引言
在容器化技術席卷全球的今天,Kubernetes(簡稱 K8s)已成為容器編排領域的事實標準。無論是互聯網企業還是傳統行業,都在通過 Kubernetes 實現應用的高效部署、彈性擴展和自動化運維。但對于初學者而言,Kubernetes 的概念繁多、架構復雜,往往讓人望而卻步。
本文基于 Kubernetes 核心文檔,從 “是什么”“為什么” 兩個維度,全面解析 Kubernetes 的起源、應用部署演變、核心特性、架構組成及現狀挑戰。內容涵蓋基礎概念、技術細節和實踐要點,確保零基礎讀者也能透徹理解。文末將附上常見問題排錯、總結與思考,幫你夯實 Kubernetes 的理論基礎。
一、基礎設施變革:應用部署的三次革命
應用部署方式的演變始終圍繞 “資源利用率”“隔離性” 和 “效率” 三大核心訴求。從物理服務器到虛擬化,再到容器,每一次變革都推動著技術架構的升級。
1.1 傳統部署時代(物理服務器)
- 是什么:直接在物理服務器上運行應用程序,沒有資源隔離機制。
- 核心問題:
- 資源分配不均:多個應用共享一臺物理機時,可能出現一個應用占用大量 CPU / 內存,導致其他應用性能驟降(例如:一個視頻處理應用占用 90% CPU,導致同服務器的 Web 應用響應超時)。
- 資源浪費:若每個應用單獨部署在物理機上,低負載時資源利用率極低(例如:一臺 8 核服務器僅運行一個輕量博客應用,資源利用率不足 5%)。
- 維護成本高:大量物理服務器的采購、機房租賃、電力消耗成本高昂,且硬件故障會直接導致應用不可用。
- 本質缺陷:無法為應用定義資源邊界,導致 “要么爭搶資源,要么閑置浪費”。
1.2 虛擬化部署時代(虛擬機 VM)
- 是什么:通過虛擬化技術(如 Hypervisor)在一臺物理服務器上運行多臺虛擬機(VM),每個 VM 包含獨立的操作系統和應用。
- 進步之處:
- 資源隔離:VM 之間通過虛擬化層隔離,避免應用間資源搶占(例如:VM1 的故障不會直接影響 VM2)。
- 資源利用率提升:物理機資源可按需求分配給多個 VM(例如:一臺 16 核服務器可劃分 4 個 4 核 VM,資源利用率從 20% 提升至 80%)。
- 可擴展性增強:通過虛擬化平臺(如 VMware vCenter)可快速創建 / 刪除 VM,適應業務波動(例如:電商促銷前快速擴容 10 臺 VM)。
- 局限性:
- 資源占用高:每個 VM 需要完整的操作系統副本(如 Windows 鏡像約 10GB)和硬件模擬(虛擬 CPU / 內存 / 網卡),通常占用 GB 級資源。
- 啟動慢:VM 啟動需加載操作系統內核、初始化服務,耗時分鐘級(對比容器的秒級啟動)。
- 靈活性不足:VM 與底層硬件綁定較深,跨平臺遷移困難(例如:從 VMware 遷移到 KVM 需重新配置驅動)。
1.3 容器部署時代(容器 Container)
是什么:容器是輕量級的隔離單元,共享主機操作系統內核,僅包含應用及依賴(如庫文件、配置),可理解為 “進程級隔離”。
核心優勢:
- 輕量高效:無需完整操作系統,僅包含必要依賴(例如:Nginx 容器約 20MB,遠小于 VM 的 10GB),啟動速度秒級(從創建到運行僅需 2-3 秒)。
- 資源共享:容器共享主機 OS 內核,減少內存 / 磁盤占用(例如:10 個 Nginx 容器共享同一 Linux 內核,總內存占用僅 500MB)。
- 可移植性強:與底層基礎設施解耦,可在 Ubuntu、RHEL、公有云(如 AWS)、本地環境中無縫遷移(“一次打包,到處運行”)。
- 隔離適度:既有獨立的文件系統、CPU / 內存配額、進程空間,又不過度隔離(共享內核降低開銷)。
容器的核心價值:解決了 “隔離性” 與 “資源效率” 的矛盾,讓應用部署從 “整機級” 進化到 “進程級”。
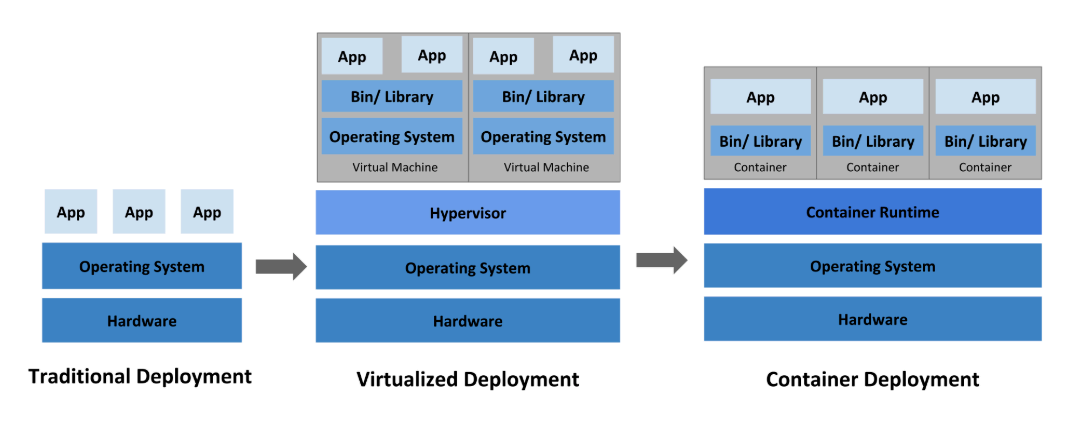
1.4 三者對比總結
| 維度 | 傳統部署 | 虛擬化部署 | 容器部署 |
|---|---|---|---|
| 隔離單元 | 物理機 | 虛擬機(VM) | 容器 |
| 資源占用 | 極高(整機) | 高(完整 OS) | 低(共享 OS 內核) |
| 啟動速度 | 慢(硬件啟動) | 較慢(OS 加載) | 快(秒級) |
| 可移植性 | 差 | 中(依賴 Hypervisor) | 優(跨云 / OS) |
| 資源利用率 | 低 | 中 | 高 |
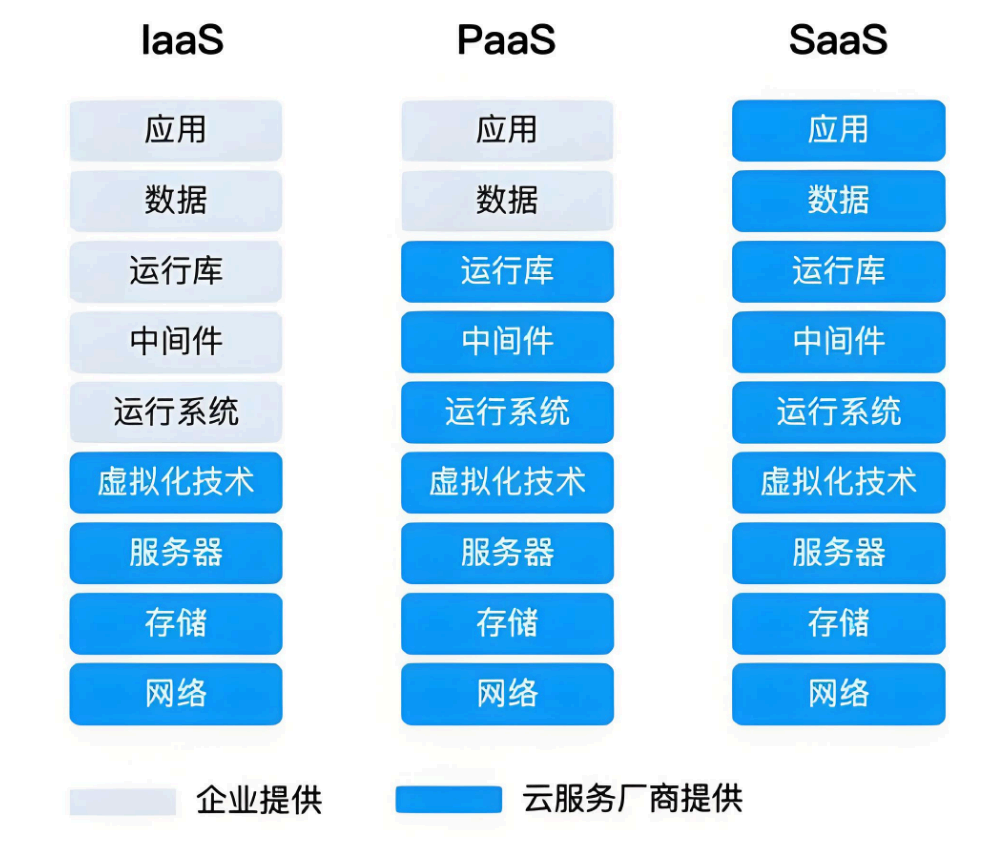
二、集群服務模式:IaaS、PaaS、SaaS
云計算服務模式從底層到上層分為 IaaS、PaaS、SaaS,分別對應基礎設施、平臺和軟件服務,Kubernetes 屬于 PaaS 層的核心工具。
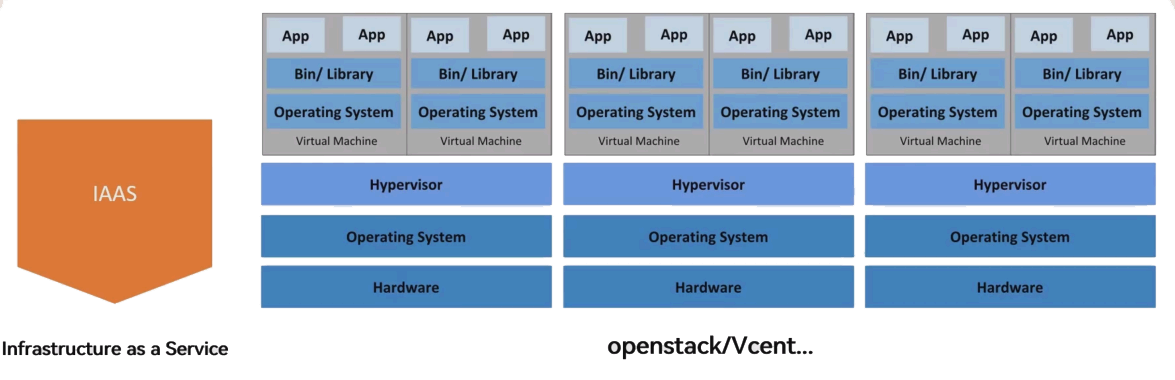
2.1 IaaS(基礎設施即服務)
- 定義:云服務廠商提供虛擬化的計算、存儲、網絡資源(如虛擬機、云硬盤、彈性 IP),用戶可遠程管理這些資源,按需付費。
- 核心價值:用戶無需購買物理硬件,通過管理平臺(如 OpenStack、AWS 控制臺)快速獲取資源,專注業務而非基礎設施維護。
- 典型場景:
- 企業通過 OpenStack 搭建私有云,管理虛擬機和存儲資源。
- 初創公司使用 AWS EC2、阿里云 ECS 等公有云虛擬機部署應用。
- 架構特點:底層為多臺物理機,每臺物理機通過 Hypervisor 運行多個 VM,VM 中運行應用,多物理機構成 IaaS 集群(如圖中 “IaaS” 架構所示)。
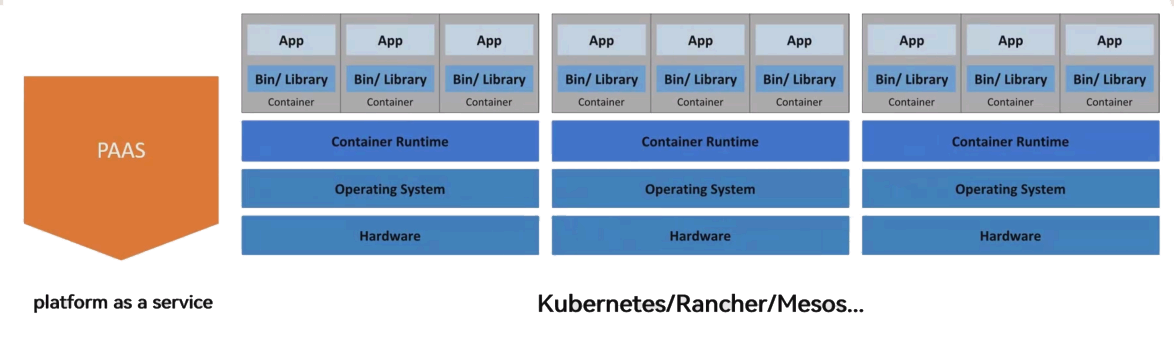
2.2 PaaS(平臺即服務)
- 定義:在 IaaS 基礎上,提供應用開發、部署、運行的完整平臺,包含開發工具、運行環境、數據庫等服務,用戶無需關注底層基礎設施。
- 核心價值:簡化應用生命周期管理,開發者只需上傳代碼,平臺自動處理部署、擴展、運維(例如:上傳 Java 代碼后,平臺自動配置 JVM、數據庫連接)。
- 典型工具:Kubernetes、Docker Swarm、Apache Mesos(均為容器編排平臺,屬于 PaaS 層核心工具)。
- 架構特點:底層為物理機,物理機上運行容器運行時,應用以容器形式部署,平臺統一管理容器生命周期(如圖中 “PaaS” 架構所示)。
2.3 SaaS(軟件即服務)
- 定義:廠商將軟件部署在云端,用戶通過互聯網直接使用(如網頁、APP),無需安裝、維護軟件及硬件,按訂閱付費。
- 核心價值:降低用戶使用門檻,廠商負責軟件更新、安全維護(例如:企業使用 Office 365,無需關心服務器部署和版本升級)。
- 典型場景:辦公軟件(Office 365)、客戶關系管理(Salesforce)、協作工具(釘釘)。
- 與前兩者的關系:IaaS 是底層基礎設施,PaaS 是中層開發 / 運行平臺,SaaS 是上層直接可用的軟件,三者構成云計算的完整棧(如圖中 “IaaS/PaaS/SaaS” 對比圖所示)。

2.4 三者對比(責任劃分)
| 服務模式 | 用戶負責 | 廠商負責 | 核心目標 |
|---|---|---|---|
| IaaS | 應用部署、運維 | 物理硬件、虛擬化層 | 靈活獲取基礎設施資源 |
| PaaS | 應用代碼開發 | 平臺、基礎設施 | 簡化應用生命周期管理 |
| SaaS | 僅使用軟件 | 全棧服務 | 降低軟件使用門檻 |
?三、容器編排工具對比:Swarm、Mesos、Kubernetes
當容器數量增長到成百上千時,手動管理容器的啟動、停止、擴縮容、故障恢復幾乎不可能,因此需要容器編排工具。主流工具包括以下三種:

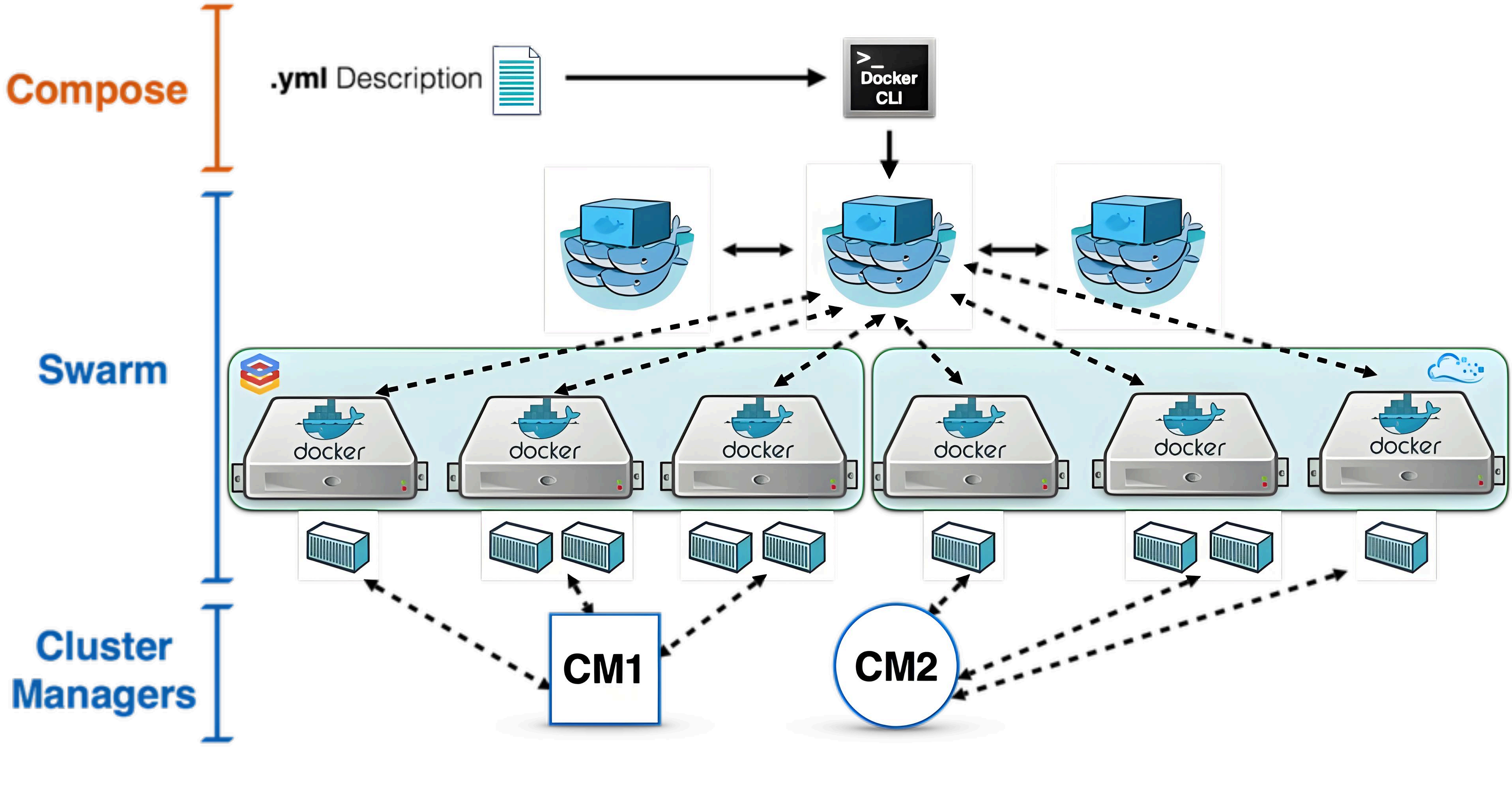
3.1 Docker Swarm
- 定位:Docker 官方推出的集群管理工具,將多臺 Docker 主機抽象為一個整體,通過統一入口管理容器資源。
- 核心特點:
- 兼容 Docker API:使用與單機 Docker 相同的命令(如
docker run),開發者無需改變工作流(例如:在 Swarm 集群中運行容器與在單機上運行命令一致)。 - 節點標簽:可通過鍵值對標簽(label)標記節點(如 “env=prod”“disk=ssd”),運行容器時可按標簽過濾節點(例如:指定 “env=prod” 的節點部署生產環境應用)。
- 架構簡單:由 Manager 節點(調度、管理)和 Worker 節點(運行容器)組成,適合中小規模集群。
- 兼容 Docker API:使用與單機 Docker 相同的命令(如
3.2 Apache Mesos
- 定位:通用集群管理器,不僅支持容器,還能運行 Hadoop、Spark、MPI 等分布式框架,目標是實現跨框架的資源共享。
- 核心特點:
- 資源共享層:底層提供輕量的資源共享層,使各框架(如 Hadoop、容器)通過統一接口訪問集群資源(解決框架間資源隔離問題)。
- 不直接調度:Mesos 負責資源分配(委派授權),具體調度由上層框架(如 Marathon 用于容器調度)完成,適合多框架混合部署場景(例如:同一集群同時運行 Hadoop 和容器)。

3.3 Kubernetes
- 定位:Google 開源的容器編排平臺,專為容器化應用設計,通過 “Pod” 和 “標簽(Label)” 實現邏輯分組,簡化集群管理。
- 與前兩者的核心區別:
- 以 Pod 為最小調度單元:Pod 是一組緊密協作的容器集合(共享網絡、存儲),作為一個整體部署和調度(Swarm 和 Mesos 直接調度單個容器)。
- 更全面的功能:內置服務發現、負載均衡、自動擴縮容、滾動更新等,適合復雜生產環境(例如:支持金絲雀部署、藍綠部署等高級策略)。
- 生態豐富:擁有龐大的周邊工具(如監控 Prometheus、日志 ELK、安全工具 Falco),支持公有云、私有云等多種環境。
3.4 市場占有率對比
根據文檔數據,容器編排工具中 Kubernetes 占絕對主導地位:
- Kubernetes:77%
- OpenShift(基于 Kubernetes):9%
- Swarm:5%
- Mesos:4%
- 其他:5%
四、Kubernetes 詳解
4.1 什么是 Kubernetes?
- 定義:Kubernetes(簡稱 K8s,因 “K” 和 “s” 之間有 8 個字母)是一個開源的容器編排平臺,用于自動化容器化應用的部署、擴展、運維和故障恢復。
- 起源:源于 Google 內部的 Borg 集群管理系統(2003 年開始使用),2014 年開源,后捐贈給 CNCF(云原生計算基金會)。
- 核心目標:提供一個彈性運行分布式系統的框架,幫助用戶實現應用的自動擴縮、故障轉移、部署模式(如金絲雀部署)等。
4.2 Kubernetes 核心特性
Kubernetes 的特性圍繞 “自動化”“可靠性”“可擴展性” 設計,以下是關鍵特性詳解:
1. 自動化上線和回滾
- 作用:分步驟部署應用更改(如代碼更新、配置調整),同時監控應用狀態;若出現問題,自動回滾到上一版本。
- 示例:部署一個 Nginx 應用更新時,K8s 會先更新 10% 的 Pod,確認無故障后再更新剩余 90%;若發現部分 Pod 健康檢查失敗,會自動將所有 Pod 回滾到舊版本。
2. 服務發現與負載均衡
- 服務發現:為每個 Pod 分配獨立 IP,為一組 Pod 提供統一的 DNS 名稱(通過 Service 資源),應用無需硬編碼 IP,直接通過 DNS 訪問(例如:
nginx-service.default.svc.cluster.local)。 - 負載均衡:Service 自動在 Pod 之間分發請求,實現流量均衡(例如:3 個 Nginx Pod,Service 會將請求平均分配給它們,避免單 Pod 過載)。
3. 自我修復
- 作用:持續監控容器和節點狀態,自動處理故障:
- 容器故障:重啟失敗的容器(例如:Nginx 進程崩潰后,K8s 會自動重啟該容器)。
- 節點故障:將故障節點上的 Pod 自動調度到健康節點(例如:Node1 宕機后,其上的 Pod 會在 Node2、Node3 上重建)。
- 健康檢查失敗:殺死不滿足健康檢查的容器,待修復后重新啟動(例如:Web 應用 5 次請求無響應,K8s 會殺死該容器并重啟)。
4. 存儲編排
- 作用:自動掛載用戶指定的存儲系統,支持本地存儲、公有云存儲(如 AWS EBS)、網絡存儲(如 NFS、iSCSI)。
- 優勢:應用無需關心存儲細節,通過聲明式配置即可使用存儲(例如:定義 “需要 10GB NFS 存儲”,K8s 自動掛載)。
5. Secret 和配置管理
- Secret:用于存儲敏感信息(如密碼、API 密鑰),以加密方式存儲,避免明文暴露在配置文件或鏡像中(例如:數據庫密碼通過 Secret 掛載,容器內通過文件或環境變量訪問)。
- 配置管理:通過 ConfigMap 存儲非敏感配置(如數據庫地址、日志級別),可在不重建鏡像的情況下更新配置(例如:修改日志級別后,只需更新 ConfigMap,容器會自動加載新配置)。
6. 水平擴縮
- 作用:根據業務需求(手動或自動)調整 Pod 數量:
- 手動:通過命令(如
kubectl scale deployment nginx --replicas=5)將 Pod 數量從 3 擴到 5。 - 自動:基于 CPU 使用率(如使用率≥80% 時擴容,≤20% 時縮容)。
- 手動:通過命令(如
- 優勢:靈活應對流量波動(例如:電商大促時自動擴容到 10 個 Pod,低谷時縮容到 2 個節省資源)。
4.3 Kubernetes 的不足
Kubernetes 雖然強大,但并非 “萬能解決方案”,需要明確其邊界:
- 不是傳統 PaaS:不提供完整的開發工具鏈(如 IDE)、數據庫等服務,僅提供容器編排基礎,需結合周邊工具構建完整平臺。
- 不直接部署源代碼:需配合 CI/CD 工具(如 Jenkins、GitLab CI)完成代碼構建、鏡像打包。
- 不內置日志 / 監控解決方案:僅提供指標收集機制,需集成 Prometheus(監控)、ELK(日志)等工具。
- 不管理機器配置:不負責物理機 / VM 的維護(如操作系統更新、硬件故障修復),需依賴底層 IaaS。
五、Kubernetes 現狀與挑戰
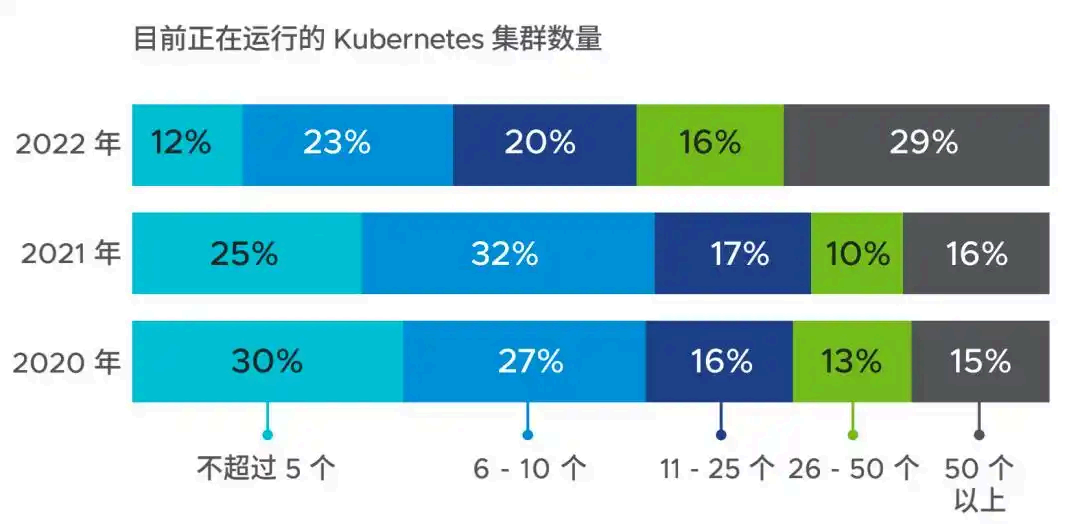
5.1 集群規模增長
Kubernetes 已成為容器編排的主流,企業部署的集群數量快速增長:
- 2022 年數據:僅 12% 的公司擁有≤5 個集群,29% 的公司擁有≥50 個集群(2020 年這一比例僅 15%)。
- 未來計劃:近一半企業預計來年集群數量增長≥50%,顯示 K8s 在企業中的滲透持續加深。
5.2 企業使用 Kubernetes 的原因
- 提高應用靈活性(62%):容器化 + K8s 使應用更易遷移、擴展(例如:從私有云遷移到公有云無需修改代碼)。
- 提高云利用率(59%):優化資源分配,減少云資源浪費(例如:通過自動裝箱將資源利用率從 50% 提升至 80%)。
- 提升開發效率(54%):簡化部署流程,縮短開發迭代周期(例如:從代碼提交到生產部署時間從天級縮短至小時級)。
5.3 帶來的核心優勢
- 資源利用率提升(59%):通過自動裝箱和混合部署,提高 CPU、內存使用率。
- 簡化應用升級和維護(49%):滾動更新、自動回滾減少人工操作(例如:零停機更新應用,無需手動啟停服務)。
- 支持云遷移和混合云(42%+40%):輕松實現從本地到公有云,或本地 + 公有云的混合部署(例如:核心業務在本地,彈性部分在公有云)。
5.4 成功案例:Pokémon Go
- 背景:2016 年推出的 AR 游戲,短時間內下載量突破 5 億,日活用戶 2000 萬,初期服務器無法承載流量(實際流量是預期的 50 倍)。
- 解決方案:借助 Google Cloud 的 Kubernetes 集群,快速擴展至數萬個內核,通過自動擴縮容應對突發流量。
- 核心價值:Kubernetes 的彈性擴縮能力幫助游戲在流量激增時保持服務可用,避免服務器崩潰。
5.5 面臨的挑戰
- 內部技能缺乏(51%):K8s 概念復雜,現有團隊難以快速掌握(例如:運維人員不熟悉 Pod、Service 等核心概念)。
- 招聘困難(37%):具備 K8s 技能的專業人才稀缺,招聘成本高(例如:K8s 工程師薪資比傳統運維高 50%)。
- 云原生技術變化快(34%):K8s 及周邊工具更新頻繁,企業難以跟上節奏(例如:K8s 每年發布多個版本,舊版本兼容性問題需持續跟進)。
六、Kubernetes 架構詳解
Kubernetes 集群由控制平面(Control Plane)?和節點(Node)?組成,控制平面負責全局決策,節點負責運行容器化應用。
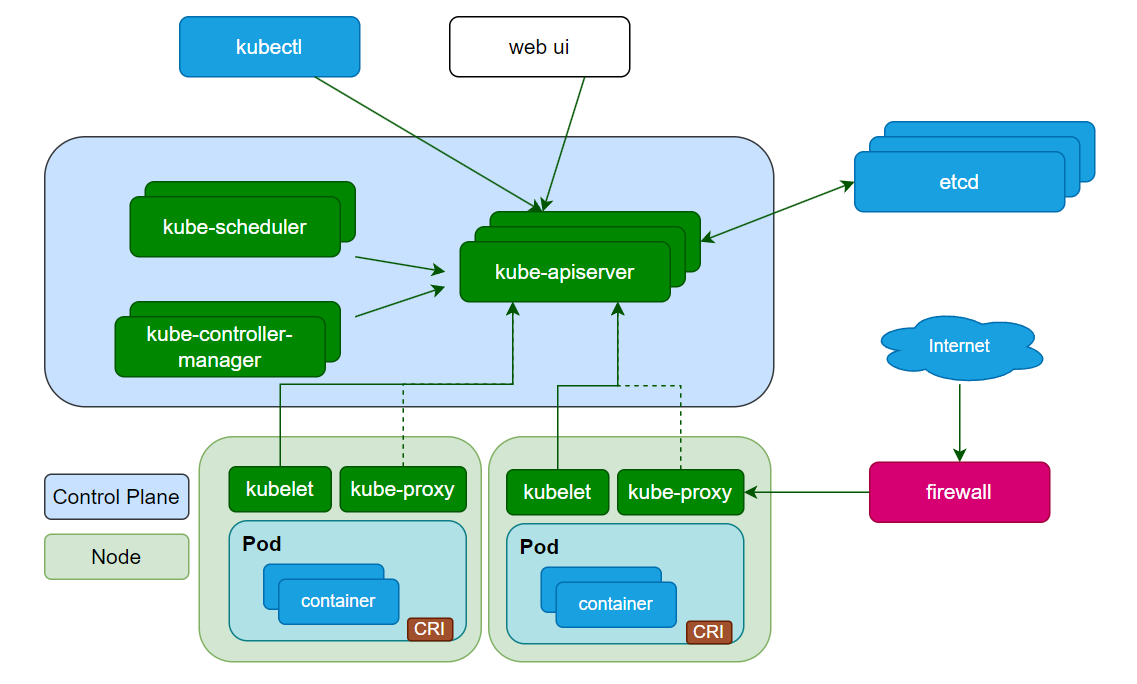
6.1 控制平面組件(Control Plane)
控制平面是集群的 “大腦”,可部署在單節點(測試環境)或多節點(生產環境,確保高可用),包含以下核心組件:
1. kube-apiserver
- 作用:Kubernetes 的 “統一入口”,所有操作(如創建 Pod、查詢服務)都通過 API Server 執行。
- 核心功能:
- 提供 RESTful API:支持 HTTP/HTTPS 請求(如
kubectl命令最終轉化為 API 請求)。 - 認證與授權:驗證請求者身份(如通過 Token、證書),檢查是否有操作權限(例如:普通用戶不能刪除集群級資源)。
- 數據驗證:確保資源配置符合規范(如 Pod 的 CPU 請求不能為負)。
- 數據存儲代理:將集群狀態寫入 etcd,并從 etcd 讀取數據。
- 提供 RESTful API:支持 HTTP/HTTPS 請求(如
2. etcd
- 作用:分布式鍵值存儲,作為 Kubernetes 的 “數據庫”,保存集群的所有狀態(如 Pod 配置、節點信息)。
- 特點:
- 一致性:采用 Raft 協議,確保多節點部署時數據一致(即使部分節點故障,數據仍可靠)。
- 高可用:通常部署 3/5 節點集群,容忍部分節點故障(例如:3 節點集群可容忍 1 個節點故障)。
3. kube-scheduler
- 作用:負責為 “未指定節點” 的 Pod 選擇合適的運行節點。
- 調度決策依據:
- 資源需求:Pod 需要的 CPU、內存是否滿足節點剩余資源(例如:Pod 需要 2 核 CPU,調度器會過濾出剩余 CPU≥2 核的節點)。
- 約束條件:如 “Pod 不能部署在某節點”“必須與某 Pod 部署在同一節點”(通過節點親和性 / 反親和性配置)。
- 其他因素:數據位置(如 Pod 需靠近存儲節點)、硬件約束(如 GPU 節點優先部署 AI 應用)。
4. kube-controller-manager
- 作用:運行一系列控制器進程,確保集群狀態與預期一致。
- 核心控制器:
- 節點控制器:監控節點健康,節點故障時標記并處理(例如:節點宕機后,將其標記為 “NotReady”,不再調度新 Pod)。
- 副本控制器:確保 Pod 副本數符合預期(如指定 3 個副本,若 1 個故障則新建 1 個)。
- 服務控制器:管理 Service 與 Pod 的關聯,實現服務發現(例如:PodIP 變化時,自動更新 Service 的 Endpoint)。
5. kubectl
- 作用:Kubernetes 的命令行工具,用于向 API Server 發送請求,操作集群(如創建 Pod、查看日志)。
- 常用命令示例:
kubectl get pods:查看所有 Pod 狀態。kubectl create deployment nginx --image=nginx:創建 Nginx Deployment。kubectl logs <pod-name>:查看 Pod 日志。
6.2 節點組件(Node)
節點是運行容器的工作機器(物理機或 VM),每個節點包含以下組件:
1. kubelet
- 作用:運行在每個節點上,負責維護容器生命周期(創建、更新、銷毀)。
- 工作邏輯:
- 接收 API Server 下發的 Pod 配置(PodSpec)。
- 確保 Pod 中描述的容器正常運行且健康(如執行健康檢查:定期發送 HTTP 請求,檢查應用是否存活)。
- 僅管理 Kubernetes 創建的容器,忽略其他容器(例如:手動用
docker run啟動的容器不受 kubelet 管理)。
2. kube-proxy
- 作用:節點上的網絡代理,實現 Kubernetes Service 的網絡功能。
- 核心功能:
- 維護節點網絡規則:確保 Pod 可被集群內 / 外網絡訪問(如將 Service 的 IP: 端口映射到后端 Pod)。
- 負載均衡:在多個 Pod 之間分發請求(基于 iptables 或 IPVS,例如:將 Service 的 80 端口請求轉發到 3 個 Nginx Pod 的 80 端口)。
3. 容器運行時(Container Runtime)
- 作用:負責容器的實際運行(創建、啟動、停止),是 Kubernetes 與容器的接口。
- 支持的運行時:containerd、CRI-O 等(需符合 Kubernetes 的容器運行時接口 CRI 規范)。
6.3 插件(Addons)
插件通過 Kubernetes 資源(如 DaemonSet、Deployment)實現集群級功能,常見插件包括:
- CoreDNS:提供集群內部 DNS 服務,為 Service 和 Pod 分配域名(如
nginx-service.default.svc.cluster.local),實現服務發現(Pod 可通過域名訪問其他 Service)。 - Ingress Controller:實現 7 層負載均衡(HTTP/HTTPS),支持域名路由、SSL 終止(Service 僅支持 4 層 TCP/UDP 負載均衡,例如:通過 Ingress 將
api.example.com路由到 API 服務,web.example.com路由到 Web 服務)。 - 網絡插件:實現容器網絡接口(CNI),負責 Pod IP 分配和跨節點 Pod 通信(如 Calico、Flannel,解決 Pod 跨節點通信問題)。
6.4 附件(Add-ons)
- Dashboard:Web 界面,用于可視化管理集群(查看 Pod 狀態、部署應用等,適合不熟悉命令行的用戶)。
- 容器資源監控:如 Prometheus+Grafana,收集容器 / 節點指標(CPU、內存使用率),提供監控面板和告警(例如:CPU 使用率≥90% 時發送告警)。
- 集群日志:如 ELK(Elasticsearch+Logstash+Kibana),集中收集容器日志,支持搜索和分析(例如:查詢某 Pod 的錯誤日志,分析故障原因)。
七、常見問題與排錯
7.1 節點未就緒(NotReady)
- 可能原因:
- kubelet 未運行:執行
systemctl status kubelet檢查狀態,若未啟動則systemctl start kubelet。 - 網絡插件未部署:節點間網絡不通,需部署 Calico/Flannel 等網絡插件(例如:
kubectl apply -f https://docs.projectcalico.org/v3.25/manifests/calico.yaml)。 - 資源不足:節點內存 / 磁盤不足,清理資源后重啟 kubelet(
systemctl restart kubelet)。
- kubelet 未運行:執行
- 排查命令:
kubectl describe node <節點名>查看節點事件,定位錯誤原因(例如:事件中顯示 “NetworkPluginNotReady” 表示網絡插件未就緒)。
7.2 Pod 啟動失敗(Pending/Error)
- 可能原因:
- 資源不足:節點剩余 CPU / 內存不足,無法滿足 Pod 需求(查看事件中的 “Insufficient cpu” 提示,需擴容節點或調整 Pod 資源請求)。
- 鏡像拉取失敗:鏡像地址錯誤或倉庫不可訪問,執行
kubectl describe pod <pod名>查看拉取日志(例如:“ErrImagePull” 表示鏡像拉取失敗,檢查鏡像名稱是否正確)。 - 健康檢查失敗:容器啟動后未通過就緒探針(Readiness Probe),需檢查應用啟動是否正常(例如:就緒探針配置為訪問
/health接口,若應用未實現該接口會導致啟動失敗)。
7.3 Service 無法訪問 Pod
- 可能原因:
- Pod 未就緒:Service 僅轉發請求到 “就緒” 狀態的 Pod,需確保 Pod 通過就緒檢查(
kubectl get pods <pod名> -o wide查看 Pod 狀態)。 - 網絡規則問題:kube-proxy 未正確配置 iptables 規則,可重啟 kube-proxy(
systemctl restart kube-proxy)。 - 標簽不匹配:Service 通過標簽選擇器關聯 Pod,若標簽錯誤則無法匹配(檢查 Service 的
selector與 Pod 的labels是否一致,例如:Service selector 為app=nginx,Pod 需有app=nginx標簽)。
- Pod 未就緒:Service 僅轉發請求到 “就緒” 狀態的 Pod,需確保 Pod 通過就緒檢查(
八、總結
Kubernetes 是容器編排領域的主流平臺,其核心價值在于:通過自動化部署、擴縮容、故障恢復等能力,解決容器化應用的大規模管理問題。
- 是什么:Kubernetes 是開源的容器編排平臺,用于自動化容器化應用的部署、擴展和管理。
- 為什么需要:傳統部署 / 虛擬化存在資源利用率低、部署慢等問題,容器化解決了這些問題,但大規模容器需要 Kubernetes 實現自動化管理。
- 核心優勢:提高資源利用率、簡化運維、支持云原生架構,幫助企業快速響應業務變化。
從應用部署演變到架構細節,Kubernetes 的知識體系雖然復雜,但掌握后能極大提升系統的可靠性和擴展性。對于初學者,建議從實踐入手(如部署一個 Nginx 應用),逐步理解核心概念(Pod、Service、Deployment)。
九、思考與答案
思考 1:容器與虛擬機的核心區別是什么?
- 答案:容器共享主機操作系統內核,僅包含應用及依賴,資源占用低(MB 級)、啟動快(秒級);虛擬機包含獨立操作系統,資源占用高(GB 級)、啟動慢(分鐘級)。容器是進程級隔離,虛擬機是系統級隔離。
思考 2:Kubernetes 控制平面的核心組件有哪些?各自的作用是什么?
- 答案:
- kube-apiserver:統一入口,處理所有請求。
- etcd:存儲集群狀態的數據庫。
- kube-scheduler:為 Pod 選擇合適的運行節點。
- kube-controller-manager:運行控制器,確保集群狀態符合預期。
- kubectl:命令行工具,操作集群。
思考 3:為什么說 Kubernetes 消除了 “編排” 的需要?
- 答案:傳統編排是按固定流程(A→B→C)執行任務,而 Kubernetes 通過控制器持續將當前狀態推向預期狀態,用戶只需定義 “想要什么”(如 3 個 Pod 副本),無需關心 “如何做”(如如何創建 / 刪除 Pod),因此無需手動編排步驟。
思考 4:企業使用 Kubernetes 時面臨的最大挑戰是什么?如何應對?
- 答案:最大挑戰是技能缺口(內部缺乏經驗、難以招聘專業人才)。應對方式:
- 內部培訓:通過官方文檔、認證課程(如 CKA)提升團隊技能。
- 采用托管服務:使用云廠商的托管 Kubernetes(如 AWS EKS、阿里云 ACK),減少底層維護成本。
- 引入簡化工具:如 Rancher 提供可視化界面,降低操作復雜度。






)





)


)
![【[CSP-J 2022] 上升點列】](http://pic.xiahunao.cn/【[CSP-J 2022] 上升點列】)


