
代碼結構

所有的代碼寫到cs336_basics/* 下面,在adapters.py里調用自己的.py,通過所有的test。
作業資料參考
karpathy視頻+倉庫:
視頻
github倉庫
測試項目運行環境
下載uv
uv官網倉庫
使用命令:
powershell -ExecutionPolicy ByPass -c "irm https://astral.sh/uv/install.ps1 | iex"
我直接運行pip install uv會報錯
進入項目文件夾下目錄:
uv self update # optional
uv sync
uv self-update 命令專門用于維護 uv 可執行文件本身。它的主要且唯一目的是檢查并安裝最新可用的 uv 版本。uv sync 命令在項目級別運行,專注于項目所依賴的 Python 包。其核心功能是確保虛擬環境中安裝的包與項目鎖文件( uv.lock 或 requirements.lock )中指定的版本完全一致(項目文件夾中有uv.lock文件)。
運行這兩條命令后,會看到文件夾下多出了.venv文件夾
激活虛擬環境
Set-ExecutionPolicy RemoteSigned -Scope CurrentUser
.venv\Scripts\Activate # windows命令
切換到虛擬環境后,運行命令
uv run pytest
由于是windows環境,我出現了報錯,原因是:tests/test_tokenizer.py 文件嘗試導入 resource 模塊,但該模塊在 Windows 系統上不可用。最開始我以為必須切換到linux環境,或者用云服務器跑,但是我只是需要在windows上測試,注釋掉test_tokenizer.py 文件中的import resource即可。kaggle和google colab還有AWS都提供了云服務器,可以白嫖。
再次運行命令后:
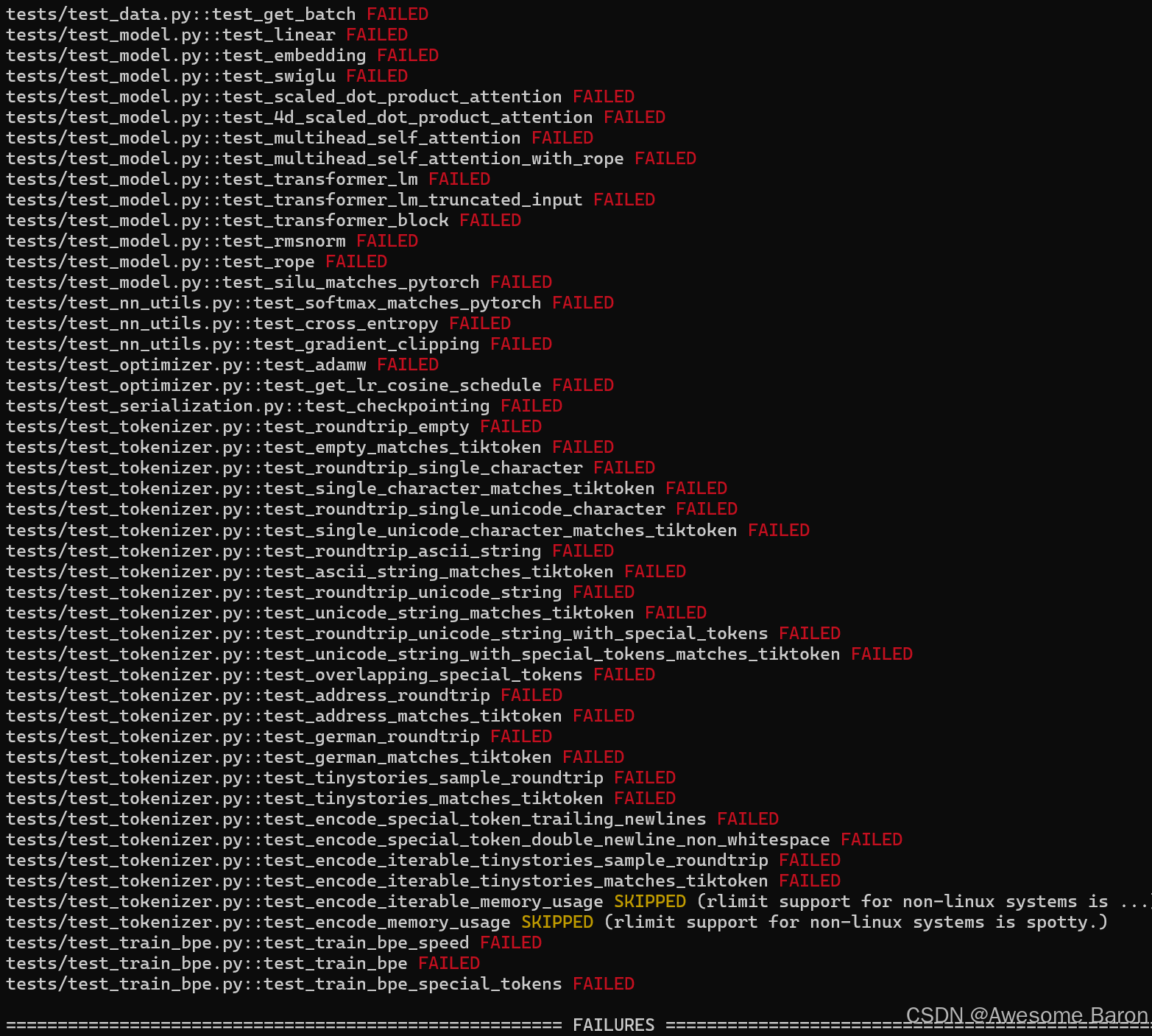
報錯: NotImplementedError
最初,所有測試應該 NotImplementedError 失敗。要將代碼實現連接到測試,要完成./tests/adapters.py 中的函數。
adapters.py 中的函數包括:
- run_linear
- run_embedding
- run_swiglu
- run_scaled_dot_product_attention
- run_multihead_self_attention
- run_multihead_self_attention_with_rope
- run_rope
- run_transformer_block
- run_transformer_lm
- run_rmsnorm
- run_silu
- run_get_batch
- run_softmax
- run_cross_entropy
- run_gradient_clipping
- get_adamw_cls
- run_get_lr_cosine_schedule
- run_save_checkpoint
- run_load_checkpoint
- get_tokenizer
- run_train_bpe
數據集下載
需要下載這兩個數據集:
- TinyStories
- OpenWebText
由于windows不方便下載,所以我在wsl下下載。踩坑:連接不到https://huggingface.co
后續發現可以鏡像站下載:https://hf-mirror.com/
用vscode連接wsl,然后新建一個文件download_data.sh,寫入命令
完整的命令如下:
#!/bin/bash# 創建數據目錄并進入echo "Creating data directory..."mkdir -p datacd data# 下載 TinyStories 數據集echo "Downloading TinyStoriesV2-GPT4-train.txt.gz... (This may take a while)"# 使用 curl -L 來正確處理重定向,并用 -o 指定輸出文件名curl -L -o TinyStoriesV2-GPT4-train.txt.gz "https://hf-mirror.com/datasets/roneneldan/TinyStories/resolve/main/TinyStoriesV2-GPT4-train.txt"echo "Downloading TinyStoriesV2-GPT4-valid.txt.gz..."curl -L -o TinyStoriesV2-GPT4-valid.txt.gz "https://hf-mirror.com/datasets/roneneldan/TinyStories/resolve/main/TinyStoriesV2-GPT4-valid.txt"# 下載并解壓 OWT sample 數據集echo "Downloading OWT sample dataset..."curl -L -o owt_train.txt.gz "https://hf-mirror.com/datasets/stanford-cs336/owt-sample/resolve/main/owt_train.txt.gz"gunzip -f owt_train.txt.gzcurl -L -o owt_valid.txt.gz "https://hf-mirror.com/datasets/stanford-cs336/owt-sample/resolve/main/owt_valid.txt.gz"gunzip -f owt_valid.txt.gz# 返回上級目錄echo "All files downloaded and processed successfully."cd ..
owt的文件下好后看似是壓縮包,實際已經解壓好了,只需要把后綴名改成txt就好。
已經下載好的文件長這個樣子:

現在我們已經做好前期所有準備了!
)


)
![【[CSP-J 2022] 上升點列】](http://pic.xiahunao.cn/【[CSP-J 2022] 上升點列】)



)







動態內存分配與它的指針變量)


SmartWaterServer)