開發中通常會結合使用,采集時用整數,處理時轉為浮點,最終輸出再轉回整數。
核心區別與適用場景
特性 | 整數(如 16/24-bit) | 浮點數(32-bit Float) |
動態范圍 | 有限(16-bit≈96dB,24-bit≈144dB) | 理論上無限(實際≈1500dB) |
超0dBFS處理能力 | ? 超過最大值直接削波(Clipping) | ? 可安全記錄超0dBFS的信號(如+6dB) |
量化誤差分布 | 全范圍固定步長,小信號精度低 | 小信號精度高(對數分布特性) |
存儲/帶寬開銷 | 較低(24-bit=3字節/采樣點) | 較高(32-bit=4字節/采樣點) |
硬件支持 | ? 所有ADC芯片、DAC芯片原生支持 | ? ADC/DAC需轉換(實際硬件處理仍用整數) |
適用階段 | 原始錄音 & 最終分發 | 音頻處理中間環節 |
為什么不同階段需要不同格式?
1. 錄音/采集階段 → 必須用整數(24-bit為主)
物理限制:?ADC(模數轉換器)芯片硬件輸出的是離散整數值,這是物理電路的量化結果。
動態范圍優化:?24-bit整數提供≈144dB動態范圍,遠超高質量模擬設備本底噪聲(-120dB),保留完整信號。
示例:?錄制交響樂時,24-bit可同時捕捉細微的三角鐵聲(-50dB)和強烈的定音鼓(0dB)。
2. 音頻處理階段(DAW/混音) → 強烈推薦浮點數(32-bit Float)
防削波:?混音時疊加多個軌道易超0dBFS(如:鼓+貝斯+人聲)。浮點允許臨時超載,保留原始數據。
高精度運算:?EQ、壓縮等效果器涉及乘法運算,浮點減少舍入誤差(避免“位數衰減”)。
靈活調參:?增益調整±20dB無需擔心失真(整數需謹慎控制電平)。
關鍵決策因素
因素 | 選整數 | 選浮點數 |
直接連接ADC/DAC硬件 | ??必須 | ? 不支持 |
處理多軌道/復雜效果鏈 | ? 易導致削波 | ??首選(DAW內部格式) |
存儲空間/帶寬敏感 | ? 更緊湊(16-bit比32-bit小50%) | ? 體積大 |
需超0dBFS記錄 | ? 不可能 | ??唯一選擇(如錄制突發爆炸聲) |
嵌入式設備(低算力) | ? 整數運算更快更省電 | ? 浮點計算開銷大 |
6、音量大小與采樣值之間存在怎樣的關系?
音量大小與采樣值之間的關系主要體現在音頻信號的振幅上。在數字音頻中,每一個采樣值代表了音頻波形在某一時刻的振幅大小。采樣值越大(無論是正值還是負值),音頻的振幅就越高,對應的主觀聽感就是音量越大。
具體來說:
振幅決定音量:采樣值的絕對值越大,表示波形振幅越高,聲音就越響亮。例如,在16位PCM中,采樣值范圍是-32768到32767,越接近這兩個極限值,聲音就越響。
增益控制的本質:我們可以通過對采樣值進行乘法運算來調整音量。例如,將所有采樣值乘以一個大于1的系數,可以提升音量;乘以一個小于1的系數,則降低音量。但需要注意避免溢出或削波失真。
浮點與整數表示的影響:在浮點數格式(如32-bit float)中,采樣值通常歸一化在[-1.0, 1.0]之間,便于進行音頻處理。而在整數格式中,動態范圍受限于位深度,因此在進行音量放大時更容易達到最大值而導致失真。
標準化與動態范圍:在音頻后期處理中,我們經常會對采樣值進行歸一化處理,使最大采樣值達到滿刻度(如0dBFS),從而充分利用動態范圍,提高整體音量。
7、通常多少個采樣點構成一幀數據?
從技術角度看,一幀(Frame)包含的采樣點數沒有絕對標準,其數量由?應用場景、系統設計需求和硬件限制?共同決定。
核心影響因素
因素 | 對幀大小的影響 | 典型場景示例 |
延遲要求 | 低延遲場景 → 小幀(更少采樣點) | 實時通話、直播(10-30ms) |
算法處理需求 | 特定算法需固定幀長(如FFT要求2^N點) | 音頻編解碼(AAC:1024點) |
硬件緩沖區限制 | 匹配DMA傳輸塊大小/內存對齊 | 嵌入式設備(64/128點) |
文件/網絡協議封裝 | 按協議定義幀結構(如MP3固定1152點) | 媒體容器(WAV無幀概念) |
行業常見幀大小參考
1. 實時音頻流(低延遲優先)
采樣率 | 幀時長 | 單通道采樣點數 | 應用場景 |
48 kHz | 10 ms | 480 | VoIP、游戲語音 |
44.1 kHz | 20 ms | 882 | 直播推流 |
16 kHz | 30 ms | 480 | 電話會議 |
📌?為什么是這些值?
10ms幀:人耳可感知延遲的臨界點(≤20ms無感)
480點:48kHz÷1000ms×10ms=480,計算直觀
2. 音頻編解碼(算法固定幀)
編碼格式 | 單幀采樣點數 | 說明 |
AAC-LC | 1024 | 標準幀長,平衡延遲與壓縮率 |
OPUS | 2.5-120ms可變 | 動態調整(默認20ms@48kHz=960點) |
MP3 | 1152 | MPEG標準固定值 |
G.711 | 80/160 | 傳統電話編碼(10ms/20ms) |
3. 硬件/驅動層(內存對齊優化)
系統平臺 | 典型幀大小 | 設計原因 |
ALSA (Linux) | 256/512/1024 | 匹配DMA緩沖區大小(2^N對齊) |
Core Audio (macOS) | 64-1024可調 | 低延遲優先,默認256點 |
嵌入式DSP | 32/64/128 | 減少內存占用,適配緩存行 |
8、左右聲道的采樣數據又是如何排列的?
在音頻處理中,立體聲的左右聲道數據主要有兩種排列方式:
第一種是?交錯排列(Interleaved),也就是左右聲道的數據是交替存放的。比如一個立體聲PCM音頻,它的采樣數據可能是這樣排的:左聲道第一個采樣點,接著是右聲道第一個采樣點,然后是左聲道第二個,再右聲道第二個,依此類推。這種格式在音頻播放和文件格式中非常常見,比如WAV文件默認就是這種格式,處理起來也比較直觀。
第二種是?平面排列(Planar),也就是把左聲道和右聲道的數據分開存儲。比如先把所有左聲道的采樣點放在一起,然后再放所有右聲道的采樣點。這種方式在音頻處理中比較常見,比如在FFmpeg或者一些音頻算法中,處理起來效率更高,特別是當你只想單獨處理某一個聲道的時候。
在音視頻開發中,交錯排列是存儲和傳輸的主流標準,因為它結構緊湊,符合硬件和文件的自然組織方式。而平面排列是專業音頻處理的“好幫手”,因為它讓單聲道數據的訪問更連續,計算效率更高。實際開發時,我們常需要根據使用的API、庫或硬件的要求,在兩者之間進行轉換。
9、音頻編碼的基本原理是什么?
音頻編碼的基本原理是將模擬音頻信號轉換為數字信號,并通過壓縮技術減少數據量,便于存儲和傳輸。
主要流程包括:
采樣和量化:把聲音從連續的模擬信號轉為離散的數字信號;
PCM 編碼:最原始的編碼方式,數據量大但音質保留完整;
壓縮處理:分為無損(如 FLAC)和有損(如 MP3、AAC)兩種方式;
心理聲學模型:用于有損編碼,去掉人耳不敏感的聲音信息;
變換編碼(如 FFT):將信號轉為頻率域,提高壓縮效率。
最終目標是在音質和壓縮率之間取得平衡。
Part2視頻基礎面試題
1、RGB?色彩模式背后的原理是什么?
RGB模式通過獨立控制紅、綠、藍三種色光的強度并進行疊加混合,在發光設備(屏幕)上再現人眼可見的各種顏色,其數值表示定義了每個像素點的具體顏色。它是數字成像和顯示技術的核心基礎。
生理基礎:RGB模擬人眼三種視錐細胞(紅/綠/藍)感光特性。
混合原理:加色法?- 通過混合不同強度的紅、綠、藍光產生其他顏色(紅+綠=黃,三色全開=白)。
數字表示:每種原色的強度用數值表示(如8位:0-255),一個像素顏色由?
(R, G, B)?三元組定義。位深度:決定每種顏色有多少級亮度(8位=256級)。
色彩空間:定義了R/G/B三原色的具體標準和白點(如sRGB, Adobe RGB)。
硬件實現:顯示設備的物理像素由紅、綠、藍子像素構成,直接受RGB數值控制。
2、為什么在視頻處理中,YUV?格式被廣泛應用?
YUV 被廣泛用于視頻處理,主要有四個原因:
- 符合人眼感知
:人眼對亮度(Y)更敏感,對色度(U/V)敏感度低,便于壓縮時減少色度數據而不影響觀感;
- 利于壓縮
:支持色度子采樣(如 4:2:0),大幅減少數據量,提升編碼效率;
- 兼容性強
:歷史原因,很多視頻標準(如 MPEG、H.264/265)都基于 YUV 設計。
編碼優化?:便于視頻壓縮算法處理,節省帶寬和存儲空間
YUV 通過 分離亮度與色度 + 智能降低色度分辨率,在幾乎不損失人眼感知畫質的前提下,大幅壓縮視頻數據量,是效率與觀感的最佳平衡。
3、什么是像素,它在視頻成像中扮演著怎樣的角色?
像素(Pixel)?是圖像顯示的基本單位,是“圖片元素”的簡稱。每個像素都是一個帶有特定顏色和亮度值的小點,當大量這樣的點按照一定的排列組合在一起時,就形成了我們看到的圖像。在數字圖像中,每一個像素的顏色通常由紅(R)、綠(G)、藍(B)三原色的不同強度組合而成。可以說像素是視頻成像的基石,它的數量和顏色數據共同定義了畫面的細節與色彩。
在視頻中,像素的作用主要有:
- 構成畫面
:視頻由一幀幀圖像組成,每幀由大量像素排列組成;
- 決定分辨率
:像素數量越多(如1920x1080),畫面越清晰;
- 影響畫質
:像素的顏色深度(如8bit、10bit)決定色彩豐富度;
- 影響壓縮和傳輸
:像素越多,視頻數據量越大,對編碼和帶寬要求越高。
4、分辨率、幀率、碼率各自代表什么含義,它們之間又有怎樣的關聯?
分辨率:畫面清晰度(像素數量,如1920x1080)。越高越清晰。
幀率:動作流暢度(每秒幀數/FPS,如30fps)。越高越流暢。
碼率:數據量/帶寬成本(每秒數據量/Mbps)。越高畫質潛力越大,文件也越大。
三者的關系:
分辨率越高、幀率越高,數據量越大,需要更高的碼率來保證畫質;
在碼率有限的情況下,提高分辨率或幀率可能會導致畫面壓縮過度、出現模糊或卡頓;
實際應用中,需要根據帶寬和設備性能做權衡,比如直播會優先控制碼率,本地播放可支持更高分辨率和幀率。
5、YUV?數據有哪些不同的存儲格式,這些格式之間存在哪些差異?
YUV 數據的主要存儲格式差異集中在兩點:色度采樣比例?和?內存排列方式
1. 色度采樣比例
- YUV444
:每個像素都有獨立的Y、U、V值,不進行任何子采樣,提供最高質量。
- YUV422
:水平方向上色度子采樣,每兩個亮度樣本共享一組色度樣本,減少一半的色度信息。
- YUV420
:在水平和垂直方向上都進行色度子采樣,每四個亮度樣本共享一組色度樣本,適合大多數應用場景,如H.264編碼。
2. 內存排列方式
- Planar(平面)格式
:像I420這樣的格式,將Y、U、V三個分量分別連續存儲在一個平面上,便于某些類型的圖像處理操作。
- Semi-planar(半平面)格式
:例如NV12或NV21,先存放全部的Y值,接著是交錯的U和V值,這種格式有利于現代GPU加速處理,因為可以更高效地訪問Y和UV數據。
- Packed(打包)格式
:比如YUYV或UYVY,亮度和色度值交錯存儲于同一行中,雖然占用更多內存但可能簡化了某些硬件實現。
6、YUV?數據在內存對齊時,需要注意哪些問題?
1、起始地址對齊:
YUV 緩沖區的首地址必須按硬件要求對齊(通常 16/64/128 字節),避免訪問異常或性能暴跌。
👉 操作:使用?aligned_alloc?等函數顯式分配內存。
2、行跨距對齊 (Stride):
每行數據的實際字節數(Stride)需 ≥ 圖像寬度字節數,并填充至對齊粒度(如 16/64 字節)。
必須用 Stride 而非圖像寬度訪問數據!
👉 原因:適配內存訪問粒度,提升 SIMD/GPU 效率。
3、色度分辨率對齊:
對于?
4:2:0/4:2:2?格式,圖像寬高必須是偶數(如 1920x1080?,1921x1081?)。U/V 平面需獨立滿足地址和 Stride 對齊(分辨率雖為 Y 的 1/2,對齊要求相同)。
👉 原因:防止色度采樣錯位導致的顏色異常(如綠屏)。
4、平臺差異適配:
不同硬件(CPU/GPU/編解碼芯片)或平臺(Windows/iOS/Android)可能有特殊對齊要求(如 NVIDIA 要求 128 字節),需查閱文檔適配。
7、畫面出現綠屏現象的原因是什么?
綠屏現象在視頻播放或處理過程中是一個比較常見的問題,其可能的原因有多種。以下是一些主要的可能原因:
編碼格式不支持或解碼錯誤:如果視頻文件采用了一種播放器或處理軟件不完全支持的編碼格式,或者在解碼過程中出現了錯誤,可能會導致顯示異常,例如出現綠屏。
硬件加速問題:一些播放器使用硬件加速來提高性能,但如果硬件加速配置不正確,或者使用的顯卡驅動程序有問題,可能導致視頻無法正常渲染,進而出現綠屏。
內存對齊和數據損壞:在視頻處理過程中,如果YUV等視頻幀數據沒有正確地進行內存對齊,或者數據在傳輸、處理過程中發生了損壞,也可能導致顯示異常如綠屏。
色彩空間轉換錯誤:視頻幀通常需要從一種色彩空間(如YUV)轉換到另一種色彩空間(如RGB)以便于顯示。如果這個轉換過程發生錯誤,比如參數設置不對,也可能導致顯示異常。
源文件損壞:如果視頻源文件本身已經損壞,無論是由于下載不完整、存儲介質故障還是其他原因,都可能導致播放時出現問題,包括綠屏現象。
軟件兼容性問題:有時特定版本的播放軟件與操作系統或其他軟件之間可能存在兼容性問題,這也可能是造成綠屏的原因之一。
解決這些問題通常涉及到檢查并更新軟件、確保編解碼器正確安裝、調整播放器設置(如關閉硬件加速)、驗證源文件完整性等方面。根據具體情況的不同,解決方案也會有所不同。
8、H264?編碼的工作原理是什么?
H.264通過 幀類型劃分(I/P/B)→ 智能預測(幀內/幀間)→ 殘差變換量化 → 熵編碼 四步曲,在時間(運動預測)、空間(紋理預測)、頻率(能量集中)、統計(概率編碼)四個維度壓縮冗余,實現高效編碼。其核心是以計算換帶寬,平衡效率與畫質。
它的基本工作原理包括以下幾個關鍵步驟:
幀類型劃分:分為 I 幀(關鍵幀)、P 幀(前向預測幀)、B 幀(雙向預測幀),利用幀與幀之間的相關性減少冗余數據。
宏塊處理:將每一幀劃分為 16x16 的宏塊,作為編碼的基本單元。
幀內/幀間預測:
幀內預測:利用當前幀內部已編碼區域預測當前宏塊。
幀間預測:通過運動估計和運動補償,用參考幀預測當前幀內容,只編碼差異部分。
變換與量化:對預測后的殘差進行 DCT 變換和量化,壓縮數據量。
熵編碼:使用 CAVLC 或 CABAC 對量化后的數據進一步壓縮。
去塊濾波:減少塊效應,提升圖像質量。
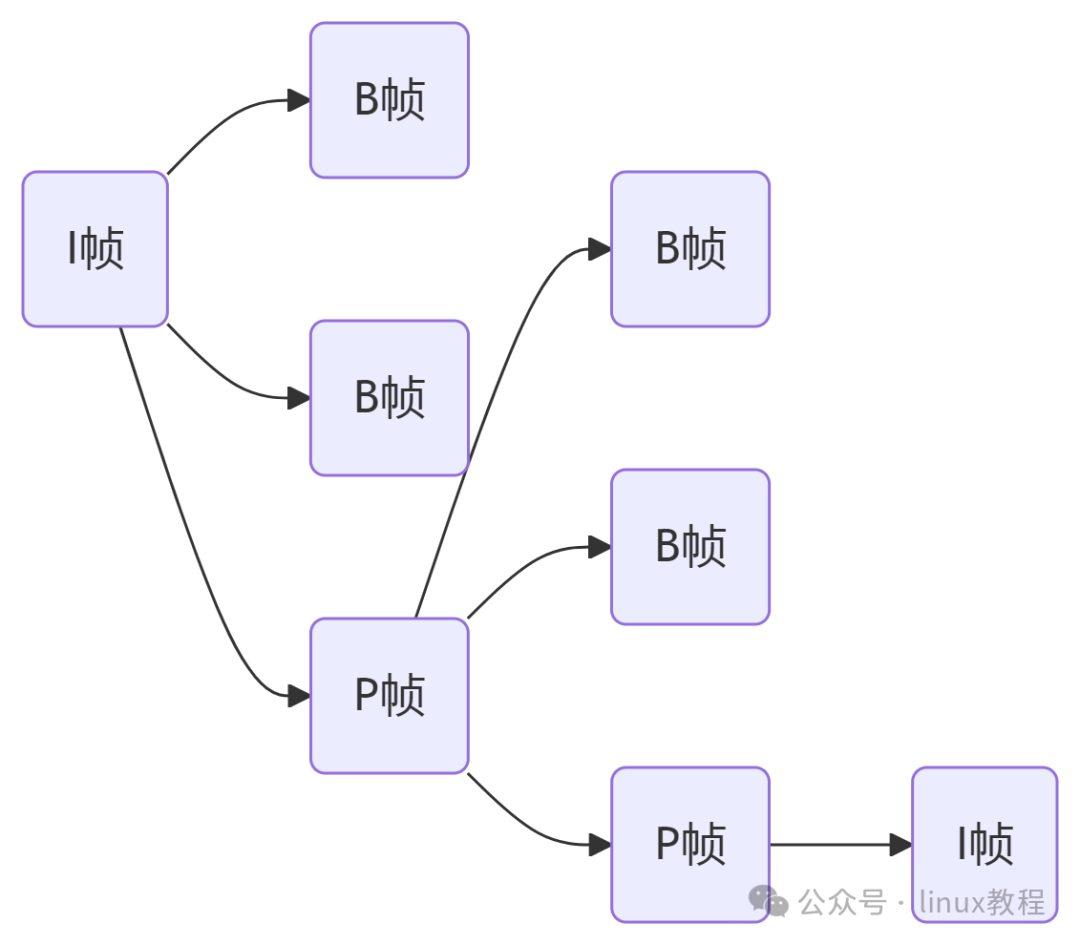
9、H264 編碼中的 I 幀、P 幀、B 幀之間存在怎樣的關系?
依賴關系(誰需要誰?)
幀類型 | 依賴對象 | 可否獨立解碼? | 示例 |
I 幀 | 不依賴任何幀 | ? 是(關鍵幀) | 視頻開頭、場景切換點 |
P 幀 | 依賴前一幀(I 或 P 幀) | ? 否 | 參考前一幀預測運動物體 |
B 幀 | 依賴前后幀(I/P 幀) | ? 否 | 參考前后幀插值中間動作 |
- 解碼順序 ≠ 播放順序:
B 幀需等待后續參考幀解碼完成,因此傳輸順序為:
I → P → B 但播放順序為 I → B → P
例:播放順序 I1, B2, B3, P4,傳輸順序 I1, P4, B2, B3
壓縮效率對比
幀類型 | 數據量 | 壓縮原理 | 適用場景 |
I 幀 | 最大(100%) | 幀內預測 + 變換量化(類似JPEG) | 場景切換、隨機訪問 |
P 幀 | 中等(≈I幀30%) | 單向運動補償 + 殘差編碼 | 普通運動畫面 |
B 幀 | 最小(≈I幀10%) | 雙向運動補償 + 更小殘差 | 慢動作、漸變鏡頭 |
? 壓縮率排序:B幀 > P幀 > I幀
?? 代價:B幀增加編解碼延遲(需緩存前后幀)
協作模式
工程中的關鍵影響
設計選擇 | 對幀類型的影響 | 應用案例 |
GOP長度 | I幀間隔越長 → 壓縮率越高,但隨機訪問延遲越大 | 直播:GOP短(1-2s) |
B幀數量 | B幀越多 → 壓縮率越高,編解碼延遲越大 | 實時通話:禁用B幀 |
參考幀數量 | P幀可參考前多幀 → 提升遮擋場景精度 | 運動鏡頭:多參考幀 |
本期面試題就更新到這里了,下期更新解復用以及FFmpeg相關面試題~
點擊下方關注【Linux教程】,獲取編程學習路線、項目教程、簡歷模板、大廠面試題pdf文檔、大廠面經、編程交流圈子等等。

)






鎖)
—— 適老化烹飪中心詳細構思)
)




JavaScript 基礎知識)



